clickhouse集群部署
一、集群部署简介
部署的详情可以看官网
先部署两个server,三个keeper[zookeeper]
clickhouse之前依赖的存储是zookeeper,后来改为了keeper,官网给出了原因
所以这就决定了clickhouse有两种安装方式,依赖于keeper做存储或者依赖于zookeeper做存储
二、zookeeper作为存储
1.zookeeper安装
zookeeper安装可以看之前的文章
2.clickhouse部署
修改配置文件
2.1 修改listen_host
<!-- Same for hosts without support for IPv6: -->
<listen_host>0.0.0.0</listen_host> <!-- 把这里注释去掉,允许所有地址可以访问 -->
2.2 修改存储路径
<!-- Path to data directory, with trailing slash. --><path>/var/lib/clickhouse/</path>
2.3 添加集群配置
<!--这属于两个分片,每个分片语一个副本的架构-->
<remote_servers><cluster_2S_1R> <!--定义的集群名字--><shard><internal_replication>true</internal_replication><replica><host>chnode1</host><port>9000</port></replica></shard><shard><internal_replication>true</internal_replication><replica><host>chnode2</host><port>9000</port></replica></shard></cluster_2S_1R></remote_servers><!--
注意,上面的写法是放到两个shard里,也可放到一个shard,下面是单一分片两副本的写法,如果放到不同的shard里macros的配置就得不同了
<remote_servers><cluster_2S_1R> <!--定义的集群名字--><shard><internal_replication>true</internal_replication><replica><host>chnode1</host><port>9000</port></replica><replica><host>chnode2</host><port>9000</port></replica></shard></cluster_2S_1R></remote_servers>-->
2.4配置zookeeper
<zookeeper><node><host>example1</host><port>2181</port></node><node><host>example2</host><port>2181</port></node><node><host>example3</host><port>2181</port></node>
</zookeeper>
2.5配置macros
<!--如果是单分片量副本的配置-->
<!-- 配置分片macros变量,在用client创建表的时候会自动带入,第一台ck的配置 --><macros><shard>01</shard><replica>chnode1</replica> <!-- 这里指定当前集群节点的名字或者IP --></macros>
<!-- 配置分片macros变量,在用client创建表的时候会自动带入,第二台ck的配置 --><macros><shard>01</shard><replica>chnode2</replica> <!-- 这里指定当前集群节点的名字或者IP --></macros>
3.启动clickhouse
systemctl start clickhouse-server.service
systemctl enable clickhouse-server.service
4.登录机器并检查集群
4.1登录
# 登录
clickhouse-client
# 查看集群信息
select * from system.clusters
4.2建表
CREATE TABLE t1 ON CLUSTER cluster_2S_1R
(`ts` DateTime,`uid` String,`biz` String
)
ENGINE = ReplicatedMergeTree('/clickhouse/test1/tables/{shard}/t1', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY ts
SETTINGS index_granularity = 8192# 出现如下报错
Received exception from server (version 23.6.2):
Code: 159. DB::Exception: Received from localhost:9000. DB::Exception: Watching task /clickhouse/task_queue/ddl/query-0000000004 is executing longer than distributed_ddl_task_timeout (=180) seconds. There are 2 unfinished hosts (0 of them are currently active), they are going to execute the query in background. (TIMEOUT_EXCEEDED)
# 这个报错是某些ck服务异常才出现的报错,我这是因为我配置文件里的remote_server里的host ip写错了,相当于找不到服务了,修改后重启就好了
4.3 测试dml
目前DDL生效,但是插入数据在其他节点不生效
查看节点2的clickhouse日志,其中会有如下报错
2023.08.10 15:49:54.836507 [ 8514 ] {} <Error> test1.t1 (*****-48d4-44ed-9bad-2a03410321a9): auto DB::StorageReplicatedMergeTree::processQueueEntry(ReplicatedMergeTreeQueue::SelectedEntryPtr)::(anonymous class)::operator()(LogEntryPtr &) const: Code: 198. DB::Exception: Not found address of host: bj-ck3. (DNS_ERROR), Stack trace (when copying this message, always include the lines below):
