[Machine Learning] decision tree 决策树
(为了节约时间,后面关于机器学习和有关内容哦就是用中文进行书写了,如果有需要的话,我在目前手头项目交工以后,用英文重写一遍)
(祝,本文同时用于比赛学习笔记和机器学习基础课程)
俺前两天参加了一个ai类的比赛,其中用到了一种名为baseline的模型来进行一些数据的识别。而这个识别的底层原理就是决策树。正好原本的学习进度刚刚完成这部分,所以集成一个笔记了,本文中所有的截图绝大多数来自吴恩达老师的公开课程,为了方便理解,把相关的图片搬过来了)
决策树是什么
决策树是一种机器学习算法,在一个类似二叉树的结构上实现的分支判断算法。每个节点都视为一个“判断语句”,将一批数据划分成不同的部分。节点上(除了叶子)都要判断“是”/“否”。

一个具体化以后的模型差不多长这样子:给出一堆宠物的数据,根据不同的特征(耳朵,脸型什么的),我们判断输入案例是狗还是猫猫。
如果还是不好理解,那么想象一下我们平时在写代码时候大量if else嵌套,展开以后也是一模一样的结构。去别在于可能if构成的判断树的后代可能多于决策树,决策树只能是二叉树,输出“是”“不是”这种问题,当面对多个离散的特征值的时候,我们还有别的技术可以使用.
简而言之,决策树是一种区别于神经网络的另一种判断算法,在一些数据的处理上可能比神经网络更快更有效,由于其结构类似二叉树,所以称之为决策树(decision tree).决策树的生成是要根据已经给出的数据案例创建的,数据有多少特征用于区分,就会有多少个节点进行分裂(split).
具体的训练过程和训练中遇到的问题会在下面解释
在训练之前要接触的一些名词
纯净(purity)/杂质(impurity):纯度和不纯是根据某个节点来说的,例如我们输入一堆宠物的数据(包括耳朵形状,毛发长度,脸型这些特征),在判断某个属性的节点上,我们会根据"符合"/"不符合"把已有的数据划分为两拨.比如这样子
原型的部分中,有四个是猫猫,三个是狗子.对于这个节点来说,我们可以认为这个节点的纯度是(4/7)
同理,另一个节点的纯度视为(1/3)
(纯度是一个相对的概念,如果你判断的是狗子,那么纯度就要变了)
熵:这个熵不是化学中的概念,而是代表混乱程度,当纯度和为0.5的时候,代表两种东西对半开,也就是最混乱的情况.根据纯度,我们有相关的公式可以计算出纯度对应熵的大小(假设纯度为p)
整个函数的图像大概就是这样子

信息增益:信息增益也是根据某一个点来说的,这个数值是训练时候的重要依据,信息增益越大,代表整个节点进行的划分越有效,信息增益的计算方式为
0.5对应的熵,减去左侧的熵和右侧的熵的加权平均和即可.比如上面的图,我们可以计算为
决策树如何进行训练
决策树底层的训练原理其实很简单,首先我们需要给定一个数据集合,这个数据集合中的每个事物都有一些共同的特征,类似这样,通常我们可以把有效的特征组合起来形成一个表格.

前面的特征为输入,而cat一列作为输出,决定这个宠物到底是不是猫,由此构成一系列符合监督学习要求的训练数据集合.
然后会从这些信息中,选择分裂时产生更小熵的特征,算法会基于某种标准(例如信息增益、基尼不纯度等)来评估每个可能的划分,并选择最优的划分特征。这些标准用于衡量数据的不纯度和分割后的纯度。这里我们使用上面讲到的信息增益来判断这个划分成都

由此可见,以耳朵形状作为划分所产生的分裂节点,信息增益更大,纯度也更好.
接下来再根据其他的特征进行划分即可,当遇到以下几种情况的时候,我们可以认为这个节点不用再继续分裂了
- 树的高度达到某些限制
- 纯度已经是100%
- 数据全部低于阈值
- ........
两个特殊情况
(1)分裂时候的数据不是二元的离散数值,而是一个连续的情况
这个很简单,设置一个阈值,比如0.5,0,7,....反正到最后还是二元的
(2)分裂的时候,可能数据是多元的离散数值,比如毛发可能是长发,短发,卷发这三种.我们总不能搞出三叉树来,所以这里我们把"是什么"转变为"是不是"的问题.比如这样一个特征,我们可以划分为"是不是长发,是不是短发,是不是卷毛"三个二元的特征
随机森林算法
给定一个数据集合,我们可以计算出一个决策树来进行一些判断,给定一个动物,决策树最红会给出我们这个是不是猫猫的答案.但是这有两个问题,节点不一定是纯净的(虽然大多数情况下,只要不超过我们的限定高度,是可以把一个决策树修炼到高度纯净的),造成判断结果不一定准确.
另一个问题就是,一些数据发生扰动以后,可能会影响决策树这个依托信息增益产生的精密系统.
最简单粗暴的方法就是,训练多个树,形成一个森林.但是一个数据集合练出来的树是一样的,没啥必要,所以我们产生了随机森林算法.
sampling with replacement(放回抽样)这东西我们在高中就学过,所以这里不加简述了.我们要做的就是确定一个规模,比如10,每次从原始数据集中抽取10个案例,然后用来训练一棵树.
如此循环多次,我们就能得到多个决策树,组成一个森林,这其中难免会有一些决策树是一样的,我们忽视掉它

