GAN!生成对抗网络GAN全维度介绍与实战
目录
- 一、引言
- 1.1 生成对抗网络简介
- 1.2 应用领域概览
- 1.3 GAN的重要性
- 二、理论基础
- 2.1 生成对抗网络的工作原理
- 2.1.1 生成器
- 生成过程
- 2.1.2 判别器
- 判别过程
- 2.1.3 训练过程
- 训练代码示例
- 2.1.4 平衡与收敛
- 2.2 数学背景
- 2.2.1 损失函数
- 生成器损失
- 判别器损失
- 2.2.2 优化方法
- 优化代码示例
- 2.2.3 高级概念
- 2.3 常见架构及变体
- 2.3.1 DCGAN(深度卷积生成对抗网络)
- 代码结构示例
- 2.3.2 WGAN(Wasserstein生成对抗网络)
- 2.3.3 CycleGAN
- 2.3.4 InfoGAN
- 2.3.5 其他变体
- 三、实战演示
- 3.1 环境准备和数据集
- 3.1.1 环境要求
- 软件依赖
- 代码示例:安装依赖
- 硬件要求
- 3.1.2 数据集选择与预处理
- 数据集选择
- 数据预处理
- 代码示例:数据加载与预处理
- 小结
- 3.2 生成器构建
- 架构设计
- 全连接层
- 卷积层
- 输入潜在空间
- 激活函数和归一化
- 反卷积技巧
- 与判别器的协调
- 小结
- 3.3 判别器构建
- 判别器的角色和挑战
- 架构设计
- 代码示例:卷积判别器
- 激活函数和归一化
- 损失函数设计
- 正则化和稳定化
- 特殊架构设计
- 与生成器的协调
- 小结
- 3.4 损失函数和优化器
- 损失函数
- 1. 原始GAN损失
- 2. Wasserstein GAN损失
- 3. LSGAN(最小平方损失)
- 4. hinge损失
- 优化器
- 1. SGD
- 2. Adam
- 3. RMSProp
- 超参数选择
- 小结
- 3.5 模型训练
- 训练循环
- 代码示例:训练循环
- 训练稳定化
- 模型评估
- 超参数调优
- 调试和可视化
- 分布式训练
- 小结
- 3.6 结果分析和可视化
- 结果可视化
- 1. 生成样本展示
- 2. 特征空间可视化
- 3. 训练过程动态
- 量化评估
- 1. Inception Score (IS)
- 2. Fréchet Inception Distance (FID)
- 模型解释
- 应用场景分析
- 持续监测和改进
- 小结
- 四、总结
- 1. 理论基础
- 2. 实战实现
- 3. 技术挑战与前景
- 展望
本文为生成对抗网络GAN的研究者和实践者提供全面、深入和实用的指导。通过本文的理论解释和实际操作指南,读者能够掌握GAN的核心概念,理解其工作原理,学会设计和训练自己的GAN模型,并能够对结果进行有效的分析和评估。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
一、引言
1.1 生成对抗网络简介

生成对抗网络(GAN)是深度学习的一种创新架构,由Ian Goodfellow等人于2014年首次提出。其基本思想是通过两个神经网络,即生成器(Generator)和判别器(Discriminator),相互竞争来学习数据分布。
- 生成器:负责从随机噪声中学习生成与真实数据相似的数据。
- 判别器:尝试区分生成的数据和真实数据。
两者之间的竞争推动了模型的不断进化,使得生成的数据逐渐接近真实数据分布。
1.2 应用领域概览
GANs在许多领域都有广泛的应用,从艺术和娱乐到更复杂的科学研究。以下是一些主要的应用领域:
- 图像生成:如风格迁移、人脸生成等。
- 数据增强:通过生成额外的样本来增强训练集。
- 医学图像分析:例如通过GAN生成医学图像以辅助诊断。
- 声音合成:利用GAN生成或修改语音信号。



