pointnet C++推理部署--tensorrt框架
classification
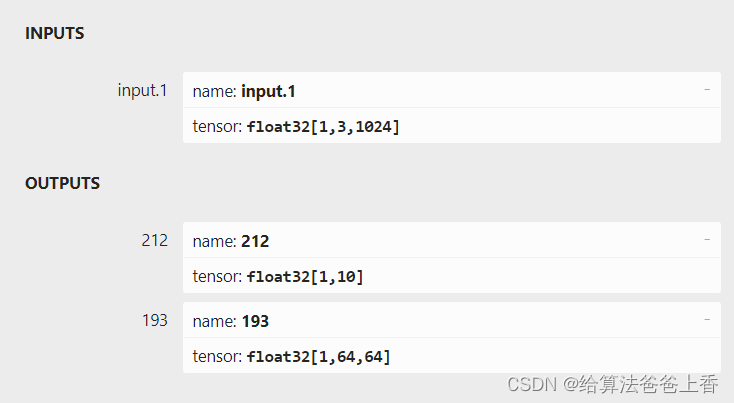
如上图所示,由于直接export出的onnx文件有两个输出节点,不方便处理,所以编写脚本删除不需要的输出节点193:
import onnxonnx_model = onnx.load("cls.onnx")
graph = onnx_model.graphinputs = graph.input
for input in inputs:print('input',input.name)outputs = graph.output
for output in outputs:print('output',output.name)graph.output.remove(outputs[1])
onnx.save(onnx_model, 'cls_modified.onnx')
C++推理代码:
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include <cuda_runtime.h>
#include <NvInfer.h>
#include <NvInferRuntime.h>
#include <NvOnnxParser.h>const int point_num = 1024;void pc_normalize(std::vector<float>& points)
{float mean_x = 0, mean_y = 0, mean_z = 0;for (size_t i = 0; i < point_num; ++i){mean_x += points[3 * i];mean_y += points[3 * i + 1];mean_z += points[3 * i + 2];}mean_x /= point_num;mean_y /= point_num;mean_z /= point_num;for (size_t i = 0; i < point_num; ++i){points[3 * i] -= mean_x;points[3 * i + 1] -= mean_y;points[3 * i + 2] -= mean_z;}float m = 0;for (size_t i = 0; i < point_num; ++i){if (sqrt(pow(points[3 * i], 2) + pow(points[3 * i + 1], 2) + pow(points[3 * i + 2], 2)) > m)m = sqrt(pow(points[3 * i], 2) + pow(points[3 * i + 1], 2) + pow(points[3 * i + 2], 2));}for (size_t i = 0; i < point_num; ++i){points[3 * i] /= m;points[3 * i + 1] /= m;points[3 * i + 2] /= m;}
}class TRTLogger : public nvinfer1::ILogger
{
public:virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override{if (severity <= Severity::kINFO) printf(msg);}
} logger;std::vector<unsigned char> load_file(const std::string& file)
{std::ifstream in(file, std::ios::in | std::ios::binary);if (!in.is_open())return {};in.seekg(0, std::ios::end);size_t length = in.tellg();std::vector<uint8_t> data;if (length > 0) {in.seekg(0, std::ios::beg);data.resize(length);in.read((char*)& data[0], length);}in.close();return data;
}void classfier(std::vector<float> & points)
{TRTLogger logger;nvinfer1::ICudaEngine* engine;//#define BUILD_ENGINE#ifdef BUILD_ENGINEnvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1);nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, logger);if (!parser->parseFromFile("cls_modified.onnx", 1)){printf("Failed to parser onnx\n");return;}int maxBatchSize = 1;config->setMaxWorkspaceSize(1 << 32);engine = builder->buildEngineWithConfig(*network, *config);if (engine == nullptr) {printf("Build engine failed.\n");return;}nvinfer1::IHostMemory* model_data = engine->serialize();FILE* f = fopen("cls.engine", "wb");fwrite(model_data->data(), 1, model_data->size(), f);fclose(f);model_data->destroy();parser->destroy();engine->destroy();network->destroy();config->destroy();builder->destroy();
#endif auto engine_data = load_file("cls.engine");nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());if (engine == nullptr){printf("Deserialize cuda engine failed.\n");runtime->destroy();return;}nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();cudaStream_t stream = nullptr;cudaStreamCreate(&stream);float* input_data_host = nullptr;const size_t input_numel = 1 * 3 * point_num;cudaMallocHost(&input_data_host, input_numel * sizeof(float));for (size_t i = 0; i < 3; i++){for (size_t j = 0; j < point_num; j++){input_data_host[point_num * i + j] = points[3 * j + i];}}float* input_data_device = nullptr;float output_data_host[10];float* output_data_device = nullptr;cudaMalloc(&input_data_device, input_numel * sizeof(float));cudaMalloc(&output_data_device, sizeof(output_data_host));cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream);float* bindings[] = { input_data_device, output_data_device };bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);cudaStreamSynchronize(stream);int predict_label = std::max_element(output_data_host, output_data_host + 10) - output_data_host;std::cout << "\npredict_label: " << predict_label << std::endl;cudaStreamDestroy(stream);execution_context->destroy();engine->destroy();runtime->destroy();
}int main()
{std::vector<float> points;std::ifstream infile;float x, y, z, nx, ny, nz;char ch;infile.open("bed_0610.txt");for (size_t i = 0; i < point_num; i++){infile >> x >> ch >> y >> ch >> z >> ch >> nx >> ch >> ny >> ch >> nz;points.push_back(x);points.push_back(y);points.push_back(z);}infile.close();pc_normalize(points);classfier(points);return 0;
}
其中推理引擎的构建也可以直接使用tensorrt的bin目录下的trtexec.exe。
LZ也实现了cuda版本的前处理代码,但似乎效率比cpu前处理还低。可能是数据量不够大吧(才10^3数量级),而且目前LZ的cuda水平也只是入门阶段…
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#include <NvInfer.h>
#include <NvInferRuntime.h>
#include <NvOnnxParser.h>const int point_num = 1024;
const int thread_num = 1024;
const int block_num = 1;__global__ void array_sum(float* data, float* val, int N)
{__shared__ double share_dTemp[thread_num];const int nStep = gridDim.x * blockDim.x;const int tid = blockIdx.x * blockDim.x + threadIdx.x;double dTempSum = 0.0;for (int i = tid; i < N; i += nStep){dTempSum += data[i];}share_dTemp[threadIdx.x] = dTempSum;__syncthreads();for (int i = blockDim.x / 2; i != 0; i /= 2){if (threadIdx.x < i){share_dTemp[threadIdx.x] += share_dTemp[threadIdx.x + i];}__syncthreads();}if (0 == threadIdx.x){atomicAdd(val, share_dTemp[0]);}
}__global__ void array_sub(float* data, float val, int N)
{const int tid = blockIdx.x * blockDim.x + threadIdx.x;const int nStep = blockDim.x * gridDim.x;for (int i = tid; i < N; i += nStep){data[i] = data[i] - val;}
}__global__ void array_L2(float* in, float* out, int N)
{const int tid = blockIdx.x * blockDim.x + threadIdx.x;const int nStep = blockDim.x * gridDim.x;for (int i = tid; i < N; i += nStep){out[i] = sqrt(pow(in[i], 2) + pow(in[i + N], 2) + pow(in[i + 2 * N], 2));}
}__global__ void array_max(float* mem, int numbers)
{int tid = threadIdx.x;int idof = blockIdx.x * blockDim.x;int idx = tid + idof;extern __shared__ float tep[];if (idx >= numbers) return;tep[tid] = mem[idx];unsigned int bi = 0;for (int s = 1; s < blockDim.x; s = (s << 1)){unsigned int kid = tid << (bi + 1);if ((kid + s) >= blockDim.x || (idof + kid + s) >= numbers) break;tep[kid] = tep[kid] > tep[kid + s] ? tep[kid] : tep[kid + s];++bi;__syncthreads();}if (tid == 0) {mem[blockIdx.x] = tep[0];}
