Flink之Task解析
Flink之Task解析
对Flink的Task进行解析前,我们首先要清楚几个角色TaskManager、Slot、Task、Subtask、TaskChain分别是什么
| 角色 | 注释 |
|---|---|
| TaskManager | 在Flink中TaskManager就是一个管理task的进程,每个节点只有一个TaskManager |
| Slot | Slot就是TaskManager中的槽位,一个TaskManager中可以存在多个槽位,取决于服务器资源和用户配置,可以在槽位中运行Task实例 |
| Task | 其实Task在Flink中就是一个类,其中可以包含一个或多个算子,这个取决于算子链的构成 |
| SubTask | SubTask就是Task类的并行实例可以是一个或多个,也就是说当代码执行的那一刻开始,就根据用户所设置或者默认的并行度创建出多个SubTask |
| TaskChain | TaskChain就是算子链,何为算子链?就是在一个Task实例中出现的串行算子,算子间必须是OneToOne模式且并行度相同. |
上面对几个角色进行了一个简单的阐述,后面会结合图解和伪代码进行讲解,这里我们以计算中比较经典wordcount为例子,伪代码如下所示:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 设置并行度3env.setParallelism(3)// 读取数据文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 转大写DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 转成tuple2格式,计数1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
上面的代码中我们使用了两次map,一次keyBy,一次sum算子,我们下面就结合这几个算子进行讲解,讲解之前有两个条件需要先记住:
- 同一个Task并行实例不能放在同一个TaskSlot上运行,一个TaskSlot上可以运行多个不同的Task并行实例
- 同一个共享组的算子允许共享槽位,不同共享组的算子决不允许共享槽位
上面这两句话一定要记牢,以便于后面的理解.
算子链划分及Task槽位分配
算子链划分
可以根据上面的代码理解下图:
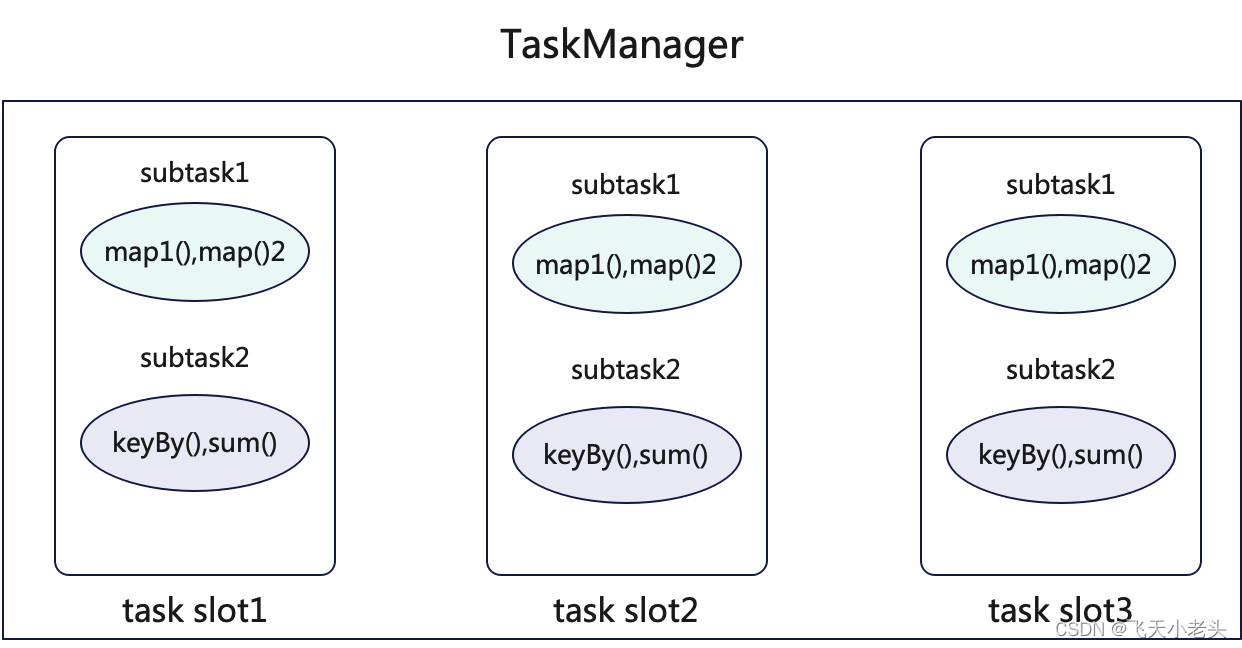
上图中我们可以看到两个map组成一个task chain,keyBy和sum组成一个task chain,这里说一下原因,首先就是两个map的并行度是一致的,而且是OneToOne模式,所以可以将两个map绑定成一个算子链,并将其放入到一个SubTask中,而到了keyBy这里为什么不能再放入到一个task chain中,这里我们可以思考一下,keyBy时会发生什么?以spark的角度来说会发生shuffle对吧,这就导致了不能满足OneToOne的模式,简单来说我们也可以想清楚,如果keyBy和map组成一个task chain那么还怎么做wordcount?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bckucHbv-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task2.png)]](https://img-blog.csdnimg.cn/589a720a88b84aebabb5ef71b1da22af.png)
通过上图应该很容易理解了.
Task槽位分配
上面讲了关于task chain怎么划分的,为什么这样划分,这里讲一下为什么同一个Task的并行实例(SubTask)不能在同一个task slot中.其实这个也很容易就想清楚,如果同一Task的多个SubTask都出现在一个task slot中那么还有什么意义呢?当这些SubTask出现在一个task slot中时就会发生串行计算,那并行的意义也就没有了.
