Flink的常用算子以及实例
1.map
特性:接收一个数据,经过处理之后,就返回一个数据
1.1. 源码分析
- 我们来看看map的源码

map需要接收一个MapFunction<T,R>的对象,其中泛型T表示传入的数据类型,R表示经过处理之后输出的数据类型 - 我们继续往下点,看看MapFunction<T,R>的源码

这是一个接口,那么在代码中,我们就需要实现这个接口
1.2. 案例
那么我们现在要实现一个功能,就是从给一个文件中读取数据,返回每一行的字符串长度。
我们要读取的文件内容如下
代码贴在这里(为了让打击不看迷糊,导包什么的我就省略了)
public class TransformTest1_Base {public static void main(String[] args) throws Exception {// 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 将并行度设为1env.setParallelism(1);// 3. 读取文件夹DataStreamSource<String> inputDataStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 4. 将文件夹每一行的数据都返回它的长度// 在这里我们用匿名内部类的方式创建了一个MapFunction对象SingleOutputStreamOperator<Integer> dataStream = inputDataStream.map(new MapFunction<String, Integer>() {// 5. 重写map方法,参数s是接收到的一个数据,我们只需要返回它的长度就行了。@Overridepublic Integer map(String s) throws Exception {return s.length();}});// 6. 打印输出dataStream.print();// 7. 启动执行环境env.execute();}
}显示
1.3. 总结
map的使用范围就是需要对的那个数据进行处理,并且每次返回一个数据的时候,map就比较方便了。
2. flatMap
- 接收一个数据,可以返回多条数据
2.1. 源码分析

我们发现,它需要传入一个FlatMapFunction的一个对象
我们继续点进去,看看FlatMapFunction的源码,可以发现,FlatMapFunction<T,R>也是一个接口,并且接口里面的方法的返回值是一个Collector,也就是多个值的集合。
2.2. 案例
我们还是读取那个文件,这次我们要做的处理是,将文件的每一行数据按照逗号隔开,给出代码:
public class TransformTest2_Base {public static void main(String[] args) throws Exception {// 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 设置并行度env.setParallelism(1);// 3. 读取文件夹DataStreamSource<String> dataStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 4. 用匿名内部类的方式重写FlatMapFuncction,将每行字符按","隔开SingleOutputStreamOperator<String> flatMapStream = dataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String s, Collector<String> collector) throws Exception {// 5. 分割一行字符,获得对应的字符串数组String[] split = s.split(",");for (String slt : split) {// 6. 将这些数据返回collector.collect(slt);}}});// 7. 打印输出处理后的数据flatMapStream.print();// 8. 启动执行环境env.execute();}
}可以看到执行的结果
3. filter
听这个名字就知道是个过滤器,用来过滤数据。
3.1. 源码分析
我们看看filer的源码,继承子FilterFunction,可以看到,这次泛型就只有一个值了,因为filter只允许返回的数据<=原来的数据,所以只做过滤,并不能改变数据蕾西,没必要设置返回的类型
我们继续点进去,看看FilterFunction的源码
果不其然,也是一个接口,而里面的filter方法只有一个参数,并且返回的是一个boolean类型,若返回true则var1原样返回,若返回false,则var1会被过滤掉。
3.2. 案例
我们还是读取以上文件,这一次我们返回以"sensor_1"开头的字符串,其余的一律不返回,给出代码
