MySQL数据库调优————ORDER BY语句
ORDER BY调优的核心原理,原则是利用索引的有序性跳过排序环节
关于ORDER BY语句的一些尝试
我们使用employees表进行尝试,索引情况如下
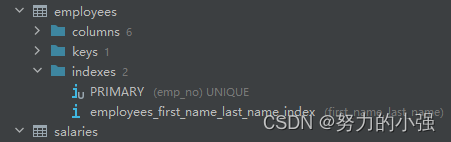
在执行计划的结果中,Extra里如果存在,Using filesort则表示,排序没有使用到索引。
explain
select *
from employees
order by first_name,last_name;
结果

并没有用到索引,发生了全表扫描
explain
select *
from employees
order by first_name,last_name
limit 10;
结果

这次的查询就用到了索引。为什么一次是ALL,一次是index呢?
因为第一次相当于对整张表进行排序的,排序是基于成本计算的,在优化器发现全表扫描开销更低时,会直接使用全表扫描。而第二次是仅仅对前10条数据进行排序,扫描索引的成本要小于扫面全表,所以用到了索引。
----------------------------------------------------------------------------------------------------------------->
explain
select *
from employees
where first_name = 'Bader'
order by last_name;
结果

这句SQL是用到了索引排序的,当执行查询时,查找出来的数据为[‘Bader’,last_name[i],emp_no],因为索引是有序的,'Bader’是确定的,那么数据已经按照last_name排好序了,就跳过了排序的环节。
----------------------------------------------------------------------------------------------------------------->
explain
select *
from employees
where first_name < 'Bader'
order by first_name;
结果

根据执行结果是使用了索引的,因为在执行查询语句时,查找出来的数据为[first_name,last_name,emp_no],这一部分数据已经是按照first_name排好序的,所以不需要再次进行排序了。
----------------------------------------------------------------------------------------------------------------->
explain
select *
from employees
where first_name = 'Bader'and last_name > 'Peng'
order by last_name;
结果

跟上面的同理,因为在执行查询语句时,查找出来的数据为[Bader,last_name[i],emp_no],这一部分数据已经是按照last_name排好序的,所以不需要再次进行排序了。
----------------------------------------------------------------------------------------------------------------->
explain
select *
from employees
order by first_name,emp_no limit 10;
结果

根据执行结果 ,该语句没有用到索引,因为两个排序字段存在于不同的两个索引中,会先按first_name进行排序,再将相同first_name的数据按照emp_no进行排序。
----------------------------------------------------------------------------------------------------------------->
explain
select *
from employees
order by first_name desc ,last_name asc limit 10;
结果

因为索引中的两个字段,在进行排序中的升降序不一致,所以无法使用索引。
----------------------------------------------------------------------------------------------------------------->
explain
select *
from employees
where first_name < 'Bader'
order by last_name limit 10;
结果

