从源代码编译构建Hive3.1.3
从源代码编译构建Hive3.1.3
- 编译说明
- 编译Hive3.1.3
- 更改Maven配置
- 下载源码
- 修改项目pom.xml
- 修改hive源码
- 修改说明
- 修改standalone-metastore模块
- 修改ql模块
- 修改spark-client模块
- 修改druid-handler模块
- 修改llap-server模块
- 修改llap-tez模块
- 修改llap-common模块
- 编译打包
- 异常集合
- 异常1
- 异常2
- 异常3
- 异常4
- 编译打包成功
- 总结
编译说明
使用Hive官方提供的预编译安装包是最常见和推荐的方式来使用Hive,适用于大多数用户。这些预编译的安装包经过了测试和验证,在许多不同的环境中都能正常运行。
在某些特定情况下,可能需要从源代码编译Hive,而不是使用预编译的安装包。
编译Hive源代码的场景、原因如下:
1.定制配置:
如果希望对Hive进行一些特定的配置定制或修改,例如更改默认的参数设置、添加新的数据存储后端、集成新的执行引擎等,那么编译源代码将能够修改和定制 Hive 的配置。
2.功能扩展:
如果需要扩展Hive的功能,例如添加自定义的 UDF(用户定义函数)、UDAF(用户定义聚合函数)、UDTF(用户定义表生成函数)等,编译源代码将添加和构建这些自定义功能。
3.调试和修改 Bug:
如果在使用Hive过程中遇到了问题,或者发现了bug,并希望进行调试和修复,那么编译源代码将能够获得运行时的源代码,进而进行调试和修改。
4.最新特性和改进:
如果希望使用Hive的最新特性、改进和优化,但这些特性尚未发布到官方的预编译包中,可以从源代码编译最新的版本,以获得并使用这些功能。
5.参与社区贡献:
如果对Hive有兴趣并希望为其开发做贡献,通过编译源代码,可以获取到完整的开发环境,包括构建工具、测试框架和源代码,以便与Hive社区一起开发和贡献代码。
编译Hive3.1.3
当使用Spark作为Hive的执行引擎时,但是Hive3.1.3本身支持的Spark版本是2.3,故此需要重新编译Hive,让Hive支持较新版本的Spark。计划编译Hive支持Spark3.4.0,Hadoop版本3.1.3
更改Maven配置
更改maven的settings.xml文件,看情况决定是否添加如下仓库地址,仅供参考:
<!-- 阿里云仓库 --><mirror><id>aliyun-central</id><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/central</url><mirrorOf>*</mirrorOf></mirror><!-- 中央仓库 --><mirror><id>repo</id><mirrorOf>central</mirrorOf><name>Human Readable Name for this Mirror.</name><url>https://repo.maven.apache.org/maven2</url></mirror>
下载源码
下载需要编译的Hive版本源码,这里打算重新编译Hive3.1.3
wget https://archive.apache.org/dist/hive/hive-3.1.3/pache-hive-3.1.3-src.tar.gz
IDEA打开pache-hive-3.1.3-src项目,打开项目后肯定会各种爆红,不用管
修改项目pom.xml
1.修改Hadoop版本
Hive3.1.3支持的Hadoop版本是3.1.10,但是Hive与Hadoop之间记得有个范围支持,故与Hadoop相关的操作看需求是否更改
<hadoop.version>3.1.0</hadoop.version><hadoop.version>3.1.3</hadoop.version>
清楚的记得Hadoop3.1.3使用日志版本是1.7.25
<slf4j.version>1.7.10</slf4j.version><slf4j.version>1.7.25</slf4j.version>
2.修改guava版本
由于Hive运行时会加载Hadoop依赖,因此需要修改Hive中guava版本为Hadoop中的guava版本。这里即使不更改,实则在使用Hive时也可能会进行更换guava版本操作(版本差异不大可以不用更换)
<guava.version>19.0</guava.version><guava.version>27.0-jre</guava.version>
3.修改spark版本
Hive3.1.3默认支持的Spark是2.3.0,这步也是核心,使其支持Spark3.4.0,使用版本较新,看需求适当降低。另外,明确指定Spark3.4.0使用的是Scala2.13版本,一同修改
<spark.version>2.3.0</spark.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.8</scala.version># 原计划编译spark3.4.0 特么的太多坑了 后面不得不放弃
<spark.version>3.4.0</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.17</scala.version># 掉坑里折腾惨了,降低spark版本
<spark.version>3.2.4</spark.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.17</scala.version>
修改hive源码
修改说明
修改Hive源代码,会对其进行删除、修改、新增操作,下图是Git版本控制对比图,大家应该都能看懂吧。但还是说明一下:
-:删除该行代码+:新增、修改该行代码

