[python] 使用Jieba工具中文分词及文本聚类概念
前面讲述了很多关于Python爬取本体Ontology、消息盒InfoBox、虎扑图片等例子,同时讲述了VSM向量空间模型的应用。但是由于InfoBox没有前后文和语义概念,所以效果不是很好,这篇文章主要是爬取百度5A景区摘要信息,再利用Jieba分词工具进行中文分词,最后提出文本聚类算法的一些概念知识。
一. Selenium爬取百度百科摘要
简单给出Selenium爬取百度百科5A级景区的代码:
[python] view plain copy
- # coding=utf-8
- """
- Created on 2015-12-10 @author: Eastmount
- """
- import time
- import re
- import os
- import sys
- import codecs
- import shutil
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- import selenium.webdriver.support.ui as ui
- from selenium.webdriver.common.action_chains import ActionChains
- #Open PhantomJS
- driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
- #driver = webdriver.Firefox()
- wait = ui.WebDriverWait(driver,10)
- #Get the Content of 5A tourist spots
- def getInfobox(entityName, fileName):
- try:
- #create paths and txt files
- print u'文件名称: ', fileName
- info = codecs.open(fileName, 'w', 'utf-8')
- #locate input notice: 1.visit url by unicode 2.write files
- #Error: Message: Element not found in the cache -
- # Perhaps the page has changed since it was looked up
- #解决方法: 使用Selenium和Phantomjs
- print u'实体名称: ', entityName.rstrip('\n')
- driver.get("http://baike.baidu.com/")
- elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
- elem_inp.send_keys(entityName)
- elem_inp.send_keys(Keys.RETURN)
- info.write(entityName.rstrip('\n')+'\r\n') #codecs不支持'\n'换行
- #load content 摘要
- elem_value = driver.find_elements_by_xpath("//div[@class='lemma-summary']/div")
- for value in elem_value:
- print value.text
- info.writelines(value.text + '\r\n')
- #爬取文本信息
- #爬取所有段落<div class='para'>的内容 class='para-title'为标题 [省略]
- time.sleep(2)
- except Exception,e: #'utf8' codec can't decode byte
- print "Error: ",e
- finally:
- print '\n'
- info.close()
- #Main function
- def main():
- #By function get information
- path = "BaiduSpider\\"
- if os.path.isdir(path):
- shutil.rmtree(path, True)
- os.makedirs(path)
- source = open("Tourist_spots_5A_BD.txt", 'r')
- num = 1
- for entityName in source:
- entityName = unicode(entityName, "utf-8")
- if u'故宫' in entityName: #else add a '?'
- entityName = u'北京故宫'
- name = "%04d" % num
- fileName = path + str(name) + ".txt"
- getInfobox(entityName, fileName)
- num = num + 1
- print 'End Read Files!'
- source.close()
- driver.close()
- if __name__ == '__main__':
- main()
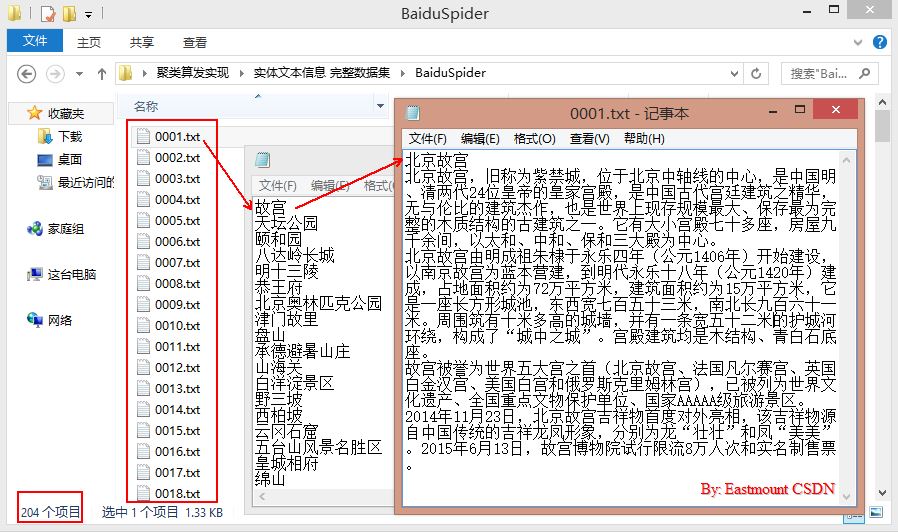
内容如下图所示,共204个国家5A级景点的摘要信息。这里就不再叙述:

二. Jieba中文分词
Python中分分词工具很多,包括盘古分词、Yaha分词、Jieba分词等。
中文分词库:中文分词库 - 开源软件 - OSCHINA - 中文开源技术交流社区
其中它们的基本用法都相差不大,但是Yaha分词不能处理如“黄琉璃瓦顶”或“圜丘坛”等词,所以使用了结巴分词。
1.安装及入门介绍
参考地址:jieba首页、文档和下载 - Python中文分词组件 - OSCHINA - 中文开源技术交流社区
下载地址:jieba · PyPI
Python 2.0我推荐使用"pip install jieba"或"easy_install jieba"全自动安装,再通过import jieba来引用(第一次import时需要构建Trie树,需要等待几秒时间)。
安装时如果出现错误"unknown encoding: cp65001",输入"chcp 936"将编码方式由utf-8变为简体中文gbk。