}__global__ void array_div(float* data, float val, int N)
{const int tid = blockIdx.x * blockDim.x + threadIdx.x;const int nStep = blockDim.x * gridDim.x;for (int i = tid; i < N; i += nStep){data[i] = data[i] / val;}
}void pc_normalize_gpu(float* points)
{float *mean_x = NULL, *mean_y = NULL, *mean_z = NULL;cudaMalloc((void**)& mean_x, sizeof(float));cudaMalloc((void**)& mean_y, sizeof(float));cudaMalloc((void**)& mean_z, sizeof(float));array_sum << <thread_num, block_num >> > (points + 0 * point_num, mean_x, point_num);array_sum << <thread_num, block_num >> > (points + 1 * point_num, mean_y, point_num);array_sum << <thread_num, block_num >> > (points + 2 * point_num, mean_z, point_num);float mx, my, mz;cudaMemcpy(&mx, mean_x, sizeof(float), cudaMemcpyDeviceToHost);cudaMemcpy(&my, mean_y, sizeof(float), cudaMemcpyDeviceToHost);cudaMemcpy(&mz, mean_z, sizeof(float), cudaMemcpyDeviceToHost);array_sub << <thread_num, block_num >> > (points + 0 * point_num, mx / point_num, point_num);array_sub << <thread_num, block_num >> > (points + 1 * point_num, my / point_num, point_num);array_sub << <thread_num, block_num >> > (points + 2 * point_num, mz / point_num, point_num);//float* pts = (float*)malloc(sizeof(float) * point_num);//cudaMemcpy(pts, points, sizeof(float) * point_num, cudaMemcpyDeviceToHost);//for (size_t i = 0; i < point_num; i++)//{// std::cout << pts[i] << std::endl;//}float* L2 = NULL;cudaMalloc((void**)& L2, sizeof(float) * point_num);array_L2 << <thread_num, block_num >> > (points, L2, point_num);//float* l2 = (float*)malloc(sizeof(float) * point_num);//cudaMemcpy(l2, L2, sizeof(float) * point_num, cudaMemcpyDeviceToHost);//for (size_t i = 0; i < point_num; i++)//{// std::cout << l2[i] << std::endl;//}int tmp_num = point_num;int share_size = sizeof(float) * thread_num;int block_num = (tmp_num + thread_num - 1) / thread_num;do {array_max << <block_num, thread_num, share_size >> > (L2, thread_num);tmp_num = block_num;block_num = (tmp_num + thread_num - 1) / thread_num;} while (tmp_num > 1);float max;cudaMemcpy(&max, L2, sizeof(float), cudaMemcpyDeviceToHost);//std::cout << max << std::endl;array_div << <thread_num, block_num >> > (points + 0 * point_num, max, point_num);array_div << <thread_num, block_num >> > (points + 1 * point_num, max, point_num);array_div << <thread_num, block_num >> > (points + 2 * point_num, max, point_num);}class TRTLogger : public nvinfer1::ILogger
{
public:virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override{if (severity <= Severity::kINFO) printf(msg);}
} logger;std::vector<unsigned char> load_file(const std::string& file)
{std::ifstream in(file, std::ios::in | std::ios::binary);if (!in.is_open())return {};in.seekg(0, std::ios::end);size_t length = in.tellg();std::vector<uint8_t> data;if (length > 0) {in.seekg(0, std::ios::beg);data.resize(length);in.read((char*)& data[0], length);}in.close();return data;
}void classfier(std::vector<float> & points)
{TRTLogger logger;nvinfer1::ICudaEngine* engine;//#define BUILD_ENGINE#ifdef BUILD_ENGINEnvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger);nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();nvinfer1::INetworkDefinition* network = builder->createNetworkV2(1);nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, logger);if (!parser->parseFromFile("cls_modified.onnx", 1)){printf("Failed to parser onnx\n");return;}int maxBatchSize = 1;config->setMaxWorkspaceSize(1 << 32);engine = builder->buildEngineWithConfig(*network, *config);if (engine == nullptr) {printf("Build engine failed.\n");return;}nvinfer1::IHostMemory* model_data = engine->serialize();FILE* f = fopen("cls.engine", "wb");fwrite(model_data->data(), 1, model_data->size(), f);fclose(f);model_data->destroy();parser->destroy();engine->destroy();network->destroy();config->destroy();builder->destroy();
#endif auto engine_data = load_file("cls.engine");nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);engine = runtime->deserializeCudaEngine(engine_data.data(), engine_data.size());if (engine == nullptr){printf("Deserialize cuda engine failed.\n");runtime->destroy();return;}nvinfer1::IExecutionContext* execution_context = engine->createExecutionContext();cudaStream_t stream = nullptr;cudaStreamCreate(&stream);float* input_data_host = nullptr;const size_t input_numel = 1 * 3 * point_num;cudaMallocHost(&input_data_host, input_numel * sizeof(float));for (size_t i = 0; i < 3; i++){for (size_t j = 0; j < point_num; j++){input_data_host[point_num * i + j] = points[3 * j + i];}}float* input_data_device = nullptr;float output_data_host[10];float* output_data_device = nullptr;cudaMalloc(&input_data_device, input_numel * sizeof(float));cudaMalloc(&output_data_device, sizeof(output_data_host));cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream);pc_normalize_gpu(input_data_device);float* bindings[] = { input_data_device, output_data_device };bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream);cudaStreamSynchronize(stream);int predict_label = std::max_element(output_data_host, output_data_host + 10) - output_data_host;std::cout << "\npredict_label: " << predict_label << std::endl;cudaStreamDestroy(stream);execution_context->destroy();engine->destroy();runtime->destroy();
}int main()
{std::vector<float> points;std::ifstream infile;float x, y, z, nx, ny, nz;char ch;infile.open("sofa_0020.txt");for (size_t i = 0; i < point_num; i++){infile >> x >> ch >> y >> ch >> z >> ch >> nx >> ch >> ny >> ch >> nz;points.push_back(x);points.push_back(y);points.push_back(z);}infile.close();classfier(points);return 0;
}
相关文章:
pointnet C++推理部署--tensorrt框架
classification 如上图所示,由于直接export出的onnx文件有两个输出节点,不方便处理,所以编写脚本删除不需要的输出节点193: import onnxonnx_model onnx.load("cls.onnx") graph onnx_model.graphinputs graph.inpu…...