修改hive源码这个操作是核心操作,具体修改哪些源代码,参考:
https://github.com/gitlbo/hive/commits/3.1.2
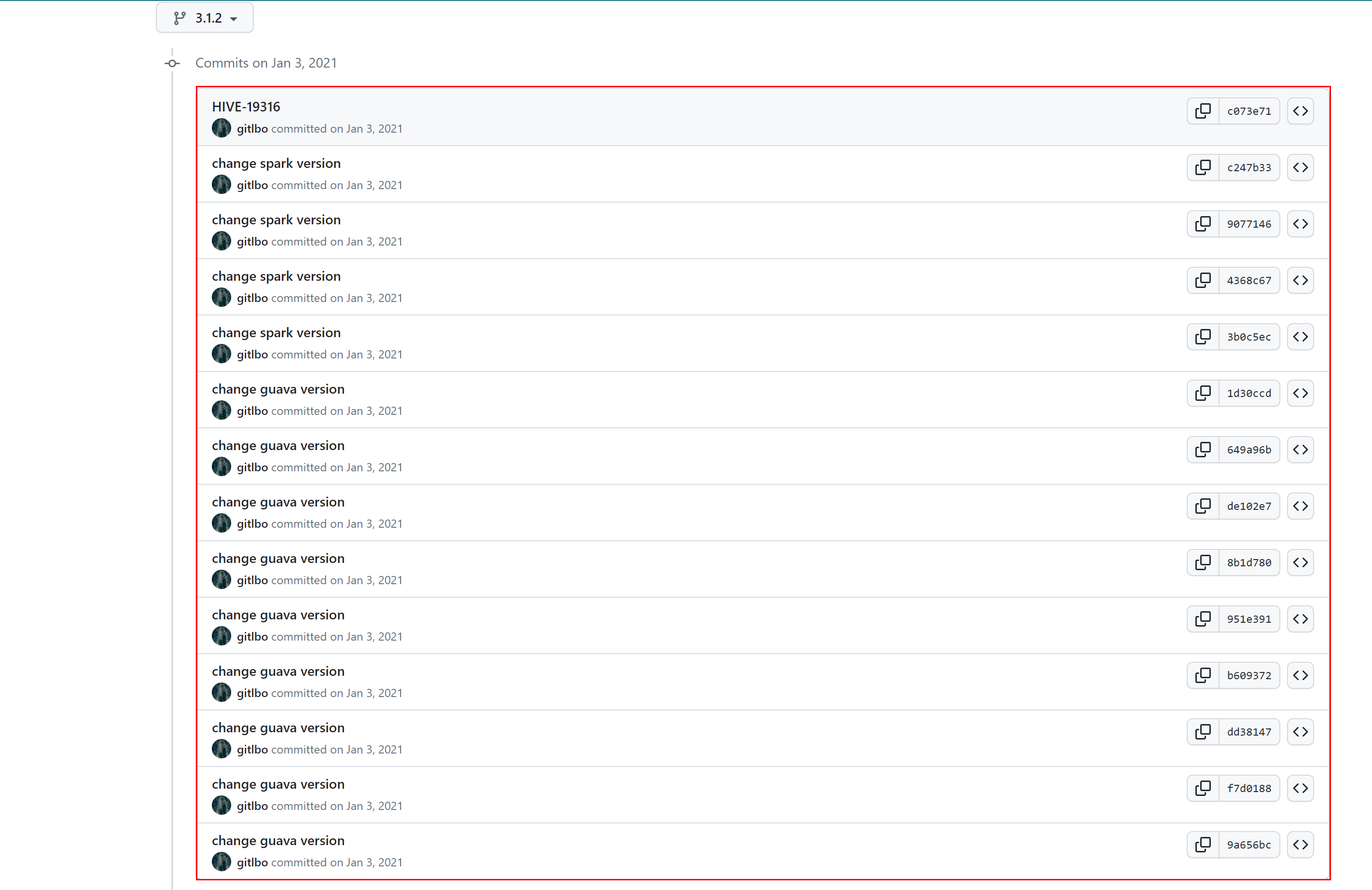
修改standalone-metastore模块
具体修改参考:https://github.com/gitlbo/hive/commit/c073e71ef43699b7aa68cad7c69a2e8f487089fd
创建ColumnsStatsUtils类
代码如下:
/** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.hadoop.hive.metastore.columnstats;import org.apache.hadoop.hive.metastore.api.ColumnStatisticsObj;
import org.apache.hadoop.hive.metastore.columnstats.cache.DateColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.DecimalColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.DoubleColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.LongColumnStatsDataInspector;
import org.apache.hadoop.hive.metastore.columnstats.cache.StringColumnStatsDataInspector;/*** Utils class for columnstats package.*/
public final class ColumnsStatsUtils {private ColumnsStatsUtils(){}/*** Convertes to DateColumnStatsDataInspector if it's a DateColumnStatsData.* @param cso ColumnStatisticsObj* @return DateColumnStatsDataInspector*/public static DateColumnStatsDataInspector dateInspectorFromStats(ColumnStatisticsObj cso) {DateColumnStatsDataInspector dateColumnStats;if (cso.getStatsData().getDateStats() instanceof DateColumnStatsDataInspector) {dateColumnStats =(DateColumnStatsDataInspector)(cso.getStatsData().getDateStats());} else {dateColumnStats = new DateColumnStatsDataInspector(cso.getStatsData().getDateStats());}return dateColumnStats;}/*** Convertes to StringColumnStatsDataInspector* if it's a StringColumnStatsData.* @param cso ColumnStatisticsObj* @return StringColumnStatsDataInspector*/public static StringColumnStatsDataInspector stringInspectorFromStats(ColumnStatisticsObj cso) {StringColumnStatsDataInspector columnStats;if (cso.getStatsData().getStringStats() instanceof StringColumnStatsDataInspector) {columnStats =(StringColumnStatsDataInspector)(cso.getStatsData().getStringStats());} else {columnStats = new StringColumnStatsDataInspector(cso.getStatsData().getStringStats());}return columnStats;}/*** Convertes to LongColumnStatsDataInspector if it's a LongColumnStatsData.