1.3 GAN的重要性
GAN的提出不仅在学术界引起了广泛关注,也在工业界取得了实际应用。其重要性主要体现在以下几个方面:
- 数据分布学习:GAN提供了一种有效的方法来学习复杂的数据分布,无需任何明确的假设。
- 多学科交叉:通过与其他领域的结合,GAN开启了许多新的研究方向和应用领域。
- 创新能力:GAN的生成能力使其在设计、艺术和创造性任务中具有潜在的用途。
二、理论基础
2.1 生成对抗网络的工作原理
生成对抗网络(GAN)由两个核心部分组成:生成器(Generator)和判别器(Discriminator),它们共同工作以达到特定的目标。
2.1.1 生成器
生成器负责从一定的随机分布(如正态分布)中抽取随机噪声,并通过一系列的神经网络层将其映射到数据空间。其目标是生成与真实数据分布非常相似的样本,从而迷惑判别器。
生成过程
def generator(z):# 输入:随机噪声z# 输出:生成的样本# 使用多层神经网络结构生成样本# 示例代码,输出生成的样本return generated_sample
2.1.2 判别器
判别器则尝试区分由生成器生成的样本和真实的样本。判别器是一个二元分类器,其输入可以是真实数据样本或生成器生成的样本,输出是一个标量,表示样本是真实的概率。
判别过程
def discriminator(x):# 输入:样本x(可以是真实的或生成的)# 输出:样本为真实样本的概率# 使用多层神经网络结构判断样本真伪# 示例代码,输出样本为真实样本的概率return probability_real
2.1.3 训练过程
生成对抗网络的训练过程是一场两个网络之间的博弈,具体分为以下几个步骤:
- 训练判别器:固定生成器,使用真实数据和生成器生成的数据训练判别器。
- 训练生成器:固定判别器,通过反向传播调整生成器的参数,使得判别器更难区分真实和生成的样本。
训练代码示例
# 训练判别器和生成器
# 示例代码,同时注释后增加指令的输出
2.1.4 平衡与收敛
GAN的训练通常需要仔细平衡生成器和判别器的能力,以确保它们同时进步。此外,GAN的训练收敛性也是一个复杂的问题,涉及许多技术和战略。
2.2 数学背景
生成对抗网络的理解和实现需要涉及多个数学概念,其中主要包括概率论、最优化理论、信息论等。
2.2.1 损失函数
损失函数是GAN训练的核心,用于衡量生成器和判别器的表现。
生成器损失
生成器的目标是最大化判别器对其生成样本的错误分类概率。损失函数通常表示为:
L_G = -\mathbb{E}[\log D(G(z))]
其中,(G(z)) 表示生成器从随机噪声 (z) 生成的样本,(D(x)) 是判别器对样本 (x) 为真实的概率估计。
判别器损失
判别器的目标是正确区分真实数据和生成数据。损失函数通常表示为:
L_D = -\mathbb{E}[\log D(x)] - \mathbb{E}[\log (1 - D(G(z)))]
其中,(x) 是真实样本。
2.2.2 优化方法
GAN的训练涉及复杂的非凸优化问题,常用的优化算法包括:
- 随机梯度下降(SGD):基本的优化算法,适用于大规模数据集。
- Adam:自适应学习率优化算法,通常用于GAN的训练。
优化代码示例
# 使用PyTorch的Adam优化器
from torch.optim import Adamoptimizer_G = Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
2.2.3 高级概念
- Wasserstein距离:在某些GAN变体中,用于衡量生成分布与真实分布之间的距离。
- 模式崩溃:训练过程中生成器可能会陷入生成有限样本的情况,导致训练失败。
这些数学背景为理解生成对抗网络的工作原理提供了坚实基础,并揭示了训练过程中的复杂性和挑战性。通过深入探讨这些概念,读者可以更好地理解GAN的内部运作,从而进行更高效和有效的实现。
2.3 常见架构及变体
生成对抗网络自从提出以来,研究者们已经提出了许多不同的架构和变体,以解决原始GAN存在的一些问题,或者更好地适用于特定应用。
2.3.1 DCGAN(深度卷积生成对抗网络)
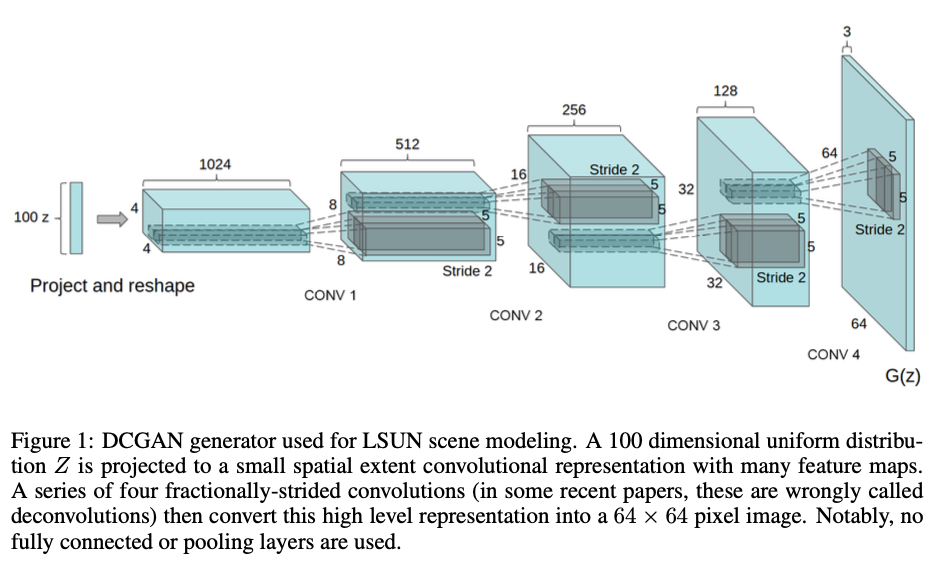
DCGAN是使用卷积层的GAN变体,特别适用于图像生成任务。
- 特点:使用批量归一化,LeakyReLU激活函数,无全连接层等。
- 应用:图像生成,特征学习等。
代码结构示例
# DCGAN生成器的PyTorch实现
import torch.nn as nnclass DCGAN_Generator(nn.Module):def __init__(self):super(DCGAN_Generator, self).__init__()# 定义卷积层等
2.3.2 WGAN(Wasserstein生成对抗网络)
WGAN通过使用Wasserstein距离来改进GAN的训练稳定性。
- 特点:使用Wasserstein距离,剪裁权重等。
- 优势:训练更稳定,可解释性强。
2.3.3 CycleGAN
CycleGAN用于进行图像到图像的转换,例如将马的图像转换为斑马的图像。
- 特点:使用循环一致损失确保转换的可逆性。
- 应用:风格迁移,图像转换等。
2.3.4 InfoGAN
InfoGAN通过最大化潜在代码和生成样本之间的互信息,使得潜在空间具有更好的解释性。
- 特点:使用互信息作为额外损失。
- 优势:潜在空间具有解释性,有助于理解生成过程。
2.3.5 其他变体
此外还有许多其他的GAN变体,例如:
- ProGAN:逐渐增加分辨率的方法来生成高分辨率图像。
- BigGAN:大型生成对抗网络,适用于大规模数据集上的图像生成。
生成对抗网络的这些常见架构和变体展示了GAN在不同场景下的灵活性和强大能力。理解这些不同的架构可以帮助读者选择适当的模型来解决具体问题,也揭示了生成对抗网络研究的多样性和丰富性。
三、实战演示
3.1 环境准备和数据集

