对比学习损失—InfoNCE理论理解
InfoNoise的理解
- InfoNCE loss
- 温度系数 τ \tau τ
InfoNCE loss
最近在看对比学习的东西,记录点基础的东西
「对比学习」 属于无监督学习的一种,给一堆数据,没有标签,自己学习出一种特征表示。
InfoNCE 这个损失是来自于论文:Momentum Contrast for Unsupervised Visual Representation Learning.
MoCo提出,我们可以把对比学习看成是一个字典查询的任务,即训练一个编码器从而去做字典查询的任务。假设已经有一个编码好的query q q q(一个特征),以及一系列编码好的样本 k 0 , k 1 , k 2 , . . . k_0, k_1, k_2,... k0,k1,k2,...,那么 k 0 , k 1 , k 2 , . . . k_0, k_1, k_2,... k0,k1,k2,...可以看作是字典里的key。假设字典里只有一个key k + k_+ k+(称为 positive)是跟 q q q 匹配的,它们就互为正样本对,其余的key为 q q q 的负样本。一旦定义好了正负样本对,就需要一个对比学习的损失函数来指导模型进行学习。
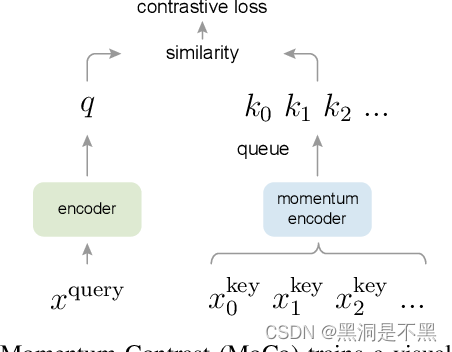
这个损失函数显然要满足要求:
- 当 q q q 和唯一的正样本 k + k_+ k+相似,并且和其他所有负样本key都不相似的时候,这个loss的值应该比较低。
- 当 q q q 和 k + k_+ k+ 不相似,或者和其他负样本的key相似了,那么loss就应该大,从而惩罚模型。
(嗯,合情合理,符合逻辑)
InfoNCE loss公式如下: L q = − l o g e x p ( q ⋅ k + / τ ) ∑ i = 0 k e x p ( q ⋅ k i / τ ) L_q=-log\frac{exp(q\cdot k_+ / \tau)}{\sum_{i=0}^k exp(q\cdot k_i / \tau)} Lq=−log∑i=0kexp(q⋅ki/τ)exp(q⋅k+/τ)Info NCE loss其实是NCE的一个简单变体,它认为如果只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理(但这里的多分类 k k k 指代的是负采样之后负样本的数量)。于是就有了InfoNCE loss
先看一下softmax公式: y ^ = s o f t m a x ( z ) = e x p ( z ) ∑ i = 0 k e x p ( z i ) \hat y=softmax(z)=\frac{exp(z)}{\sum_{i=0}^k exp(z_i)} y^=softmax(z)=∑i=0kexp(zi)exp(z)而交叉熵损失函数为: L ( y ^ ) = − ∑ i = 0 k y i l o g ( y ^ i ) L(\hat y)=-\sum_{i=0}^ky_ilog(\hat y_i) L(y^)=−i=0∑kyilog(y^i)仔细观察上面的交叉熵的计算公式可以知道,因为 y i y_i yi的元素不是0就是1,而且又是乘法,所以很自然地我们如果知道1所对应的index,那么就不用做其他无意义的运算了。
在监督学习下,ground truth是一个one-hot向量,softmax的 y ^ \hat y y^结果取 − l o g -log −log,再与ground truth相乘,即得到如下交叉熵损失: − l o g e x p ( z ) ∑ i = 0 k e x p ( z i ) -log\frac{exp(z)}{\sum_{i=0}^k exp(z_i)} −log∑i=0kexp(zi)exp(z)
上式中, q ⋅ k q\cdot k q⋅k 是模型出来的logits,相当于softmax公式中的 z z z, τ \tau τ是一个温度超参,是个标量,假设我们忽略,那么infoNCE loss其实就是cross entropy loss。唯一的区别是,在cross entropy loss里, k k k 指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个 k k k 指的是负样本的数量。上式分母中的 ∑ \sum ∑ 是在1个正样本和 k k k个负样本上做的,从0到k,所以共 k + 1 k+1 k+1 个样本,也就是字典里所有的key。MoCo里提到,InfoNCE loss其实就是一个cross entropy loss,做的是一个k+1类的分类任务,目的就是想把这个 q q q 图片分到 k + k_+ k+这个类。
温度系数 τ \tau τ
再来说一下这个温度系数 τ \tau τ,虽然只是一个超参数,但它的设置是非常讲究的,直接影响了模型的效果。
上式Info NCE loss中的相当于是logits,温度系数可以用来控制logits的分布形状。对于既定的logits分布的形状,当 τ \tau τ值变大,则 1 / τ 1/\tau 1/τ就变小,则 q ⋅ k / τ q\cdot k/\tau q⋅k/τ 会使得原来logits分布里的数值都变小,且经过指数运算之后,就变得更小了,导致原来的logits分布变得更平滑。相反,如果 τ \tau τ取得值小,就 1 / τ 1/\tau 1/τ 变大,原来的logits分布里的数值就相应的变大,经过指数运算之后,就变得更大,使得这个分布变得更集中,更加的peak。
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。
总之,温度系数的作用就是控制模型对负样本的区分度。
相关文章:
对比学习损失—InfoNCE理论理解
InfoNoise的理解 InfoNCE loss温度系数 τ \tau τ InfoNCE loss 最近在看对比学习的东西,记录点基础的东西 「对比学习」 属于无监督学习的一种,给一堆数据,没有标签,自己学习出一种特征表示。 InfoNCE 这个损失是来自于论文&am…...