* @param cso ColumnStatisticsObj* @return LongColumnStatsDataInspector*/public static LongColumnStatsDataInspector longInspectorFromStats(ColumnStatisticsObj cso) {LongColumnStatsDataInspector columnStats;if (cso.getStatsData().getLongStats() instanceof LongColumnStatsDataInspector) {columnStats =(LongColumnStatsDataInspector)(cso.getStatsData().getLongStats());} else {columnStats = new LongColumnStatsDataInspector(cso.getStatsData().getLongStats());}return columnStats;}/*** Convertes to DoubleColumnStatsDataInspector* if it's a DoubleColumnStatsData.* @param cso ColumnStatisticsObj* @return DoubleColumnStatsDataInspector*/public static DoubleColumnStatsDataInspector doubleInspectorFromStats(ColumnStatisticsObj cso) {DoubleColumnStatsDataInspector columnStats;if (cso.getStatsData().getDoubleStats() instanceof DoubleColumnStatsDataInspector) {columnStats =(DoubleColumnStatsDataInspector)(cso.getStatsData().getDoubleStats());} else {columnStats = new DoubleColumnStatsDataInspector(cso.getStatsData().getDoubleStats());}return columnStats;}/*** Convertes to DecimalColumnStatsDataInspector* if it's a DecimalColumnStatsData.* @param cso ColumnStatisticsObj* @return DecimalColumnStatsDataInspector*/public static DecimalColumnStatsDataInspector decimalInspectorFromStats(ColumnStatisticsObj cso) {DecimalColumnStatsDataInspector columnStats;if (cso.getStatsData().getDecimalStats() instanceof DecimalColumnStatsDataInspector) {columnStats =(DecimalColumnStatsDataInspector)(cso.getStatsData().getDecimalStats());} else {columnStats = new DecimalColumnStatsDataInspector(cso.getStatsData().getDecimalStats());}return columnStats;}
