kafka的位移
文章目录
- 概要
- 消费位移
- __consumer_offsets主题
- 位移提交
概要
本文主要总结kafka的位移是如何管理的,在broker端如何通过命令行查看到位移信息,并从代码层面总结了位移的提交方式。
消费位移
对于 Kafka 中的分区而言,它的每条消息都有唯一offset ,用来表示消息在分区中对应位置;对于消费者来说,它也有 offset 的概念,消费者使用 offse 来表示消费到分区中某个消息所在的位置。可通过命令行在查看到一个群组,在topic中两者当前的位置
bin/kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group kafka-boot
[root@node1 kafka_2.13-3.2.1]# bin/kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group kafka-bootConsumer group 'kafka-boot' has no active members.GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
kafka-boot test-error-topic 0 26 26 0 - - -
kafka-boot normal-test 0 23 24 1 - - -这里对offse 做些区分 对于消息在分区中的位置 CURRENT-OFFSET称为“偏移量” 或消息位移;对于消费者消费到的位置,LOG-END-OFFSET称为“位移 ,有时候也会更明确地称之为“消费位移“。
生产者位移跟消费者位移的关系可以用下图来说明:
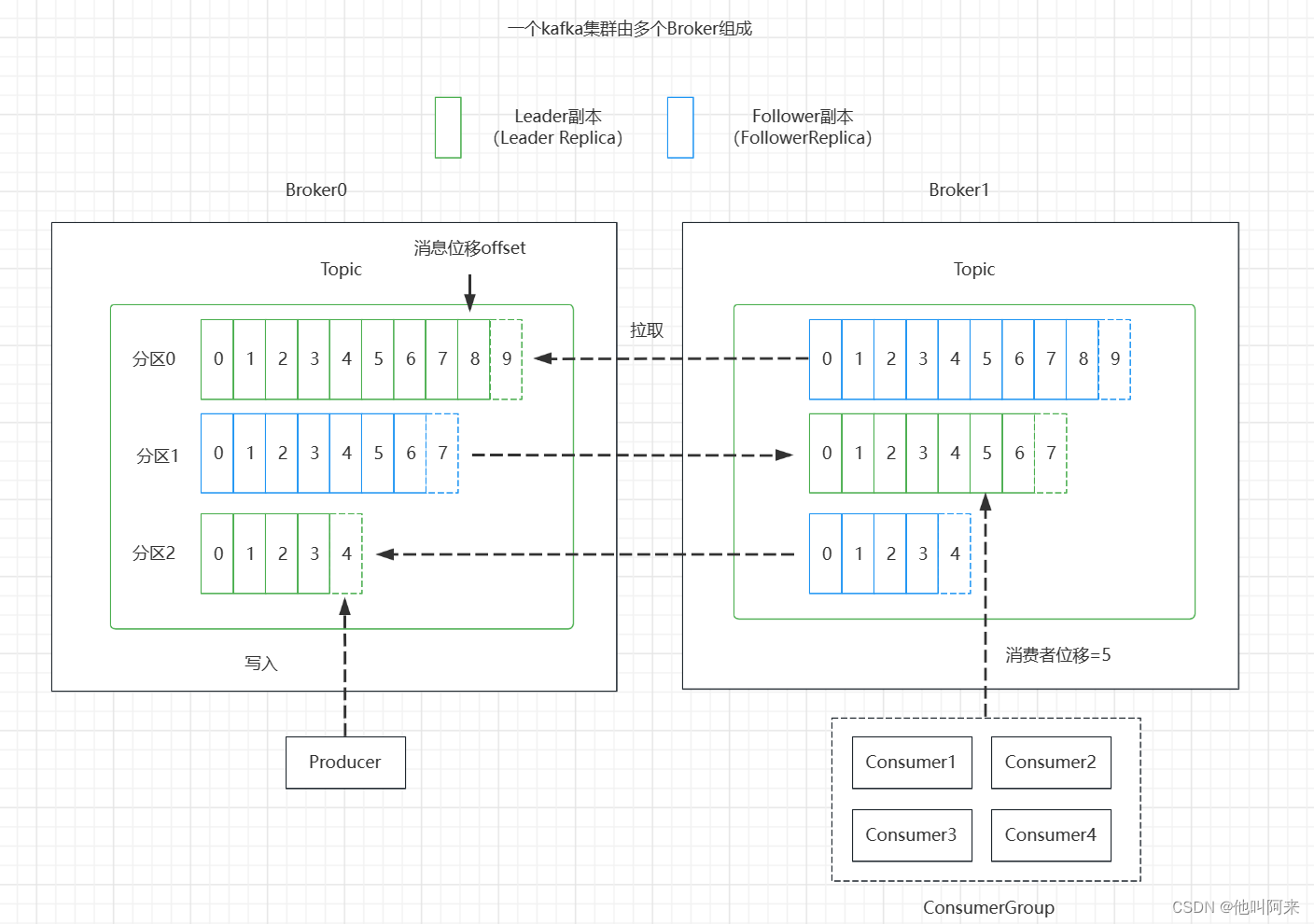
总结几个需要注意的点:
- 分区副本有两种类型
领导者副本:生产者跟消费者的请求都只会经过领导者副本;
跟随者副本:首领之外的副本,不处理客户端请求,从领导者副本那里通过拉取的方式同步消息 - 消费位移存储在Zookeeper或Kafka中,新消费者客户端,偏移量存储咋Kafka内部主题
__consumer_offsets - 消费者提交的位移是当前消费消息位移的下一个位置,即:lastConsumeedOffset+1
__consumer_offsets主题
Consumer需要向Kafka记录自己的位移数据,这个汇报过程称为提交位移(Committing Offsets)。
老版本 Consumer 的位移是提交到 ZooKeeper 中保存的。当 Consumer 重启后,它能自动从 ZooKeeper 中读取位移数据,从而在上次消费截止的地方继续消费。这种设计使得Kafka Broker 不需要保存位移数据,减少了 Broker 端需要持有的状态空间,因而有利于实现高伸缩性。
但是,ZooKeeper 其实并不适用于这种高频的写操作,Kafka 社区自 0.8.2.x 版本开始推出了全新的位移管理
机制,将 Consumer 的位移数据作为一条条普通的 Kafka 消息,提交到 __consumer_offsets 中。可以这么说,
__consumer_offsets 的主要作用是保存 Kafka 消费者的位移信息。这种方式能够满足高频的写操作。
两个相关参数:
offsets.topic.num.partitions : 设置 __consumer_offsets主题的分区数,默认是50个分区
offsets.topic.replication.factor : 设置__consumer_offsets主题的副本数,默认是3(下载安装的包中此值可能为1 )
当Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题
一共有50个分区,那么消费者将位移提交到了哪个分区呢?
通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区,这个分区leader对应的broker
就是这个consumer group的coordinator
公式:Math.abs(groupID.hashCode()) % numPartitions
Kafka 1.0.2及以后提供了kafka_consumer_groups.sh脚本供用户查看consumer信息
1. 创建一个topic,分区数设置为1,副本数设置为1
[root@node1 kafka_2.13-3.2.1]# bin/kafka-topics.sh --bootstrap-server node1:9092 --create --topic test-offset --partitions 1 --replication-factor 1
Created topic test-offset.[root@node1 kafka_2.13-3.2.1]# bin/kafka-topics.sh --bootstrap-server node1:9092 --describe --topic test-offset
Topic: test-offset TopicId: in6gxQ5OQS6x9R8V3oJ7AQ PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824Topic: test-offset Partition: 0 Leader: 0 Replicas: 0 Isr: 0
2. 向主题test-offset中发送消息
[root@node1 kafka_2.13-3.2.1]# bin/kafka-console-producer.sh --broker-list node1:9092 --topic test-offset
>hello
3. 创建一个消费组,并从头开始消费
[root@node1 kafka_2.13-3.2.1]# bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --from-beginning --consumer-property group.id=testOffsetGroup --topic test-offset
hello
4. 用代码根据上面的公式计算消费组testOffsetGroup提交位移的分区数
@Test
