用户新增预测(Datawhale机器学习AI夏令营第三期)
文章目录
- 简介
- 任务1:跑通Baseline
- 实操并回答下面问题:
- 如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
- 代码中如何对udmp进行了人工的onehot?
- 任务2.1:数据分析与可视化
- 编写代码回答下面的问题:
- **问题一:字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?**
- **问题二:对于数值类型的字段,考虑绘制在标签分组下的箱线图。**
- **问题三:从common_ts中提取小时,绘制每小时下标签分布的变化。**
- **问题四:对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。**
- 任务2.2:模型交叉验证
- 编写代码回答下面的问题:
- **问题一:在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?**
- **问题二:使用树模型训练,然后对特征重要性进行可视化;**
- **问题三:再加入3个模型训练,对比模型精度;**
- 任务2.3:特征工程
简介
内容为AI夏令营第三期 - 用户新增预测挑战赛教程的笔记,比赛链接为用户新增预测挑战赛,感觉教程比较适合新入门的小白,对新手很友好。这是我第一次参加机器学习相关的竞赛,记录小白升级打怪过程!
第一次修改时间:2023年8月18日,初步提交内容,完成教程了教程中所有的练习题。
任务1:跑通Baseline
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 sklearn.tree 模块中导入 DecisionTreeClassifier 类
# DecisionTreeClassifier 用于构建决策树分类模型
from sklearn.tree import DecisionTreeClassifier
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train_data = pd.read_csv('train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test_data = pd.read_csv('test.csv')
train_data.head()
| uuid | eid | udmap | common_ts | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 26 | {"key3":"67804","key2":"650"} | 1689673468244 | 4 | 0 | 41 | 107 | 206 | 1 | 0 | 1 | 0 |
| 1 | 1 | 26 | {"key3":"67804","key2":"484"} | 1689082941469 | 4 | 0 | 41 | 24 | 283 | 4 | 8 | 1 | 0 |
| 2 | 2 | 8 | unknown | 1689407393040 | 4 | 0 | 41 | 71 | 288 | 4 | 7 | 1 | 0 |
| 3 | 3 | 11 | unknown | 1689467815688 | 1 | 3 | 41 | 17 | 366 | 1 | 6 | 1 | 0 |
| 4 | 4 | 26 | {"key3":"67804","key2":"650"} | 1689491751442 | 0 | 3 | 41 | 92 | 383 | 4 | 8 | 1 | 0 |
# 3. 将 'udmap' 列进行 One-Hot 编码
# 数据样例:
# udmap key1 key2 key3 key4 key5 key6 key7 key8 key9
# 0 {'key1': 2} 2 0 0 0 0 0 0 0 0
# 1 {'key2': 1} 0 1 0 0 0 0 0 0 0
# 2 {'key1': 3, 'key2': 2} 3 2 0 0 0 0 0 0 0# 在 python 中, 形如 {'key1': 3, 'key2': 2} 格式的为字典类型对象, 通过key-value键值对的方式存储
# 而在本数据集中, udmap实际是以字符的形式存储, 所以处理时需要先用eval 函数将'udmap' 解析为字典# 具体实现代码:
# 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
def udmap_onethot(d):v = np.zeros(9) # 创建一个长度为 9 的零数组if d == 'unknown': # 如果 'udmap' 的值是 'unknown'return v # 返回零数组d = eval(d) # 将 'udmap' 的值解析为一个字典for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身if 'key' + str(i) in d: # 如果当前键存在于字典中v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上return v # 返回 One-Hot 编码后的数组# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 4. 编码 udmap 是否为空
# 使用比较运算符将每个样本的 'udmap' 列与字符串 'unknown' 进行比较,返回一个布尔值的 Series
# 使用 astype(int) 将布尔值转换为整数(0 或 1),以便进行后续的数值计算和分析
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)# 5. 提取 eid 的频次特征
# 使用 map() 方法将每个样本的 eid 映射到训练数据中 eid 的频次计数
# train_data['eid'].value_counts() 返回每个 eid 出现的频次计数
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())# 6. 提取 eid 的标签特征(不同访问行为的人有不同的target标签)
# 使用 groupby() 方法按照 eid 进行分组,然后计算每个 eid 分组的目标值均值
# train_data.groupby('eid')['target'].mean() 返回每个 eid 分组的目标值均值
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())# 7. 提取时间戳
# 使用 pd.to_datetime() 函数将时间戳列转换为 datetime 类型
# 样例:1678932546000->2023-03-15 15:14:16
# 注: 需要注意时间戳的长度, 如果是13位则unit 为 毫秒, 如果是10位则为 秒, 这是转时间戳时容易踩的坑
# 具体实现代码:
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})# 10. 保存结果文件到本地
# 将结果DataFrame保存为一个CSV文件,文件名为 'submit.csv'
# 参数 index=None 表示不将DataFrame的索引写入文件中
result_df.to_csv('submit.csv', index=None)
实操并回答下面问题:
