机器学习之数据集
目录
1、简介
2、可用数据集
3、scikit-learn数据集API
3.1、小数据集
3.2、大数据集
4、数据集使用
⭐所属专栏:人工智能
文中提到的代码如有需要可以私信我发给你😊
1、简介
当谈论数据集时,通常是指在机器学习和数据分析中使用的一组数据样本,这些样本通常代表了某个特定问题领域的实际观测数据。数据集可以用于开发、训练和评估机器学习模型,从而使模型能够从数据中学习并做出预测或分类。
数据集通常由以下几个组成部分组成:
- 特征(Features):也称为自变量、属性或输入变量,是用来描述每个数据样本的不同方面的数据。特征可以是数值型、类别型、文本型等。在监督学习中,特征被用来训练模型。
- 目标变量(Target Variable):也称为因变量、标签或输出变量,是我们希望模型预测或分类的值。在监督学习中,模型使用特征来预测或分类目标变量。
- 样本(Samples):每个样本是数据集中的一行,包含特征和目标变量的值。样本代表了问题领域中的一个观测点或数据点。
- 特征名称(Feature Names):如果数据集中的特征有名称,通常会提供一个特征名称列表,以便更好地理解和解释特征。
- 目标变量的类别(Target Variable Classes):对于分类问题,目标变量可能有多个类别,每个类别表示一个不同的类或标签。
- 数据集描述(Dataset Description):通常包括数据集的来源、数据采集方法、特征和目标变量的含义,以及数据的格式和结构等信息。
数据集可以在各种领域和问题中使用,例如医疗诊断、自然语言处理、计算机视觉、金融预测等。不同类型的数据集可能需要不同的预处理和特征工程步骤,以便为模型提供有意义的数据。
在机器学习中,一个常见的任务是将数据集划分为训练集和测试集,用于模型的训练和评估。这样可以确保模型在未见过的数据上能够进行泛化。数据集的质量和适用性对机器学习模型的性能和效果有很大影响,因此选择合适的数据集和进行有效的特征工程非常重要。
2、可用数据集
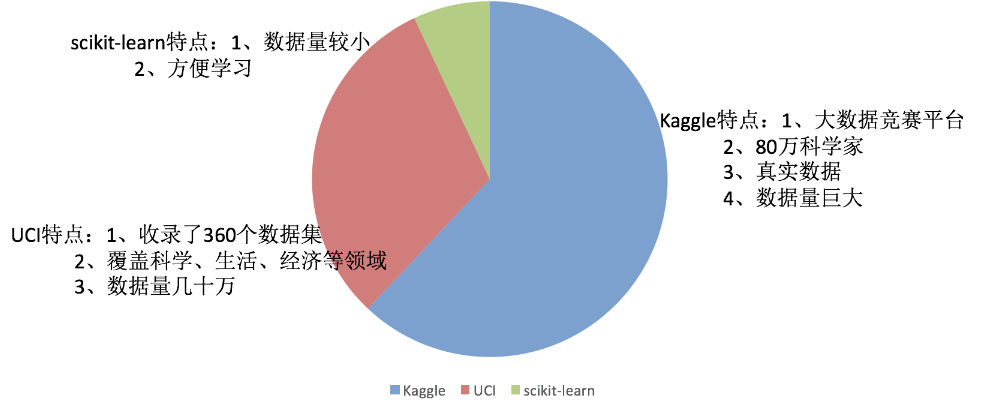
Kaggle网址:Find Open Datasets and Machine Learning Projects | Kaggle
UCI数据集网址: UCI Machine Learning Repository
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
Scikit-learn工具介绍:

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
安装:pip3 install Scikit-learn==0.19.1 (安装scikit-learn需要Numpy, Scipy等库)
Scikit-learn包含的内容:
scikitlearn接口
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
3、scikit-learn数据集API
- sklearn.datasets 加载获取流行数据集
- datasets.load_*() 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None) 获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
3.1、小数据集
sklearn.datasets.load_iris() 加载并返回鸢尾花数据集

sklearn.datasets.load_boston() 加载并返回波士顿房价数据集
3.2、大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
-
- subset:'train'或者'test','all',可选,选择要加载的数据集。
- 训练集的“训练”,测试集的“测试”,两者的“全部”
4、数据集使用
这里使用的是鸢尾花数据集