同时这种机制也保证了任务的容错性,也就是说对于同一个Task一旦某一个task slot出现异常的情况,其他的task slot中的SubTask还能正常运行,如果将这些SubTask放到一个task slot中,当这个task slot出现异常情况时,就会影响整个任务的执行.
总结来说,这种设计保证了Flink任务的隔离性、容错性、资源利用性.这里用图解的方式便于大家记忆,如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rlgqeo6A-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task3.png)]](https://img-blog.csdnimg.cn/c0e80184d18b44cebf8faaaa72c59ca8.png)
槽位共享及算子链断/连
槽位共享
前面讲过同一个Task的多个SubTask不能出现在一个task slot中,但是不同Task的SubTask是可以共享同一个task slot的,但是在Flink中有一个机制,就是用户(开发人员)可以自定义不同的算子间是否可以共享同一个task slot,如上面的例子中两个map的并行度一致并且符合OneToOne的模式,在正常情况下必然会会分到一个task chain中,但是Flink给用户提供了的slot group的概念,也就是说用户可以将这两个map分配到不同的slot group中,这种情况下两个map就不会划分到一个task chain中,试想一下当两个map都不允许共享同一个task slot时,怎么可能划分到同一个task chain中呢?
伪代码如下:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 设置并行度3env.setParallelism(1)// 读取数据文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 转大写DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 通过slotSharingGroup()将upperCaseSource作为一个分组"g1"SingleOutputStreamOperator<String> slotGroup1 = upperCaseSource.slotSharingGroup("g1");// 转成tuple2格式,计数1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 通过slotSharingGroup()将mapStream作为一个分组"g3"SingleOutputStreamOperator<Tuple2<String, Integer>> slotGroup2 = mapStream.slotSharingGroup("g2");// 按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
上面的代码中我们将upperCaseSource和mapStream分成了两个task slot,这样两个map就不可以共享相同的task slot,同时代码中将并行度改为了1,这样便于图解,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-saLgMu0Q-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task4.png)]](https://img-blog.csdnimg.cn/c791831068674b58b13c2987e671c6a3.png)
如果说集群中总task slot只有3个,并且在代码中两个map设置了不同的task slot且两个map的并行度都为3时会怎么样?很简单,提交任务时就会报错,因为提交任务所需要的资源已经超出了集群的资源.