这样我们计算结果的时候,要考虑到整个森林所有树木的输出效果,然后综合考虑我们怎样确定输出效果
XGBoost算法和使用
在众多随机森林算法中,XGBoost是一种使用很广泛的随机森林算法,并且XGBoost也是一个开源库(不是放在tf或者pytorch的库中的).XGBoost非常像我们之前聊过的增强算法(啥,哦博客还没写出来,8好意思,尽快补上)
XGBoost算法和普通决策树的区别在于放回抽样的不疯魔,传统的决策树是平等地抽取,xgb算法则是会根据上一次,估计错了哪些数值,在本次抽取中优先提取上一次参与训练并且估计失败的数值案例.
比如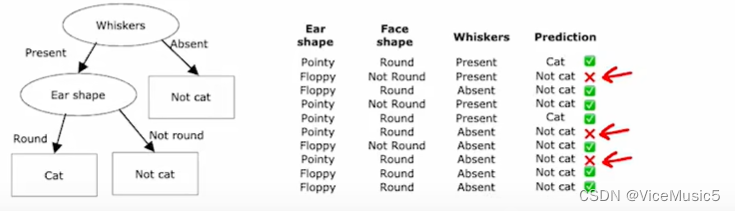
构建某一次决策树的时候,2,6,8号数据估计错误,则下一次会优先提取出这些作为训练案例之一.
当然这些主要是底层实现了(注意对应的函数从xgboost包中导入,这个包需要提前下载)
下面来看一下具体的使用案例.
pip3 install xgboost#xgboost算法 这里没有使用训练集合什么de
# 定义特征矩阵和标签
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 创建并训练模型
model = XGBClassifier()
model.fit(X, y)# 预测一个数据
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)print(f"预测结果: {prediction}")#xgboost算法 这里没有使用训练集合什么de
# 定义特征矩阵和标签
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 创建并训练模型
model = XGBClassifier()
model.fit(X, y)# 预测一个数据
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)print(f"预测结果: {prediction}")和神经网络有什么区别捏?
相比于神经网络来说,决策树和随机森林算法更适合一些有固定相似数据结构的数据集合.换句话说,更容易处理那种可以形成表格的数据.
而神经网络则用来处理一些非相似结构的数据,这一点就是他们的主要区别
决策树同样是一种很重要的监督学习算法.
关于baseline(未完待续)
baseline是一种基于决策树的大模型,适用于多重二元分析等操作,在竞赛和论文中应用很广泛.
(至少与我们之前用到tensorflow要广泛.....tf都快开摆了)
不过这个模型我现在也不是很熟悉,仅仅是停留在"用过"这个层面上,后面有机会我会继续在这里补充这个模型的使用和优缺点,
相关文章:
[Machine Learning] decision tree 决策树
(为了节约时间,后面关于机器学习和有关内容哦就是用中文进行书写了,如果有需要的话,我在目前手头项目交工以后,用英文重写一遍) (祝,本文同时用于比赛学习笔记和机器学习基础课程&a…...

【数学建模】-- 数学规划模型
概述: 什么是数学规划? 数学建模中的数学规划是指利用数学方法和技巧对问题进行数学建模,并通过数学规划模型求解最优解的过程。数学规划是一种数学优化方法,旨在找到使目标函数达到最大值或最小值的变量取值,同时满足…...