结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
同时结巴分词支持繁体分词和自定义字典方法。
[python] view plain copy
- #encoding=utf-8
- import jieba
- #全模式
- text = "我来到北京清华大学"
- seg_list = jieba.cut(text, cut_all=True)
- print u"[全模式]: ", "/ ".join(seg_list)
- #精确模式
- seg_list = jieba.cut(text, cut_all=False)
- print u"[精确模式]: ", "/ ".join(seg_list)
- #默认是精确模式
- seg_list = jieba.cut(text)
- print u"[默认模式]: ", "/ ".join(seg_list)
- #新词识别 “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
- seg_list = jieba.cut("他来到了网易杭研大厦")
- print u"[新词识别]: ", "/ ".join(seg_list)
- #搜索引擎模式
- seg_list = jieba.cut_for_search(text)
- print u"[搜索引擎模式]: ", "/ ".join(seg_list)
输出如下图所示:


代码中函数简单介绍如下:
jieba.cut():第一个参数为需要分词的字符串,第二个cut_all控制是否为全模式。
jieba.cut_for_search():仅一个参数,为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
其中待分词的字符串支持gbk\utf-8\unicode格式。返回的结果是一个可迭代的generator,可使用for循环来获取分词后的每个词语,更推荐使用转换为list列表。
2.添加自定义词典
由于"国家5A级景区"存在很多旅游相关的专有名词,举个例子:
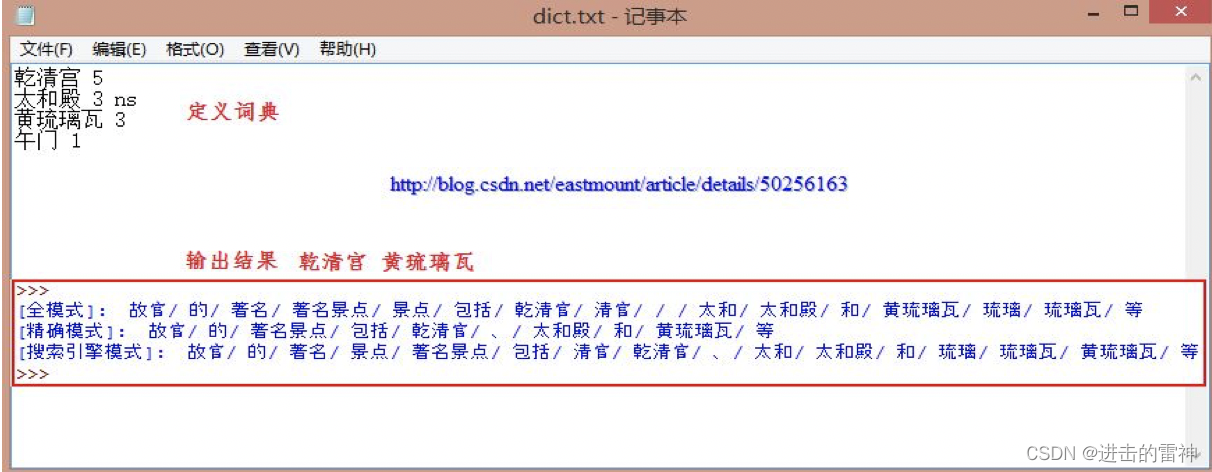
[输入文本] 故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等
[精确模式] 故宫/的/著名景点/包括/乾/清宫/、/太和殿/和/黄/琉璃瓦/等
[全 模 式] 故宫/的/著名/著名景点/景点/包括/乾/清宫/太和/太和殿/和/黄/琉璃/琉璃瓦/等
显然,专有名词"乾清宫"、"太和殿"、"黄琉璃瓦"(假设为一个文物)可能因分词而分开,这也是很多分词工具的又一个缺陷。但是Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
基本用法:jieba.load_userdict(file_name) #file_name为自定义词典的路径
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频,最后为词性(可省略,ns为地点名词),用空格隔开。
强烈推荐一篇词性标注文章,链接如下:
http://www.hankcs.com/nlp/part-of-speech-tagging.html
[python] view plain copy
- #encoding=utf-8
- import jieba
- #导入自定义词典
- jieba.load_userdict("dict.txt")
- #全模式
- text = "故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
- seg_list = jieba.cut(text, cut_all=True)
- print u"[全模式]: ", "/ ".join(seg_list)
- #精确模式
- seg_list = jieba.cut(text, cut_all=False)
- print u"[精确模式]: ", "/ ".join(seg_list)
- #搜索引擎模式
- seg_list = jieba.cut_for_search(text)
- print u"[搜索引擎模式]: ", "/ ".join(seg_list)
输出结果如下所示,其中专有名词连在一起,即"乾清宫"和"黄琉璃瓦"。
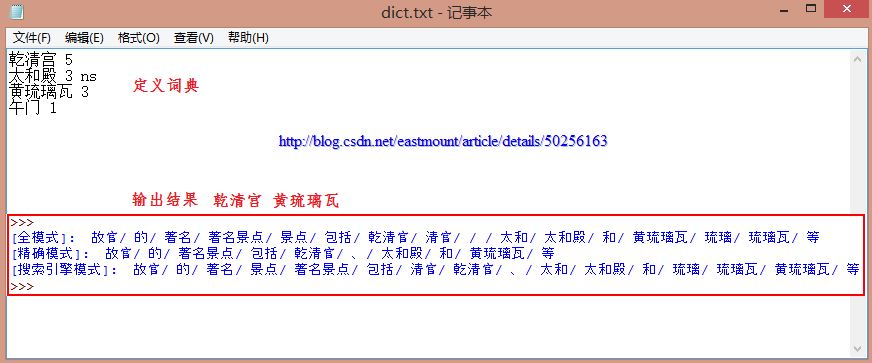
3.关键词提取
在构建VSM向量空间模型过程或者把文本转换成数学形式计算中,你需要运用到关键词提取的技术,这里就再补充该内容,而其他的如词性标注、并行分词、获取词位置和搜索引擎就不再叙述了。
基本方法:jieba.analyse.extract_tags(sentence, topK)
需要先import jieba.analyse,其中sentence为待提取的文本,topK为返回几个TF/IDF权重最大的关键词,默认值为20。
[python] view plain copy
- #encoding=utf-8
- import jieba
- import jieba.analyse
- #导入自定义词典
- jieba.load_userdict("dict.txt")
- #精确模式
- text = "故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门,午门居中向阳。"
- seg_list = jieba.cut(text, cut_all=False)
- print u"分词结果:"
- print "/".join(seg_list)
- #获取关键词
- tags = jieba.analyse.extract_tags(text, topK=3)
- print u"关键词:"
- print " ".join(tags)
输出结果如下,其中"午门"出现3次、"乾清宫"出现2次、"著名景点"出现1次,按照顺序输出提取的关键词。如果topK=5,则输出:"午门 乾清宫 著名景点 太和殿 向阳"。
[python] view plain copy
- >>>
- 分词结果:
- 故宫/的/著名景点/包括/乾清宫/、/太和殿/和/午门/等/。/其中/乾清宫/非常/精美/,/午门/是/紫禁城/的/正门/,/午门/居中/向阳/。
- 关键词:
- 午门 乾清宫 著名景点
- >>>
4.对百度百科获取摘要分词
