论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
- Background
- Introduciton
- Problem Statement
- Methodology
- 总结
今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Language Models》,论文提出了大模型 tuning 框架 LoRA (Low-Rank Adaptation)。
论文地址:https://openreview.net/pdf?id=nZeVKeeFYf9
附录下载地址:https://openreview.net/attachment?id=nZeVKeeFYf9&name=supplementary_material
代码地址:https://github.com/microsoft/LoRA
Background
一些术语介绍:
· Intrinsic Dimension(本征维度):An objective function’s intrinsic dimensionality describes the minimum dimension needed to solve the optimization problem it defines to some precision level. 是指在pre-trained LLM中,对于下游的tuning工作,实际上不需要对模型所有参数都进行更新,在保证某种精度(如90%)的要求下,可以只更新一部分就可以了(可称为 d 90 d_{90} d90)。
few-shot learning:少样本学习。借助于少样本学习,大模型在特定下游任务的训练过程中,只需要少数的特定任务数据就可以发挥不错的性能。
Prompt Engineering:提示工程。这是 LLM 在 NLP 应用中的特有应用,类似于特征工程,是一种需要专家背景知识,通过组织input的格式,风格等内容,使得输入内容对LLM能够具备更好的促进作用。
Adaptation:适应。也就是大模型对特定下游任务的tuning,使其能够在下游任务中性能更好。
Introduciton
本文提出的主要出发点在于 大模型 的训练模式,即先通过对 大量的 task-independent 语料的预训练,然后再在特定任务上进行精调 fine-tuning,使得模型能够在特定的下游任务中展现较好的表现。
这里就出现一个问题,大模型无论是在存储还是计算上,都是很大的,需要很大的算力和存储。Fine-tuning所有参数就会很费时费力。举例来说,GPT-3 175B总共包含175 billion个参数,也就是1750亿个,fine-tuning所有层,所有Transformer中的Q K V 和 output 矩阵加上 bias,可想而知是一个很大的开销。如何解决这个问题构成本文的 Motivation。
当然已经有诸多此类问题的解决方案。例如,Adapter Layer,也就是在Transformer中插入了两层Adapter Layer 来适应下游任务,只更新Adapter Layer 中的参数,原来的Transformer中的参数 不进行更新。这类模型的问题在于,Adapter Layer 和原来的大模型参数是从输入到输出上下夹在一起的(类似于汉堡),参数计算时必须从输入到输出一层一层进行。那么模型在推理的时候,就必然涉及到等上一层计算完才可以计算下一层,那么就带来了模型的延迟,影响模型体验。
作者提出了低秩矩阵乘法作为任意矩阵 W W W的 特定增量 Δ W \Delta W ΔW,通过只更新 Δ W \Delta W ΔW 的方式减小模型开销的同时,保住模型性能。
是的,模型就是这么“简单”,但是一方面模型的切入点非常犀利;另一方面模型性能不错且带来了巨大的 tuning 节省,让贫穷的学生党探索大模型时能够更自如一些;同时,本文的实验部分也非常充分(附录中),在不同benchmark中的表现都能够佐证LoRA模型的有效性。

