【Go】锁相关
文章目录
- Mutex锁
- mutex源码分析
- Lock
- UnLock
- mutex两种运行模式
- mutex normal 正常模式
- 自旋
- mutex starvation 饥饿模式
- 锁的底层实现类型
- RWMutex
- RWMutex 实现
- 其他共享内存线程安全的方式
- 思考
- 如何设计一个并发更高的锁?
Mutex锁
mutex源码分析
Locker接口:
type Locker interface {Lock()Unlock()
}
Mutex 就实现了这个接口,Lock请求锁,Unlock释放锁
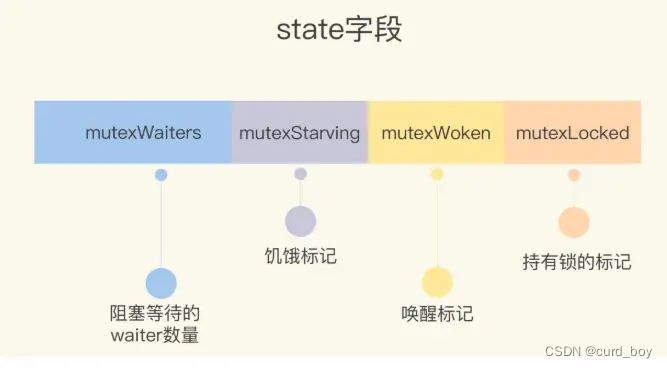
type Mutex struct {state int32 //锁状态,保护四部分含义sema uint32 //信号量,用于阻塞等待或者唤醒
}
-
Locked:表示该 mutex 是否被锁定,0 表示没有,1 表示处于锁定状态;
-
Woken:表示是否有协程被唤醒,0 表示没有,1 表示有协程处于唤醒状态,并且在加锁过程中;
-
Starving:Go1.9 版本之后引入,表示 mutex 是否处于饥饿状态,0 表示没有,1 表示有协程处于饥饿状态;
-
Waiter: 等待锁的协程数量。
方法解析
const (// mutex is locked ,在低位,值 1mutexLocked = 1 << iota//标识有协程被唤醒,处于 state 中的第二个 bit 位,值 2mutexWoken//标识 mutex 处于饥饿模式,处于 state 中的第三个 bit 位,值 4mutexStarving// 值 3,state 值通过右移三位可以得到 waiter 的数量// 同理,state += 1 << mutexWaiterShift,可以累加 waiter 的数量mutexWaiterShift = iota// 标识协程处于饥饿状态的最长阻塞时间,当前被设置为 1msstarvationThresholdNs = 1e6
)
Lock
func (m *Mutex) Lock() {// Fast path: grab unlocked mutex. //运气好,直接加锁成功if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {if race.Enabled {race.Acquire(unsafe.Pointer(m))}return}// Slow path (outlined so that the fast path can be inlined)//内联,加锁失败,就得去自旋竞争或者饥饿模式下竞争m.lockSlow()
}
func (m *Mutex) lockSlow() {var waitStartTime int64// 标识是否处于饥饿模式starving := false// 唤醒标记awoke := false// 自旋次数iter := 0old := m.statefor {// 非饥饿模式下,开启自旋操作// 从 runtime_canSpin(iter) 的实现中(runtime/proc.sync_runtime_canSpin)可以知道,// 如果 iter 的值大于 4,将返回 falseif old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) {// 如果没有其他 waiter 被唤醒,那么将当前协程置为唤醒状态,同时 CAS 更新 mutex 的 Woken 位if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 &&atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) {awoke = true}// 开启自旋runtime_doSpin()iter++// 重新检查 state 的值old = m.statecontinue}new := old// 非饥饿状态if old&mutexStarving == 0 {// 当前协程可以直接加锁new |= mutexLocked}// mutex 已经被锁住或者处于饥饿模式// 那么当前协程不能获取到锁,将会进入等待状态if old&(mutexLocked|mutexStarving) != 0 {// waiter 数量加 1,当前协程处于等待状态new += 1 << mutexWaiterShift}// 当前协程处于饥饿状态并且 mutex 依然被锁住,那么设置 mutex 为饥饿模式if starving && old&mutexLocked != 0 {new |= mutexStarving}if awoke {if new&mutexWoken == 0 {throw("sync: inconsistent mutex state")}// 清除唤醒标记// &^ 与非操作,mutexWoken: 10 -> 01// 此操作之后,new 的 Locked 位值是 1,如果能够成功写入到 m.state 字段,那么当前协程获取锁成功new &^= mutexWoken}// CAS 设置新状态成功if atomic.CompareAndSwapInt32(&m.state, old, new) {// 旧的锁状态已经被释放并且处于非饥饿状态// 这个时候当前协程正常请求到了锁,就可以直接返回了if old&(mutexLocked|mutexStarving) == 0 {break}// 处理当前协程的饥饿状态// 如果之前已经处于等待状态了(已经在队列里面),那么将其加入到队列头部,从而可以被高优唤醒queueLifo := waitStartTime != 0if waitStartTime == 0 {// 阻塞开始时间waitStartTime = runtime_nanotime()}// P 操作,阻塞等待runtime_SemacquireMutex(&m.sema, queueLifo, 1)// 唤醒之后,如果当前协程等待超过 1ms,那么标识当前协程处于饥饿状态starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNsold = m.state// mutex 已经处于饥饿模式if old&mutexStarving != 0 {// 1. 