贝锐蒲公英助力电子公交站牌联网远程运维,打造智慧出行新趋势
在现代城市公共交通系统中,我们随处可见电子公交站牌的身影。作为公共交通服务的核心之一,电子公交站牌的稳定运行至关重要,公交站台的实时公交状况、公共广告信息,是市民候车时关注的焦点。 某交通科技公司在承接某市智能电子站牌…...
SpringBoot + Vue 微人事(十)
职位管理前后端接口对接 先把table中的数据展示出来,table里面的数据实际上是positions里面的数据,就是要给positions:[] 赋上值 可以在methods中定义一个initPosition方法 methods:{//定义一个初始化positions的方法initPositions(){//发送一个get请求…...
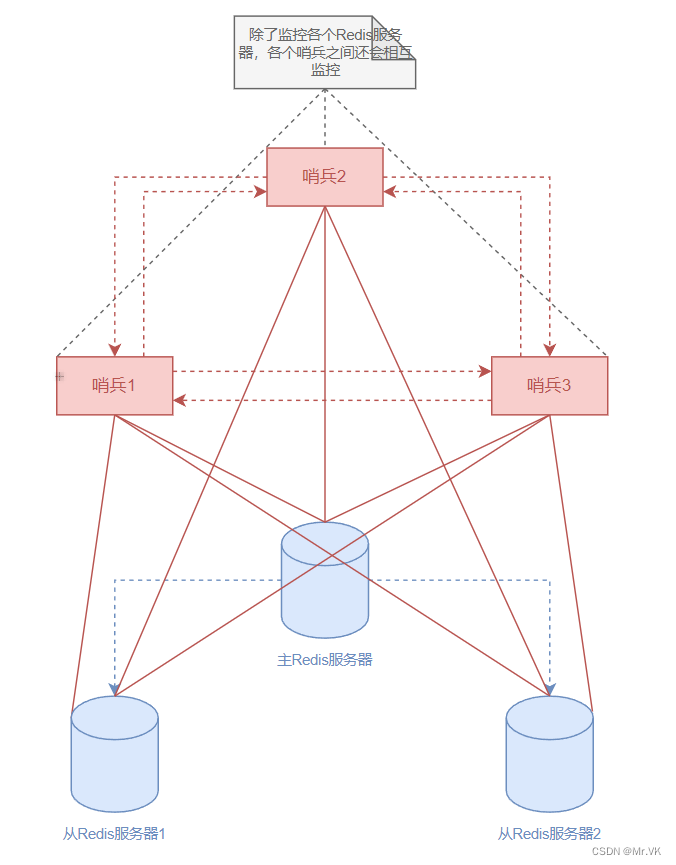
【Redis】Redis哨兵模式
【Redis】Redis哨兵模式 Redis主从模式当主服务器宕机后,需要手动把一台从服务器切换为主服务器,需要人工干预费事费力,为了解决这个问题出现了哨兵模式。 哨兵模式是是一个管理多个 Redis 实例的工具,它可以实现对 Redis 的监控…...