SpringBoot使用RabbitMQ自动创建Exchange和Queue
背景 小项目,使用RabbitMQ作为消息队列,发布到不同的新环境时,由于新搭建的MQ中不存在Exchange和Queue,就会出错,还得手动去创建,比较麻烦,于是想在代码中将这些定义好后,自动控制M…...
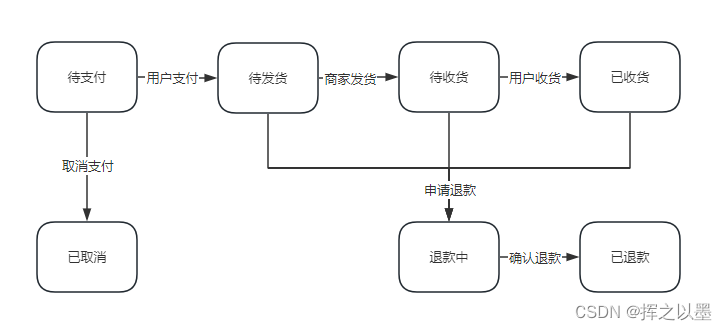
【设计模式】订单状态流传中的状态机与状态模式
文章目录 1. 前言2.状态模式2.1.订单状态流转案例2.1.1.状态枚举定义2.1.2.状态接口与实现2.1.3.状态机2.1.4.测试 2.2.退款状态的拓展2.2.1.代码拓展2.2.2.测试 2.3.小结 3.总结 1. 前言 状态模式一般是用在对象内部的状态流转场景中,用来实现状态机。 什么是状态…...
用来修改或者添加属性或者属性值)
2.js中attr()用来修改或者添加属性或者属性值
attr()可以用来修改或者添加属性或者属性值 例:<input type"button" class"btn btn-info" id"subbtn" style"font-size:12px" value"我也说一句"/>1.如果想获取input中value的值 $(#subbtn).attr(value);…...

【虫洞攻击检测】使用多层神经网络的移动自组织网络中的虫洞攻击检测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

微分流形学习之一:基本定义
微分流形学习之一:基本定义引入 引言一、微分流形的历史简介二、拓扑空间三、微分流形 引言 本文是作者在学习微分流形的时候的笔记,尽量严格完整,并带有一定理解,绝不是结论的简单罗列。如果读者知道数学分析中的 ϵ − δ \ep…...
[C++]笔记-制作自己的静态库
一.静态库的创建 在项目属性c/c里面,选用无预编译头,创建头文件与cpp文件,需要注意release模式下还是debug模式,在用库时候要与该模式相匹配,库的函数实现是外界无法看到的,最后在要使用的项目里面导入.h文件和.lib文件 二.使用一个循环给二维数组赋值 行数 : 第几个元素 / …...

优酷视频码率、爱奇艺视频码率、B站视频码率、抖音视频码率对比
优酷视频码率、爱奇艺视频码率与YouTube视频码率对比 优酷视频码率: 优酷的视频码率可以根据视频质量、分辨率和内容类型而变化。一般而言,优酷提供了不同的码率选项,包括较低的标清(SD)码率和较高的高清(…...
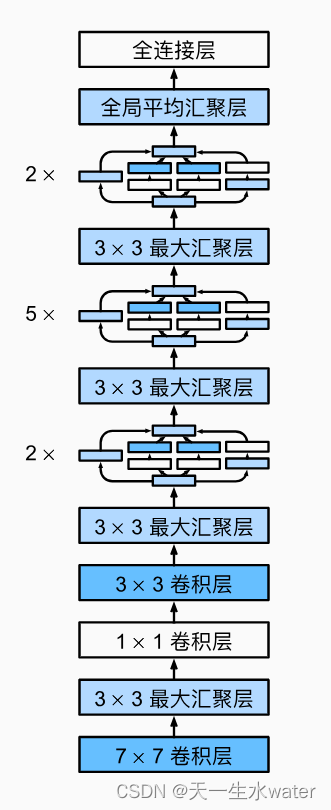
用pytorch实现google net
GoogleNet(也称为Inception v1)是由Google在2014年提出的一个深度卷积神经网络架构。它在ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014比赛中取得了优秀的成绩,并引起了广泛的关注。 GoogleNet的设计目标是构建一个更…...

2023-8-15差分矩阵
题目链接:差分矩阵 #include <iostream>using namespace std;const int N 1010;int n, m, q; int a[N][N], b[N][N];void insert(int x1, int y1, int x2, int y2, int c) {b[x1][y1] c;b[x1][y2 1] - c;b[x2 1][y1] - c;b[x2 1][y2 1] c; }int main…...

