iceberg系列之 hadoop catalog 小文件合并实战
- 背景
flink1.15 hadoop3.0 - pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.iceberg</groupId><artifactId>flink-iceberg</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.15.3</flink.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.30</slf4j.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-core</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><!--idea运行时也有webui--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version><scope>compile</scope></dependency><dependency><groupId>org.apache.iceberg</groupId><artifactId>iceberg-flink-runtime-1.15</artifactId><version>1.3.0</version></dependency><dependency><groupId>org.apache.iceberg</groupId><artifactId>iceberg-core</artifactId><version>1.3.0</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><configuration><archive><manifest><!-- 指定主类 --><mainClass>com.iceberg.flink.UnionDelData</mainClass></manifest></archive><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
- 资源配置文件
hadoop三个常用配置文件core-site.xml hdfs-site.xml yarn-site.xml 放到资源目录下 - java代码
package com.iceberg.flink;import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.Table;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.flink.actions.Actions;
import org.apache.iceberg.hadoop.HadoopCatalog;import java.io.File;
import java.net.MalformedURLException;public class UnionDelData {public static void main(String[] args) throws MalformedURLException { String tableNames = args[1];long targetsSize = parseSizeToBytes(args[2]);int parallelism = Integer.parseInt(args[3]);long retainTime = parseTimeToMillis(args[4]);int retainLastNum = Integer.parseInt(args[5]);Configuration conf = new Configuration();conf.addResource(new File("/home/hadoop/hadoopconf/core-site.xml").toURI().toURL());conf.addResource(new File("/home/hadoop/hadoopconf/hdfs-site.xml").toURI().toURL());conf.addResource(new File("/home/hadoop/hadoopconf/yarn-site.xml").toURI().toURL());HadoopCatalog hadoopCatalog = new HadoopCatalog(conf, "/user/hadoop/path/");for (String tableName : tableNames.split(",")) {Table table = hadoopCatalog.loadTable(TableIdentifier.of("prod", tableName));UnionDataFile(table,parallelism,targetsSize);deleteSnap(table,retainTime,retainLastNum);}}public static void UnionDataFile(Table table,int parallelism,long targetsSize) {Actions.forTable(table).rewriteDataFiles().maxParallelism(parallelism).caseSensitive(false).targetSizeInBytes(targetsSize).execute();}public static void deleteSnap(Table table,long retainTime,int retainLastNum){Snapshot snapshot = table.currentSnapshot();long oldSnapshot = snapshot.timestampMillis() - retainTime;if (snapshot != null) { table.expireSnapshots().expireOlderThan(oldSnapshot).cleanExpiredFiles(true).retainLast(retainLastNum).commit();}}public static long parseSizeToBytes(String sizeWithUnit) {long size = Long.parseLong(sizeWithUnit.substring(0, sizeWithUnit.length() - 1));char unit = sizeWithUnit.charAt(sizeWithUnit.length() - 1); switch (unit) {case 'B':return size;case 'K':case 'k': return size * 1024;case 'M':case 'm': return size * 1024 * 1024;case 'G':case 'g': return size * 1024 * 1024 * 1024;default:throw new IllegalArgumentException("Invalid size unit: " + unit);}}public static long parseTimeToMillis(String timeWithUnit) {long time = Long.parseLong(timeWithUnit.substring(0, timeWithUnit.length() - 1));char unit = timeWithUnit.charAt(timeWithUnit.length() - 1);switch (unit) {case 's':case 'S':return time * 1000;case 'm':case 'M':return time * 60 * 1000;case 'h':case 'H':return time * 60 * 60 * 1000;case 'd':case 'D':return time * 24 * 60 * 60 * 1000;default:throw new IllegalArgumentException("Invalid time unit: " + unit);}}
}相关文章:

iceberg系列之 hadoop catalog 小文件合并实战
背景 flink1.15 hadoop3.0pom文件 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://mave…...