可以看到这里是因为域名无法解析,因为ZooKeeper 里面存储的是hosts域名,不是IP,所以需要配置/etc/hosts
192.168.1.1 bj-ck1
192.168.1.2 bj-ck2
192.168.1.3 bj-ck3
ps: /etc/hosts的配置里,如果配置多个的话,是以第一个为准,其他都类似别名么
比如192.168.1.1配置如下:192.168.1.1 bj-1 bj-2
如果别的机器是以域名访问192.168.1.1,如果别的机器只配置了192.168.1.1 bj-2,其实是解析不到192.168.1.1的
三、keeper作为存储
ClickHouse Keeper 提供数据复制和分布式 DDL 查询执行的协调系统。 ClickHouse Keeper 与 Apache ZooKeeper 兼容。 此配置在端口 9181 上启用 ClickHouse Keeper。
注意:
如果出于任何原因更换或重建 Keeper 节点,请勿重复使用现有的 server_id。 例如,如果重建了server_id为2的Keeper节点,则将其server_id设置为4或更高。
分片和副本降低了分布式 DDL 的复杂性。 配置的值会自动替换到您的 DDL 查询中,从而简化您的 DDL。
1.安装并启动keeper
# 安装clickhouse-keeper
sudo apt-get install -y clickhouse-keeper
# 启用并启动clickhouse-keeper
sudo systemctl enable clickhouse-keeper
sudo systemctl start clickhouse-keeper
sudo systemctl status clickhouse-keeper
2.修改keeper配置文件keeper_config.xml
<keeper_server><tcp_port>9181</tcp_port><!-- 这里是主要的修改位置,保证集群中每个几点的id是唯一的 --><server_id>1</server_id><log_storage_path>/var/lib/clickhouse/coordination/logs</log_storage_path><snapshot_storage_path>/var/lib/clickhouse/coordination/snapshots</snapshot_storage_path><coordination_settings><operation_timeout_ms>10000</operation_timeout_ms><min_session_timeout_ms>10000</min_session_timeout_ms><session_timeout_ms>100000</session_timeout_ms><raft_logs_level>information</raft_logs_level><!-- All settings listed in https://github.com/ClickHouse/ClickHouse/blob/master/src/Coordination/CoordinationSettings.h --></coordination_settings><!-- enable sanity hostname checks for cluster configuration (e.g. if localhost is used with remote endpoints) --><hostname_checks_enabled>true</hostname_checks_enabled><!-- 这里是第二处需要变更的位置,需要把集群中的keeper配置上 --><raft_configuration><server><id>1</id><!-- Internal port and hostname --><hostname>192.168.1.1</hostname><port>9234</port></server><server><id>2</id><!-- Internal port and hostname --><hostname>192.168.1.2</hostname><port>9234</port></server><server><id>3</id><!-- Internal port and hostname --><hostname>192.168.1.3</hostname><port>9234</port></server><!-- Add more servers here --></raft_configuration></keeper_server><zookeeper><node index="1"><host>chnode1</host><port>9181</port></node><node index="2"><host>chnode2</host><port>9181</port></node><node index="3"><host>chnode3</host><port>9181</port></node></zookeeper>
3.clickhouse的配置
clickhouse的配置与zookeeper作为存储时的配置几乎一致,只需要把zookeeper的配置注释掉即可
ps: 这里还有个小插曲,使用keeper的时候发现dml的数据又一次不同步了,查看clickhouse-server.err.log,发现有如下报错
2023.08.16 11:19:00.782071 [ 8566 ] {} <Error> ConfigReloader: Error updating configuration from '/etc/clickhouse-server/config.xml' config.: Code: 999. Coordination::Exception: Connection loss, path: All connection tries failed while connecting to ZooKeeper
使用telnet后发现确实telnet不通,于是修改keeper的配置文件keeper_config.xml,添加如下内容
<listen_host>0.0.0.0</listen_host>
重启keeper
systemctl restart clickhouse-keeper
相关文章:

clickhouse集群部署
一、集群部署简介 部署的详情可以看官网 先部署两个server,三个keeper[zookeeper] clickhouse之前依赖的存储是zookeeper,后来改为了keeper,官网给出了原因 所以这就决定了clickhouse有两种安装方式,依赖于keeper做存储或者依赖于zookeeper做存储 二、zookeeper作…...

centos8 使用phpstudy安装tomcat部署web项目
系统配置 1、安装Tomcat 2、问题 正常安装完Tomcat应该有个配置选项,用来配置server.xml web.xml 还有映射webapps路径选项,但是我用的这个版本并没有。所以只能曲线救国。 3、解决 既然没有配置项,那就只能按最基本的方法配置,…...

爬虫百度返回“百度安全验证”终极解决方案
这篇文章也可以在我的博客查看 爬不了啊!! 最近一哥们跟我说百度爬虫爬不了 弹出:“百度安全验证”,“网络不给力,请稍后重试” 说到爬虫,这里指的是Python中最常用的requests库 我说怎么爬不了了&#x…...
visual studio 2022配置
前提:我linux c 开发 一直在使用vscode 更新了个版本突然代码中的查找所用引用和变量修改名称不能用了,尝试了重新配置clang vc都不行,估计是插件问题,一怒之下改用visual studio 2022 为了同步2个IDE之间的差别,目前…...
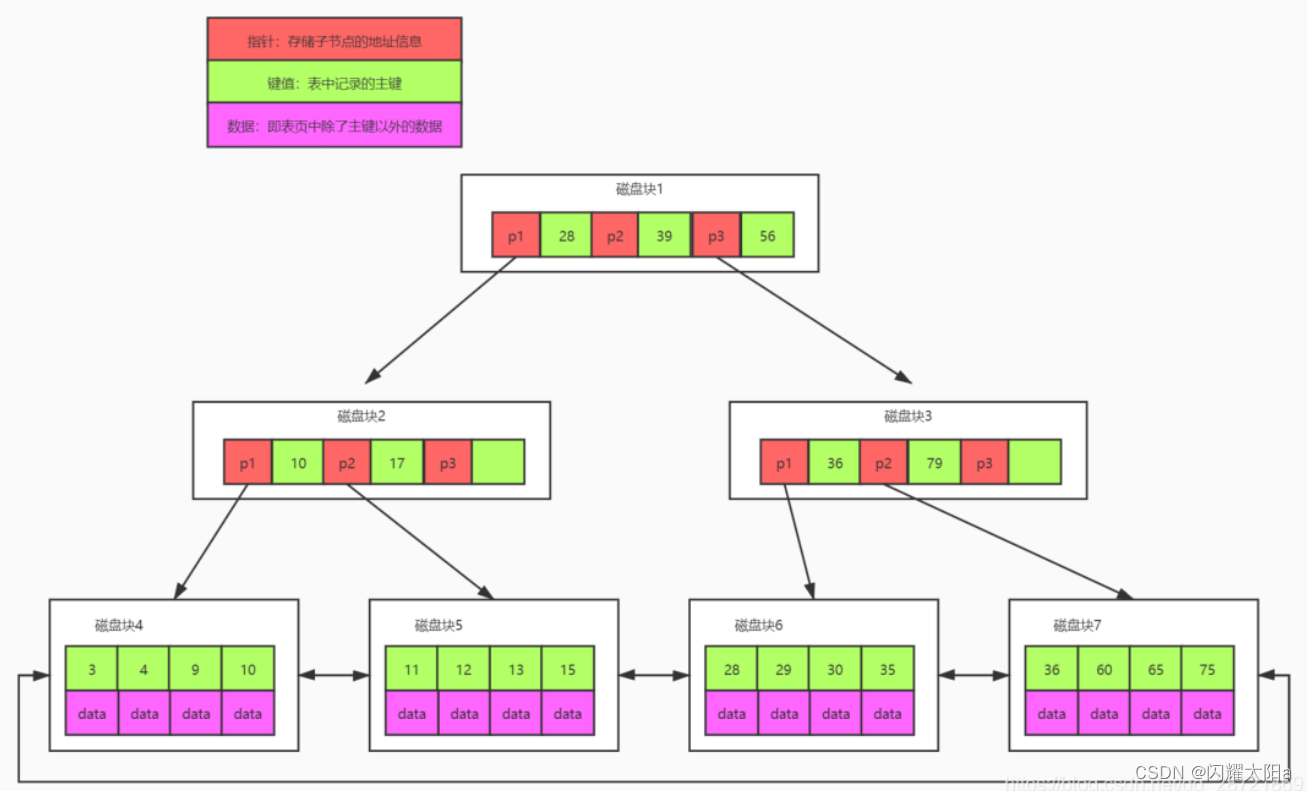
B-树和B+树的区别
B-树和B树的区别 一、B-tree数据存储 在下图中 P 代表的是指针,指向的是下一个磁盘块。在第一个节点中的 16、24 就是代表我们的 key 值是什么。date 就是这个 key 值对应的这一行记录是什么。 假设寻找 key 为 33 的这条记录,33 在 16 和 34 中间&am…...