34.Netty源码之Netty如何处理网络请求
highlight: arduino-light 通过前面两节源码课程的学习,我们知道 Netty 在服务端启动时会为创建 NioServerSocketChannel,当客户端新连接接入时又会创建 NioSocketChannel,不管是服务端还是客户端 Channel,在创建时都会初始化自己…...
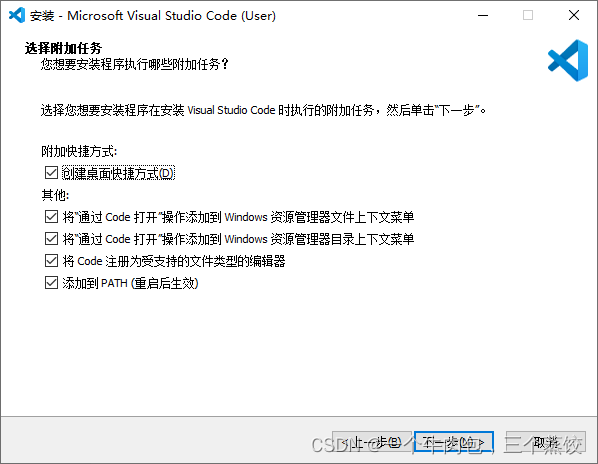
vscode 安装勾选项解释
1、通过code 打开“操作添加到windows资源管理器文件上下文菜单 :把这个两个勾选上,可以对文件使用鼠标右键,选择VSCode 打开。 2、将code注册为受支持的文件类型的编辑器:不建议勾选,这样会默认使用VSCode打开支持的相…...
Spring 6.0官方文档示例(24): replace-method的用法
一、原始bean定义 package cn.edu.tju.study.service.anno.domain;public class MyValueCalculator {public String computeValue(String input) {return "you inputted: " input;}// some other methods... }二、replace bean定义 package cn.edu.tju.study.serv…...
-[聊天消息记录])
自然语言处理从入门到应用——LangChain:记忆(Memory)-[聊天消息记录]
分类目录:《自然语言处理从入门到应用》总目录 Cassandra聊天消息记录 Cassandra是一种分布式数据库,非常适合存储大量数据,是存储聊天消息历史的良好选择,因为它易于扩展,能够处理大量写入操作。 # List of contact…...