根据结果得知,在进行查询时使用了索引,但在排序时使用的是Using filesort。说明排序时没有用到索引。组合索引中part1范围查询,使用part2进行排序是无法使用索引排序的。
排序模式
Using filesort排序原理,目前MySQL使用了三种排序模式
模式一:rowid排序(常规排序)
排序过程
- 从表中获取满足where条件的数据。
- 对于每条记录,将记录的主键及排序字段(id,order_column)取出放入sort buffer(由sort_buffer_size控制大小)。
- 如果sort buffer能存放所有满足条件的(id,order_column),则进行排序;否则,当sort buffer存满后,会将sort buffer中的数据排序并存放到临时文件中。
- 在没有产生临时文件时,在内存中使用快速排序算法
- 如果产生了临时文件,则需要利用归并排序算法,从而保证记录有序
- 扫描排序好的(id,order_column)数据,并利用id去取select需要返回的其他字段。
- 返回结果集。
排序特点
- 看sort buffer是否能存放查询出来的所有的结果集,如果不满足,就会差生临时文件
- 一次排序需要两次IO
- 第一次,把查询出来的(id,order_column)结果集放入sort buffer中;第二次,通过id去获取需要返回的其他字段。由于返回结果是按照order_column进行排序的,所以主键id是乱序的,会存在随机IO的问题。之前文中提到,在用主键id取值前,会按照主键id进行排序,并放入一个缓存中,该缓存大小是由read_rnd_buffer_size控制,接着再去取记录,从而把随机IO转换成顺序IO。
模式二:全字段排序(优化排序)
排序过程
跟第一种模式相比,有几点不同
- 直接取出表中需要的所有字段,放到sort buffer种
- 由于sort buffer已经包含了查询需要的所有的字段,因此sort buffer种排序完成后直接返回结果集
全字段排序 vs rowid排序
- 优点:性能的提升,无需两次IO,因为全字段排序已经将需要的所有字段存储到了sort buffer种,无需再次用主键id去表中获取
- 缺点:由于全字段排序会将需要的所有的字段放入sort buffer中,所以占用空间比较大,如果sort buffer不够大,那么很容易产生临时文件
排序算法的选择
- max_length_for_sort_data:当OEDER BY中出现的字段的总长度小于该值,使用全字段排序,反之则使用rowid排序。
模式三:打包字段排序
- MySQL5.7引入
- 与模式二工作原理一致,不同点在于会将字段紧密的排列在一起,而不是固定长度的空间。
- 例如:一个字段定义为VARCHAR(32),值为’yes’;在不打包的情况下占用32字节,打包的情况下2+3字节。
参数汇总
| 变量 | 作用 |
|---|---|
| sort_buffer_size | 指定sort buffer的大小 |
| max_length_for_fort_data | 当ORDER BY中出现字段的总长度小于该值时使用全字段排序,反之使用rowid排序 |
| read_rnd_buffer_size | 按照主键排序后存放的缓存区大小 |
使用optimizer_trace分析排序过程
explain展示的排序方式很有限,仅仅是Using filesort,如果我们想了解更多的细节就需要使用optimizer_trace进行分析了。
以下面语句为例:
select *
from employees
where first_name < 'Bader'
order by last_name;
执行
SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=on;
SET optimizer_trace_offset=-30,optimizer_trace_limit=30;
开启OPTIMIZER_TRACE,执行示例SQL语句,再次执行
select * from information_schema.OPTIMIZER_TRACE where QUERY like '%Bader%';
获取分析结果,将trace字段的内容复制出来进行分析;
我们主要关注的是filesort_summary,
“filesort_summary”: {
“memory_available”: 262144,
“key_size”: 265,
“row_size”: 399,
“max_rows_per_buffer”: 502,
“num_rows_estimate”: 927744,
“num_rows_found”: 22287,
“num_initial_chunks_spilled_to_disk”: 0,
“peak_memory_used”: 204314,
“sort_algorithm”: “std::sort”,
“unpacked_addon_fields”: “using_priority_queue”,
“sort_mode”: “<varlen_sort_key, additional_fields>”
}
其相关字段解读如下:
- memory_available:可用内存,其实就是fort_buffer_size设置的值
- num_rows_found:有多少条数据参与排序,越小越好
- num_initial_chunks_spilled_to_disk:产生了几个临时文件,0表示完全基于内存排序
- sort_mode
- <varlen_sort_key,rowid>:使用了rowid排序模式
- <varlen_sort_key, additional_fields>:使用了全字段排序模式
- <varlen_sort_key, packed_additional_fields>:使用了打包字段排序模式
如何调优ORDER BY
- 利用索引,防止filesort发生
- 如果发生了filesort,且无法避免,就要对filesort进行优化
如何调优filesort
- 调大sort_buffer_size,减少/避免临时文件的产生,从而进行的归并操作
- 当optimizer_trace的结果中 num_initial_chunks_spilled_to_disk的值较大时,需要调整
- show status like ‘%sort_merge_passes%’;查看发生归并操作的次数
- 调大read_rnd_buffer_size,让一次顺序IO返回更多的结果
- 设置合理的max_length_for_sort_data的值
相关文章:
MySQL数据库调优————ORDER BY语句
ORDER BY调优的核心原理,原则是利用索引的有序性跳过排序环节 关于ORDER BY语句的一些尝试 我们使用employees表进行尝试,索引情况如下 在执行计划的结果中,Extra里如果存在,Using filesort则表示,排序没有使用到索…...

