Spark第三课
1.分区规则
1.分区规则
shuffle
1.打乱顺序
2.重新组合
1.分区的规则
默认与MapReduce的规则一致,都是按照哈希值取余进行分配.
一个分区可以多个组,一个组的数据必须一个分区
2. 分组的分区导致数据倾斜怎么解决?
- 扩容 让分区变多
- 修改分区规则
3.HashMap扩容为什么必须是2的倍数?
当不是2的倍数时, 好多的位置取不到
比如 为5 01234 123都取不到
必须保证,相关的位数全是1,所以必定2的倍数 2的n次方
所以位运算不是什么时候都能用的

2.转换算子
1.单值转换算子
1.filter过滤器
1.注意
过滤只是将数据进行校验,而不是修改数据. 结果为true就保留,false就丢弃
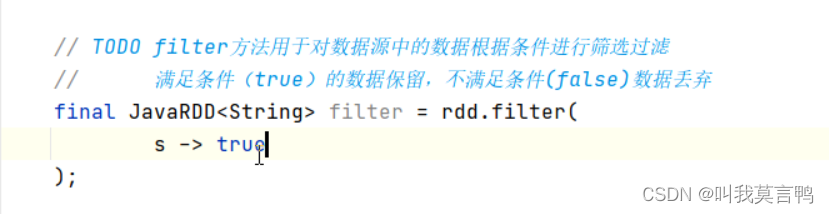
2.代码
JavaSparkContext sc = new JavaSparkContext("local[*]","filter");List<String> dataList = Arrays.asList("giao","giao2","zhangsan","lisi");
JavaRDD<String> rdd1 = sc.parallelize(dataList);
//JavaRDD<String> rddFilter1 = rdd1.filter(null);
JavaRDD<String> rddFilter2= rdd1.filter(s->s.substring(0,1).toLowerCase().equals("g"));
//rddFilter1.collect().forEach(System.out::println);
System.out.println("----------------------------");
rddFilter2.collect().forEach(System.out::println);
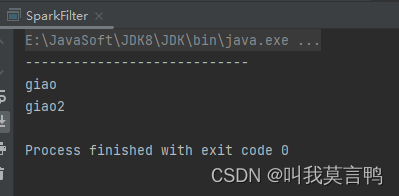
2.dinstinct
1.原理
分组
通过使用分组取重,相同的话,都是一个组了,所以Key唯一
应该是先分组,然后吧K提出来就好了
2.代码
JavaSparkContext sc = new JavaSparkContext("local[*]","Distinct");List<String> dataList = Arrays.asList("giao1","gg1","gg1","gg2","gg2","gg1","gg3","gg1","gg5","gg3");
JavaRDD<String> rdd1 = sc.parallelize(dataList);
JavaRDD<String> rddDistinct = rdd1.distinct();
rddDistinct.collect().forEach(System.out::println);
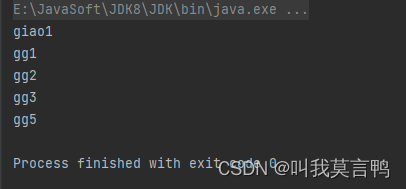
3.排序
1.介绍
sortby方法需要传3个参数
参数1 排序规则
参数2 升序还是降序(false) 默认升序(true)
参数3 排序的分区数量(说明方法底层是靠shuffle实现,所以才有改变分区的能力)
2.排序规则
排序规则,是按照结果去排序
其实是用结果生成一个K值,通过K值进行排序,然后展示 V值
或者说权值, 按照权值排序
将Value变成K V
3.代码
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","SparkSort");List<String> dataList = Arrays.asList("kunkun","giaogiao","GSD","JJ","chenzhen","Lixiaolong");JavaRDD<String> rdd1 = sc.parallelize(dataList);JavaRDD<String> rddSort = rdd1.sortBy(s -> {switch (s.substring(0, 1).toLowerCase()) {case "k":return 5;case "g":return 3;case "j":return 1;case "c":return 2;case "l":return 4;}return null;}, false, 3);rddSort.collect().forEach(System.out::println);}
2.键值对转换算子
1.介绍
1.什么是键值对转换算子
如何区分是键值对方法还是单值方法呢?
通过参数来判断, 如果参数是一个值,就是单值,如果是2个,就是键值对
2.元组是不是键值对?