void getCommitOffsetPartitionTest() {String groupId = "testOffsetGroup";// 运行结果为16System.out.println(Math.abs(groupId.hashCode() % 50));
}
- 将kafka配置文件consumer.properties中设置exclude.internal.topics=false,并重启服务
6. 查看主题__consumer_offsets第16分区上的信息,可以看到消费组testOffsetGroup提交的位移确实保存在了16分区上
[root@node1 kafka_2.13-3.2.1]# bin/kafka-console-consumer.sh --topic __consumer_offsets --partition 16 --bootstrap-server node1:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896116191, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896121189, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896126188, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896131188, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896133573, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896162124, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896167124, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896172123, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896177124, expireTimestamp=None)
[testOffsetGroup,test-offset,0]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1691896178781, expireTimestamp=None)从上面也可看出__consumer_offsets topic的每一日志项的格式都是:
[Group, Topic, Partition]::[OffsetMetadata[Offset, Metadata], CommitTime, ExpirationTime]
客户端提交消费位移是使用OffsetCommitRequest 请求实现的,其结构如下
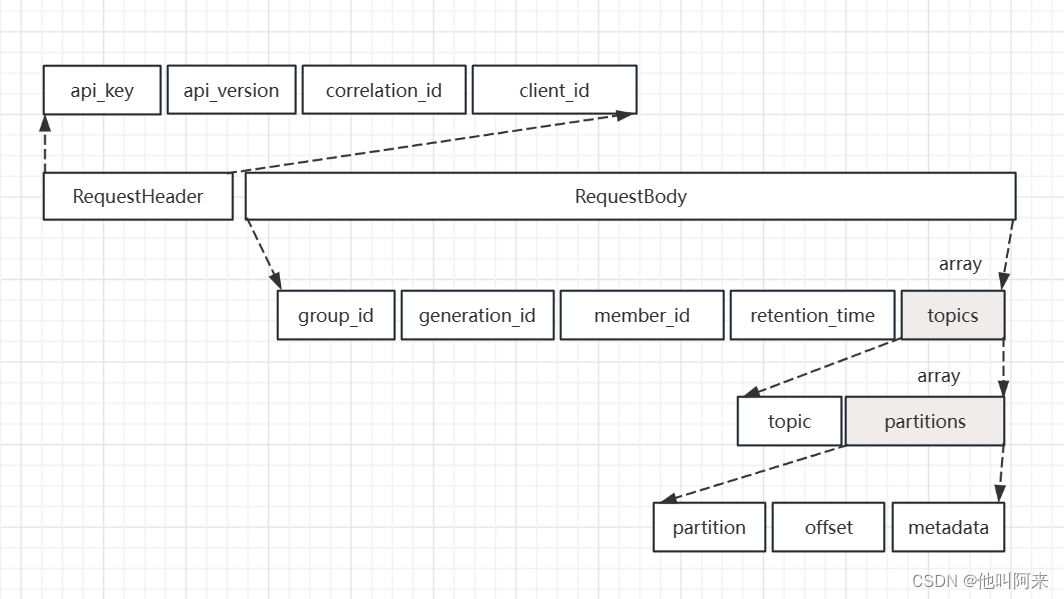
__consumer_offsets这个主题中的消息格式为KV对,key为[Group, Topic, Partition],value可以简单理解为记录了偏移量;这样的记录方式,使得broker端不需要关系group下有多少个消费者,新增消费者或者减少消费者发生重平衡时,都能准确地定位到对应地分区应该从哪个位置开始消费。
位移提交
鉴于位移提交甚至是位移管理对 Consumer 端的巨大影响,Kafka,特别是KafkaConsumer API,提供了多种提交位移的方法。从用户的角度来说,位移提交分为自动提交和手动提交;从 Consumer 端的角度来说,位移提交分为同步提交和异步提交。
自动提交
自动提交,就是指 Kafka Consumer 在后台默默地为你提交位移
两个重要的参数
enable.auto.commit设置是否自动提交位移,默认是trueauto.commit.interval.ms:设置自动提交为true时,该参数生效,标识多久提交一次位移,默认5s,
public static void main(String[] args) {Map<String, Object> configs = new HashMap<>();configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, UserDeserializer.class);configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer1");configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "con1");// 设置偏移量自动提交。自动提交是默认值。这里做示例。configs.put("enable.auto.commit", "true");// 偏移量自动提交的时间间隔configs.put("auto.commit.interval.ms", "2000");KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(configs);consumer.subscribe(Collections.singleton("tp_demo_01"));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {System.out.println(record.topic()+ "\t" + record.partition()+ "\t" + record.offset()+ "\t" + record.key()+ "\t" + record.value());}}}设置了 enable.auto.commit 为 true,Kafka 会保证在开始调用 poll 方法时,提交上次 poll 返回的所有消息。从顺序上来说,poll 方法的逻辑是先提交上一批消息的位移,再处理下一批消息,因此它能保证不出现消费丢失的情况。但是会出现消息重复消费。
在默认情况下,Consumer 每 5 秒自动提交一次位移。现在,我们假设提交位移之后的 3秒发生了 Rebalance 操作。在 Rebalance 之后,所有 Consumer 从上一次提交的位移处继续消费,但该位移已经是 3 秒前的位移数据了,故在Rebalance 发生前 3 秒消费的所有数据都要重新再消费一次。虽然你能够通过减少 auto.commit.interval.ms 的值来提高提交频率,但这么做只能缩小重复消费的时间窗口,不可能完全消除它。这是自动提交机制的一个缺陷。