public class TransformTest3_Base {public static void main(String[] args) throws Exception {// 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 设置并行度env.setParallelism(1);// 3. 读取文件DataStreamSource<String> dataStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 4. 用匿名内部类的方式重写FilterFunctionSingleOutputStreamOperator<String> filterDataStream = dataStream.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String s) throws Exception {// 5. 若s以"sensor_1"开头,则返回truereturn s.startsWith("\"sensor_1\"");}});// 6. 打印处理后的数据filterDataStream.print();// 7. 启动执行环境env.execute();}
}4. 分组聚合
- 注意:任何的聚合操作都有默认的分组,聚合是在分组的基础上进行的。比如,对整体进行求和,那么分组就是整体。所以,在做聚合操作之前,一定要明确是在哪个分组上进行聚合操作
- 注意:聚合操作,本质上是一个多对一(一对一是多对一的特殊情况)的操作。特别注意的是这个’一‘,可以是一个值(mean, sum等),同样也可以是一个对象(list, set等对象)
4.1. 分组(keyBy)
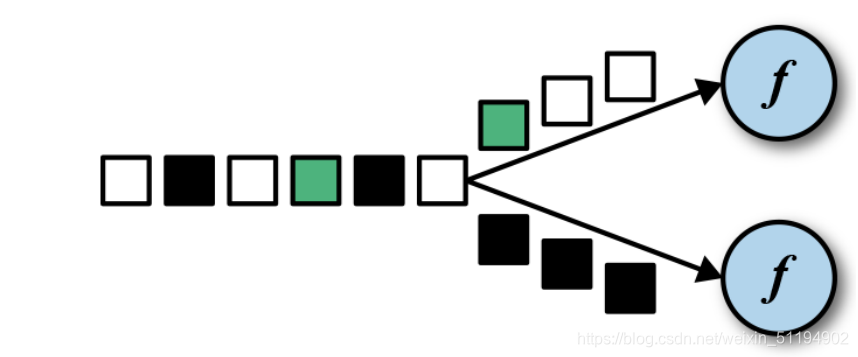
DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同 key 的元素,在内部以 hash 的形式实现的。
- 分组就是为了聚合操作做准备的,keyBy方法会将数据流按照hash实现,分别放在不同的分区,每个分区都可以进行聚合操作。
- 我们可以用这个性质,计算每一个sensor温度的最大值,我们为此将文件修改:
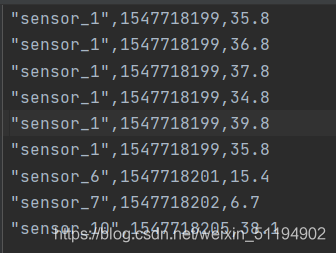
分组之后的图就是所有sensor_1在一个分区里,sensor_6,sensor_7,sensor_10在不同的三个分区,也就是有四个分区,而后三个分区中只有一条数据,所以最大值和最小值都只有一个 - 在flink中,分组操作是由keyBy方法来完成的,我们来看看keyBy的源码
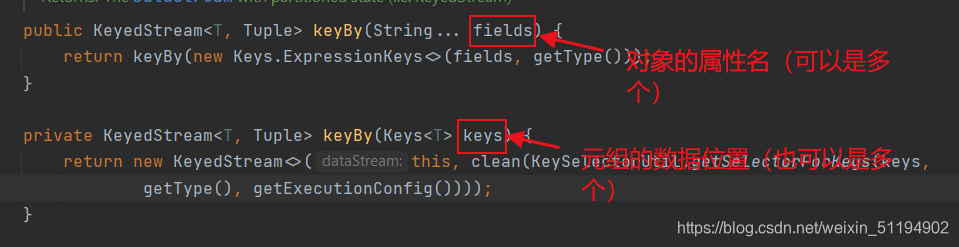
可以发现,keyBy可以对对象和元组进行聚合。
4.2. 聚合
这些算子可以针对 KeyedStream 的每一个支流做聚合。
⚫ sum():对每个支流求和
⚫ min():对每个支流求最小值
⚫ max():对每个支流求最大值
⚫ minBy()
⚫ maxBy()
我们来看看max()的源码
这也是传一个属性名,也就是求对应的属性名的最大值。
4.3. 实例演示
public class TransformTest1_RollingAggreation {public static void main(String[] args) throws Exception {// 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 设置并行度env.setParallelism(1);// 3. 读取文件DataStreamSource<String> stringDataStreamSource = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 4. 用map将每行数据变成一个对象SingleOutputStreamOperator<SensorReading> map = stringDataStreamSource.map(new MapFunction<String, SensorReading>() {@Overridepublic SensorReading map(String s) throws Exception {String[] split = s.split(",");return new SensorReading(split[0], new Long(split[1]), new Double(split[2]));}});// 5. 分组操作,以id属性分组KeyedStream<SensorReading, Tuple> keyedstream = map.keyBy("id");// 6. 聚合操作,求每个分组的温度最大值SingleOutputStreamOperator<SensorReading> resultStream = keyedstream.max("temperature");// 7. 打印输出resultStream.print();// 8. 启动执行环境env.execute();}
}运行结果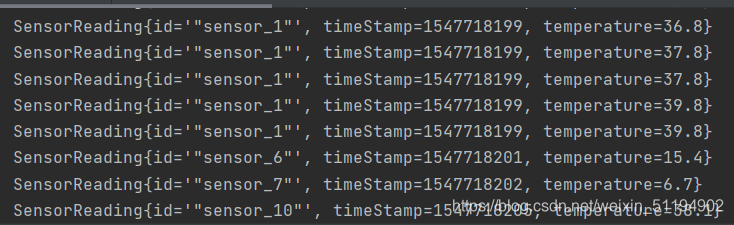
诶,这有人就要问了,不是求每一个分组的温度最大值么?为什么sensor_1的这个分组所有的数据都有?