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","KVRDD");List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);JavaRDD<Integer> rdd1 = sc.parallelize(dataList);JavaRDD<Tuple2> rddmap = rdd1.map(num -> new Tuple2(num, num));rddmap.collect().forEach(System.out::println);
}
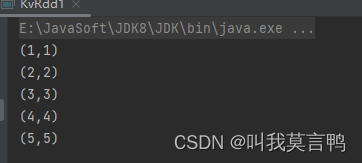
答案是,不是,因为这个的返回值,是一个元组,而元组整体,是一个单值,所以,是单值
只有返回值 是RDD<K1,V1 >的时候,才是键值对类型算子
3. 使用Pair转换键值对算子
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","RddPair");List<Integer> dataList = Arrays.asList(1, 2, 3, 4, 5);JavaRDD<Integer> rdd = sc.parallelize(dataList);JavaPairRDD<Integer, Integer> rddPair = rdd.mapToPair(num -> new Tuple2<>(num, num));rddPair.collect().forEach(System.out::println);}
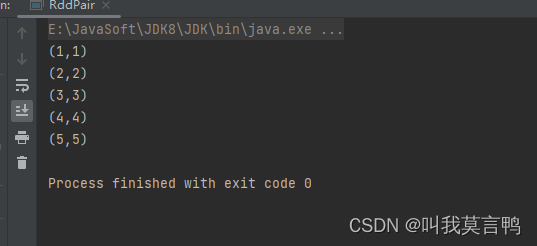
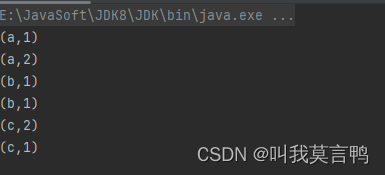
4.直接在获取时转换键值对
这里使用的是parallelizePairs方法 获取的是JavaPairRDD
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","KVRDD");JavaPairRDD<String, Integer> rddPair = sc.parallelizePairs(Arrays.asList(new Tuple2<>("a", 1),new Tuple2<>("a", 2),new Tuple2<>("b", 1),new Tuple2<>("b", 1),new Tuple2<>("c", 2),new Tuple2<>("c", 1)));rddPair.collect().forEach(System.out::println);}
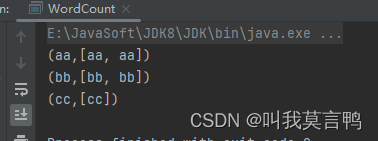
5.分组来获取键值对
```java
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","RddPair");List<String> dataList = Arrays.asList("aa","bb","aa","bb","cc");JavaRDD<String> rdd = sc.parallelize(dataList);JavaPairRDD<Object, Iterable<String>> rddGroup = rdd.groupBy(s->s);rddGroup.collect().forEach(System.out::println);
}
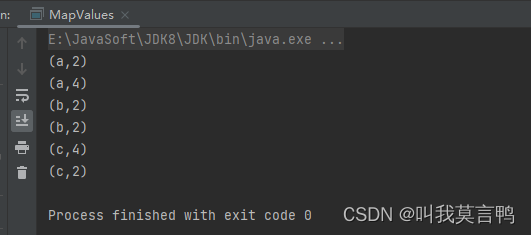
2.mapValue方法
1.介绍
直接对value进行操作,不需要管K
当然,也有mapKey方法可以无视Value操作Key
2.代码演示
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","KVRDD");JavaPairRDD<String, Integer> rddPair = sc.parallelizePairs(Arrays.asList(new Tuple2<>("a", 1),new Tuple2<>("a", 2),new Tuple2<>("b", 1),new Tuple2<>("b", 1),new Tuple2<>("c", 2),new Tuple2<>("c", 1)));JavaPairRDD<String, Integer> mapV = rddPair.mapValues(num -> num * 2);mapV.collect().forEach(System.out::println);}
3.WordCount实现
iter.spliterator().estimateSize());
spliterator
Spliterator(Split Iterator)是Java 8引入的一个新接口,用于支持并行遍历和操作数据。它是Iterator的扩展,可以用于在并行流(Parallel Stream)中对数据进行划分和遍历,从而实现更高效的并行处理