神经网络基础-神经网络补充概念-25-深层神经网络
简介 深层神经网络(Deep Neural Network,DNN)是一种具有多个隐藏层的神经网络,它可以用来解决复杂的模式识别和特征学习任务。深层神经网络在近年来的机器学习和人工智能领域中取得了重大突破,如图像识别、自然语言处…...
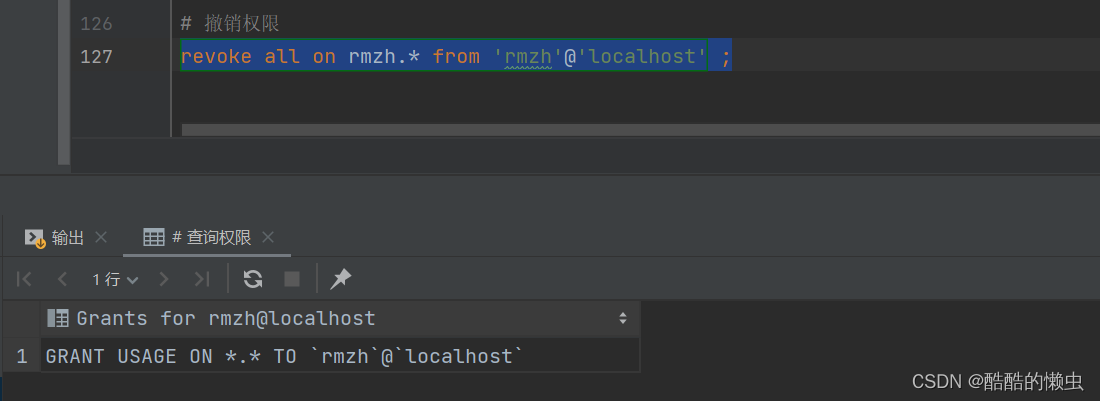
MySQL— 基础语法大全及操作演示!!!(上)
MySQL—— 基础语法大全及操作演示(上) 一、MySQL概述1.1 、数据库相关概念1.1.1 MySQL启动和停止 1.2 、MySQL 客户端连接1.3 、数据模型 二、SQL2.1、SQL通用语法2.2、SQL分类2.3、DDL2.3.1 DDL — 数据库操作2.3.1 DDL — 表操作 2.4、DML2.4.1 DML—…...
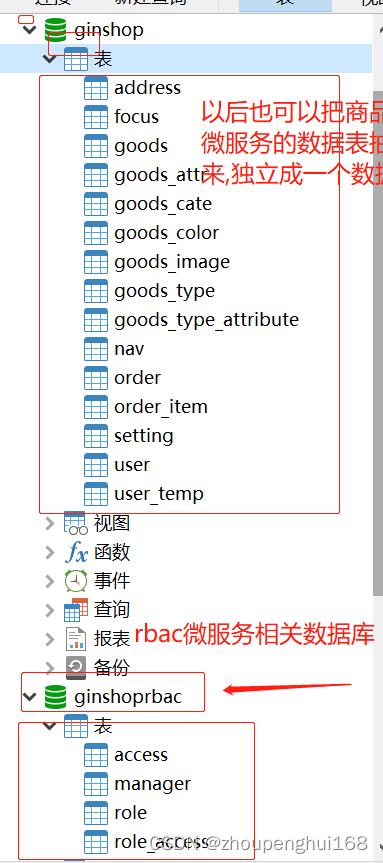
[golang gin框架] 46.Gin商城项目-微服务实战之后台Rbac客户端调用微服务权限验证以及Rbac微服务数据库抽离
一. 根据用户的权限动态显示左侧菜单微服务 1.引入 后台Rbac客户端调用微服务权限验证功能主要是: 登录后显示用户名称、根据用户的权限动态显示左侧菜单,判断当前登录用户的权限 、没有权限访问则拒绝,参考[golang gin框架] 14.Gin 商城项目-RBAC管理,该微服务功能和上一节[g…...

