Kubernetes的演变:从etcd到分布式SQL的过渡
DevRel领域专家Denis Magda表示,他偶然发现了一篇解释如何用PostgreSQL无缝替换etcd的文章。该文章指出,Kine项目作为外部etcd端点,可以将Kubernetes etcd请求转换为底层关系数据库的SQL查询。

受到这种方法的启发,Magda决定进一步探索Kine的潜力,从etcd切换到YugabyteDB。YugabyteDB是一个基于PostgreSQL构建的分布式SQL数据库。
etcd有什么问题?
etcd是Kubernetes用来存放所有集群数据的键值库。
在Kubernetes集群遇到可扩展性或高可用性(HA)问题之前,它通常不会引起人们的注意。以可扩展和高可用性(HA)的方式管理etcd对于大型Kubernetes部署来说尤其具有挑战性。
此外,Kubernetes社区对etcd项目的未来开发也有越来越多的担忧。它的社区规模正在缩小,只有少数维护人员有兴趣和能力支持和推进这个项目。
这些问题催生了Kine,这是一个etcd API到SQL的转换层。Kine正式支持SQLite、PostgreSQL和MySQL,这些系统的使用量正在不断增长,并且拥有强大的社区。
为什么选择分布式SQL数据库?
虽然PostgreSQL、SQLite和MySQL是Kubernetes的理想选择,但它们是为单一服务器部署而设计和优化的。这意味着它们可能会带来一些挑战,特别是对于具有更严格的可扩展性和可用性要求的大型Kubernetes部署。
如果开发人员的Kubernetes集群要求RPO(恢复点目标)为零,RTO(恢复时间目标)以秒为单位测量,那么MySQL或PostgreSQL部署的架构和维护将是一个挑战。如果人们有兴趣深入研究这个话题,可以探索PostgreSQL的高可用性选项。
分布式SQL数据库作为一个相互连接的节点集群,可以跨多个机架、可用区或区域部署。通过设计,它们具有高可用性和可扩展性,因此可以为Kubernetes改进相同的特性。
在YugabyteDB上启动Kine
而决定使用YugabyteDB作为Kubernetes的分布式SQL数据库是受到PostgreSQL的影响。YugabyteDB建立在PostgreSQL源代码的基础上,在提供自己的分布式存储实现的同时,重用了PostgreSQL的上半部分(查询引擎)。
YugabyteDB和PostgreSQL之间的紧密联系允许开发人员为YugabyteDB重新设计PostgreSQL的Kine实现。然而需要继续关注,这不会是一个简单的提升和转移的故事。
现在,将这些想法转化为行动,并在YugabyteDB上启动Kine。为此,使用了一个配备了8个CPU和32GB内存的Ubuntu22.04虚拟机。
首先,在虚拟机上启动一个三个节点的YugabyteDB集群。在进行分布式之前,可以在单个服务器上对分布式SQL数据库进行试验。有多种方法可以在本地启动YugabyteDB,但作者更喜欢的方法是通过Docker:
Shell mkdir ~/yb_docker_datadocker network create custom-networkdocker run -d --name yugabytedb_node1 --net custom-network \-p 15433:15433 -p 7001:7000 -p 9000:9000 -p 5433:5433 \-v ~/yb_docker_data/node1:/home/yugabyte/yb_data --restart unless-stopped \yugabytedb/yugabyte:latest \bin/yugabyted start --tserver_flags="ysql_sequence_cache_minval=1" \--base_dir=/home/yugabyte/yb_data --daemon=falsedocker run -d --name yugabytedb_node2 --net custom-network \-p 15434:15433 -p 7002:7000 -p 9002:9000 -p 5434:5433 \-v ~/yb_docker_data/node2:/home/yugabyte/yb_data --restart unless-stopped \yugabytedb/yugabyte:latest \bin/yugabyted start --join=yugabytedb_node1 --tserver_flags="ysql_sequence_cache_minval=1" \--base_dir=/home/yugabyte/yb_data --daemon=falsedocker run -d --name yugabytedb_node3 --net custom-network \-p 15435:15433 -p 7003:7000 -p 9003:9000 -p 5435:5433 \-v ~/yb_docker_data/node3:/home/yugabyte/yb_data --restart unless-stopped \yugabytedb/yugabyte:latest \bin/yugabyted start --join=yugabytedb_node1 --tserver_flags="ysql_sequence_cache_minval=1" \--base_dir=/home/yugabyte/yb_data --daemon=false注:在启动YugabyteDB节点时设置ysql_sequence_cache_minval=1,以确保数据库序列可以按顺序递增1。如果没有这个选项,一个Kine连接到YugabyteDB将缓存序列的下一个100个ID。这可能导致在Kubernetes集群引导期间出现“版本不匹配”错误,因为一个Kine连接可能插入ID范围从1到100的记录,而另一个Kine连接可能插入ID范围从101到200的记录。