Linux命令之grep
Linux grep是一个非常强大的文本搜索工具。按照给定的正则表达式对目标文本进行匹配检查,打印匹配到的行。grep命令可以跟其他命令一起使用,对其他命令的输出进行匹配。 grep语法如下: grep [options] [pattern] content 文本检索 grep可以对…...

一起学 pixijs(4):如何绘制文字md
大家好,我是前端西瓜哥,今天我们来学 pixijs 如何绘制文字。pixijs 版本为 7.1.2。 使用原生的 WebGL 来绘制文字是非常繁琐的,pixijs 对此进行了高层级的封装,提供了 Text 类和 BitMapText 类来绘制文字。 Text 最基本的写法&…...
mac m1设备上安装Qt并使用qt编程遇到的问题以及解决方式
# 简介: 首先在M1平台上的程序可以看到有两种架构,分别是intel的(x86-64)和苹果的m1(arm64架构),根据苹果的介绍,当在m1上面运行intel程序的时候使用的是转译的方式运行的ÿ…...

tensorflow 学习笔记(二):神经网络的优化过程
前言: 学习跟随 如何原谅奋力过但无声的 tensorflow 笔记笔记。 本章主要讲解神经网络的优化过程:神经网络的优化方法,掌握学习率、激活函数、损失函数和正则化的使用,用 Python 语言写出 SGD、Momentum、Adagrad、RMSProp、Ada…...
【Java】《Java8 实战》 CompletableFuture 学习