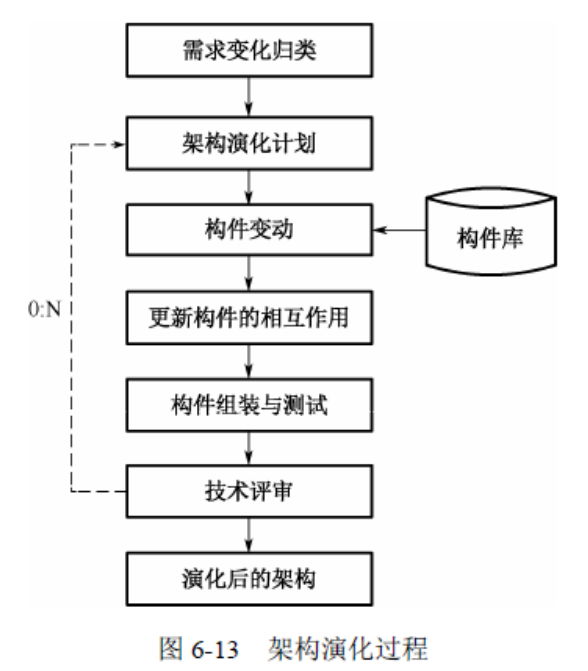
系统架构师---软件重用、基于架构的软件设计、软件模型
目录 软件重用 构件技术 基于架构的软件设计 ABSD方法与生命周期 抽象功能需求 用例 抽象的质量和业务需求 架构选项 质量场景 约束 基于架构的软件开发模型 架构需求 需求获取 标识构件 需求评审 架构设计 架构文档 架构复审 架构实现 架构演化 前言&…...
【Web开发指南】MyEclipse XML编辑器的高级功能简介
MyEclipse v2023.1.2离线版下载 1. 在MyEclipse中编辑XML 本文档介绍MyEclipse XML编辑器中的一些可用的函数,MyEclipse XML编辑器包括高级XML编辑,例如: 语法高亮显示标签和属性内容辅助实时验证(当您输入时)文档内容的源(Sou…...
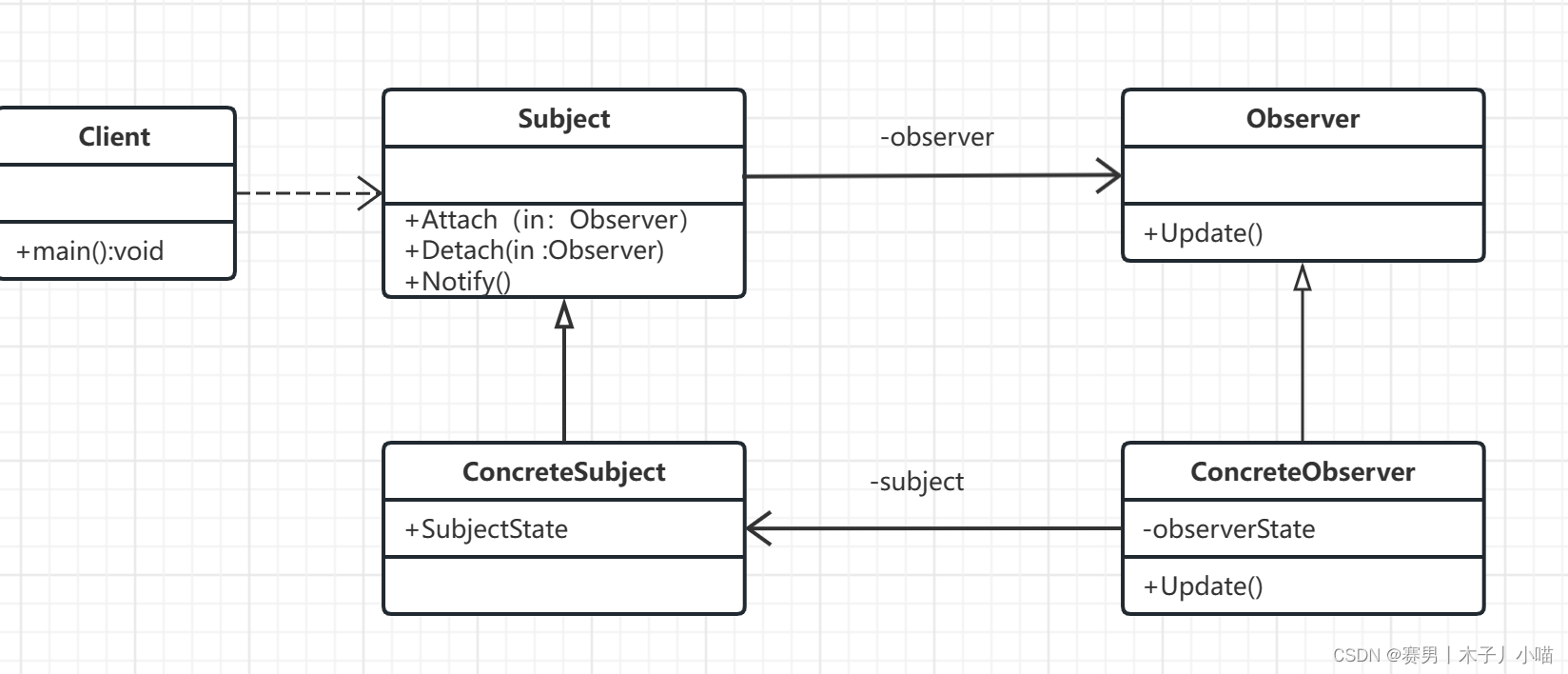
设计模式-观察者模式(观察者模式的需求衍变过程详解,关于监听的理解)
目录 前言概念你有过这样的问题吗? 详细介绍原理:应用场景: 实现方式:类图代码 问题回答监听,为什么叫监听,具体代码是哪观察者模式的需求衍变过程观察者是为什么是行为型 总结: 前言 在软件设计…...