如果当前协程被唤醒但是 mutex 还是处于锁住状态// 那么 mutex 处于非法状态//// 2. 或者如果此时 waiter 数量是 0,并且 mutex 未被锁住// 代表当前协程没有在 waiters 中,但是却想要获取到锁,那么 mutex 状态非法if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 {throw("sync: inconsistent mutex state")}// delta 代表加锁并且将 waiter 数量减 1 两步操作delta := int32(mutexLocked - 1<<mutexWaiterShift)// 非饥饿状态 或者 当前只剩下一个 waiter 了(就是当前协程本身)if !starving || old>>mutexWaiterShift == 1 {// 那么 mutex 退出饥饿模式delta -= mutexStarving}// 设置新的状态atomic.AddInt32(&m.state, delta)break}awoke = trueiter = 0} else {old = m.state}}if race.Enabled {race.Acquire(unsafe.Pointer(m))}
}
解锁操作会根据 Mutex.state 的状态来判断需不需要去唤醒其他等待中的协程。
func (m *Mutex) unlockSlow(new int32) {// new - state 字段原子减 1 之后的值,如果之前是处于加锁状态,那么此时 new 的末位应该是 0// 此时 new+mutexLocked 正常情况下会将 new 末位变成 1// 那么如果和 mutexLocked 做与运算之后的结果是 0,代表 new 值非法,解锁了一个未加锁的 mutexif (new+mutexLocked)&mutexLocked == 0 {throw("sync: unlock of unlocked mutex")}// 如果不是处于饥饿状态if new&mutexStarving == 0 {old := newfor {// old>>mutexWaiterShift == 0 代表没有等待加锁的协程了,自然不需要执行唤醒操作// old&mutexLocked != 0 代表已经有协程加锁成功,此时没有必要再唤醒一个协程(因为它不可能加锁成功)// old&mutexWoken != 0 代表已经有协程被唤醒并且在加锁过程中,此时不需要再执行唤醒操作了// old&mutexStarving != 0 代表已经进入了饥饿状态,// 以上四种情况,皆不需要执行唤醒操作if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 {return}// 唤醒一个等待中的协程,将 state woken 位置为 1// old - 1<<mutexWaiterShift waiter 数量减 1new = (old - 1<<mutexWaiterShift) | mutexWokenif atomic.CompareAndSwapInt32(&m.state, old, new) {runtime_Semrelease(&m.sema, false, 1)return}old = m.state}} else {// 饥饿模式// 将 mutex 的拥有权转移给下一个 waiter,并且交出 CPU 时间片,从而能够让下一个 waiter 立刻开始执行runtime_Semrelease(&m.sema, true, 1)}
}
UnLock
// 解锁操作
func (m *Mutex) Unlock() {if race.Enabled {_ = m.staterace.Release(unsafe.Pointer(m))}// mutexLocked 位设置为 0,解锁new := atomic.AddInt32(&m.state, -mutexLocked)// 如果此时 state 值不是 0,代表其他位不是 0(或者出现异常使用导致 mutexLocked 位也不是 0)// 此时需要进一步做一些其他操作,比如唤醒等待中的协程等if new != 0 {m.unlockSlow(new)}
}
mutex两种运行模式
饥饿模式是对公平性和性能的一种平衡,它避免了某些 goroutine 长时间的等待锁。在饥饿模式下,优先对待的是那些一直在等待的 waiter。
mutex normal 正常模式
默认情况下,Mutex的模式为normal。
该模式下,协程如果加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。
正常模式 高吞吐量