Problem Statement
首先是问题形式化,对于fine-tuning,就是把预训练完成的所有参数checkpoint进行存储dump,在精调阶段,将所有参数初始化为dump出来的value,以此作为参数更新的起始点,完成模型优化。表示如下:
max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) (1) \max _{\Phi} \sum_{(x, y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left(P_{\Phi}\left(y_{t} \mid x, y_{<t}\right)\right) \tag{1} Φmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))(1)
如上所示,通过对下游任务数据集 Z \mathcal{Z} Z 进行模型所有参数 Φ \Phi Φ 的更新。如果 Φ {\Phi} Φ 很大,那么fine-tuning 就会很麻烦。
对此,作者提出了只更新 task-specific 的 新引入的 少量的参数 Δ Φ = Δ Φ ( Θ ) \Delta \Phi = \Delta \Phi(\Theta) ΔΦ=ΔΦ(Θ),完成模型的tuning。这里 Θ \Theta Θ 是新参数,而且维度相比较于原LLM模型很小( ∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta| \ll |\Phi_{0}| ∣Θ∣≪∣Φ0∣。作者指出,LoRA能够将需要更新的参数数量缩小到万分之一的地步。
max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) (2) \max _{\Theta} \sum_{(x, y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left(p_{\Phi_{0}+\Delta \Phi(\Theta)}\left(y_{t} \mid x, y_{<t}\right)\right) \tag{2} Θmax(x,y)∈Z∑t=1∑∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))(2)
Methodology
LoRA的具体设计实际上用两句话可以完成概括,(1)引入低秩矩阵进行 Δ W \Delta W ΔW 的计算;(2)选择哪些矩阵进行引入。
Δ W \Delta W ΔW 的选择
对于 Δ W \Delta W ΔW 的计算,如下所示:
h = W 0 x + Δ W x = W 0 x + B A x (3) h=W_{0} x+\Delta W x=W_{0} x+B A x \tag{3} h=W0x+ΔWx=W0x+BAx(3)
即,针对Transformer中的矩阵,加入一个 B ⋅ A B \cdot A B⋅A 的操作,其中, B B B 和 A A A 共享的那个维度是 r r r,远小于 输入维度( x x x 的维度)和 输出维度 ( h h h 的维度)。
W W W的选择
Transformer中的几个矩阵可以分为四类,这里分别表示为Q/K/V/O,分别对应到query/key/value/output。作者在附录中加入了对矩阵的选择(所有可训练参数总数18M, 18 M / 175 B ≈ 1 / 10 K 18M/175B \approx 1/10K 18M/175B≈1/10K),可以看到对QKVO所有矩阵都进行更新,性能最佳。但是在文中,作者普遍使用了只更新QV的方式,并说QV表现更好,这里不太明白。

总结
本文simple but effective,值得一看!
相关文章:
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读
论文《LoRA: Low-Rank Adaptation of Large Language Models》阅读 BackgroundIntroducitonProblem StatementMethodology Δ W \Delta W ΔW 的选择 W W W的选择 总结 今天带来的是由微软Edward Hu等人完成并发表在ICLR 2022上的论文《LoRA: Low-Rank Adaptation of Large Lan…...

MySQL数据类型篇
数值类型 类型有符号(SIGNED)取值范围无符号(UNSIGNED)取值范围大小描述TINYINT(-128,127)(0,255)1byte小整数值SMALLINT(-32768,32767)(0,65535)2bytes大整数值INT/INTEGER(-2147483648,2147483647)(0,429…...

Eureka注册中心
全部流程 注册服务中心 添加maven依赖 <!--引用注册中心--> <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-server</artifactId> </dependency> 配置Eureka 因为自…...

代码随想录算法训练营第53天|动态规划part14
8.19周六 1143.最长公共子序列 1035.不相交的线 53. 最大子序和 动态规划 详细布置 1143.最长公共子序列 题目:两个字符串,问最长的公共子序列多长(不连续) 题解: 1、dp[i][j]:长度为[0, i - 1]的字…...
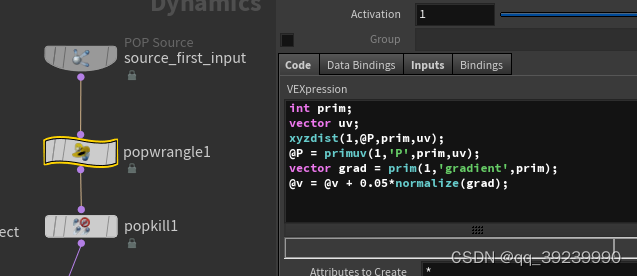
houdini xyzdist primuv 实现按路径走
2. meause distance v 0; add popforce...