vue+electron中实现文件下载打开wps预览
下载事件 win.webContents.downloadURL(url) 触发session的will-download事件 win.webContents.session.on(will-download, (event, downloadItem, webContents) > {// 设置文件保存路径// 如果用户没有设置保存路径,Electron将使用默认方式来确定保存路径&am…...

第4章 性能分析中的术语和指标
Linux perf和Intel VTune Profiler工具。 4.1 退休指令与执行指令 考虑到投机执行,CPU执行的指令要不退休指令多。Linux perf使用perf stat -e instruction ./a.exe即可获得退休指令的数量。 4.2 CPU利用率 CPU利用率表示在一段时间内的繁忙程度,用时…...

数字化转型能带来哪些价值?_光点科技
随着科技的迅猛发展,数字化转型已成为企业和组织的一项重要战略。它不仅改变了商业模式和运营方式,还为各行各业带来了诸多新的机遇和价值。在这篇文章中,我们将探讨数字化转型所能带来的价值。 数字化转型能够显著提升效率和生产力。通过引入…...
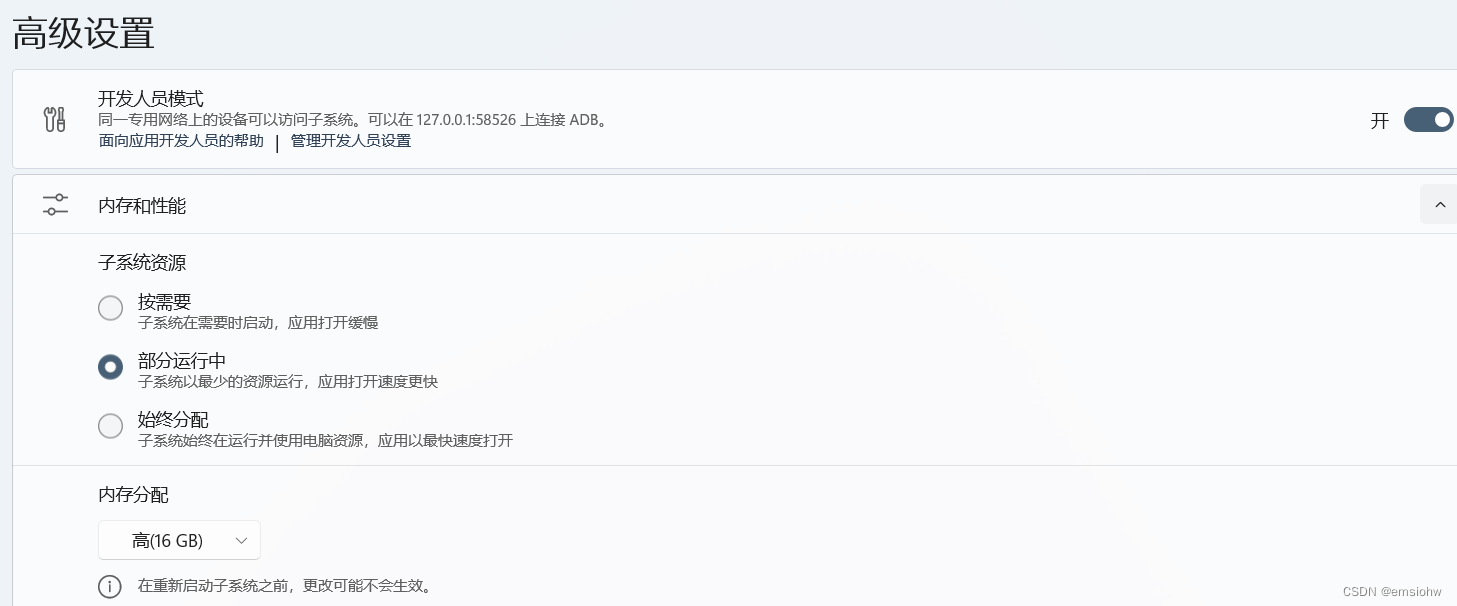
适用于Android™的Windows子系统Windows Subsystem fo r Android™Win11安装指南
文章目录 一、需求二、Windows Subsystem for Android™Win11简介三、安装教程1.查看BIOS是否开启虚拟化2.安装Hyper-V、虚拟机平台3.启动虚拟机管理程序(可选)4.安装适用于Android™的Windows子系统5.相关设置 一、需求 需要在电脑上进行网课APP(无客户端只有App&…...

