ElasticSearch相关概念
文章目录
- 前提
- 倒排索引
- MySQL、ES的区别和关联
- IK分词器
- 索引库
- mapping属性
- 索引库的crud
- 文档的crud
- RestClient
- DSL
- 查询
- DSL 查询种类
- DSL query 基本语法
- 搜索结构处理
- 排序
- 分页
- 高亮
- RestClient
前提
开源的搜索引擎,从海量数据中快速找到需要的内容。(分词检索,类似百度查询、博客文章关键词搜索)
elasticsearch结合 Kibana、Logstas、Beats,也就是 elastic stack(简称ELK),广泛应用于日志分析、实时监控。
JDK兼容性:https://www.elastic.co/cn/support/matrix#matrix_jvm
操作系统兼容性:https://www.elastic.co/cn/support/matrix
自身兼容性:https://www.elastic.co/cn/support/matrix#matrix_compatibility
对于ES 8.1 及以上版本而言,支持 JDK 17、JDK 18
docker安装步骤(es、kibana、IK)
倒排索引
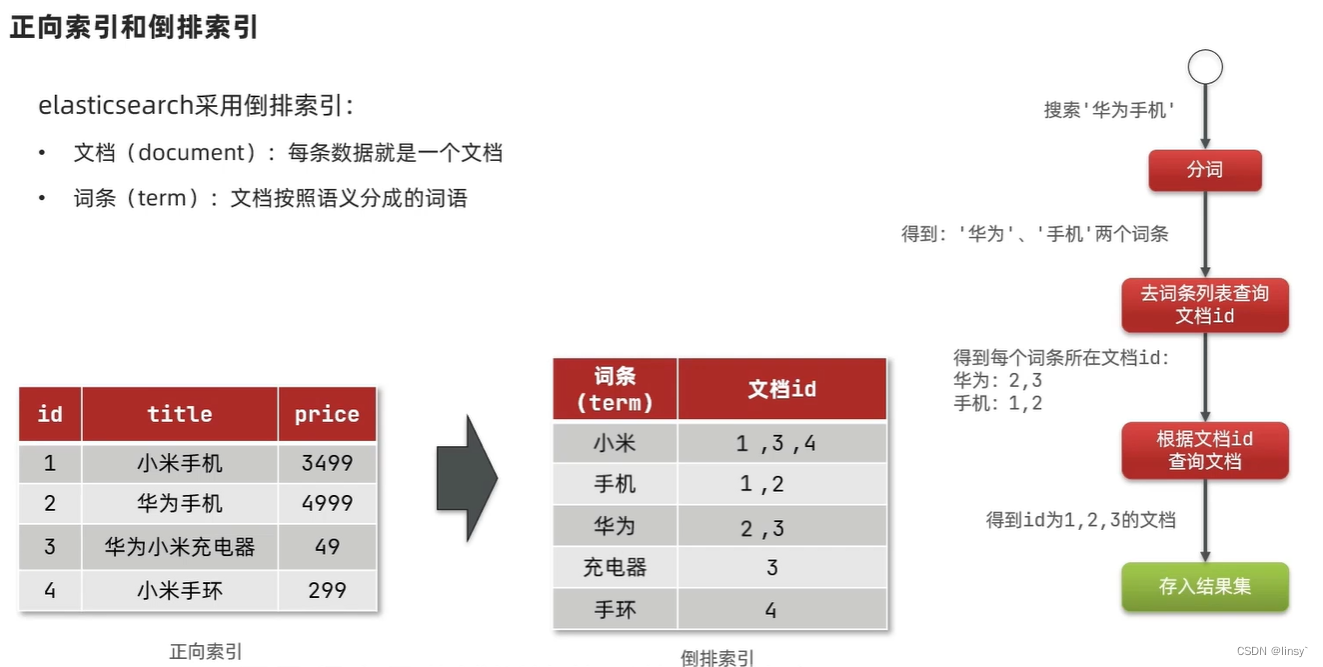
MySQL、ES的区别和关联
mysql擅长事务操作(ACID),确保数据安全和一致性
ES擅长海量数据搜索、分析、计算
文档
elasticsearch是面向文档存储的(JSON),每一条数据就是一个文档