数据集返回值介绍:
load和fetch返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名,新闻数据,手写数字、回归数据集没有
target_names:标签名
from sklearn.datasets import load_iris'''
load和fetch返回的数据类型datasets.base.Bunch(字典格式)data:特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组target:标签数组,是 n_samples 的一维 numpy.ndarray 数组DESCR:数据描述feature_names:特征名,新闻数据,手写数字、回归数据集没有target_names:标签名
'''
def getIris_1():# 获取鸢尾花数据集iris = load_iris()print("鸢尾花数据集的返回值:\n", iris)# 返回值是一个继承自字典的Benchprint("鸢尾花的特征值:\n", iris["data"])print("鸢尾花的目标值:\n", iris.target)print("鸢尾花特征的名字:\n", iris.feature_names)print("鸢尾花目标值的名字:\n", iris.target_names)print("鸢尾花的描述:\n", iris.DESCR)if __name__ == '__main__':getIris_1()数据集划分:
机器学习一般的数据集会划分为两个部分:
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70% 80% 75%
- 测试集:30% 20% 30%
数据集划分api:
sklearn.model_selection.train_test_split(arrays, *options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。
return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
from sklearn.model_selection import train_test_split # 数据集划分'''
sklearn.model_selection.train_test_split(arrays, *options)x 数据集的特征值y 数据集的标签值test_size 测试集的大小,一般为floatrandom_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同。return 测试集特征训练集特征值值,训练标签,测试标签(默认随机取)
'''
def datasets_demo():"""对鸢尾花数据集的演示:return: None"""# 1、获取鸢尾花数据集iris = load_iris()print("鸢尾花数据集的返回值:\n", iris)# 返回值是一个继承自字典的Benchprint("鸢尾花的特征值:\n", iris["data"])print("鸢尾花的目标值:\n", iris.target)print("鸢尾花特征的名字:\n", iris.feature_names)print("鸢尾花目标值的名字:\n", iris.target_names)print("鸢尾花的描述:\n", iris.DESCR)# 2、对鸢尾花数据集进行分割# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_testx_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)print("x_train:\n", x_train.shape)# 随机数种子x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)print("如果随机数种子不一致:\n", x_train == x_train1)print("如果随机数种子一致:\n", x_train1 == x_train2)return Noneif __name__ == '__main__':datasets_demo()相关文章:
机器学习之数据集
目录 1、简介 2、可用数据集 3、scikit-learn数据集API 3.1、小数据集 3.2、大数据集 4、数据集使用 ⭐所属专栏:人工智能 文中提到的代码如有需要可以私信我发给你😊 1、简介 当谈论数据集时,通常是指在机器学习和数据分析中使用的一组…...

PyTorch Geometric基本教程
PyG官方文档 # Install torch geometric !pip install -q torch-scatter -f https://pytorch-geometric.com/whl/torch-1.10.2cu102.html !pip install -q torch-sparse -f https://pytorch-geometric.com/whl/torch-1.10.2cu102.html !pip install -q torch-geometricimport t…...

MAC 命令行启动tomcat的详细介绍
MAC 命令行启动tomcat MAC 命令行启动tomcat的详细介绍 一、修改授权 进入tomcat的bin目录,修改授权 1 2 3 ➜ bin pwd /Users/yp/Documents/workspace/apache-tomcat-7.0.68/bin ➜ bin sudo chmod 755 *.sh sudo为系统超级管理员权限.chmod 改变一个或多个文件的存取模…...
idea2023 springboot2.7.5+mybatisplus3.5.2+jsp 初学单表增删改查
创建项目 修改pom.xml 为2.7.5 引入mybatisplus 2.1 修改pom.xml <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version></dependency><!--mysq…...
轻松搭建书店小程序
在现今数字化时代,拥有一个自己的小程序成为了许多企业和个人的追求。而对于书店经营者来说,拥有一个能够提供在线购书服务的小程序将有助于吸引更多的读者,并提升销售额。本文将为您介绍如何轻松搭建书店小程序,并将其成功上线。…...