域名和ip的关系
域名和ip的关系 一:什么是域名 域名,简称域名、网域,是由一串用点分隔的名字组成的上某一台计算机或计算机组的名称,用于在数据传输时标识 计算机的电子方位(有时也指地理位置)。网域名称系统,有时也简称为域名…...

excel日期函数篇1
1、DAY(serial_number):返回序列数表示的某月的天数 在括号内给出一个时间对象或引用一个时间对象(年月日),返回多少日 下面结果都为20 2、MONTH(serial_number):返回序列数表示的某年的月份 在括号内给出一个时间对…...

Leetcode151 翻转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。 单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。 返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。 注意:输入字符串 s中可能会存在前导空格、尾随空格…...

PHP FTP的相关函数及简单使用示例
简介 FTP是ARPANet的标准文件传输协议,该网络就是现今Internet的前身。 PHP FTP函数是通过文件传输协议提供对文件服务器的客户端访问,FTP函数用于打开、登陆以及关闭连接,也用于上传、下载、重命名、删除以及获取服务器上文件信息。 安装 …...
高光谱 | 矿物识别和分类标签数据制作、农作物病虫害数据分类、土壤有机质含量回归与制图、木材含水量评估和制图
本课程提供一套基于Python编程工具的高光谱数据处理方法和应用案例。 本课程涵盖高光谱遥感的基础、方法和实践。基础篇以学员为中心,用通俗易懂的语言解释高光谱的基本概念和理论,旨在帮助学员深入理解科学原理。方法篇结合Python编程工具,…...

【数据结构】二叉树篇| 纲领思路01+刷题
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: 是瑶瑶子啦每日一言🌼: 所谓自由,不是随心所欲,而是自我主宰。——康德 目录 一、二叉树刷题纲领二、刷题1、104. 二叉树的最大深度2、 二叉…...