自旋
自旋是一种多线程同步机制,当前的进程在进入自旋的过程中会一直保持 CPU 的占用,持续检查某个条件是否为真。
在多核的 CPU 上,自旋可以避免 Goroutine 的切换,使用恰当会对性能带来很大的增益,但是使用的不恰当就会拖慢整个程序,所以 Goroutine 进入自旋的条件非常苛刻:
- 互斥锁只有在普通模式才能进入自旋;
- runtime.sync_runtime_canSpin 需要返回 true:
运行在多 CPU 的机器上 - 当前 Goroutine 为了获取该锁进入自旋的次数小于四次;
- 当前机器上至少存在一个正在运行的处理器 P 并且处理的运行队列为空;
https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-sync-primitives/
mutex starvation 饥饿模式
自旋过程中能抢到锁,一定意味着同一时刻有协程释放了锁,我们知道释放锁时如果发现有阻塞等待的协程,还会释放一个信号量来唤醒一个等待协程,被唤醒的协程得到CPU后开始运行,此时发现锁已被抢占了,自己只好再次阻塞,不过阻塞前会判断自上次阻塞到本次阻塞经过了多长时间,如果超过1ms的话,会将Mutex标记为"饥饿"模式,然后再阻塞。
处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减1。
在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin(自旋),它会乖乖地加入到等待队列的尾部。
如果拥有 Mutex 的 waiter 发现下面两种情况的其中之一,它就会把这个 Mutex 转换成正常模式:
- 此 waiter 已经是队列中的最后一个 waiter 了,没有其它的等待锁的 goroutine 了;
- 此 waiter 的等待时间小于 1 毫秒(ms)。
锁的底层实现类型
锁内存总线,针对内存的读写操作,在总线上控制,限制程序的内存访问
锁缓存行,同一个缓存行的内容读写操作,CPU内部的高速缓存保证一致性
锁,作用在一个对象或者变量上。现代CPU会优先在高速缓存查找,如果存在这个对象、变量的缓存行数据,会使用锁缓存行的方式。否则,才使用锁总线的方式。
RWMutex
RWMutex 实现
type RWMutex struct {w Mutex // 复用互斥锁能力//写锁信号量 当阻塞写操作的读操作goroutine释放读锁时,通过该信号量通知阻塞的写操作的goroutine;writerSem uint32
// 读锁信号量 当写操作goroutine释放写锁时,通过该信号量通知阻塞的读操作的goroutinereaderSem uint32 // 当前读操作的数量,包含所有已经获取到读锁或者被写操作阻塞的等待获取读锁的读操作数量readerCount int32 // 获取写锁需要等待读锁释放的数量readerWait int32
}
通过记录 readerCount 读锁的数量来进行控制,当有一个写锁的时候,会将读 锁数量设置为负数 1<<30。目的是让新进入的读锁等待之前的写锁释放通知读 锁。同样的当有写锁进行抢占时,也会等待之前的读锁都释放完毕,才会开始 21 进行后续的操作。 而等写锁释放完之后,会将值重新加上 1<<30, 并通知刚才 新进入的读锁(rw.readerSem),两者互相限制。
const rwmutexMaxReaders = 1 << 30
func (rw *RWMutex) Lock() {// First, resolve competition with other writers.// 写锁也就是互斥锁,复用互斥锁的能力来解决与其他写锁的竞争// 如果写锁已经被获取了,其他goroutine在获取写锁时会进入自旋或者休眠rw.w.Lock()// 将readerCount设置为负值,告诉读锁现在有一个正在等待运行的写锁(获取互斥锁成功)r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders// 获取互斥锁成功并不代表goroutine获取写锁成功,我们默认最大有2^30的读操作数目,减去这个最大数目// 后仍然不为0则表示前面还有读锁,需要等待读锁释放并更新写操作被阻塞时等待的读操作goroutine个数;if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {runtime_SemacquireMutex(&rw.writerSem, false, 0)}
}
func (rw *RWMutex) Unlock() {// Announce to readers there is no active writer.// 将readerCount的恢复为正数,也就是解除对读锁的互斥r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)if r >= rwmutexMaxReaders {race.Enable()throw("sync: Unlock of unlocked RWMutex")}// 如果后面还有读操作的goroutine则需要唤醒他们for i := 0; i < int(r); i++ {runtime_Semrelease(&rw.readerSem, false, 0)}// 释放互斥锁,写操作的goroutine和读操作的goroutine同时竞争rw.w.Unlock()