如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
代码中如何对udmp进行了人工的onehot?
1:0.62734
2:对umap列中的字典元素按键取值,初始为一个九维的向量,将字典中键对应的值覆盖到向量中的对应位置。
任务2.1:数据分析与可视化
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 读取训练集和测试集文件
train_data = pd.read_csv('train.csv')
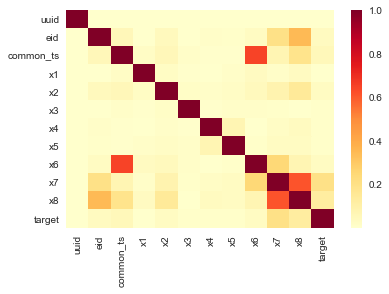
test_data = pd.read_csv('test.csv')# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')
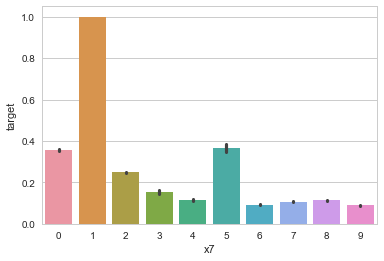
# x7分组下标签均值
sns.barplot(x='x7', y='target', data=train_data)
编写代码回答下面的问题:
- 字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
- 对于数值类型的字段,考虑绘制在标签分组下的箱线图。
- 从common_ts中提取小时,绘制每小时下标签分布的变化。
- 对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
问题一:字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
x1, x2, x3, x4, x5, x6, x7, x8为类别类型,x3,x4,x5为数值类型。
#1:
import pandas as pd# 假设您的数据已经加载到名为 'data' 的 DataFrame 中
train_data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8']].head(5)
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 0 | 41 | 107 | 206 | 1 | 0 | 1 |
| 1 | 4 | 0 | 41 | 24 | 283 | 4 | 8 | 1 |
| 2 | 4 | 0 | 41 | 71 | 288 | 4 | 7 | 1 |
| 3 | 1 | 3 | 41 | 17 | 366 | 1 | 6 | 1 |
| 4 | 0 | 3 | 41 | 92 | 383 | 4 | 8 | 1 |
问题二:对于数值类型的字段,考虑绘制在标签分组下的箱线图。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(10, 6))
for i,y in enumerate(['x3', 'x4', 'x5']):sns.boxplot(x="target", y=y, data=train_data, width=0.5, showfliers=False,ax=axes[i])ax.set_xlabel('Label')ax.set_ylabel(f'Feature {col}')ax.set_title(f'Box Plot of Feature {col}')ax.yaxis.grid(True)
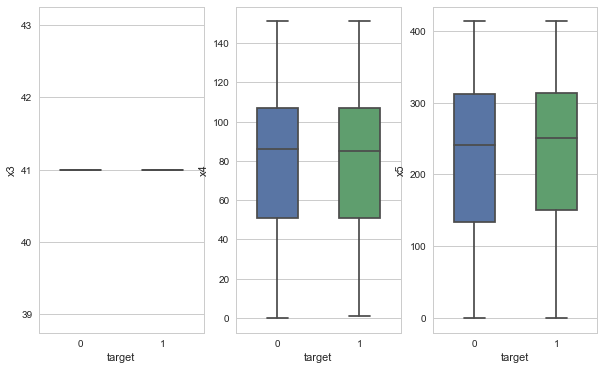
问题三:从common_ts中提取小时,绘制每小时下标签分布的变化。
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6),dpi=80)train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hoursns.countplot(x="common_ts_hour",hue='target', data=train_data,ax = axes[0])new_df = (train_data.groupby('common_ts_hour')['target'].value_counts(normalize=True).sort_index().unstack())
new_df.plot.bar(stacked=True,ax = axes[1])
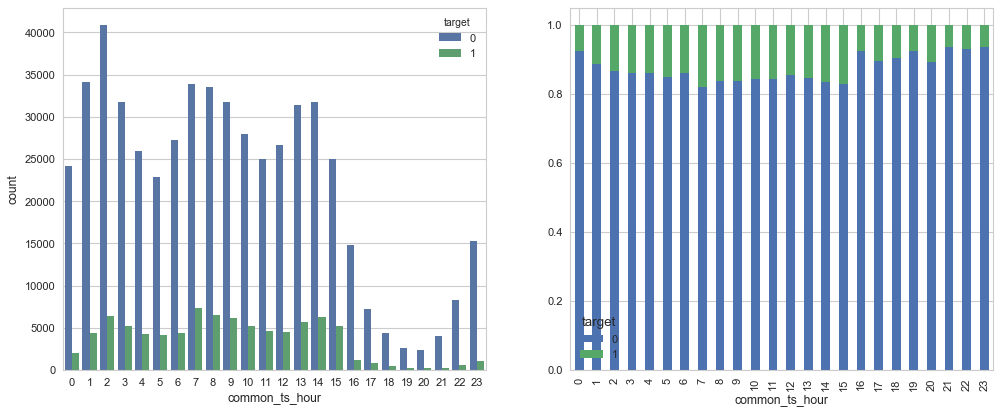
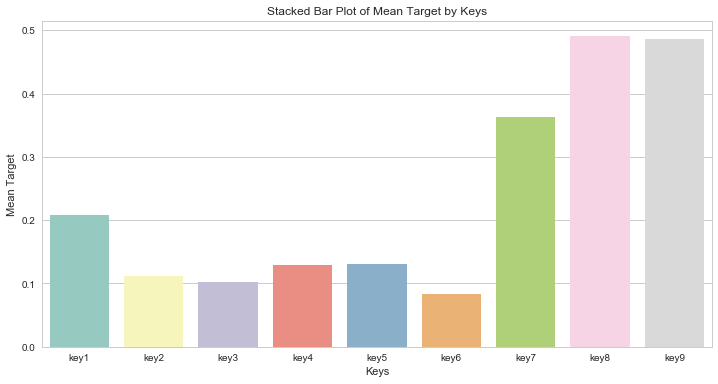
问题四:对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
train_data = pd.read_csv('train.csv')
def udmap_onethot(d):v = np.zeros(9) # 创建一个长度为 9 的零数组if d == 'unknown': # 如果 'udmap' 的值是 'unknown'return v # 返回零数组d = eval(d) # 将 'udmap' 的值解析为一个字典for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身if 'key' + str(i) in d: # 如果当前键存在于字典中v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上return v # 返回 One-Hot 编码后的数组# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
key_means = {}
for key in ["key"+str(i) for i in range(1,10)]:key_mean = train_data[train_data[key]!=0]["target"].mean()key_means[key] = key_mean
key_means
{'key1': 0.20862740446395034,'key2': 0.11199392180793882,'key3': 0.10190294045637927,'key4': 0.12993673492307117,'key5': 0.13023321337551066,'key6': 0.08351648351648351,'key7': 0.363013698630137,'key8': 0.49056603773584906,'key9': 0.4857142857142857}
key_means_df = pd.DataFrame(key_means, index = [0])
plt.figure(figsize=(12, 6))
sns.barplot(data=key_means_df, palette="Set3")
plt.xlabel('Keys')
plt.ylabel('Mean Target')
plt.title('Stacked Bar Plot of Mean Target by Keys')
plt.legend(title='Keys', loc='upper right')
plt.show()
任务2.2:模型交叉验证
# 导入库
import pandas as pd
import numpy as np# 读取训练集和测试集文件
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')# 提取udmap特征,人工进行onehot