Spark MLlib机器学习库(一)决策树和随机森林案例详解
Spark MLlib机器学习库(一)决策树和随机森林案例详解 1 决策树预测森林植被 1.1 Covtype数据集 数据集的下载地址: https://www.kaggle.com/datasets/uciml/forest-cover-type-dataset 该数据集记录了美国科罗拉多州不同地块的森林植被类型,每个样本…...
CI/CD入门(二)
CI/CD入门(二) 目录 CI/CD入门(二) 1、代码上线方案 1.1 早期手动部署代码1.2 合理化上线方案1.3 大型企业上线制度和流程1.4 php程序代码上线的具体方案1.5 Java程序代码上线的具体方案1.6 代码上线解决方案注意事项2、理解持续集成、持续交付、持续部署 2.1 持续集成2.2 持续…...
)
【BASH】回顾与知识点梳理(三十五)
【BASH】回顾与知识点梳理 三十五 三十五. 二十七至三十四章知识点总结及练习35.1 总结35.2 练习RAIDLVMsystemd 35.3 简答题 该系列目录 --> 【BASH】回顾与知识点梳理(目录) 三十五. 二十七至三十四章知识点总结及练习 35.1 总结 Quota 可公平的分…...
excel逻辑函数篇2
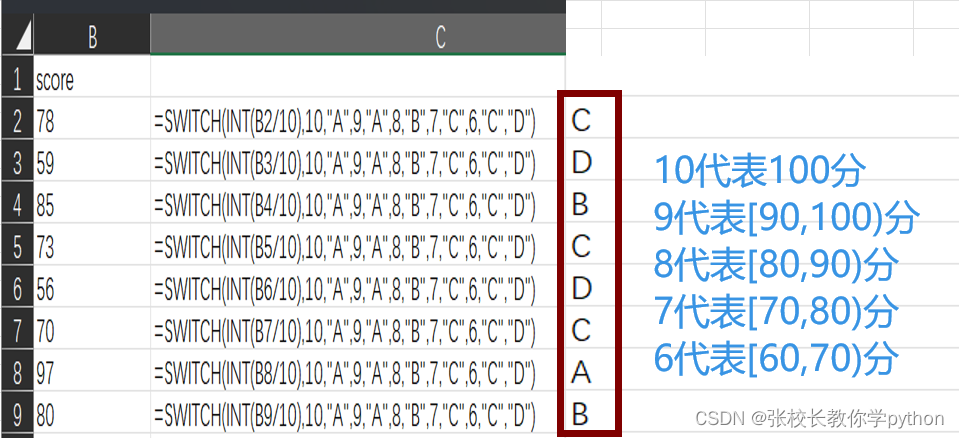
1、IF(logical_test,[value_if_true],[value_if_false]):判断是否满足某个条件,如果满足返回一个值,如果不满足则返回另一个值 if(条件,条件成立返回的值,条件不成立返回的值) 2、IFS(logical_test1,value_if_true1,…):检查是否…...

设计模式详解-解释器模式
类型:行为型模式 实现原理:实现了一个表达式接口,该接口使用标识来解释语言中的句子 作用:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器来解释。 主要解决:一些重…...

如何在React项目中动态插入HTML内容
React是一种流行的JavaScript库,用于构建用户界面。它提供了一种声明式的方法来创建可复用的组件,使得开发者能够更轻松地构建交互性的Web应用程序。在React中,我们通常使用JSX语法来描述组件的结构和行为。 在某些情况下,我们可…...
十六、Spring Cloud Sleuth 分布式请求链路追踪
目录 一、概述1、为什么出出现这个技术?需要解决哪些问题2、是什么?3、解决 二、搭建链路监控步骤1、下载运行zipkin2、服务提供者3、服务调用者4、测试 一、概述 1、为什么出出现这个技术?需要解决哪些问题 2、是什么? 官网&am…...

ElasticSearch DSL语句(bool查询、算分控制、地理查询、排序、分页、高亮等)
文章目录 DSL 查询种类DSL query 基本语法1、全文检索2、精确查询3、地理查询4、function score (算分控制)5、bool 查询 搜索结果处理1、排序2、分页3、高亮 RestClient操作 DSL 查询种类 查询所有:查询所有数据,一般在测试时使…...
)
【考研数学】概率论与数理统计 | 第一章——随机事件与概率(2,概率基本公式与事件独立)
文章目录 引言四、概率基本公式4.1 减法公式4.2 加法公式4.3 条件概率公式4.4 乘法公式 五、事件的独立性5.1 事件独立的定义5.1.1 两个事件的独立5.1.2 三个事件的独立 5.2 事件独立的性质 写在最后 引言 承接上文,继续介绍概率论与数理统计第一章的内容。 四、概…...

SpringBoot整合RabbitMQ,笔记整理
1创建生产者工程springboot-rabbitmq-produce 2.修改pom.xml文件 <!--父工程--> <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.6.0</version><r…...
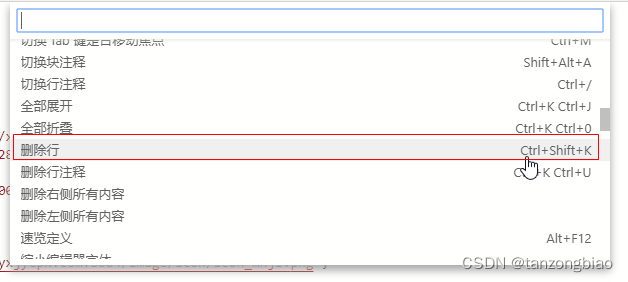
搜狗拼音暂用了VSCode及微信小程序开发者工具快捷键Ctrl + Shit + K 搜狗拼音截图快捷键
修改搜狗拼音的快捷键 右键--更多设置--属性设置--按键--系统功能快捷键--系统功能快捷键设置--取消Ctrl Shit K的勾选--勾选截屏并设置为Ctrl Shit A 微信开发者工具设置快捷键 右键--Command Palette--删除行 微信开发者工具快捷键 删除行:Ctrl Shit K 或…...

