Flask-SQLAlchemy
认识Flask-SQLAlchemy
- Flask-SQLAlchemy 是一个为 Flask 应用增加 SQLAlchemy 支持的扩展。它致力于简化在 Flask 中 SQLAlchemy 的使用。
- SQLAlchemy 是目前python中最强大的 ORM框架, 功能全面, 使用简单。
ORM优缺点
优点
- 有语法提示, 省去自己拼写SQL,保证SQL语法的正确性
- orm提供方言功能(dialect, 可以转换为多种数据库的语法), 减少学习成本
- 防止sql注入攻击
- 搭配数据迁移, 更新数据库方便
- 面向对象, 可读性强, 开发效率高
缺点
- 需要语法转换, 效率比原生sql低
- 复杂的查询往往语法比较复杂 (可以使用原生sql替换)
环境安装
pip install flask-sqlalchemy
flask-sqlalchemy 在安装/使用过程中, 如果出现 ModuleNotFoundError: No module named 'MySQLdb’错误, 则表示缺少mysql依赖包, 可依次尝试下列两个方案后重试:
方案1: 安装 mysqlclient依赖包 (如果失败再尝试方案2)pip install mysqlclient
方案2: 安装pymysql依赖包pip install pymysql
mysqlclient 和 pymysql 都是用于mysql访问的依赖包, 前者由C语言实现的, 而后者由python实现, 前者的执行效率比后者更高, 但前者在windows系统中兼容性较差, 工作中建议优先前者。
组件初始化
基本配置
flask-sqlalchemy 的相关配置也封装到了 flask 的配置项中, 可以通过app.config属性 或 配置加载方案 (如config.from_object) 进行设置
数据库URI(连接地址)格式: 协议名://用户名:密码@数据库IP:端口号/数据库名, 如:
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
注意点如果数据库驱动使用的是 pymysql, 则协议名需要修改为
mysql+pymysql://xxxxxxx
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)# 设置数据库连接地址
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
# 是否追踪数据库修改(开启后会触发一些钩子函数) 一般不开启, 会影响性能
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# 是否显示底层执行的SQL语句
app.config['SQLALCHEMY_ECHO'] = True
两种初始化方式
.方式1
flask-sqlalchemy 支持两种组件初始化方式:
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)# 应用配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True# 方式1: 初始化组件对象, 直接关联Flask应用
db = SQLAlchemy(app)
方式2: 先创建组件, 延后关联Flass应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy# 方式2: 初始化组件对象, 延后关联Flask应用
db = SQLAlchemy()def create_app(config_type):"""工厂函数"""# 创建应用flask_app = Flask(__name__)# 加载配置config_class = config_dict[config_type]flask_app.config.from_object(config_class)# 关联flask应用db.init_app(app)return flask_app
构建模型类
flask-sqlalchemy 的关系映射和 Django-orm 类似
类 对应 表
类属性 对应 字段
实例对象 对应 记录
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
import os
import pymysql as MySQLdbbasedir = os.path.abspath(os.path.dirname(__file__))
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:yu201541010@127.0.0.1:3306/pythontest'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True# 创建组件对象
db = SQLAlchemy(app)# 构建模型类 类->表 类属性->字段 实例对象->记录
class User(db.Model):__tablename__ = 't_user' # 设置表名, 表名默认为类名小写id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引with app.app_context():db.create_all()if __name__ == '__main__':app.run(debug=True)
注意点
- 模型类必须继承 db.Model, 其中 db 指对应的组件对象
- 表名默认为类名小写, 可以通过 __tablename__类属性 进行修改
- 类属性对应字段, 必须是通过 db.Column() 创建的对象
- 可以通过 create_all() 和 drop_all()方法 来创建和删除所有模型类对应的表常用的字段类型
常用的字段选项
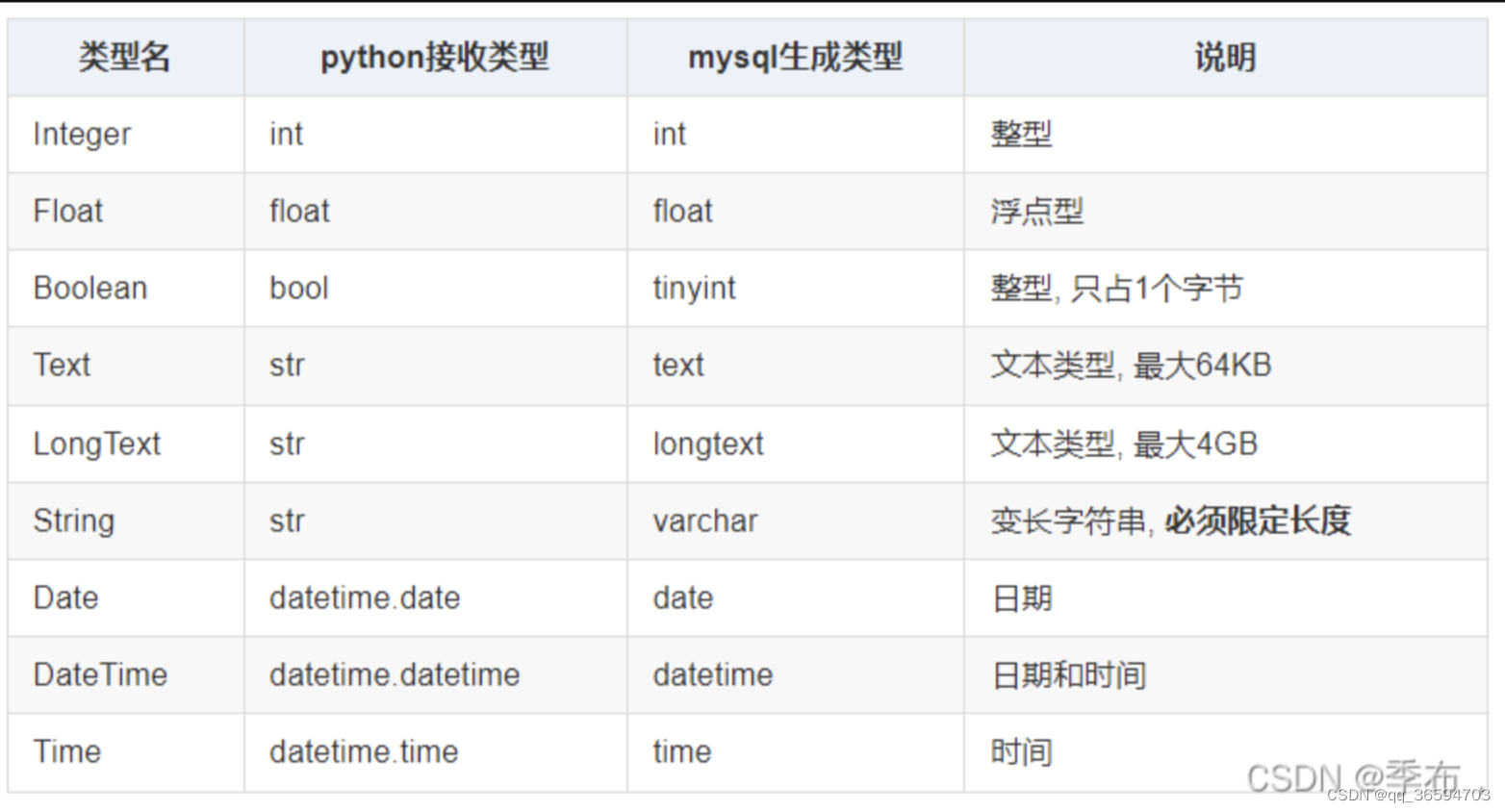
注意点: 如果没有给对应字段的类属性设置default参数, 且添加数据时也没有给该字段赋值, 则sqlalchemy会给该字段设置默认值 None
数据操作
增加数据
@app.route('/')
def index():# 增加数据user1 = User(name = 'zs', age = 20)#将模型对象添加到会话中db.session.add(user1)db.session.commit()return "index"
注意点:
这里的 会话 并不是 状态保持机制中的 session,而是 sqlalchemy 的会话。它被设计为 数据操作的执行者, 从SQL角度则可以理解为是一个 加强版的数据库事务
sqlalchemy 会 自动创建事务, 并将数据操作包含在事务中, 提交会话时就会提交事务
事务提交失败会自动回滚
查询数据