这里说一下对于对task slot进行分组处理的实际用处,就以代码中两个map为例子,在实际的业务中如果两个map处理的数据量都极大,如果将两个map的计算都放到一个节点的一个task slot时会发生什么?数据的积压、任务异常失败等等都有可能发生,但是有slotSharingGroup我们就可以保证同一个task slot不会承载过大的计算任务,也就达到了资源合理分配的目的.
算子链断/连
前面讲了关于将两个map进行slotSharingGroup后会将两个map划分到不同的task chain,如果有这样一个情况两个map满足OneToOne的模式且并行度相同时,我们不使用slotSharingGroup能否将两个map划分成不同的task chain?答案是当然可以的,Flink为我们提供了对应的API,伪代码如下:
public class FLinkWordCount {public static void main(String[] args) throws Exception {// 创建流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\// 设置并行度3env.setParallelism(3)// 读取数据文件DataStreamSource<String> streamSource = env.readTextFile("xxx");// 转大写DataStreamSource<String> upperCaseSource = streamSource.map(word -> word.toUpperCase())// 转成tuple2格式,计数1SingleOutputStreamOperator<Tuple2<String, Integer>> mapStream = upperCaseSource.map(word -> Tuple2.of(word, 1));// 将mapStream划分到一个新的task chain中SingleOutputStreamOperator<Tuple2<String, Integer>> newTaskChainMapStream = mapStream.startNewChain();// 按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyed = mapStream.keyBy(tup -> tup.f0);// 求和keyed.sum("f1")env.execute();}
}
在上面代码中我们调用了startNewChain()后就可以将mapStream划分到一个新的task chain中,这样的情况下,两个map既属于不同的task chain又可以共享同一个task slot,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jOIlz8uH-1692099761760)(/Users/jinlong/data/Typora_WorkSpase/FlinkTask/task5.png)]](https://img-blog.csdnimg.cn/2314559b6cad40358b5606dec3b91305.png)
以上就是对于Task的讲解,如有错误欢迎指出,如有问题共同探讨.
相关文章:
Flink之Task解析
Flink之Task解析 对Flink的Task进行解析前,我们首先要清楚几个角色TaskManager、Slot、Task、Subtask、TaskChain分别是什么 角色注释TaskManager在Flink中TaskManager就是一个管理task的进程,每个节点只有一个TaskManagerSlotSlot就是TaskManager中的槽位,一个TaskManager中可…...
计算机竞赛 python 爬虫与协同过滤的新闻推荐系统
1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 python 爬虫与协同过滤的新闻推荐系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖&…...

如何使用Kali Linux进行密码破解?
今天我们探讨Kali Linux的应用,重点是如何使用它来进行密码破解。密码破解是渗透测试中常见的任务,Kali Linux为我们提供了强大的工具来帮助完成这项任务。 1. 密码破解简介 密码破解是一种渗透测试活动,旨在通过不同的方法和工具来破解密码…...
【Freertos基础教程】任务管理之基本使用
文章目录 前言一、freertos任务管理是什么?二、任务管理涉及到的一些概念1.任务状态2.优先级3.栈(Stack)4.事件驱动5.协助式调度(Co-operative Scheduling) 二、任务的基本操作1.创建任务什么是任务 2.创建任务3.任务的删除4.任务的调度3.简单示例 总结 前言 本fre…...

VMware安装BC-linux-eluer 21.10,配置网络
参考配置:https://hiworld.blog.csdn.net/article/details/121608950 /etc/sysconfig/network-scripts/ifcfg-ens33 配置内容如下: TYPEEthernet PROXY_METHODnone BROWSER_ONLYno BOOTPROTOstatic DEFROUTEyes IPV4_FAILURE_FATALno IPV6INITyes IPV6_…...
2023最新Windows编译ffmpeg详细教程,附msys2详细安装配置教程
安装MSYS2 msys2是一款跨平台编译套件,它模拟linux编译环境,支持整合mingw32和mingw64,能很方便的在windows上对一些开源的linux工程进行编译运行。 类似的跨平台编译套件有:msys,cygwin,mingw 优势&…...