从BaiduSpider文件中读取0001.txt~0204.txt文件,分别进行分词处理再保存。
[python] view plain copy
- #encoding=utf-8
- import sys
- import re
- import codecs
- import os
- import shutil
- import jieba
- import jieba.analyse
- #导入自定义词典
- jieba.load_userdict("dict_baidu.txt")
- #Read file and cut
- def read_file_cut():
- #create path
- path = "BaiduSpider\\"
- respath = "BaiduSpider_Result\\"
- if os.path.isdir(respath):
- shutil.rmtree(respath, True)
- os.makedirs(respath)
- num = 1
- while num<=204:
- name = "%04d" % num
- fileName = path + str(name) + ".txt"
- resName = respath + str(name) + ".txt"
- source = open(fileName, 'r')
- if os.path.exists(resName):
- os.remove(resName)
- result = codecs.open(resName, 'w', 'utf-8')
- line = source.readline()
- line = line.rstrip('\n')
- while line!="":
- line = unicode(line, "utf-8")
- seglist = jieba.cut(line,cut_all=False) #精确模式
- output = ' '.join(list(seglist)) #空格拼接
- print output
- result.write(output + '\r\n')
- line = source.readline()
- else:
- print 'End file: ' + str(num)
- source.close()
- result.close()
- num = num + 1
- else:
- print 'End All'
- #Run function
- if __name__ == '__main__':
- read_file_cut()
运行结果如下图所示:
5.去除停用词
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。但是,并没有一个明确的停用词表能够适用于所有的工具。甚至有一些工具是明确地避免使用停用词来支持短语搜索的。[参考百度百科]
[python] view plain copy
- #encoding=utf-8
- import jieba
- #去除停用词
- stopwords = {}.fromkeys(['的', '包括', '等', '是'])
- text = "故宫的著名景点包括乾清宫、太和殿和午门等。其中乾清宫非常精美,午门是紫禁城的正门。"
- segs = jieba.cut(text, cut_all=False)
- final = ''
- for seg in segs:
- seg = seg.encode('utf-8')
- if seg not in stopwords:
- final += seg
- print final
- #输出:故宫著名景点乾清宫、太和殿和午门。其中乾清宫非常精美,午门紫禁城正门。
- seg_list = jieba.cut(final, cut_all=False)
- print "/ ".join(seg_list)
- #输出:故宫/ 著名景点/ 乾清宫/ 、/ 太和殿/ 和/ 午门/ 。/ 其中/ 乾清宫/ 非常/ 精美/ ,/ 午门/ 紫禁城/ 正门/ 。
三. 基于VSM的文本聚类算法
这部分主要参考2008年上海交通大学姚清坛等《基于向量空间模型的文本聚类算法》的论文,因为我的实体对齐使用InfoBox存在很多问题,发现对齐中会用到文本内容及聚类算法,所以简单讲述下文章一些知识。
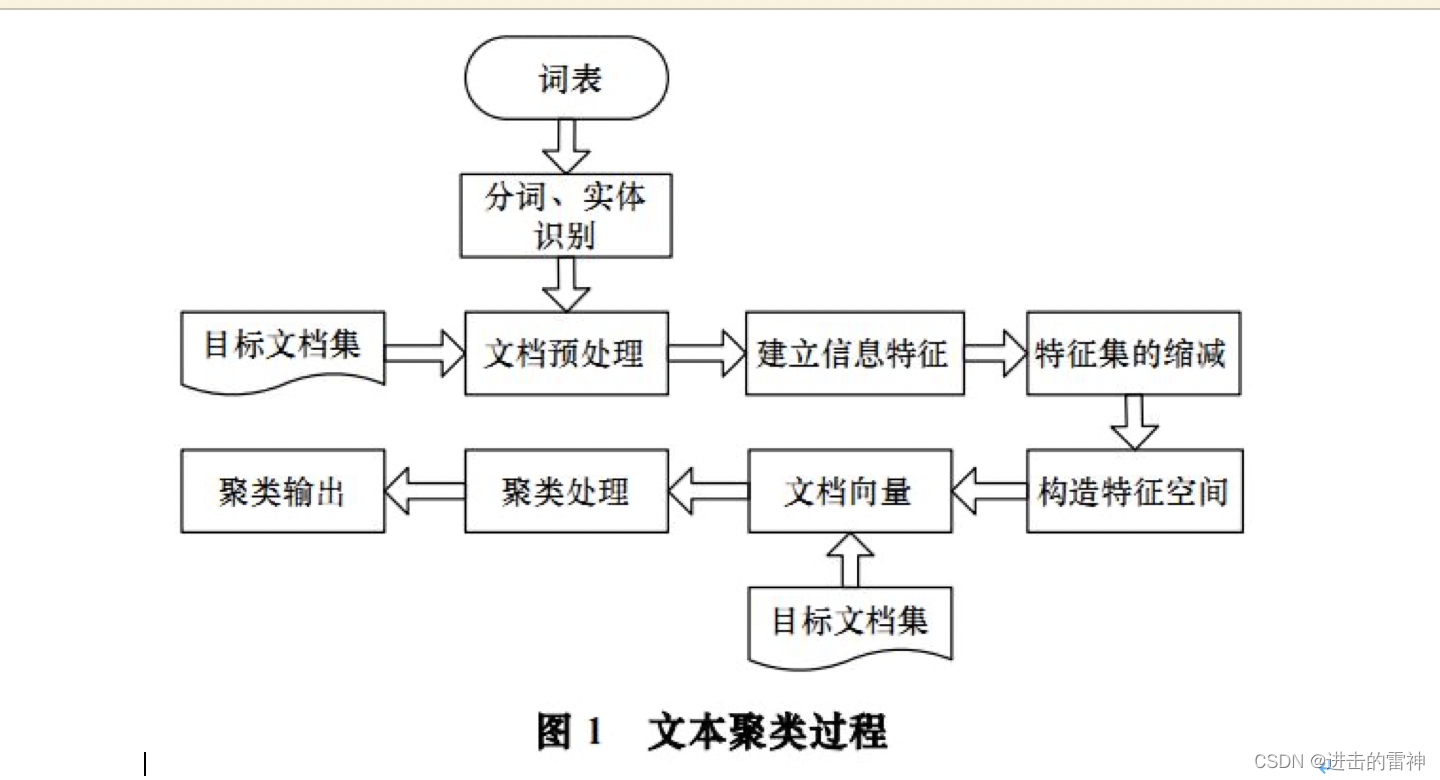
文本聚类的主要依据聚类假设是:同类的文档相似度较大,而非同类文档相似度较小。同时使用无监督学习方法,聚类不需要训练过程以及不需要预先对文档手工标注类别,因此具有较高的灵活性和自动化处理能力。主要分为以下部分:
(1) 预处理常用方法
文本信息预处理(词性标注、语义标注),构建统计词典,对文本进行词条切分,完成文本信息的分词过程。
(2) 文本信息的特征表示
采用方法包括布尔逻辑型、概率型、混合型和向量空间模型。其中向量空间模型VSM(Vector Space Model)是将文档映射成向量的形式,(T1, T2, ..., Tn)表示文档词条,(W1, W2, ..., Wn)文档词条对应权重。建立文本特征主要用特征项或词条来表示目标文本信息,构造评价函数来表示词条权重,尽最大限度区别不同的文档。
(3) 文本信息特征缩减
VSM文档特征向量维数众多。因此,在文本进行聚类之前,应用文本信息特征集进行缩减,针对每个特征词的权重排序,选取最佳特征,包括TF-IDF。推荐向量稀疏表示方法,提升聚类的效果,其中(D1, D2, ..., Dn)表示权重不为0的特征词条。
(4) 文本聚类
文本内容表示成数学课分析形势后,接下来就是在此数学基础上进行文本聚类。包括基于概率方法和基于距离方法。其中基于概率是利用贝叶斯概率理论,概率分布方式;基于聚类是特征向量表示文档(文档看成一个点),通过计算点之间的距离,包括层次聚类法和平面划分法。
后面我可能也会写具体的Python聚类算法,VSM计算相似度我前面已经讲过。同时,他的实验数据是搜狐中心的10个大类,包括汽车、财经、IT、体育等,而我的数据都是旅游,如何进一步聚类划分,如山川、河流、博物馆等等,这是另一个难点。
相关文章:
[python] 使用Jieba工具中文分词及文本聚类概念
前面讲述了很多关于Python爬取本体Ontology、消息盒InfoBox、虎扑图片等例子,同时讲述了VSM向量空间模型的应用。但是由于InfoBox没有前后文和语义概念,所以效果不是很好,这篇文章主要是爬取百度5A景区摘要信息,再利用Jieba分词工…...