系统架构设计师---计算机基础知识之数据库系统结构与规范化
目录 一、基本概念 二、 数据库的结构 三、常用的数据模型 概念数据模型...
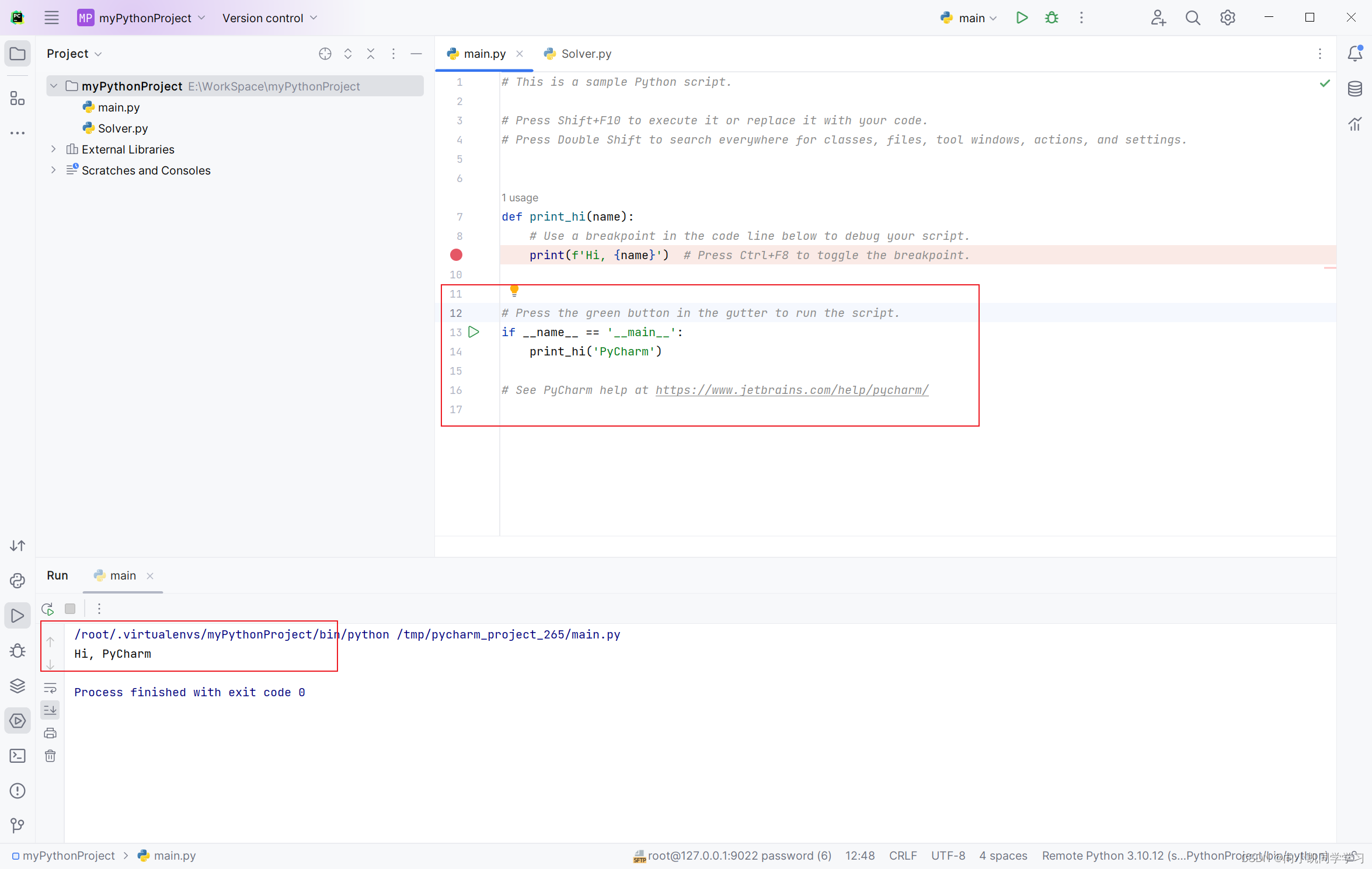
PyCharm连接Docker中的容器(ubuntu)
一、为什么要用Pycharm链接Docker中的ubuntu 因为在进行深度学习的时候,基于windows系统在开发的过程中,老是出现很多问题,大多数是环境问题。 尽管安装了Conda,也不能很好的解决问题,使用ubuntu是最好的选择。 二、…...
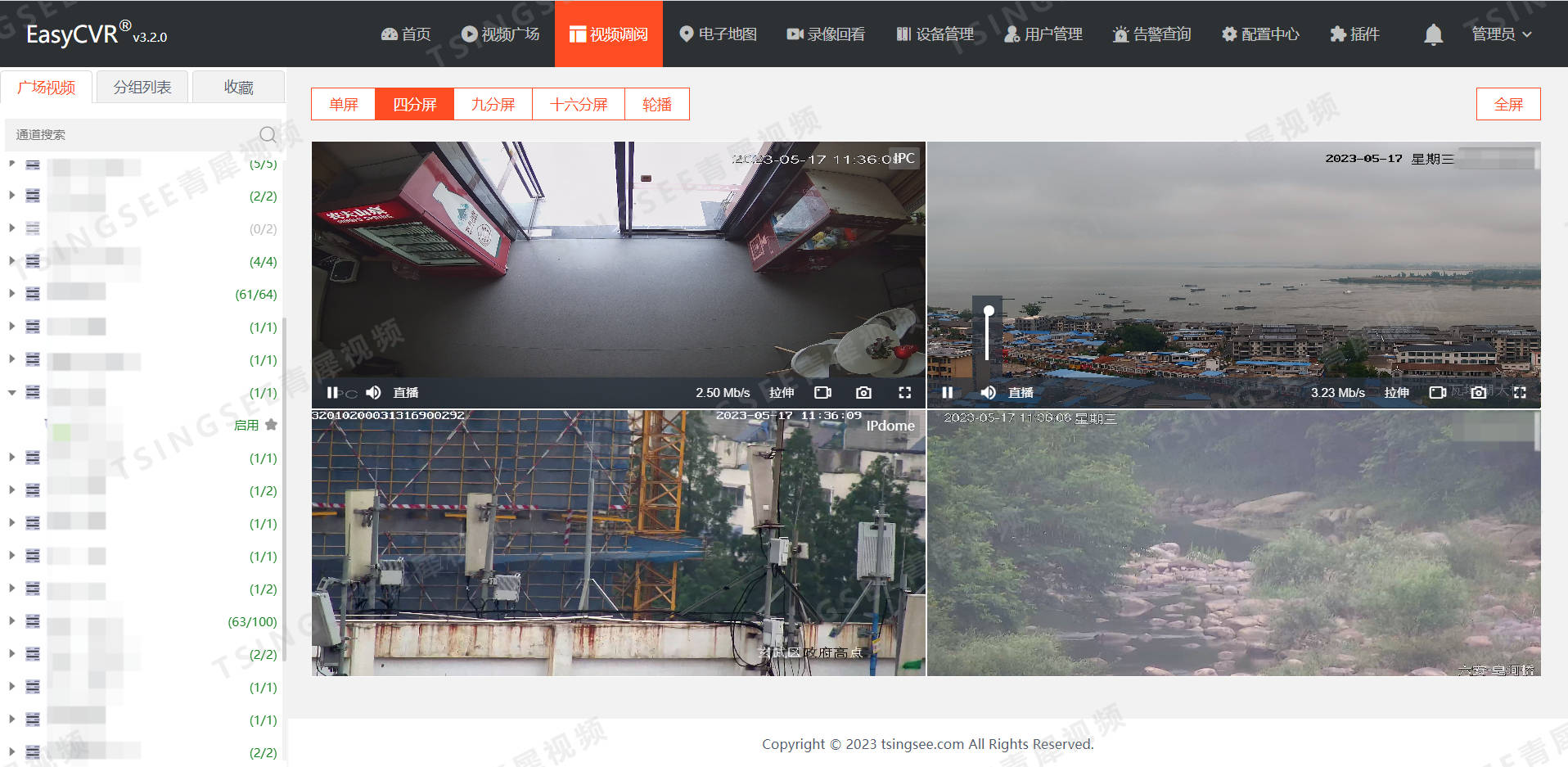
安防视频汇聚平台EasyCVR视频监控综合管理平台H.265转码功能更新,新增分辨率配置的具体步骤