索引
es中的索引是指相同类型的文档集合,即mysql中表的概念
映射:索引中文档字段的约束,比如名称、类型


IK分词器
作用:
- 在创建倒排索引时对文档进行分词
- 用户搜索时,对内容进行分词
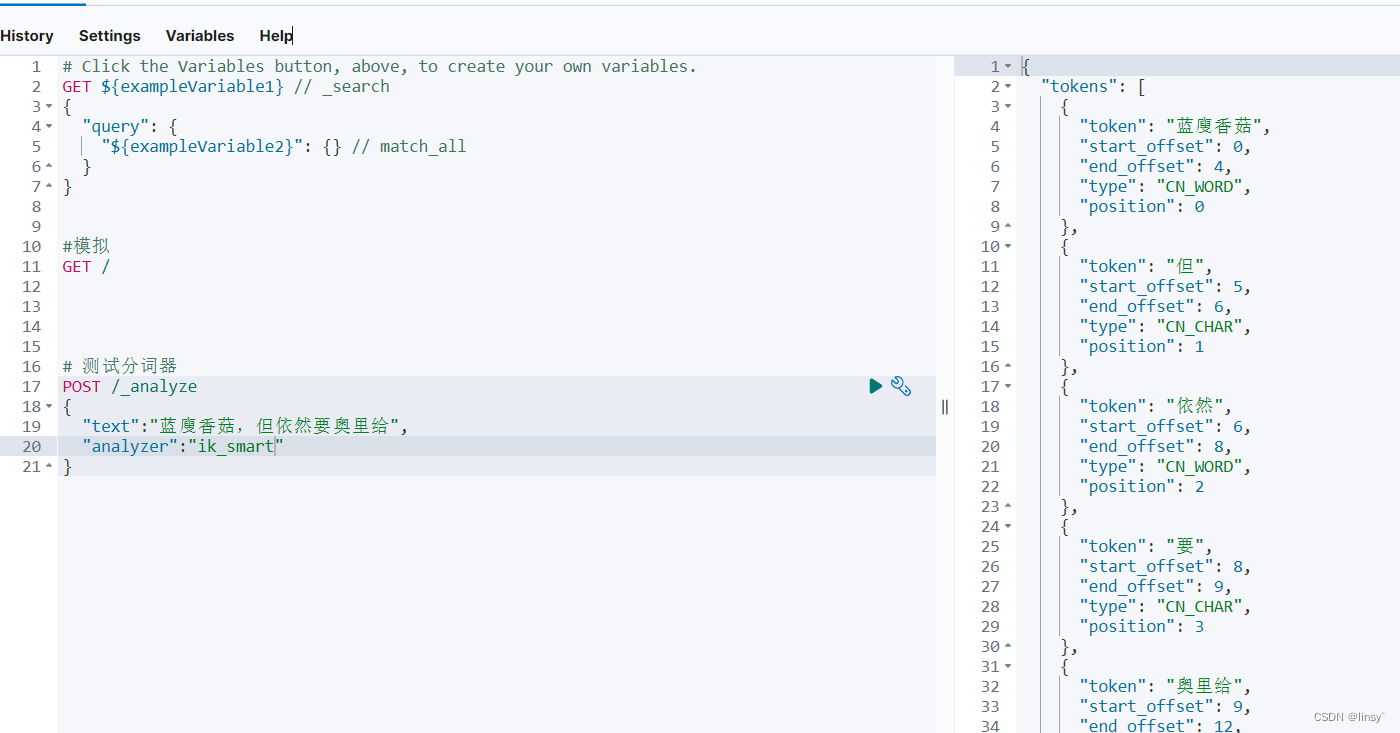
ik分词器的两种模式
POST /_analyze
{
“text”:“这是程序员的一次测试,包含English”,
“analyzer”:“ik_max_word”
}
ik_smart:最小切分(粗粒度),分出来的词不会再细分(程序员)
ik_max_word:最细切分(细粒度),分出来的词更多更细(程序员、程序)

拓展词条、停用词条
进入docker 创建的容器的插件目录,找到Ik分词器下的 IKAnalyzer.cfg.xml 文件,扩展词典在 中添加文件名称(例如ext.dic),停用词典在 中添加,(例如stopword.dic)。当然之后需要你手段创建词典文件,内容格式为一词一行。


索引库
mapping属性
mapping映射是对索引库中文档的约束。类似mysql对表单字段的约束
{"id":[1, 2, 3, 4, 5],"name":{"firstname":"明","lastname":"李"}
}
- type:字段数据类型,常见的类型有:
- 字符串:text(可分词的文本)、keyword(不可分词的文本,例如国家、品牌、IP地址)
- 布尔:boolean
- 日期:date
- 数值:long、short、byte、integer、double、float
- Object:对象
es里面没有数组类型,json格式key、value,允许value有多个值。上图id字段
- index:是否创建索引,默认为true。就是是否创建倒排索引,不创建之后就不能通过它搜索。
- analyzer:使用那种分词器
- properties:该字段的子字段,上面name
索引库的crud
# 建立索引库
PUT /linsy
{"mappings": {"properties": {"info": {"type": "text","analyzer": "ik_smart"},"email": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstname": {"type": "keyword"},"lastName": {"type": "keyword"}}}}}
}查询索引库 GET /索引库名 GET /linsy
删除索引库 DELETE /索引库名
ES 禁止修改索引库字段类型及属性,会影响整个索引的结构,但是允许在原有索引库中新增字段。
注意不能新增已有字段
PUT /索引库名/_mapping
{"properties": {"新字段名": {"type": "integer"}}
}
文档的crud
新增操作
POST /索引库名/_doc/文档id
{
“字段1”: "值1“,
“字段2”: “值2”,
“字段3”: “值3”,
}
查询 GET /索引库名/_doc/文档id
删除 DELETE /索引库名/_doc/文档id
# 文档操作
# 插入
POST /linsy/_doc/1
{"age": "11","email": "linsy@linsy.work","info": "this is a first test 文档","name": {"firstname": "明","lastName": "李"}
}GET /linsy/_doc/1DELETE /linsy/_doc/1POST /linsy/_update/1
{"doc":{"age":1111}
}
修改文档:
- 全量修改:删除旧文档,添加新文档。就是将上面新增的 DSL 改为 PUT
PUT /索引库名/_doc/文档id
{"字段1": "值1“,"字段2": "值2","字段3": "值3",
}
- 增量修改,修改指定字段
POST /索引库名/_update/文档id
{"doc":{"字段名":"新的值"}
}
RestClient
springboot 导入elasticsearch依赖需注意,它默认使用的版本和springboot的版本一致,你需要对应到安装在服务器上的版本。
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId></dependency>
<properties><java.version>8</java.version><elasticsearch.version>7.17.11</elasticsearch.version></properties>