Asrock-Z690-PG-Reptide i5-13600kf电脑 Hackintosh 黑苹果引导文件
硬件配置(需要下载请百度搜索:黑果魏叔) 硬件型号驱动情况主板 Asrock Z690 PG Reptide 处理器i5-13600kf RaptorLake (Undervolted)已驱动内存2x16Gb DDR4 3600 ADATA XPG已驱动硬盘1Tb Netac NV7000 NVME M2 (PCI-e 4.0)已驱动显卡Radeon …...
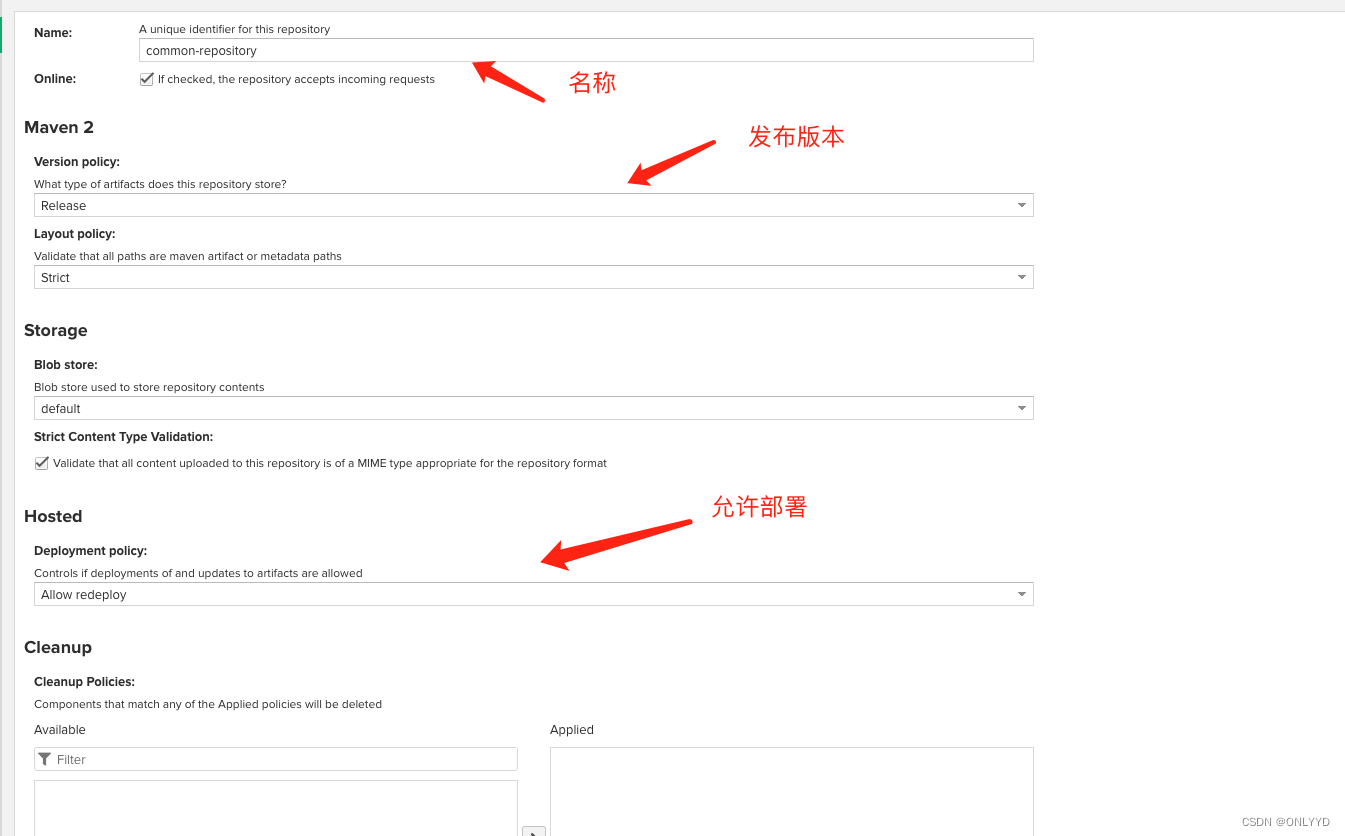
linux 搭建 nexus maven私服
目录 环境: 下载 访问百度网盘链接 官网下载 部署 : 进入目录,创建文件夹,进入文件夹 将安装包放入nexus文件夹,并解压编辑 启动 nexus,并查看状态.编辑 更改 nexus 端口为7020,并重新启动,访问虚拟机7020…...