class Users(db.Model):__tablename__ = 'users'id = db.Column(db.Integer, primary_key=True)name = db.Column(db.String(64))email = db.Column(db.String(64))age = db.Column(db.Integer)def __repr__(self):return "(%s, %s, %s, %s)" % (self.id, self.name, self.email, self.age)
@app.route('/createusers')
def createusers():user1 = Users(name='wang', email='wang@163.com', age=20)user2 = Users(name='zhang', email='zhang@189.com', age=33)user3 = Users(name='chen', email='chen@126.com', age=23)user4 = Users(name='zhou', email='zhou@163.com', age=29)user5 = Users(name='tang', email='tang@itheima.com', age=25)user6 = Users(name='wu', email='wu@gmail.com', age=25)user7 = Users(name='qian', email='qian@gmail.com', age=23)user8 = Users(name='liu', email='liu@itheima.com', age=30)user9 = Users(name='li', email='li@163.com', age=28)user10 = Users(name='sun', email='sun@163.com', age=26)db.session.add_all([user1, user2, user3, user5, user4, user6, user7, user8,user9,user10])db.session.commit()return "success"
@app.route('/query')
def query():user = Users.query.first()return user.name+" "+user.email
# 查询所有用户数据
User.query.all() 返回列表, 元素为模型对象# 查询有多少个用户
User.query.count()# 查询第1个用户
User.query.first() 返回模型对象/None# 查询id为4的用户[3种方式]
# 方式1: 根据id查询 返回模型对象/None
User.query.get(4)# 方式2: 等值过滤器 关键字实参设置字段值 返回BaseQuery对象
# BaseQuery对象可以续接其他过滤器/执行器 如 all/count/first等
User.query.filter_by(id=4).all()# 方式3: 复杂过滤器 参数为比较运算/函数引用等 返回BaseQuery对象
User.query.filter(User.id == 4).first()# 查询名字结尾字符为g的所有用户[开始 / 包含]
User.query.filter(User.name.endswith("g")).all()
User.query.filter(User.name.startswith("w")).all()
User.query.filter(User.name.contains("n")).all()
User.query.filter(User.name.like("w%n%g")).all() # 模糊查询# 查询名字和邮箱都以li开头的所有用户[2种方式]
User.query.filter(User.name.startswith('li'), User.email.startswith('li')).all()
from sqlalchemy import and_
User.query.filter(and_(User.name.startswith('li'), User.email.startswith('li'))).all()# 查询age是25 或者 `email`以`itheima.com`结尾的所有用户
from sqlalchemy import or_
User.query.filter(or_(User.age==25, User.email.endswith("itheima.com"))).all()# 查询名字不等于wang的所有用户[2种方式]
from sqlalchemy import not_
User.query.filter(not_(User.name == 'wang')).all()
User.query.filter(User.name != 'wang').all()# 查询id为[1, 3, 5, 7, 9]的用户
User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()# 所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个
User.query.order_by(User.age, User.id.desc()).limit(5).all()# 查询年龄从小到大第2-5位的数据 2 3 4 5
User.query.order_by(User.age).offset(1).limit(4).all()# 分页查询, 每页3个, 查询第2页的数据 paginate(页码, 每页条数)
pn = User.query.paginate(2, 3)
pn.pages 总页数 pn.page 当前页码 pn.items 当前页的数据 pn.total 总条数# 查询每个年龄的人数 select age, count(name) from t_user group by age 分组聚合
from sqlalchemy import func
data = db.session.query(User.age, func.count(User.id).label("count")).group_by(User.age).all()
for item in data:
# print(item[0], item[1])
print(item.age, item.count) # 建议通过label()方法给字段起别名, 以属性方式获取数据
# 只查询所有人的姓名和邮箱 优化查询 User.query.all() # 相当于select *
from sqlalchemy.orm import load_only
data = User.query.options(load_only(User.name, User.email)).all() # flask-sqlalchem的语法