c注册cpp回调函数
在C语言中注册回调函数,函数需要使用静态函数,可使用bind和function来转换 案例一: #include <iostream> #include <functional> #include <string.h> #include "http_server.h" #include "ret_err_code.…...

批量将excel中字段为“八百”替换成“九百”
要批量将Excel中字段为"八百"的内容替换为"九百",您可以使用Python的openpyxl库来实现。以下是一个示例代码演示如何读取Excel文件并进行替换操作: from openpyxl import load_workbook # 打开Excel文件 wb load_workbook(your_ex…...

关于docker-compose up -d在文件下无法运行的原因以及解决方法
一、确认文件下有docker-compose.yml文件 二、解决方法 检查 Docker 服务是否运行: 使用以下命令检查 Docker 服务是否正在运行: systemctl status docker 如果 Docker 未运行,可以使用以下命令启动它: systemctl start docker …...
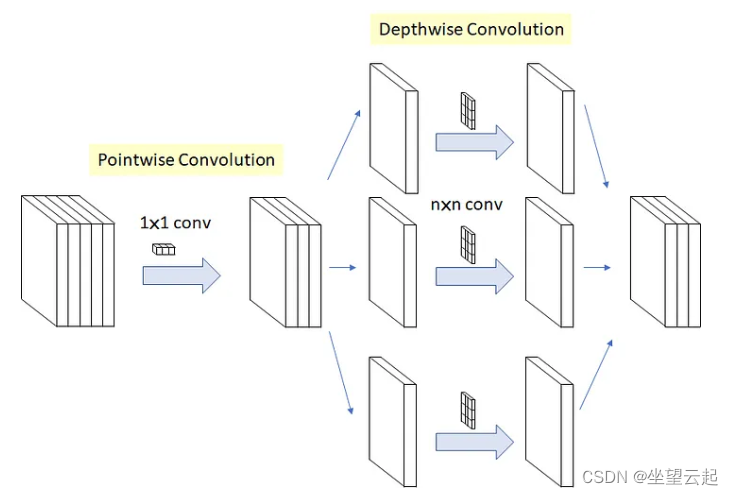
机器学习笔记 - 基于keras + 小型Xception网络进行图像分类
一、简述 Xception 是深度为 71 层的卷积神经网络,仅依赖于深度可分离的卷积层。 论文中将卷积神经网络中的 Inception 模块解释为常规卷积和深度可分离卷积运算(深度卷积后跟点卷积)之间的中间步骤。从这个角度来看,深度可分离卷积可以理解为具有最大数量塔的 Inception 模…...

【Unity每日一记】SceneManager场景资源动态加载
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...

自动驾驶数据回传需求
1、需求分析 用户 用户需求 实时性要求 需回传数据 数据类型 采样周期 数据量 大小 数据回传通道 研发工程师 分析评估系统性能表现,例如智驾里程统计、接管率表现、油耗表现、AEB报警次数等 当天 车身底盘数据、自动驾驶系统状态数据等 结构化数据 10…...
使用Jmeter自带recorder代理服务器录制接口脚本
脚本录制 配置线程组 添加代理服务器 端口 和 录制脚本放置位置可根据需要设置 启动录制 点击启动后 弹出创建证书提示,点击OK 这个证书后续需要使用到 然后可见 一个弹窗。 Recorder . 本质是代理服务录制交易控制 可设置对应数据 方便录制脚本的查看 证书配置…...
我和 TiDB 的故事 | 远近高低各不同
作者: ShawnYan 原文来源: https://tidb.net/blog/b41a02e6 Hi, TiDB, Again! 书接上回, 《我和 TiDB 的故事 | 横看成岭侧成峰》 ,一年时光如白驹过隙,这一年我好似在 TiDB 上投入的时间总量不是很多࿰…...