文章目录前言1. 并发(Concurrent) 和 并行(Parallel)1.1 并发的来源1.2 并发技术解决了什么问题2. 并行的来源2.1 并行解决了什么问题3. CompletableFuture 简介4. CompletableFuture 简单应用5. CompletableFuture 工厂方法的应用6. CompletableFuture join() 方法7. 使用 Par…...
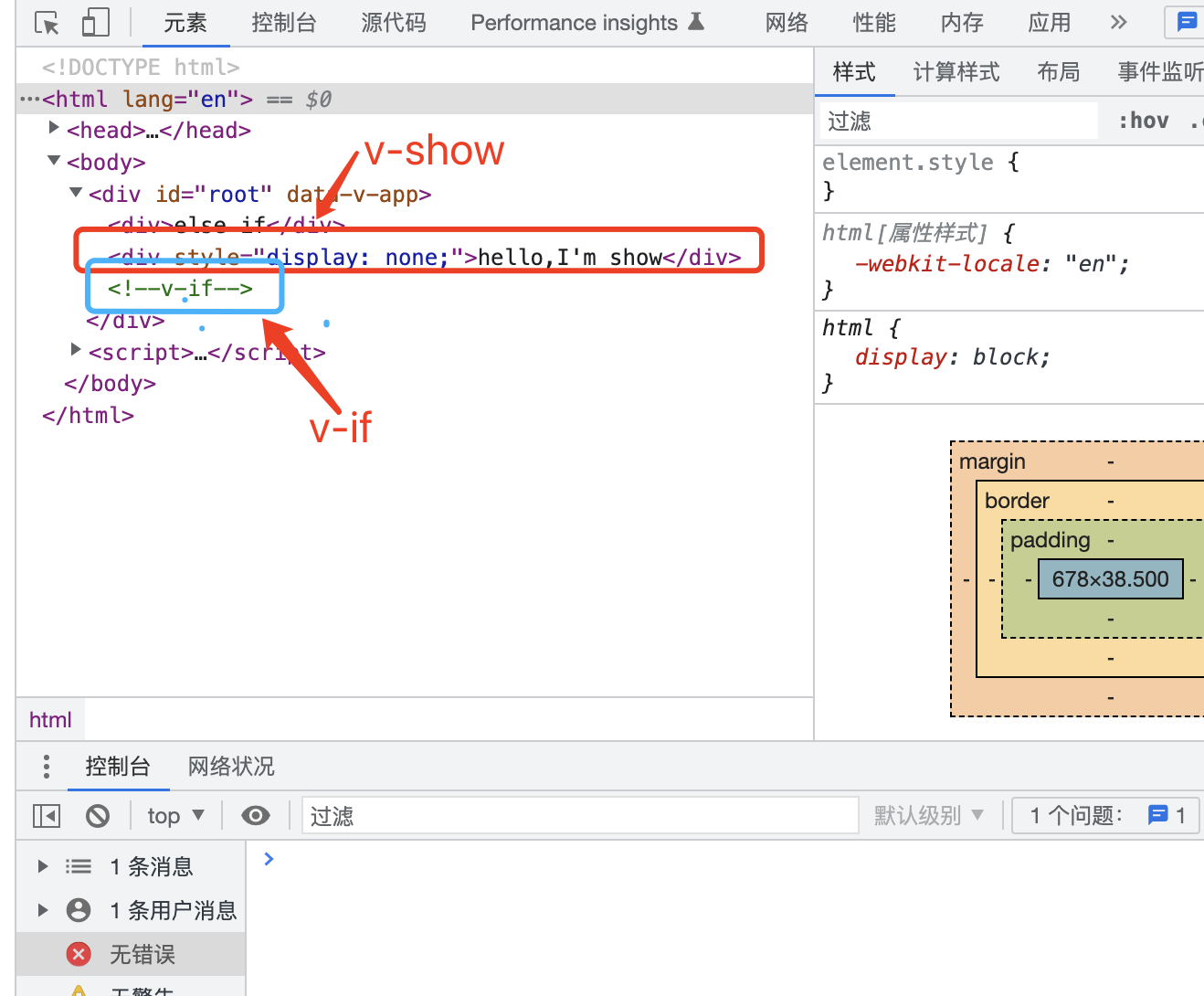
Vue3之条件渲染
1.何为条件渲染 条件渲染就是在指定的条件下,渲染出指定的UI。比如当我们显示主页的时候,应该隐藏掉登录等一系列不相干的UI元素。即UI元素只在特定条件下进行显示。而在VUE3中,这种UI元素的显示和隐藏可以通过两个关键字,v-if 和…...
将Nginx 核心知识点扒了个底朝天(四)
为什么 Nginx 不使用多线程? Apache: 创建多个进程或线程,而每个进程或线程都会为其分配 cpu 和内存(线程要比进程小的多,所以 worker 支持比 perfork 高的并发),并发过大会榨干服务器资源。 Nginx: 采用…...

设计模式之工厂模式
文章の目录一、什么是工厂模式二、工厂模式有什么用?三、应用场景四、示例1、用字面量的方式创建对象2、使用工厂模式创建对象参考写在最后一、什么是工厂模式 工厂模式是一种众所周知的设计模式,广泛应用于软件工程领域,用于抽象创建特定对…...