物理公式分类
(99 封私信 / 81 条消息) 定义式和决定式有什么区别,怎么区分? - 知乎 (zhihu.com) 1、首先,定义一个物理符号(物理量)来表征物理世界最直观/最基本的物理现象,例如,长度(米…...

vue实现登录注册
目录 一、登录页面 二、注册页面 三、配置路由 一、登录页面 <template><div class"login_container" style"background-color: rgb(243,243,243);height: 93.68vh;background-image: url(https://ts1.cn.mm.bing.net/th/id/R-C.f878c96c4179c501a6…...
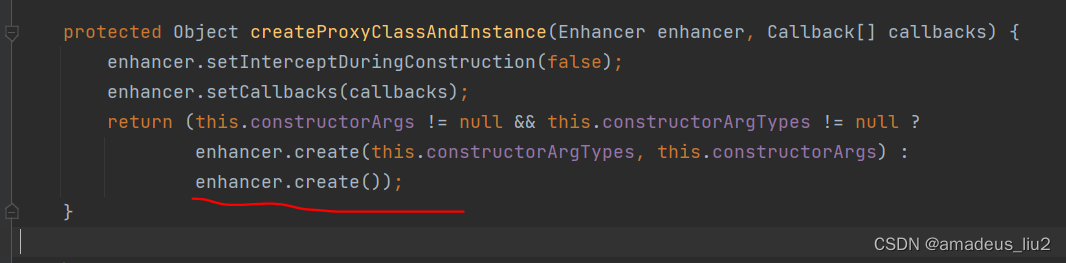
SpringBoot复习:(55)在service类中的方法上加上@Transactional注解后,Spring底层是怎么生成代理对象的?
SpringBoot run方法代码如下: 可以看到它会调用refreshContext方法来刷新Spring容器,这个refreshContext方法最终会调用AbstractApplicationContext的refresh方法,代码如下 如上图,refresh方法最终会调用finisheBeanFactoryInit…...

常用的图像校正方法
在数字图像处理中,常用的校正方法包括明场均匀性校正、查找表(LUT)校正和伽玛(Gamma)校正。这些校正方法分别针对不同的图像问题,可以改善图像质量,提升图像的可读性和可分析性。下面是这三种校…...

AWS security 培训笔记
云计算的好处 Amazon S3 (Storage) Amazon EC2 (Compute) 上图aws 的几个支柱:安全是其中一个啦 其中安全有几个方面 IAMdetection基础架构保护数据保护应急响应 关于云供应商的责任 data center 原来长这样 ,据说非常之隐蔽的 如果有天退役了…...
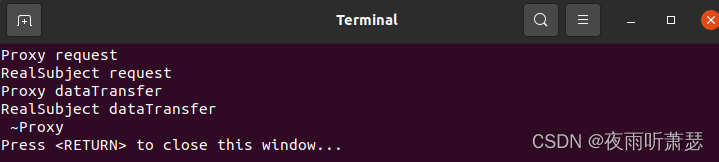
设计模式之代理模式(Proxy)的C++实现
1、代理模式的提出 在组件的开发过程中,有些对象由于某种原因(比如对象创建的开销很大,或者对象的一些操作需要做安全控制,或者需要进程外的访问等),会使Client使用者在操作这类对象时可能会存在问题&…...
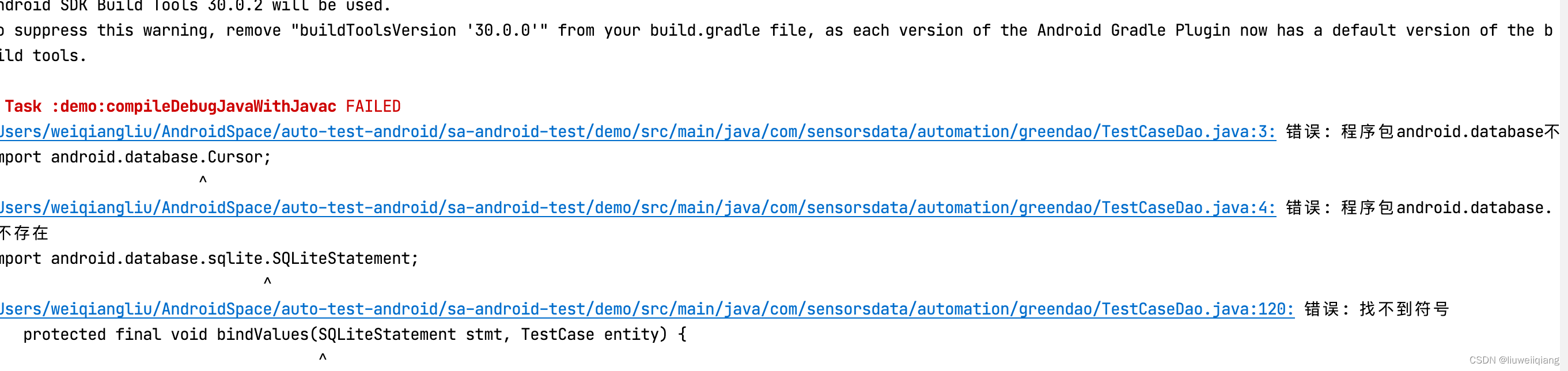
vim 配置环境变量与 JDK 编译器异常
vim 配置环境变量 使用 vim 打开系统中的配置信息(不存在将会创建): vim ~/.bash_profile 以配置两个版本 JDK 为例(前提是已安装 JDK),使用上述命令打开配置信息: 输入法调成英文,输入 i&…...

