[PyTorch][chapter 52][迁移学习]
前言:
迁移学习(Transfer Learning)是一种机器学习方法,它通过将一个领域中的知识和经验迁移到另一个相关领域中,来加速和改进新领域的学习和解决问题的能力。
这里面主要结合前面ResNet18 例子,详细讲解一下迁移学习的流程
一 简介
迁移学习可以通过以下几种方式实现:
1.1 基于预训练模型的迁移:
将已经在大规模数据集上预训练好的模型(如BERT、GPT等)作为一个通用的特征提取器,然后在新领域的任务上进行微调。
1.2 网络结构迁移:
将在一个领域中训练好的模型的网络结构应用到另一个领域中,并在此基础上进行微调。
1.3 特征迁移:
将在一个领域中训练好的某些特征应用到另一个领域中,并在此基础上进行微调。
word2vec
1.4 参数迁移:
将在一个领域中训练好的模型的参数应用到另一个领域中,并在此基础上进行微调。
本文主要例子用的是 参数迁移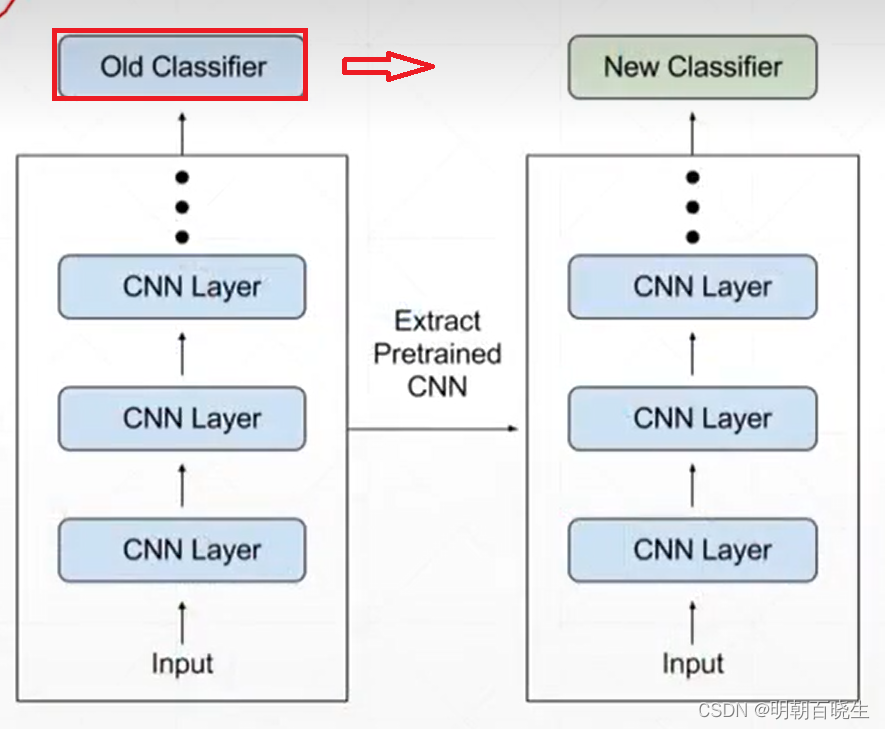
二 Flatten
作用:
输入的向量x [batch, c, w, h]=>[batch, c*w*h]
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 16 15:11:35 2023@author: chengxf2
"""import torch
from torch import optim,nnclass Flatten(nn.Module):def __init__(self):super(Flatten,self).__init__()def forward(self, x):a = torch.tensor(x.shape[1:])#dim 中 input 张量的每一行的乘积。shape = torch.prod(a).item()#print("\n ---new shape--- ",shape)return x.view(-1,shape)
三 迁移学习
torchvision 已经提供好了一些分类器 resnet18,resnet152, 利用其训练好的参数,把最后的分类类型更改掉。
from torchvision.models import resnet152
from torchvision.models import resnet18
注意:
现有分类器分类的类型 > = 新分类器类型,再做transfer.
才能取得好的效果.
| 分类器 | 分类类型 |
| 已有分类器 | [猫,狗,鸡,鸭】 |
| 新分类器 | [猫,狗] |
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 16 14:56:35 2023@author: chengxf2
"""# -*- coding: utf-8 -*-
"""
Created on Tue Aug 15 15:38:18 2023@author: chengxf2
"""import torch
from torch import optim,nn
import visdom
from torch.utils.data import DataLoader
from PokeDataset import Pokemon
from torchvision.models import resnet152
from torchvision.models import resnet18from util import FlattenbatchNum = 32
lr = 1e-3
epochs = 20
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(1234)root ='pokemon'
resize =224csvfile ='data.csv'
train_db = Pokemon(root, resize, 'train',csvfile)
val_db = Pokemon(root, resize, 'val',csvfile)
test_db = Pokemon(root, resize, 'test',csvfile)train_loader = DataLoader(train_db, batch_size =batchNum,shuffle= True,num_workers=4)
val_loader = DataLoader(val_db, batch_size =batchNum,shuffle= True,num_workers=2)