for item in data:
print(item.name, item.email)data = db.session.query(User.name, User.email).all() # sqlalchemy本体的语法
for item in data:
print(item.name, item.email)
更新数据
flask-sqlalchemy 提供了两种更新数据的方案
先查询, 再更新
对应SQL中的 先select, 再update
基于过滤条件的更新 (推荐方案)
对应SQL中的 update xx where xx = xx (也称为 update子查询 )
先查询, 再更新
这种方式的缺点
查询和更新分两条语句, 效率低
如果并发更新, 可能出现更新丢失问题(Lost Update)
class Goods(db.Model):__tablename__ = 't_good'id = db.Column(db.Integer, primary_key = True)name = db.Column(db.String(20), unique=True)count = db.Column(db.Integer)
@app.route('/addgood')
def addgood():goods = Goods(name='方便面', count=10)db.session.add(goods)db.session.commit()return "success"
@app.route('/updategood')
def updategood():goods = Goods.query.filter(Goods.name=='方便面').first()goods.count = goods.count - 1db.session.commit()return "success"
基于过滤条件的更新
这种方式的优点:
一条语句, 被网络IO影响程度低, 执行效率更高
查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
操作步骤如下:
配合 查询过滤器filter() 和 更新执行器update() 进行数据更新
提交会话
@app.route('/updategood2')
def updategood2():Goods.query.filter(Goods.name=='方便面').update({'count':Goods.count-1})db.session.commit()return "success"
删除数据
类似更新数据, 也存在两种删除数据的方案
先查询, 再删除
对应SQL中的 先select, 再delete
基于过滤条件的删除 (推荐方案)
对应SQL中的 delete xx where xx = xx (也称为 delete子查询 )
这种方式的缺点:
查询和删除分两条语句, 效率低
@app.route('/deletegood')
def deletegood():goods = Goods.query.filter(Goods.name=='方便面').first()db.session.delete(goods)db.session.commit()return "success"
基于过滤条件的删除
这种方式的优点:
一条语句, 被网络IO影响程度低, 执行效率更高
会对满足过滤条件的所有记录进行删除, 可以实现批量删除处理
操作步骤如下:
配合 查询过滤器filter() 和 删除执行器delete() 进行数据删除
提交会话
@app.route('/deletegood2')
def deletegood2():Goods.query.filter(Goods.name=='方便面').delete()db.session.commit()return "success"
增删改操作都需要提交会话, 对应事务中进行数据库变化后提交事务
刷新数据
Session 被设计为数据操作的执行者, 会先将操作产生的数据保存到内存中
在执行 flush刷新操作 后, 数据操作才会同步到数据库中
有两种情况下会 隐式执行刷新操作
提交会话
执行查询操作 (包括 update 和 delete 子查询)
开发者也可以 手动执行刷新操作 session.flush()
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# 构建模型类
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/')
def purchase():
goods = Goods(name='方便面', count=20)
db.session.add(goods)
# 主动执行flush操作, 立即执行SQL操作(数据库同步)
db.session.flush()
# Goods.query.count() # 查询操作会自动执行flush操作
db.session.commit() # 提交会话会自动执行flush操作
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
多表查询
案例中包含两个模型类: User用户模型 和 Address地址模型, 并且一个用户可以有多个地址, 两张表之间存在一对多关系
class Address(db.Model):__tablename__='t_adr'id = db.Column(db.Integer, primary_key=True)detail = db.Column(db.String(20))user_id = db.Column(db.Integer)
@app.route('/addadr')
def addadr():adr1 = Address(detail='中关村3号', user_id=1)adr2 = Address(detail='华强北5号', user_id=1)db.session.add_all([adr2, adr1])db.session.commit()return "success"
关联查询
关联查询步骤: (以主查从为例)
先查询主表数据
再通过外键字段查询 关联的从表数据
@app.route('/queryadr')
def queryadr():user1 = User.query.filter_by(name='zs').first()adrs = Address.query.filter_by(user_id=user1.id).all()for adr in adrs:print(adr.detail)return "success"
连接查询
开发中有 联表查询需求 时, 一般会使用 join连接查询
sqlalchemy 也提供了对应的查询语法
db.session.query(主表模型字段1, 主表模型字段2, 从表模型字段1, xx.. ).join(从表模型类, 主表模型类.主键 == 从表模型类.外键)