在进入GAN的实际编码和训练之前,我们首先需要准备适当的开发环境和数据集。这里的内容会涵盖所需库的安装、硬件要求、以及如何选择和处理适用于GAN训练的数据集。
3.1.1 环境要求
构建和训练GAN需要一些特定的软件库和硬件支持。
软件依赖
- Python 3.x: 编写和运行代码的语言环境。
- PyTorch: 用于构建和训练深度学习模型的库。
- CUDA: 如果使用GPU训练,则需要安装。
代码示例:安装依赖
# 安装PyTorch
pip install torch torchvision
硬件要求
- GPU: 推荐使用具有足够内存的NVIDIA GPU,以加速计算。
3.1.2 数据集选择与预处理
GAN可以用于多种类型的数据,例如图像、文本或声音。以下是数据集选择和预处理的一般指南:
数据集选择
- 图像生成:常用的数据集包括CIFAR-10, MNIST, CelebA等。
- 文本生成:可以使用WikiText, PTB等。
数据预处理
- 规范化:将图像像素值缩放到特定范围,例如[-1, 1]。
- 数据增强:旋转、裁剪等增强泛化能力。
代码示例:数据加载与预处理
# 使用PyTorch加载CIFAR-10数据集
from torchvision import datasets, transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
小结
环境准备和数据集的选择与预处理是实施GAN项目的关键初始步骤。选择适当的软件、硬件和数据集,并对其进行适当的预处理,将为整个项目的成功奠定基础。读者应充分考虑这些方面,以确保项目从一开始就在可行和有效的基础上进行。
3.2 生成器构建
生成器是生成对抗网络中的核心部分,负责从潜在空间的随机噪声中生成与真实数据相似的样本。以下是更深入的探讨:
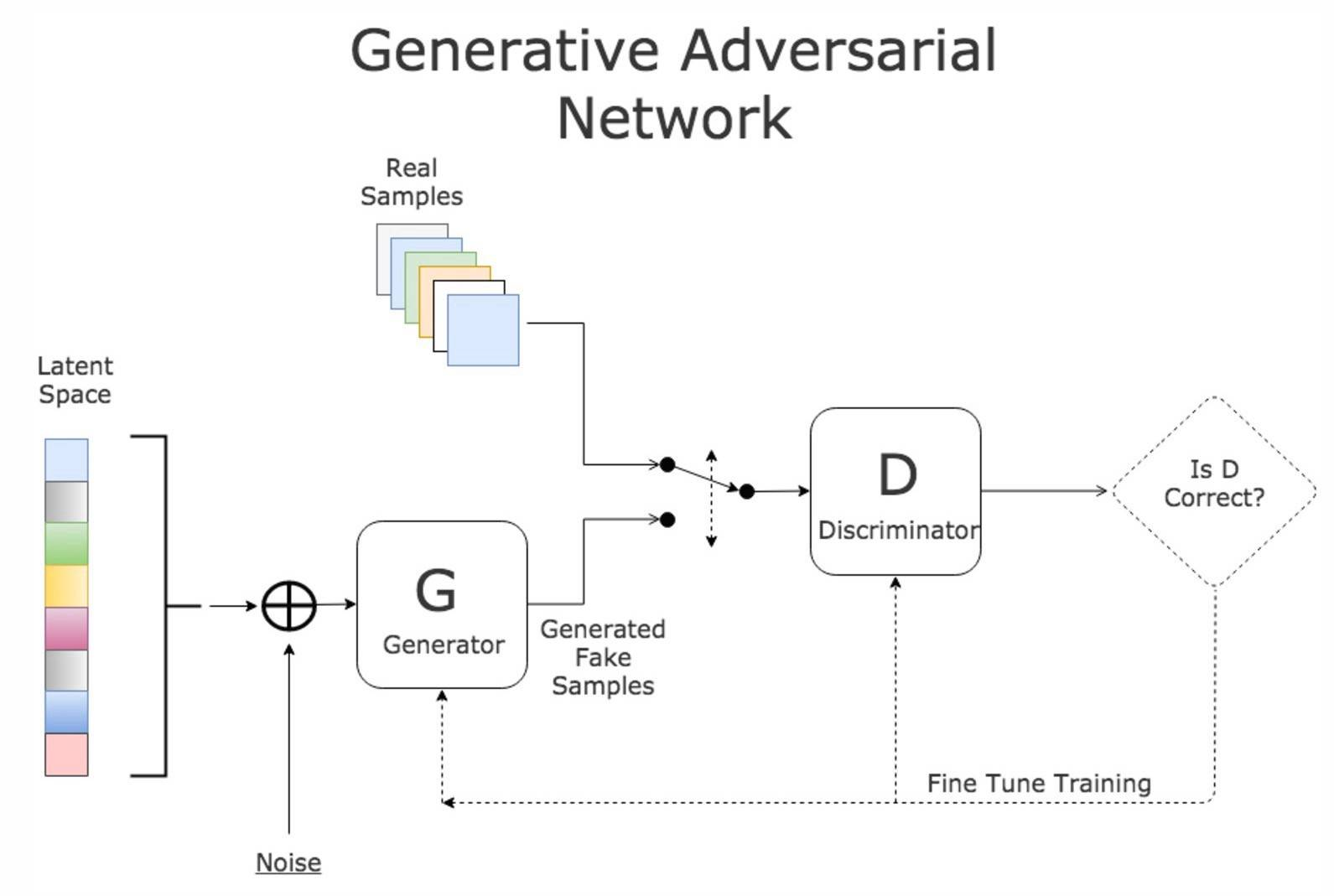
架构设计
生成器的设计需要深思熟虑,因为它决定了生成数据的质量和多样性。
全连接层
适用于较简单的数据集,如MNIST。
class SimpleGenerator(nn.Module):def __init__(self):super(SimpleGenerator, self).__init__()self.main = nn.Sequential(nn.Linear(100, 256),nn.ReLU(),nn.Linear(256, 512),nn.ReLU(),nn.Linear(512, 784),nn.Tanh())def forward(self, input):return self.main(input)
卷积层
适用于更复杂的图像数据生成,如DCGAN。
class ConvGenerator(nn.Module):def __init__(self):super(ConvGenerator, self).__init__()self.main = nn.Sequential(# 逆卷积层nn.ConvTranspose2d(100, 512, 4),nn.BatchNorm2d(512),nn.ReLU(),# ...)def forward(self, input):return self.main(input)
输入潜在空间
- 维度选择:潜在空间的维度选择对于模型的生成能力有重要影响。
- 分布选择:通常使用高斯分布或均匀分布。
激活函数和归一化
- ReLU和LeakyReLU:常用在生成器的隐藏层。
- Tanh:通常用于输出层,将像素值缩放到[-1, 1]。
- 批归一化:帮助提高训练稳定性。
反卷积技巧
- 逆卷积:用于上采样图像。
- PixelShuffle:更高效的上采样方法。
与判别器的协调
- 设计匹配:生成器和判别器的设计应相互协调。
- 卷积层参数共享:有助于增强生成能力。
小结
生成器构建是一个复杂和细致的过程。通过深入了解生成器的各个组成部分和它们是如何协同工作的,我们可以设计出适应各种任务需求的高效生成器。不同类型的激活函数、归一化、潜在空间设计以及与判别器的协同工作等方面的选择和优化是提高生成器性能的关键。
3.3 判别器构建
生成对抗网络(GAN)的判别器是一个二分类模型,用于区分生成的数据和真实数据。以下是判别器构建的详细内容:
判别器的角色和挑战
- 角色:区分真实数据和生成器生成的虚假数据。
- 挑战:平衡生成器和判别器的能力。
架构设计
- 卷积网络:常用于图像数据,效率较高。
- 全连接网络:对于非图像数据,例如时间序列。
代码示例:卷积判别器
class ConvDiscriminator(nn.Module):def __init__(self):super(ConvDiscriminator, self).__init__()self.main = nn.Sequential(nn.Conv2d(3, 64, 4, stride=2, padding=1),nn.LeakyReLU(0.2),# ...nn.Sigmoid() # 二分类输出)def forward(self, input):return self.main(input)
激活函数和归一化
- LeakyReLU:增加非线性,防止梯度消失。
- Layer Normalization:训练稳定性。
损失函数设计
- 二分类交叉熵损失:常用损失函数。
- Wasserstein距离:WGAN中使用,理论基础坚实。
正则化和稳定化
- 正则化:如L1、L2正则化防止过拟合。
- Gradient Penalty:例如WGAN-GP中,增加训练稳定性。
特殊架构设计
- PatchGAN:局部感受域的判别器。
- 条件GAN:结合额外信息的判别器。
与生成器的协调
- 协同训练:注意保持生成器和判别器训练的平衡。
- 渐进增长:例如ProGAN中,逐步增加分辨率。
小结
判别器的设计和实现是复杂的多步过程。通过深入了解判别器的各个组件以及它们是如何协同工作的,我们可以设计出适应各种任务需求的强大判别器。判别器的架构选择、激活函数、损失设计、正则化方法,以及如何与生成器协同工作等方面的选择和优化,是提高判别器性能的关键因素。
3.4 损失函数和优化器