手动同步提交
开启手动提交位移的方法就是设置enable.auto.commit 为 false。但是,仅仅设置它为 false 还不够,因为你只是告诉
Kafka Consumer 不要自动提交位移而已,你还需要调用相应的 API 手动提交位移。
public static void main(String[] args) {Map<String, Object> configs = new HashMap<>();configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, UserDeserializer.class);configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer1");configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "con1");configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(configs);consumer.subscribe(Collections.singleton("tp_demo_01"));while (true) {ConsumerRecords<String, String> records =consumer.poll(Duration.ofSeconds(1));process(records); // 处理消息try {consumer.commitSync();} catch (CommitFailedException e) {handle(e); // 处理提交失败异常}}
}
调用 commitSync() 时,Consumer 程序会处于阻塞状态,直到远端的 Broker 返回提交结果,这个状态才会结束,这样就会影响TPS。
鉴于此问题,还有另外一个提交方式
手动异步提交
public static void main(String[] args) {Map<String, Object> configs = new HashMap<>();configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, UserDeserializer.class);configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer1");configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "con1");configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(configs);while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));process(records); // 处理消息consumer.commitAsync((offsets, exception) -> {if (exception != null) {handle(exception);}});}
}
commitAsync 是否能够替代 commitSync 呢?答案是不能。commitAsync 的问题在于,出现问题时它不会自动重试。因为它是异步操作,倘若提交失败后自动重试,那么它重试时提交的位移值可能早已经“过期”或不是最新值了。因此,异步提交的重试其实没有意义,所以 commitAsync 是不会重试的。
是手动提交,需要将 commitSync 和 commitAsync 组合使用才能到达最理想的效果,原因有两个:
- 利用 commitSync 的自动重试来规避那些瞬时错误,比如网络的瞬时抖动,Broker 端 GC 等。这些问题都是短暂的,自动重试通常都会成功。
- 不希望程序总处于阻塞状态,影响 TPS。
public static void main(String[] args) {Map<String, Object> configs = new HashMap<>();configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092");configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, UserDeserializer.class);configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer1");configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");configs.put(ConsumerConfig.CLIENT_ID_CONFIG, "con1");configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(configs);consumer.subscribe(Collections.singleton("tp_demo_01"));try {while (true) {ConsumerRecords<String, String> records =consumer.poll(Duration.ofSeconds(1));consumer.commitAsync();process(records); // 处理消息consumer.commitAsync(); // 异步提交}} catch (Exception e) {handle(e); // 处理异常} finally {try {consumer.commitSync();// 最后一次提交使用同步阻塞式提交} finally {consumer.close();}}
}
相关文章:
kafka的位移
文章目录 概要消费位移__consumer_offsets主题位移提交 概要 本文主要总结kafka的位移是如何管理的,在broker端如何通过命令行查看到位移信息,并从代码层面总结了位移的提交方式。 消费位移 对于 Kafka 中的分区而言,它的每条消息都有唯一…...