【SpringBoot】87、SpringBoot中集成Redisson实现Redis分布式锁
1、Redisson 介绍 Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。Redisson 在基于 NIO 的 Netty 框架上,充分的利用了 Redis 键值数据库提供的一系列优势,在 Java 实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的…...

宝藏级画图工具-drawio
今天推荐一款非常好用的免费开源画图工具drawio. Drawio即可以下载安装到本地,也可以在线编辑,在线编辑网址为 https://app.diagrams.net/。 本地版下载地址为https://github.com/jgraph/drawio-desktop/releases 1、支持各类图形 Drawio可以非常便捷…...

36_windows环境debug Nginx 源码-使用 VSCode 和WSL
文章目录 配置 WSL编译 NginxVSCode 安装插件launch.json配置 WSL sudo apt-get -y install gcc cmake sudo apt-get -y install pcre sudo apt-get -y install libpcre3 libpcre3-dev sudo apt-get...

海康威视iVMS综合安防系统任意文件上传(0Day)
漏洞描述 攻击者通过请求/svm/api/external/report接口任意上传文件,导致获取服务器webshell权限,同时可远程进行恶意代码执行。 免责声明 技术文章仅供参考,任何个人和组织使用网络应当遵守宪法法律,遵守公共秩序,尊重社会公德,不得利用网络从事危害国家安全、荣誉和…...

SOME/IP通信对数据包的大小有要求
SOME/IP通信对数据包的大小有要求,因为SOME/IP是基于UDP协议的,而UDP协议有一个最大传输单元(MTU)的限制,即每个数据包的大小不能超过MTU的值。 不同的网络环境下,MTU的值可能不同,一般在1500字节到9000字节之间。 如果SOME/IP数据包的大小超过了MTU的值,那么就需要进…...
苹果电脑会自动清理垃圾吗 苹果电脑系统垃圾怎么清除
苹果电脑是很多人喜欢使用的一种电脑,它有着优美的外观,流畅的操作系统,丰富的应用程序和高效的性能。但是,随着时间的推移,苹果电脑也会产生一些不必要的文件和数据,这些文件和数据就是我们常说的垃圾。那…...
资源初始化之获取IPV4套接字地址信息(2))
【0216】stats collector(统计信息收集器)资源初始化之获取IPV4套接字地址信息(2)
相关阅读: 【0215】stats collector(统计信息收集器)工作原理之资源初始化(1) 1. 如何获取ipv4套接字地址信息 在【0215】stats collector(统计信息收集器)工作原理之资源初始化(1)一文的2.1.3节中讲解了stats collector进程会创建UDP,与其他进程进行通信,从而实现…...
)
uni-app 面容、指纹识别插件(uni-face-login)
面容、指纹识别插件(uni-face-login) 介绍 人脸指纹登录授权,可以使用手机自带的人脸、指纹进行生物识别,进而判断是否机主本人,从而进行授权验证,适配安卓、iOS、鸿蒙设备 猛戳这里去插件市场看看 使用 该插件支持鸿蒙、安卓…...
专治疗懒病:GO、KEGG富集分析一体函数
之前我们写过GO、KEGG的富集分析,参见:补充更新:GO、KEGG(批量分组)分析及可视化。演示了差异基因KEGG或者GO的分析流程。其实差异基因的富集分析输入的文件只需要一组基因就可以了。所以我们发挥了专治懒病的优良传统…...