安防视频集中存储EasyCVR视频监控综合管理平台可以根据不同的场景需求,让平台在内网、专网、VPN、广域网、互联网等各种环境下进行音视频的采集、接入与多端分发。在视频能力上,视频云存储平台EasyCVR可实现视频实时直播、云端录像、视频云存储、视频存储…...
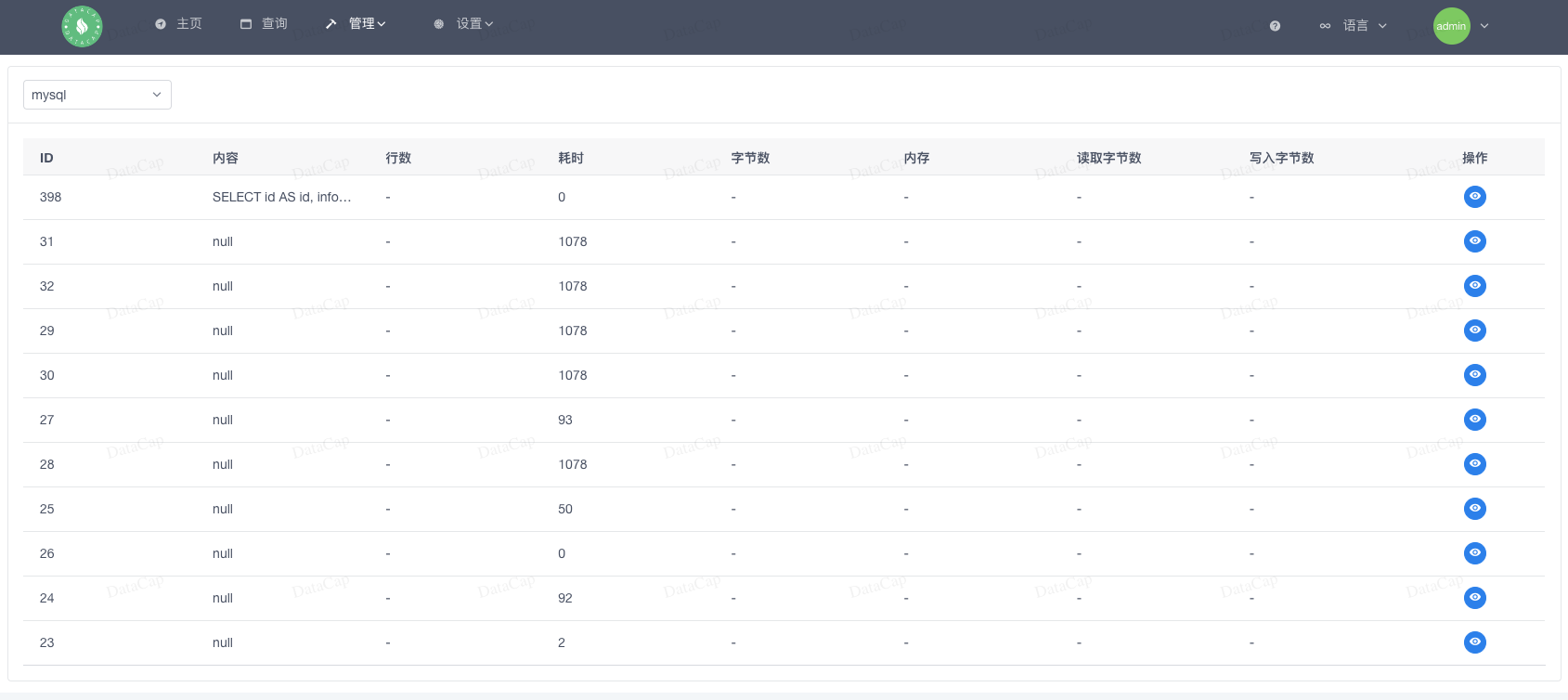
全平台数据(数据库)管理工具 DataCap 管理 Rainbond 上的所有数据库
DataCap是用于数据转换、集成和可视化的集成软件,支持多种数据源、文件类型、大数据相关数据库、关系数据库、NoSQL数据库等。通过该 DataCap 可以实现对多个数据源的管理,对数据源下的数据进行各种操作转换,制作数据图表,监控数据…...