答:flink是一个流处理分布式框架,这是一条数据流,每来一个数据就得处理一次,所以输出的都是当前状态下的最大值。
4.4. reduce自定义聚合
在实际生产中,不可能让我们完成这么简单的操作就行了,所以我们需要更复杂的操作,而reduce就是满足这个条件,它可以让我们自定义聚合的方式。
- 我们来看看reduce的源码

reduce需要传入的是一个ReduceFunction的对象,我们再来看看ReduceFunction是个什么东西
var1是当前这个分组的状态,var2是新加入的值,而reduce函数体就是我们要进行的操作,返回一个新的状态。
到这我就明白了,要是我们向实时获取最大温度的话,var1是之前的最大温度,通过var1和var2的比较就能实现。
4.5. reduce实例
我们这一次要实现一个实时的温度最大值,也就是返回的数据中的时间戳是当前的。
public class TransformTest1_Reduce {public static void main(String[] args) throws Exception {// 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 设置并行度env.setParallelism(1);// 3. 读取文件DataStreamSource<String> dataStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 4. 通过map将每行数据转换为一个对象SingleOutputStreamOperator<SensorReading> map = dataStream.map(new MapFunction<String, SensorReading>() {@Overridepublic SensorReading map(String s) throws Exception {String[] split = s.split(",");return new SensorReading(split[0], new Long(split[1]), new Double(split[2]));}});// 5. 按对象的id分组KeyedStream<SensorReading, Tuple> keyStream = map.keyBy("id");// 6. reduce自定义聚合SingleOutputStreamOperator<SensorReading> reduce = keyStream.reduce(new ReduceFunction<SensorReading>() {@Overridepublic SensorReading reduce(SensorReading sensorReading, SensorReading t1) throws Exception {// 7. 获取当前时间为止接收到的最大温度return new SensorReading(sensorReading.getId(), System.currentTimeMillis(), Math.max(sensorReading.getTemperature(),t1.getTemperature()));}});// 8. 打印输出reduce.print();// 9. 启动运行环境env.execute();}
}这一次的输出我们就得你好好研究一下了。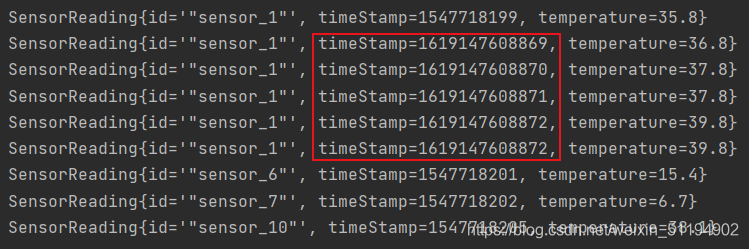
从这块可以发现,我们获取的都是当前的时间戳,而且时间戳也在改变,这一点很好理解,但是下面这个数据就很诡异了。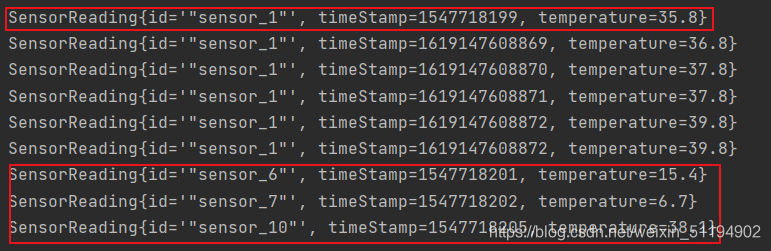
- 这两块的时间戳为什么没有改变呢?这需要我们再来看看reduce方法了,reduce方法是传入两个参数,第一个是当前的状态,第二个是新读取的值,通过方法体的操作返回一个最新的状态。