常见程序搜索关键字转码
个别搜索类的网站因为用户恶意搜索出现误拦截情况,这类网站本身没有非法信息,只是因为把搜索关键字显示在网页中(如下图),可以参考下面方法对输出的关键字进行转码 DEDECMS程序 本文针对Dedecms程序进行搜索转码&…...

细谈商品详情API接口设计
一、引言 随着互联网技术的发展,商品详情信息的展示和交互变得越来越重要。为了提供更好的用户体验,我们需要设计一套高效、稳定且易于扩展的商品详情API接口。本文将详细探讨商品详情API接口的设计,包括接口的通用性、安全性和扩展性等方面…...
详解)
Go 1.21新增的内置函数(built-in functions)详解
Go 1.21新增的内置函数分别是 min、max 和 clear,接下来看下这几个函数的用途和使用示例。 在编程过程中,需要知道一组值中的最大或最小值的场景是很常见的,比如排序、统计等场景。之前都需要自己写代码来实现这个功能,现在 Go 1…...
【云原生,k8s】基于Helm管理Kubernetes应用
第四阶段 时 间:2023年8月18日 参加人:全班人员 内 容: 基于Helm管理Kubernetes应用 目录 一、Kubernetes部署方式 (一)minikube (二)二进制包 (三)Kubeadm …...