spliterator()方法是在Iterable接口中定义的一个默认方法,用于生成一个Spliterator对象,以支持数据的并行遍历。它的具体作用是将Iterable中的数据转换为一个可以在并行流中使用的Spliterator对象。
estimateSize
estimateSize()方法是Java中Spliterator接口的一个方法,用于估算Spliterator所包含的元素数量的大小。Spliterator是用于支持并行遍历和操作数据的接口,而estimateSize()方法提供了一个估计值,用于在处理数据时预测Spliterator包含的元素数量。
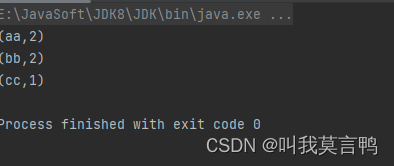
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","RddPair");List<String> dataList = Arrays.asList("aa","bb","aa","bb","cc");JavaRDD<String> rdd = sc.parallelize(dataList);JavaPairRDD<Object, Iterable<String>> rddGroup = rdd.groupBy(s->s);JavaPairRDD<Object, Long> wordCount = rddGroup.mapValues(iter -> iter.spliterator().estimateSize());wordCount.collect().forEach(System.out::println);
}
3.groupby 与groupByKey
1 .代码
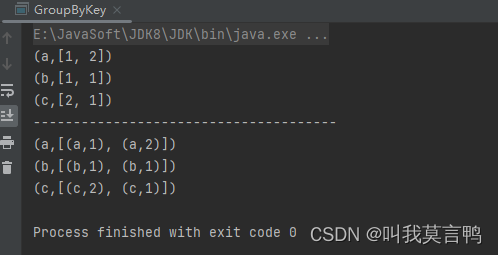
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","G1");JavaPairRDD<String, Integer> rddPair;rddPair = sc.parallelizePairs(Arrays.asList(new Tuple2<>("a", 1),new Tuple2<>("a", 2),new Tuple2<>("b", 1),new Tuple2<>("b", 1),new Tuple2<>("c", 2),new Tuple2<>("c", 1)));JavaPairRDD<String, Iterable<Integer>> rddGroupByKey = rddPair.groupByKey();JavaPairRDD<String, Iterable<Tuple2<String, Integer>>> rddGroupBy = rddPair.groupBy(t -> t._1);rddGroupByKey.collect().forEach(System.out::println);}
2.分析区别
- 1.参数
GroupBy是自选规则 而GroupByKey是将PairRDD的Key当做分组规则 - 2.结果
GroupBy是将作为单值去分组,即使RDD是Pair, 而GroupByKey 则是将K V分开 ,将V作为组成员
3.注意
GroupByKey是不能进行随意使用的,底层用的含有shuffle,如果计算平均值,就不能通过GroupByKey直接进行计算.
4.reduce与reduceByKey
1.介绍
多个变量进行同样的运算规则
Stream是1.8新特性,
计算的本质 两两结合
reduce
2. 代码
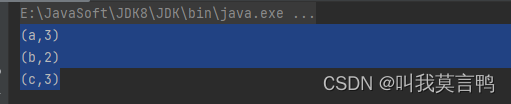
public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","Reduce");JavaPairRDD<String, Integer> rddPair;rddPair = sc.parallelizePairs(Arrays.asList(new Tuple2<>("a", 1),new Tuple2<>("a", 2),new Tuple2<>("b", 1),new Tuple2<>("b", 1),new Tuple2<>("c", 2),new Tuple2<>("c", 1)));rddPair.reduceByKey(Integer::sum).collect().forEach(System.out::println);}
3.理解
相同Key值的V进行运算,所以底层是有分组的,所以底层是一定有Shuffle,一定有改变分区的能力,改变分区数量和分区规则.
4.与groupByKey区别
reduceByKey
将相同key的数量中1的V进行两两聚合
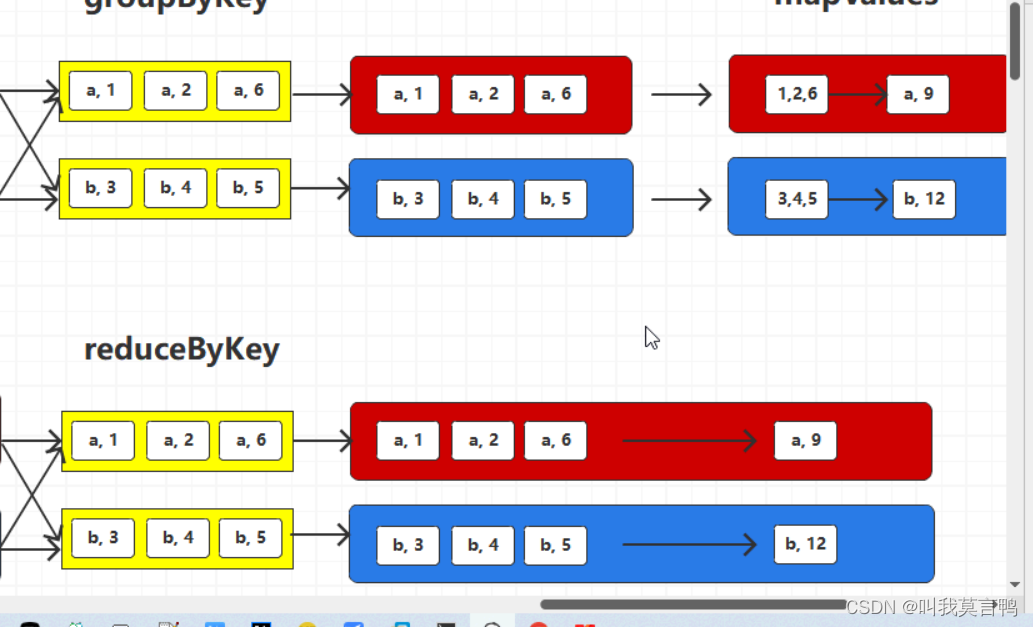
reduceByKey 相同的key两两聚合,在shuffle落盘之前对分区内数据进行聚合,这样会减少落盘数据量,并不会影响最终结果(预聚合) 这就是combine
有钱先整IBM小型机
Shuffle优化
1.花钱
2.调大缓冲区(溢出次数减少)
3.