}
读锁
func (rw *RWMutex) RLock() {// 原子操作readerCount 只要值不是负数就表示获取读锁成功if atomic.AddInt32(&rw.readerCount, 1) < 0 {// 有一个正在等待的写锁,为了避免饥饿后面进来的读锁进行阻塞等待runtime_SemacquireMutex(&rw.readerSem, false, 0)}
}func (rw *RWMutex) RUnlock() {// 将readerCount的值减1,如果值等于等于0直接退出即可;否则进入rUnlockSlow处理if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {// Outlined slow-path to allow the fast-path to be inlinedrw.rUnlockSlow(r)}
}
其他共享内存线程安全的方式
官方不太推荐使用锁,更多的是通过channel做数据交换
思考
如何设计一个并发更高的锁?
在Go语言中,使用切片来设计并发更高效的锁是一种常见的做法,通常被称为"分段锁"或"分片锁"。
这种技术可以在一定程度上减小锁的粒度,从而提高并发性能。
package mainimport ("fmt""sync""hash/fnv"
)const numSegments = 16type ConcurrentMap struct {segments []sync.Mutexdata map[interface{}]interface{}
}func NewConcurrentMap() *ConcurrentMap {segments := make([]sync.Mutex, numSegments)data := make(map[interface{}]interface{})return &ConcurrentMap{segments: segments, data: data}
}func (cm *ConcurrentMap) getSegment(key interface{}) *sync.Mutex {hash := hashFunction(key) % numSegmentsreturn &cm.segments[hash]
}func (cm *ConcurrentMap) Get(key interface{}) interface{} {segment := cm.getSegment(key)segment.Lock()defer segment.Unlock()return cm.data[key]
}func (cm *ConcurrentMap) Set(key, value interface{}) {segment := cm.getSegment(key)segment.Lock()defer segment.Unlock()cm.data[key] = value
}// 假设的哈希函数,仅用于示例目的
func hashFunction(key interface{}) int {h := fnv.New32a()// 将键的字节表示写入哈希函数_, _ = h.Write([]byte(fmt.Sprintf("%v", key)))return int(h.Sum32())
}func main() {concurrentMap := NewConcurrentMap()var wg sync.WaitGroupnumItems := 1000for i := 0; i < numItems; i++ {wg.Add(1)go func(index int) {defer wg.Done()key := fmt.Sprintf("key%d", index)concurrentMap.Set(key, index)}(i)}wg.Wait()// 输出结果for i := 0; i < numItems; i++ {key := fmt.Sprintf("key%d", i)fmt.Printf("%s: %v\n", key, concurrentMap.Get(key))}
}相关文章:
【Go】锁相关
文章目录 Mutex锁mutex源码分析LockUnLock mutex两种运行模式mutex normal 正常模式自旋 mutex starvation 饥饿模式 锁的底层实现类型 RWMutexRWMutex 实现其他共享内存线程安全的方式 思考如何设计一个并发更高的锁? Mutex锁 mutex源码分析 Locker接口ÿ…...
git环境超详细配置说明
一,简介 在git工具安装完成之后,需要设置一下常用的配置,如邮箱,缩写,以及git commit模板等等。本文就来详细介绍些各个配置如何操作,供参考。 二,配置步骤 2.1 查看当前git的配置 git conf…...