hive高频使用的拼接函数及“避坑”
hive高频使用的拼接函数及“避坑” 说到拼接函数应用场景和使用频次还是非常高,比如一个员工在公司充当多个角色,我们在底层存数的时候往往是多行,但是应用的时候我们通常会只需要一行,角色字段进行拼接,这样join其他…...
windows ipv4 多ip地址设置,默认网关跃点和自动跃点是什么意思?(跃点数)
文章目录 Windows中的IPv4多IP地址设置以及默认网关跃点和自动跃点的含义引言IPv4和IPv6:简介多IP地址设置:Windows环境中的实现默认网关跃点:概念和作用自动跃点:何时使用?关于“跃点数”如何确定应该设置多少跃点数&…...
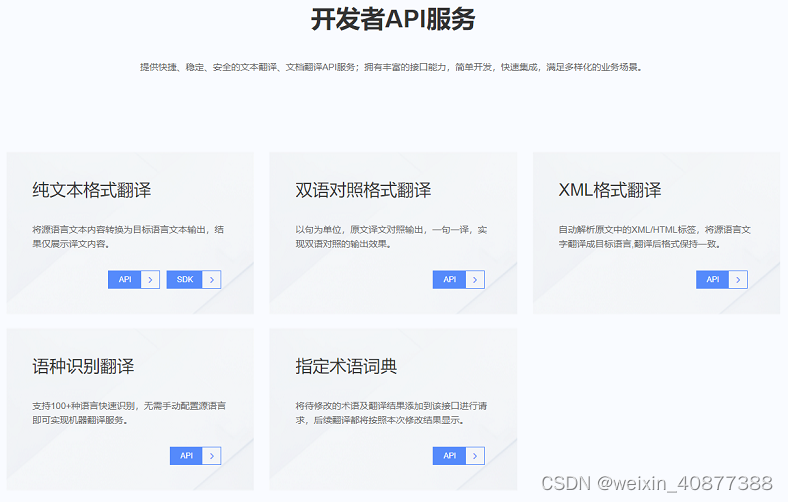
java_免费文本翻译API_小牛翻译
目录 前言 开始集成API 纯文本翻译接口 双语对照翻译接口 指定术语翻译接口 总结 前言 网络上对百度,有道等的文本翻译API集成的文章比较多,所以集成的第一篇选择了小牛翻译的文本翻译API。 小牛翻译文本翻译API,支持388个语种࿰…...

flink消费kafka数据,按照指定时间开始消费
kafka中根据时间戳开始消费数据 import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.OffsetRese…...

【SpringCloud】Feign使用
文章目录 配置maven启动类添加yml 使用添加Feign服务Controller 其他设置超时设置YML开启OpenFeign客户端超时控制(Ribbon Timeout)OpenFeign日志打印功能日志级别YML开启日志 配置 maven <dependencies><!--openfeign--><dependency&g…...