def udmap_onethot(d):v = np.zeros(9)if d == 'unknown':return vd = eval(d)for i in range(1, 10):if 'key' + str(i) in d:v[i-1] = d['key' + str(i)]return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]# 编码udmap是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)# udmap特征和原始数据拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)# 提取eid的频次特征
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())# 提取eid的标签特征
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour# 导入模型
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
# 训练并验证SGDClassifier
pred = cross_val_predict(SGDClassifier(max_iter=20),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target'],
)
print(classification_report(train_data['target'], pred, digits=3))
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.ConvergenceWarning)
D:\Anaconda\lib\site-packages\sklearn\linear_model\_stochastic_gradient.py:577: ConvergenceWarning: Maximum number of iteration reached before convergence. Consider increasing max_iter to improve the fit.ConvergenceWarning)precision recall f1-score support0 0.865 0.767 0.813 5331551 0.159 0.269 0.200 87201accuracy 0.697 620356macro avg 0.512 0.518 0.507 620356
weighted avg 0.766 0.697 0.727 620356
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(DecisionTreeClassifier(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target'], cv=5
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.955 0.951 0.953 5331551 0.708 0.725 0.716 87201accuracy 0.919 620356macro avg 0.831 0.838 0.835 620356
weighted avg 0.920 0.919 0.920 620356
# 训练并验证MultinomialNB
pred = cross_val_predict(MultinomialNB(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.891 0.738 0.808 5331551 0.220 0.450 0.295 87201avg / total 0.797 0.698 0.736 620356
# 训练并验证RandomForestClassifier
pred = cross_val_predict(RandomForestClassifier(n_estimators=5),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.936 0.964 0.950 5331551 0.732 0.595 0.656 87201accuracy 0.912 620356macro avg 0.834 0.780 0.803 620356
weighted avg 0.907 0.912 0.909 620356
编写代码回答下面的问题:
- 在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
- 使用树模型训练,然后对特征重要性进行可视化;
- 再加入3个模型训练,对比模型精度;
问题一:在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
决策树的F1分数最好,是因为它的建模能力和解释性使其适用于许多问题。
问题二:使用树模型训练,然后对特征重要性进行可视化;
train_data.columns.drop(['udmap', 'common_ts', 'uuid', 'target'])
Index(['eid', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8','udmap_isunknown', 'key1', 'key2', 'key3', 'key4', 'key5', 'key6','key7', 'key8', 'key9', 'eid_freq', 'eid_mean', 'common_ts_hour'],dtype='object')
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as pltfrom sklearn.tree import export_graphviz
import graphviz
%matplotlib inlineX = train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
y = train_data['target']# 训练模型
dt_model = DecisionTreeClassifier()
dt_model.fit(X[0], y)
DecisionTreeClassifier()
tmp_dot_file = 'decision_tree_tmp.dot'
export_graphviz(dt_model, out_file=tmp_dot_file, feature_names=X[0].columns, class_names="target",filled=True, impurity=False)
with open(tmp_dot_file) as f:dot_graph = f.read()
graphviz.Source(dot_graph)
plt.figure(figsize=(18,12))# 绘制图像
_ = plot_tree(dt_model,filled = True,feature_names=X[0].columns) # 由于返回值不重要,因此直接用下划线接收
plt.show()
问题三:再加入3个模型训练,对比模型精度;
这里分别采用默认参数的岭回归分类器、极度随机树和梯度提升树进行训练得到结果
from sklearn.linear_model import RidgeClassifier