创建索引库的mapping映射
PUT /hotel
{"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "ik_max_word","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
RestHighLevelClient 的使用

RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://http://192.168.52.150:9200")));// index的增删查CreateIndexRequest createIndexRequest = new CreateIndexRequest("linsy");createIndexRequest.source("建立索引库语句(put)", XContentType.JSON);restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);restHighLevelClient.indices().delete(new DeleteIndexRequest("要删除的索引库名"), RequestOptions.DEFAULT);// 判断是否存在boolean b = restHighLevelClient.indices().exists(new GetIndexRequest("索引库名"), RequestOptions.DEFAULT);
es8.x已经弃用了RestHighLevelClient
官方创建RestClient文档
文档的crud

查询文档


@Autowiredprivate IHotelService iHotelService;@BeforeEachpublic void before() {restHighLevelClient = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.52.150:9200")));}@AfterEachpublic void after() throws IOException {restHighLevelClient.close();}@Testpublic void addDocumentTest() throws IOException {Hotel hotel = iHotelService.getById(61075);HotelDoc hotelDoc = new HotelDoc(hotel);IndexRequest indexRequest = new IndexRequest("hotel").id(hotel.getId().toString());indexRequest.source(JSON.toJSONString(hotelDoc), XContentType.JSON);restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);}@Testpublic void queryDocumentTest() throws IOException {GetResponse getResponse = restHighLevelClient.get(new GetRequest("hotel", "61075"), RequestOptions.DEFAULT);String json = getResponse.getSourceAsString();System.out.println(json);}@Testpublic void updateDocumentTest() throws IOException {UpdateRequest updateRequest = new UpdateRequest("hotel", "61075");updateRequest.doc("city", "北京","score", "90");restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);}@Testpublic void deleteDocumentTest() throws IOException {restHighLevelClient.delete(new DeleteRequest("hotel", "61075"), RequestOptions.DEFAULT);}@Testpublic void batchAdd() throws IOException {BulkRequest bulkRequest = new BulkRequest();List<Hotel> list = iHotelService.list();for (Hotel hotel : list) {HotelDoc hotelDoc = new HotelDoc(hotel);bulkRequest.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(JSON.toJSONString(hotelDoc), XContentType.JSON));}restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);}DSL
查询
DSL 查询种类
- 查询所有:查询所有数据,一般在测试时使用。march_all,但是一般显示全部,有一个分页的功能
- 全文检索(full text)查询:利用分词器对用户的输入内容进行分词,然后去倒排索引库匹配。例如:
- match_query
- mutil_match_query
- 精确查询:根据精确词条值查询数据,一般查找的时keyword、数值、日期、boolean等字段。例如:
- ids
- term
- range
- 地理查询(geo):根据经纬度查询,例如:
- geo_distance
- geo_bounding_box
- 复合(compound)查询:复合查询时将上面各种查询条件组合在一起,合并查询条件。例如:
- bool
- funcation_score
DSL query 基本语法
# DSL查询
GET /indexName/_search
{"query":{"查询类型":{"查询条件":"条件值"}}
}
match 与 multi_match 的与别是前者根据单字段查,后者根据多字段查。
参与搜索的字段越多,查询效率越低,建议利用copy_to将多个检索字段放在一起,然后使用match—all字段查。
GET /hotel/_search
{"query": {"match": {"city": "上海"}}
}GET /hotel/_search
{"query": {"match": {"all": "如家"}}
}GET /hotel/_search{"query": {"multi_match": {"query": "如家","fields": ["name","brand","business"]}}}
精确查询: term字段全值匹配,range字段范围匹配。
精确查询一般查找keyword、数值、boolean等不可分词的字段
# term
GET /hotel/_search
{"query": {"term": {"city": {"value": "北京"}}}
}
# range
GET /hotel/_search
{"query": {"range": {"price": {"gt": 1000,"lt": 2000}}}
}
地理查询:
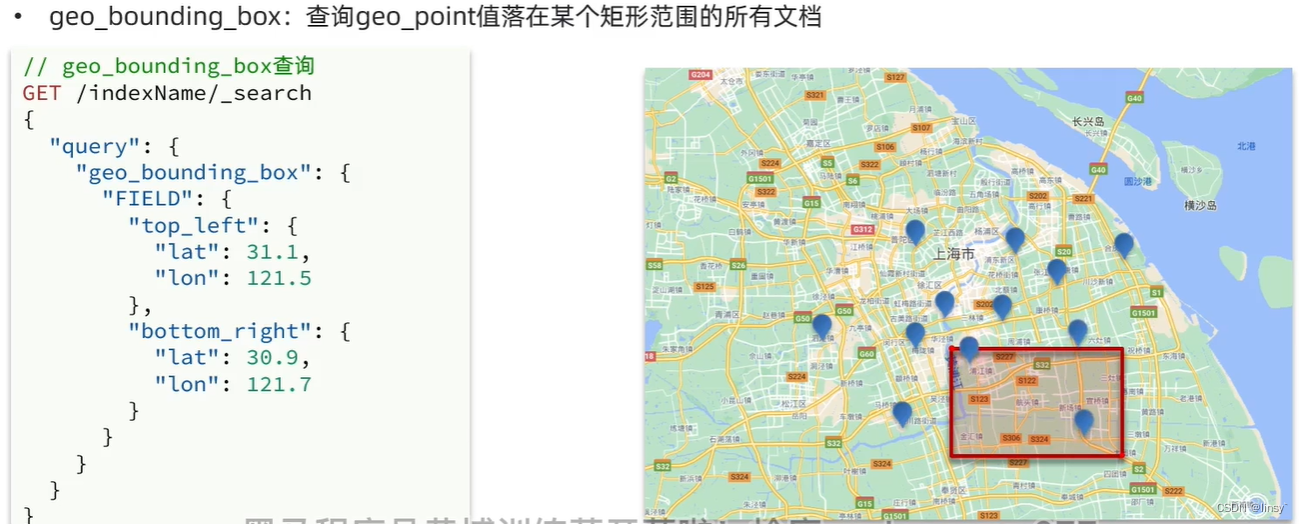