}
接着修改以下内容,具体修改参考以下截图说明
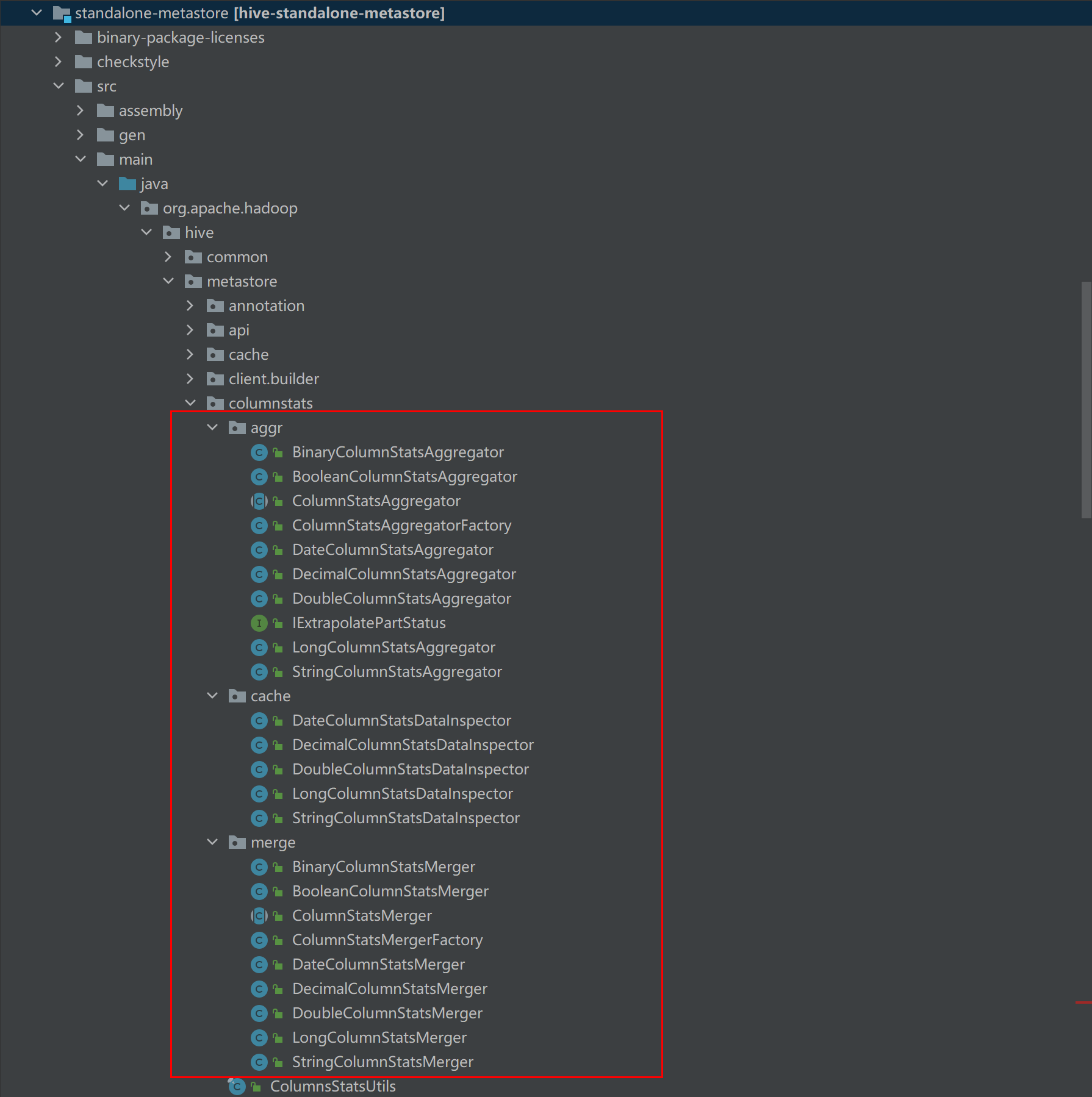
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/DateColumnStatsAggregator.java
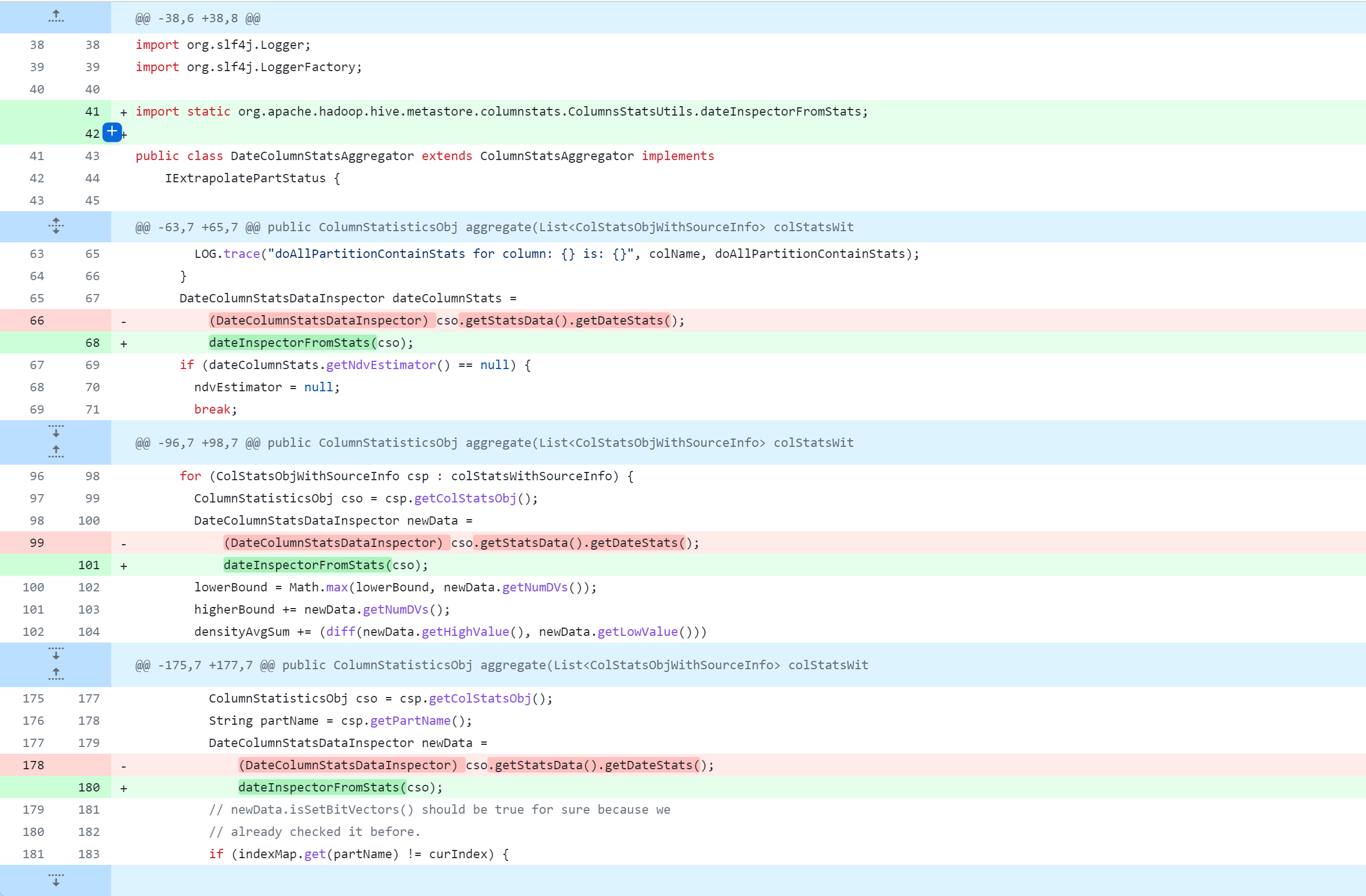
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/DecimalColumnStatsAggregator.java
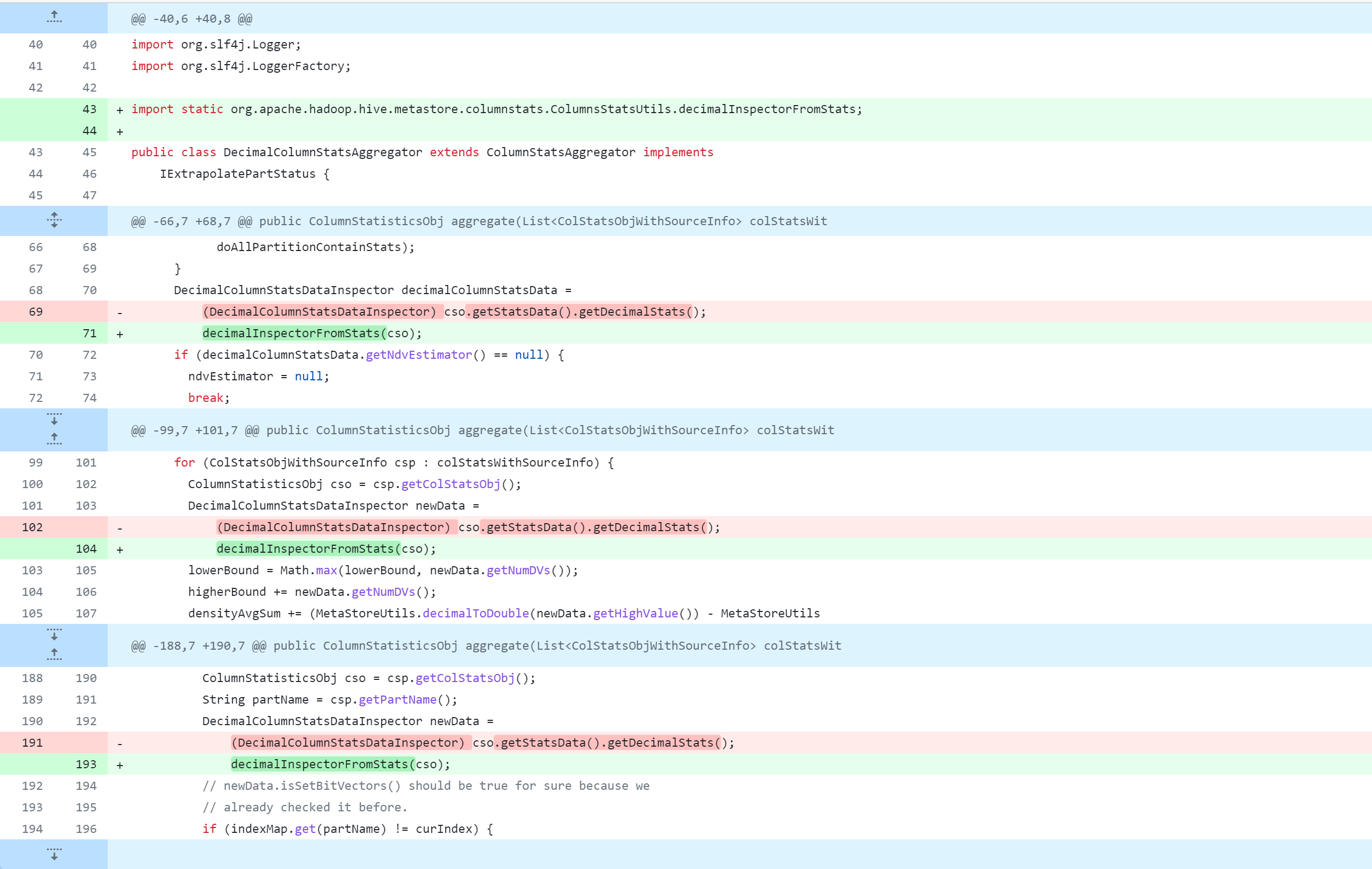
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/DoubleColumnStatsAggregator.java
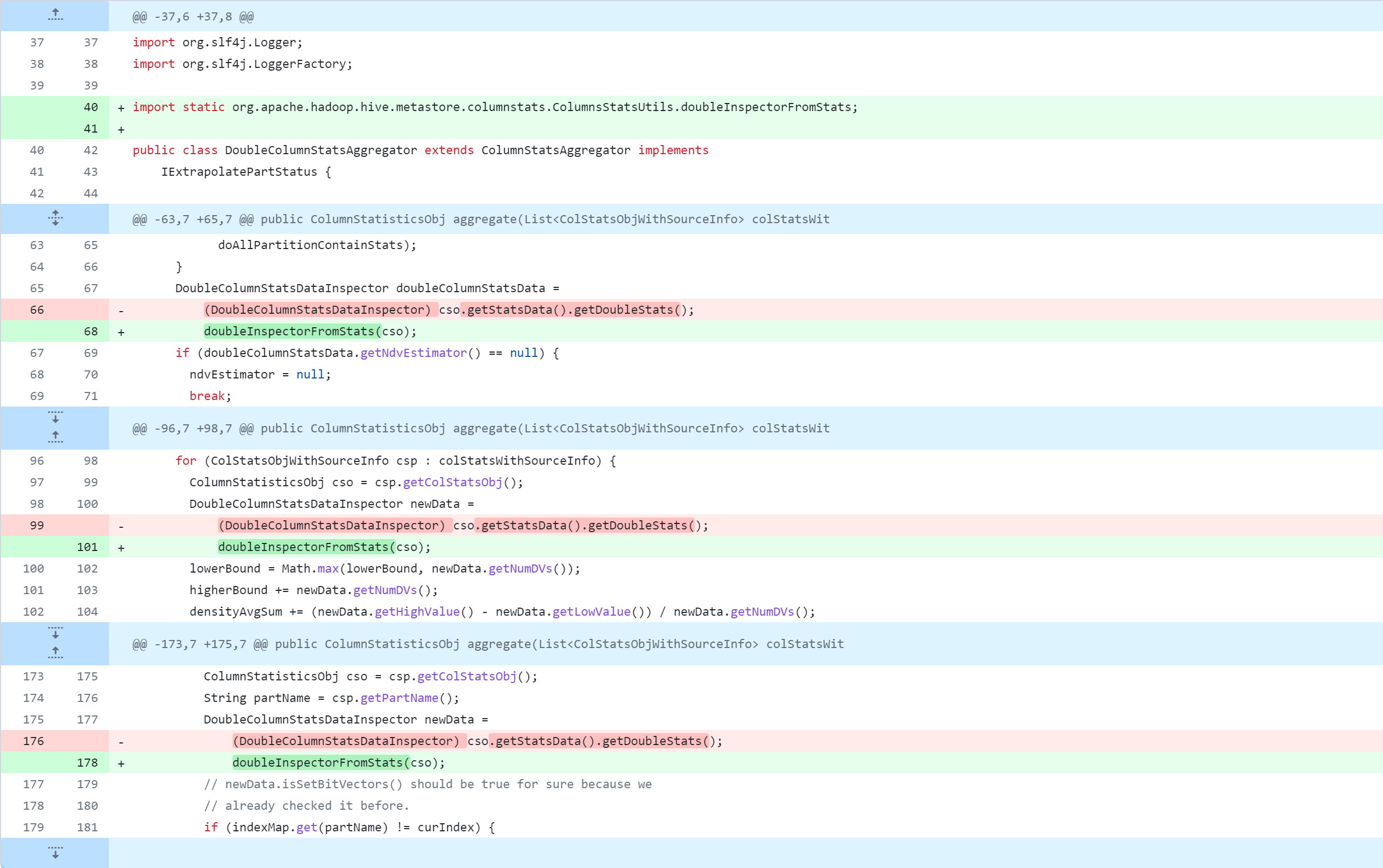
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/LongColumnStatsAggregator.java
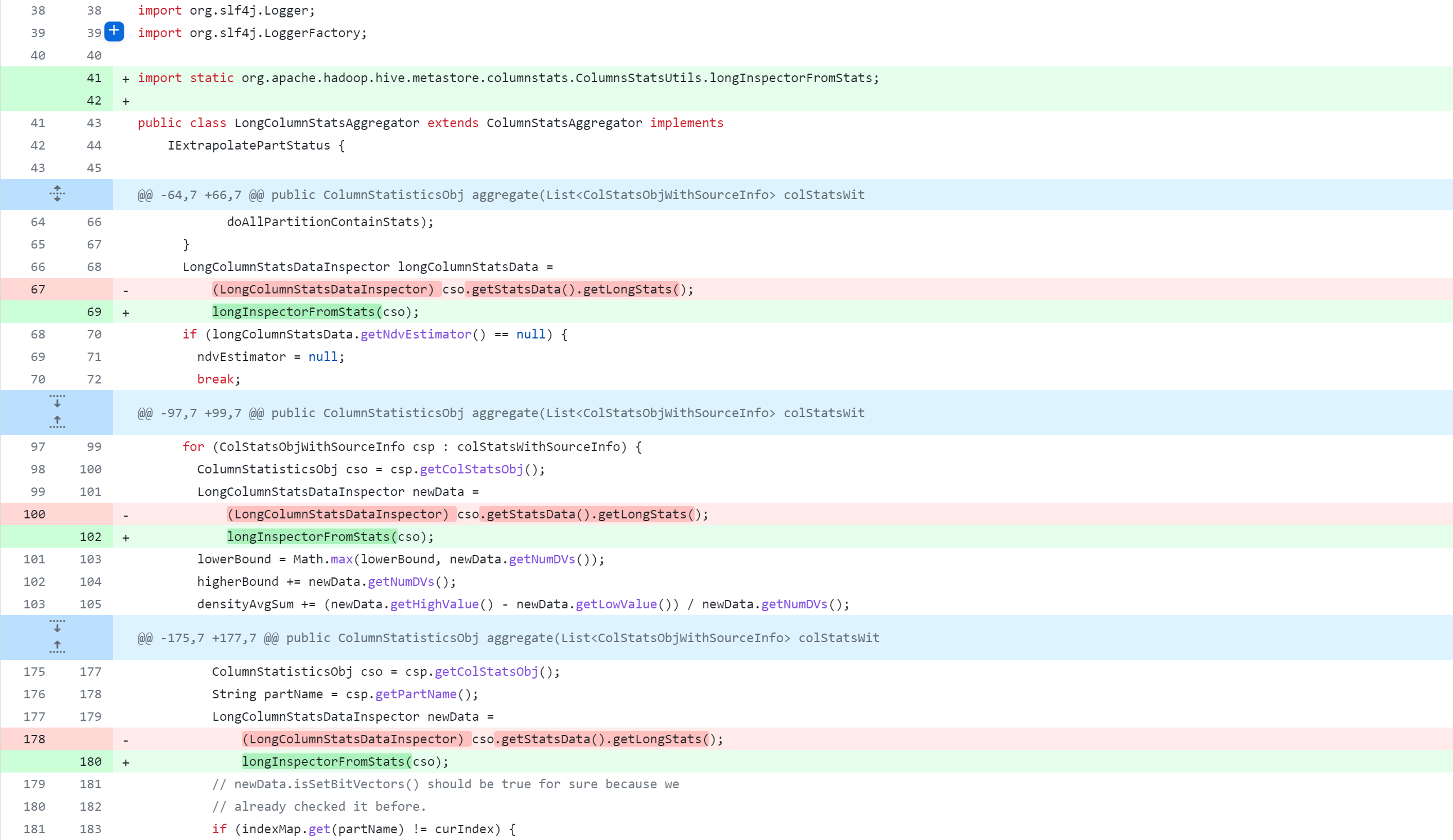
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/aggr/StringColumnStatsAggregator.java
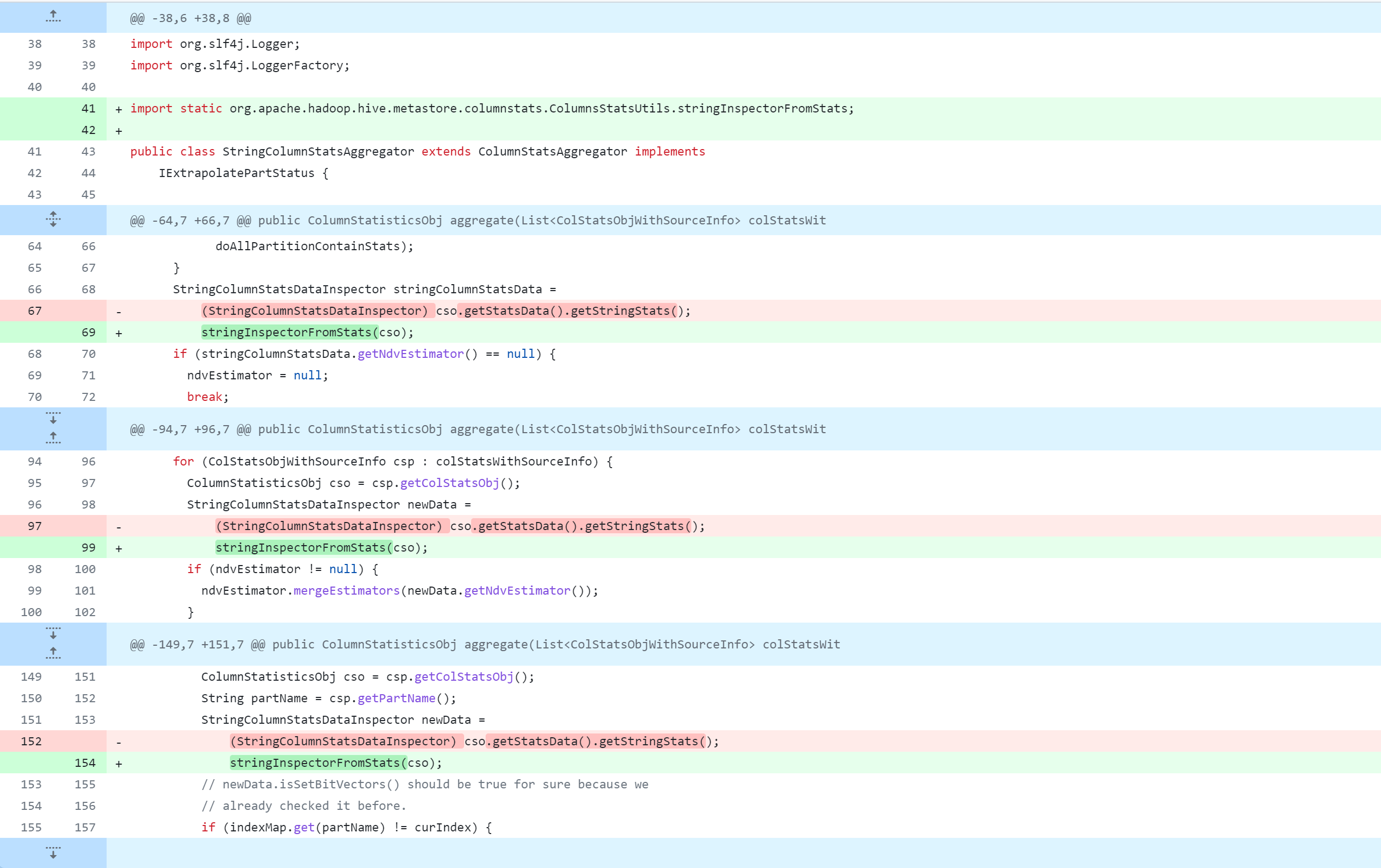
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/DateColumnStatsDataInspector.java
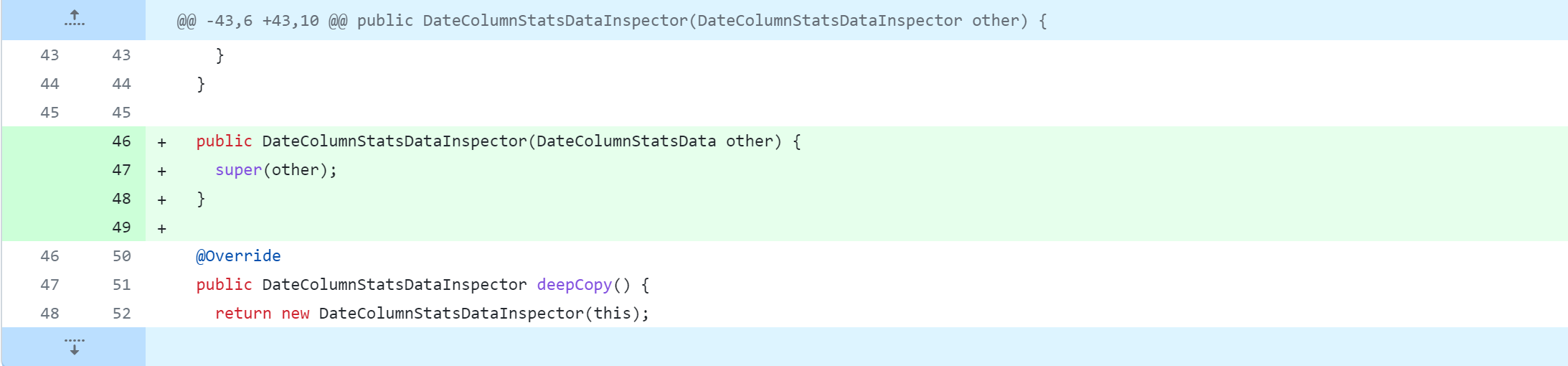
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/DecimalColumnStatsDataInspector.java
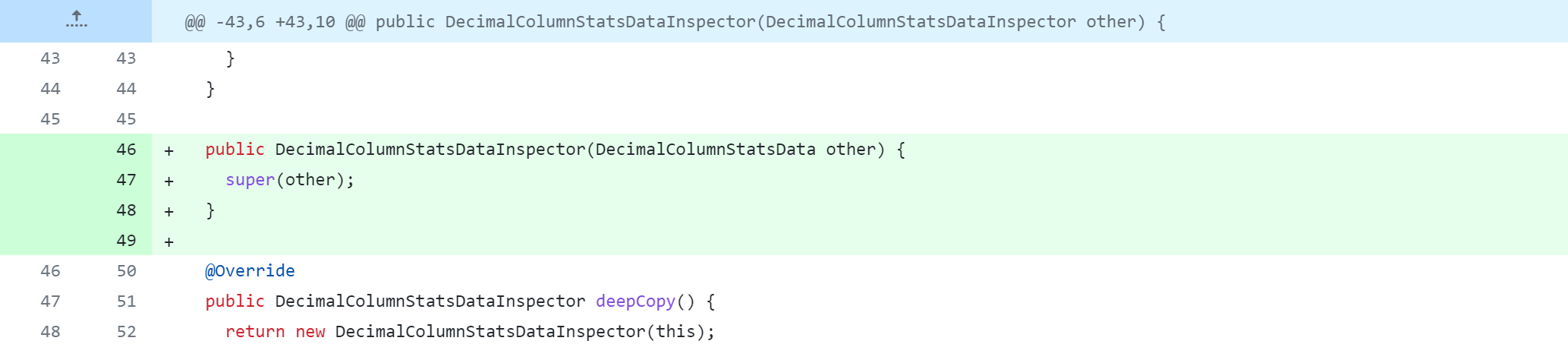
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/DoubleColumnStatsDataInspector.java
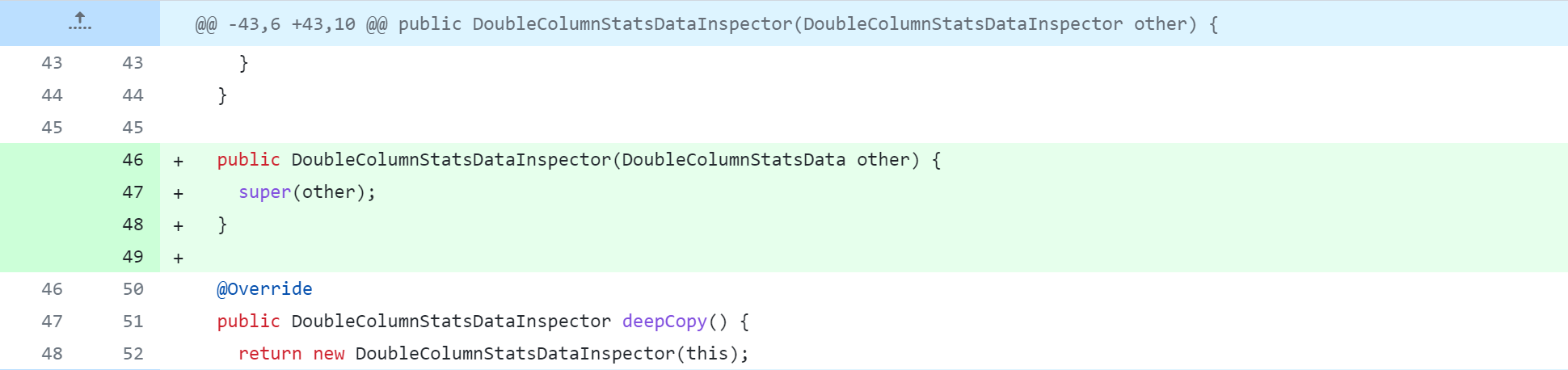
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/LongColumnStatsDataInspector.java
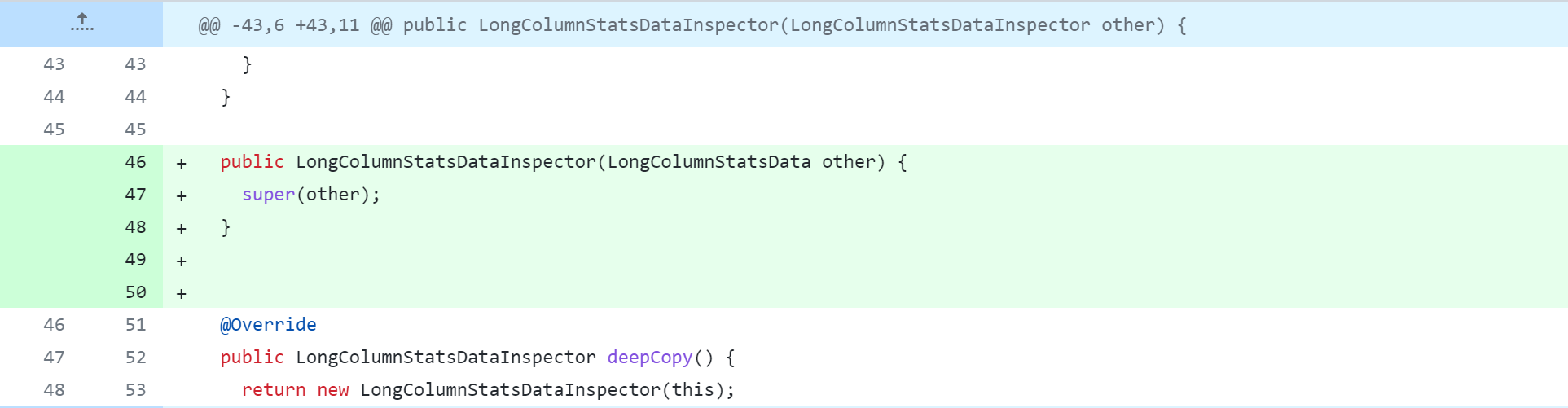
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/cache/StringColumnStatsDataInspector.java
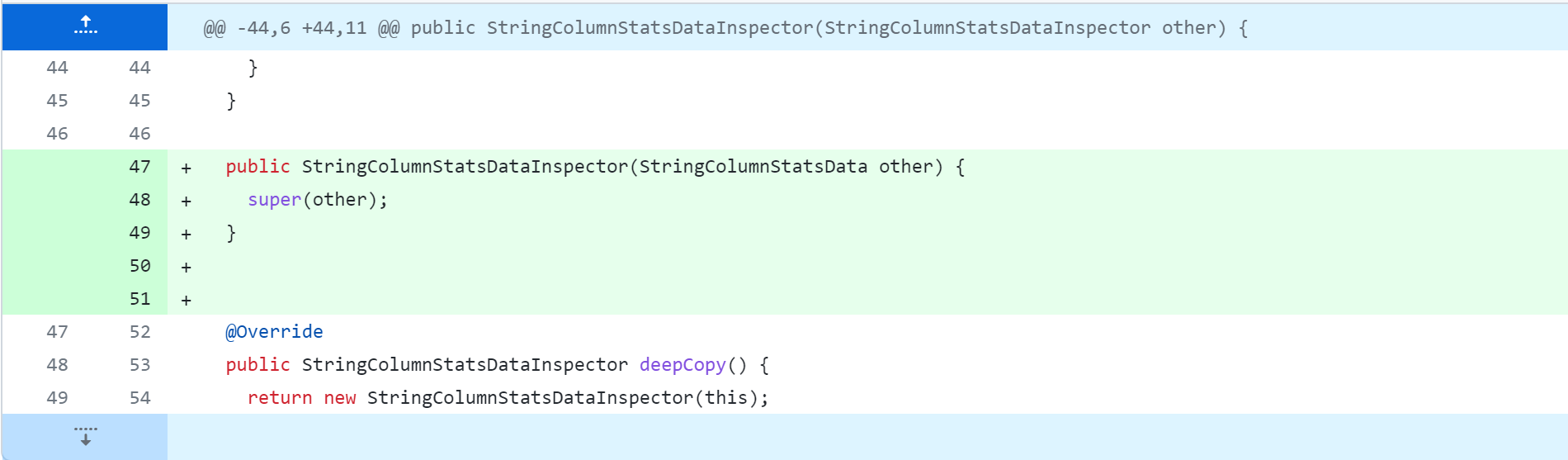
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/DateColumnStatsMerger.java
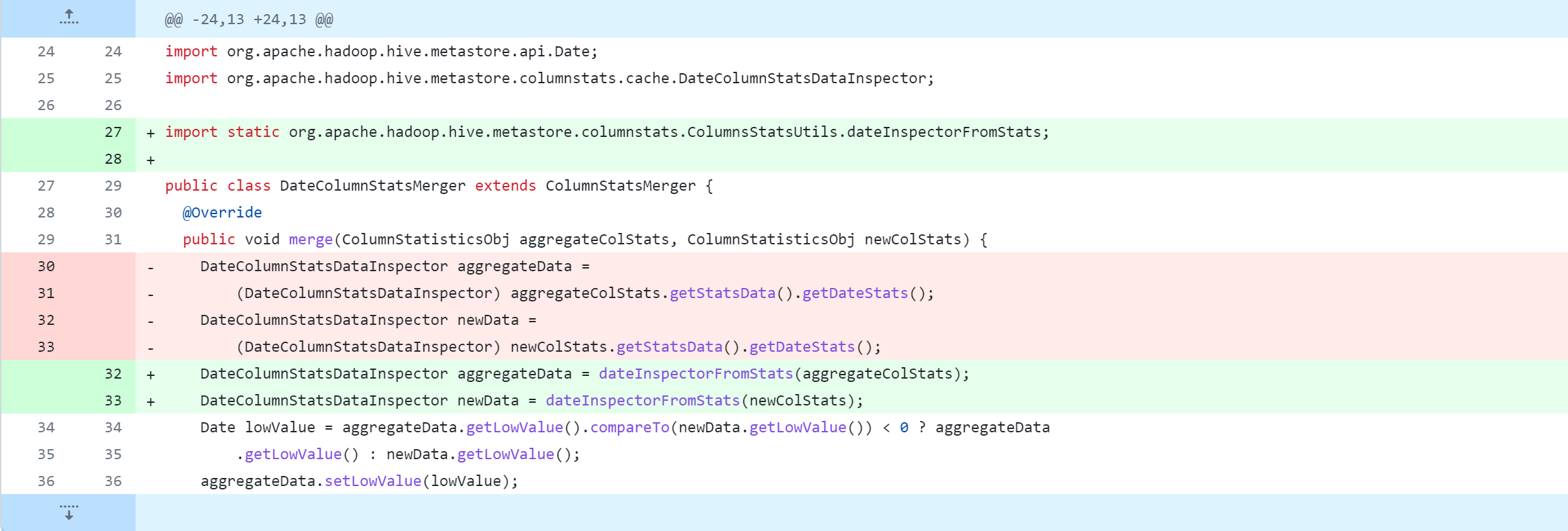
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/DecimalColumnStatsMerger.java
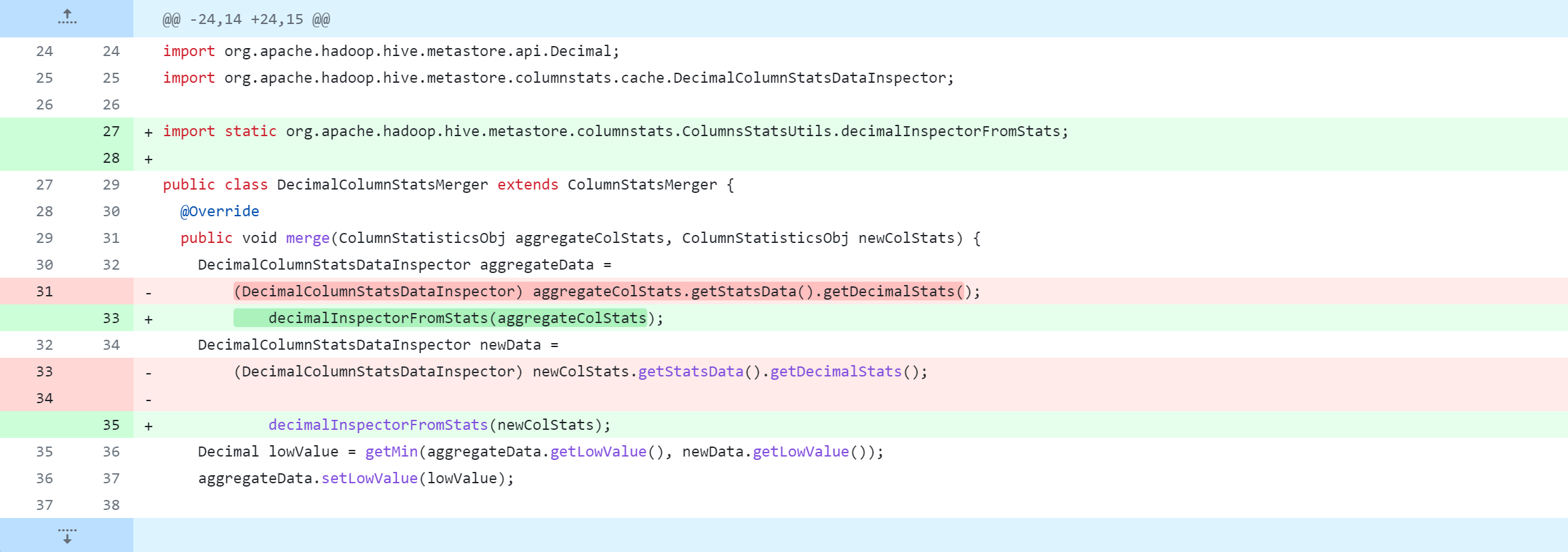
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/DoubleColumnStatsMerger.java
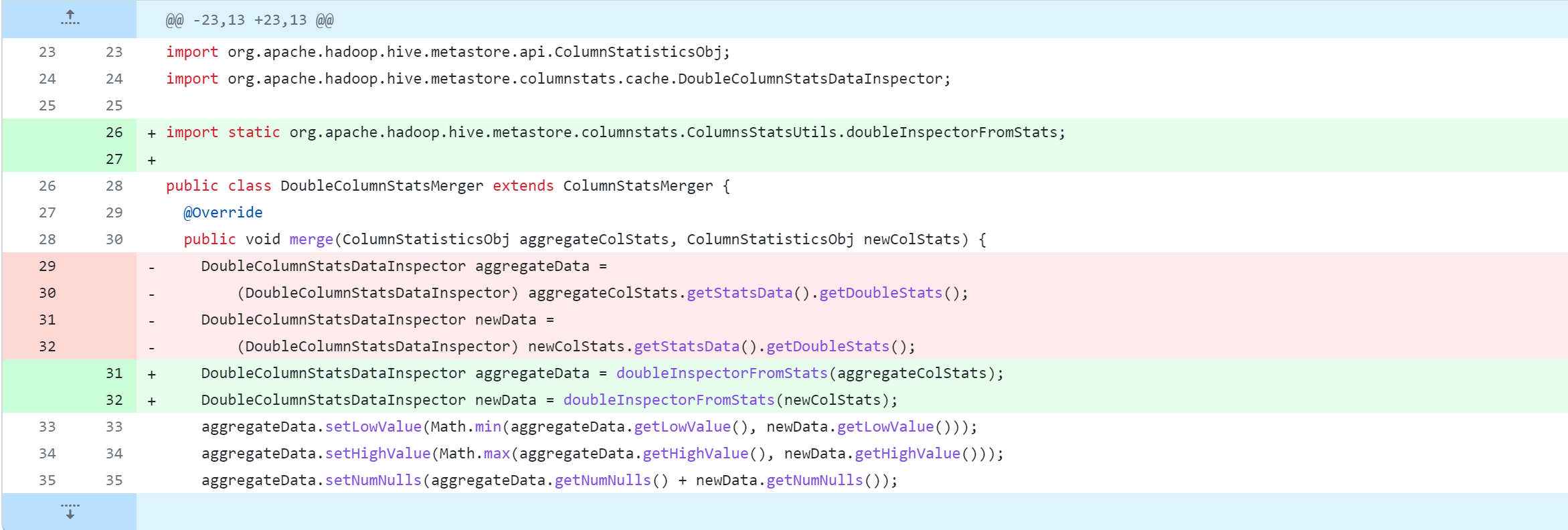
standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/LongColumnStatsMerger.java