test_loader = DataLoader(test_db, batch_size =batchNum,shuffle= True,num_workers=2)
viz = visdom.Visdom()def evalute(model, loader):total =len(loader.dataset)correct =0for x,y in loader:x = x.to(device)y = y.to(device)with torch.no_grad():logits = model(x)pred = logits.argmax(dim=1)correct += torch.eq(pred, y).sum().float().item()acc = correct/totalreturn acc def main():trained_model = resnet152(pretrained=True)model = nn.Sequential(*list(trained_model.children())[:-1],Flatten(),nn.Linear(in_features=2048, out_features=5))optimizer = optim.Adam(model.parameters(),lr =lr) criteon = nn.CrossEntropyLoss()best_epoch=0,best_acc=0viz.line([0],[-1],win='train_loss',opts =dict(title='train loss'))viz.line([0],[-1],win='val_loss', opts =dict(title='val_acc'))global_step =0for epoch in range(epochs):print("\n --main---: ",epoch)for step, (x,y) in enumerate(train_loader):#x:[b,3,224,224] y:[b]x = x.to(device)y = y.to(device)#print("\n --x---: ",x.shape)logits =model(x)loss = criteon(logits, y)#print("\n --loss---: ",loss.shape)optimizer.zero_grad()loss.backward()optimizer.step()viz.line(Y=[loss.item()],X=[global_step],win='train_loss',update='append')global_step +=1if epoch %2 ==0:val_acc = evalute(model, val_loader)if val_acc>best_acc:best_acc = val_accbest_epoch =epochtorch.save(model.state_dict(),'best.mdl')print("\n val_acc ",val_acc)viz.line([val_acc],[global_step],win='val_loss',update='append')print('\n best acc',best_acc, "best_epoch: ",best_epoch)model.load_state_dict(torch.load('best.mdl'))print('loaded from ckpt')test_acc = evalute(model, test_loader)print('\n test acc',test_acc)if __name__ == "__main__":main()
参考:
https://blog.csdn.net/qq_44089890/article/details/130460700
课时107 迁移学习实战_哔哩哔哩_bilibili
相关文章:
[PyTorch][chapter 52][迁移学习]
前言: 迁移学习(Transfer Learning)是一种机器学习方法,它通过将一个领域中的知识和经验迁移到另一个相关领域中,来加速和改进新领域的学习和解决问题的能力。 这里面主要结合前面ResNet18 例子,详细讲解一…...
Ceph如何操作底层对象数据
1.基本原理介绍 1.1 ceph中的对象(object) 在Ceph存储中,一切数据最终都会以对象(Object)的形式存储在硬盘(OSD)上,每个的Object默认大小为4M。 通过rados命令,可以查看一个存储池中的所有object信息,例如…...