Python web实战之细说 Django 的单元测试
关键词: Python Web 开发、Django、单元测试、测试驱动开发、TDD、测试框架、持续集成、自动化测试 大家好,今天,我将带领大家进入 Python Web 开发的新世界,深入探讨 Django 的单元测试。通过本文的实战案例和详细讲解ÿ…...

pytorch 42 C#使用onnxruntime部署内置nms的yolov8模型
在进行目标检测部署时,通常需要自行编码实现对模型预测结果的解码及与预测结果的nms操作。所幸现在的各种部署框架对算子的支持更为灵活,可以在模型内实现预测结果的解码,但仍然需要自行编码实现对预测结果的nms操作。其实在onnx opset===11版本以后,其已支持将nms操作嵌入…...
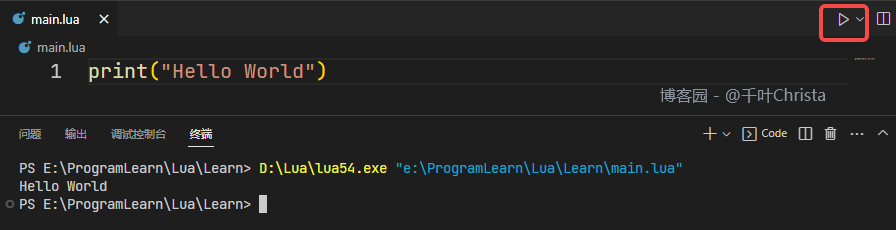
【Lua】(一)VSCode 搭建 Lua 开发环境
前言 最近在找工作,基本所有的岗位都会问到 Lua(甚至拼 UI 的都要求会 Lua),咱能怎么办呢,咱也只能学啊…… 工欲善其事,必先利其器。第一步,先来把环境配置好吧! 当前适用版本&a…...