MySQL中按月统计并逐月累加统计值的几种写法
有时候,我们可能有这样的场景,需要将销量按月统计,并且按月逐月累加。写惯了GROUP BY,按月统计倒是小case,但是逐月累加实现起来,要稍微麻烦一点。下面就整理几种写法,以备不时之需。 本月第一天 -- 本月第一天 SELE…...
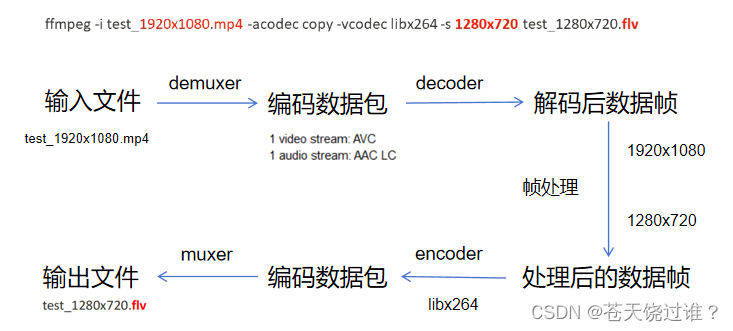
音视频 FFmpeg音视频处理流程
ffmpeg -i test_1920x1080.mp4 -acodec copy -vcodec libx264 -s 1280x720 test_1280x720.flv推荐一个零声学院项目课,个人觉得老师讲得不错,分享给大家: 零声白金学习卡(含基础架构/高性能存储/golang云原生/音视频/Linux内核&am…...

Linux网络编程:多进程 多线程_并发服务器
文章目录: 一:wrap常用函数封装 wrap.h wrap.c server.c client.c 二:多进程process并发服务器 实现思路 server.c服务器 client.c客户端 三:多线程thread并发服务器 实现思路 server.c服务器 client.c客户端 一&am…...
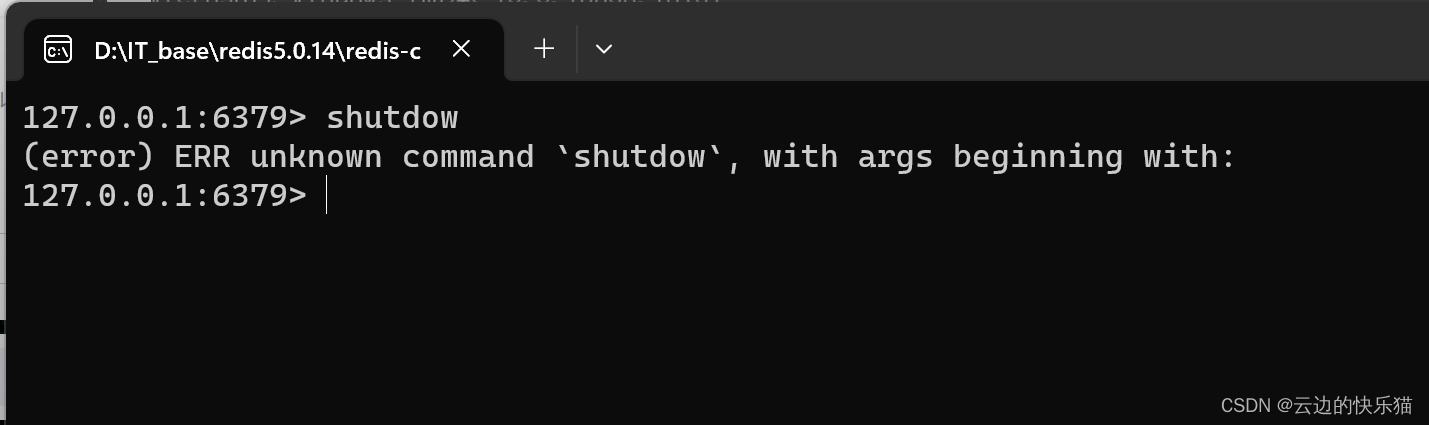
解决:(error) ERR unknown command shutdow,with args beginning with
目录 一、遇到问题 二、出现问题的原因 三、解决办法 一、遇到问题 要解决连接redis闪退的问题,按照许多的方式去进行都没有成功,在尝试使用了以下的命名去尝试时候,发现了这个问题。 二、出现问题的原因 这是一个粗心大意导致的错误&am…...