1
join语句 属于查询过滤器, 返回值也是 BaseQuery 类型对象
@app.route('/queryadr2')
def queryadr2():data = db.session.query(User.id, Address.detail).join(Address, User.id==Address.user_id).filter(User.name=='zs').all()for item in data:print(item.detail, item.id)return "success"
关联查询的性能优化
通过前边的学习, 可以发现 无论使用 外键 还是 关系属性 查询关联数据, 都需要查询两次, 一次查询用户数据, 一次查询地址数据
两次查询就需要发送两次请求给数据库服务器, 如果数据库和web应用不在一台服务器中, 则 网络IO会对查询效率产生一定影响
可以考虑使用 连接查询 join 使用一条语句就完成关联数据的查询
# 使用join语句优化关联查询
adrs = Address.query.join(User, Address.user_id == User.id).filter(User.name == '张三').all() # 列表中包含地址模型对象
Session机制
生命周期
flask-sqlalchemy 对于 sqlalchemy本体 的 Session 进行了一定的封装:
Session的生命周期和请求相近
请求中的首次数据操作会创建Session
整个请求过程中使用的Session为同一个, 并且线程隔离
请求结束时会自动销毁Session(释放内存)
Session和事务
Session中可以包含多个事务, 提交事务失败后, 会自动执行SQL的回滚操作
同一个请求中, 想要在前一个事务失败的情况下创建新的事务, 必须先手动回滚事务 Session.rollback
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/toutiao'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
age = db.Column(db.Integer, default=0, index=True)
@app.route('/')
def index():
"""事务1"""
try:
user1 = User(name='zs', age=20)
db.session.add(user1)
db.session.commit()
except BaseException:
# 手动回滚 同一个session中, 前一个事务如果失败, 必须手动回滚, 否则无法创建新的事务
db.session.rollback()
"""事务2"""
user1 = User(name='lisi', age=30)
db.session.add(user1)
db.session.commit()
return "index"
if __name__ == '__main__':
"""为了进行测试, 首次运行 建表并添加一条测试数据后, 注释下方代码, 并重新运行测试"""
# 重置所有继承自db.Model的表
# db.drop_all()
# db.create_all()
# 添加一条测试数据
# user1 = User(name='zs', age=20)
# db.session.add(user1)
# db.session.commit()
app.run(debug=True)
数据迁移
flask-migrate组件 为flask-sqlalchemy提供了数据迁移功能, 以便进行数据库升级, 如增加字段、修改字段类型等
安装组件 pip install flask-migrate
# hm_数据迁移.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrateapp = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:yu201541010@127.0.0.1:3306/pythontest'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = Falsedb = SQLAlchemy(app)
#迁移组件初始化
Migrate(app, db)
class User(db.Model):__tablename__ ='t_user'id = db.Column(db.Integer, primary_key=True)name = db.Column('username', db.String(20), unique=True)@app.route('/')
def index():return "index"if __name__ =='__main__':app.run()
执行迁移命令
终端进入当前文件目录下,注意export命令后面等号不能有空格
- export FLASK_APP=hm_数据迁移.py # 设置环境变量指定启动文件
- flask db init # 生成迁移文件夹 只执行一次
- flask db migrate # ⽣成迁移版本, 保存到迁移文件夹中
- flask db upgrade # 执行迁移
执行迁移命令前需要先设置环境变量指定启动文件
相关文章:
Flask-SQLAlchemy
认识Flask-SQLAlchemy Flask-SQLAlchemy 是一个为 Flask 应用增加 SQLAlchemy 支持的扩展。它致力于简化在 Flask 中 SQLAlchemy 的使用。SQLAlchemy 是目前python中最强大的 ORM框架, 功能全面, 使用简单。 ORM优缺点 优点 有语法提示, 省去自己拼写SQL,保证SQL…...
)
大数据bug-sqoop(二:sqoop同步mysql数据到hive进行字段限制。)
一:sqoop脚本解析。 #!/bin/sh mysqlHost$1 mysqlUserName$2 mysqlUserPass$3 mysqlDbName$4 sql$5 split$6 target$7 hiveDbName$8 hiveTbName$9 partFieldName${10} inputDate${11}echo ${mysqlHost} echo ${mysqlUserName} echo ${mysqlUserPass} ec…...
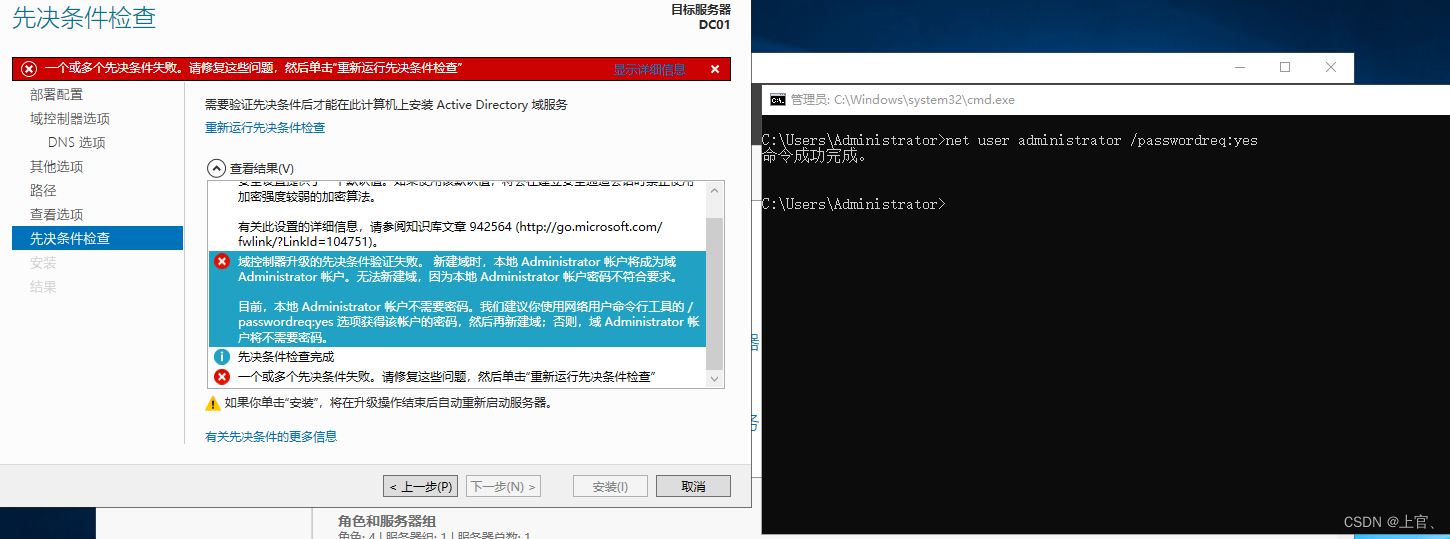
Windows小记
一、域控制器升级的先决条件验证失败。 新建域时,本地 Administrator 帐户将成为域 Administrator 帐户。无法新建域,因为本地 Administrator 帐户密码不符合要求。 目前,本地 Administrator 帐户不需要密码。我们建议你使用网络用户命令行工…...