react-vite-antd环境下新建项目
vite 创建一个react项目 1. 安装vite并创建一个react项目1. 我使用的 yarn安装,基本配置项目名字, 框架react ,js2. cd vite-react进入项目目录安装node包并启动项目 2. 安装引入Ant Design引入依赖(我用的yarn,没有安装的也可以使…...
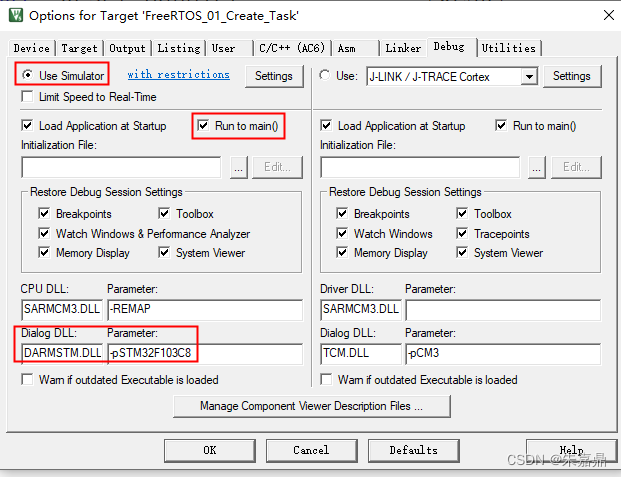
KeilMDk软仿真设置_STM32F03C8
1、KeilMDK软仿真的价值 (1)在没有硬件的情况下进行程序的编写调试。 (2)避免频繁的下载程序,延长单片机Flash寿命。 2、软仿真配置。 (1)打开Keil工程。 (2)点击“Options for Target ***”,如下图所示。 (3)点击“Debug”。 (4)进行如下配置。 U…...