《TCP IP网络编程》第十八章
第 18 章 多线程服务器端的实现 18.1 理解线程的概念 线程背景: 第 10 章介绍了多进程服务端的实现方法。多进程模型与 select 和 epoll 相比的确有自身的优点,但同时也有问题。如前所述,创建(复制)进程的工作本身会…...

TCP编程流程
目录 1、主机字节序列和网络字节序列 2、套接字地址结构 3、IP地址转换函数 4、TCP协议编程: (1)服务器端: (2)客户端: 1、主机字节序列和网络字节序列 主机字节序列分为大端字节序和小端字节序 大端…...
)
CSDN编程题-每日一练(2023-08-19)
CSDN编程题-每日一练(2023-08-19) 一、题目名称:风险投资二、题目名称:幼稚班作业三、题目名称:韩信点兵一、题目名称:风险投资 时间限制:1000ms内存限制:256M 题目描述: 风险投资是一种感性和理性并存的投资方式,风险投资人一般会对请公允的第三方评估公司对投资对象…...
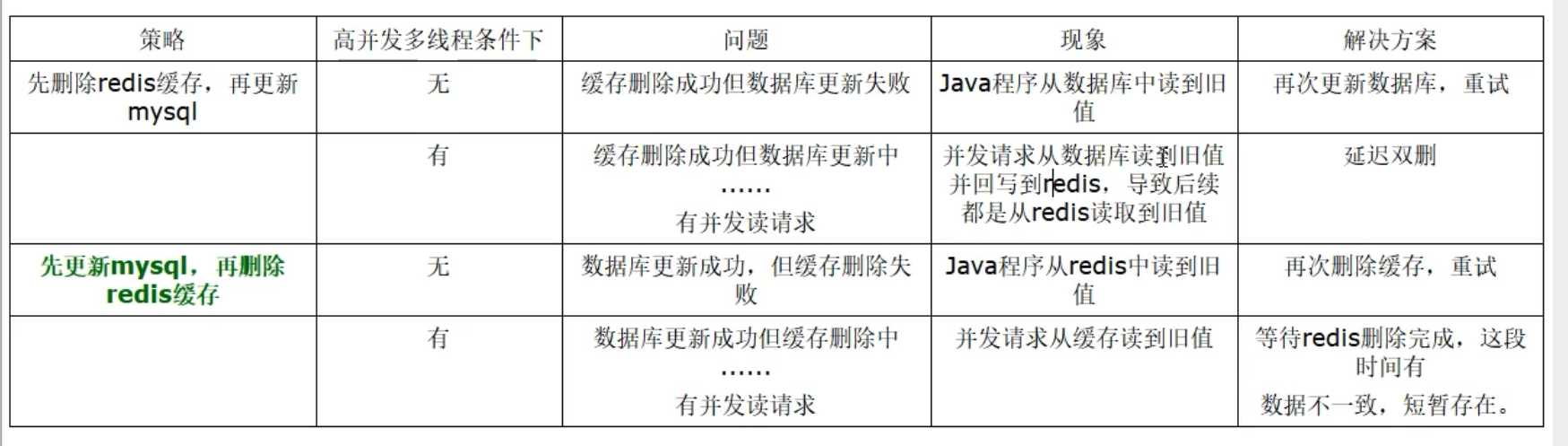
03_缓存双写一致性
03——缓存双写一致性 一、缓存双写一致性 如果redis中有数据,需要和数据库中的值相同如果redis中无数据,数据库中的值要是最新值,且准备回写redis 缓存按照操作来分,可以分为两种: 只读缓存 读写缓存 同步直写操作…...

机器学习之数据集
目录 1、简介 2、可用数据集 3、scikit-learn数据集API 3.1、小数据集 3.2、大数据集 4、数据集使用 ⭐所属专栏:人工智能 文中提到的代码如有需要可以私信我发给你😊 1、简介 当谈论数据集时,通常是指在机器学习和数据分析中使用的一组…...

PyTorch Geometric基本教程
PyG官方文档 # Install torch geometric !pip install -q torch-scatter -f https://pytorch-geometric.com/whl/torch-1.10.2cu102.html !pip install -q torch-sparse -f https://pytorch-geometric.com/whl/torch-1.10.2cu102.html !pip install -q torch-geometricimport t…...