sklearn机器学习库(二)sklearn中的随机森林
sklearn机器学习库(二)sklearn中的随机森林 集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。 多个模型集成成为的模型叫做集成评估器(ensemble estimator)…...

FlutterBoost 实现Flutter页面内嵌iOS view
在使用Flutter混合开发中会遇到一些原生比Flutter优秀的控件,不想使用Flutter的控件,想在Flutter中使用原生控件。这时就会用到 Flutter页面中内嵌 原生view,这里简单介绍一个 内嵌 iOS 的view。 注:这里使用了 FlutterBoost。网…...

走嵌入式还是纯软件?学长告诉你怎么选
最近有不少理工科的本科生问我,未来是走嵌入式还是纯软件好,究竟什么样的同学适合学习嵌入式呢?在这里我整合一下给他们的回答,根据自己的经验提供一些建议。 嵌入式领域也可以分为单片机方向、Linux方向和安卓方向。如果你的专业…...
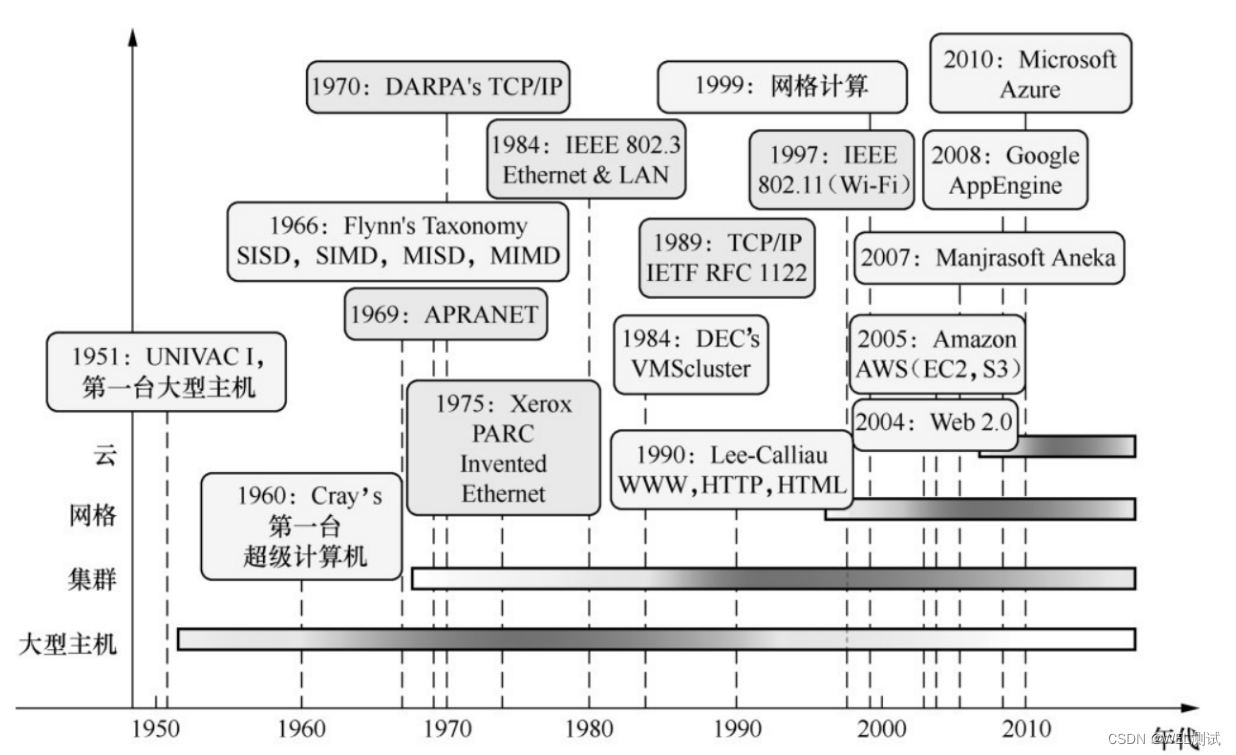
【云计算原理及实战】初识云计算
该学习笔记取自《云计算原理及实战》一书,关于具体描述可以查阅原本书籍。 云计算被视为“革命性的计算模型”,因为它通过互联网自由流通使超级计算能力成为可能。 2006年8月,在圣何塞举办的SES(捜索引擎战略)大会上&a…...
 基于拟合高差的点云地面点提取)
Open3D (C++) 基于拟合高差的点云地面点提取