损失函数和优化器是训练生成对抗网络(GAN)的关键组件,它们共同决定了GAN的训练速度和稳定性。
损失函数
损失函数量化了GAN的生成器和判别器之间的竞争程度。
1. 原始GAN损失
- 生成器损失:欺骗判别器。
- 判别器损失:区分真实和虚假样本。
# 判别器损失
real_loss = F.binary_cross_entropy(D_real, ones_labels)
fake_loss = F.binary_cross_entropy(D_fake, zeros_labels)
discriminator_loss = real_loss + fake_loss# 生成器损失
generator_loss = F.binary_cross_entropy(D_fake, ones_labels)
2. Wasserstein GAN损失
- 理论优势:更连续的梯度。
- 训练稳定性:解决模式崩溃问题。
3. LSGAN(最小平方损失)
- 减小梯度消失:在训练早期。
4. hinge损失
- 鲁棒性:对噪声和异常值具有鲁棒性。
优化器
优化器负责根据损失函数的梯度更新模型的参数。
1. SGD
- 基本但强大。
- 学习率调整:如学习率衰减。
2. Adam
- 自适应学习率。
- 用于大多数情况:通常效果很好。
3. RMSProp
- 适用于非平稳目标。
- 自适应学习率。
# 示例
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
超参数选择
- 学习率:重要的调整参数。
- 动量参数:例如Adam中的beta。
- 批大小:可能影响训练稳定性。
小结
损失函数和优化器在GAN的训练中起着核心作用。损失函数界定了生成器和判别器之间的竞争关系,而优化器则决定了如何根据损失函数的梯度来更新这些模型的参数。在设计损失函数和选择优化器时需要考虑许多因素,包括训练的稳定性、速度、鲁棒性等。理解各种损失函数和优化器的工作原理,可以帮助我们为特定任务选择合适的方法,更好地训练GAN。
3.5 模型训练
在生成对抗网络(GAN)的实现中,模型训练是最关键的阶段之一。本节详细探讨模型训练的各个方面,包括训练循环、收敛监控、调试技巧等。
训练循环
训练循环是GAN训练的心脏,其中包括了前向传播、损失计算、反向传播和参数更新。
代码示例:训练循环
for epoch in range(epochs):for real_data, _ in dataloader:# 更新判别器optimizer_D.zero_grad()real_loss = ...fake_loss = ...discriminator_loss = real_loss + fake_lossdiscriminator_loss.backward()optimizer_D.step()# 更新生成器optimizer_G.zero_grad()generator_loss = ...generator_loss.backward()optimizer_G.step()
训练稳定化
GAN训练可能非常不稳定,下面是一些常用的稳定化技术:
- 梯度裁剪:防止梯度爆炸。
- 使用特殊的损失函数:例如Wasserstein损失。
- 渐进式训练:逐步增加模型的复杂性。
模型评估
GAN没有明确的损失函数来评估生成器的性能,因此通常需要使用一些启发式的评估方法:
- 视觉检查:人工检查生成的样本。
- 使用标准数据集:例如Inception Score。
- 自定义度量标准:与应用场景相关的度量。
超参数调优
- 网格搜索:系统地探索超参数空间。
- 贝叶斯优化:更高效的搜索策略。
调试和可视化
- 可视化损失曲线:了解训练过程的动态。
- 检查梯度:例如使用梯度直方图。
- 生成样本检查:实时观察生成样本的质量。
分布式训练
- 数据并行:在多个GPU上并行处理数据。
- 模型并行:将模型分布在多个GPU上。
小结
GAN的训练是一项复杂和微妙的任务,涉及许多不同的组件和阶段。通过深入了解训练循环的工作原理,学会使用各种稳定化技术,和掌握模型评估和超参数调优的方法,我们可以更有效地训练GAN模型。
3.6 结果分析和可视化
生成对抗网络(GAN)的训练结果分析和可视化是评估模型性能、解释模型行为以及调整模型参数的关键环节。本节详细讨论如何分析和可视化GAN模型的生成结果。
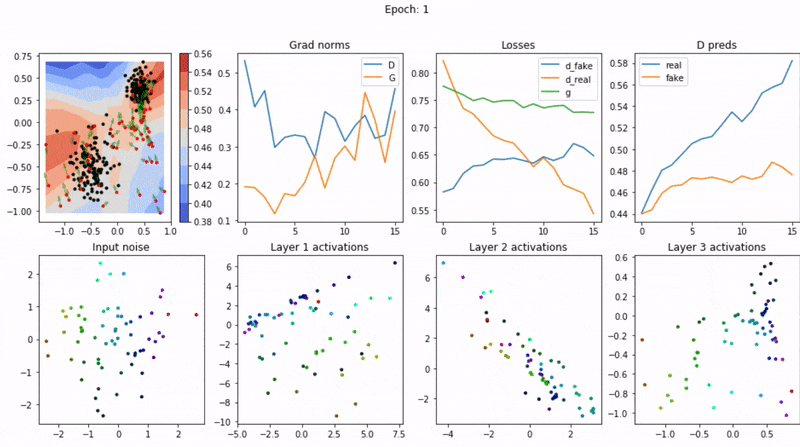
结果可视化
可视化是理解GAN的生成能力的直观方法。常见的可视化方法包括:
1. 生成样本展示
- 随机样本:从随机噪声生成的样本。
- 插值样本:展示样本之间的平滑过渡。
2. 特征空间可视化
- t-SNE和PCA:用于降维的技术,可以揭示高维特征空间的结构。
3. 训练过程动态
- 损失曲线:观察训练稳定性。
- 样本质量随时间变化:揭示生成器的学习过程。
量化评估
虽然可视化直观,但量化评估提供了更准确的性能度量。常用的量化方法包括:
1. Inception Score (IS)
- 多样性和一致性的平衡。
- 在标准数据集上评估。
2. Fréchet Inception Distance (FID)
- 比较真实和生成分布。
- 较低的FID表示更好的性能。
模型解释
理解GAN如何工作以及每个部分的作用可以帮助改进模型:
- 敏感性分析:如何输入噪声的变化影响输出。
- 特征重要性:哪些特征最影响判别器的决策。
应用场景分析
- 实际使用情况下的性能。
- 与现实世界任务的结合。
持续监测和改进
- 自动化测试:保持模型性能的持续监测。
- 迭代改进:基于结果反馈持续优化模型。
小结
结果分析和可视化不仅是GAN工作流程的最后一步,还是一个持续的、反馈驱动的过程,有助于改善和优化整个系统。可视化和量化分析工具提供了深入了解GAN性能的方法,从直观的生成样本检查到复杂的量化度量。通过这些工具,我们可以评估模型的优点和缺点,并做出有针对性的调整。
四、总结
生成对抗网络(GAN)作为一种强大的生成模型,在许多领域都有广泛的应用。本文全面深入地探讨了GAN的不同方面,涵盖了理论基础、常见架构、实际实现和结果分析。以下是主要的总结点:

1. 理论基础
- 工作原理:GAN通过一个生成器和一个判别器的博弈过程实现强大的生成能力。
- 数学背景:深入了解了损失函数、优化方法和稳定化策略。
- 架构与变体:讨论了不同的GAN结构和它们的适用场景。
2. 实战实现
- 环境准备:提供了准备训练环境和数据集的指导。
- 模型构建:详细解释了生成器和判别器的设计以及损失函数和优化器的选择。
- 训练过程:深入讨论了训练稳定性、模型评估、超参数调优等关键问题。
- 结果分析:强调了可视化、量化评估和持续改进的重要性。
3. 技术挑战与前景
- 训练稳定性:GAN训练可能不稳定,需要深入理解和恰当选择稳定化技术。
- 评估标准:缺乏统一的评估标准仍是一个挑战。
- 多样性与真实性的平衡:如何在保持生成样本多样性的同时确保其真实性。
- 实际应用:将GAN成功地应用于实际问题,仍需进一步研究和实践。
展望
GAN的研究和应用仍然是一个快速发展的领域。随着技术的不断进步和更多的实际应用,我们期望未来能够看到更多高质量的生成样本,更稳定的训练方法,以及更广泛的跨领域应用。GAN的理论和实践的深入融合将为人工智能和机器学习领域开辟新的可能性。
作者 TechLead,拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人
相关文章:
GAN!生成对抗网络GAN全维度介绍与实战