TiDB v7.1.0 跨业务系统多租户解决方案
本文介绍了 TiDB 数据库的资源管控技术,并通过业务测试验证了效果。资源管控技术旨在解决多业务共用一个集群时的资源隔离和负载问题,通过资源组概念,可以限制不同业务的计算和 I/O 资源,实现资源隔离和优先级调度,提高…...
)
【题解】二叉树中和为某一值的路径(一)
二叉树中和为某一值的路径(一) 题目链接:二叉树中和为某一值的路径(一) 解题思路1:递归 我们或许想记录下每一条从根节点到叶子节点的路径,计算出该条路径的和,但此种思路用递归稍麻烦,我们可以试着把和转换为差&am…...

NTN 长距离通信领域亮相
核心蜂窝解决方案亮相并带来Nordic NTN 核心解决方案深度分享。环节将全面解析 nRF9151 模组的核心特性与技术优势,详解卫星星座生态布局及 nRFCloud 平台的应用价值,为参会者勾勒 NTN 技术的整体框架与商业落地前景,为后续内容奠定专业基础。…...

第一卷第4章:接口而非实现编程
第一卷第4章:接口而非实现编程 目录介绍 00.先回答上篇思考题 0.1 上篇遗留三道题 0.2 云迁移6万行代码 0.3 五次反转补锅 0.4 灵魂五连问 01.从一个搬迁切入 1.1 上云搬迁案例...

[STM32U3] 【STM32U385RG 测评】+ PWM调节控制LED
在厂家提供的例程中,提供了多个PWM通道输出固定占空比的示例,但缺少改变占空比的介绍。为此,作了一下自动改变占空比和按键改变占空比的尝试。这采用的是以PWM通道1输出脉冲来控制外挂LED模块的亮度,通道1的输出引脚为PA0…...

【NotebookLM要点提取黄金法则】:20年AI工具实战总结的5大避坑指南与3步精准萃取法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法论全景概览 NotebookLM 是 Google 推出的面向研究者与知识工作者的 AI 原生笔记工具,其核心能力在于对用户上传文档(PDF、TXT、Google Docs)进…...

5分钟搞定Android Studio中文界面:免费汉化插件完整指南
5分钟搞定Android Studio中文界面:免费汉化插件完整指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Androi…...

Java OCR实战:精准提取与解析身份证信息
1. 为什么选择Java OCR处理身份证信息? 在企业级应用开发中,身份证信息录入是个高频需求场景。传统人工录入不仅效率低下,还容易出错。我去年参与过一个政务系统改造项目,工作人员每天要处理300张身份证照片,手动录入的…...

如何用MPC-HC打造专业级影音播放体验:从安装到优化的完整指南
如何用MPC-HC打造专业级影音播放体验:从安装到优化的完整指南 【免费下载链接】mpc-hc MPC-HCs main repository. For support use our Trac: https://trac.mpc-hc.org/ 项目地址: https://gitcode.com/gh_mirrors/mpc/mpc-hc MPC-HC(Media Playe…...

Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程
Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程 在医疗设备、工业控制等物联网场景中,Android设备与外围硬件通过串口通信的需求日益增长。CH340作为一款高性价比的USB转串口芯片,因其稳定性和广泛兼容性成为许多硬件…...

MySQL 跑得稳不稳,Prometheus 得能抓到这个数据才能说清楚
前言 数据库出问题的时候,最怕的不是故障本身,而是故障发生了却没人知道,等用户反馈过来才去翻日志,慢了不止一拍。 MySQL 本身有一些状态变量能反映运行状况——连接数、QPS、缓冲池命中率、慢查询数量——但这些数据要么存着没…...
 全解析|≤68kg 包装件部分模拟运输测试指南)
ISTA 2A-2011 (2022) 全解析|≤68kg 包装件部分模拟运输测试指南
前言ISTA 2A-2011 (2022) 属于 ISTA 2 系列部分模拟性能测试,专门面向 **≤68kg(150lb)的单个小型运输包装件 **,是电商小件、3C 数码、小家电、仪器仪表最常用的入门级包装验证标准。它结合基础测试与仿真要素,快速验…...