目录 一、算法原理1、原理概述2、参考文献二、代码实现三、结果展示1、原始点云2、提取结果四、相关链接系列文章(连载中。。。): Open3D (C++) 基于高程的点云地面点提取Open3D (C++) 基于拟合平面的点云地面点提取Open3D (C++) 基于拟合高差的点云地面点提取</...
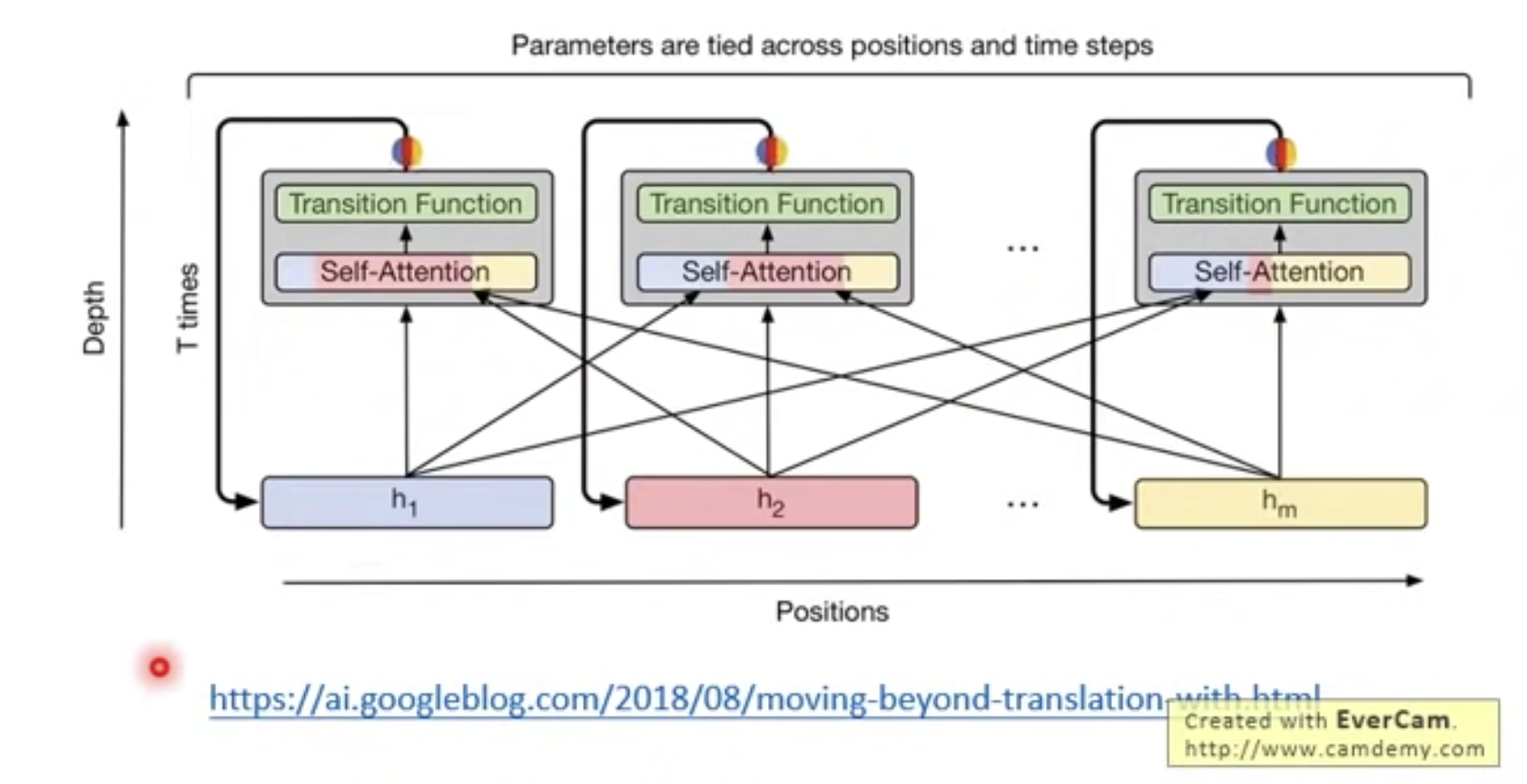
认识Transformer:入门知识
视频链接: https://www.youtube.com/watch?vugWDIIOHtPA&listPLJV_el3uVTsOK_ZK5L0Iv_EQoL1JefRL4&index60 文章目录 Self-Attention layerMulti-head self-attentionPositional encodingSeq2Seq with AttentionTransformerUniversal Transformer Seq2Seq …...
《TCP IP网络编程》第二十四章
第 24 章 制作 HTTP 服务器端 24.1 HTTP 概要 本章将编写 HTTP(HyperText Transfer Protocol,超文本传输协议)服务器端,即 Web 服务器端。 理解 Web 服务器端: web服务器端就是要基于 HTTP 协议,将网页对…...
【AI】文心一言的使用
一、获得内测资格: 1、点击网页链接申请:https://yiyan.baidu.com/ 2、点击加入体验,等待通过 二、获得AI伙伴内测名额 1、收到短信通知,点击链接 网页Link:https://chat.baidu.com/page/launch.html?fa&sourc…...