字符设备驱动分布注册
驱动文件: 脑图: 现象:...
在Gazebo中添加悬浮模型后,利用键盘控制其移动方法
前段时间写了文章,通过修改sdf、urdf模型的方法,在Gazebo中添加悬浮模型方法 / Gazebo中模型如何不因重力下落:在Gazebo中添加悬浮模型方法 / Gazebo中模型如何不因重力下落:修改sdf、urdf模型_sagima_sdu的博客-CSDN博客 今天讲…...
 模板方法设计模式)
Java设计模式 (一) 模板方法设计模式
什么是模板方法设计模式? 模板方法设计模式是一种行为型设计模式,它定义了一个算法的骨架,并将一些步骤的具体实现延迟到子类中。模板方法模式可以帮助确保在算法的不同部分中保持一致性,同时也允许子类根据需要进行具体实现。 模板方法模式…...

PHP在线客服系统推荐
在当今数字化时代,企业客户服务的重要性不容忽视。为了提供卓越的客户体验,许多企业正在寻找PHP在线客服系统。这种系统不仅可以满足客户的需求,还能提升企业的形象。本文将深入探讨PHP在线客服系统的一些有趣话题。 理解PHP在线客服系统 PHP…...
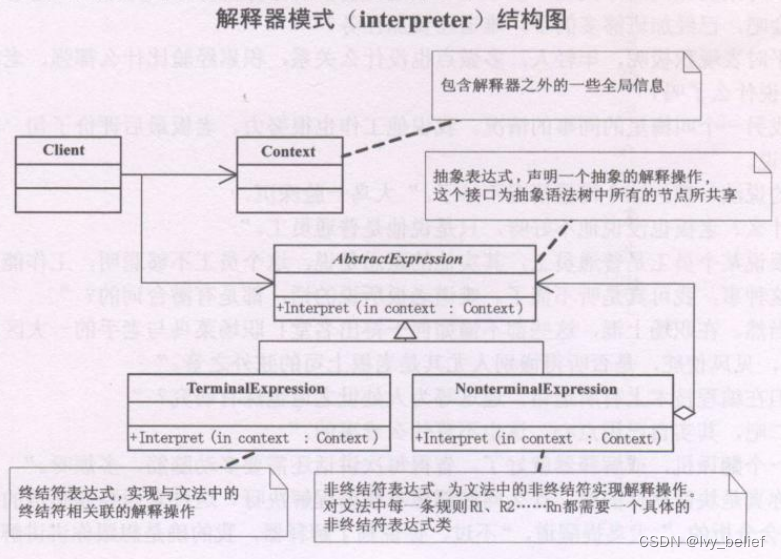
(三)行为型模式:3、解释器模式(Interpreter Pattern)(C++示例)
目录 1、解释器模式(Interpreter Pattern)含义 2、解释器模式的UML图学习 3、解释器模式的应用场景 4、解释器模式的优缺点 5、C实现解释器模式的实例 1、解释器模式(Interpreter Pattern)含义 解释器模式(Interp…...