大数据平台运维实训室建设方案
一、概况 本实训室的主要目的是培养大数据平台运维项目的实践能力,以数据计算、分析、挖掘和可视化的案例训练为辅助。同时,实训室也承担相关考评员与讲师培训考试、学生认证培训考试、社会人员认证培训考试、大数据技能大赛训练、大数据专业课程改革等多项任务。 实训室旨在培…...

dll调用nodejs的回调函数
nodejs使用ffi调用dll。dll中有回调函数调用js中的方法。 c语言中cdll.h文件 extern "C" {typedef void(*JsCall)(int index); //这个就是要传入的类型结构extern __declspec(dllimport) int Add(int a, int b);extern __declspec(dllexport) void CallBackTest(Js…...
网络安全--linux下Nginx安装以及docker验证标签漏洞
目录 一、Nginx安装 二、docker验证标签漏洞 一、Nginx安装 1.首先创建Nginx的目录并进入: mkdir /soft && mkdir /soft/nginx/cd /soft/nginx/ 2.下载Nginx的安装包,可以通过FTP工具上传离线环境包,也可通过wget命令在线获取安装包…...

多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测
多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现WOA-CNN-BiGRU-Attention多变量时间序列预测 1.程…...
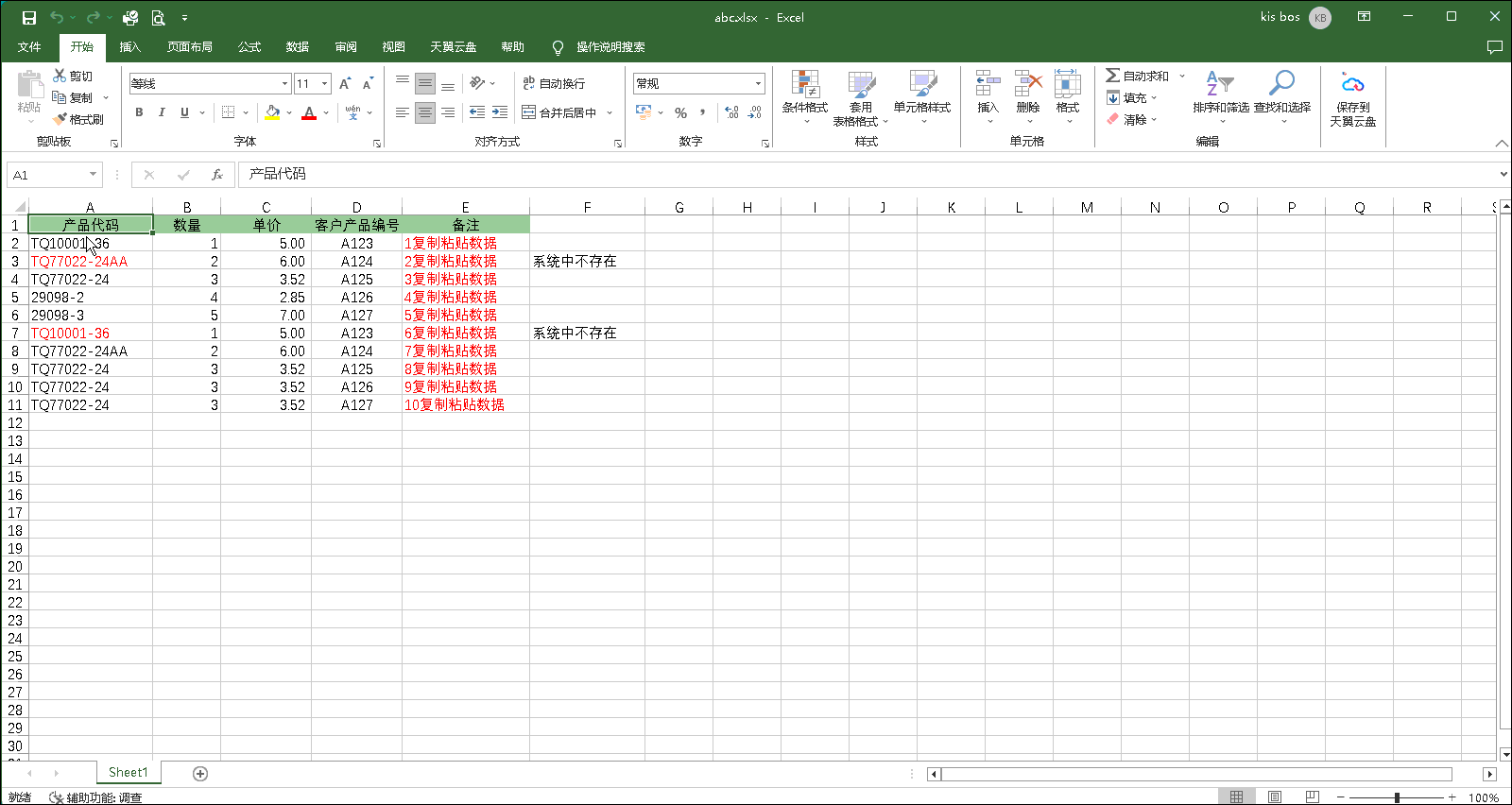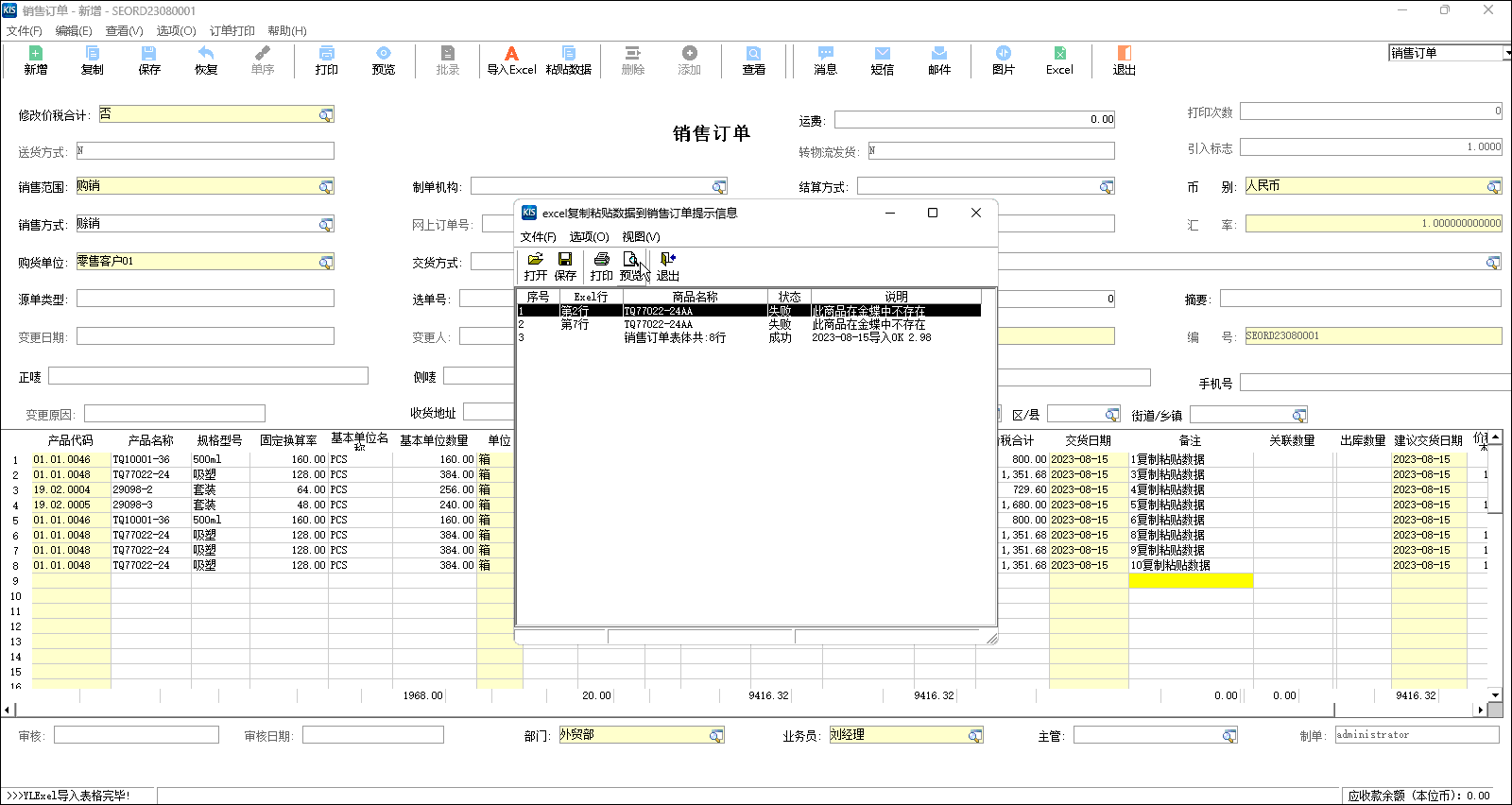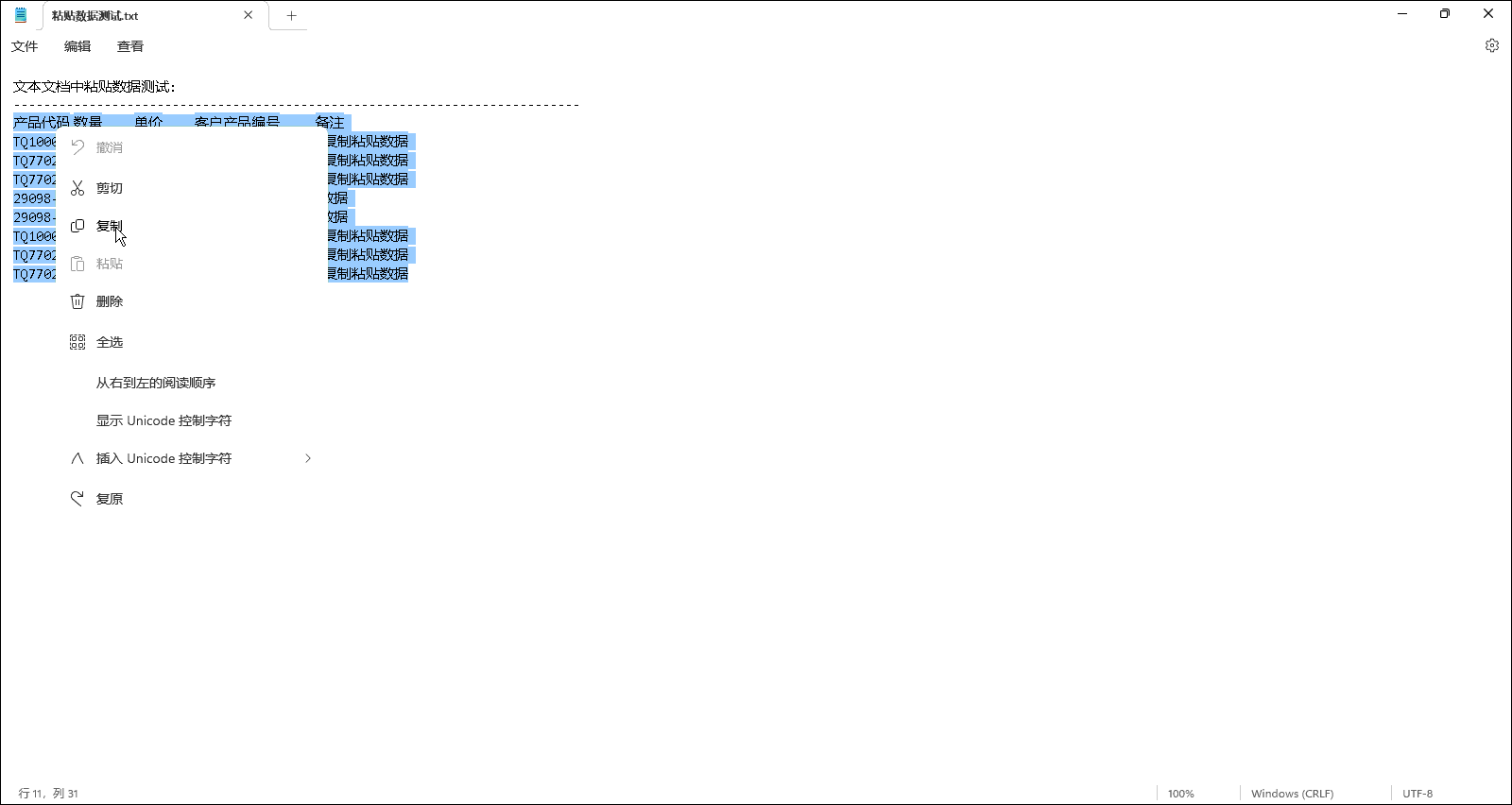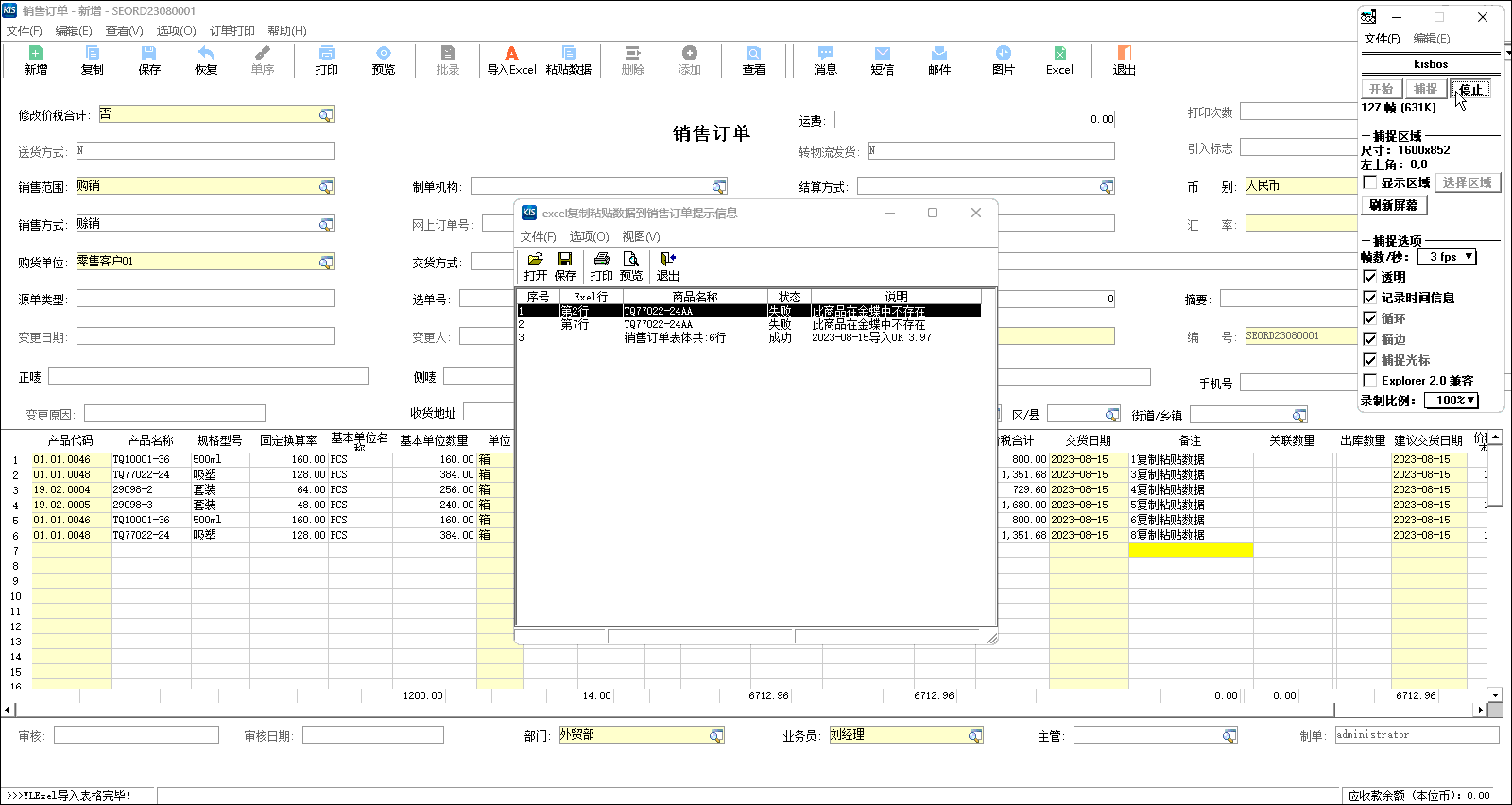
金蝶软件实现Excel数据复制分录信息粘贴到单据体分录行中
>>>适合KIS云专业版V16.0|KIS云旗舰版V7.0|K/3 WISE 14.0等版本<<< 实现Excel数据复制分录信息粘贴到金蝶单据体分录中,在采购订单|采购入库单|销售订单|销售出库单等类型单据中,以少量的必要字段在excel表格中按模板填列好,很方便快捷地复制到金蝶单据表体…...
【Linux操作系统】深入探索Linux进程:创建、共享与管理
进程的创建是Linux系统编程中的重要概念之一。在本节中,我们将介绍进程的创建、获取进程ID和父进程ID、进程共享、exec函数族、wait和waitpid等相关内容。 文章目录 1. 进程的创建1.1 函数原型和返回值1.2 函数示例 2. 获取进程ID和父进程ID2.1 函数原型和返回值2.…...
【云原生、k8s】Calico网络策略
第四阶段 时 间:2023年8月17日 参加人:全班人员 内 容: Calico网络策略 目录 一、前提配置 二、Calico网络策略基础 1、创建服务 2、启用网络隔离 3、测试网络隔离 4、允许通过网络策略进行访问 三、Calico网络策略进阶 1、创…...