目录 一、引言1.1 生成对抗网络简介1.2 应用领域概览1.3 GAN的重要性 二、理论基础2.1 生成对抗网络的工作原理2.1.1 生成器生成过程 2.1.2 判别器判别过程 2.1.3 训练过程训练代码示例 2.1.4 平衡与收敛 2.2 数学背景2.2.1 损失函数生成器损失判别器损失 2.2.2 优化方法优化代…...
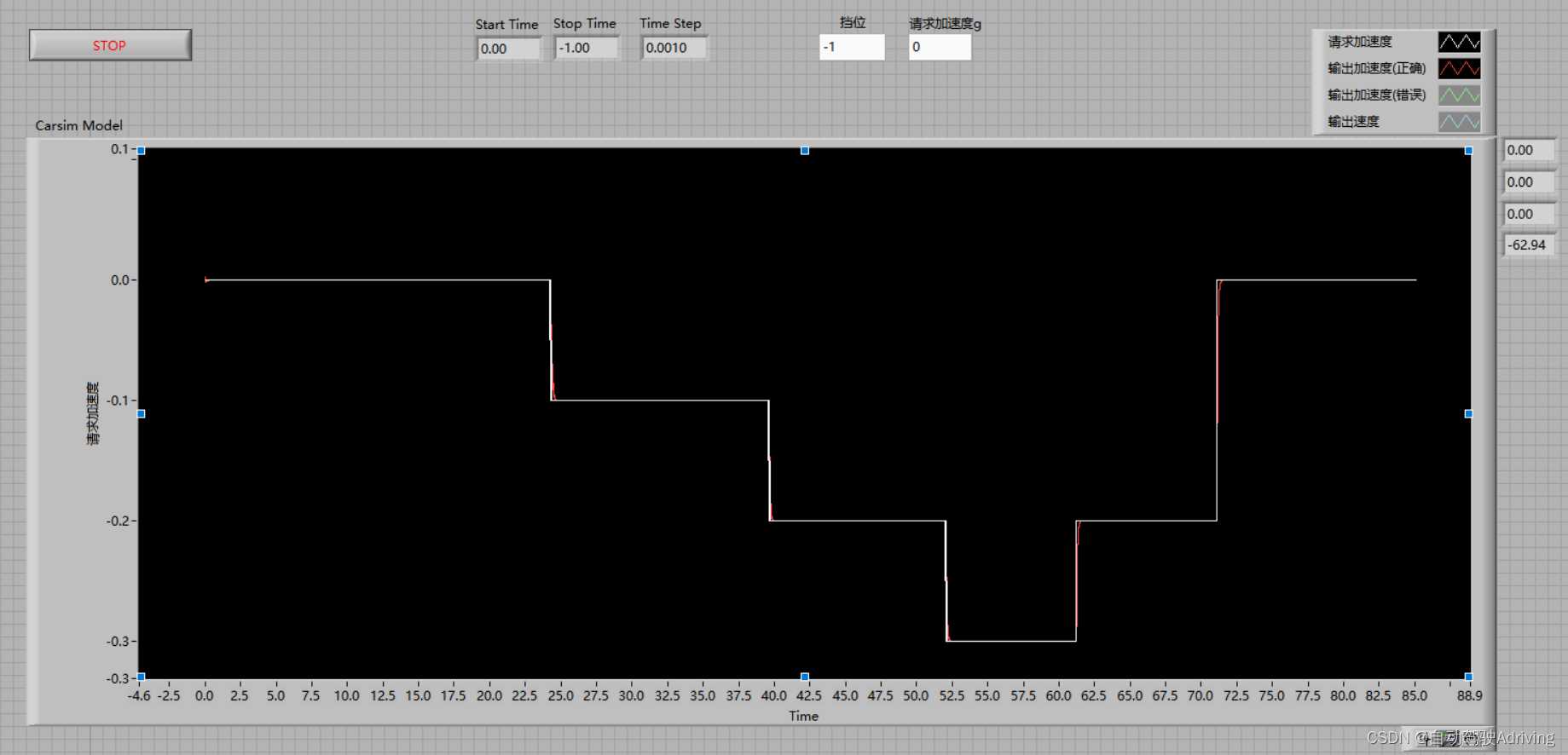
自动驾驶仿真:基于Carsim开发的加速度请求模型
文章目录 前言一、加速度输出变量问题澄清二、配置Carsim动力学模型三、配置Carsim驾驶员模型四、添加VS Command代码五、Run Control联合仿真六、加速度模型效果验证 前言 1、自动驾驶行业中,算法端对于纵向控制的功能预留接口基本都是加速度,我们需要…...
.netcore grpc客户端工厂及依赖注入使用
一、客户端工厂概述 gRPC 与 HttpClientFactory 的集成提供了一种创建 gRPC 客户端的集中方式。可以通过依赖包Grpc.Net.ClientFactory中的AddGrpcClient进行gRPC客户端依赖注入AddGrpcClient函数提供了许多配置项用于处理一些其他事项;例如AOP、重试策略等 二、案…...
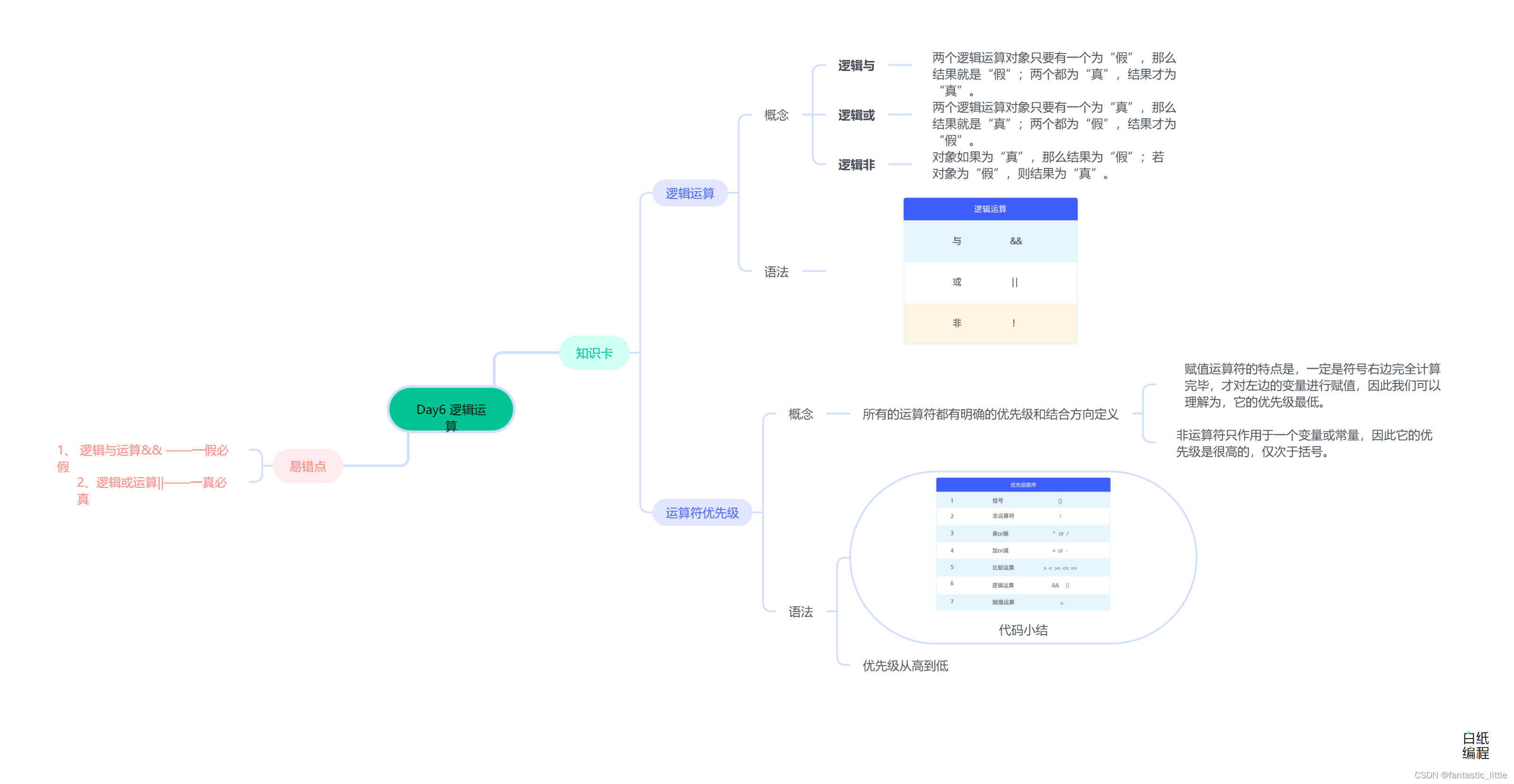
C语言入门_Day7 逻辑运算
目录: 前言 1.逻辑运算 2.优先级 3.易错点 4.思维导图 前言 算术运算用来进行数据的计算和处理;比较运算是用来比较不同的数据,进而来决定下一步怎么做;除此以外还有一种运算叫做逻辑运算,它的应用场景也是用来影…...