Zookeeper 启动闪退
常见的大概这两种情况 1.找不到zoo.cfg文件 在下载zookeeper后,在 %zookeeper安装目录%/conf 目录下有一个zoo.sample.cfg 文件,把 zoo.sample.cfg 文件改名为 zoo.cfg 再重启zkServer.cmd echo off REM Licensed to the Apache Software Foundation …...
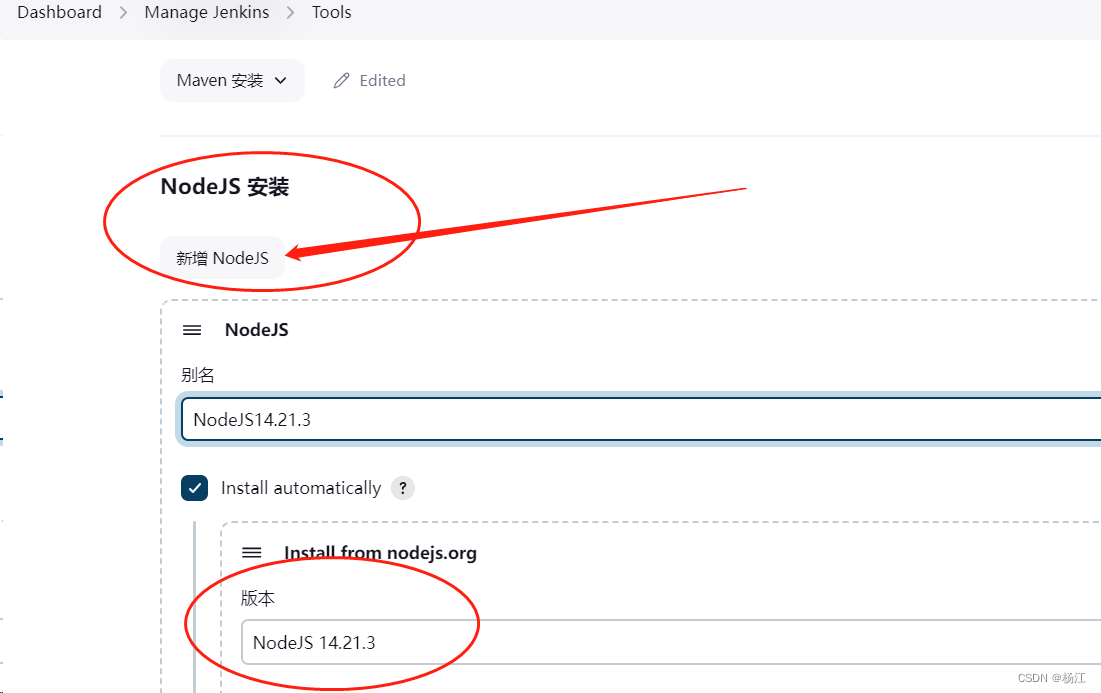
jenkins 安装nodejs 14
参考: jenkins容器安装nodejs-前端问答-PHP中文网...
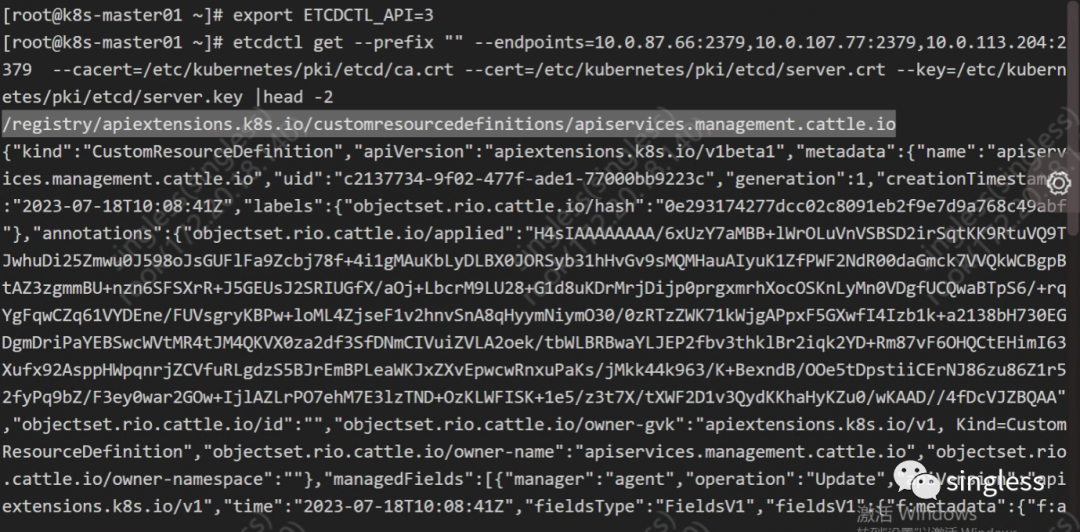
K8S核心组件etcd详解(上)
1 介绍 https://etcd.io/docs/v3.5/ etcd是一个高可用的分布式键值存储系统,是CoreOS(现在隶属于Red Hat)公司开发的一个开源项目。它提供了一个简单的接口来存储和检索键值对数据,并使用Raft协议实现了分布式一致性。etcd广泛应用…...
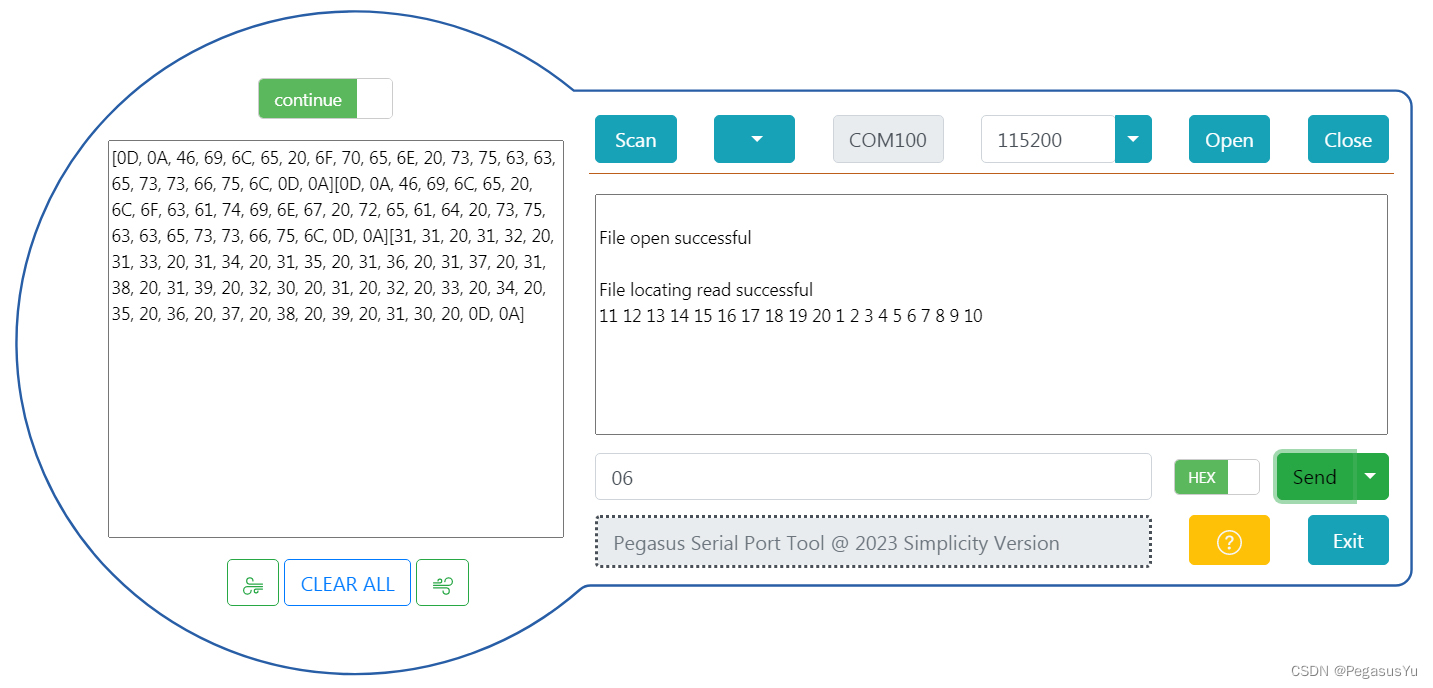
