自然语言处理从入门到应用——LangChain:记忆(Memory)-[聊天消息记录]
分类目录:《自然语言处理从入门到应用》总目录
Cassandra聊天消息记录
Cassandra是一种分布式数据库,非常适合存储大量数据,是存储聊天消息历史的良好选择,因为它易于扩展,能够处理大量写入操作。
# List of contact points to try connecting to Cassandra cluster.
contact_points = ["cassandra"]from langchain.memory import CassandraChatMessageHistorymessage_history = CassandraChatMessageHistory(contact_points=contact_points, session_id="test-session"
)message_history.add_user_message("hi!")message_history.add_ai_message("whats up?")
message_history.messages
[HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]
DynamoDB聊天消息记录
首先确保我们已经正确配置了AWS CLI,并再确保我们已经安装了boto3。接下来,创建我们将存储消息 DynamoDB表:
import boto3# Get the service resource.
dynamodb = boto3.resource('dynamodb')# Create the DynamoDB table.
table = dynamodb.create_table(TableName='SessionTable',KeySchema=[{'AttributeName': 'SessionId','KeyType': 'HASH'}],AttributeDefinitions=[{'AttributeName': 'SessionId','AttributeType': 'S'}],BillingMode='PAY_PER_REQUEST',
)# Wait until the table exists.
table.meta.client.get_waiter('table_exists').wait(TableName='SessionTable')# Print out some data about the table.
print(table.item_count)
输出:
0
DynamoDBChatMessageHistory
from langchain.memory.chat_message_histories import DynamoDBChatMessageHistoryhistory = DynamoDBChatMessageHistory(table_name="SessionTable", session_id="0")
history.add_user_message("hi!")
history.add_ai_message("whats up?")
history.messages
输出:
[HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]
使用自定义端点URL的DynamoDBChatMessageHistory
有时候在连接到AWS端点时指定URL非常有用,比如在本地使用Localstack进行开发。对于这种情况,我们可以通过构造函数中的endpoint_url参数来指定URL。
from langchain.memory.chat_message_histories import DynamoDBChatMessageHistoryhistory = DynamoDBChatMessageHistory(table_name="SessionTable", session_id="0", endpoint_url="http://localhost.localstack.cloud:4566")
Agent with DynamoDB Memory
from langchain.agents import Tool
from langchain.memory import ConversationBufferMemory
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.utilities import PythonREPL
from getpass import getpassmessage_history = DynamoDBChatMessageHistory(table_name="SessionTable", session_id="1")
memory = ConversationBufferMemory(memory_key="chat_history", chat_memory=message_history, return_messages=True)
python_repl = PythonREPL()# You can create the tool to pass to an agent
tools = [Tool(name="python_repl",description="A Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`.",func=python_repl.run
)]
llm=ChatOpenAI(temperature=0)
agent_chain = initialize_agent(tools, llm, agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION, verbose=True, memory=memory)
agent_chain.run(input="Hello!")
日志输出:
> Entering new AgentExecutor chain...
{"action": "Final Answer","action_input": "Hello! How can I assist you today?"
}> Finished chain.
输出:
'Hello! How can I assist you today?'
输入:
agent_chain.run(input="Who owns Twitter?")
日志输出:
> Entering new AgentExecutor chain...
{"action": "python_repl","action_input": "import requests\nfrom bs4 import BeautifulSoup\n\nurl = 'https://en.wikipedia.org/wiki/Twitter'\nresponse = requests.get(url)\nsoup = BeautifulSoup(response.content, 'html.parser')\nowner = soup.find('th', text='Owner').find_next_sibling('td').text.strip()\nprint(owner)"