sortByKey
想比较必须实现可比较的接口
默认排序规则为升序,
通过K对键值对进行排序
行动算子
通过调用RDD方法让Spark的功能行动起来

map 是在new

转换算子 得到的是RDD
注意 转换跑不起来 行动能跑起来 这句话是错误的
当使用sort时,也是能跑起来的,但是还是转换算子
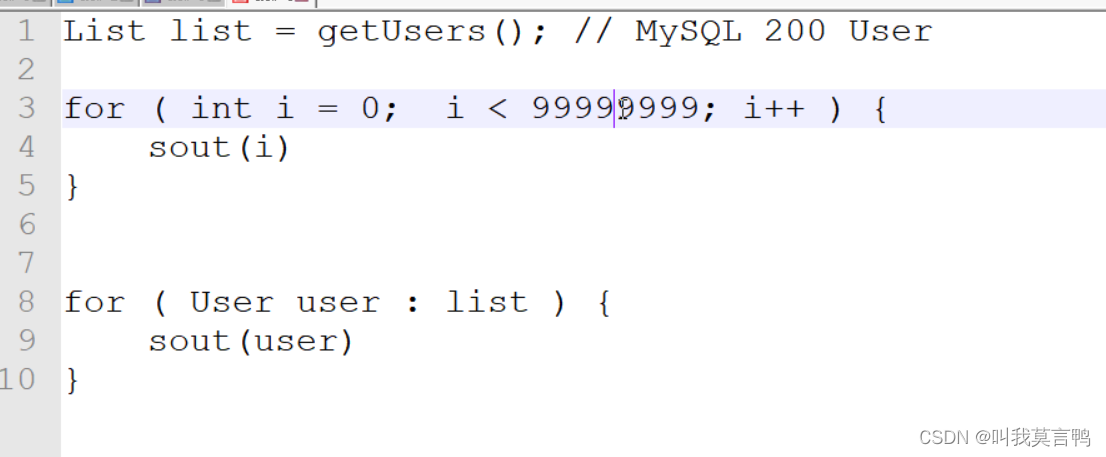
第一行运行占用内存,第一个for 运算需要内存,但是第一行占用了大量内存,所以第一行浪费了,这就需要懒加载,所以第一行的执行时机是在第二个for运行前使用的.
注意map collect 不是懒加载,只是没人调用他的job(RDD算子内部的代码)
RDD算子外部的代码都是在Driver端
相关文章:
Spark第三课
1.分区规则 1.分区规则 shuffle 1.打乱顺序 2.重新组合 1.分区的规则 默认与MapReduce的规则一致,都是按照哈希值取余进行分配. 一个分区可以多个组,一个组的数据必须一个分区 2. 分组的分区导致数据倾斜怎么解决? 扩容 让分区变多修改分区规则 3.HashMap扩容为什么必须…...

LangChain手记 Chains
整理并翻译自DeepLearning.AILangChain的官方课程:Chains(源代码可见) Chains 直译链,表达的意思更像是对话链,对话链的背后是思维链 LLM Chain(LLM链) 首先介绍了一个最简单的例子,…...

ONNX版本YOLOV5-DeepSort (rknn版本已经Ready)
目录 1. 前言 2. 储备知识 3. 准备工作 4. 代码修改的地方 5.结果展示 1. 前言 之前一直在忙着写文档,之前一直做分类,检测和分割,现在看到跟踪算法,花了几天时间找代码调试,看了看,展示效果比单纯的检…...

MySQL的约束
文章目录 1、约束的概念2、约束的分类2.1 主键约束2.1.1 概念2.1.2 主键操作 2.2 自增约束2.2.1 概念2.2.2 自增操作 2.3 唯一约束2.3.1 概念2.3.2 唯一操作 2.4 非空约束2.4.1 概念2.4.2 非空操作 2.5 默认约束2.5.1 概念2.5.2 默认操作 2.6 外键约束2.6.1 概念2.6.2 外键操作…...

Lnton羚通关于【PyTorch】教程:torchvision 目标检测微调
torchvision 目标检测微调 本教程将使用Penn-Fudan Database for Pedestrian Detection and Segmentation 微调 预训练的Mask R-CNN 模型。 它包含 170 张图片,345 个行人实例。 定义数据集 用于训练目标检测、实例分割和人物关键点检测的参考脚本允许轻松支持添加…...