GET /hotel/_search
{"query": {"geo_bounding_box": {"location": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}GET /hotel/_search
{"query": {"geo_distance": {"distance": "20km","location": {"lat": 31.13,"lon": 121.8}}}
}
复合查询(compound ):将简单查询条件组合在一起,实现复杂搜索逻辑。
function score:算分函数查询,可以控制文档的相关性算分,控制排名。例如百度竞价
es在5.1及之后就弃用了 TF-IDF 算法,开始采用 BM25算法。BM25算法不会因为词的出现频率变大而导致算分无限增大,会逐渐趋近一个值

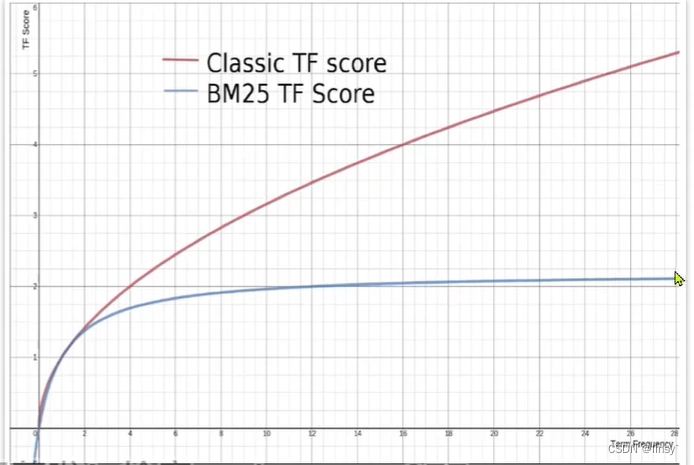
function score query :可以修改文档相关性算分,得到新的算分。
三要素
- 过滤条件:决定哪些条件要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算

GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"all": "如家酒店"}},"functions": [{"filter": {"term": {"city": "上海"}},"weight": 10}],"boost_mode": "sum"}}
}
boolean query:布尔查询是一个或多个子查询的组合。
- must:必须匹配每个子查询,类似”and“
- should:选择性匹配子查询,类似”or“
- must_not:必须不匹配,不参与算分,类似”非“
- filter:必须匹配,不参与算分

GET /hotel/_search
{"query": {"bool": {"must": [{"match": {"all": "上海"}}],"must_not": [{"range": {"price": {"gt": 500}}}],"filter": [{"geo_distance": {"distance": "10km","location": {"lat": 31.21,"lon": 121.5}}}]}}
}
搜索结构处理
排序
es支持对搜索结构进行排序,默认是根据相关度算分(_score)进行排序。可以排序的字段有keyword,数值、地理坐标、日期类型等。
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"id": {"order": "desc"}}]
}
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"location": {"lat": 31.2,"lon": 121.5},"order": "asc","unit": "km"}}]
}
这个排序的结果就是相聚的公里数。

分页


针对深度分页;ES给出了两种方案
- search after:分页时需要排序,原理是从上次的排序值开始(末尾值),查询下一页的数据。官方推荐使用,不会太占内存。手机向下反动滚页。
- scroll:原理是将排序数据形成快照,保存在内存。不推荐
高亮

ES默认搜索字段和高亮字段必须一致,否则不会高亮。或者使用 "require_field_match": "false" 也能高亮。
最后将查询结果中 highlight 与 指定高亮的字段进行替换返回给前端就行。

RestClient


普通查询
@Testpublic void testMatchAll() throws IOException {SearchRequest searchRequest = new SearchRequest("hotel");searchRequest.source().query(QueryBuilders.matchAllQuery());SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHits searchHits = searchResponse.getHits();long value = searchHits.getTotalHits().value;System.out.println(value);SearchHit[] hits = searchHits.getHits();System.out.println(hits[0]);HotelDoc hotelDoc = JSON.parseObject(hits[0].getSourceAsString(), HotelDoc.class);System.out.println(hotelDoc);}QueryBuilders.matchAllQuery()QueryBuilders.matchQuery("all","如家")QueryBuilders.multiMatchQuery("如家","name","brand","business")QueryBuilders.termQuery("city","上海")QueryBuilders.rangeQuery("price").gt(100).lt(400)BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.termQuery("city","北京"));boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gt(100).lt(400));分页和排序
public void testPageAndSort() throws IOException {int pageNum = 2, pageSize = 10;SearchRequest searchRequest = new SearchRequest("hotel");BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("brand", "如家");MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("all", "北京");boolQueryBuilder.must(termQueryBuilder);boolQueryBuilder.must(matchQueryBuilder);searchRequest.source().query(boolQueryBuilder);searchRequest.source().from((pageNum - 1) * pageSize).size(pageSize);searchRequest.source().sort("price", SortOrder.ASC);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {String source = hit.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);System.out.println(hotelDoc);}}
高亮
public void testHighLight() throws IOException {SearchRequest searchRequest = new SearchRequest("hotel");searchRequest.source().query(QueryBuilders.matchQuery("all","如家"));searchRequest.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHit[] hits = searchResponse.getHits().getHits();for (SearchHit hit : hits) {String source = hit.getSourceAsString();HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);Map<String, HighlightField> highlightFields = hit.getHighlightFields();if(!highlightFields.isEmpty()){HighlightField highlightField = highlightFields.get("name");//一般value只有一个元素,取数组第一个String name = highlightField.getFragments()[0].string();hotelDoc.setName(name);}System.out.println(hotelDoc);}}
让指定酒店置顶 (function_score )广告业务