接下来,使用PostgreSQL实现启动一个连接到YugabyteDB的Kine实例:
(1)克隆Kine库:
Shell
1 git clone https://github.com/k3s-io/kine.git && cd kine(2)启动一个连接到本地YugabyteDB集群的Kine实例:
Shell
1 go run . --endpoint postgres://yugabyte:yugabyte@127.0.0.1:5433/yugabyte(3)连接YugabyteDB,确认Kine架构已准备就绪:
SQL psql -h 127.0.0.1 -p 5433 -U yugabyteyugabyte=# \dList of relationsSchema | Name | Type | Owner--------+-------------+----------+----------public | kine | table | yugabytepublic | kine_id_seq | sequence | yugabyte
(2 rows)很好,第一次测试成功了。Kine将YugabyteDB视为PostgreSQL,并且启动时没有任何问题。现在进入下一个阶段:使用YugabyteDB在Kine之上启动Kubernetes。
使用YugabyteDB在Kine上启动Kubernetes
Kine可以被各种Kubernetes引擎使用,包括标准的Kubernetes部署、Rancher Kubernetes引擎(RKE)或K3 (一种轻量级的Kubernetes引擎)。为简单起见,将使用后者。
K3s集群可以通过一个简单的命令启动:
(1)停止上一节中启动的Kine实例。
(2)启动连接到相同本地YugabyteDB集群的K3s(K3s可执行文件随Kine提供):
Shell
curl -sfL https://get.k3s.io | sh -s - server --write-kubeconfig-mode=644 \--token=sample_secret_token \
--datastore-endpoint="postgres://yugabyte:yugabyte@127.0.0.1:5433/yugabyte"(3)Kubernetes启动时应该没有问题,可以通过运行以下命令来确认:
Shell k3s kubectl get nodesNAME STATUS ROLES AGE VERSIONubuntu-vm Ready control-plane,master 7m13s v1.27.3+k3s1Kubernetes在YugabyteDB上无缝运行。这要归功于YugabyteDB很好的特性和与PostgreSQL的运行时兼容性。这意味着可以重用为PostgreSQL创建的大多数库、驱动程序和框架。
这可能标志着这一旅程的结束,可以回顾一下K3s日志。在Kubernetes引导期间,日志可能会报告缓慢的查询,如下所示:
SQL INFO[0015] Slow SQL(total time: 3s) :SELECT*FROM (SELECT(SELECTMAX(rkv.id) AS idFROMkine AS rkv),(SELECTMAX(crkv.prev_revision) AS prev_revisionFROMkine AS crkvWHEREcrkv.name = 'compact_rev_key'), kv.id AS theid, kv.name, kv.created, kv.deleted, kv.create_revision, kv.prev_revision, kv.lease, kv.value, kv.old_valueFROMkine AS kvJOIN (SELECTMAX(mkv.id) AS idFROMkine AS mkvWHEREmkv.name LIKE $1GROUP BYmkv.name) AS maxkv ON maxkv.id = kv.idWHEREkv.deleted = 0OR $2) AS lkvORDER BYlkv.theid ASCLIMIT 10001
在一台机器上运行YugabyteDB时,这可能不是一个重要的问题,但是一旦切换到分布式设置,这样的查询就会成为热点并产生瓶颈。
因此克隆了Kine源代码,并开始探索PostgreSQL实现,寻找潜在的优化机会。
YugabyteDB的Kine优化
在这里,Magda与Franck Pachot合作,Pachot是一位精通SQL层优化的数据库专家,对应用程序逻辑没有或只有很少的更改。
在检查了Kine生成的数据库模式并将EXPLAIN ANALYZE用于某些查询之后,Franck提出了对任何分布式SQL数据库都有利的基本优化。
幸运的是,优化不需要对Kine应用程序逻辑进行任何更改。所要做的就是引入一些SQL级别的增强。因此,创建了一个直接支持YugabyteDB的Kine fork。
与此同时,与PostgreSQL相比,YugabyteDB的实现有三个优化:
(1)kine表的主索引已从primary index(id)更改为primary INCEX(id asc)。在默认情况下,YugabyteDB使用哈希分片在集群中均匀分布记录。然而,Kubernetes在id列上运行了许多范围查询,这使得切换到范围分片是合理的。