深入浅出Pytorch函数——torch.nn.init.zeros_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

Jenkins-发送邮件配置
在Jenkins构建执行完毕后,需要及时通知相关人员。因此在jenkins中是可以通过邮件通知的。 一、Jenkins自带的邮件通知功能 找到manage Jenkins->Configure System,进行邮件配置: 2. 配置Jenkins自带的邮箱信息 完成上面的配置后…...
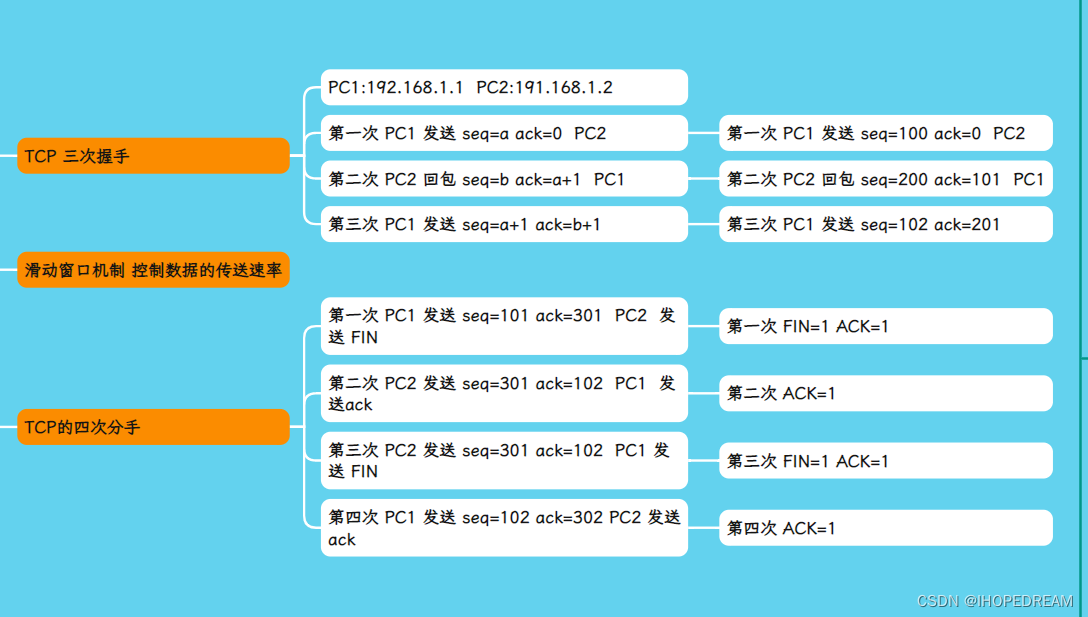
网络通信原理传输层TCP三次建立连接(第四十八课)
ACK :确认号 。 是期望收到对方的下一个报文段的数据的第1个字节的序号,即上次已成功接收到的数据字节序号加1。只有ACK标识为1,此字段有效。确认号X+1SEQ:序号字段。 TCP链接中传输的数据流中每个字节都编上一个序号。序号字段的值指的是本报文段所发送的数据的第一个字节的…...