centos安装elasticsearch7.9
安装es 下载elasticsearch安装包解压安装包,并修改配置文件解压进入目录修改配置文件 添加用户,并修改所有者切换用户,运行es如何迁移旧版本的数据 下载elasticsearch安装包 下载地址如下,版本号可以替换成自己想要的。 这里需要注意一点&am…...
221、仿真-基于51单片机的智能啤酒发酵罐多点温度压力水位排水加水检测报警系统设计(程序+Proteus仿真+配套资料等)
毕设帮助、开题指导、技术解答(有偿)见文未 目录 一、硬件设计 二、设计功能 三、Proteus仿真图 编辑 四、程序源码 资料包括: 需要完整的资料可以点击下面的名片加下我,找我要资源压缩包的百度网盘下载地址及提取码。 方案选择 单片机的选择 方…...

C语言好题解析(三)
目录 选择题一选择题二选择题三选择题四编程题一编程题二 选择题一 以下程序段的输出结果是()#include<stdio.h> int main() { char s[] "\\123456\123456\t"; printf("%d\n", strlen(s)); return 0; }A: 12 B: 13 …...

OpenCV之remap的使用
OpenCV中使用remap实现图像的重映射。 重映射是指将图像中的某一像素值赋值到指定位置的操作:g(x,y) f ( h(x,y) ), 在这里, g( ) 是目标图像, f() 是源图像, 而h(x,y) 是作用于 (x,y) 的映射方法函数。为了完成映射过程, 需要获得一些插值为…...
leetcode 377. 组合总和 Ⅳ
2023.8.17 本题属于完全背包问题,乍一看和昨天那题 零钱兑换II 类似,但细看题目发现:今天这题是排列问题,而“零钱兑换II”是组合问题。排列问题强调顺序,而组合顺序不强调顺序。 这里先说个结论:先遍历物品…...
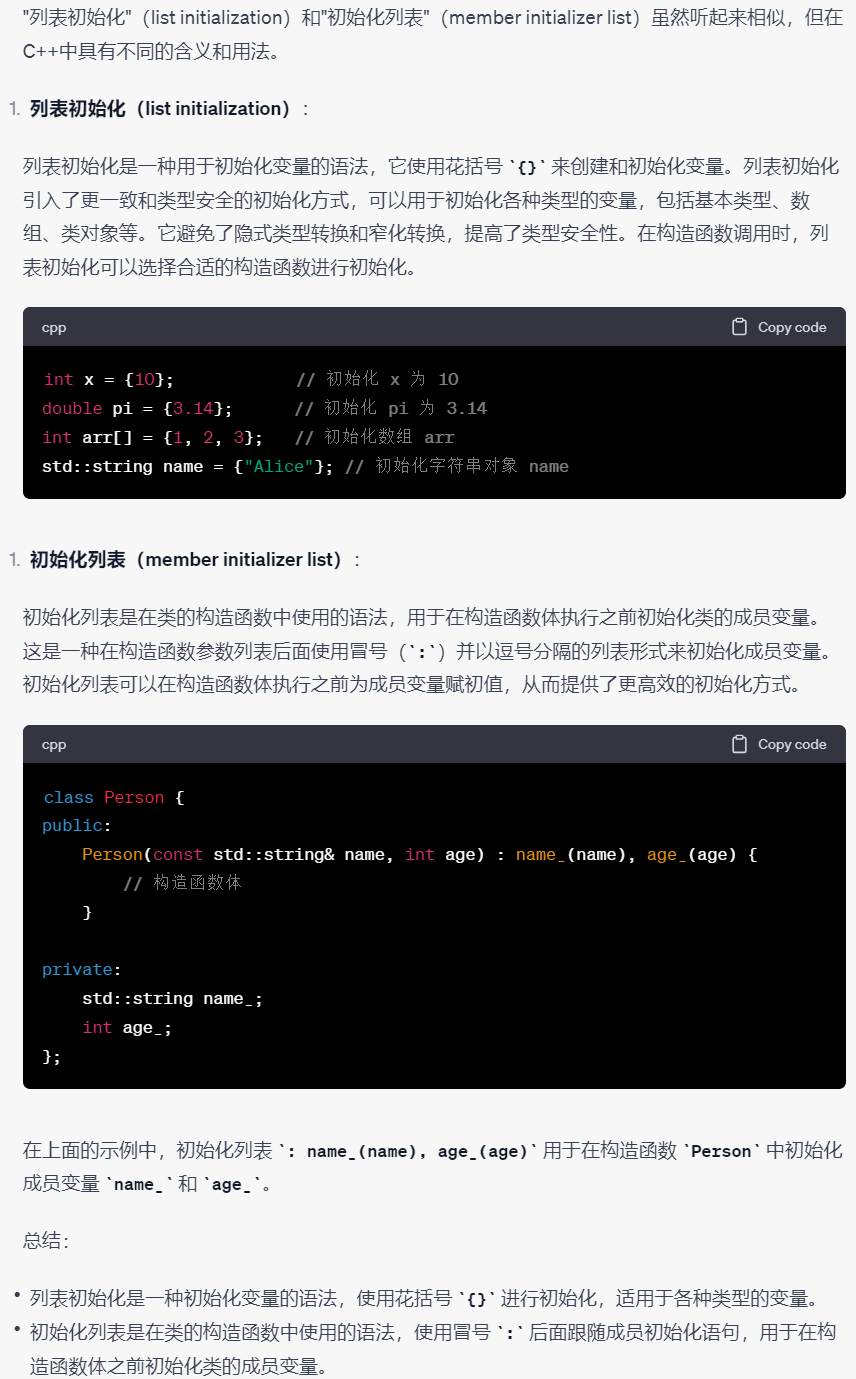
C++笔记之花括号和圆括号初始化区别,列表初始化和初始化列表区别
C笔记之花括号和圆括号初始化区别,列表初始化和初始化列表区别 code review! 文章目录 C笔记之花括号和圆括号初始化区别,列表初始化和初始化列表区别1.花括号{}进行初始化和圆括号()进行初始化2.列表初始化(list initialization࿰…...