WebApIs 第五天
window对象 BOM(浏览器对象模型)定时器-延时函数JS执行机制location对象navigator对象histroy对象 本地存储 一.BOM(浏览器对象模型) ① BOM是浏览器对象模型 window 对象是一个全局对象,也可以说是JavaScript中的…...

按斤称的C++散知识
一、多线程 std::thread()、join() 的用法:使用std::thread()可以创建一个线程,同时指定线程执行函数以及参数,同时也可使用lamda表达式。 #include <iostream> #include <thread>void threadFunction(int num) {std::cout <…...

C++策略模式
1 简介: 策略模式是一种行为型设计模式,用于在运行时根据不同的情况选择不同的算法或行为。它将算法封装成一个个具体的策略类,并使这些策略类可以相互替换,以达到动态改变对象的行为的目的。 2 实现步骤: 以下是使用…...

如何在网页下载腾讯视频为本地MP4格式
1.打开腾讯视频官网地址 腾讯视频 2.搜索你想要下载的视频 3. 点击分享,选择复制通用代码 <iframe frameborder="0" src="ht...

Wan2.2-I2V-A14B图像转视频实战:基于卷积神经网络的风格迁移与动态生成
Wan2.2-I2V-A14B图像转视频实战:基于卷积神经网络的风格迁移与动态生成 1. 引言:当静态艺术遇见动态魔法 想象一下,你手中有一幅精美的水墨画或一张概念设计草图,如果能让它"活过来",变成一段流动的视频&a…...

ComfyUI-WanVideoWrapper显存优化终极指南:让8GB显卡也能流畅生成高清视频
ComfyUI-WanVideoWrapper显存优化终极指南:让8GB显卡也能流畅生成高清视频 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 还在为视频生成时的显存不足而烦恼吗?ComfyUI-…...

春招已经过半,这一波再不动手,基本就没位置了
关注 霍格沃兹测试学院公众号,回复「资料」,领取人工智能测试开发技术合集导读3月底这个时间点,如果你还在纠结“要不要投”,那基本已经慢半拍了。现在的真实情况是:大厂已经进入筛选面试并行阶段一部分公司已经开始发…...

异构计算与边缘协同:基于 ARM/X86 的企业级 AI 视频中台架构设计
引言:算力碎片化时代的“异构”挑战 在 AI 落地安防的深水区,架构师面临的最大挑战不再是算法模型的精度,而是算力底座的碎片化。项目现场往往呈现出复杂的“万国牌”局面:总部机房可能部署着 NVIDIA A100 的 x86 服务器用于离线训…...

5分钟终极指南:Windows虚拟手柄驱动ViGEmBus完整教程
5分钟终极指南:Windows虚拟手柄驱动ViGEmBus完整教程 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows系统上享受专业级的游戏控制体…...

告别手速焦虑:Python大麦网自动抢票脚本终极指南
告别手速焦虑:Python大麦网自动抢票脚本终极指南 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 还在为心仪演出门票秒光而烦恼吗?每次热门演唱会开票…...

解锁知识:9种突破信息壁垒的创新方案
解锁知识:9种突破信息壁垒的创新方案 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在信息爆炸的数字时代,高效的"信息获取"与"资源解锁"…...

Fish Speech 1.5 Web界面保姆级教程:上传参考音频→文本对齐→语音生成全链路
Fish Speech 1.5 Web界面保姆级教程:上传参考音频→文本对齐→语音生成全链路 你是不是也想用AI生成和自己声音一模一样的语音?Fish Speech 1.5就能帮你实现这个愿望!这个强大的语音合成工具不仅能生成自然流畅的语音,还能通过参…...

Kook Zimage 真实幻想 Turbo在软件测试中的应用:自动化UI设计验证
Kook Zimage 真实幻想 Turbo在软件测试中的应用:自动化UI设计验证 1. 引言:UI设计验证的痛点与机遇 在软件开发流程中,UI设计验证一直是个让人头疼的环节。测试人员需要对照设计稿,逐个像素检查界面元素的位置、颜色、字体和布局…...

Wan2.2-I2V-A14B企业级部署案例:单卡24GB显存实现高并发视频API服务
Wan2.2-I2V-A14B企业级部署案例:单卡24GB显存实现高并发视频API服务 1. 企业级视频生成解决方案概述 在数字内容创作领域,视频生成技术正经历革命性变革。Wan2.2-I2V-A14B作为新一代文生视频模型,通过私有化部署方案,为企业提供…...