from sklearn.tree import ExtraTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
pred = cross_val_predict(RidgeClassifier(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.866 0.996 0.926 5331551 0.703 0.057 0.105 87201accuracy 0.864 620356macro avg 0.784 0.526 0.516 620356
weighted avg 0.843 0.864 0.811 620356
pred = cross_val_predict(ExtraTreeClassifier(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.936 0.935 0.935 5331551 0.604 0.609 0.607 87201accuracy 0.889 620356macro avg 0.770 0.772 0.771 620356
weighted avg 0.889 0.889 0.889 620356
pred = cross_val_predict(BaggingClassifier(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.949 0.978 0.963 5331551 0.834 0.677 0.747 87201accuracy 0.936 620356macro avg 0.891 0.828 0.855 620356
weighted avg 0.933 0.936 0.933 620356
任务2.3:特征工程
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.daytrain_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())##x3_freq和x4_freq存在为nan的值
#train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
#test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())#train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
#test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())
train_data.head()
| uuid | eid | udmap | common_ts | x1 | x2 | x3 | x4 | x5 | x6 | ... | x1_freq | x1_mean | x2_freq | x2_mean | x6_freq | x6_mean | x7_freq | x7_mean | x8_freq | x8_mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 26 | {"key3":"67804","key2":"650"} | 2023-07-18 09:44:28.244 | 4 | 0 | 41 | 107 | 206 | 1 | ... | 381218 | 0.139332 | 272402 | 0.126622 | 226935 | 0.153811 | 39042 | 0.358153 | 530689 | 0.12232 |
| 1 | 1 | 26 | {"key3":"67804","key2":"484"} | 2023-07-11 13:42:21.469 | 4 | 0 | 41 | 24 | 283 | 4 | ... | 381218 | 0.139332 | 272402 | 0.126622 | 392989 | 0.133067 | 77262 | 0.114649 | 530689 | 0.12232 |
| 2 | 2 | 8 | unknown | 2023-07-15 07:49:53.040 | 4 | 0 | 41 | 71 | 288 | 4 | ... | 381218 | 0.139332 | 272402 | 0.126622 | 392989 | 0.133067 | 185272 | 0.107151 | 530689 | 0.12232 |
| 3 | 3 | 11 | unknown | 2023-07-16 00:36:55.688 | 1 | 3 | 41 | 17 | 366 | 1 | ... | 95663 | 0.130155 | 125743 | 0.130671 | 226935 | 0.153811 | 130071 | 0.091688 | 530689 | 0.12232 |
| 4 | 4 | 26 | {"key3":"67804","key2":"650"} | 2023-07-16 07:15:51.442 | 0 | 3 | 41 | 92 | 383 | 4 | ... | 124004 | 0.136342 | 125743 | 0.130671 | 392989 | 0.133067 | 77262 | 0.114649 | 530689 | 0.12232 |
5 rows × 37 columns
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(DecisionTreeClassifier(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
precision recall f1-score support0 0.955 0.950 0.952 5331551 0.704 0.724 0.714 87201accuracy 0.918 620356macro avg 0.829 0.837 0.833 620356
weighted avg 0.919 0.918 0.919 620356
# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})
#由于这里进行特征工程后存在为0的值表示为nan,我们将nan值填充为0
相关文章:
用户新增预测(Datawhale机器学习AI夏令营第三期)
文章目录 简介任务1:跑通Baseline实操并回答下面问题:如果将submit.csv提交到讯飞比赛页面,会有多少的分数?代码中如何对udmp进行了人工的onehot? 任务2.1:数据分析与可视化编写代码回答下面的问题…...
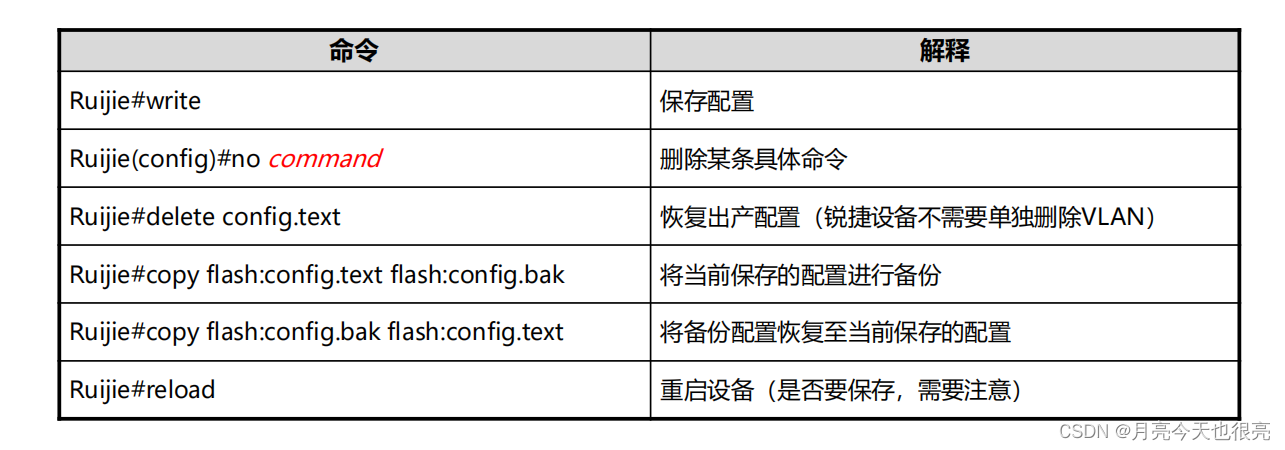
RGOS日常管理操作
RGOS日常管理操作 一、前言二、RGOS平台概述2.1、锐捷设备的常用登陆方式2.2、使用Console登入2.3、Telnet远程管理2.4、SSH远程管理2.5、登陆软件:SecureCRT 三、CLI命令行操作3.1、CLI命令行基础3.2、CLI模式3.3、CLI模式互换3.4、命令行特性3.4.1、分屏显示3.4.2…...
阿里云使用WordPress搭建个人博客
手把手教你使用阿里云服务器搭建个人博客 一、免费创建服务器实例 1.1 点击试用 点击试用会需要你创建服务器实例,直接选择默认的操作系统即可,点击下一步 1.2 修改服务器账号密码 二、创建云数据库实例 2.1 免费获取云数据库使用 2.2 实例列表页 在…...