git报错Add correct host key
想克隆备份的笔记库,失败。 测试连接github报错如下。 $ ssh -T gitgithub.comWARNING: POSSIBLE DNS SPOOFING DETECTED! The RSA host key for github.com has changed, and the key for the corresponding IP address 140.82.121.4 is unknown. This c…...
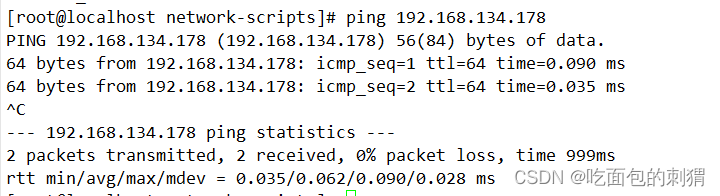
Kvm配置ovs网桥
环境:部署在kvm虚拟环境上(让虚拟机和宿主机都可以直接从路由器获取到独立ip) 1、安装ovs软件安装包并启动服务(一般采用源码安装,此处用yum安装) yum install openvswitch-2.9.0-3.el7.x86_64.rpm syste…...
AraNet:面向阿拉伯社交媒体的新深度学习工具包
阿拉伯语是互联网上第四大最常用的语言,它在社交媒体上的日益增加为大规模研究阿拉伯语在线社区提供了充足的资源。然而,目前很少有工具可以从这些数据中获得有价值的见解,用于决策、指导政策、协助应对等。这种情况即将改变吗? …...