AMD fTPM RNG的BUG使得Linus Torvalds不满
导读因为在 Ryzen 系统上对内核造成了困扰,Linus Torvalds 最近在邮件列表中表达了对 AMD fTPM 硬件随机数生成器的不满,并提出了禁用该功能的建议。 因为在 Ryzen 系统上对内核造成了困扰,Linus Torvalds 最近在邮件列表中表达了对 AMD fTPM…...
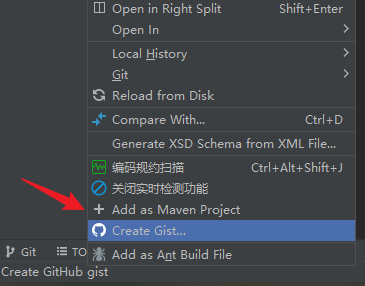
idea 转换为 Maven Project 的方法
选项: Add as Maven Project...

es1.7.2 按照_type先聚合,再按照时间二次聚合
// 设置查询条件if (this.query ! null) {this.searchbuilder.setQuery(this.query);}TermsBuilder typeAggregation AggregationBuilders.terms("agg_type").field("_type");DateHistogramBuilder dateTermsBuilder AggregationBuilders.dateHistogram(…...

pyqt5 如何修改QplainTextEdit 背景色和主窗口的一样颜色
如果您希望将 QPlainTextEdit 的背景颜色设置为与窗口背景相似的灰色,您可以使用窗口的背景颜色作为基准来设置 QPlainTextEdit 的背景颜色。以下是一个示例代码,展示如何实现这一点: from PyQt5.QtWidgets import QApplication, QMainWindo…...

解决使用element ui时el-input的属性type=number,仍然可以输入e的问题。
使用element ui时el-input的属性typenumber,仍然可以输入e, 其他的中文特殊字符都不可以输入,但是只有e是可以输入的,原因是e也输入作为科学计数法的时候,e是可以被判定为数字的, 但是有些场景是需要把e这种…...

ShardingSphere 可观测 SQL 指标监控
ShardingSphere并不负责如何采集、存储以及展示应用性能监控的相关数据,而是将SQL解析与SQL执行这两块数据分片的最核心的相关信息发送至应用性能监控系统,并交由其处理。 换句话说,ShardingSphere仅负责产生具有价值的数据,并通过…...

Redisson实现分布式锁示例
一、引入依赖 <dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.16.0</version></dependency>二、配置类 import org.redisson.Redisson; import org.redisson.api.RedissonClient;…...

使用Nginx作为一个普通代理服务器
使用Nginx作为一个普通代理服务器, 请不要用于违法用途哦 nginx作为一个反向代理工具,除了可以进行反向代理之外,还可以用来作为代理工具来使用,作为代理工具使用的步骤如下,这个配置目前支持80端口 Windows系统代理设置对应IP, …...
chatglm2-6b模型在9n-triton中部署并集成至langchain实践 | 京东云技术团队
一.前言 近期, ChatGLM-6B 的第二代版本ChatGLM2-6B已经正式发布,引入了如下新特性: ①. 基座模型升级,性能更强大,在中文C-Eval榜单中,以51.7分位列第6; ②. 支持8K-32k的上下文;…...

Shell编程之正则表达式(非常详细)
正则表达式 1.通配符和正则表达式的区别2.基本正则表达式2.1 元字符 (字符匹配)2.2 表示匹配次数2.4 位置锚定2.5 分组 和 或者 3.扩展正则表达式4.部分文本处理工具4.1 tr 命令4.2 cut命令4.3 sort命令4.4 uniq命令 1.通配符和正则表达式的区别 通配符一般用于文件…...
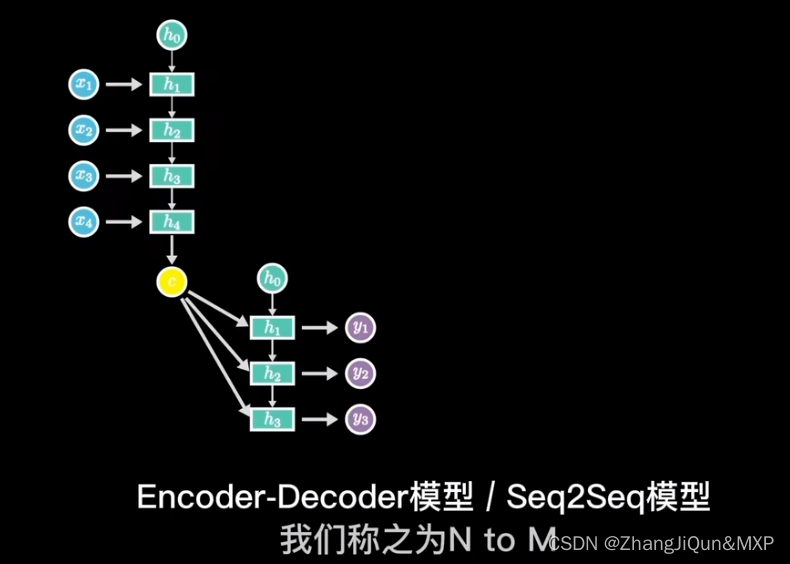
RNN模型简单理解和CNN区别
目录 神经网络:水平方向延伸,数据不具有关联性 RNN:在神经网络的基础上加上了时间顺序,语义理解 RNN: 训练中采用梯度下降,反向传播 长短期记忆模型 输出关系:1 toN,N to N 单入…...