使用阿里云服务器搭建PostgreSQL主从架构图文流程
阿里云百科分享使用阿里云服务器搭建PostgreSQL主从架构图文流程,PostgreSQL被业界誉为最先进的开源数据库,支持NoSQL数据类型(JSON/XML/hstore)。本文档介绍在CentOS 7操作系统的ECS实例上搭建PostgreSQL主从架构的操作步骤。 目…...
Linux的基本权限(文件,目录)
文章目录 前言一、Linux权限的概念二、Linux权限管理 1.文件访问者分类2.文件类型和访问类型3.文件访问权限的相关设置方法三、目录的权限四、权限的总结 前言 Linux下一切皆文件,指令的本质就是可执行文件,直接安装到了系统的某种路径下 一、Linux权限的…...
: TCP重传、滑动窗口、流量控制、拥塞控制)
网络编程(12): TCP重传、滑动窗口、流量控制、拥塞控制
1、TCP重传机制 通过序列号和确认号确保可靠传输,当发送端发送数据给接收到,接收端会返回一个确认号,表示收到消息了 超时重传:没有在指定时间内收到ACK报文 超时重传的两种可能:数据包丢失、确认包丢失超时重传时间RT…...

Docker安装RabbitMQ服务端
使用docker安装RabbitMQ服务端 1、搜索镜像 docker search rabbitmq2、拉取镜像 默认拉取最后一个版本,可以在后面加版本号拉取指定版本 docker pull rabbitmq 3、运行镜像 docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 rabbitmq4、查看…...
vueuse常用方法
useDateFormat 时间格式化 <script setup lang"ts">import { useNow, useDateFormat } from vueuse/coreconst formatted useDateFormat(useNow(), YYYY-MM-DD HH:mm:ss)</script><template><div>{{ formatted }}</div> </templa…...
选择大型语言模型自定义技术
推荐:使用 NSDT场景编辑器 助你快速搭建可二次编辑器的3D应用场景 企业需要自定义模型来根据其特定用例和领域知识定制语言处理功能。自定义LLM使企业能够在特定的行业或组织环境中更高效,更准确地生成和理解文本。 自定义模型使企业能够创建符合其品牌…...