“深入探究JVM内部机制:从字节码到实际执行“
标题:深入探究JVM内部机制:从字节码到实际执行 摘要:本文将深入探究Java虚拟机(JVM)的内部机制,从字节码的生成、类加载、字节码解释和即时编译等环节,详细介绍JVM是如何将Java程序的字节码转化…...
C++写文件,直接写入结构体
C写文件,直接写入结构体 以前写文件都是写入字符串或者二进制再或者就是一些配置文件,今天介绍一下直接写入结构体,可以在软件参数较多的时候直接进行读写,直接将整个结构体写入和读取,看代码: #include&…...
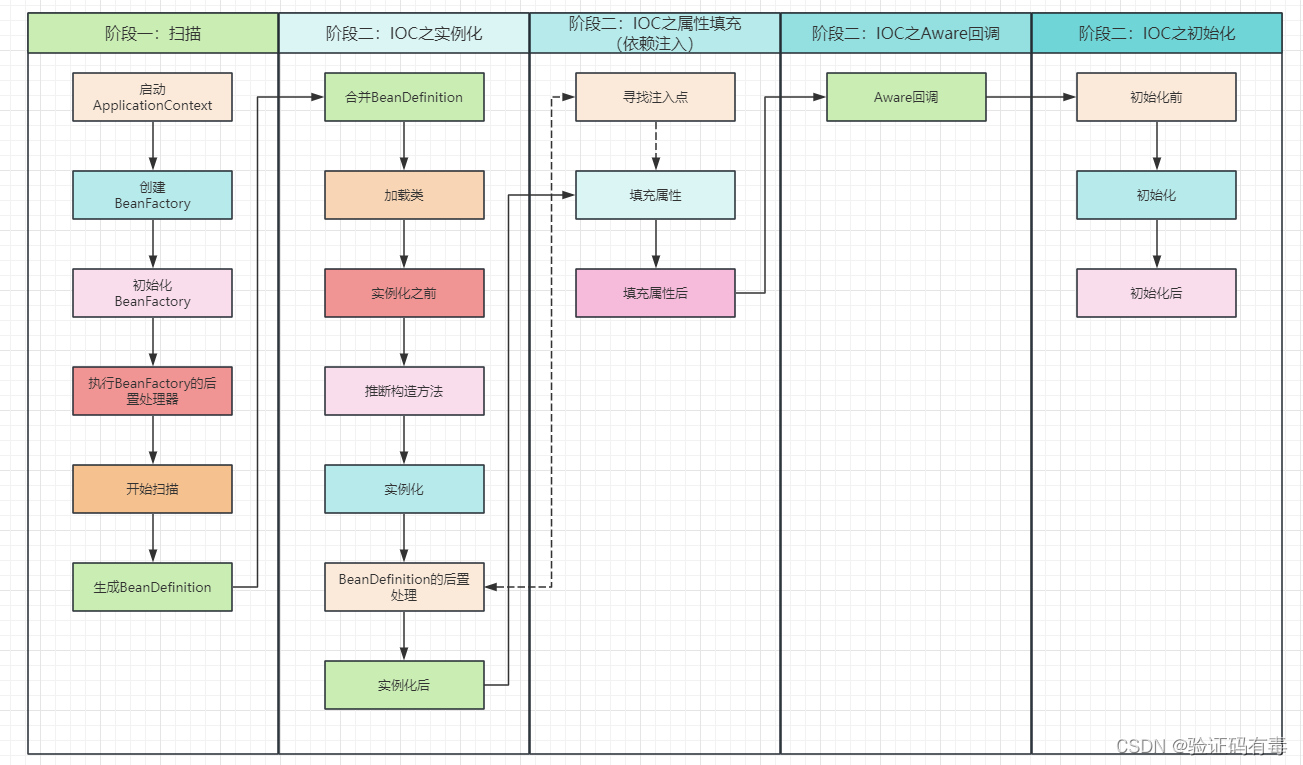
【Spring专题】Spring之Bean的生命周期源码解析——阶段二(二)(IOC之属性填充/依赖注入)
目录 前言阅读准备阅读指引阅读建议 课程内容一、依赖注入方式(前置知识)1.1 手动注入1.2 自动注入1.2.1 XML的autowire自动注入1.2.1.1 byType:按照类型进行注入1.2.1.2 byName:按照名称进行注入1.2.1.3 constructor:…...