CSAPP Lab2:Bomb Lab
说明 6关卡,每个关卡需要输入相应的内容,通过逆向工程来获取对应关卡的通过条件 准备工作 环境 需要用到gdb调试器 apt-get install gdb系统: Ubuntu 22.04 本实验会用到的gdb调试器的指令如下 r或者 run或者run filename 运行程序,run filename就…...

Java中使用流将两个集合根据某个字段进行过滤去重?
Java中使用流将两个集合根据某个字段进行过滤去重? 在Java中,您可以使用流(Stream)来过滤和去重两个集合。下面是一个示例代码,展示如何根据对象的某个字段进行过滤和去重操作: import java.util.ArrayList; import java.util.List; impor…...

自动驾驶HMI产品技术方案
版本变更 序号 日期 变更内容 编制人 审核人 文档版本 1 2 1....

Git判断本地是否最新
场景需求 需要判断是否有新内容更新,确定有更新之后执行pull操作,然后pull成功之后再将新内容进行复制到其他地方 pgit log -1 --prettyformat:"%H" HEAD -- . "origin/HEAD" rgit rev-parse origin/HEAD if [[ $p $r ]];thenecho "Is La…...

Spring 整合RabbitMQ,笔记整理
1.创建生产者工程 spring-rabbitmq-producer 2.pom.xml添加依赖 <dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.1.7.RELEASE</version></dep…...

Lua 语言笔记(一)
1. 变量命名规范 弱类型语言(动态类型语言),定义变量的时候,不需要类型修饰 而且,变量类型可以随时改变每行代码结束的时候,要不要分号都可以变量名 由数字,字母下划线组成,不能以数字开头,也不…...
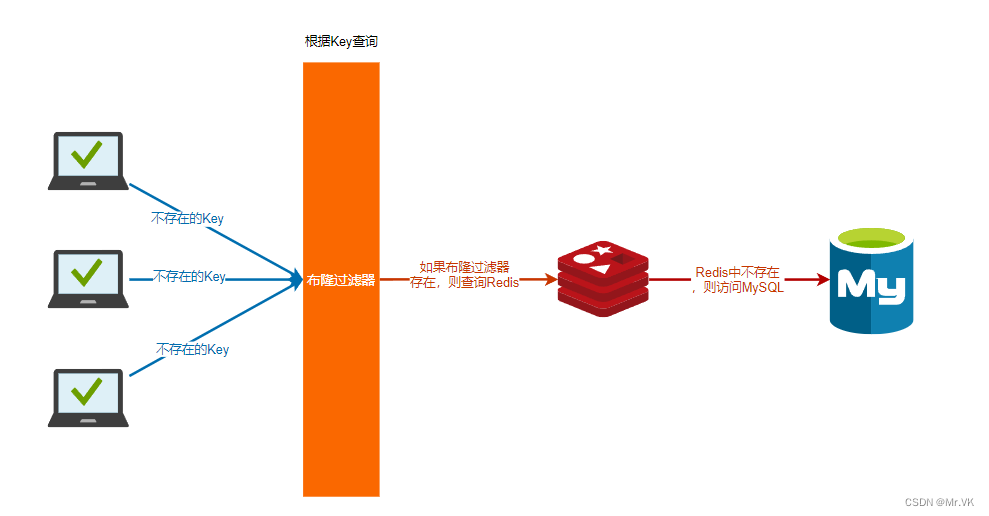
【Redis】什么是缓存穿透,如何预防缓存穿透?
【Redis】什么是缓存穿透,如何预防缓存穿透? 缓存穿透是指查询一个一定不存在的数据,由于缓存中不存在,这时会去数据库查询查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,这…...