80.链表-由来
链表是怎么发展来的 线性表:是n个具有相同特性的数据元素的有限序列。 链表:具有线性存储结构的线性表。 为什么需要使用链表?(链表是如何被设计出来的) 程序开发最重要的部分是如何在项目程序中找到一种合适的、好…...
元胞自动机
文章目录前言文献阅读摘要主要贡献方法框架实验结论元胞自动机元胞自动机是什么?构成及规则案例及代码实现总结前言 This week,the paper proposes a Multi-directional Temporal Convolutional Artificial Neural Network (MTCAN) model to impute and forecast P…...
设计模式之各种设计模式总结与对比
目录1 目标2 定位3 一句话归纳设计原则4 G0F 23种设计模式简介5 设计模式使用频次总结6 —句话归纳设计模式7 设计模式之间的关联关系和对比1 目标 1、 简要分析GoF 23种设计模式和设计原则,做整体认知。 2、 剖析Spirng的编程思想,启发思维,为之后深入学习Spring…...

JAVA练习55- Fizz Buzz
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、题目-Fizz Buzz 1.题目描述 2.思路与代码 2.1 思路 2.2 代码 总结 前言 提示:这里可以添加本文要记录的大概内容: 2月19日练习…...

LeetCode笔记:Biweekly Contest 98
LeetCode笔记:Biweekly Contest 98 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 比赛链接:https://leetcode.com/contest/biweekly-contest-98 1. 题目一 给出题目一的试题链接如…...

HNUCM-《算法分析与设计》期末考试考前复习题
问题 A: X星人的地盘题目描述一天,X星人和Y星人在一张矩形地图上玩抢地盘的游戏。X星人每抢到一块地,在地图对应的位置标记一个“X”;Y星人每抢到一块地,在地图对应的位置标记一个“Y”;如果某一块地无法确定其归属则标…...

算法导论【分治思想】—大数乘法、矩阵相乘、残缺棋盘
这里写自定义目录标题分治法概述特点大数相乘问题分治算法矩阵相乘分治算法残缺棋盘分治算法分治法概述 在分而治之的方法中,一个问题被划分为较小的问题,然后较小的问题被独立地解决,最后较小问题的解决方案被组合成一个大问题的解决。 通常…...
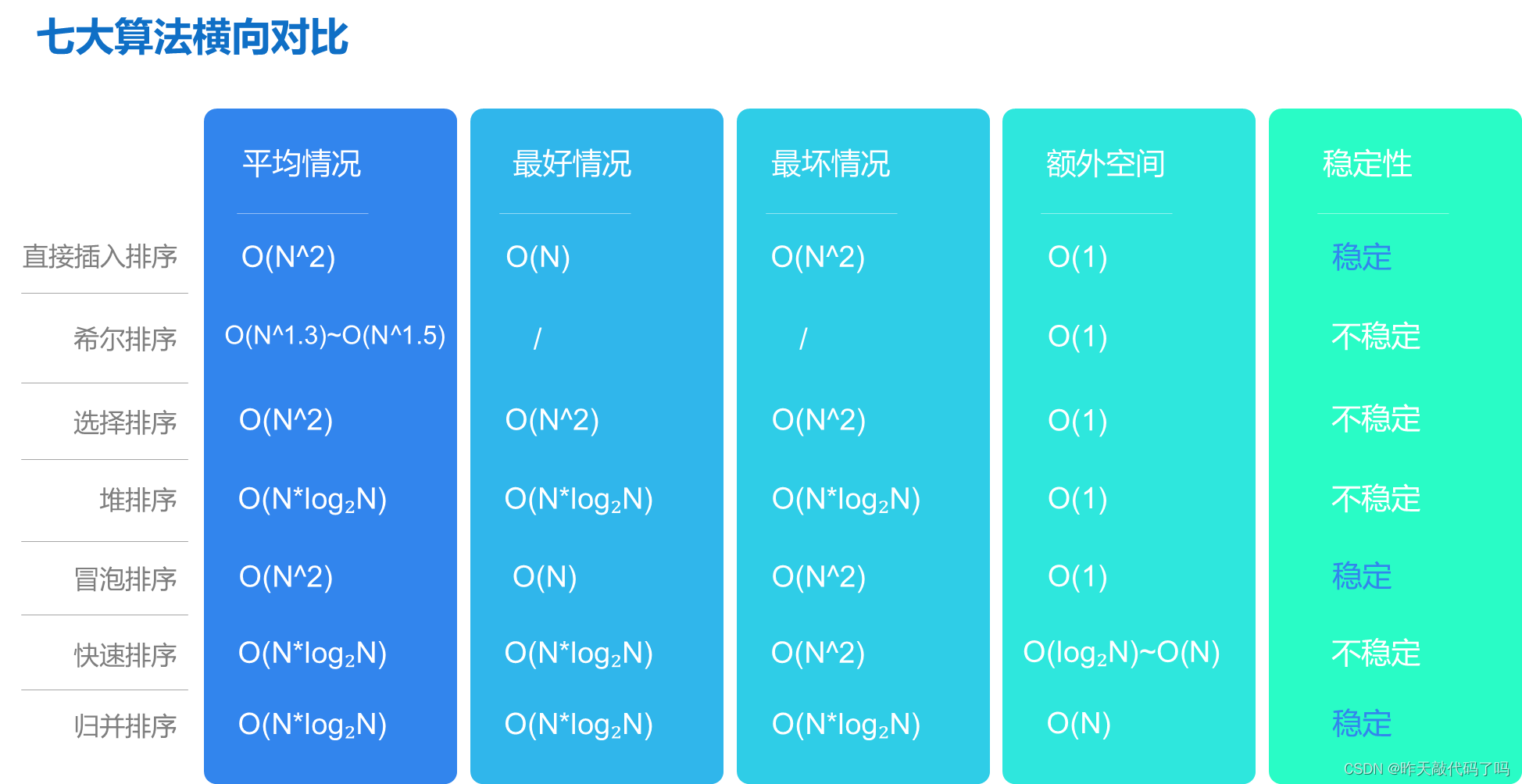
Java【七大排序】算法详细图解,一篇文章吃透
文章目录一、排序相关概念二、七大排序1,直接插入排序2,希尔排序3,选择排序4,堆排序5,冒泡排序5.1冒泡排序的优化6,快速排序6.1 快速排序的优化7,归并排序三、排序算法总体分析对比总结提示&…...