线程|线程的使用、四种实现方式
1.线程的实现方式 1.用户级线程 开销小,用户空间就可以创建多个。缺点是:内核无法感知用户级多个线程的存在,把其当作只有一个线程,所以只会提供一个处理器。 2.内核级线程 相对于用户级开销稍微大一点,可以利用多…...
Facebook 应用未启用:这款应用目前无法使用,应用开发者已得知这个问题。
错误:Facebook 应用未启用:这款应用目前无法使用,应用开发者已得知这个问题。应用重新启用后,你便能登录。 「应用未经过审核或未发布」: 如果一个应用还没有经过Facebook的审核或者开发者尚未将应用发布,那么它将无法…...
(十八)大数据实战——Hive的metastore元数据服务安装
前言 Hive的metastore服务作用是为Hive CLI或者Hiveserver2提供元数据访问接口。Hive的metastore 是Hive元数据的存储和管理组件,它负责管理 Hive 表、分区、列等元数据信息。元数据是描述数据的数据,它包含了关于表结构、存储位置、数据类型等信息。本…...

VIIRS在灾害监测中的实战应用:以洪水检测为例的Python代码解析
VIIRS在灾害监测中的实战应用:以洪水检测为例的Python代码解析 当洪水席卷城镇时,每一分钟的响应延迟都可能意味着更多生命财产的损失。VIIRS(可见光红外成像辐射计套件)作为NASA灾害监测系统的"鹰眼",其375…...