P13-CNN学习1.3-ResNet(神之一手~)
论文地址:CVPR 2016 Open Access Repository https://arxiv.org/pdf/1512.03385.pdf Abstract 翻译 深层的神经网络越来越难以训练。我们提供了一个残差学习框架用来训练那些非常深的神经网络。我们重新定义了网络的学习方式,让网络可以直接学习输入信息与输出信息…...

【C++】set/multiset容器
1.set基本概念 #include <iostream> using namespace std;//set容器构造和赋值 #include<set>//遍历 void printSet(const set<int>& st) {for (set<int>::const_iterator it st.begin(); it ! st.end(); it){cout << *it << " …...

docker拉取镜像时报错Error response from daemon: Head ““no basic auth credentials
一:场景:新搭建一台服务器,需要拉取公司私有镜像仓库。 docker拉取私有仓库报如下错误: Error response from daemon: Head "" no basic auth credentials 二:解决方式 docker私有仓库需要登录授权,因此…...
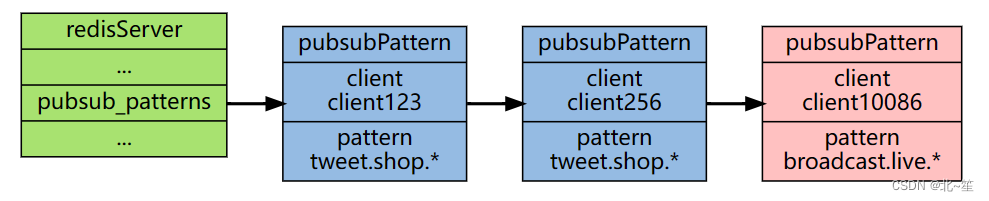
Redis消息传递:发布订阅模式详解
目录 1.Redis发布订阅简介 2.发布/订阅使用 2.1 基于频道(Channel)的发布/订阅 2.2 基于模式(pattern)的发布/订阅 3.深入理解Redis的订阅发布机制 3.1 基于频道(Channel)的发布/订阅如何实现的? 3.2 基于模式(Pattern)的发布/订阅如何实现的? 3.3 Sp…...
- 句柄)
最强自动化测试框架Playwright(36)- 句柄
剧作家可以为页面 DOM 元素或页面内的任何其他对象创建句柄。这些句柄存在于 Playwright 进程中,而实际对象位于浏览器中。有两种类型的句柄: JSHandle 引用页面中的任何 JavaScript 对象ElementHandle 引用页面中的 DOM 元素,它具有额外的方…...
推荐一个绘图平台(可替代Visio)
不废话,简易记网址: draw.io 网站会重定向到:https://app.diagrams.net/...