Autosar OS IOC
Inter-OS-Application Communicator 背景和基本原理General purposeIOC functionalityCommunicationNotificationIOC interface背景和基本原理 The IOC implementation shall be part of the Operating System IOC和操作系统紧密相关,是操作系统实现的一部分 The IO…...
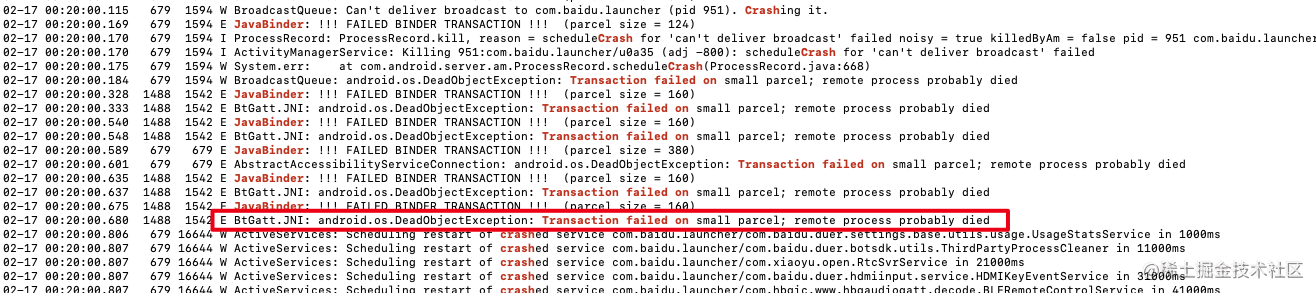
记录一次Binder内存相关的问题导致APP被杀的BUG排查过程
事情的起因的QA压测过程发生进程号变更,怀疑APP被杀掉过,于是开始看日志 APP的压测平台会上报进程号变更时间点,发现是在临晨12:20分,先大概确定在哪个日志文件去找关键信息一开始怀疑是crash,然后就在日志…...
设计模式(十)----结构型模式之适配器模式
1、概述 如果去欧洲国家去旅游的话,他们的插座如下图最左边,是欧洲标准。而我们使用的插头如下图最右边的。因此我们的笔记本电脑,手机在当地不能直接充电。所以就需要一个插座转换器,转换器第1面插入当地的插座,第2面…...