(2)通过在索引定义中包括id列,kine_name_prev_revision_uindex索引已被更新为覆盖索引:
CREATE UNIQUE INDEX IF NOT EXISTS kine_name_prev_revision_uindex ON kine (name asc, prev_revision asc) INCLUDE(id);YugabyteDB的索引分布类似于表记录。因此,索引条目可能引用存储在不同YugabyteDB节点上的id。为了避免节点之间额外的网络往返,可以将id包含在二级索引中。
(3)Kine在完成Kubernetes请求的同时执行许多连接。如果查询规划器/优化器决定使用嵌套循环连接,那么在默认情况下,YugabyteDB查询层将每次读取和连接一条记录。为了加快这个过程,可以启用批处理嵌套循环连接。YugabyteDB的Kine实现通过在启动时执行以下语句来实现:
ALTER DATABASE " + dbName + " set yb_bnl_batch_size=1024;尝试一下这个优化的YugabyteDB实现。
首先,停止之前的K3s服务,并从YugabyteDB集群中删除Kine模式:
(1)停止并删除K3s服务:
Shell sudo /usr/local/bin/k3s-uninstall.shsudo rm -r /etc/rancher(2)删除模式:
SQL psql -h 127.0.0.1 -p 5433 -U yugabytedrop table kine cascade;接下来,启动一个为YugabyteDB提供优化版本的Kine实例:
(1)克隆fork:
Shell git clone https://github.com/dmagda/kine-yugabytedb.git && cd kine-yugabytedb(2)启动Kine:
Shell go run . --endpoint "yugabytedb://yugabyte:yugabyte@127.0.0.1:5433/yugabyte"Kine的启动没有任何问题。现在唯一的区别是,不是在连接字符串中指定“postgres”,而是指示“yugabytedb”以启用优化的YugabyteDB实现。关于Kine和YugabyteDB之间的实际通信,Kine继续使用Go的标准PostgreSQL驱动程序。
在Kine的优化版本上构建Kubernetes
最后,在这个优化版本的Kine上启动k3。
要做到这一点,首先需要从资源中构建k3:
(1)停止上一节中启动的Kine实例。
(2)克隆K3s存储库:
Shell git clone --depth 1 https://github.com/k3s-io/k3s.git && cd k3s(3)打开go.mod文件,并在replace(..)部分的末尾添加以下行:
Go github.com/k3s-io/kine => github.com/dmagda/kine-yugabytedb v0.2.0这条指令告诉Go使用带有YugabyteDB实现的最新版本的Kinefork。
(4)启用对私有仓库和模块的支持:
Shell go env -w GOPRIVATE=github.com/dmagda/kine-yugabytedb(5)确保更改生效:
Shell go mod tidy(6)准备构建K3s的完整版本:
Shell mkdir -p build/data && make download && make generate(7)构建完整版本:
Shell SKIP_VALIDATE=true make完成构建大约需要五分钟。
注意:一旦停止使用这个自定义K3s构建,可以按照说明卸载它。
在优化的Kubernetes版本上运行示例工作负载
在构建完成后,可以使用Kine的优化版本启动K3s。
(1)导航到包含构建构件的目录:
Shell cd dist/artifacts/(2)通过连接到本地YugabyteDB集群启动K3s:
Shell sudo ./k3s server \--token=sample_secret_token \--datastore-endpoint="yugabytedb://yugabyte:yugabyte@127.0.0.1:5433/yugabyte"(3)确认Kubernetes启动成功:
Shell sudo ./k3s kubectl get nodesNAME STATUS ROLES AGE VERSIONubuntu-vm Ready control-plane,master 4m33s v1.27.4+k3s-36645e73现在,部署一个示例应用程序,以确保Kubernetes集群不仅仅能够自我引导:
(1)采用Kubernetes克隆一个库的例子:
Shell git clone https://github.com/digitalocean/kubernetes-sample-apps.git(2)部署Emojivoto应用:
Shell sudo ./k3s kubectl apply -k ./kubernetes-sample-apps/emojivoto-example/kustomize(3)确保所有部署和服务成功启动:
Shell sudo ./k3s kubectl get all -n emojivotoNAME READY STATUS RESTARTS AGEpod/vote-bot-565bd6bcd8-rnb6x 1/1 Running 0 25spod/web-75b9df87d6-wrznp 1/1 Running 0 24spod/voting-f5ddc8ff6-69z6v 1/1 Running 0 25spod/emoji-66658f4b4c-wl4pt 1/1 Running 0 25sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/emoji-svc ClusterIP 10.43.106.87 <none> 8080/TCP,8801/TCP 27sservice/voting-svc ClusterIP 10.43.14.118 <none> 8080/TCP,8801/TCP 27sservice/web-svc ClusterIP 10.43.110.237 <none> 80/TCP 27sNAME READY UP-TO-DATE AVAILABLE AGEdeployment.apps/vote-bot 1/1 1 1 26sdeployment.apps/web 1/1 1 1 25sdeployment.apps/voting 1/1 1 1 26sdeployment.apps/emoji 1/1 1 1 26sNAME DESIRED CURRENT READY AGEreplicaset.apps/vote-bot-565bd6bcd8 1 1 1 26sreplicaset.apps/web-75b9df87d6 1 1 1 25sreplicaset.apps/voting-f5ddc8ff6 1 1 1 26sreplicaset.apps/emoji-66658f4b4c 1 1 1 26s(4)使用CLUSTER_IP:80调用服务/web svc以触发应用程序逻辑:
Shell curl 10.43.110.237:80应用程序将使用以下HTML进行响应:
HTML <!DOCTYPE html><html><head><meta charset="UTF-8"><title>Emoji Vote</title><link rel="icon" href="/img/favicon.ico"><script async src="https://www.googletagmanager.com/gtag/js?id=UA-60040560-4"></script><script>window.dataLayer = window.dataLayer || [];function gtag(){dataLayer.push(arguments);}gtag('js', new Date());gtag('config', 'UA-60040560-4');</script></head><body><div id="main" class="main"></div></body><script type="text/javascript" src="/js" async></script></html>结语
完成工作!Kubernetes现在可以使用YugabyteDB作为其所有数据的分布式和高可用性SQL数据库。
现在可以进入下一阶段:在跨多个可用性区域和区域的真正云计算环境中部署Kubernetes和YugabyteDB,并测试解决方案如何处理各种中断。
软件开发构建工具
JNPF快速开发平台是一款基于SpringBoot+Vue3的全栈开发平台,采用微服务、前后端分离架构,基于可视化流程建模、表单建模、报表建模工具,快速构建业务应用,平台即可本地化部署,也支持K8S部署。
应用体验地址:https://www.jnpfsoft.com/?csdn,操作一下试试吧!
引擎式软件快速开发模式,除了上述功能,还配置了图表引擎、接口引擎、门户引擎、组织用户引擎等可视化功能引擎,基本实现页面UI的可视化搭建。内置有百种功能控件及使用模板,使得在拖拉拽的简单操作下,也能大限度满足用户个性化需求。由于JNPF平台的功能比较完善,本文选择这项工具进行展开,使你更加直观看到低代码的优势。
相关文章:
Kubernetes的演变:从etcd到分布式SQL的过渡
DevRel领域专家Denis Magda表示,他偶然发现了一篇解释如何用PostgreSQL无缝替换etcd的文章。该文章指出,Kine项目作为外部etcd端点,可以将Kubernetes etcd请求转换为底层关系数据库的SQL查询。 受到这种方法的启发,Magda决定进一步…...
29、简单通过git把项目远程提交到gitee
简单通过git把项目远程提交到gitee 1、在gitee上创建一个仓库 2、在要提交的项目文件夹打开git 输入 git init 初始化git 然后设置下用户名和邮箱 git config --global user.name “username” git config --global user.email “yourEmail” 因为我是要把文件简单提交到…...
沉浸式游戏)
元宇宙之应用(04)沉浸式游戏
在数字科技迅猛发展的今天,元宇宙的概念正逐渐从科幻走向现实,重新定义了人们与虚拟世界的交互方式。在这一概念的引领下,"沉浸式游戏" 蓬勃发展,为游戏体验带来了前所未有的深度和广度。那么,为什么沉浸式游…...
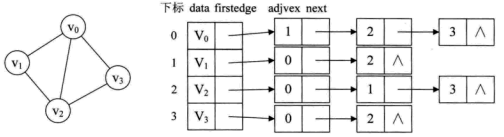
浙大数据结构第八周之08-图7 公路村村通
题目详情: 现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低成本。 输入格式: 输入数据包括城镇数目正整数N(≤1000)和候选道路数目M(…...