// 算分控制FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(// 原始查询boolQueryBuilder,// FunctionScore 数组new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("isAD", true),ScoreFunctionBuilders.weightFactorFunction(10))});
相关文章:
ElasticSearch相关概念
文章目录 前提倒排索引MySQL、ES的区别和关联IK分词器索引库mapping属性索引库的crud 文档的crudRestClientDSL查询DSL 查询种类DSL query 基本语法 搜索结构处理排序分页高亮RestClient 前提 开源的搜索引擎,从海量数据中快速找到需要的内容。(分词检索…...
微服务实战项目-学成在线-项目部署
微服务实战项目-学成在线-项目部署 1 什么是DevOps 一个软件的生命周期包括:需求分析阶、设计、开发、测试、上线、维护、升级、废弃。 通过示例说明如下: 1、产品人员进行需求分析 2、设计人员进行软件架构设计和模块设计。 3、每个模块的开发人员…...

封装form表单
目录 1. 源码 2. 其他页面引用 ps:请看完看明白再复用 1. 源码 <template><div style"width: 100%; height: 100%" class"form-condition"><!-- 普通表单 --><el-card shadow"hover" class"cardheigh…...

程序员如何利用公网远程访问查询本地硬盘【内网穿透】
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《高效编程技巧》《cpolar》 ⛺️生活的理想,就是为了理想的生活! 公网远程访问本地硬盘文件【内网穿透】 文章目录 公网远程访问本地硬盘文件【内网穿透】前言1. 下载cpolar和Everything软件1.…...

算法|Day42 动态规划10
LeetCode 121.买卖股票的最佳时机 题目链接:https://leetcode.cn/problems/best-time-to-buy-and-sell-stock/description/ 题目描述:给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。 你只能选择 某一天…...
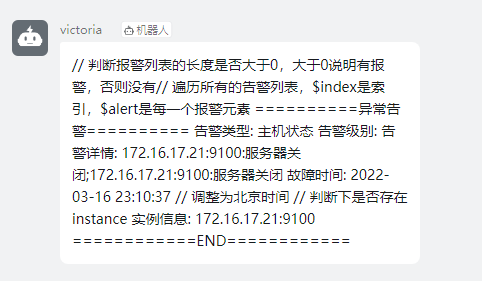
vmalert集成钉钉告警
vmalert通过在alert.rules中配置告警规则实现告警,告警规则语法与Prometheus兼容,依赖Alertmanager与prometheus-webhook-dingtalk实现钉钉告警,以下步骤: 1、构建vmalert 从源代码构建vmalert: git clone https://…...