LeetCode128.最长连续序列
我这个方法有点投机取巧了,题目说时间复杂度最多O(n),而我调用了Arrays.sort()方法,他的时间复杂度是n*log(n),但是AC了,这样的话这道题还是非常简单的,创建一个Hashmap,以nums数组的元素作为ke…...

Datawhale Django入门组队学习Task02
Task02 首先启动虚拟环境(复习一下之前的) 先退出conda的, conda deactivate然后cd到我的venv下面 ,然后cd 到 scripts,再 activate (powershell里面) 创建admin管理员 首先cd到项目路径下&a…...

PCTA 认证考试高分通过经验分享
作者: msx-yzu 原文来源: https://tidb.net/blog/0b343c9f 序言 我在2023年8月10日,参加了 PingCAP 认证 TiDB 数据库专员 V6 考试 ,并以 90分 的成绩通过考试。 考试总分是100分,超过60分就算通过考试。试卷…...

Halbot框架解析:从零构建可扩展聊天机器人的实践指南
1. 项目概述:一个轻量级、可扩展的聊天机器人框架最近在折腾一个需要集成多个聊天平台(比如微信、钉钉、Telegram)的自动化项目,发现市面上现成的机器人框架要么太重,要么扩展性不够,要么就是文档写得云里雾…...

激光雷达距离传感器:智能感知时代的“千里眼“
在万物互联的智能时代,激光雷达距离传感器正以厘米级的精准测距能力,重塑自动驾驶、机器人导航与智慧城市的感知边界。它不仅是一款传感器,更是智能系统的"第三只眼"——看得远、看得清、看得准。一、硬核原理:光速丈量…...

Horos:免费开源医学影像软件,3D医疗图像处理的终极指南
Horos:免费开源医学影像软件,3D医疗图像处理的终极指南 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos…...

深度测评2026广州个体户核定流程精选榜单,革新个体工商户税务办理新变革
在数字经济浪潮席卷之下,个体工商户税务办理正面临前所未有的变革压力与机遇窗口。2026年的广州,作为电商与直播产业的高地,其个体户核定流程的效率与合规性,已成为衡量区域营商环境的试金石。然而,一个深层的价值悖论…...

STM32CubeMX生成代码后,Keil编译烧写的那些“隐藏”步骤与调试器避坑
STM32CubeMX生成代码后,Keil编译烧写的那些“隐藏”步骤与调试器避坑 当你用STM32CubeMX生成代码后,以为万事大吉,结果在Keil里编译烧写时却频频碰壁——这几乎是每个STM32开发者都会经历的“成人礼”。那些教程里一笔带过的“编译”、“烧写…...

为 Claude Code 配置 Taotoken 以解决访问不稳定与 Token 不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Claude Code 配置 Taotoken 以解决访问不稳定与 Token 不足问题 Claude Code 作为一款强大的编程助手,其原生服务有…...

每日大赛间歇期通过Taotoken模型广场探索新模型特性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 每日大赛间歇期通过Taotoken模型广场探索新模型特性 对于每日参与各类AI应用开发或创意大赛的选手而言,比赛间歇期并非…...

ModusToolbox实战:如何系统化降低物联网开发复杂性
1. 项目概述:为什么我们需要关注“复杂性”?在物联网(IoT)领域摸爬滚打十几年,我见过太多项目从雄心勃勃到最终搁浅,其核心症结往往不在于某个高深的技术难题,而在于“复杂性失控”。一个典型的…...

RK3576开发板AIoT实战:从模型转换到边缘部署全流程解析
1. 项目概述:从一块开发板到AI应用落地的完整旅程 最近几年,AIoT(人工智能物联网)的概念越来越火,但很多开发者朋友拿到一块功能强大的开发板后,往往卡在“如何把AI模型真正跑起来”这一步。我手头这块RK35…...

终极指南:如何用MAA Assistant Arknights实现明日方舟全自动化
终极指南:如何用MAA Assistant Arknights实现明日方舟全自动化 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: htt…...