- 仔细理解一下这句话,若我刚开始没有数据的时候,那么哪来的状态呢?所以reduce把接收到的第一个参数作为状态,其中sensor_6,7,8这三个分区只有一个数据,所以直接拿来当作状态。
5. 多流转换算子
5.1. 分流操作(Split 和 Select)
- Split能将流中的数据按条件贴上标签,比如我把温度大于30度的对象贴上一个high标签,把温度低于30度的贴上一个low标签,标签可以贴多个。那么就把流中的数据,按照标签分类了(这里并没有分流)
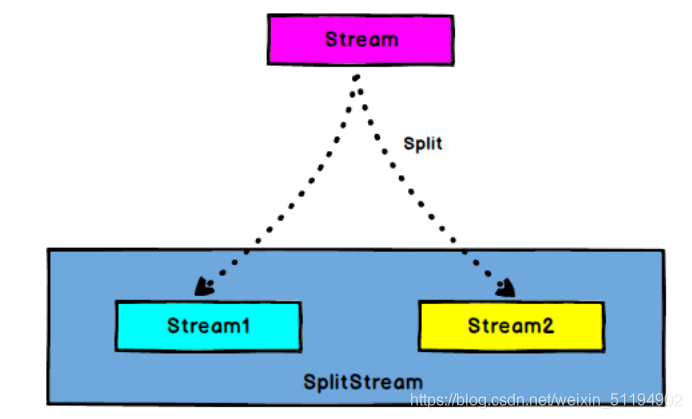
- Select是按照标签来分流
- split源码
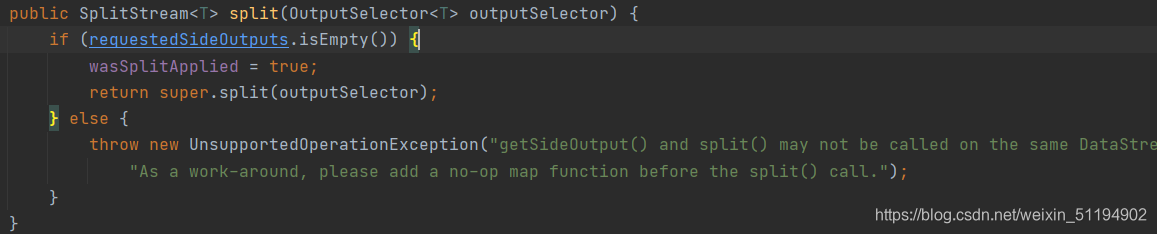
可以发现,返回的是一个SplitStream,需要传入一个选择器,我们看看OutputSeclector的源码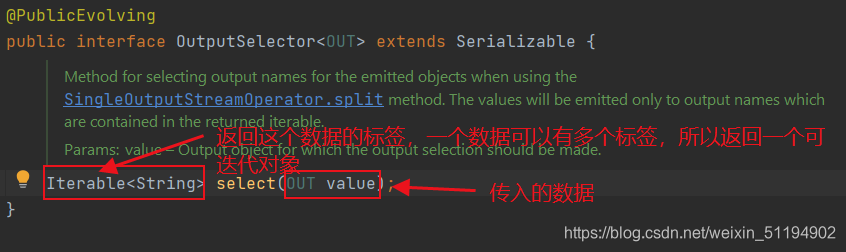
传入value,返回这个value对应的标签,实现对这个value进行类似"分类"的操作。 - select源码

只需要接收一个或者多个标签就能返回包含那个标签对象的数据流。
5.2. 实例演示
- 我们这一次要把读取到的数据分成三条流,一条是high(高于30度),一条是low(低于30度),一条是all(所有的数据)。代码:
public class TransformTest4_MultipleStreams {public static void main(String[] args) throws Exception {// 1. 获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 设置并行度env.setParallelism(1);// 3. 读取文件DataStreamSource<String> dataStream = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 4. 通过map将每行数据转换为一个对象SingleOutputStreamOperator<SensorReading> map = dataStream.map(new MapFunction<String, SensorReading>() {@Overridepublic SensorReading map(String s) throws Exception {String[] split = s.split(",");return new SensorReading(split[0], new Long(split[1]), new Double(split[2]));}});// 5. 按条件贴标签SplitStream<SensorReading> split = map.split(new OutputSelector<SensorReading>() {@Overridepublic Iterable<String> select(SensorReading value) {return value.getTemperature() > 30 ? Collections.singletonList("high") : Collections.singletonList("low");}});// 6. 按标签选择,生成不同的数据流DataStream<SensorReading> high = split.select("high");DataStream<SensorReading> low = split.select("low");DataStream<SensorReading> all = split.select("high", "low");high.print("high");low.print("low");all.print("all");env.execute();}
}5.3. 合流操作Connect 和 CoMap
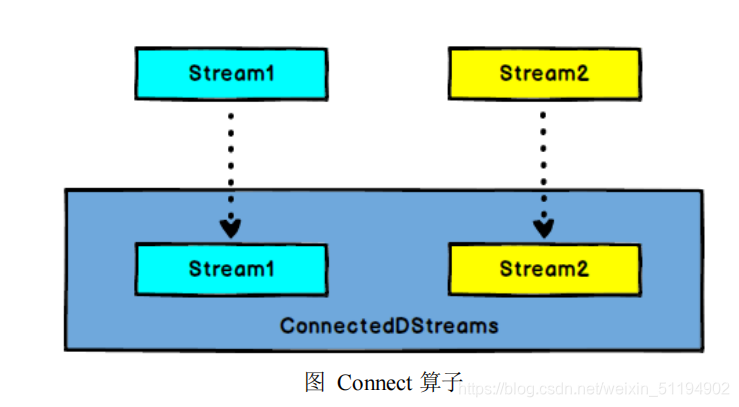