standalone-metastore/src/main/java/org/apache/hadoop/hive/metastore/columnstats/merge/StringColumnStatsMerger.java

修改ql模块
ql/src/test/org/apache/hadoop/hive/ql/stats/TestStatsUtils.java

ql/src/test/org/apache/hadoop/hive/ql/exec/tez/SampleTezSessionState.java
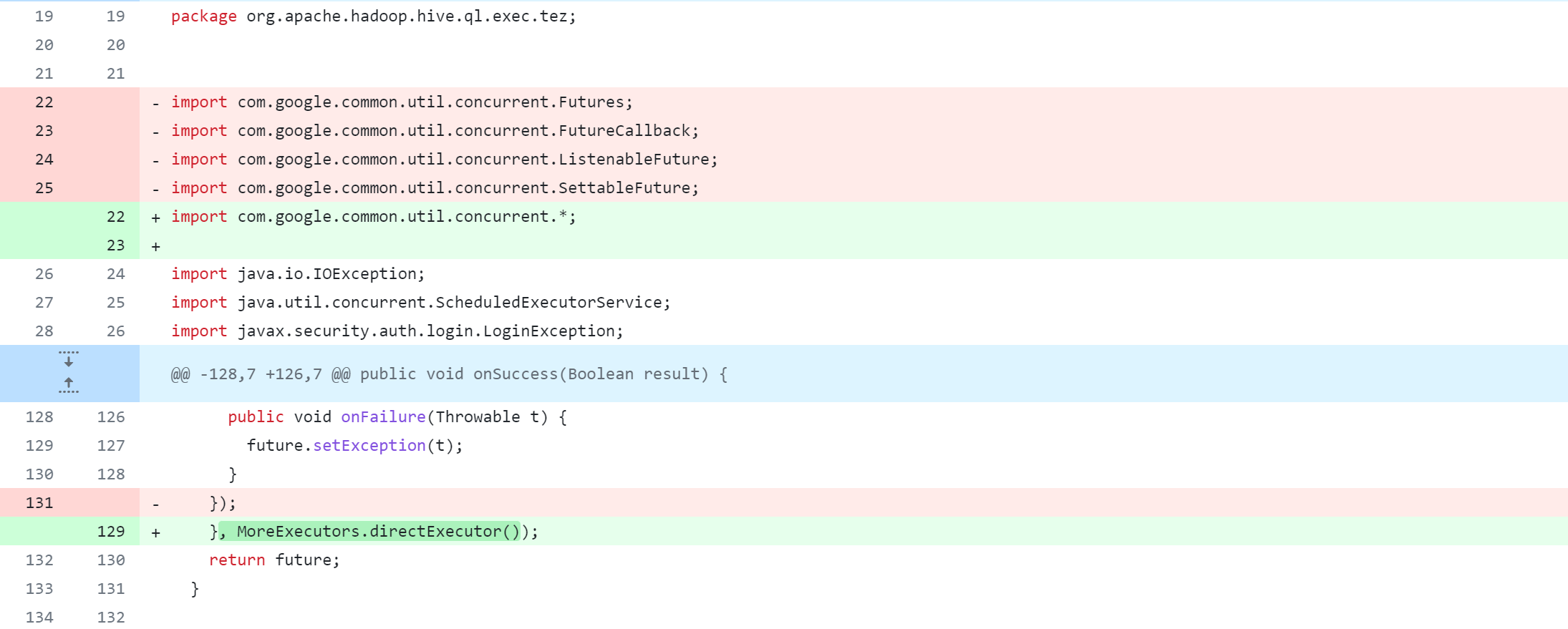
ql/src/java/org/apache/hadoop/hive/ql/exec/tez/WorkloadManager.java
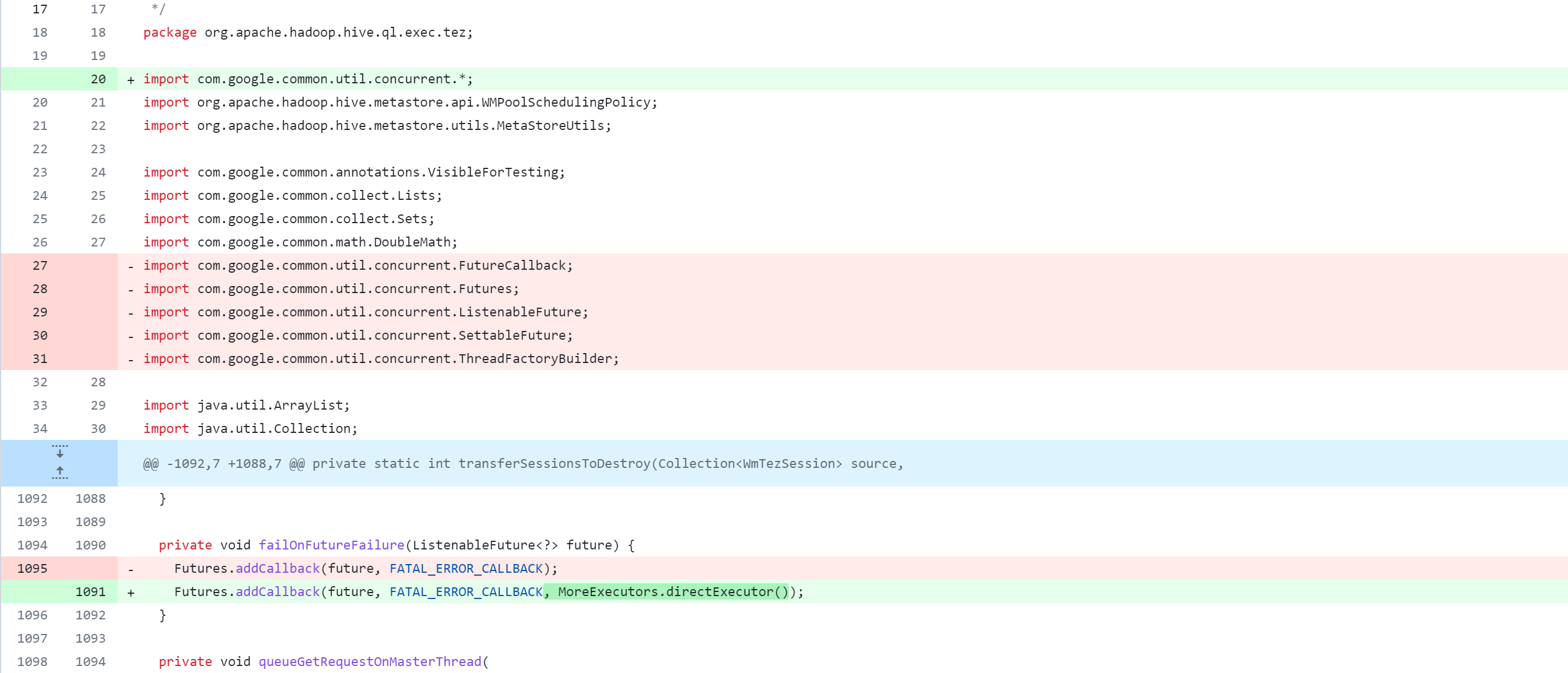

修改spark-client模块
spark-client/src/main/java/org/apache/hive/spark/client/metrics/ShuffleWriteMetrics.java