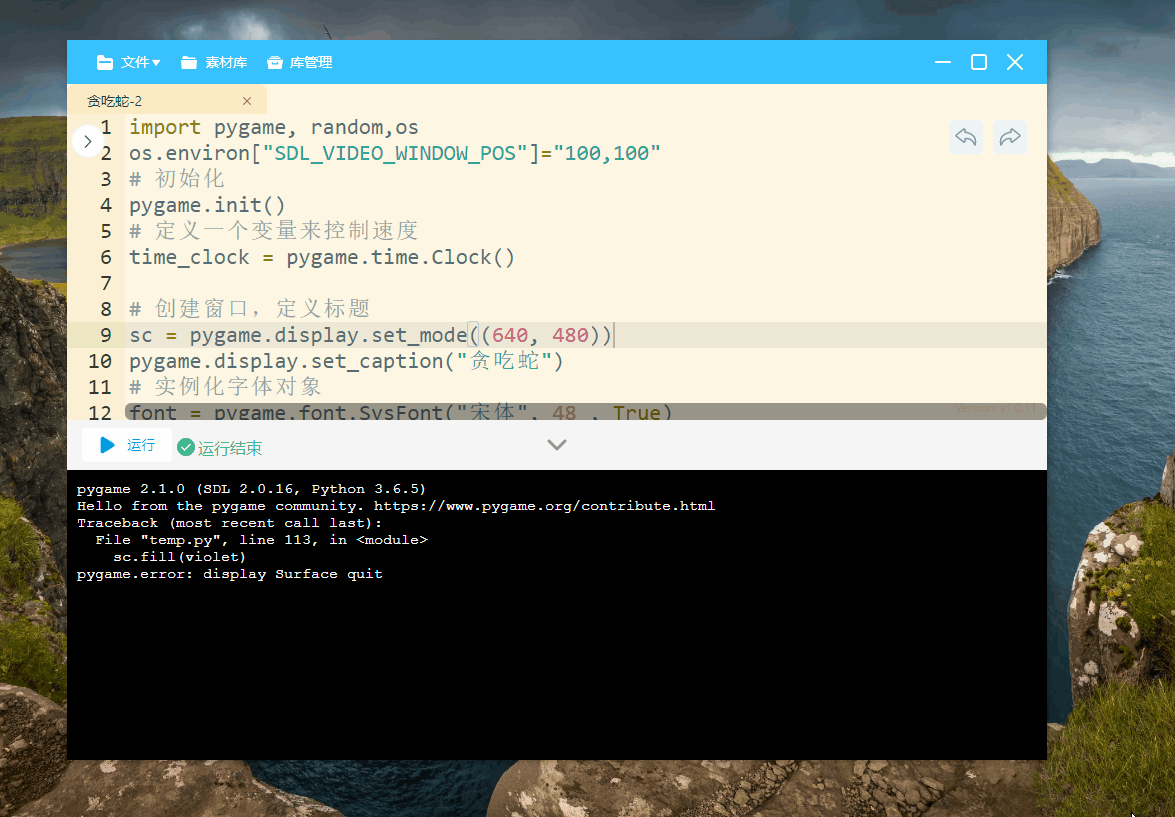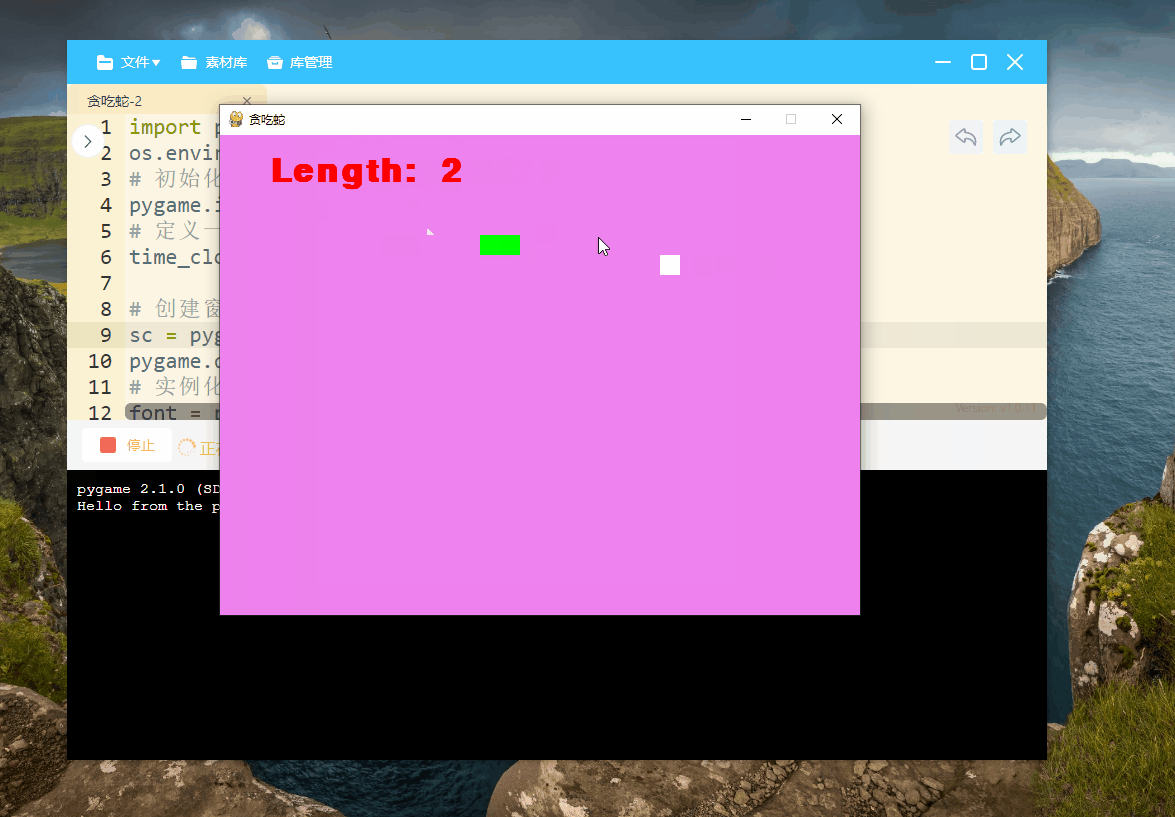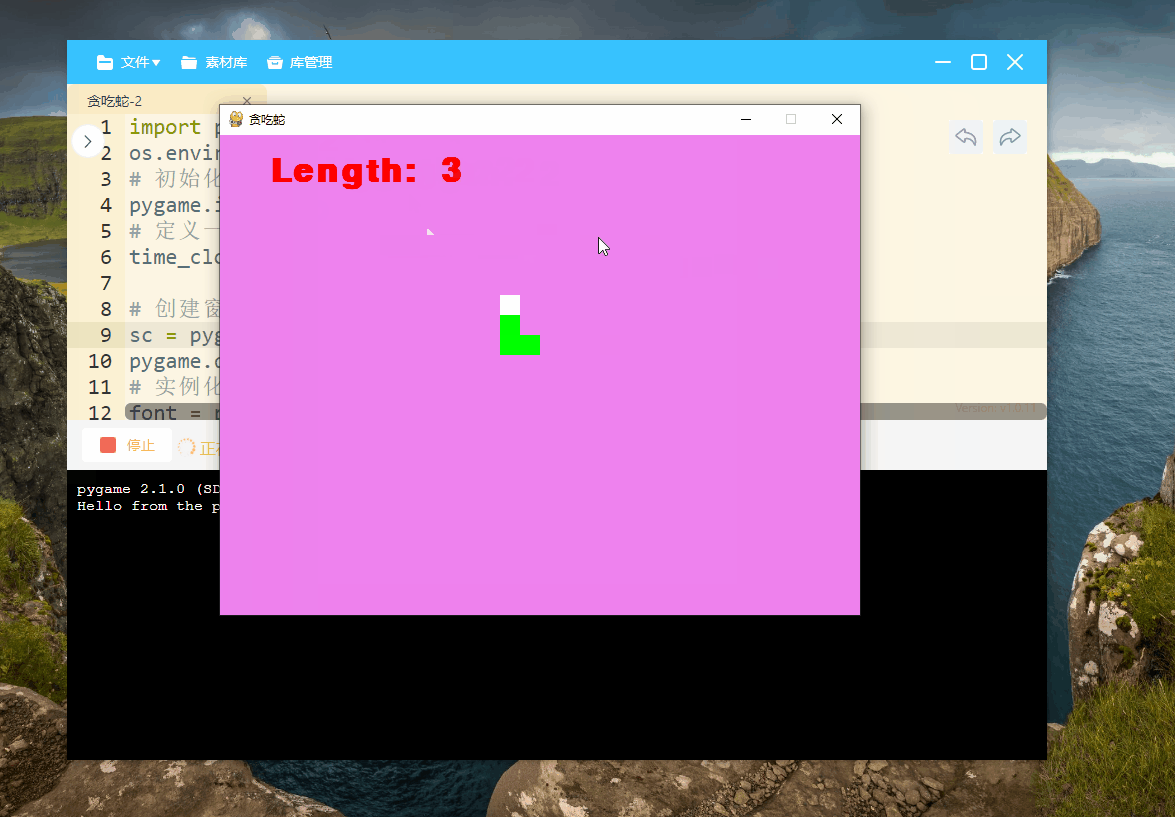