算法概述-Java常用算法
算法概述-Java常用算法 1、算法概念2、算法相关概念3、算法的性能评价4、算法应用归纳 1、算法概念 广泛算法定义:算法是模型分析的一组可行性的、确定的和有穷的规则。 经典算法特征:有穷性、确切性、输入、输出和可行性。 常用的算法包括递推、递归、穷…...
CCLINK转MODBUS-TCP网关cclink通讯接线图 终端电阻
大家好,今天我们要聊的是生产管理系统中的CCLINK和MODBUS-TCP协议,它们的不同使得数据互通比较困难,但捷米JM-CCLK-TCP网关的出现改变了这一切。 1捷米JM-CCLK-TCP是一款自主研发的CCLINK从站功能的通讯网关,它的主要功能是将各种…...

香蕉派 BPI-P2 Pro采用RK3308芯片,512M内存,8G存储,支持PoE供电
Banana Pi BPI-P2 pro(Armsom pro)是一款基于瑞芯瑞(Rockchip) RK3308B-S芯片的开发板。采用高性能4核ARM Cortex-A35处理器,512M RAM内存。和8G eMMC板载存储,支持PoE网线供电功能。芯片具有丰富的接口,如I2S、PCM、TDM、I2C、UART、SPDIF、…...
「隐语小课」拆分学习之“水平拆分学习”
一、引言 拆分学习是 2018 年由 MIT 最先提出的分布式算法。本文结合该领域的相关英文文献,介绍水平拆分学习的基本方法,同时还将对比拆分模型与中心化模型、联邦模型在不同条件下模型效率和准确性。拆分学习作为主流的隐私计算学习范式之一,…...

WPF--关于Action事件小结
WPF--关于Action事件小结 1.需要类实例去调用事件建立订阅关系 public event Action<int, object> MaintainEvent; new GP1().MaintainEvent NormalCmdAction; 2.static用处--在不便实例的时候,可以直接由类调用 public static event Action<int, objec…...
创建一个 React+Typescript 项目
接下来 我们来一起探索一下用TypeScript 来编写react 这也是一个非常好的趋势,目前也非常多人使用 那么 我们就先从创建项目开始 首先 我们先找一个 或者 之前创建一个目录 用来放我们的项目 然后 在这个目录下直接输入 例如 这里 我想创建一个叫 tsReApp 的项目…...
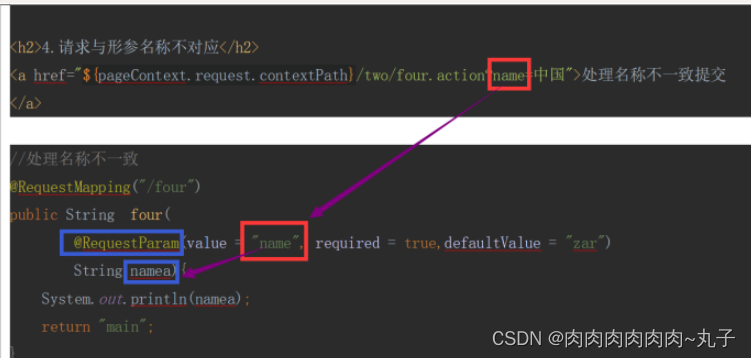
Java课题笔记~ 数据提交的方式
前四种数据注入的方式,会自动进行类型转换。但无法自动转换日期类型。 (1)单个数据(基本数据类型)注入 在方法中声明一个和表单提交的参数名称相同的参数,由框架按照名称直接注入。 (2&#x…...

VUE3给页面添加按钮事件
在Vue 3中,可以通过使用setup函数来添加事件和自定义逻辑。下面是一个示例代码,演示了如何添加页面上的altb事件 <template><div><p>Press Alt B to trigger the event!</p></div> </template><script setup&g…...

基于centos7.9通过nginx实现负载均衡以及反向代理
摘要:负载均衡: 负载均衡是一种技术,用于在多个服务器之间分发传入的网络流量,以平衡服务器的负载,提高系统的可用性和性能。当您有多台服务器时,您可以使用负载均衡将请求分发到这些服务器上,从…...

前端原生写自定义旋转变换轮播图
html部分: <div class"banner_box"><div class"swiperWrapper" v-show"bannerList.length>0"><div class"swiper-item" :id"swiperSlide${index}" :class"{active:index0,next:index1,pr…...

linux tomcat server.xml 项目访问路径变更不生效
如果想改成默认的127.0.0.1:8080 访问项目 先确定更改的作用文件 server.xml 的 host:appBase 标签 默认找到appBase webapps 下的war包,并解压,解压后的appname为访问路径 也就变成了 127.0.0.1:8080/appname host:Context:path 标签 appBase的 优先…...