STM32存储左右互搏 I2C总线FATS读写EEPROM ZD24C1MA
STM32存储左右互搏 I2C总线FATS读写EEPROM ZD24C1MA 在较低容量存储领域,EEPROM是常用的存储介质,可以通过直接或者文件操作方式进行读写。不同容量的EEPROM的地址对应位数不同,在发送字节的格式上有所区别。EEPROM是非快速访问存储…...
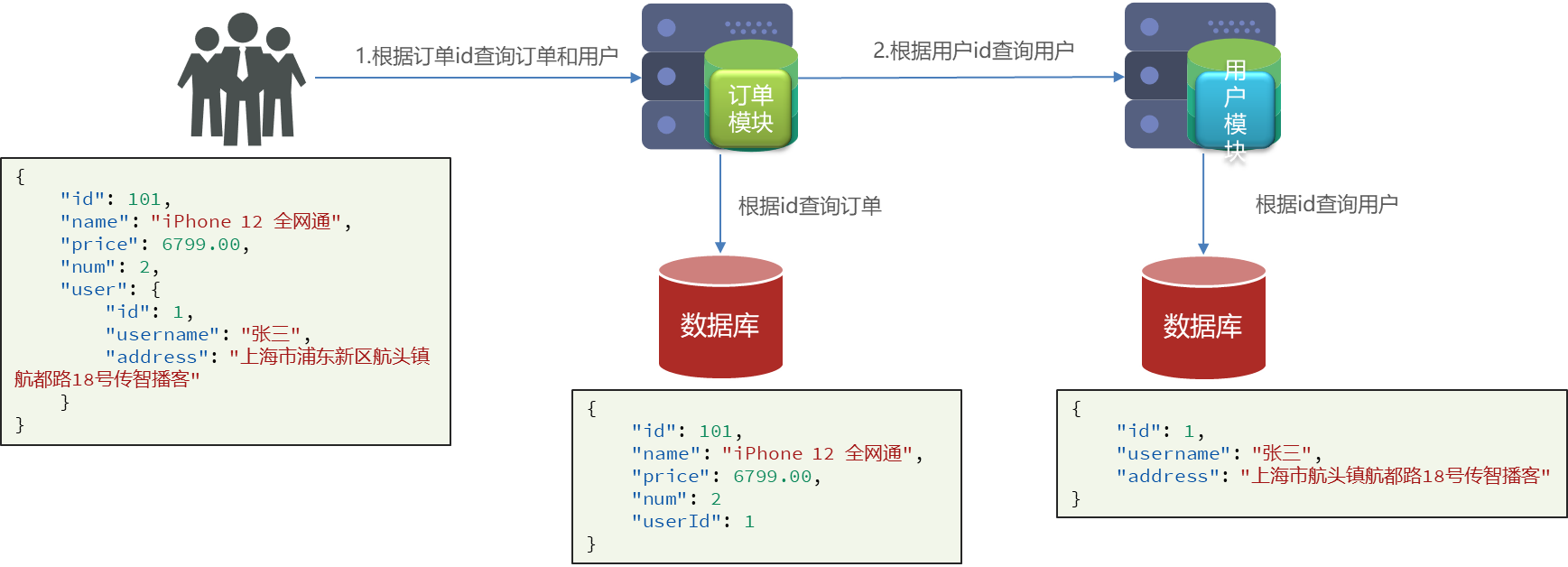
微服务—远程调用(RestTemplate)
在微服务的所有框架中,SpringCloud脱颖而出,它是目前国内使用的最广泛的微服务框架 (官网地址),它集成了各种微服务功能组件,并基于SpringBoot实现了这些组件的自动装配,从而提供了良好的开箱…...
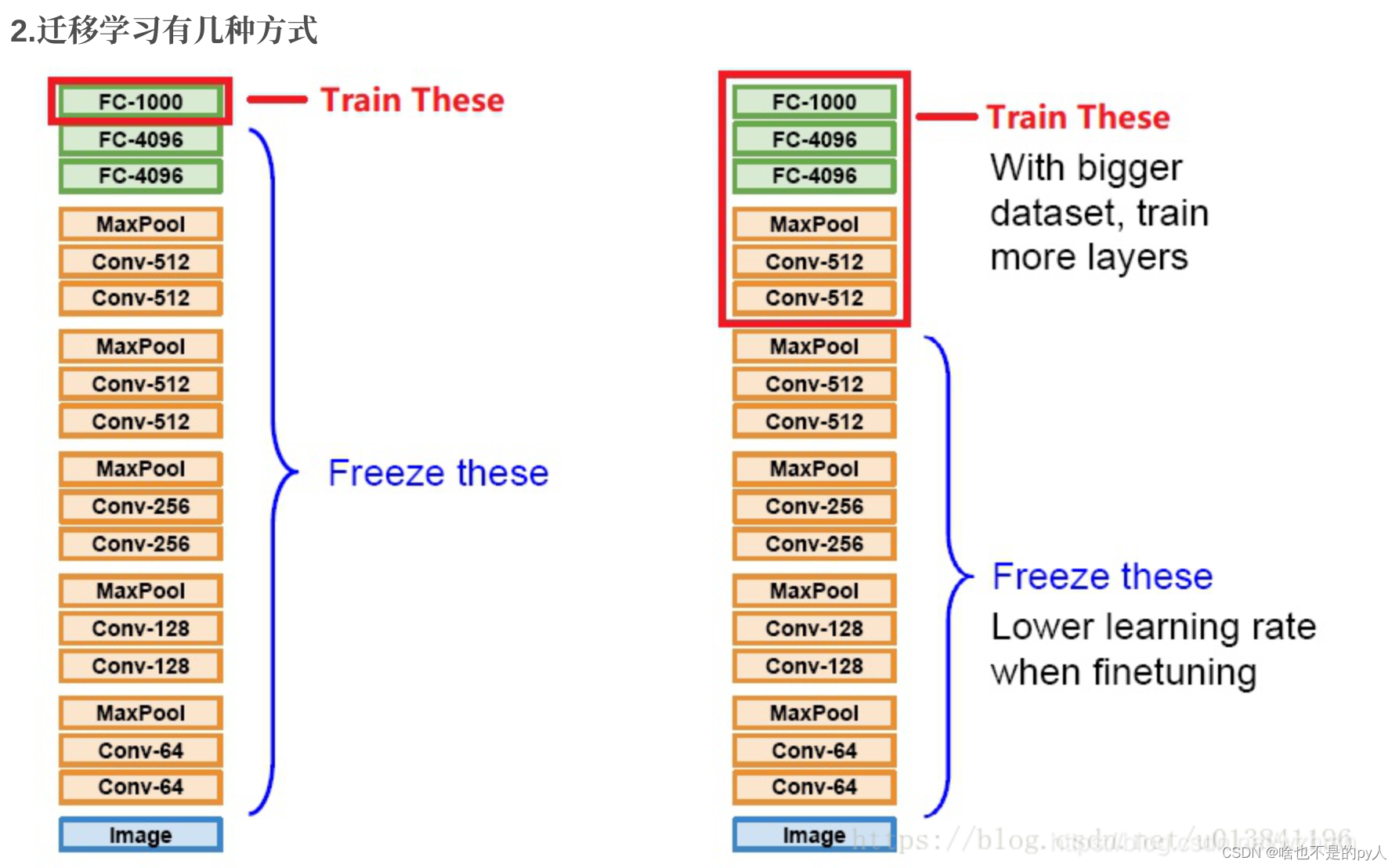
Fine tune简介
目录 Intro Related work Example .1 重新训练 .2 使用新的数据集进行fine tune .3 修改net结构 References 移学习不是一种算法而是一种机器学习思想,应用到深度学习就是微调(Fine-tune)。通过修改预训练网络模型结构(如修改样本类别输出个数),选择性载入预训练网络…...