深入解析 MyBatis 中的 <foreach> 标签:优雅处理批量操作与动态 SQL
在当今的Java应用程序开发中,数据库操作是一个不可或缺的部分。MyBatis作为一款颇受欢迎的持久层框架,为我们提供了一种优雅而高效的方式来管理数据库操作。在MyBatis的众多特性中,<foreach>标签无疑是一个强大的工具,它使得…...
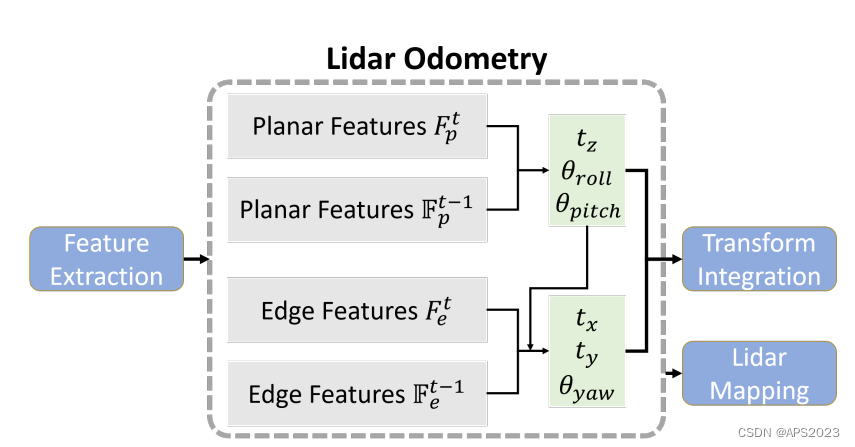
LeGO-Loam代码解析(二)--- Lego-LOAM的地面点分离、聚类、两步优化方法
1 地面点分离剔除方法 1.1 数学推导 LeGO-LOAM 中前端改进中很重要的一点就是充分利用了地面点,那首先自然是提取 对地面点的提取。 如上图,相邻的两个扫描线束的同一列打在地面上如 点所示,他们的垂直高度差 ,水平距离差 ,计算垂直高度差和水平高度差…...
程序员如何利用公网打造低成本轻量化的搜索和下载平台【内网穿透】
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《高效编程技巧》《cpolar》 ⛺️生活的理想,就是为了理想的生活! 公网远程访问本地硬盘文件【内网穿透】 文章目录 公网远程访问本地硬盘文件【内网穿透】前言1. 下载cpolar和Everything软件1.…...
构建可远程访问的企业内部论坛
文章目录 前言1.cpolar、PHPStudy2.Discuz3.打开PHPStudy,安装网页论坛所需软件4.进行网页运行环境的构建5.运行Discuz网页程序6.使用cpolar建立穿透内网的数据隧道,发布到公网7.对云端保留的空白数据隧道进行配置8.Discuz论坛搭建完毕 前言 企业在发展…...
场:河南理工大学-C 旅游)
2023河南萌新联赛第(六)场:河南理工大学-C 旅游
2023河南萌新联赛第(六)场:河南理工大学 https://ac.nowcoder.com/acm/contest/63602/C 文章目录 2023河南萌新联赛第(六)场:河南理工大学题意解题思路代码 题意 小C喜欢旅游,现在他要去DSH旅…...
)
C语言 常用工具型API ----------strchr()
函数原型 char *strchr(const char *str, int c) 参数 str-- 要被检索的 C 字符串。 c-- 在 str 中要搜索的字符。 功能 在参数str所指向的字符串中搜索第一次出现字符c(一个无符号字符)的位置 头文件 #include <string.h> 返回值 返回一…...

建造者模式的理论与实现
本文实践代码仓库:https://github.com/goSilver/my_practice 文章目录 一、定义二、作用三、实现四、总结 一、定义 建造者模式是一种创建复杂对象的设计模式。它将一个复杂对象的构建过程分解为多个简单的步骤,并且允许按照特定的顺序来构建对象。通过…...

非计算机科班如何顺利转码进入计算机领域?
文章目录 如何规划才能实现转码?计算机岗位发展前景?现阶段转码 总结 🎉欢迎来到Java学习路线专栏~探索非计算机科班如何顺利转码进入计算机领域 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博客dz…...
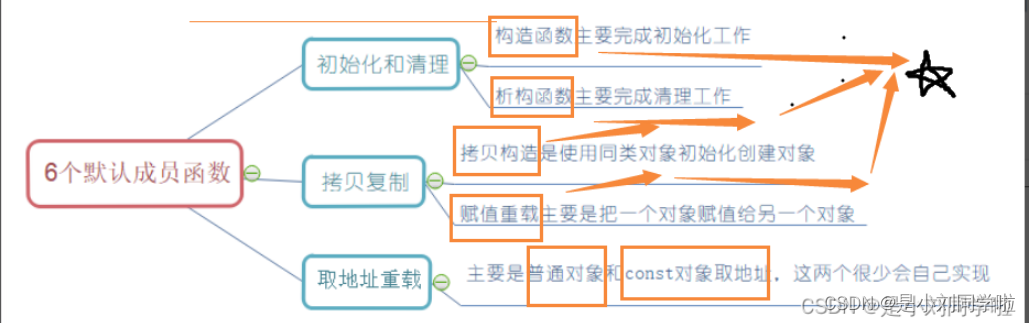
【C++类和对象】类有哪些默认成员函数呢?(下)
文章目录 一、类的6个默认成员函数二、日期类的实现2.1 运算符重载部分2.2 日期之间的运算2.3 整体代码1.Date.h部分2. Date.cpp部分 三. const成员函数四. 取地址及const取地址操作符重载扩展内容 总结 ヾ(๑╹◡╹)ノ" 人总要为过去的懒惰而付出代价ヾ(๑╹◡…...

springboot自定义banner的输出与源码解析
文章目录 一、介绍二、演示环境三、自定义banner1. 文本2. 图片3. placeholder占位符4. 关闭banner 四、源码分析1. 关闭banner2. banner模式3. banner打印器4. 打印banner① 获取banner② 打印banner 5. 版本号占位符的解析器6. 文本格式占位符的解析器7. 应用标题占位符的解析…...