SpringBoot 解决跨域问题
同源策略(CORS):浏览器在解析发送的请求时,要求浏览器的路径与发送的请求的路径必须满足三个要求,即请求的协议、域名、端口号都相同,满足同源策略,才可以访问服务器,否则࿰…...

2023 年牛客多校第十场题解
C Multiplication 题意:定义 k k k-shift 数是满足 k x y ‾ y x ‾ k\overline{xy}\overline{yx} kxyyx 的数字。给定 k k k,求最大不超过 n n n 的 k k k-shift 数。 1 ≤ n ≤ 1 0 100 1 \le n \le 10^{100} 1≤n≤10100, 2 ≤…...

韦东山老师 RTOS 入门课程(一)RTOS 介绍,熟悉裸机的汇编逻辑
韦东山老师 RTOS 入门课程 课程链接:韦东山直播公开课:RTOS实战项目之实现多任务系统 第1节:裸机程序框架和缺陷_哔哩哔哩_bilibili RTOS 介绍 裸机:固定顺序执行。 中断:可以一直专心做循环里的事情,直…...
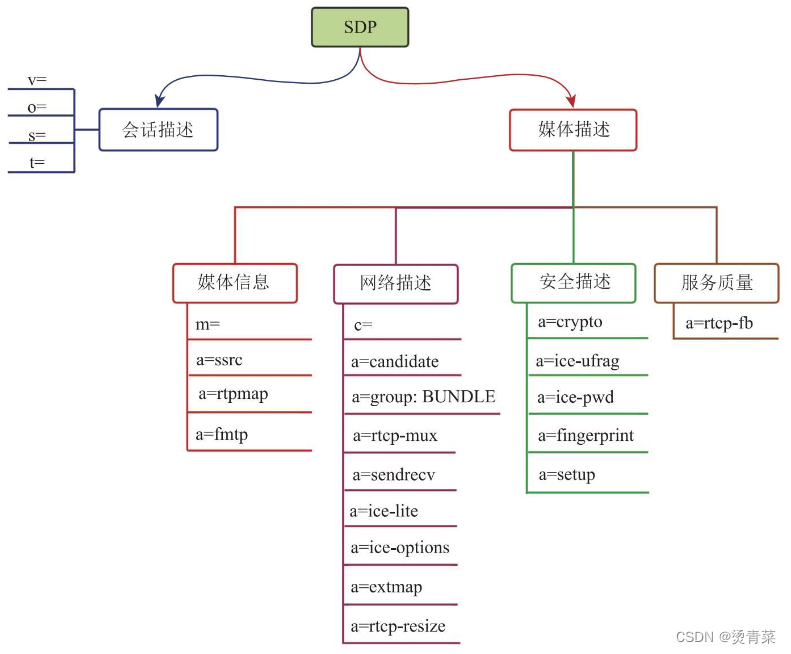
WebRTC | SDP详解
目录 一、SDP标准规范 1. SDP结构 2. SDP内容及type类型 二、WebRTC中的SDP结构 1. 媒体信息描述 (1)SDP中媒体信息格式 i. “artpmap”属性 ii. “afmtp”属性 (2)SSRC与CNAME (3)举个例子 &…...
springboot集成Oauth2.0授权包,5个接口文件配置详解)
Springboot 实践(9)springboot集成Oauth2.0授权包,5个接口文件配置详解