什么是Eureka?以及Eureka注册服务的搭建
导包 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 htt…...

Docker安装并配置镜像加速器,镜像、容器的基本操作
目录 1.安装docker服务,配置镜像加速器 (1)安装依赖的软件包 (2)设置yum源,我配置的阿里仓库 (3)选择一个版本安装 (4)启动docker服务,并设置…...

前端 -- 基础 网页、HTML、 WEB标准 扫盲详解
什么是网页 : 网页是构成网站的基本元素,它通常由 图片、链接、文字、声音、视频等元素组成。 通常我们看到的网页 ,常见以 .html 或 .htm 后缀结尾的文件, 因此俗称 HTML 文件 什么是 HTML : HTML 指的是 超文本标记语言,…...

分布式锁实现方式
分布式锁 1 分布式锁介绍 1.1 什么是分布式 一个大型的系统往往被分为几个子系统来做,一个子系统可以部署在一台机器的多个 JVM(java虚拟机) 上,也可以部署在多台机器上。但是每一个系统不是独立的,不是完全独立的。需要相互通信ÿ…...

C语言小练习(一)
🌞 “人生是用来体验的,不是用来绎示完美的,接受迟钝和平庸,允许出错,允许自己偶尔断电,带着遗憾,拼命绽放,这是与自己达成和解的唯一办法。放下焦虑,和不完美的自己和解…...

Flask-flask系统运行后台轮询线程
对于有些flask系统,后台需要启动轮询线程,执行特定的任务,以下是一个简单的例子。 globals/daemon.py import threading from app.executor.ops_service import find_and_run_ops_task_todo_in_redisdef context_run_func(app, func):with …...

jsp本质-servlet
jsp本质-servlet 一、jsp文件 <% page language"java" contentType"text/html; charsetUTF-8" pageEncoding"UTF-8"%> <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>JSP Example…...

回归预测 | MATLAB实现GWO-SVM灰狼优化算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现GWO-SVM灰狼优化算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现GWO-SVM灰狼优化算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基…...

科技资讯|苹果Vision Pro新专利曝光:可调节液态透镜
苹果公司近日申请了名为“带液态镜头的电子设备”,概述了未来可能的头显设计。头显设备中的透镜采用可调节的液态透镜,每个透镜可以具有填充有液体的透镜腔,透镜室可以具有形成光学透镜表面的刚性和 / 或柔性壁。 包括苹果自家的 Vision Pr…...

神经网络基础-神经网络补充概念-38-归一化输入
概念 归一化输入是一种常见的数据预处理技术,旨在将不同特征的取值范围映射到相似的尺度,从而帮助优化机器学习模型的训练过程。归一化可以提高模型的收敛速度、稳定性和泛化能力,减少模型受到不同特征尺度影响的情况。 常见的归一化方法 …...

【Redis】什么是缓存雪崩,如何预防缓存雪崩?
【Redis】什么是缓存雪崩,如何预防缓存雪崩? 如果缓存集中在一段时间内失效,也就是通常所说的热点数据集中失效 (一般都会给缓存设定一个失效时间,过了失效时间后,该数据库会被缓存直接删除,从…...

[国产MCU]-W801开发实例-开发环境搭建
W801开发环境搭建 文章目录 W801开发环境搭建1、W801芯片介绍2、W801芯片特性3、W801芯片结构4、开发环境搭建1、W801芯片介绍 W801芯片是联盛德微电子推出的一款高性价比物联网芯片。 W801 芯片是一款安全 IoT Wi-Fi/蓝牙 双模 SoC芯片。芯片提供丰富的数字功能接口。支持2.…...
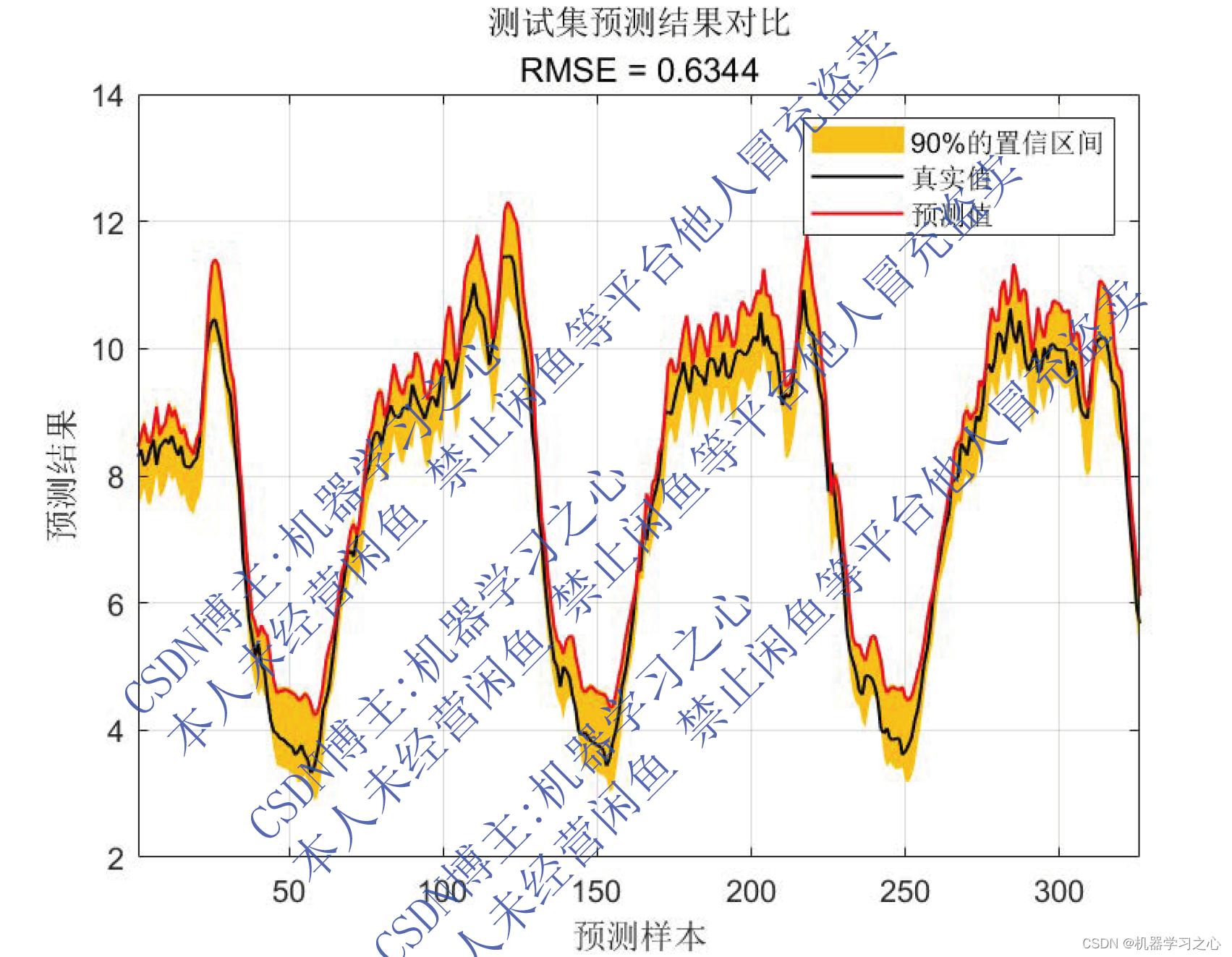
区间预测 | MATLAB实现QRGRU门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRGRU门控循环单元分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRGRU门控循环单元分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRGRU门控循环单元分位数回归时间序列区间预测。基于分位…...
改善神经网络——优化算法(mini-batch、动量梯度下降法、Adam优化算法)
改善神经网络——优化算法 梯度下降Mini-batch 梯度下降(Mini-batch Gradient Descent)指数加权平均包含动量的梯度下降RMSprop算法Adam算法 优化算法可以使神经网络运行的更快,机器学习的应用是一个高度依赖经验的过程,伴随着大量…...
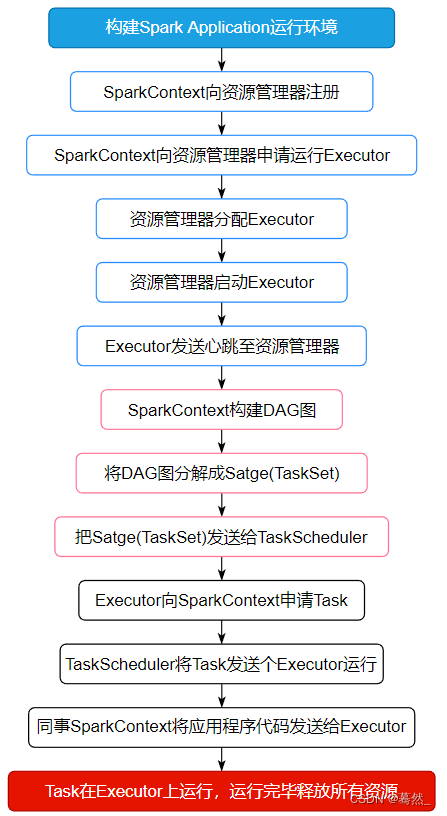
大数据面试题:Spark的任务执行流程
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 可回答:1)Spark的工作流程?2)Spark的调度流程;3)Spark的任务调度原理…...