mysql的隐式连接和显式连接的区别
隐式连接(Implicit Join)和显式连接(Explicit Join)是 SQL 查询中用于联结多个表的两种不同语法方式。它们的区别主要体现在语法的书写风格和可读性上。 隐式连接: 隐式连接使用逗号 , 将多个表名放在 FROM 子句中&am…...
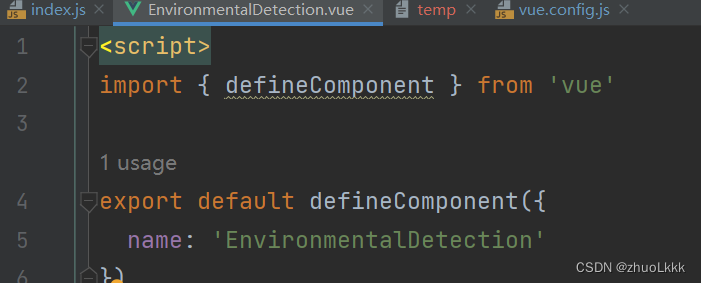
vue-element-admin新增view后点击侧边栏加载慢问题
按照官网文档新增view 新增之后点击显示一直在加载中 解决方案:删除script中这段代码...

论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读 BackgroundIntroducitonProblem StatementMethodology Δ W \Delta W ΔW 的选择 W W W的选择 总结 今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Lan…...

MySQL数据类型篇
数值类型 类型有符号(SIGNED)取值范围无符号(UNSIGNED)取值范围大小描述TINYINT(-128,127)(0,255)1byte小整数值SMALLINT(-32768,32767)(0,65535)2bytes大整数值INT/INTEGER(-2147483648,2147483647)(0,429…...

Eureka注册中心
全部流程 注册服务中心 添加maven依赖 <!--引用注册中心--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> 配置Eureka 因为自…...

代码随想录算法训练营第53天|动态规划part14
8.19周六 1143.最长公共子序列 1035.不相交的线 53. 最大子序和 动态规划 详细布置 1143.最长公共子序列 题目:两个字符串,问最长的公共子序列多长(不连续) 题解: 1、dp[i][j]:长度为[0, i - 1]的字…...
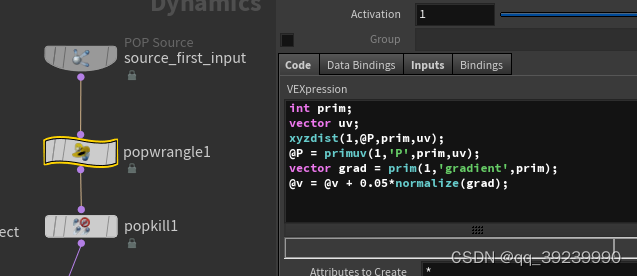
houdini xyzdist primuv 实现按路径走
2. meause distance v 0; add popforce...