}
Observation: X Corp. (2023–present)Twitter, Inc. (2006–2023)Thought:{"action": "Final Answer","action_input": "X Corp. (2023–present)Twitter, Inc. (2006–2023)"
}> Finished chain.
输出:
'X Corp. (2023–present)Twitter, Inc. (2006–2023)'
输入:
agent_chain.run(input="My name is Bob.")
日志输出:
> Entering new AgentExecutor chain...
{"action": "Final Answer","action_input": "Hello Bob! How can I assist you today?"
}> Finished chain.
输出:
'Hello Bob! How can I assist you today?'
输入:
agent_chain.run(input="Who am I?")
日志输出:
> Entering new AgentExecutor chain...
{"action": "Final Answer","action_input": "Your name is Bob."
}> Finished chain.
输出:
'Your name is Bob.'
Momento聊天消息记录
本节介绍如何使用Momento Cache来存储聊天消息记录,我们会使用MomentoChatMessageHistory类。需要注意的是,默认情况下,如果不存在具有给定名称的缓存,我们将创建一个新的缓存。我们需要获得一个Momento授权令牌才能使用这个类。这可以直接通过将其传递给momento.CacheClient实例化,作为MomentoChatMessageHistory.from_client_params的命名参数auth_token,或者可以将其设置为环境变量MOMENTO_AUTH_TOKEN。
from datetime import timedelta
from langchain.memory import MomentoChatMessageHistorysession_id = "foo"
cache_name = "langchain"
ttl = timedelta(days=1)
history = MomentoChatMessageHistory.from_client_params(session_id, cache_name,ttl,
)history.add_user_message("hi!")history.add_ai_message("whats up?")
history.messages
输出:
[HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]
MongoDB聊天消息记录
本节介绍如何使用MongoDB存储聊天消息记录。MongoDB是一个开放源代码的跨平台文档导向数据库程序。它被归类为NoSQL数据库程序,使用类似JSON的文档,并且支持可选的模式。MongoDB由MongoDB Inc.开发,并在服务器端公共许可证(SSPL)下许可。
# Provide the connection string to connect to the MongoDB database
connection_string = "mongodb://mongo_user:password123@mongo:27017"
from langchain.memory import MongoDBChatMessageHistorymessage_history = MongoDBChatMessageHistory(connection_string=connection_string, session_id="test-session")message_history.add_user_message("hi!")message_history.add_ai_message("whats up?")
message_history.messages
输出:
[HumanMessage(content='hi!', additional_kwargs={}, example=False),
AIMessage(content='whats up?', additional_kwargs={}, example=False)]
Postgres聊天消息历史记录
本节介绍了如何使用 Postgres 来存储聊天消息历史记录。
from langchain.memory import PostgresChatMessageHistoryhistory = PostgresChatMessageHistory(connection_string="postgresql://postgres:mypassword@localhost/chat_history", session_id="foo")history.add_user_message("hi!")history.add_ai_message("whats up?")
history.messages
Redis聊天消息历史记录
本节介绍了如何使用Redis来存储聊天消息历史记录。
from langchain.memory import RedisChatMessageHistoryhistory = RedisChatMessageHistory("foo")history.add_user_message("hi!")
history.add_ai_message("whats up?")
history.messages
输出:
[AIMessage(content='whats up?', additional_kwargs={}),
HumanMessage(content='hi!', additional_kwargs={})]
参考文献:
[1] LangChain官方网站:https://www.langchain.com/
[2] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[3] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[聊天消息记录])
自然语言处理从入门到应用——LangChain:记忆(Memory)-[聊天消息记录]
分类目录:《自然语言处理从入门到应用》总目录 Cassandra聊天消息记录 Cassandra是一种分布式数据库,非常适合存储大量数据,是存储聊天消息历史的良好选择,因为它易于扩展,能够处理大量写入操作。 # List of contact…...