centos nginx配置ipv4和ipv6的地址都可以访问同一个网站
标题centos nginx配置ipv4和ipv6的地址都可以访问同一个网站 在 Nginx 中配置使 IPv4 和 IPv6 地址都可以访问同一个网站相对简单。只需要确保 Nginx 配置文件正确地配置了监听 IPv4 和 IPv6 地址的监听器即可。 打开你的 Nginx 配置文件,通常位于 /etc/nginx/nginx…...

高教杯数学建模2020C题总结
🧡1. 前言🧡 跟队友花了三天模拟2020C题,现在整理一下一些数据处理的代码,以及在模拟中没有解决的问题。方便以后回溯笔记。 🧡2. 数据处理🧡 2.1 导入数据,并做相关预处理 import pandas a…...

Swagger
目录 简介 使用方式: 常用注解 简介 使用Swagger你只需要按照他的规范去定义接口及接口相关信息再通过Swagger衍生出来的一系列项目和工具,就可以做到生成各种格式的接口文档,以及在线接口调试页面等等。 官网:https://swagger…...

Android 13像Settings一样获取热点和网络共享
一.背景 由于客户定制的Settings里面需要获取到热点和网络共享状态,所以需要实现此功能。 目录 一.背景 二.前提条件 三.调用api 二.前提条件 首先应用肯定要是系统应用,并且导入framework.jar包,具体可以参考: Android 应用自动开启辅助(无障碍)功能并使用辅助(无障碍…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...

差分隐私GDP机制紧密度量化:从隐私剖面到∆度量的实践指南
1. 差分隐私GDP机制:从理论到实践,如何量化隐私保护紧密度在差分隐私(Differential Privacy, DP)的实际部署中,尤其是在机器学习的隐私保护训练(如DP-SGD)场景里,我们常常面临一个核…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

3分钟告别英文恐惧:Android Studio中文界面轻松切换指南
3分钟告别英文恐惧:Android Studio中文界面轻松切换指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 你是否曾经因…...

BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕
BiliBiliCCSubtitle终极指南:5个实战技巧高效下载B站字幕 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 还在为无法保存B站视频字幕而烦恼࿱…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...

Arduino土壤湿度监测仪制作:从传感器原理到自动灌溉实现
1. 项目概述:用Arduino Uno和LCD屏打造你的土壤湿度监测仪作为一个喜欢在阳台种点番茄、辣椒的业余园丁,我经常为浇水这事儿头疼。浇多了怕烂根,浇少了又怕旱着,光靠手指插土里感觉,实在是不准。后来玩上了Arduino&…...