供应链安全和第三方风险管理:讨论如何应对供应链中的安全风险,以及评估和管理第三方合作伙伴可能带来的威胁
第一章:引言 在当今数字化时代,供应链的安全性越来越受到重视。企业的成功不仅仅依赖于产品和服务的质量,还取决于供应链中的安全性。然而,随着供应链越来越复杂,第三方合作伙伴的参与也带来了一系列安全风险。本文将…...

《Java极简设计模式》第04章:建造者模式(Builder)
作者:冰河 星球:http://m6z.cn/6aeFbs 博客:https://binghe.gitcode.host 文章汇总:https://binghe.gitcode.host/md/all/all.html 源码地址:https://github.com/binghe001/java-simple-design-patterns/tree/master/j…...
Go download
https://go.dev/dl/https://golang.google.cn/dl/...
)
2023年Java核心技术面试第四篇(篇篇万字精讲)
目录 八. 对比Vector,ArrayList, LinkedList有何区别? 8.1 典型回答 8.1.1 Vector: 8.1.2 ArrayList : 8.1.3 LinkedList 8.2 考察点分析: 8.2.1 不同容器类型适合的场景 八. 对比Vector,ArrayList, Linke…...

数字化时代,数据仓库和商业智能BI系统演进的五个阶段
数字化在逐渐成熟的同时,社会上也对数字化的性质有了进一步认识。当下,数字化除了前边提到的将复杂的信息、知识转化为可以度量的数字、数据,在将其转化为二进制代码,引入计算机内部,建立数据模型,统一进行…...
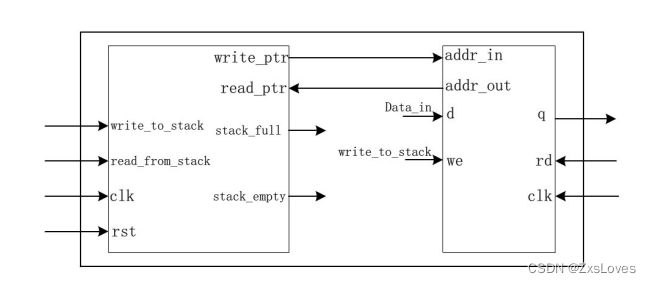
【【Verilog典型电路设计之FIFO设计】】
典型电路设计之FIFO设计 FIFO (First In First Out)是一种先进先出的数据缓存器,通常用于接口电路的数据缓存。与普通存储器的区别是没有外部读写地址线,可以使用两个时钟分别进行写和读操作。FIFO只能顺序写入数据和顺序读出数据࿰…...
JAVA设计模式总结之23种设计模式
一、什么是设计模式 设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计…...
Flutter 测试小结
Flutter 项目结构 pubspec.yaml 类似于 RN 的 package.json,该文件分别在最外层及 example 中有,更新该文件后,需要执行的 Pub get lib 目录下的 dart 文件为 Flutter 插件封装后的接口源码,方便在其他 dart 文件中调用 example 目…...