Python web实战之细说 Django 的单元测试
关键词: Python Web 开发、Django、单元测试、测试驱动开发、TDD、测试框架、持续集成、自动化测试 大家好,今天,我将带领大家进入 Python Web 开发的新世界,深入探讨 Django 的单元测试。通过本文的实战案例和详细讲解ÿ…...

pytorch 42 C#使用onnxruntime部署内置nms的yolov8模型
在进行目标检测部署时,通常需要自行编码实现对模型预测结果的解码及与预测结果的nms操作。所幸现在的各种部署框架对算子的支持更为灵活,可以在模型内实现预测结果的解码,但仍然需要自行编码实现对预测结果的nms操作。其实在onnx opset===11版本以后,其已支持将nms操作嵌入…...
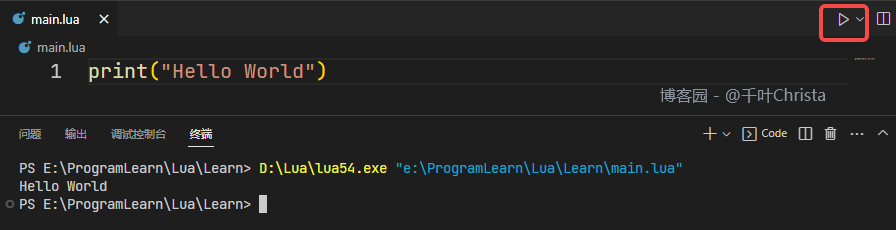
【Lua】(一)VSCode 搭建 Lua 开发环境
前言 最近在找工作,基本所有的岗位都会问到 Lua(甚至拼 UI 的都要求会 Lua),咱能怎么办呢,咱也只能学啊…… 工欲善其事,必先利其器。第一步,先来把环境配置好吧! 当前适用版本&a…...

react-vite-antd环境下新建项目
vite 创建一个react项目 1. 安装vite并创建一个react项目1. 我使用的 yarn安装,基本配置项目名字, 框架react ,js2. cd vite-react进入项目目录安装node包并启动项目 2. 安装引入Ant Design引入依赖(我用的yarn,没有安装的也可以使…...
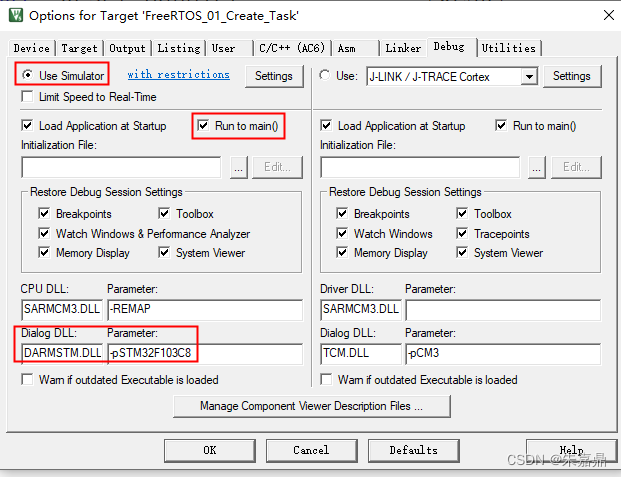
KeilMDk软仿真设置_STM32F03C8
1、KeilMDK软仿真的价值 (1)在没有硬件的情况下进行程序的编写调试。 (2)避免频繁的下载程序,延长单片机Flash寿命。 2、软仿真配置。 (1)打开Keil工程。 (2)点击“Options for Target ***”,如下图所示。 (3)点击“Debug”。 (4)进行如下配置。 U…...

mysql的隐式连接和显式连接的区别
隐式连接(Implicit Join)和显式连接(Explicit Join)是 SQL 查询中用于联结多个表的两种不同语法方式。它们的区别主要体现在语法的书写风格和可读性上。 隐式连接: 隐式连接使用逗号 , 将多个表名放在 FROM 子句中&am…...
vue-element-admin新增view后点击侧边栏加载慢问题
按照官网文档新增view 新增之后点击显示一直在加载中 解决方案:删除script中这段代码...

论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读 BackgroundIntroducitonProblem StatementMethodology Δ W \Delta W ΔW 的选择 W W W的选择 总结 今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Lan…...

MySQL数据类型篇
数值类型 类型有符号(SIGNED)取值范围无符号(UNSIGNED)取值范围大小描述TINYINT(-128,127)(0,255)1byte小整数值SMALLINT(-32768,32767)(0,65535)2bytes大整数值INT/INTEGER(-2147483648,2147483647)(0,429…...

Eureka注册中心
全部流程 注册服务中心 添加maven依赖 <!--引用注册中心--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> 配置Eureka 因为自…...

代码随想录算法训练营第53天|动态规划part14
8.19周六 1143.最长公共子序列 1035.不相交的线 53. 最大子序和 动态规划 详细布置 1143.最长公共子序列 题目:两个字符串,问最长的公共子序列多长(不连续) 题解: 1、dp[i][j]:长度为[0, i - 1]的字…...
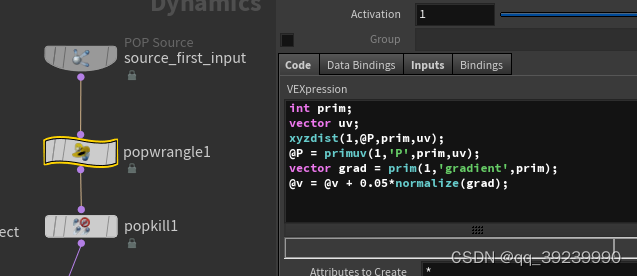
houdini xyzdist primuv 实现按路径走
2. meause distance v 0; add popforce...