Asrock-Z690-PG-Reptide i5-13600kf电脑 Hackintosh 黑苹果引导文件
硬件配置(需要下载请百度搜索:黑果魏叔) 硬件型号驱动情况主板 Asrock Z690 PG Reptide 处理器i5-13600kf RaptorLake (Undervolted)已驱动内存2x16Gb DDR4 3600 ADATA XPG已驱动硬盘1Tb Netac NV7000 NVME M2 (PCI-e 4.0)已驱动显卡Radeon …...
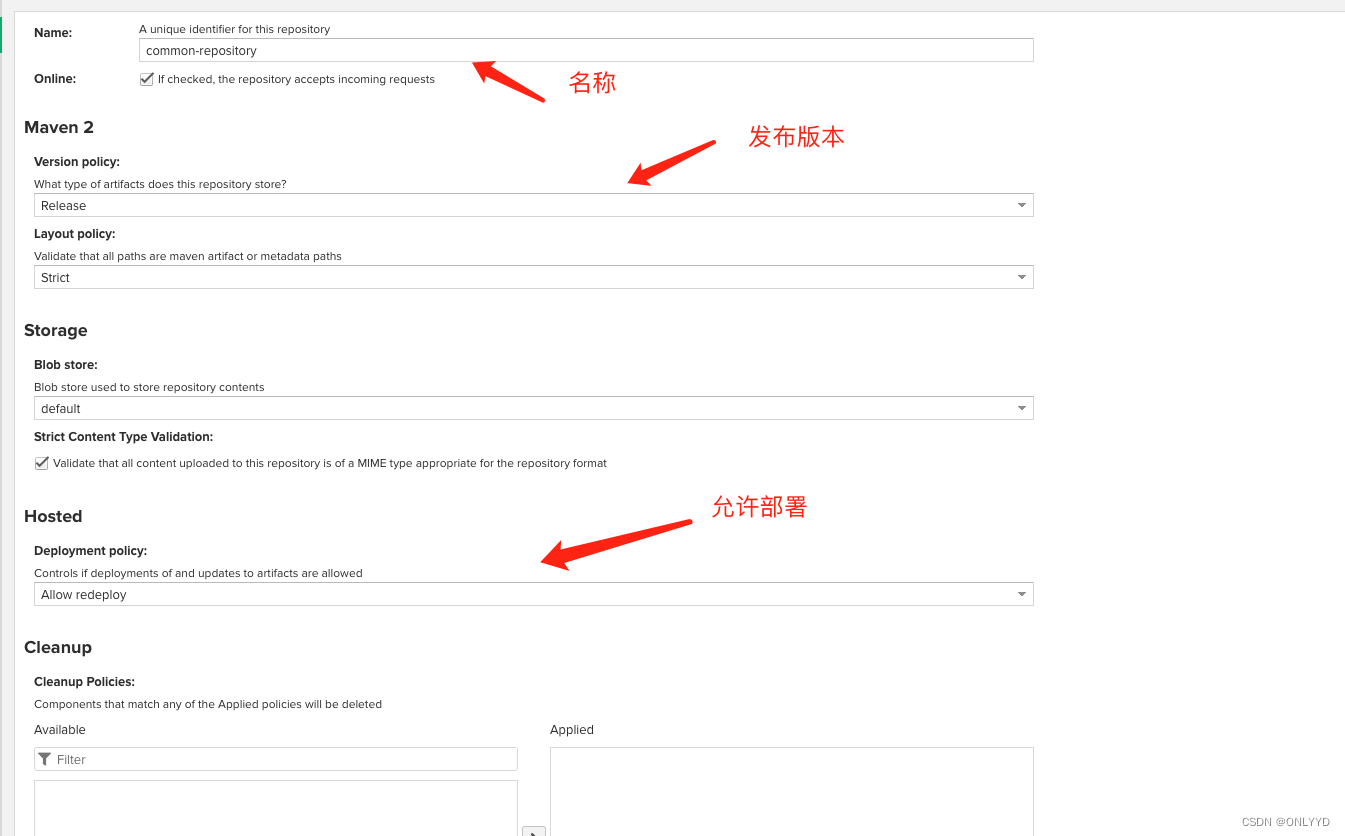
linux 搭建 nexus maven私服
目录 环境: 下载 访问百度网盘链接 官网下载 部署 : 进入目录,创建文件夹,进入文件夹 将安装包放入nexus文件夹,并解压编辑 启动 nexus,并查看状态.编辑 更改 nexus 端口为7020,并重新启动,访问虚拟机7020…...