docker build -t 和 docker build -f 区别
docker build 是用于构建Docker镜像的命令,它允许你基于一个Dockerfile来创建一个镜像。在 docker build 命令中,有两个常用的选项 -t 和 -f,它们有不同的作用。 -t’选项: -t’选项用于指定构建出来的镜像的名称和标签。格式为 &…...

Java 项目日志实例基础:Log4j
点击下方关注我,然后右上角点击...“设为星标”,就能第一时间收到更新推送啦~~~ 介绍几个日志使用方面的基础知识。 1 Log4j 1、Log4j 介绍 Log4j(log for java)是 Apache 的一个开源项目,通过使用 Log4j,我…...
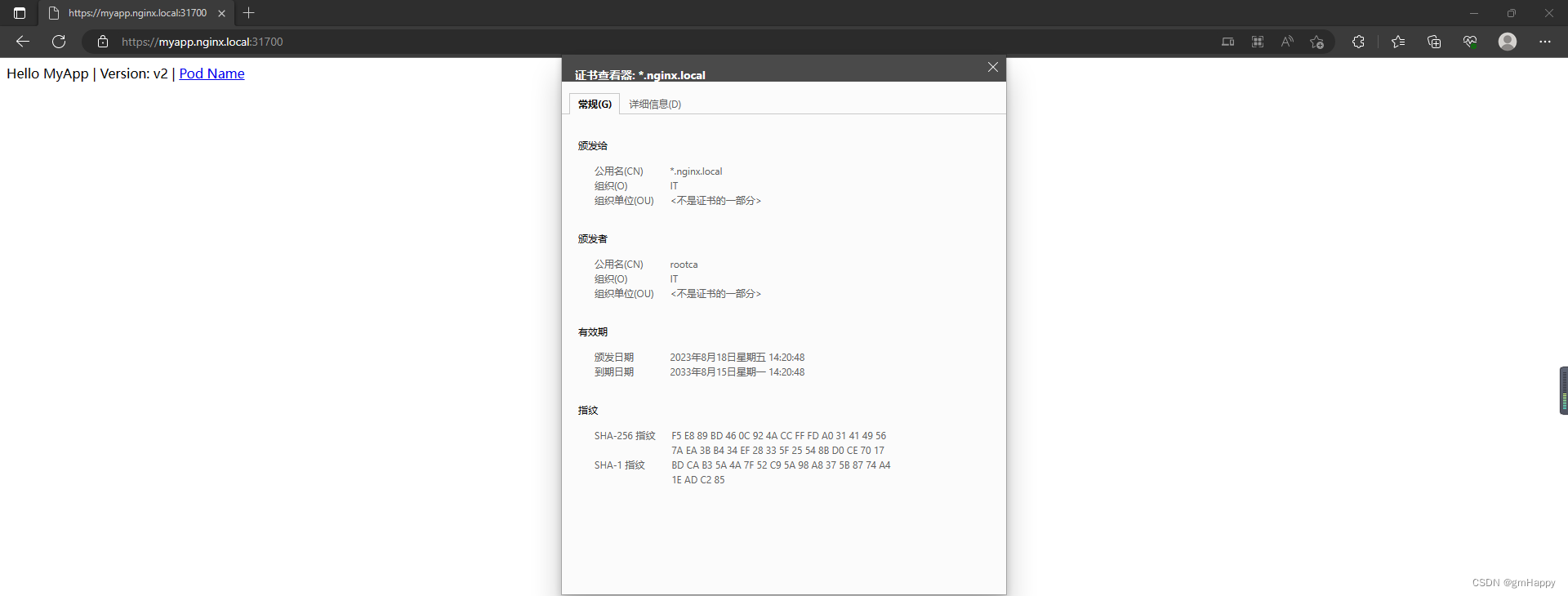
K8S应用笔记 —— 签发自签名证书用于Ingress的https配置
一、需求描述 在本地签发自命名证书,用于K8S集群的Ingress的https配置。 前提条件: 完成K8S集群搭建。完成证书制作机器的openssl服务安装。 二、自签名证书制作 2.1 脚本及配置文件准备 2.1.1 CA.sh脚本准备 注意事项: openssl服务默认CA…...
webpack 和 ts 简单配置及使用
如何使用webpack 与 ts结合使用 新建项目 ,执行项目初始化 npm init -y会生成 {"name": "tsdemo01","version": "1.0.0","description": "","main": "index.js","scripts&…...