STM32F103C8T6驱动MAX30102:从I2C配置到心率可视化,一个LED灯带你看懂心跳
STM32F103C8T6驱动MAX30102:从I2C配置到心跳可视化实战指南 当LED灯随着你的心跳闪烁时,冰冷的电子元件仿佛被赋予了生命。本文将带你深入探索如何用STM32F103C8T6驱动MAX30102血氧传感器,将生物信号转化为直观的视觉反馈。不同于简单的数据采…...

PCF8591模数转换器实战指南:从I2C通信到多通道数据采集
1. 项目概述:为什么你需要一个PCF8591?在嵌入式开发和电子制作的世界里,我们常常需要处理一个核心矛盾:我们的大脑和代码生活在离散的数字世界(0和1),但我们身处的物理世界却是一个充满连续变化…...

LaTeX-PPT:如何在PowerPoint中3分钟实现专业数学公式排版
LaTeX-PPT:如何在PowerPoint中3分钟实现专业数学公式排版 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint中编辑复杂数学公式而头疼吗?LaTeX-PPT这款开源插件将彻底…...

终极指南:如何让微信网页版恢复正常访问的完整教程
终极指南:如何让微信网页版恢复正常访问的完整教程 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无法登录而烦恼吗&…...

FPGA调试技术:ILA与VIO核心实战指南
1. FPGA调试基础与核心工具解析在FPGA开发流程中,调试环节往往占据整个项目周期的40%以上时间。传统逻辑分析仪存在连接复杂、探头数量有限等问题,而基于JTAG的片上调试技术则提供了更高效的解决方案。Xilinx Vivado设计套件内置的集成逻辑分析仪(ILA)和…...
)
保姆级避坑指南:用GGCNN源码搞定Cornell抓取数据集转换(附.mat/.tiff生成全流程)
保姆级避坑指南:用GGCNN源码搞定Cornell抓取数据集转换全流程 当你第一次尝试复现GGCNN这个经典的机器人抓取项目时,Cornell数据集的预处理往往会成为第一个拦路虎。作为一个曾经在这个环节卡了整整两天的过来人,我深知那些官方文档没写的细节…...

Photoshop AVIF插件:专业图像工作者的下一代格式解决方案
Photoshop AVIF插件:专业图像工作者的下一代格式解决方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 在当今数字图像处理领域,AVIF格…...

AI应用开发利器:Prompster提示词管理库的设计与实践
1. 项目概述:一个为AI应用开发者准备的提示词管理利器如果你正在开发基于大语言模型(LLM)的应用,无论是聊天机器人、内容生成工具,还是复杂的AI工作流,那么你一定对“提示词工程”这个词深有体会。从最初的…...

【2026实测】英文论文怎么降AI率?3大辅助工具与过渡词优化全盘点
看着检测报告上大片刺眼的浅蓝色,真的让人瞬间破防。为了把这串数字降下来,很多人到处找偏方,结果数值没变,文本反而变得奇奇怪怪。其实给英文降ai是有门道的。 我今天不整虚的,直接分享实测过的英文降ai率思路和好用…...

AI安全实战:构建AIGC内容检测与防御系统
1. 项目概述:当AI遇上网络安全最近在GitHub上看到一个挺有意思的项目,叫genaura-guard。光看名字,可能有点摸不着头脑,但如果你对AI生成内容(AIGC)和网络安全这两个领域有所关注,大概就能猜到它…...