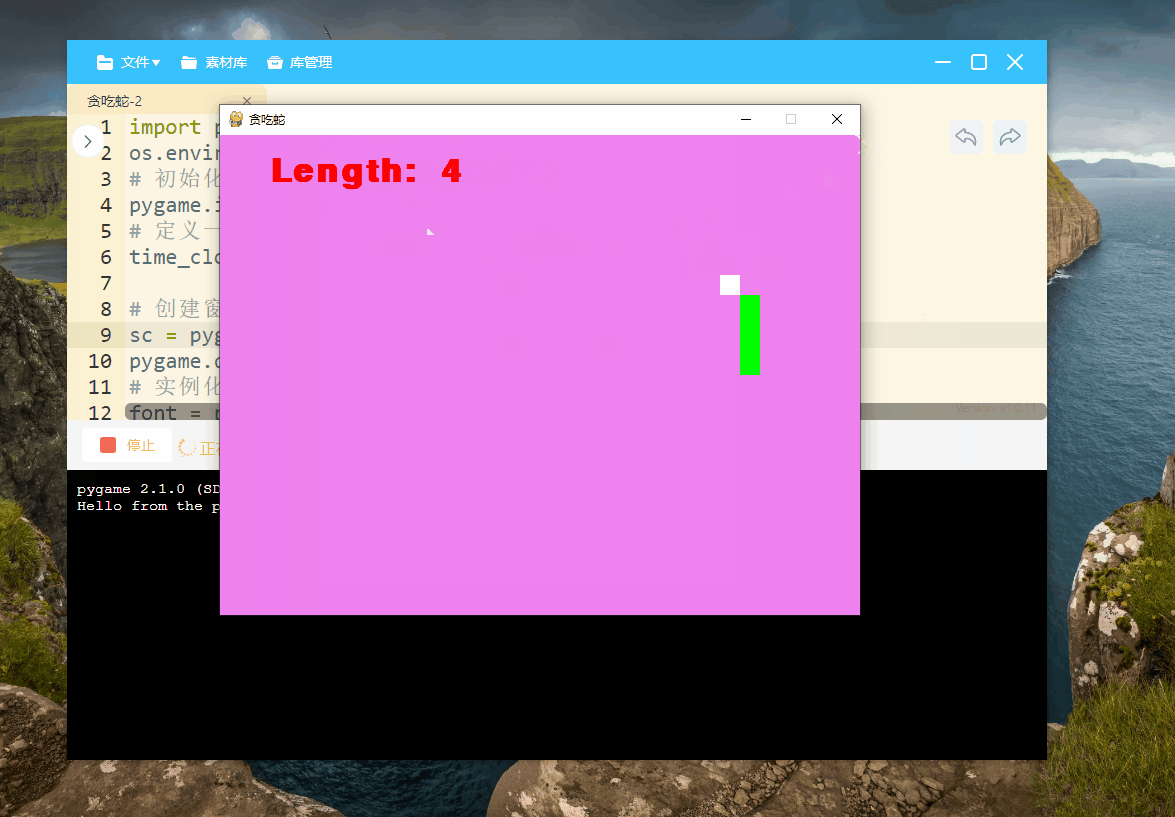
pygame第6课——贪吃蛇小游戏
今天我们开始Pygame的第六课,前几节课的内容在这里【点我】,欢迎大家前去考古: 今天我们一起来学习制作一个小游戏【贪吃蛇】,这是一个非常经典的小游戏,那么我们一起开始吧 1、游戏准备工作 import pygame, random,o…...