【探索Linux】—— 强大的命令行工具 P.6(调试器-gdb、项目自动化构建工具-make/Makefile)
阅读导航 前言一、什么是调试器二、详解 GDB - 调试器1.使用前提2.经常使用的命令3.使用小技巧 三、项目自动化构建工具 - make/Makefile1. make命令⭕语法⭕常用选项⭕常用操作⭕make命令的工作原理⭕make命令的优势: 2.Makefile文件⭕Makefile的基本结构⭕Makefil…...
echarts-convert.js使用
echarts-convert.js demo 点击下载 1、本地安装phantom.js插件 window版本下载 2、更改文件路径 (D:\phantomjs-2.1.1-windows\bin)改为本地项目文件路径 3、打开cmd命令行,并格式化语言 运行以下命令 将命令行语言改为中文简体 chcp…...

构建轻量级应用沙盒:Microverse原理与实践指南
1. 项目概述:一个轻量级、可移植的“微宇宙”开发沙盒最近在折腾一些边缘计算和嵌入式AI应用的原型验证,经常遇到一个头疼的问题:开发环境和部署环境不一致。在本地笔记本上跑得好好的Python脚本,放到树莓派或者Jetson Nano上&…...

如何为深信服超融合平台上的应用快速接入大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为深信服超融合平台上的应用快速接入大模型能力 对于在深信服超融合平台上部署业务应用的企业开发团队而言,集成智…...

从零部署开源语音助手:OpenClaw项目实战与二次开发指南
1. 项目概述:从开源代码到可用的语音助手看到leilei926524-tech/openclaw-voice-assistant这个项目标题,我的第一反应是:又一个基于开源代码的语音助手项目。在GitHub上,类似的项目多如牛毛,但真正能让一个普通开发者&…...

CircuitPython REPL与库管理:嵌入式开发的效率利器
1. CircuitPython REPL:你的嵌入式开发“瑞士军刀” 如果你玩过Arduino,肯定对“上传-编译-看结果”这个循环不陌生。每次改一行代码,都得重新编译、上传,然后盯着串口看输出,效率低得让人抓狂。CircuitPython带来的R…...

2026运营经理学习数据分析对职场能力提升的影响
一、数据分析在运营管理中的核心价值数据分析能力帮助运营经理优化决策流程,通过数据驱动的方法提升业务效率。掌握用户行为分析、市场趋势预测等技能,能够更精准地制定运营策略。数据可视化工具(如Tableau、Power BI)的应用&…...

RP2350微控制器模拟Macintosh 128K:嵌入式复古计算实践
1. 项目概述:在RP2350上复活Macintosh 128K拿到一块Adafruit Fruit Jam开发板,看着上面那颗RP2350双核微控制器,我就在想,除了跑跑MicroPython、控制几个LED,这玩意儿还能干点啥更“出格”的事?答案是把一台…...

自学 Vibe Coding 这三个网站就够了!
背景 我之前想学 Vibe Coding,刷到各种"AI 编程神器"、"零基础用 AI 写代码"的文章,看得心潮澎湃。 结果一上手就懵了:装了插件、开了 AI、对着编辑器发呆,不知道下一步干嘛。 网上搜教程,要么…...

量子计算优化Benders分解:减少量子比特与提升收敛效率
1. 量子辅助Benders分解框架概述混合整数线性规划(MILP)在供应链管理、金融优化和资源调度等领域有着广泛应用。传统Benders分解算法通过将原问题拆分为处理整数变量的主问题(MP)和处理连续变量的子问题(SP)进行迭代求解。然而,随着问题规模扩大,主问题的…...

血管分割新突破:详解DSCNet中的蛇形卷积如何解决管状结构难题
血管分割新突破:详解DSCNet中的蛇形卷积如何解决管状结构难题 在医学影像分析领域,血管分割一直是个令人头疼的问题。想象一下,当你面对一张OCTA(光学相干断层扫描血管成像)图像时,那些细如发丝、蜿蜒曲折…...

基于节点电价的电网对电动汽车接纳能力评估模型研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &…...