Asrock-Z690-PG-Reptide i5-13600kf电脑 Hackintosh 黑苹果引导文件
硬件配置(需要下载请百度搜索:黑果魏叔) 硬件型号驱动情况主板 Asrock Z690 PG Reptide 处理器i5-13600kf RaptorLake (Undervolted)已驱动内存2x16Gb DDR4 3600 ADATA XPG已驱动硬盘1Tb Netac NV7000 NVME M2 (PCI-e 4.0)已驱动显卡Radeon …...
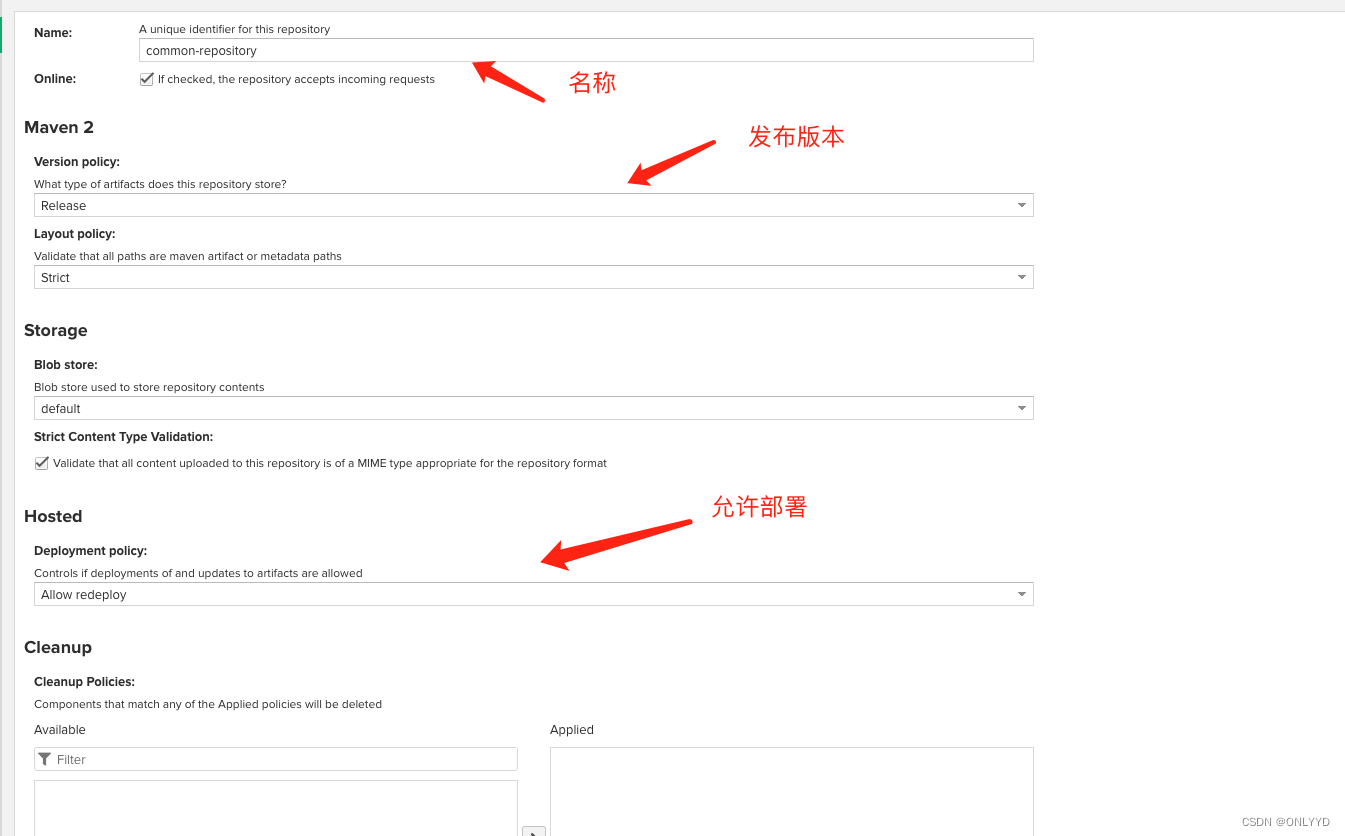
linux 搭建 nexus maven私服
目录 环境: 下载 访问百度网盘链接 官网下载 部署 : 进入目录,创建文件夹,进入文件夹 将安装包放入nexus文件夹,并解压编辑 启动 nexus,并查看状态.编辑 更改 nexus 端口为7020,并重新启动,访问虚拟机7020…...