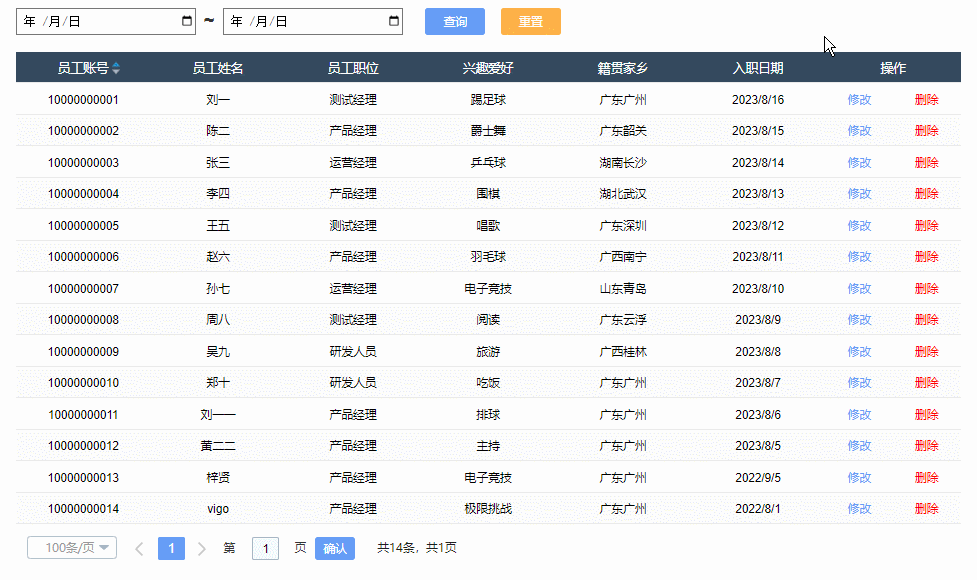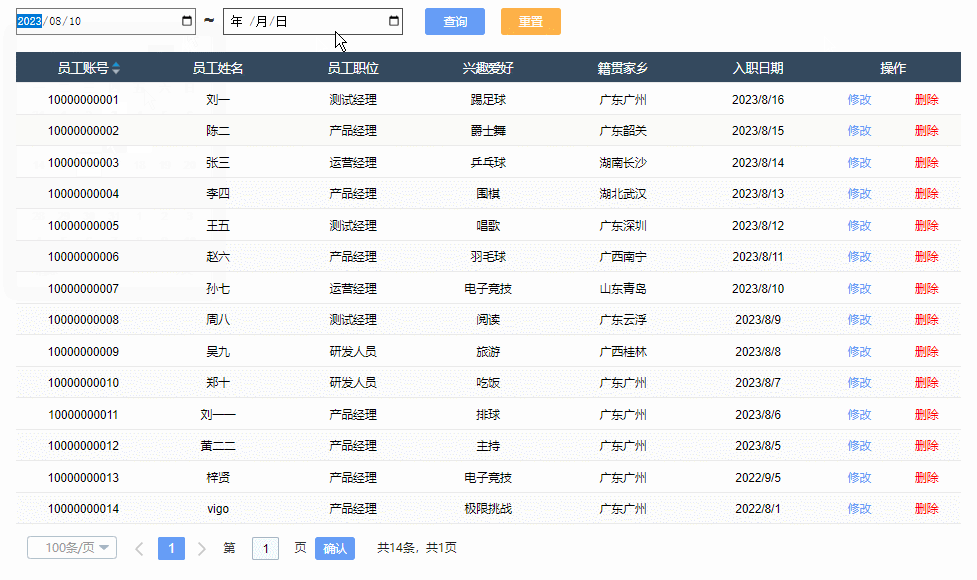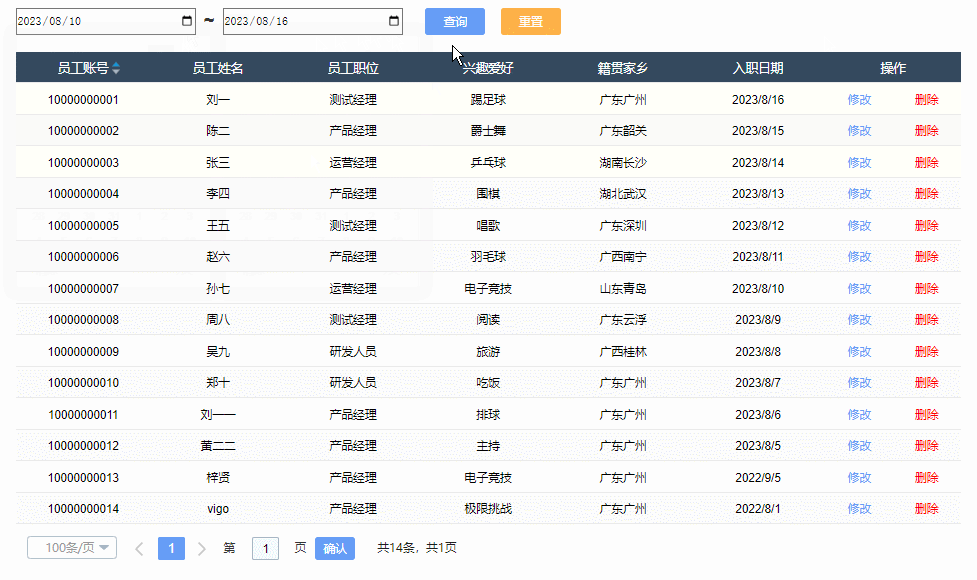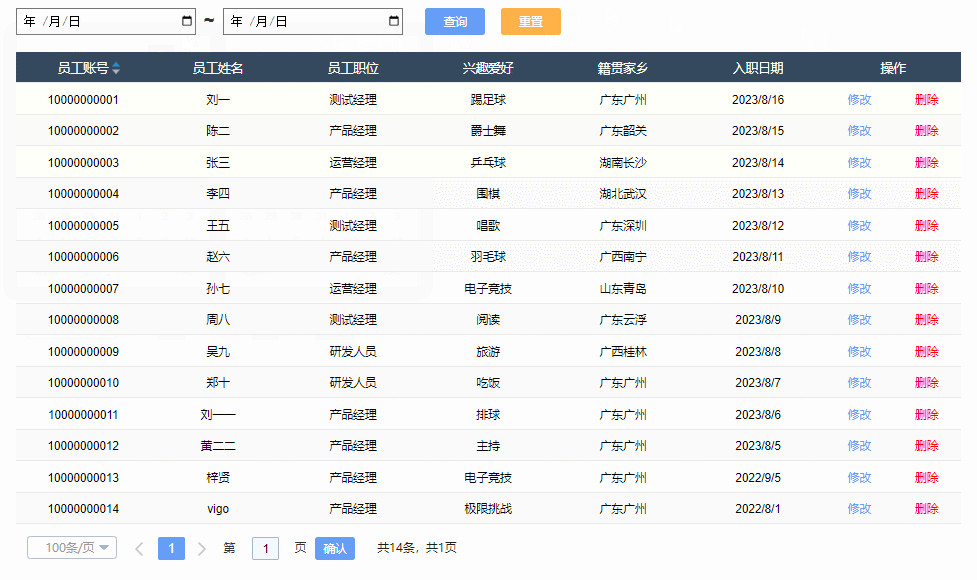
【Axure高保真原型】JS日期选择器筛选中继器表格
今天和大家分享JS日期选择器筛选中继器表格的原型模板,通过调用浏览器的日期选择器,所以可以获取真实的日历效果,具体包括哪一年二月份有29天,几号对应星期几,都是真实的,获取日期值后,通过交互…...

android bp脚本
一。android大约从7.0开始引入 .bp文件代替以前的.mk文件,用于帮助android项目的编译配置文件。 二。mk文件转化为bp文件,可以使用下面命令转化,注意命令中>,这是写入文件。androidmk是android源码自带的工具,他可…...