【Python机器学习】实验14 手写体卷积神经网络(PyTorch实现)
文章目录 LeNet-5网络结构(1)卷积层C1(2)池化层S1(3)卷积层C2(4)池化层S2(5)卷积层C3(6)线性层F1(7)线性层F2 …...
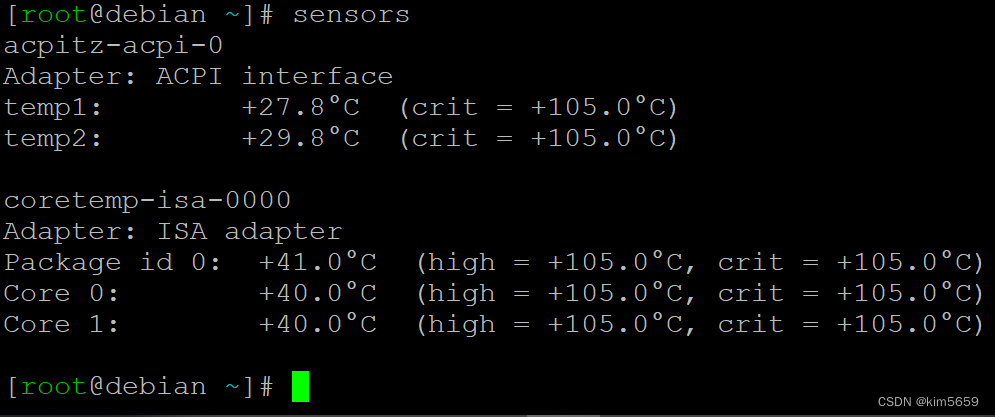
Debian查询硬件状态
很早以前写过一个查询树霉派硬件状态的文章,用是Python写的一个小程序。里面用到了vcgencmd这个测温度的内部命令,但这个命令在debian里面没有,debian里只有lm_sensors的外部命令,需要安装:apt-get install lm_sensors…...
)
除自身以外数组的乘积(c语言详解)
题目:除自身外数组的乘积 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据保证数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请不要使用除…...

ONES × 鲁邦通|打造研发一体化平台,落地组织级流程规范
近日,ONES 签约工业互联网行业领先的解决方案提供商——鲁邦通,助力鲁邦通优化组织级流程规范,落地从需求到交付的全生命周期线上化管理。 依托于 ONES 一站式研发管理平台,鲁邦通在软硬件设计开发、项目管理和精益生产等方面的数…...

AI Native Web 开发实战:从零构建智能应用
AI Native Web 产品实战指南:从概念到落地的完整路线做了大半年 AI 应用开发之后,我发现一个现象:很多人知道 “AI Native” 这个词,但真要动手做一个 AI Native 的 Web 产品,脑子里是一团浆糊的。这篇文章就是想把这块…...

如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南
如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 想在Mac上流畅运行Windows游戏…...

【Java用法】jar包运行后显示 没有主清单属性
jar包运行后显示 没有主清单属性一、问题现象二、问题分析三、解决方案3.1 添加 spring-boot-maven-plugin 插件3.2 修改 spring-boot 父级依赖3.3 配置IDEA开发工具一、问题现象 jar包运行后显示 没有主清单属性!如下图所示: 前些天发现了一个特别好用…...

G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制
G-Helper终极指南:全面掌握华硕笔记本性能优化与硬件控制 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

从零构建MCP服务:AI应用外部工具集成入门指南
1. 项目概述:从零构建你的第一个MCP服务 最近在AI应用开发圈里,MCP(Model Context Protocol)这个词的热度越来越高。如果你正在尝试将大型语言模型(LLM)的能力集成到自己的应用里,或者想为你的A…...

忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码
忘记压缩包密码怎么办?5分钟学会用ArchivePasswordTestTool找回密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经…...

别再手动配置时钟树了!用STM32CubeMX 6.10 + Keil MDK 5分钟搞定LED闪烁工程
5分钟极速开发:STM32CubeMX图形化工具颠覆传统嵌入式开发模式 第一次接触STM32开发时,面对密密麻麻的寄存器手册和复杂的时钟树配置,我花了整整三天才让一个LED灯闪烁起来。直到发现STM32CubeMX这个神器——它彻底改变了嵌入式开发的入门门槛…...

3步开启游戏自动化革命:智能助手解放你的游戏时间
3步开启游戏自动化革命:智能助手解放你的游戏时间 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode…...

2026年5月14隔夜暗盘挂单排行榜
推荐好文:每年节约五六千交易费不香吗如何获取龙虎榜是否有量化参与如何获取股东减持信息大A有5400多只股票, 这里面只有不到10%, 约500只由资金投票, 剩余的都是杂毛, 炒股看龙头找主线. 从隔夜挂单里选择, 再叠加我们之前分享的如何判断是否有大股东减持, 是否有融资融券参与…...

Windows驱动管理专业解决方案:Driver Store Explorer完全指南
Windows驱动管理专业解决方案:Driver Store Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称Rapr)是一款…...