spark-client/src/main/java/org/apache/hive/spark/counter/SparkCounter.java
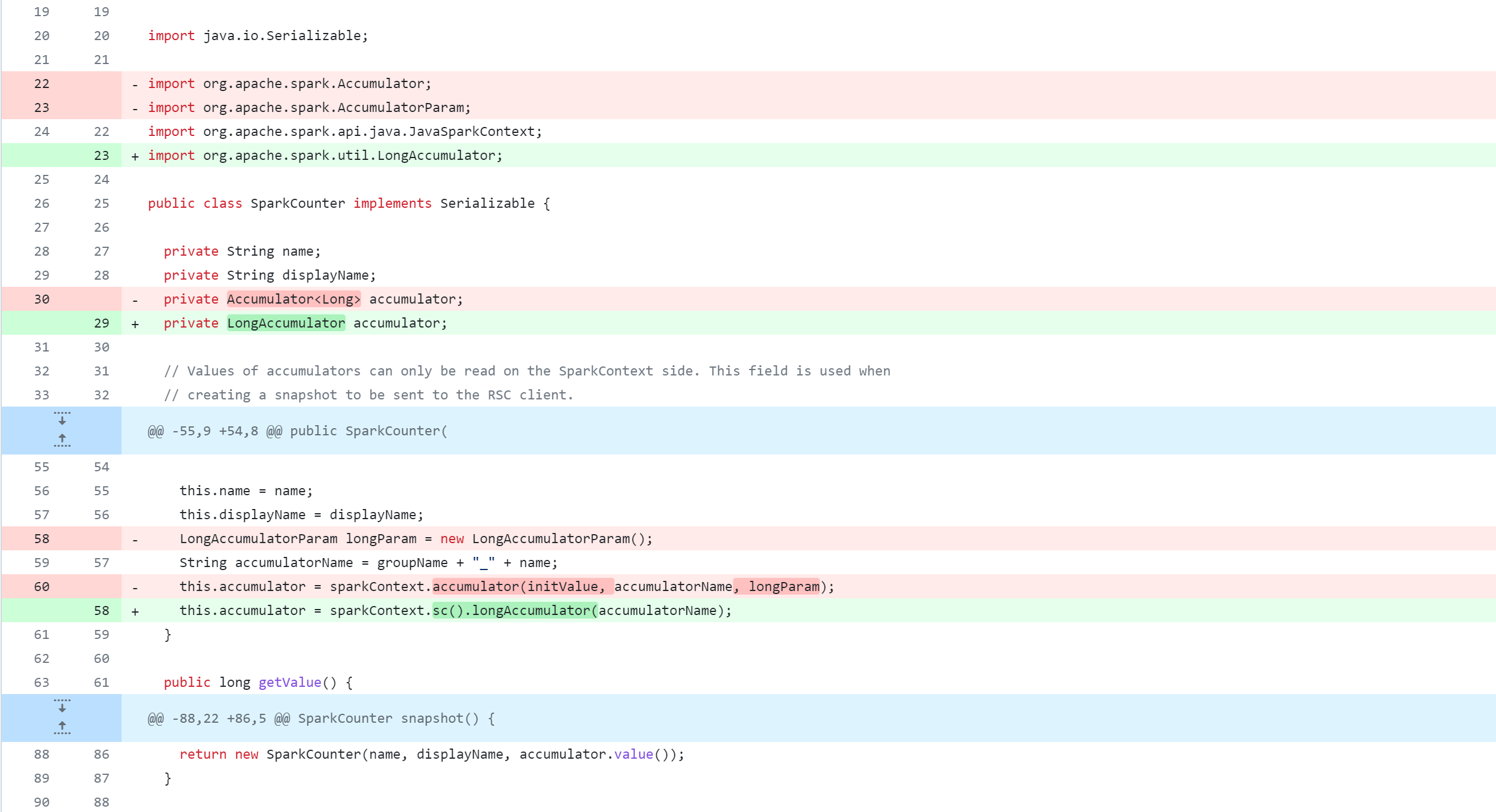
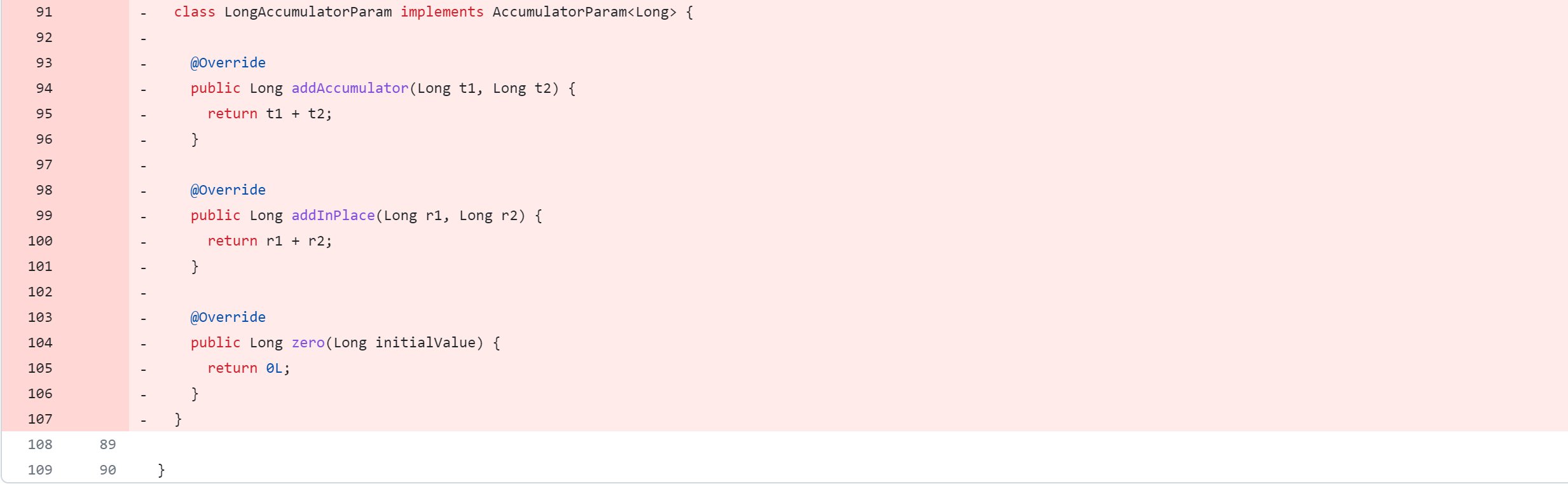
修改druid-handler模块
druid-handler/src/java/org/apache/hadoop/hive/druid/serde/DruidScanQueryRecordReader.java
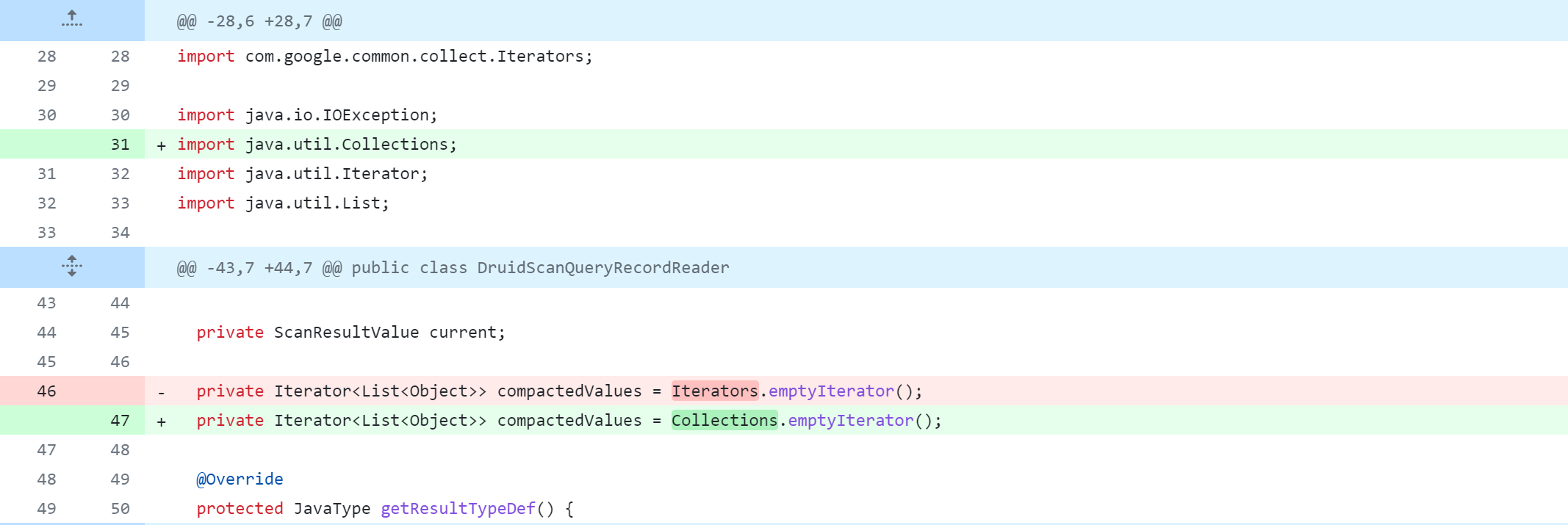
修改llap-server模块
llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/AMReporter.java
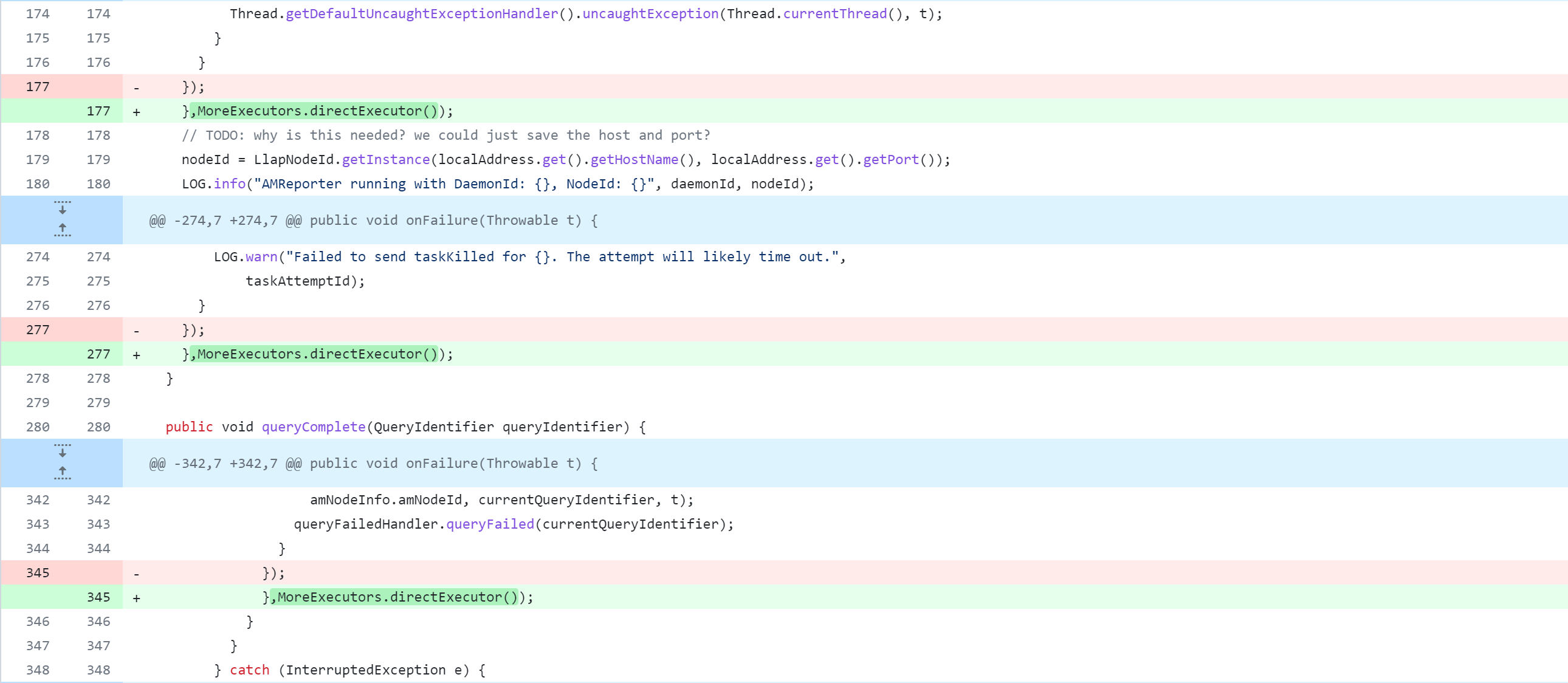
llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/LlapTaskReporter.java

llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/TaskExecutorService.java

修改llap-tez模块
llap-tez/src/java/org/apache/hadoop/hive/llap/tezplugins/LlapTaskSchedulerService.java
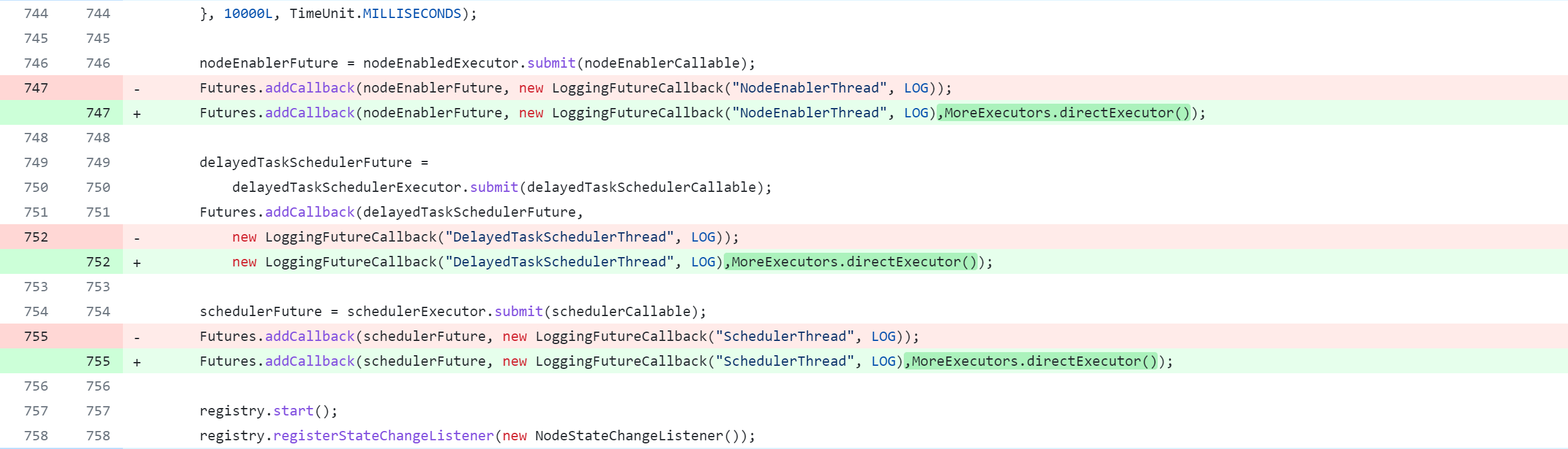
修改llap-common模块
llap-common/src/java/org/apache/hadoop/hive/llap/AsyncPbRpcProxy.java
编译打包
对Hive源码修改完成后,执行编译打包命令:
mvn clean package -Pdist -DskipTests -Dmaven.javadoc.skip=truemvn clean package -Pdist -DskipTests
在执行编译打包命令过程中,肯定会有各种问题的,这些问题是需要解决的,期间遇到的各种异常请参考下方异常集合对比解决。
注意点
1.有时本地仓库中的缓存可能会引起依赖项解析错误。可以尝试清理该项目依赖的本地仓库中的maven包,这个命令会清理pom.xml中的包,并重新下载,执行以下命令:
mvn dependency:purge-local-repository
2.修改Pom.xml文件版本号,或更改代码、安装Jar到本地仓库后,建议关闭IDEA重新打开进入,防止缓存、或者更新不及时
异常集合
注意:以下异常均是按照编译Hive支持Spark3.4.0过程中产生的异常,后来降低了Spark的版本。
异常1
1.maven会提示无法找到、无法下载某个Jar包、或者下载Jar耗时长(即使开启魔法也是)
例如:maven仓库找不到
hive-upgrade-acid-3.1.3.jar与pentaho-aggdesigner-algorithm-5.1.5-jhyde_2.jar
具体异常如下,仅供参考:
[ERROR] Failed to execute goal on project hive-upgrade-acid: Could not resolve dependencies for project org.apache.hive:hive-upgrade-acid:jar:3.1.3: Failure to find org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde in https://maven.aliyun.com/repository/central was cached in the local repository, resolution will not be reattempted until the update interval of aliyun-central has elapsed or updates are forced -> [Help 1]
解决方案:
到以下仓库搜索需要的Jar包,手动下载,并安装到本地仓库
仓库地址1:https://mvnrepository.com/
仓库地址2:https://central.sonatype.com/
仓库地址3:https://developer.aliyun.com/mvn/search
将一个JAR安装到本地仓库,示例命令的语法:
mvn install:install-file -Dfile=<path-to-jar> -DgroupId=<group-id> -DartifactId=<artifact-id> -Dversion=<version> -Dpackaging=<packaging><path-to-jar>:JAR文件的路径,可以是本地文件系统的绝对路径。
<group-id>:项目组ID,通常采用反向域名格式,例如com.example。
<artifact-id>:项目的唯一标识符,通常是项目名称。
<version>:项目的版本号。
<packaging>:JAR文件的打包类型,例如jar。
mvn install:install-file -Dfile=./hive-upgrade-acid-3.1.3.jar -DgroupId=org.apache.hive -DartifactId=hive-upgrade-acid -Dversion=3.1.3 -Dpackaging=jarmvn install:install-file -Dfile=./pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jarmvn install:install-file -Dfile=./hive-metastore-2.3.3.jar -DgroupId=org.apache.hive -DartifactId=hive-metastore -Dversion=2.3.3 -Dpackaging=jarmvn install:install-file -Dfile=./hive-exec-3.1.3.jar -DgroupId=org.apache.hive -DartifactId=hive-exec -Dversion=3.1.3 -Dpackaging=jar
异常2
提示bash相关东西,心凉了一大截。由于window下操作,bash不支持。
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (generate-version-annotation) on project hive-common: An Ant BuildException has occured: Execute failed: java.io.IOException: Cannot run program "bash" (in directory "C:\Users\JackChen\Desktop\apache-hive-3.1.3-src\common"): CreateProcess error=2, 系统找不到指定的文件。
[ERROR] around Ant part ...<exec failonerror="true" executable="bash">... @ 4:46 in C:\Users\JackChen\Desktop\apache-hive-3.1.3-src\common\target\antrun\build-main.xml
解决方案:
正常来说,作为开发者,肯定有安装Git,Git有bash窗口,即在Git的Bash窗口执行编译打包命令
mvn clean package -Pdist -DskipTests
异常3
当前进度在Hive Llap Server失败
[INFO] Hive Llap Client ................................... SUCCESS [ 4.030 s]
[INFO] Hive Llap Tez ...................................... SUCCESS [ 4.333 s]
[INFO] Hive Spark Remote Client ........................... SUCCESS [ 5.382 s]
[INFO] Hive Query Language ................................ SUCCESS [01:28 min]
[INFO] Hive Llap Server ................................... FAILURE [ 7.180 s]
[INFO] Hive Service ....................................... SKIPPED
[INFO] Hive Accumulo Handler .............................. SKIPPED
[INFO] Hive JDBC .......................................... SKIPPED
[INFO] Hive Beeline ....................................... SKIPPED
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.6.1:compile (default-compile) on project hive-llap-server: Compilation failure
[ERROR] /C:/Users/JackChen/Desktop/apache-hive-3.1.3-src/llap-server/src/java/org/apache/hadoop/hive/llap/daemon/impl/QueryTracker.java:[30,32] org.apache.logging.slf4j.Log4jMarker▒▒org.apache.logging.slf4j▒в▒▒ǹ▒▒▒▒▒; ▒▒▒▒▒ⲿ▒▒▒▒▒▒ж▒▒▒▒▒з▒▒▒
[ERROR]
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :hive-llap-server
public class QueryTracker extends AbstractService {// private static final Marker QUERY_COMPLETE_MARKER = new Log4jMarker(new Log4jQueryCompleteMarker());private static final Marker QUERY_COMPLETE_MARKER = MarkerFactory.getMarker("MY_CUSTOM_MARKER");}
异常4
编译执行到Hive HCatalog Webhcat模块失败
[INFO] Hive HCatalog ...................................... SUCCESS [ 10.947 s]
[INFO] Hive HCatalog Core ................................. SUCCESS [ 7.237 s]
[INFO] Hive HCatalog Pig Adapter .......................... SUCCESS [ 2.652 s]
[INFO] Hive HCatalog Server Extensions .................... SUCCESS [ 9.255 s]
[INFO] Hive HCatalog Webhcat Java Client .................. SUCCESS [ 2.435 s]
[INFO] Hive HCatalog Webhcat .............................. FAILURE [ 7.284 s]
[INFO] Hive HCatalog Streaming ............................ SKIPPED
[INFO] Hive HPL/SQL ....................................... SKIPPED
[INFO] Hive Streaming ..................................... SKIPPED
具体异常:
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.6.1:compile (default-compile) on project hive-webhcat: Compilation failure
[ERROR] /root/apache-hive-3.1.3-src/hcatalog/webhcat/svr/src/main/java/org/apache/hive/hcatalog/templeton/Main.java:[258,31] 对于FilterHolder(java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>), 找不到合适的构造器
[ERROR] 构造器 org.eclipse.jetty.servlet.FilterHolder.FilterHolder(org.eclipse.jetty.servlet.BaseHolder.Source)不适用
[ERROR] (参数不匹配; java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>无法转换为org.eclipse.jetty.servlet.BaseHolder.Source)
[ERROR] 构造器 org.eclipse.jetty.servlet.FilterHolder.FilterHolder(java.lang.Class<? extends javax.servlet.Filter>)不适用
[ERROR] (参数不匹配; java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>无法转换为java.lang.Class<? extends javax.servlet.Filter>)
[ERROR] 构造器 org.eclipse.jetty.servlet.FilterHolder.FilterHolder(javax.servlet.Filter)不适用
[ERROR] (参数不匹配; java.lang.Class<org.apache.hadoop.hdfs.web.AuthFilter>无法转换为javax.servlet.Filter)
[ERROR]
[ERROR] -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoFailureException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <args> -rf :hive-webhcat
看源码发现AuthFilter是继承AuthenticationFilter,AuthenticationFilter又实现Filter,应该不会出现此异常信息才对,于是手动修改源码进行强制转换试试,发现任然不行。
public FilterHolder makeAuthFilter() throws IOException {
// FilterHolder authFilter = new FilterHolder(AuthFilter.class);FilterHolder authFilter = new FilterHolder((Class<? extends Filter>) AuthFilter.class);UserNameHandler.allowAnonymous(authFilter);
解决方案:
在IDEA中单独编译打包此模块,发现是能构建成功的
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 40.755 s
[INFO] Finished at: 2023-08-06T21:39:17+08:00
[INFO] ------------------------------------------------------------------------
于是乎产生了一个想法:
1.因为项目使用Maven进行打包(执行mvn package),再次执行相同的命令将不会重新打包项目
2.所以先针对项目执行clean命令,然后对该Webhcat模块打包,最后在整体编译打包时,不执行clean操作,直接运行 mvn package -Pdist -DskipTests。
注意:后来降低了Spark版本,没有产生该问题
编译打包成功
经过数个小时的解决问题与漫长的编译打包,终于成功,发现这个界面是多么的美好。
[INFO] --- maven-dependency-plugin:2.8:copy (copy) @ hive-packaging ---
[INFO] Configured Artifact: org.apache.hive:hive-jdbc:standalone:3.1.3:jar
[INFO] Copying hive-jdbc-3.1.3-standalone.jar to C:\Users\JackChen\Desktop\apache-hive-3.1.3-src\packaging\target\apache-hive-3.1.3-jdbc.jar
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Hive 3.1.3:
[INFO]
[INFO] Hive Upgrade Acid .................................. SUCCESS [ 5.264 s]
[INFO] Hive ............................................... SUCCESS [ 0.609 s]
[INFO] Hive Classifications ............................... SUCCESS [ 1.183 s]
[INFO] Hive Shims Common .................................. SUCCESS [ 2.239 s]
[INFO] Hive Shims 0.23 .................................... SUCCESS [ 2.748 s]
[INFO] Hive Shims Scheduler ............................... SUCCESS [ 2.286 s]
[INFO] Hive Shims ......................................... SUCCESS [ 1.659 s]
[INFO] Hive Common ........................................ SUCCESS [ 9.671 s]
[INFO] Hive Service RPC ................................... SUCCESS [ 6.608 s]
[INFO] Hive Serde ......................................... SUCCESS [ 6.042 s]
[INFO] Hive Standalone Metastore .......................... SUCCESS [ 42.432 s]
[INFO] Hive Metastore ..................................... SUCCESS [ 2.304 s]
[INFO] Hive Vector-Code-Gen Utilities ..................... SUCCESS [ 1.150 s]
[INFO] Hive Llap Common ................................... SUCCESS [ 3.343 s]
[INFO] Hive Llap Client ................................... SUCCESS [ 2.380 s]
[INFO] Hive Llap Tez ...................................... SUCCESS [ 2.476 s]
[INFO] Hive Spark Remote Client ........................... SUCCESS [31:34 min]
[INFO] Hive Query Language ................................ SUCCESS [01:09 min]
[INFO] Hive Llap Server ................................... SUCCESS [ 7.230 s]
[INFO] Hive Service ....................................... SUCCESS [ 28.343 s]
[INFO] Hive Accumulo Handler .............................. SUCCESS [ 6.179 s]
[INFO] Hive JDBC .......................................... SUCCESS [ 19.058 s]
[INFO] Hive Beeline ....................................... SUCCESS [ 4.078 s]
[INFO] Hive CLI ........................................... SUCCESS [ 3.436 s]
[INFO] Hive Contrib ....................................... SUCCESS [ 4.770 s]
[INFO] Hive Druid Handler ................................. SUCCESS [ 17.245 s]
[INFO] Hive HBase Handler ................................. SUCCESS [ 6.759 s]
[INFO] Hive JDBC Handler .................................. SUCCESS [ 4.202 s]
[INFO] Hive HCatalog ...................................... SUCCESS [ 1.757 s]
[INFO] Hive HCatalog Core ................................. SUCCESS [ 5.455 s]
[INFO] Hive HCatalog Pig Adapter .......................... SUCCESS [ 4.662 s]
[INFO] Hive HCatalog Server Extensions .................... SUCCESS [ 4.629 s]
[INFO] Hive HCatalog Webhcat Java Client .................. SUCCESS [ 4.652 s]
[INFO] Hive HCatalog Webhcat .............................. SUCCESS [ 8.899 s]
[INFO] Hive HCatalog Streaming ............................ SUCCESS [ 4.934 s]
[INFO] Hive HPL/SQL ....................................... SUCCESS [ 7.684 s]
[INFO] Hive Streaming ..................................... SUCCESS [ 4.049 s]
[INFO] Hive Llap External Client .......................... SUCCESS [ 3.674 s]
[INFO] Hive Shims Aggregator .............................. SUCCESS [ 0.557 s]
[INFO] Hive Kryo Registrator .............................. SUCCESS [03:17 min]
[INFO] Hive TestUtils ..................................... SUCCESS [ 1.154 s]
[INFO] Hive Packaging ..................................... SUCCESS [01:58 min]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 38:22 min (Wall Clock)
[INFO] Finished at: 2023-08-08T22:50:15+08:00
[INFO] ------------------------------------------------------------------------
总结
在整个编译、打包过程中,有2点非常重要:
1.相关Jar无法下载或者下载缓慢问题,一定要想方设法解决,因为Jar是构建的核心,缺一不可
2.Jar依赖解决了,但是任然存在可能的兼容性问题,编译问题,遇到问题一定要一一解决,解决一步走一步
相关文章:
从源代码编译构建Hive3.1.3
从源代码编译构建Hive3.1.3 编译说明编译Hive3.1.3更改Maven配置下载源码修改项目pom.xml修改hive源码修改说明修改standalone-metastore模块修改ql模块修改spark-client模块修改druid-handler模块修改llap-server模块修改llap-tez模块修改llap-common模块 编译打包异常集合异常…...
探索性测试及基本用例
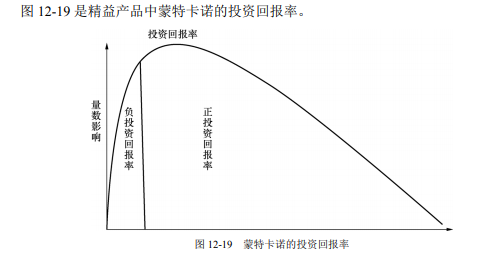
1 测试决策5要素 测试目标:所有的重要任务都完成了,而剩下没做的事情是比较次要的,我们做到这一点就可以尽早尽可能地降低发布风险。 测试方法:测试是一个不断抉择的过程,测试人员必须理解运行测试用例时和分析现有信…...
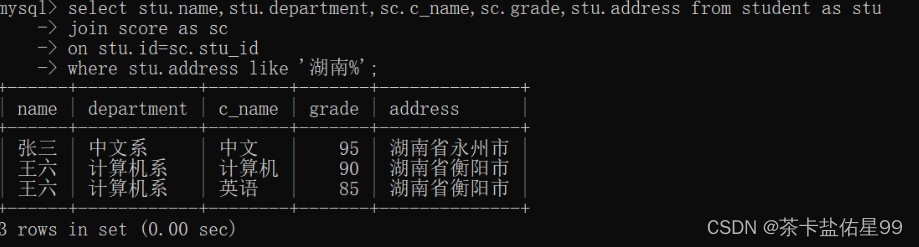
MYSQL 作业三
创建一个student表格: create table student( id int(10) not null unique primary key, name varchar(20) not null, sex varchar(4), birth year, department varchar(20), address varchar(50) ); 创建一个score表格 create table score( id int(10) n…...

【深度学习 | 感知器 MLP(BP神经网络)】掌握感知的艺术: 感知器和MLP-BP如何革新神经网络
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...

Kali Linux中常用的渗透测试工具有哪些?
今天我们将继续探讨Kali Linux的应用,这次的重点是介绍Kali Linux中常用的渗透测试工具。Kali Linux作为一款专业的渗透测试发行版,拥有丰富的工具集,能够帮助安全专家和渗透测试人员检测和评估系统的安全性。 1. 常用的渗透测试工具 以下是…...
SpringBoot案例 调用第三方接口传输数据
一、前言 最近再写调用三方接口传输数据的项目,这篇博客记录项目完成的过程,方便后续再碰到类似的项目可以快速上手 项目结构: 二、编码 这里主要介绍HttpClient发送POST请求工具类和定时器的使用,mvc三层架构编码不做探究 pom.x…...