前文讲解实现了spring boot集成Oauth2.0,实现了授权服务器和资源服务器的搭建,并通过浏览器和postman测试,获取到了授权码,用携带授权码的URL能够争取范文到资源。 本文详细讲解spring boot集成Oauth2.0的几个重要文件接口&#…...
最新AI系统ChatGPT程序源码/支持GPT4/自定义训练知识库/GPT联网/支持ai绘画(Midjourney)+Dall-E2绘画/支持MJ以图生图
一、前言 SparkAi系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。 那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!…...
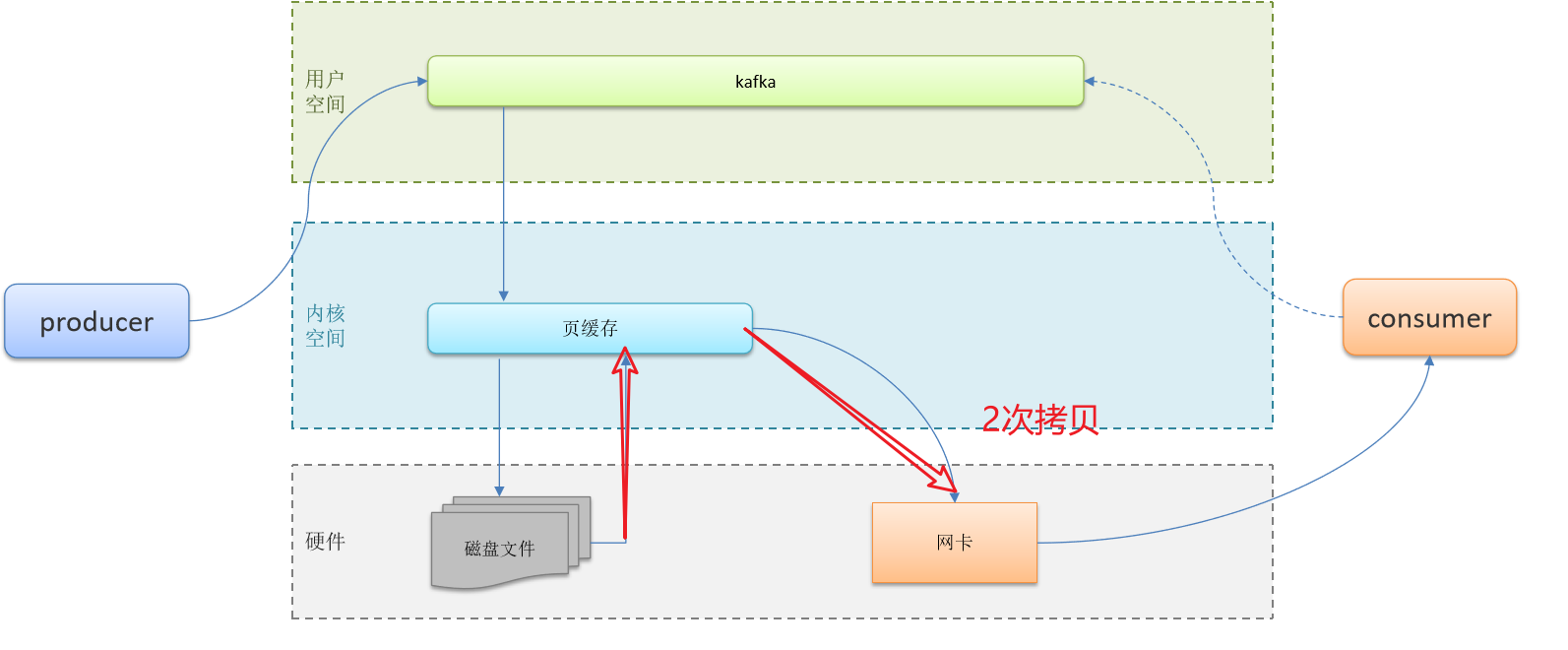
【高频面试题】 消息中间件
文章目录 1、RabbitMQ1.1 RabbitMQ-如何保证消息不丢失1.2 RabbitMQ消息的重复消费问题如何解决的1.3 RabbitMQ中死信交换机 ? (RabbitMQ延迟队列有了解过嘛)1.4 RabbitMQ如果有100万消息堆积在MQ , 如何解决(消息堆积怎么解决)1.5 RabbitMQ的高可用机制有了解过嘛 2、Kafka2.…...
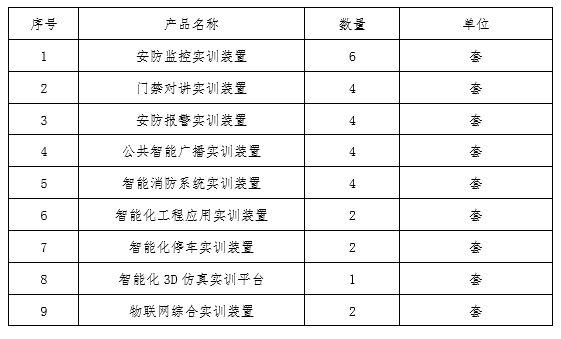
物联网智慧安防实训综合实训基地建设方案
一、系统概述 物联网智慧安防实训综合实训基地是一个为学生提供综合实践、培养技能的场所,专注于物联网技术与智慧安防应用的培训和实训。通过物联网智慧安防实训综合实训基地的建设和运营,学生可以在真实的环境中进行实践训练,提高其物联网技…...