LeetCode 141.环形链表
文章目录 💡题目分析💡解题思路🔔接口源码💡深度思考❓思考1❓思考2 题目链接👉 LeetCode 141.环形链表👈 💡题目分析 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中…...
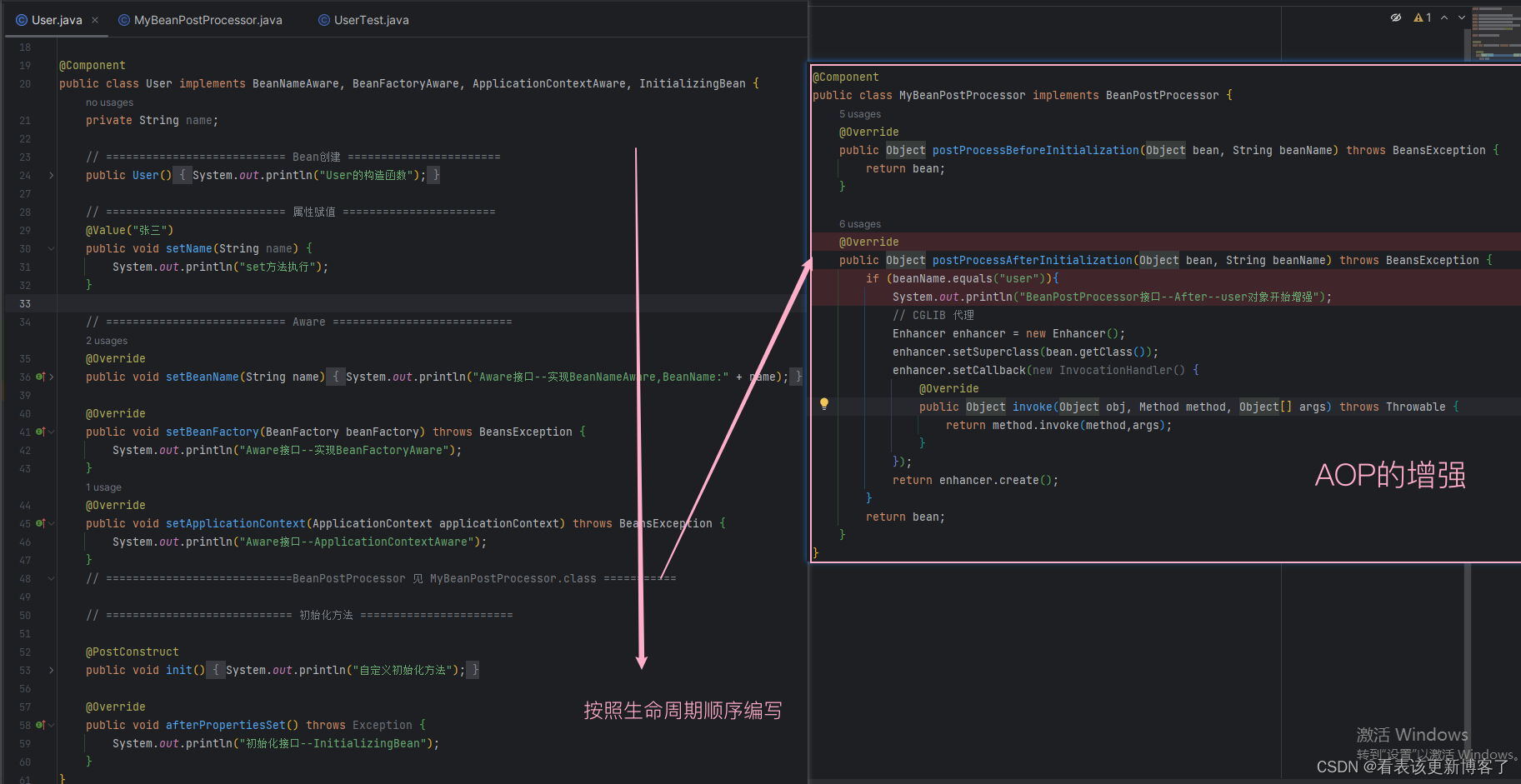
Spring-Bean的生命周期
目录 生命周期汇总 细分生命周期 1.实例化 2.属性赋值(依赖注入) 3.Aware接口 4.BeanPostProcessor接口 5.初始化 6.销毁 测试验证 类结构 业务类 测试类 生命周期汇总 Spring Bean 的生命周期见下图 (一定记忆好下图&#x…...
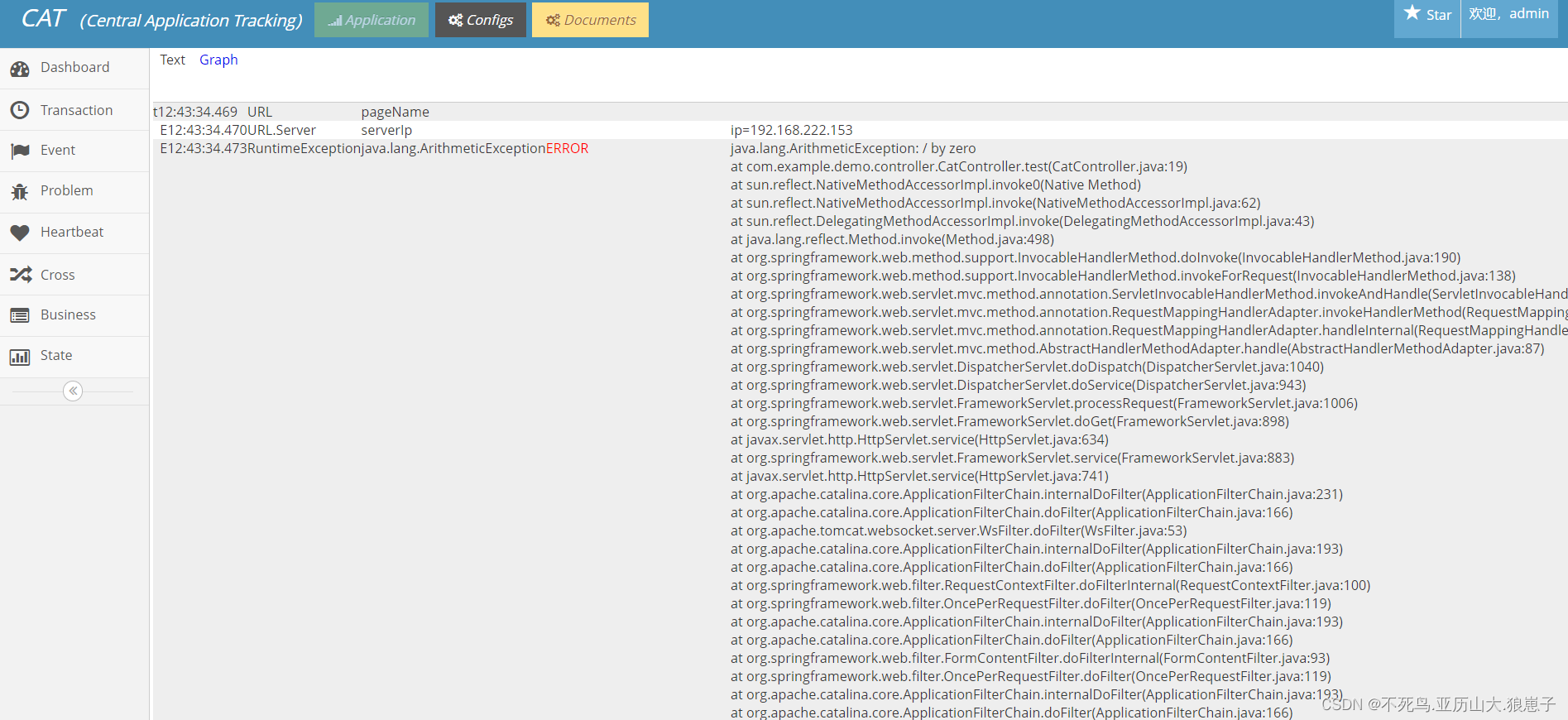
Cat(3):客户端集成—简单案例
接下来编写一个简单的springboot与Cat整合的案例 1 新建springboot项目 首先创建一个Spring Boot的初始化工程。只需要勾选web依赖即可。 2 添加 Maven 添加依赖 <dependency><groupId>com.dianping.cat</groupId><artifactId>cat-client</artifa…...