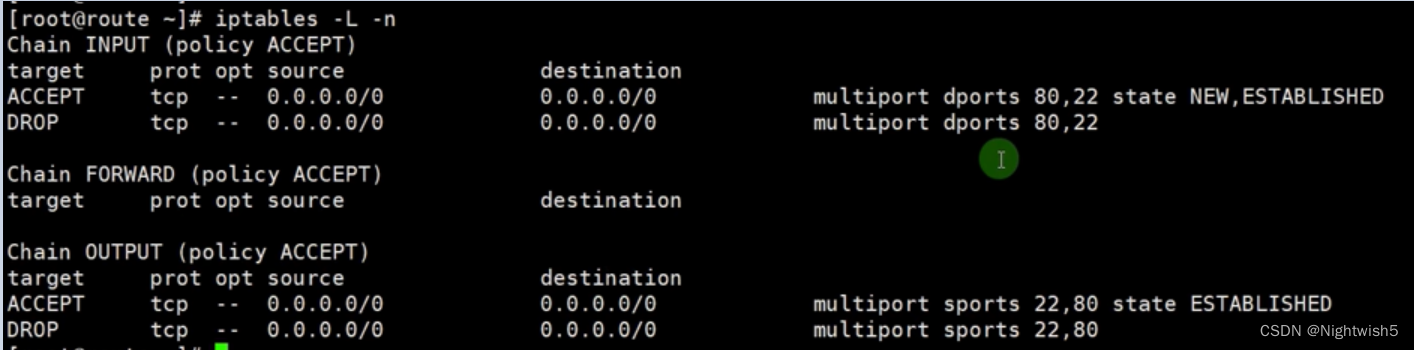
iptables之iptables表、链、规则 、匹配模式、扩展模块、连接追踪模块(一)
一、iptables的链 1.请求到达本机: PREROUTING --> INPUT --> Local Process (本机) 2.请求经过本机: PREROUTING --> FORWARD --> POSTROUTING 3.请求从本机发出:local Process(本机…...

Mac 卸载appium
安装了最新版的appium 2.0.1,使用中各种问题,卡顿....,最终决定回退的。记录下卸载的过程 1.打开终端应用程序 2.卸载全局安装的 Appium 运行以下命令以卸载全局安装的 Appium: npm uninstall -g appium 出现报错:Error: EACCES: permiss…...

数据结构----哈夫曼树
这里写目录标题 基本概念引子基本概念各种路径长度各种带权路径长度结点的带权路径长度树的带权路径长度哈夫曼树 哈夫曼树的构造理论基础构造思想总结 哈夫曼树的实现哈夫曼编码前缀编码哈夫曼编码的思想案例代码实现 编码与解码 基本概念 引子 哈夫曼树就是寻找构造最优二叉…...
--使用/教程/实例)
Spring之Aop切面---日志收集(环绕处理、前置处理方式)--使用/教程/实例
Spring之Aop切面---日志收集(环绕处理、前置处理方式)--使用/教程/实例 简介系统登录日志类LoginLogEntity .java 一、环绕处理方式1、自定义注解类LoginLogAop.class2、切面处理类LogoutLogAspect.java 二、前置处理方式:1、自定义注解类Log…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

从分立逻辑到单片机:基于ATmega8的MIDI通道分析仪设计与实现
1. 项目概述:从分立逻辑到单片机的MIDI通道分析仪进化史二十年前,当我在《Elektor》杂志上发表第一版MIDI通道分析仪时,整个数字音乐世界还处于一个相当“硬核”的阶段。那个版本的设计,用今天的话来说,简直就是一场“…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个 API 源,使用 Taotoken 聚合服务在运维复杂度上的降低 在构建依赖多个大语言模型的应用时,…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...