Unity3D 测试总结
windows 平台上导出 exe 文件 在Unity界面中,点击菜单栏的“File”,选择“Build Settings”。 在“Build Settings”窗口中,选择要生成的平台(例如Windows)。 点击“Player Settings”按钮,进入“Player Se…...
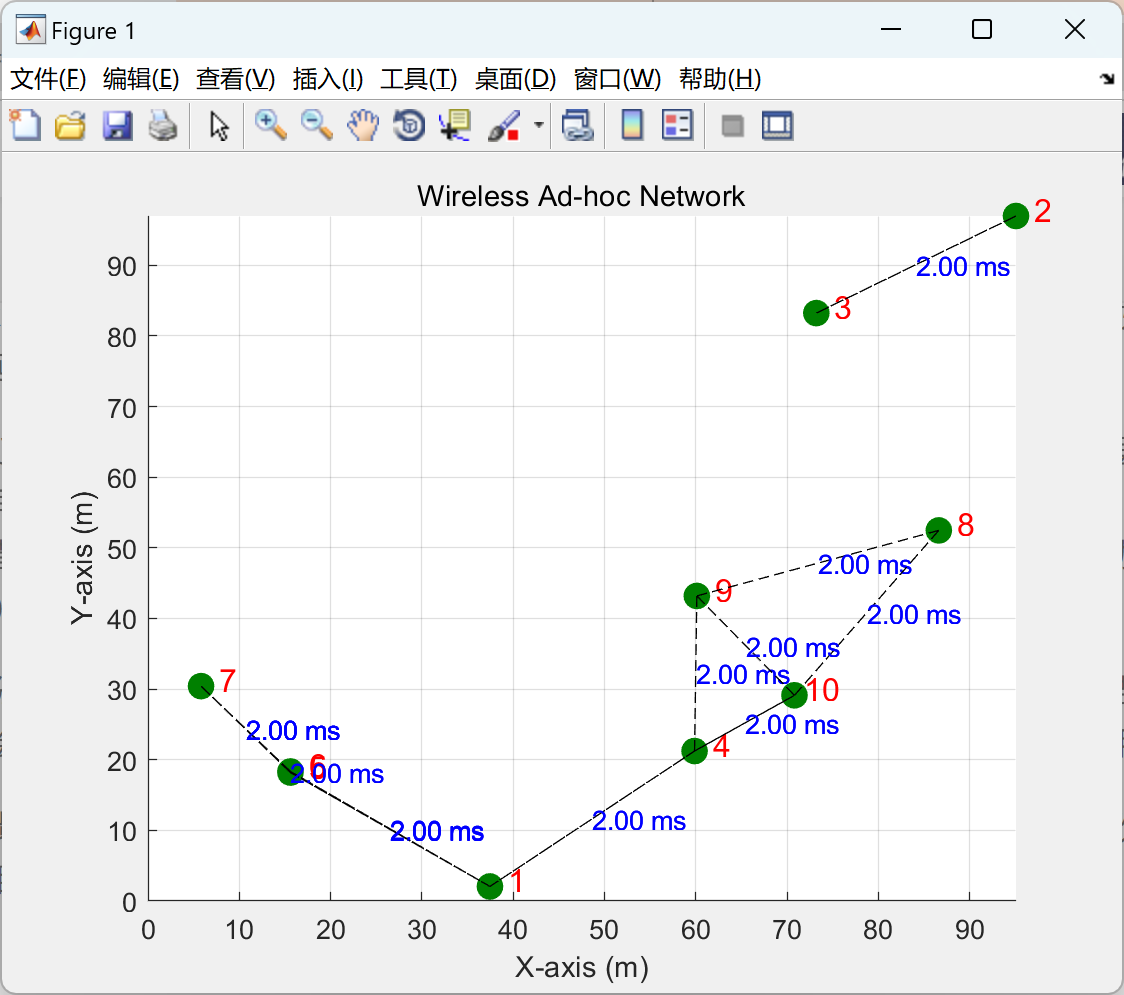
【无线点对点网络时延分析和可视化】模拟无线点对点网络中的延迟以及物理层和数据链路层之间的相互作用(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
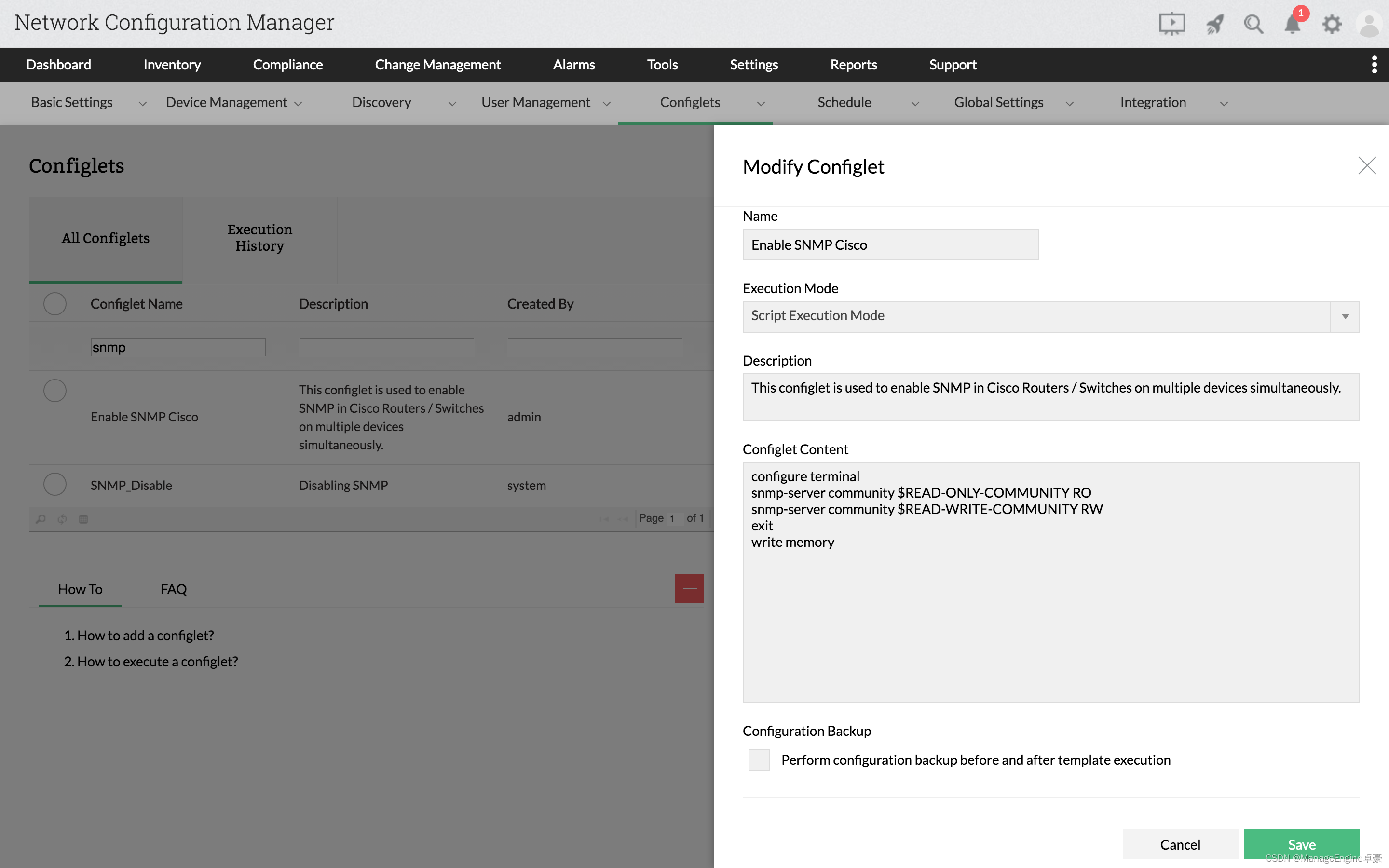
在思科(Cisco)路由器中使用 SNMP
什么是SNMP SNMP,称为简单网络管理协议,被发现可以解决具有复杂网络设备的复杂网络环境,SNMP 使用标准化协议来查询网络上的设备,为网络管理员提供保持网络环境稳定和远离停机所需的重要信息。 为什么要在思科设备中启用SNMP S…...