虚拟机/双系统Ubuntu扩容
虚拟机Ubuntu扩容 1.需要删除所有的快照 2.扩展虚拟机磁盘大小 虚拟机(M)→设置(s)→硬盘(SCSI)→扩展磁盘容量 3.Ubuntu内调整分区大小 安装gparted分区工具:sudo apt-get install gparted 启动gparted并resize分区 4.最后最好建一个快照,不然gg了…...

实现Degrees of Lewdity游戏本地化:完整中文补丁安装教程
实现Degrees of Lewdity游戏本地化:完整中文补丁安装教程 本教程将指导您完成Degrees of Lewdity游戏的中文本地化过程,通过系统的游戏本地化方法,帮助您顺利安装中文补丁,解决游戏界面语言障碍,提升游戏体验。我们将…...

ESP32开发踩坑记:从HID库缺失到PlatformIO环境搭建的全流程复盘
ESP32开发踩坑记:从HID库缺失到PlatformIO环境搭建的全流程复盘 那天深夜,我盯着屏幕上"hid.h: No such file or directory"的报错信息,意识到自己掉进了嵌入式开发的第一个坑。原本想用Arduino做个体感鼠标来提升游戏体验…...

基于Apify与NLP的大麻监管情报系统架构与MCP集成实践
1. 项目概述:当AI遇见大麻监管情报如果你在合规、法律科技或者生命科学领域工作,最近可能听过“监管情报”这个词。简单说,它就是利用技术手段,从海量的、不断变化的法规文件中,自动提取、分析和监控关键信息ÿ…...

NotebookLM Pro版到底贵在哪?——基于172小时真实工作流压测的TCO建模分析
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Pro版到底贵在哪?——基于172小时真实工作流压测的TCO建模分析 在连续172小时跨时区协同实验中,我们部署了3类典型知识工作流:法律条文溯源分析、学术论文…...

Windows热键侦探:快速定位热键冲突的终极解决方案指南
Windows热键侦探:快速定位热键冲突的终极解决方案指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 在Window…...

ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成
ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 想要在有限硬件条件下实现专业级AI视频生成吗?ComfyUI-Fram…...

pdf2pptx:LaTeX到PowerPoint的无缝转换终极方案
pdf2pptx:LaTeX到PowerPoint的无缝转换终极方案 【免费下载链接】pdf2pptx Convert your (Beamer) PDF slides to (Powerpoint) PPTX 项目地址: https://gitcode.com/gh_mirrors/pd/pdf2pptx 还在为LaTeX Beamer制作的精美学术幻灯片无法在PowerPoint中完美展…...

Anno 1800模组加载器:3分钟解锁游戏无限可能的终极指南
Anno 1800模组加载器:3分钟解锁游戏无限可能的终极指南 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an…...

Emacs集成ChatGPT:AI助手无缝融入编辑器工作流
1. 项目概述:在Emacs中集成ChatGPT的魔法工具作为一名在Emacs生态里摸爬滚打了十多年的老用户,我对于在编辑器里“折腾”各种生产力工具一直乐此不疲。当ChatGPT这类大语言模型(LLM)横空出世时,我的第一反应就是&#…...

虚假信息注入下异构系统弹性纳什均衡【附代码】
✨ 长期致力于博弈论、分布式纳什均衡、虚假信息注入攻击、线性系统、参数不确定、事件触发研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)虚假信息观…...