MySQL中按月统计并逐月累加统计值的几种写法
有时候,我们可能有这样的场景,需要将销量按月统计,并且按月逐月累加。写惯了GROUP BY,按月统计倒是小case,但是逐月累加实现起来,要稍微麻烦一点。下面就整理几种写法,以备不时之需。 本月第一天 -- 本月第一天 SELE…...
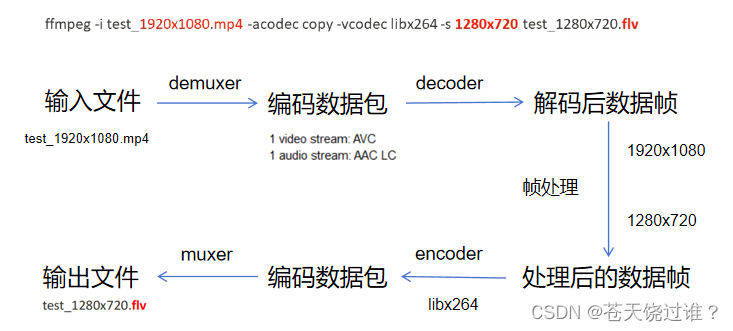
音视频 FFmpeg音视频处理流程
ffmpeg -i test_1920x1080.mp4 -acodec copy -vcodec libx264 -s 1280x720 test_1280x720.flv推荐一个零声学院项目课,个人觉得老师讲得不错,分享给大家: 零声白金学习卡(含基础架构/高性能存储/golang云原生/音视频/Linux内核&am…...

Linux网络编程:多进程 多线程_并发服务器
文章目录: 一:wrap常用函数封装 wrap.h wrap.c server.c client.c 二:多进程process并发服务器 实现思路 server.c服务器 client.c客户端 三:多线程thread并发服务器 实现思路 server.c服务器 client.c客户端 一&am…...
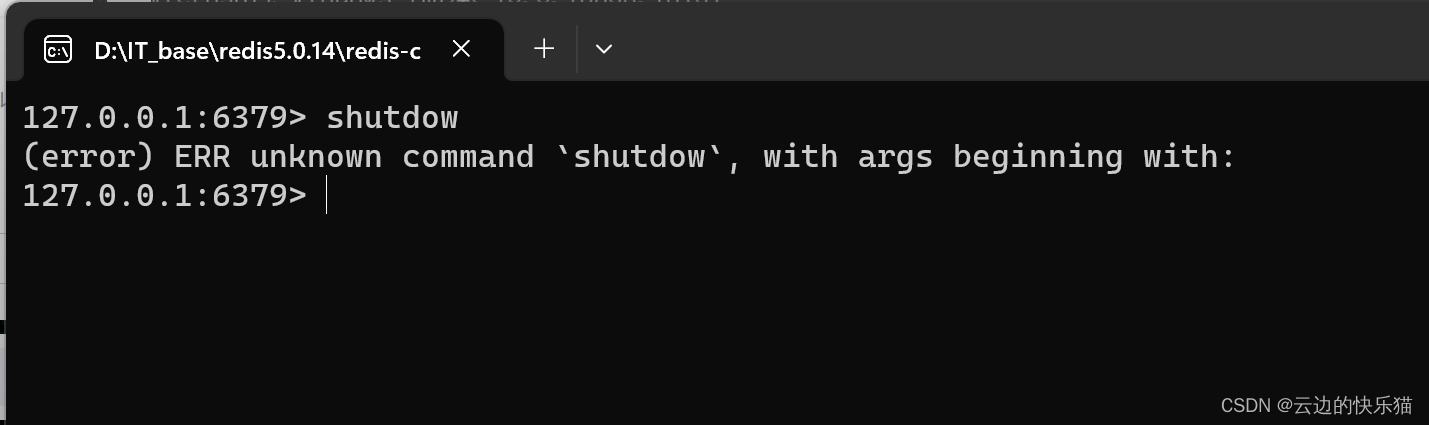
解决:(error) ERR unknown command shutdow,with args beginning with
目录 一、遇到问题 二、出现问题的原因 三、解决办法 一、遇到问题 要解决连接redis闪退的问题,按照许多的方式去进行都没有成功,在尝试使用了以下的命名去尝试时候,发现了这个问题。 二、出现问题的原因 这是一个粗心大意导致的错误&am…...