通过 Amazon SageMaker JumpStart 部署 Llama 2 快速构建专属 LLM 应用
来自 Meta 的 Llama 2 基础模型现已在 Amazon SageMaker JumpStart 中提供。我们可以通过使用 Amazon SageMaker JumpStart 快速部署 Llama 2 模型,并且结合开源 UI 工具 Gradio 打造专属 LLM 应用。 Llama 2 简介 Llama 2 是使用优化的 Transformer 架构的自回归语…...

MQTT 协议 超详细精讲
一、MQTT 协议简介全称:Message Queuing Telemetry Transport(消息队列遥测传输协议)定位:专为物联网、嵌入式设备、低带宽、弱网环境设计的轻量级发布 / 订阅式消息传输协议,是数字孪生、智能家居、工业物联网最常用的…...

突破Cursor AI试用限制:技术实现与实战指南
突破Cursor AI试用限制:技术实现与实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial request…...

OpenSpeedy:智能游戏加速引擎的架构解析与应用指南
OpenSpeedy:智能游戏加速引擎的架构解析与应用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾在单机游戏中遭遇过这样的困扰?角色扮演游…...

Linux系统变更追踪工具whatdiditdo:实现文件级监控与审计
1. 项目概述:一个追踪系统变更的“时光机”最近在排查一个线上服务故障,问题最终定位到是某个依赖库在几天前的一次静默升级上。为了搞清楚到底是谁、在什么时候、改了什么东西,我不得不翻遍了近一周的服务器操作日志、CI/CD流水线记录和版本…...

基于RAG技术构建AI知识库插件:从原理到实践
1. 项目概述与核心价值最近在折腾个人知识库和AI助手,发现一个挺有意思的插件项目:urantia-hub/urantia-papers-plugin。乍一看这个名字,可能很多人会有点懵,不知道这具体是干嘛的。简单来说,这是一个为AI助手…...

STHS34PF80红外存在检测:InfraredPD算法库集成与调试实战
1. 项目概述与核心价值最近在折腾一个智能家居的节能项目,核心需求是让设备能精准判断房间里到底有没有人,而不是简单地检测到有物体移动就触发。市面上很多基于PIR(被动红外)的运动传感器,对于静止不动的人体识别效果…...
)
RFSoC开发避坑指南:手把手教你理解并配置RF数据转换器的核心结构体(以XRFdc为例)
RFSoC开发实战:深度解析XRFdc结构体配置与避坑策略 第一次打开xrfdc.h头文件时,面对密密麻麻的结构体定义,我的鼠标滚轮不由自主地滑动了三分钟才看完所有内容。作为曾经在RFSoC项目上踩过无数坑的开发者,我完全理解那种面对数十个…...

AI与Web3融合:Solana开发者工具箱core-ai架构解析与实践
1. 项目概述:当AI遇见Web3,一个开发者工具箱的诞生最近在Web3和AI的交叉领域里折腾,发现了一个挺有意思的项目——helius-tech-labs/core-ai。这名字听起来就很有野心,core(核心)和ai(人工智能&…...

Wonder3D完整教程:如何用单张图片快速生成3D模型
Wonder3D完整教程:如何用单张图片快速生成3D模型 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 想要将一张普通的图片变成立体的3D模型吗࿱…...

3D打印技术如何重塑消费电子供应链:从原型验证到小批量生产
1. 项目概述:当3D打印遇上消费电子最近几年,我身边不少做产品设计、硬件开发的朋友,聊天时总会不约而同地提到一个词:3D打印。以前大家觉得这玩意儿就是个做手办、打样机的“玩具”,但现在风向明显变了。尤其是在消费电…...