第三章,矩阵,08-矩阵的秩及相关性质
第三章,矩阵,08-矩阵的秩及相关性质 秩的定义1最高阶非零子式定理秩的定义2秩的性质性质1性质2性质3性质4性质5性质6性质7性质8性质9性质10性质11性质12性质12的推论 玩转线性代数(20)矩阵的秩的笔记,相关证明以及例子见原文 秩的定义1 设矩…...
VS2019 + Qt : setToolTip的提示内容出现乱码
VS2019 Qt : setToolTip的提示内容出现乱码 在使用setToolTip()时, setToolTip(QString("asd你好!");标签提示只有英文是对的,中文是乱码! 应该是编码出了问题。默认情况下,Qt使用的是UTF-8编码…...

PO、BO、VO、DTO、DAO、POJO
文章目录 PO(Persistant Object)持久对象DO(Data Object)数据对象AO(Application Object)应用对象BO(Business Object)业务对象VO(Value Object)表现对象DTO&…...
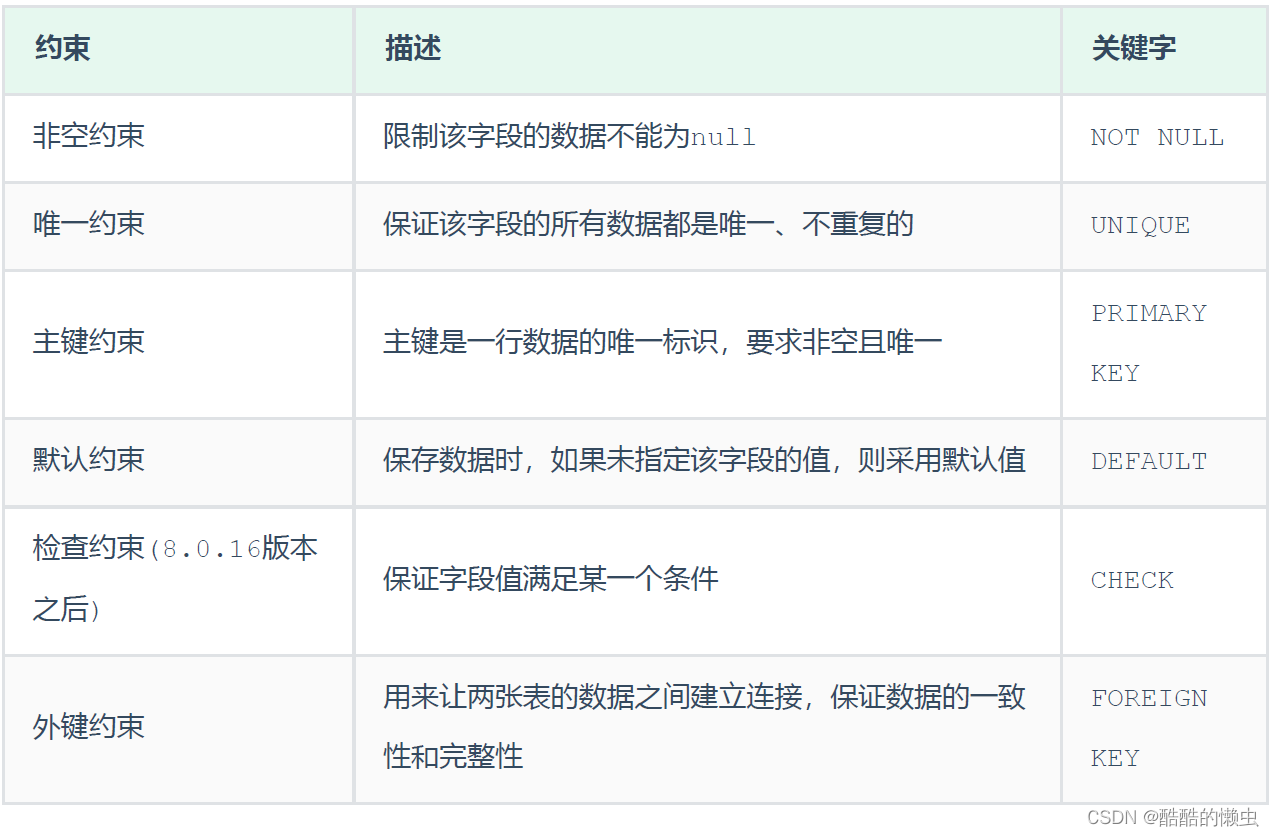
MySQL— 基础语法大全及操作演示!!!(下)
MySQL—— 基础语法大全及操作演示(下)—— 持续更新 三、函数3.1 字符串函数3.2 数值函数3.3 日期函数3.4 流程函数 四、约束4.1 概述4.2 约束演示4.3 外键约束4.3.1 介绍4.3.2 语法4.3.3 删除/更新行为 五、多表查询5.1 多表关系5.1.1 一对多5.1.2 多对…...

Springboot+vue网上招聘系统
系统的首页,头部有三个选项框,第一个是主页,第二个是才艺技能平台,第三个是登录注册。1.1.2 登录注册模块 系统的登录注册包括登录和注册两个部分。所有系统用户使用后台管理功能都需要经行登录,根据选择不同的身份进入…...

奥威BI数据可视化工具:报表就是平台,随时自助分析
别的数据可视化工具,报表就只是报表,而奥威BI数据可视化工具,一张报表就约等于一个平台,可随时展开多维动态自助分析,按需分析,立得数据信息。 奥威BI是一款多维立体分析数据的数据可视化工具。它可以帮助…...

iPhone(iPad)安装deb文件
最简单的方法就是把deb相关的文件拖入手机对应的目录,一般是DynamicLibraries文件夹 参考:探讨手机越狱和安装deb文件的几种方式研究 1、在 Mac 上安装 dpkg 命令 打包 deb 教程之在 Mac 上安装 dpkg 命令_xcode打包root权限deb_qq_34810996的博客-CS…...
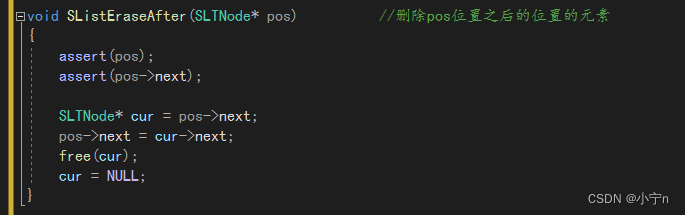
手撕单链表
目录 链表的概念和结构 单链表的实现 申请新结点 打印 尾插 头插 尾删 头删 编辑 查找 在pos位置前插入元素 在pos位置后插入元素 删除pos位置的元素 删除pos位置之后的位置的元素编辑 完整代码 SListNode.h SListNode.c 链表的概念和结构 链表是一种物理存储…...
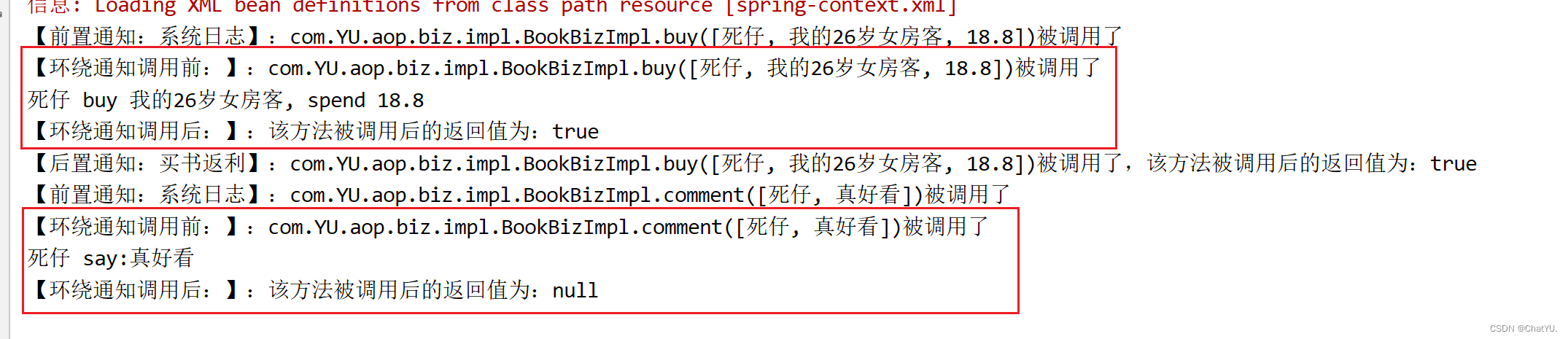
Spring-aop特点,专业术语及案例演示
一.aop简介 AOP(Aspect-Oriented Programming)是Spring框架的一个重要特性,它通过将横切关注点(cross-cutting concerns)从核心业务逻辑中分离出来,以模块化的方式在整个应用程序中重复使用。以下是关于AOP…...

探秘Java的Map集合:键值映射的奇妙世界
文章目录 1. 单列集合 vs. 双列集合2. Map接口:键与值的契约3. 深入探索HashMap3.1 特性与构造方法3.2 常用方法3.3 遍历HashMap 4. 美妙的LinkedHashMap 在Java编程中,集合是不可或缺的重要部分,它为我们提供了各种数据结构和算法的实现。其…...

git权限问题解决方法Access denied fatal: Authentication failed
文章目录 遇到Access denied 的权限问题解决方法1、git的密码修改过,但是本地没更新。2、确定问题,然后增加配置① 查询用户信息②如果名称和email不对,设置名称:③ 检查ssh-add是否链接正常④ 设置不要每次都输入用户名密码 3、配…...
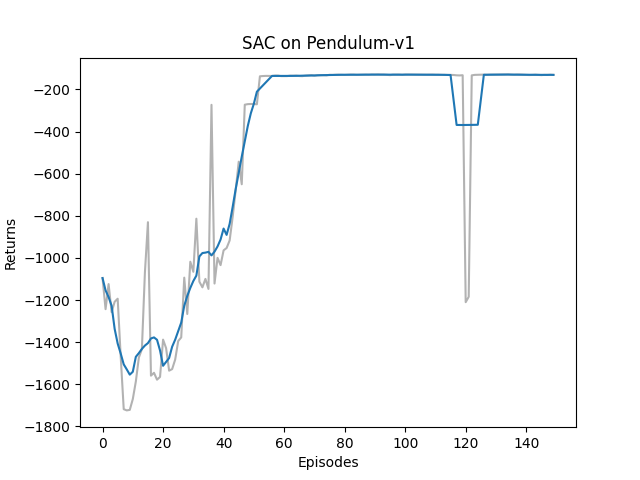
Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC)
Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC) 文章目录 Hands on RL 之 Off-policy Maximum Entropy Actor-Critic (SAC)1. 理论基础1.1 Maximum Entropy Reinforcement Learning, MERL1.2 Soft Policy Evaluation and Soft Policy Improvement in SAC1.3 Tw…...

JavaScript中的this指向,call、apply、bind的简单实现
JavaScript中的this this是JavaScript中一个特殊关键字,用于指代当前执行上下文中的对象。它的难以理解之处就是值不是固定的,是再函数被调用时根据调用场景动态确定的,主要根据函数的调用方式来决定this指向的对象。this 的值在函数被调用时…...
Linux学习之基本指令一
在学习Linux下的基本指令之前首先大家要知道Linux下一切皆目录,我们的操作基本上也都是对目录的操作,这里我们可以联想我们是如何在windows上是如何操作的,只是形式上不同,类比学习更容易理解。 目录 01.ls指令 02. pwd命令 0…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...

【CH32V307实战】4P OLED屏I2C驱动移植与快速显示指南
1. CH32V307与4P OLED屏的硬件连接指南 第一次拿到CH32V307开发板和4P OLED屏时,最让我头疼的就是接线问题。这种4线制OLED(通常标注为4P或4PIN)相比传统的7线制简化了不少,但引脚定义各家厂商可能略有差异。经过多次实测…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...

SVG与CSS变量驱动的自动化品牌视觉生成技术实践
1. 项目概述:一分钟品牌塑造的实践宝库在品牌营销和创意设计领域,一个常见的痛点是如何快速、高效地生成高质量的视觉品牌资产。无论是初创公司需要一个临时的Logo,还是内容创作者想为新的系列视频设计一个统一的片头,传统的品牌设…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...

AI项目脚手架:标准化与自动化提升工程效率
1. 项目概述:一个为AI项目量身定制的“脚手架”如果你和我一样,在AI领域摸爬滚打多年,从早期的机器学习模型到现在的深度学习、大语言模型应用,肯定经历过无数次从零开始搭建项目的“阵痛”。每次新建一个项目,都要重复…...

大语言模型与多模态生成融合:架构、工具与实践指南
1. 项目概述:当大语言模型遇见多模态生成最近两年,AI领域最激动人心的进展,莫过于大语言模型(LLMs)和多模态生成模型的“双向奔赴”。前者以ChatGPT、GPT-4为代表,展现了惊人的语言理解、推理和生成能力&am…...

ViewTurbo:基于响应式依赖追踪的前端渲染优化方案
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 ViewTurbo。这名字听起来就带点“涡轮增压”的劲儿,事实上,它也确实是一个旨在为视图渲染“加速”的工具。简单来说,ViewTurbo 的核心目标,是解决在复杂前端…...