【压测】wg/wrk 轻量级压测
wg/wrk 轻量级压测 说明:环境是 centos,不过现在 centos 免费版本不再更新和维护了,所以大家可以用阿里云的或者用 ubuntu 内核 用的 https://github.com/wg/wrk.git 有 35k star 然后据我了解,windows 用 wrk 压测有点麻烦&…...

Redis可以用作消息队列吗?如何实现简单的消息队列功能?
是的,Redis可以被用作简单的消息队列。下面是一种实现简单消息队列功能的方式: 生产者(Producer)端: 使用LPUSH命令将消息推送到一个列表中,作为消息队列的实现。例如,使用LPUSH命令将消息推送到…...

[Java基础]对象转型
系列文章目录 【Java基础】Java总览_小王师傅66的博客-CSDN博客 [Java基础]基本概念(上)(标识符,关键字,基本数据类型)_小王师傅66的博客-CSDN博客 [Java基础]基本概念(下)运算符,表达式和语句,分支,循环,方法,变量的作用域,递归调用_小王师傅66的博客-CSDN博客 Java字节码…...

JVM——类文件结构
文章目录 一 概述二 Class 文件结构总结2.1 魔数2.2 Class 文件版本2.3 常量池2.4 访问标志2.5 当前类索引,父类索引与接口索引集合2.6 字段表集合2.7 方法表集合2.8 属性表集合 一 概述 在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class …...
银河麒麟服务器v10 sp1 .Net6.0 上传文件错误
上一篇:银河麒麟服务器v10 sp1 部署.Net6.0 http https_csdn_aspnet的博客-CSDN博客 .NET 6之前,在Linux服务器上安装 libgdiplus 即可解决,libgdiplus是System.Drawing.Common原生端跨平台实现的主要提供者,是开源mono项目。地址…...

C#实现普通的语音播报
Windows有文字转语音功能,C#提供了调用的类库Interop.SpeechLib.dll 使用方法很简单,在你的项目中添加Interop.SpeechLib.dll引用,在类中引用: using SpeechLib;这里提供一个CVoice类 帮助实现语音播报 public class CVoice{pri…...

django中实现事务的几种方式
1.实现事务的三种方式 1.1 全局开启事务---> 全局开启事务,绑定的是http请求响应整个过程 DATABASES {default: {#全局开启事务,绑定的是http请求响应整个过程ATOMIC_REQUESTS: True, }} from django.db import transaction# 局部禁用事务 transac…...

【es6】具名组匹配
1、组匹配 正则表达式使用圆括号进行组匹配,如:const RE_DATE /(\d{4})-(\d{2})-(\d{2})/;,三个圆括号形成了三个组匹配。 代码: const RE_DATE /(\d{4})-(\d{2})-(\d{2})/;const matchObj RE_DATE.exec(1999-12-31); const year matchO…...
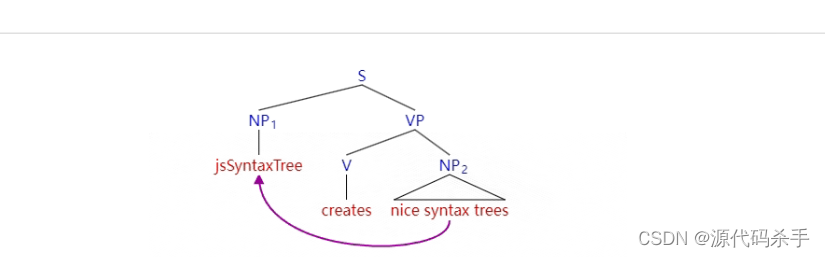
自然语言处理技术:NLP句法解析树与可视化方法
自然语言处理(Natural Language Processing,NLP)句法解析树是一种表示自然语言句子结构的图形化方式。它帮助将句子中的每个词汇和短语按照语法规则连接起来,形成一个树状结构,以便更好地理解句子的语法结构和含义。句法解析树对于理解句子的句法关系、依存关系以及语义角…...

gitru:一个由 Rust 打造的零依赖 Git 提交信息校验工具
gitru 基于 Git 的 commit-msg Hook 实现,用于在提交阶段自动校验提交信息格式。 在团队协作开发中,规范的 Git 提交信息是代码追溯、版本管理、自动生成变更日志的基础。 但现实往往是: 人工约束容易遗漏手动配置 Hook 繁琐提交信息格式随心…...

解决B站视频收藏难题的8K超清下载解决方案:Bilidown全解析
解决B站视频收藏难题的8K超清下载解决方案:Bilidown全解析 【免费下载链接】bilidown 哔哩哔哩视频解析下载工具,支持 8K 视频、Hi-Res 音频、杜比视界下载、批量解析,可扫码登录,常驻托盘。 项目地址: https://gitcode.com/gh_…...

Python实战:M3FD红外数据集高效转YOLO格式的完整指南
1. 为什么需要转换M3FD数据集格式 红外目标检测在夜间安防、自动驾驶等领域越来越重要,而M3FD作为优质的红外数据集却采用了VOC格式标注。这就像你买了台进口电器,却发现插头不匹配国内插座——虽然东西是好东西,但直接使用会遇到麻烦。 YO…...

特斯拉行车记录仪视频合并神器:告别碎片化,一键生成完整记录
特斯拉行车记录仪视频合并神器:告别碎片化,一键生成完整记录 【免费下载链接】tesla_dashcam Convert Tesla dash cam movie files into one movie 项目地址: https://gitcode.com/gh_mirrors/te/tesla_dashcam 还在为特斯拉行车记录仪生成的海量…...

Aurix TC275实战:手把手教你配置.lsl链接文件,搞定多核Trap向量表
Aurix TC275多核开发实战:深度解析.lsl链接文件与Trap向量表配置 在Aurix TC275多核MCU开发中,.lsl链接文件的配置往往是工程师面临的最大挑战之一。不同于传统单核MCU的简单内存布局,多核系统需要精确控制每个核心的代码和数据位置ÿ…...

VDisk技术详解:原理、应用与优化实践指南
VDisk技术详解:原理、应用与优化实践指南传统的桌面运维管理面临效率和成本控制的双重挑战,例如操作系统和应用部署繁琐、维护更新困难、资源利用率低等。VDisk(虚拟磁盘)技术通过将操作系统、应用程序和用户数据集中存储在服务器…...

构建高性能语音识别API:FastAPI与Whisper实战指南 [特殊字符]
构建高性能语音识别API:FastAPI与Whisper实战指南 🚀 【免费下载链接】awesome-fastapi A curated list of awesome things related to FastAPI 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-fastapi 在当今人工智能和语音技术飞速发展的…...

如何解决教育资源获取难题?国家中小学智慧教育平台电子课本下载工具来帮忙
如何解决教育资源获取难题?国家中小学智慧教育平台电子课本下载工具来帮忙 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具 项目地址: https://gitcode.com/GitHub_Trending/tc/tchMaterial-parser 在数字化教育日益普及的今天…...

OpenClaw人人养虾:网络模型
Gateway 支持多种网络拓扑(Network Topology),从纯本地到跨互联网远程访问。本文档介绍各种连接架构及其配置。 网络拓扑概览 ┌─────────────────────────────────────────────┐ │ …...

文墨共鸣模型作为Claude Code的替代或补充:代码生成与解释能力对比
文墨共鸣模型作为Claude Code的替代或补充:代码生成与解释能力对比 最近和几个做开发的朋友聊天,大家不约而同地提到了一个话题:现在AI写代码的工具这么多,到底哪个更靠谱?有人习惯用GitHub Copilot,有人偏…...