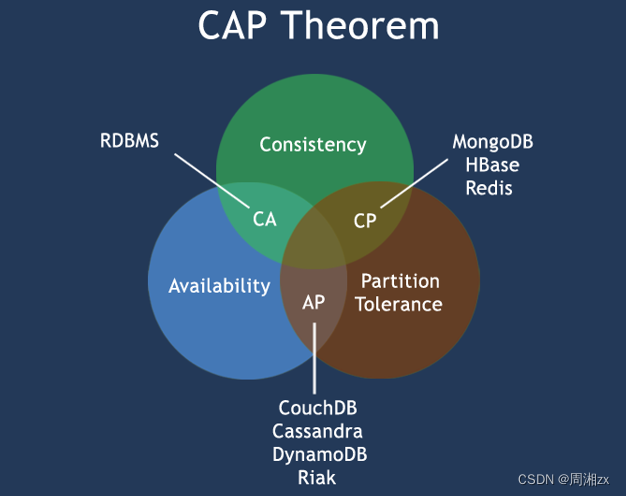
Redis 数据库 NoSQL
目录 一、NoSQL 二、为什么会出现NoSQL技术 三、NoSQL的类别 键值(Key-Value)存储数据库 列存储数据库 文档型数据库 图形(Graph)数据库 四、NoSQL适应场景 五、在分布式数据库中CAP原理 1、CAP 2、BASE 一、NoSQL NoS…...

RN 项目异常问题整理
常见问题 无法找到 CardStackStyleInterpolator StackViewStyleInterpolator 这个方法集来代替 CardStackStyleInterpolator的,这个方法集的路径也需要注意一下,在2.12.1版本之前, 该文件在react-navigation/src/views/StackView/中…...

基于Agent Deck构建多智能体系统:从原理到工程实践
1. 项目概述:从“Agent Deck”看智能体协作平台的构建最近在GitHub上看到一个挺有意思的项目,叫asheshgoplani/agent-deck。光看这个名字,你可能会联想到一副“牌”,或者一个“控制台”。没错,这个项目的核心思想&…...
)
别再手动点选了!用Python脚本5分钟搞定Abaqus批量加载节点力(附完整代码)
Python自动化赋能Abaqus:高效批量加载节点力的工程实践 在有限元分析领域,Abaqus作为行业标杆软件,其强大的计算能力与灵活的二次开发接口深受工程师青睐。然而,当面对需要为数百甚至上千个节点分别施加不同载荷的复杂工况时&…...

NVIDIA Profile Inspector终极指南:轻松解锁显卡隐藏性能的免费工具
NVIDIA Profile Inspector终极指南:轻松解锁显卡隐藏性能的免费工具 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏卡顿、画面撕裂而烦恼?想要彻底掌控显卡性能却找不…...

Claude Code提示词入门:CLAUDE.md编写完全指南
目录Claude Code提示词入门:CLAUDE.md编写完全指南 🎯📌 目录1. 什么是CLAUDE.md2. 为什么CLAUDE.md这么重要2.1 没有CLAUDE.md会怎样?2.2 有了CLAUDE.md会怎样?2.3 核心价值3. CLAUDE.md的加载机制3.1 加载优先级3.2 …...

IDEA项目乱码终结指南:从UTF-8全局设置到.properties文件特殊处理
IDEA项目乱码终结指南:从UTF-8全局设置到.properties文件特殊处理 在Java开发中,编码问题就像一颗定时炸弹,随时可能在最意想不到的时刻引爆。特别是当项目涉及多语言支持、团队协作或接手遗留代码时,乱码问题往往成为开发者挥之不…...

3步解决网盘下载限速难题:一站式直链解析工具实战指南
3步解决网盘下载限速难题:一站式直链解析工具实战指南 【免费下载链接】netdisk-fast-download 聚合多种主流网盘的直链解析下载服务, 一键解析下载,已支持夸克网盘/uc网盘/蓝奏云/蓝奏优享/小飞机盘/123云盘等. 支持文件夹分享解析. 体验地址: https://…...

ncmdump终极NCM解密转换完全指南
ncmdump终极NCM解密转换完全指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾遇到过这样的困扰?从网易云音乐下载的歌曲只能在特定播放器中播放,想要在其他设备上欣赏却束手无策。这种被格式限制的…...

Apex Legends压枪宏终极指南:轻松掌握自动武器检测与后坐力补偿技术
Apex Legends压枪宏终极指南:轻松掌握自动武器检测与后坐力补偿技术 【免费下载链接】Apex-NoRecoil-2021 Scripts to reduce recoil for Apex Legends. (auto weapon detection, support multiple resolutions) 项目地址: https://gitcode.com/gh_mirrors/ap/Ape…...

歌词滚动姬:重新定义歌词时间轴同步的专业级工具
歌词滚动姬:重新定义歌词时间轴同步的专业级工具 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为歌词与音乐不同步而烦恼吗?是否曾经花…...

自托管小说创作平台部署指南:从Docker到API集成
1. 项目概述:一个为小说创作者量身打造的全能工具箱最近在折腾一个个人项目,想搭建一个私有的、功能全面的小说创作与管理平台。作为一个深度文字爱好者兼技术从业者,我受够了在各种零散的文档、表格和笔记软件之间来回切换,也厌倦…...