openGauss学习笔记-44 openGauss 高级数据管理-存储过程
文章目录 openGauss学习笔记-44 openGauss 高级数据管理-存储过程44.1 语法格式44.2 参数说明44.3 示例 openGauss学习笔记-44 openGauss 高级数据管理-存储过程 存储过程是能够完成特定功能的SQL语句集。用户可以进行反复调用,从而减少SQL语句的重复编写数量&…...

【Linux】进程信号篇Ⅲ:可重入函数、volatile关键字、SIGCHLD信号
信号Ⅲ 🔗 接上篇七、可重入函数八、volatile 关键字九、SIGCHLD 信号 🔗 接上篇 👉🔗进程信号篇Ⅰ:信号的产生(signal、kill、raise、abort、alarm)、信号的保存(core dump&#x…...

排序算法:冒泡排序
冒泡排序是入门级的算法,但也有一些有趣的玩法。通常来说,冒泡排序有三种写法: 一边比较一边向后两两交换,将最大值 / 最小值冒泡到最后一位;经过优化的写法:使用一个变量记录当前轮次的比较是否发生过交换…...
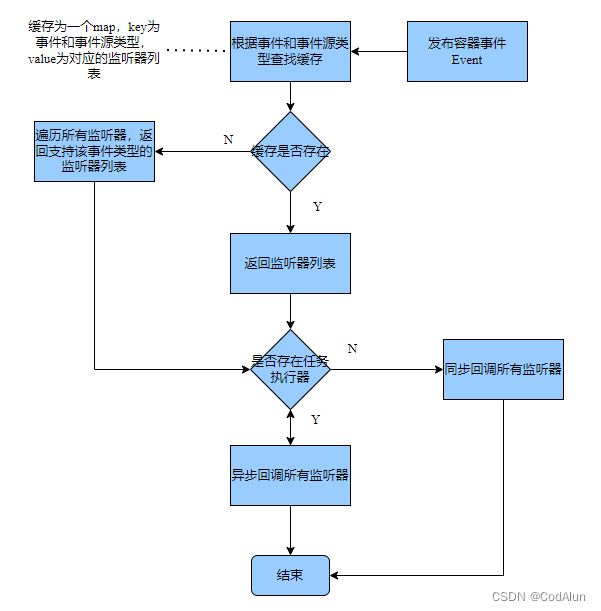
Spring事件监听源码解析
spring事件监听机制离不开容器IOC特性提供的支持,比如容器会自动创建事件发布器,自动识别用户注册的监听器并进行管理,在特定的事件发布后会找到对应的事件监听器并对其监听方法进行回调。Spring帮助用户屏蔽了关于事件监听机制背后的很多细节…...
Cpp学习——list的模拟实现
目录 一,实现list所需要包含的三个类 二,三个类的实现 1.list_node 2.list类 3.iterator_list类 三,功能实现 1.list类里的push_back() 2.iterator类里的运算符重载 3,list类里面的功能函数 1.insert(ÿ…...
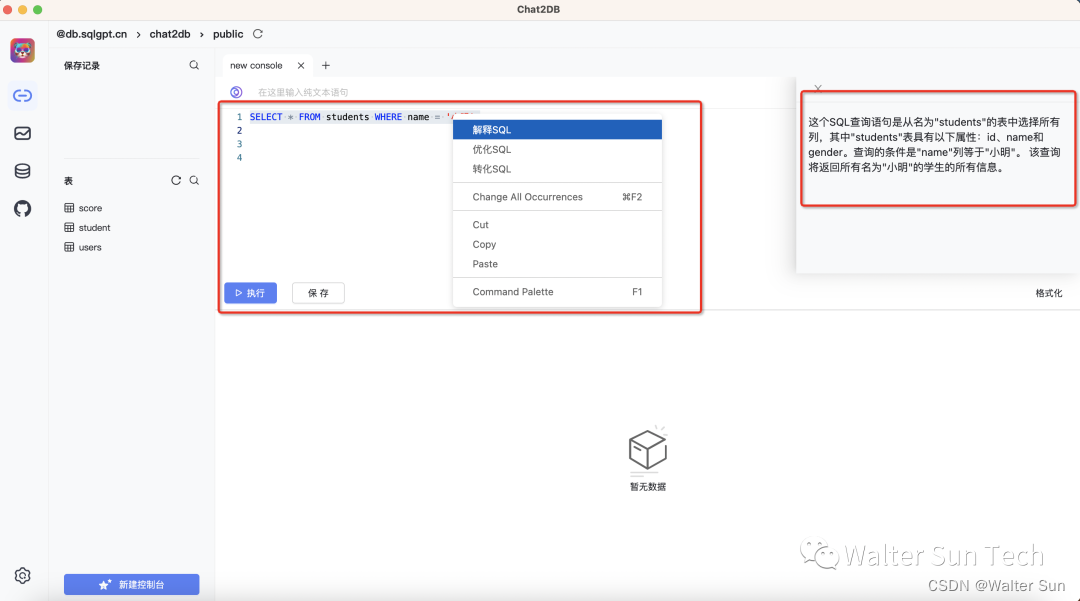
工具推荐:Chat2DB一款开源免费的多数据库客户端工具
文章首发地址 Chat2DB是一款开源免费的多数据库客户端工具,适用于Windows和Mac操作系统,可在本地安装使用,也可以部署到服务器端并通过Web页面进行访问。 相较于传统的数据库客户端软件如Navicat、DBeaver,Chat2DB具备了与AIGC…...
C语言刷题指南(二)
📙作者简介: 清水加冰,目前大二在读,正在学习C/C、Python、操作系统、数据库等。 📘相关专栏:C语言初阶、C语言进阶、C语言刷题训练营、数据结构刷题训练营、有感兴趣的可以看一看。 欢迎点赞 👍…...
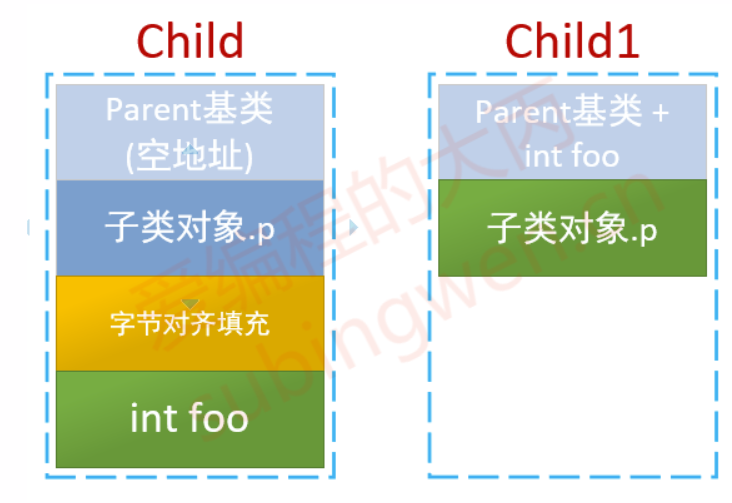
[C++11]
文章目录 1. 自动类型推导1.1 auto1.1.1 推导规则1.1.2 auto的限制1.1.3 auto的应用1.1.4 范围for 1.2 decltype1.2.1 推导规则1.2.2 decltype的应用 1.3 返回类型后置 2.可调用对象包装器、绑定器2.1 可调用对象包装器2.1.1 基本用法2.1.2 作为回调函数使用 2.2 绑定器 3. usi…...