高分二号卫星全解析:从光谱波段到城市管理的实战应用
1. 高分二号卫星的技术参数详解 高分二号卫星作为我国首颗亚米级高分辨率民用光学遥感卫星,其技术参数直接决定了它在城市管理中的应用能力。先说说最核心的空间分辨率:全色波段0.8米意味着能清晰识别小轿车级别的物体,多光谱3.2米分辨率则适…...

前开发转行AI萨满:给大模型驱魔收费百万
在人工智能的狂潮中,一个看似荒诞的职业正在硅谷悄然兴起——AI萨满。他们不是巫师,而是精通软件测试的前开发者,用测试思维为大型语言模型“驱魔”,收费高达百万。本文将从软件测试的专业视角,揭秘这一转型背后的逻辑…...

LabVIEW标准表法开发气体流量标准装置
标准表法是气体流量计检定校准的主流方法,针对气体流量检测过程中自动化程度低、数据采集精度不足、设备控制协同性差的问题,依托 LabVIEW 图形化编程平台搭建气体流量标准装置应用系统,实现温度、压力、流量等参数的自动化采集、设备精准调控…...

OpenCV处理RTSP流太慢?试试把视频帧存成二进制文件吧!一个提升IO效率的实战技巧
OpenCV处理RTSP流性能优化:二进制帧存储实战指南 在实时视频分析系统中,我们常常遇到这样的困境:OpenCV能够快速解码RTSP流,但后续的处理环节(如算法推理、视频录制)却跟不上节奏。这种"解码快、消费慢…...
)
保姆级教程:用LayoutLMv3和CDLA数据集搞定文档版面分析(附完整代码)
从零构建文档智能分析系统:基于LayoutLMv3与CDLA的实战指南 当一份复杂的合同或报告需要快速解析时,传统OCR技术往往只能提供杂乱无章的文本碎片。而现代文档智能系统已经能够理解文档的逻辑结构——自动识别标题、段落、表格的位置关系,就像…...

OpenClaw + 搜索与资讯:让 AI 帮你「刷」信息,告别信息焦虑
你每天花多少时间刷信息流?30分钟?1小时?今天这篇文章,帮你把这段时间降为零。 01 信息过载是现代人的标配焦虑 早上醒来第一件事是什么?很多人已经条件反射地拿起手机,打开微信公众号、知乎、微博、Twitt…...

ChatTTS一键启动:从零搭建语音合成服务的实战指南
语音合成服务在现代应用中扮演着越来越重要的角色。它被广泛应用于智能客服、有声读物生成和视频内容配音等场景。通过将文本转化为自然流畅的语音,极大地提升了人机交互的体验和应用的可访问性。 然而,对于希望快速部署ChatTTS这类先进语音合成模型的开…...

TensorRT性能调优实战指南:从瓶颈诊断到引擎优化
TensorRT性能调优实战指南:从瓶颈诊断到引擎优化 【免费下载链接】TensorRT NVIDIA TensorRT™ 是一个用于在 NVIDIA GPU 上进行高性能深度学习推理的软件开发工具包(SDK)。此代码库包含了 TensorRT 的开源组件 项目地址: https://gitcode.…...

OpenClaw+nanobot学术助手:文献自动归类与摘要生成
OpenClawnanobot学术助手:文献自动归类与摘要生成 1. 为什么需要自动化文献管理工具 作为一名经常需要阅读大量论文的研究者,我长期被文献管理问题困扰。电脑里堆积如山的PDF文件,每次需要查找特定内容时都要花费大量时间翻找。更痛苦的是&…...