Python包sklearn画ROC曲线和PR曲线
前言 关于ROC和PR曲线的介绍请参考: 机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线 参考: Python下使用sklearn绘制ROC曲线(超详细) Python绘图|Python绘制ROC曲线和PR曲线 源码 …...

snpEff变异注释的一点感想
snpEff变异注释整成人生思考 1.介绍2.安装过程以及构建物种参考数据库3.坑货来了4.结果文件判读5.小tips 1.介绍   SnpEff(Snp Effect)是一个用于预测基因组变异(例如单核苷酸变异、插入、缺失等)对基因功能的影响的生物…...

“保姆级”考研下半年备考时间表
7月-8月 确定考研目标与备考计划 暑假期间是考研复习的关键时期,需要复习的主要内容有:重点关注重要的学科和专业课程,复习相关基础知识和核心概念。制定详细的复习计划并合理安排每天的学习时间,增加真题练习熟悉考试题型和答题技…...

具有弱监督学习的精确3D人脸重建:从单幅图像到图像集的Python实现详解
随着深度学习和计算机视觉技术的飞速发展,3D人脸重建技术在多个领域获得了广泛应用,例如虚拟现实、电影特效、生物识别等。但是,由单幅图像实现高精度的3D人脸重建仍然是一个巨大的挑战。在本文中,我们将探讨如何利用弱监督学习进…...

Arduino ESP32终极配置指南:5步解决环境搭建难题
Arduino ESP32终极配置指南:5步解决环境搭建难题 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 Arduino ESP32是专为ESP32系列芯片设计的开源开发板支持包&am…...

Vue3-DateTime-Picker:现代化Vue 3日期时间选择器的完整指南
Vue3-DateTime-Picker:现代化Vue 3日期时间选择器的完整指南 【免费下载链接】vue3-date-time-picker Datepicker component for Vue 3 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-date-time-picker 在当今的Web开发中,日期时间选择器是几…...

TimerBlox:基于电流基准的硬件定时新方案,替代555与MCU
1. 项目概述:重新认识定时电路的设计范式在嵌入式系统、电源管理、电机控制乃至各类信号发生器的设计中,定时功能几乎无处不在。无论是生成一个精确的PWM波去调节LED亮度,还是产生一个可调的时钟信号驱动VCO,亦或是需要一个精准的…...

Aviator表达式引擎:从编译优化到规则引擎实战
1. Aviator表达式引擎初探 第一次接触Aviator是在一个电商风控项目中,当时系统需要处理大量实时交易规则判断。传统的if-else代码已经膨胀到难以维护的程度,每次业务规则变更都需要重新发布。这时候技术负责人推荐了Aviator,一个基于Java的高…...

260513实训:路由器连接
路由器工作原理: 转发动作:路由器收到数据后,根据目的IP地址查路由器路由表(地图)转发 路由表:路由器默认会将直连网段加入路由表 查看IP路由表:display ip routing-table 127.0.0.0/8 本地环…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...

[4G5G专题] RRU CFR技术:从“削峰”到“塑形”的算法演进与工程实践
1. 从“削峰”到“塑形”:CFR技术的本质蜕变 第一次接触CFR(Crest Factor Reduction)技术时,我把它简单理解为“信号削峰器”——就像用菜刀切掉蛋糕顶端多余的部分。早期在4G RRU(Remote Radio Unit)项目中…...

3步解决AKShare金融数据接口stock_zh_a_spot_em异常:完整数据获取指南
3步解决AKShare金融数据接口stock_zh_a_spot_em异常:完整数据获取指南 【免费下载链接】aktools AKTools is an elegant and simple HTTP API library for AKShare, built for AKSharers! 项目地址: https://gitcode.com/gh_mirrors/ak/aktools AKTools作为一…...

stm32开发者如何快速接入大模型api实现智能对话功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 STM32开发者如何快速接入大模型API实现智能对话功能 为嵌入式设备增加自然语言交互能力,是许多STM32开发者希望实现的功…...

基于RT-Thread与N32G457的三通道UART透明监控网关设计与实现
1. 项目概述与核心需求解析在嵌入式开发,特别是涉及工业控制、智能硬件或者多设备联调的现场,我们经常会遇到一个非常实际的痛点:如何在不干扰原有通信链路的前提下,实时监控两台设备之间的串口数据交互。无论是调试新的通信协议&…...