MAC 命令行启动tomcat的详细介绍
MAC 命令行启动tomcat MAC 命令行启动tomcat的详细介绍 一、修改授权 进入tomcat的bin目录,修改授权 1 2 3 ➜ bin pwd /Users/yp/Documents/workspace/apache-tomcat-7.0.68/bin ➜ bin sudo chmod 755 *.sh sudo为系统超级管理员权限.chmod 改变一个或多个文件的存取模…...
idea2023 springboot2.7.5+mybatisplus3.5.2+jsp 初学单表增删改查
创建项目 修改pom.xml 为2.7.5 引入mybatisplus 2.1 修改pom.xml <dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.2</version></dependency><!--mysq…...
轻松搭建书店小程序
在现今数字化时代,拥有一个自己的小程序成为了许多企业和个人的追求。而对于书店经营者来说,拥有一个能够提供在线购书服务的小程序将有助于吸引更多的读者,并提升销售额。本文将为您介绍如何轻松搭建书店小程序,并将其成功上线。…...
图解ConvTranspose1d:从计算图到代码实现的逆向思维
1. 从Conv1d到ConvTranspose1d的思维转换 第一次接触ConvTranspose1d时,我和大多数人一样困惑:为什么要把好好的卷积操作反过来计算?直到在语音合成项目中被迫深入使用后,才明白这种"逆向思维"的价值。想象你正在玩拼图…...

透明背景图片制作方法全解析:2026年最实用的免费抠图工具推荐
最近有个朋友问我,怎样快速把商品照片的背景去掉,做电商上传用。我才意识到,很多人其实都被"透明背景图片制作方法"这个问题困扰着——无论是证件照换底色、商品图去背景,还是做设计素材,都需要一个趁手的抠…...

车载网络测试演进:从CAN总线到TSN与SOA的实战解析
1. 项目概述:一场关于“神经”与“体检”的进化史几年前,我和几个同行在路边摊就着麻小和扎啤,聊起车载以太网测试,那时它还是个新鲜玩意儿,大家讨论的焦点更多是“要不要做”和“怎么做”。几年过去,再回头…...

虚拟机开发环境中如何通过Taotoken管理多个项目的API Key与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 虚拟机开发环境中如何通过Taotoken管理多个项目的API Key与用量 应用场景类,开发者在同一虚拟机中维护多个不同项目&am…...

LEANN:基于选择性重计算的本地向量检索,实现97%存储压缩
1. 项目概述:LEANN,一个重新定义本地向量检索的开源项目如果你和我一样,对当前AI应用生态里动辄需要将个人数据上传到云端、依赖昂贵且臃肿的向量数据库感到厌倦,那么LEANN的出现,绝对会让你眼前一亮。这不仅仅是一个工…...
)
用Python+OpenCV搞定热红外与可见光图像自动对齐(附完整代码与避坑指南)
PythonOpenCV实战:热红外与可见光图像自动配准全流程解析 引言 在工业检测、安防监控、医疗诊断等领域,热红外与可见光图像的融合分析正成为关键技术。两种成像模式各具优势:可见光图像色彩丰富、细节清晰,而热红外图像则能揭示物…...

Taotoken助力初创团队以可控成本集成大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken助力初创团队以可控成本集成大模型能力 为产品添加智能对话功能是许多初创团队提升用户体验的关键一步。然而,…...

基于Circuit Playground与柔性3D打印的可穿戴设备制作全攻略
1. 项目概述:当创客遇上柔性穿戴如果你玩过Arduino,或者对智能硬件有点兴趣,那你大概率听说过Adafruit的Circuit Playground。这块板子挺有意思,它把一堆传感器、LED灯、小喇叭和按钮都塞进了一个硬币大小的板子上,号称…...
如何快速设置Translumo:面向初学者的完整实时屏幕翻译指南
如何快速设置Translumo:面向初学者的完整实时屏幕翻译指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是…...

实测Taotoken在低功耗arm7设备上的API调用延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken在低功耗arm7设备上的API调用延迟与稳定性表现 1. 测试背景与目的 在边缘计算或资源受限的嵌入式场景中,…...