《TCP IP网络编程》第十八章
第 18 章 多线程服务器端的实现 18.1 理解线程的概念 线程背景: 第 10 章介绍了多进程服务端的实现方法。多进程模型与 select 和 epoll 相比的确有自身的优点,但同时也有问题。如前所述,创建(复制)进程的工作本身会…...

Taotoken API Key的精细化管理与审计日志功能实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key的精细化管理与审计日志功能实践 对于需要将大模型能力集成到业务流程中的团队而言,API Key的管理与安…...

CentOS LVM实战:动态调整home与root分区空间,解决系统盘爆满难题
1. 当服务器根分区告急时,你该怎么办? 最近接手了一台运行了3年的CentOS服务器,刚登录就发现系统弹出了"磁盘空间不足"的警告。df -h一看,好家伙,根分区(/)已经用了98%,而…...

免费Windows风扇控制神器:FanControl让你的电脑静音又凉爽
免费Windows风扇控制神器:FanControl让你的电脑静音又凉爽 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendin…...

终极指南:fmt库如何用SFINAE和Concepts构建现代C++类型特征系统
终极指南:fmt库如何用SFINAE和Concepts构建现代C类型特征系统 【免费下载链接】fmt A modern formatting library 项目地址: https://gitcode.com/GitHub_Trending/fm/fmt fmt库作为现代C格式化库的典范,巧妙融合了SFINAE(Substitutio…...

怎么快速降AI率?答辩前1周从60%降到10%以内实操指南!
怎么快速降AI率?答辩前1周从60%降到10%以内实操指南! 答辩前 1 周拿到 AI 率 65% 报告,是什么具体场景? 周一早上 9 点。我硕士答辩定在下周一上午 9 点——还有整整 7 天。导师周日晚发消息:「答辩前再送一次维普看…...

Next.js静态站点图片优化实战:next-image-export-optimizer配置指南
1. 项目概述:为什么我们需要一个“静态图片优化器”?如果你和我一样,经常用 Next.js 做项目,那你肯定对next/image组件又爱又恨。爱的是它开箱即用的图片懒加载、自动格式转换和响应式适配,恨的是它在构建和部署时带来…...

还在用高斯牛顿法?看看有全局最优保证的求解器!
点击下方卡片,关注「3D视觉工坊」公众号选择星标,干货第一时间送达3D视觉工坊很荣幸邀请到了西湖大学与浙江大学联合培养项目的博士生三年级研究生廖邦彦,为大家着重分享他们团队的工作。如果您有相关内容需要分享,欢迎文末联系我…...

Android自动化测试代理droidrun-agent:原理、实现与工程实践
1. 项目概述:一个面向Android应用的自动化测试代理在移动应用开发与测试领域,自动化测试是保障应用质量、提升迭代效率的核心环节。对于Android平台,虽然官方提供了Espresso、UI Automator等成熟的测试框架,但在面对复杂业务场景、…...

基于Cursor的AI编程助手:从提示词工程到个性化工作流配置
1. 项目概述:一个基于Cursor的AI编程助手最近在GitHub上看到一个挺有意思的项目,叫mk-knight23/AI-ASSISTANT-CURSOR。乍一看名字,你可能以为又是一个普通的AI代码生成工具,但仔细研究下来,发现它的定位和实现思路有点…...

用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法
用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法 当数学建模问题遇上Python编程,会产生怎样的化学反应?本文将以2020年高教杯数学建模国赛B题"穿越沙漠"为例,带你从零开始构建一个完整的路径规划…...