介绍原型模式:快速构建和复制对象的设计模式
经过瀑布模式之后,我们不禁想要用模型解决更多的问题,最重要的就是不再单向行径。 由此,介绍 原型模式, 所谓原型,就是我们有一个框架或者初始角色。我们可以根据项目的不同,对它进行不同的修改࿰…...
+empty_cache显存防泄漏实践)
Z-Image-Turbo-rinaiqiao-huiyewunv开发者教程:gc.collect()+empty_cache显存防泄漏实践
Z-Image-Turbo-rinaiqiao-huiyewunv开发者教程:gc.collect()empty_cache显存防泄漏实践 1. 项目概述 Z-Image Turbo (辉夜大小姐-日奈娇)是基于Tongyi-MAI Z-Image底座模型开发的专属二次元人物绘图工具。该工具通过注入辉夜大小姐(日奈娇)微调safetensors权重&am…...

LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗
LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗 1. 当爬虫遇上大模型:数据采集的新思路 传统爬虫开发就像在迷宫里摸索前行——你需要手动解析每个网站的HTML结构,针对不同反爬机制编写特定规则,还要处理杂乱…...
)
Unity3D集成百度语音识别与唤醒功能实战指南(Android平台)
1. 为什么选择百度语音SDK? 在Unity3D项目中实现语音交互功能时,百度语音识别与唤醒SDK是我测试过最稳定的解决方案之一。特别是在Android平台上,它的离线唤醒功能响应速度能控制在800毫秒内,识别准确率在安静环境下能达到95%以上…...

需求分析避坑指南:如何避免‘用户说要马实际要车’的经典陷阱?
需求分析避坑指南:如何避免‘用户说要马实际要车’的经典陷阱? 在软件开发领域,需求分析是项目成败的关键环节。据统计,约70%的项目失败源于需求不明确或理解偏差。当用户说"想要一匹更快的马"时,他们真正需…...

手机端能用嘎嘎降AI吗:移动端使用完整指南和注意事项
手机端能用嘎嘎降AI吗:移动端使用完整指南和注意事项 上周室友第一次用降AI工具,操作错了好几步,差点浪费机会。觉得有必要写一篇详细教程。 我用的是嘎嘎降AI(www.aigcleaner.com),4.8元一篇,…...

Outline完整指南:如何搭建高效团队知识库与协作文档系统
Outline完整指南:如何搭建高效团队知识库与协作文档系统 【免费下载链接】outline Outline 是一个基于 React 和 Node.js 打造的快速、协作式团队知识库。它可以让团队方便地存储和管理知识信息。你可以直接使用其托管版本,也可以自己运行或参与开发。源…...

如何借助Kilo Code提升开发效率:从入门到专家的资源指南
如何借助Kilo Code提升开发效率:从入门到专家的资源指南 【免费下载链接】kilocode Kilo Code (forked from Roo Code) gives you a whole dev team of AI agents in your code editor. 项目地址: https://gitcode.com/GitHub_Trending/ki/kilocode 开篇价值…...
)
Claude Code子代理开发手册:如何打造专属AI编程助手(含MCP服务器对接技巧)
Claude Code子代理开发手册:如何打造专属AI编程助手(含MCP服务器对接技巧) 在当今快节奏的软件开发环境中,团队开发者越来越需要能够适应特定工作流程的智能辅助工具。Claude Code作为新一代AI编程助手平台,其子代理(…...

深入解析ACS SPiiPlus运动控制器的托管接口设计与实现
1. ACS SPiiPlus运动控制器托管接口概述 在工业自动化领域,运动控制器的性能直接影响着设备的精度和效率。ACS SPiiPlus系列作为业内知名的高性能运动控制器,其托管接口设计一直是工程师们关注的焦点。这套接口本质上是一套软件中间层,它架起…...
3步掌握像素艺术精灵表生成:SD_PixelArt_SpriteSheet_Generator终极指南
3步掌握像素艺术精灵表生成:SD_PixelArt_SpriteSheet_Generator终极指南 【免费下载链接】SD_PixelArt_SpriteSheet_Generator 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/SD_PixelArt_SpriteSheet_Generator 你是否在为游戏开发中的角色动画…...