MATLAB算法实战应用案例精讲-【图像处理】交并比
目录 交并比 非极大值抑制 Soft NMS Soft NMS 提出背景 Soft NMS 算法流程 Soft NMS 算法示例...
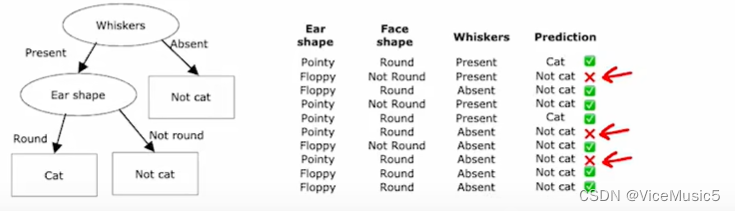
[Machine Learning] decision tree 决策树
(为了节约时间,后面关于机器学习和有关内容哦就是用中文进行书写了,如果有需要的话,我在目前手头项目交工以后,用英文重写一遍) (祝,本文同时用于比赛学习笔记和机器学习基础课程&a…...

【数学建模】-- 数学规划模型
概述: 什么是数学规划? 数学建模中的数学规划是指利用数学方法和技巧对问题进行数学建模,并通过数学规划模型求解最优解的过程。数学规划是一种数学优化方法,旨在找到使目标函数达到最大值或最小值的变量取值,同时满足…...