MySQL中按月统计并逐月累加统计值的几种写法
有时候,我们可能有这样的场景,需要将销量按月统计,并且按月逐月累加。写惯了GROUP BY,按月统计倒是小case,但是逐月累加实现起来,要稍微麻烦一点。下面就整理几种写法,以备不时之需。 本月第一天 -- 本月第一天 SELE…...

开源技能模块开发实战:基于OpenProject API的智能集成与自动化
1. 项目概述与核心价值最近在折腾一个很有意思的开源项目,叫openclaw-skill-openproject。光看这个名字,可能有点摸不着头脑,它其实是ALT-F1-OpenClaw组织下的一个技能模块,专门用于对接和集成OpenProject这个开源的项目管理软件。…...

量子生成分类技术:原理、优势与应用解析
1. 量子生成分类技术概述量子生成分类(Quantum Generative Classification, QGC)是一种基于量子计算原理的新型机器学习范式,它从根本上改变了传统分类任务的实现方式。与常见的判别式学习方法不同,QGC采用生成式学习策略…...

Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面
Six Degrees of Wikipedia技术解析:广度优先搜索算法如何连接百万页面 【免费下载链接】sdow Six Degrees of Wikipedia 项目地址: https://gitcode.com/gh_mirrors/sd/sdow Six Degrees of Wikipedia(简称sdow)是一个基于维基百科页面…...
)
iOS BLE 开发(Swift 实现 + 面试 + 开发必备)
一、BLE 基础概念(必须懂) 1. BLE 是什么 Bluetooth Low Energy 低功耗蓝牙,特点:低功耗、连接快、小数据传输适用于:智能硬件、手环、车机、传感器、设备诊断2. BLE 角色Central(中心设备)&…...

番茄小说下载器终极指南:如何轻松构建个人离线图书馆
番茄小说下载器终极指南:如何轻松构建个人离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否经常在地铁、高铁或飞机上想要阅读番茄小说,…...

实测Taotoken在低功耗arm7设备上的API调用延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken在低功耗arm7设备上的API调用延迟与稳定性表现 1. 测试背景与目的 在边缘计算或资源受限的嵌入式场景中,…...

【UEFI实战】GOP协议详解:从模式查询到像素操作
1. GOP协议基础:UEFI图形显示的核心机制 第一次接触UEFI图形编程时,我被屏幕上突然出现的红色进度条震撼到了——原来在系统启动的早期阶段就能实现图形化显示。这背后的关键就是EFI_GRAPHICS_OUTPUT_PROTOCOL(简称GOP)࿰…...

从‘调制方向’到‘闭环稳定’:一个公式搞定单相PWM整流器电流环PI参数整定
从动态模型到实战调参:单相PWM整流器电流环PI整定的工程化方法 在电力电子控制领域,单相PWM整流器的电流环设计一直是工程师面临的实操难点。理论教材中复杂的传递函数推导与实验室里实际系统的振荡现象之间,往往存在一道需要经验跨越的鸿沟…...

NLP知识图谱构建实战:从文本到结构化知识的完整流程
1. 项目概述:当NLP遇上知识图谱如果你在NLP(自然语言处理)领域摸爬滚打了一段时间,或者对知识图谱(Knowledge Graph)这个听起来就很有“智慧感”的东西感兴趣,那么你大概率在GitHub上见过或搜索…...

无显式ID推荐系统:从冷启动到跨域泛化的核心技术解析
1. 项目概述:当推荐系统“看不见”用户与物品在推荐系统这个领域里干了十几年,我见过太多模型把“用户ID”和“物品ID”当作理所当然的输入。这就像我们认识一个人,首先记住的是他的名字和长相。传统的协同过滤(Collaborative Fil…...