PPTAgent终极指南:如何5分钟完成专业演示文稿的AI智能生成
PPTAgent终极指南:如何5分钟完成专业演示文稿的AI智能生成 【免费下载链接】PPTAgent An Agentic Framework for Reflective PowerPoint Generation 项目地址: https://gitcode.com/gh_mirrors/pp/PPTAgent 你是否曾为制作演示文稿而熬夜加班?是否…...

跨平台实战:Windows QGC与Linux JMAVSim模拟器的局域网联调
1. 环境准备与基础概念 在开始跨平台联调之前,我们需要先理解几个关键组件的作用。QGroundControl(QGC)是无人机领域最流行的开源地面站软件,相当于无人车的"方向盘";而PX4 JMAVSim则是基于Java开发的轻量级…...

Installing the classic Jupyter Notebook interface
简单来说,Jupyter Notebook 是一个基于网页的编程环境,让你可以: 边写代码边运行:可以一次只运行一小段代码,而不是整个程序 混合显示:代码、运行结果(包括图表、图片)、文字说明可…...

攻克:C8051Fxxx uVision驱动在Keil Debug中“隐身”的安装与配置实战
1. 问题背景与现象分析 第一次接触C8051Fxxx系列芯片的开发者,大概率会在Keil uVision环境中遇到一个让人抓狂的问题:明明按照官方文档安装了驱动,但在Debug选项列表中死活找不到"C8051Fxxx uVision"这个关键驱动。我当年接手公司一…...

用74LS181和6116芯片手把手复现CPU累加器:计算机组成原理实验避坑指南
74LS181与6116芯片实战:从零构建CPU累加器的硬件艺术 实验室的灯光下,几块看似普通的集成电路板正等待着被赋予生命。对于计算机专业的学生和硬件爱好者而言,用74LS181算术逻辑单元(ALU)和6116静态RAM芯片亲手搭建一个CPU累加器,…...

open62541批量读写踩坑实录:从‘UA_ReadRequest’配置到结果解析的完整避坑指南
open62541批量读写深度实战:从核心配置到异常处理的完整解决方案 在工业自动化与物联网系统开发中,OPC UA协议已成为设备互联的事实标准。作为开源实现的佼佼者,open62541为开发者提供了强大而灵活的工具集。但当面对需要高效处理大量节点数据…...

RK3568金融自助终端方案:AI边缘计算与高可靠设计实践
1. 项目概述:当金融自助终端遇上RK3568最近几年,如果你留意过银行网点或者一些商业中心,会发现自助终端的形态正在发生一些微妙的变化。从传统的ATM机,到如今功能繁多的VTM(远程视频柜员机)、智能柜台、自助…...

普冉PY32F0系列开发:如何用VSCode+Cortex-Debug插件实现媲美Keil的图形化调试体验?
普冉PY32F0开发实战:VSCodeCortex-Debug打造专业级嵌入式调试环境 在嵌入式开发领域,高效的调试工具往往能决定项目的成败。对于使用普冉PY32F0系列Cortex-M0 MCU的开发者而言,传统商业IDE虽然功能完善,但存在许可成本高、跨平台支…...

手机拍照鬼影是算法背锅?聊聊Sensor DOL-HDR技术如何从源头减少融合断层
手机HDR成像鬼影溯源:从DOL-HDR硬件机制到ISP融合调优实战 在手机摄影技术快速迭代的今天,高动态范围(HDR)成像已成为旗舰机型的标配功能。然而,当算法工程师面对合成图像中的鬼影伪影和亮度断层时,往往陷入…...

基于大语言模型的塔罗牌AI解读系统:技术架构与实现详解
1. 项目概述:当塔罗占卜遇见AI最近在GitHub上看到一个挺有意思的项目,叫“chatgpt-tarot-divination”。光看名字,你大概就能猜到它的核心玩法:用AI来解读塔罗牌。这可不是简单的“随机抽牌固定释义”,而是结合了像Cha…...