SpringBoot使用RabbitMQ自动创建Exchange和Queue
背景 小项目,使用RabbitMQ作为消息队列,发布到不同的新环境时,由于新搭建的MQ中不存在Exchange和Queue,就会出错,还得手动去创建,比较麻烦,于是想在代码中将这些定义好后,自动控制M…...
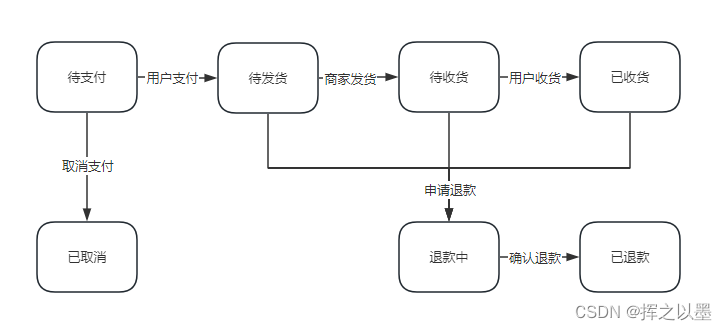
【设计模式】订单状态流传中的状态机与状态模式
文章目录 1. 前言2.状态模式2.1.订单状态流转案例2.1.1.状态枚举定义2.1.2.状态接口与实现2.1.3.状态机2.1.4.测试 2.2.退款状态的拓展2.2.1.代码拓展2.2.2.测试 2.3.小结 3.总结 1. 前言 状态模式一般是用在对象内部的状态流转场景中,用来实现状态机。 什么是状态…...

智能体状态管理:会话、上下文与检查点
从一个“跑了三天三夜的Agent突然失忆”说起,聊聊状态管理的那些坑先给你讲一个让我头皮发麻的运维事故。 去年冬天,我们做了一个自动爬取竞品价格并生成调价建议的Agent。它跑得很好,连续工作了三天,完成了两万多件商品的价格监控…...

Ti AWR2243实测:毫米波雷达通道积累,选相干还是非相干?一个实验讲清楚
Ti AWR2243毫米波雷达通道积累策略:工程实践中的深度抉择 毫米波雷达在现代自动驾驶系统中扮演着关键角色,而通道积累策略的选择直接影响着目标检测的精度与系统实时性。面对192个虚拟通道的海量数据,工程师们常常陷入两难:是追求…...

虚幻引擎网络协议逆向分析:从抓包到安全加固的工程实践
1. 项目概述与核心价值最近在游戏开发圈里,特别是那些深耕UE(Unreal Engine,虚幻引擎)网络同步和反外挂的同行们,可能都听说过或者正在研究一个叫venetianglassmaking858/UnrealClientProtocol的项目。这个名字听起来有…...

【DeepSeek本地部署终极指南】:20年AI架构师亲授,从零到生产级部署的7大避坑步骤
更多请点击: https://codechina.net 第一章:DeepSeek本地部署完整指南 DeepSeek系列大模型(如DeepSeek-V2、DeepSeek-Coder)已开源权重,支持在消费级GPU或本地服务器上高效部署。本指南聚焦零基础用户,提供…...
)
告别全屏地球!用Cesium.js在地图上只显示一个县(附完整代码)
用Cesium.js实现区域聚焦:打造专属行政区划三维地图 在WebGIS开发中,我们经常遇到需要将三维地球的显示范围限定在特定行政区划内的需求。无论是为了突出展示某个城市的发展规划,还是为了制作县域级别的专题地图,区域聚焦技术都能…...

AVPlayer 卡顿、缓冲、加载失败问题根治与监控方案
在 iOS 音视频开发中,AVPlayer 作为系统原生播放器,凭借其稳定性、兼容性和低功耗优势,成为大多数 App 的首选。但在实际落地过程中,卡顿、缓冲异常、加载失败三大问题,却常常成为开发者的“拦路虎”——弱网环境下频繁…...

如何用Win11Debloat轻松优化Windows系统:完整指南
如何用Win11Debloat轻松优化Windows系统:完整指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and custom…...

别再让电池充不满!用CN3791芯片设计太阳能充电电路,这几个调试坑我帮你踩了
太阳能充电电路实战:CN3791芯片调试避坑指南 当阳光洒在太阳能板上,理论上我们应该获得源源不断的清洁能源。但现实往往比理想骨感得多——尤其当你发现精心设计的CN3791充电电路始终无法将锂电池充满时。这不是芯片的错,而是我们在参数设置和…...

机器人抓取技能自动化:从仿真学习到现实迁移的实践指南
1. 项目概述与核心价值最近在机器人抓取领域,一个名为simpliolabs/manus-open-claw-skill-hunter-and-developer的项目引起了我的注意。乍一看这个标题,它像是一个开源工具或框架,核心围绕着“机械手开放爪具”的“技能猎人”与“开发者”。这…...

高校图书馆未公开的Perplexity学术协议:解锁DOI深度解析、跨库引文追踪与灰色文献捕获权限
更多请点击: https://codechina.net 第一章:高校图书馆未公开的Perplexity学术协议全景解析 Perplexity学术协议并非官方发布的标准规范,而是国内部分高校图书馆在采购或对接Perplexity Pro教育版API服务时,经谈判形成的定制化协…...