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数
据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。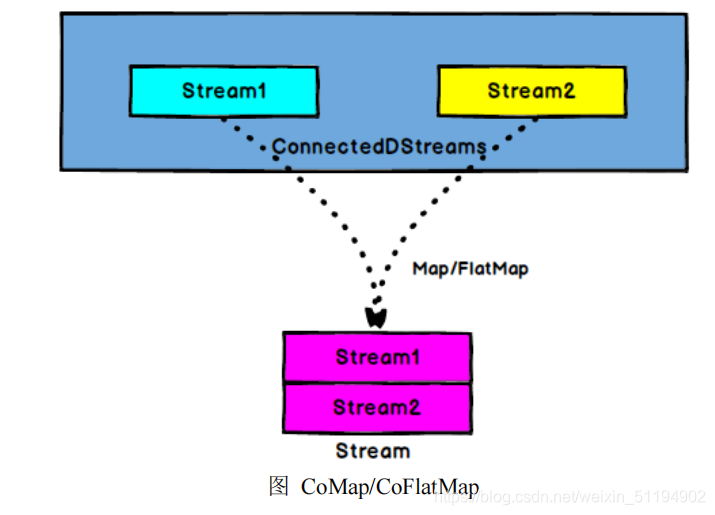
ConnectedStreams → DataStream:作用于 ConnectedStreams 上,功能与 map和 flatMap 一样,对 ConnectedStreams 中的每一个 Stream 分别进行 map 和 flatMap处理。
类似于一国两制,看似两条流合并在了一起,其实内部依旧是按照自己的约定运行,类型并没有改变。
- connect源码

将当前调用者的流和参数中的流合并,返回一个ConnectedStreams<T,R>类型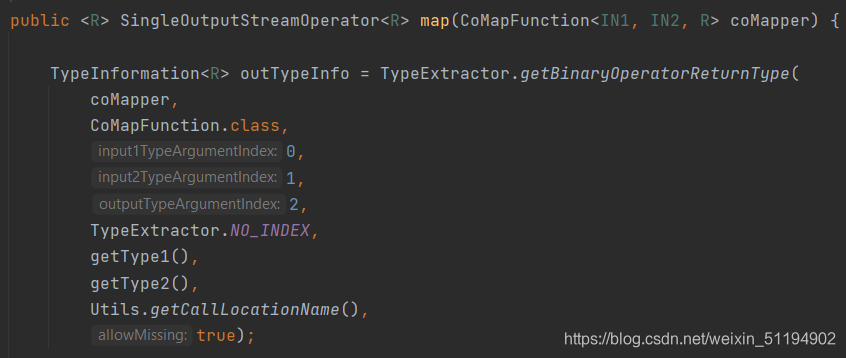
我们再来看看ConnectionStreams<T,R>中的map方法,其中要传的是一个CoMapFunction<IN1,IN2,R>的对象,最重要的就是这个类,我们来看看这个类
这个CoMapFunction<IN1,IN2,R>和之前的MapFunction不太一样,这里要重写的方法有两个,map1和map2,一个是针对IN1的,一个是针对IN2的,R就是返回类型。
这下全明白了,在这个方法内部,对这两条流分别操作,合成一条流。
5.4. 实例演示
public class TransformTest5_MultipleStreams {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 1. 读取文件DataStreamSource<String> dataStreamSource = env.readTextFile("C:\\Users\\Administrator\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensor");// 2. 将每行数据变成一个对象SingleOutputStreamOperator<SensorReading> map = dataStreamSource.map(new MapFunction<String, SensorReading>() {@Overridepublic SensorReading map(String s) throws Exception {String[] split = s.split(",");return new SensorReading(split[0], new Long(split[1]), new Double(split[2]));}});// 3. 将数据打上标签SplitStream<SensorReading> split = map.split(new OutputSelector<SensorReading>() {@Overridepublic Iterable<String> select(SensorReading value) {return value.getTemperature() > 30 ? Collections.singletonList("high") : Collections.singletonList("low");}});// 4. 按照高温和低温的标签分成两条流DataStream<SensorReading> high = split.select("high");DataStream<SensorReading> low = split.select("low");// 5. 将high流的数据转换为二元组SingleOutputStreamOperator<Tuple2<String, Double>> tuple2SingleOutputStreamOperator = high.map(new MapFunction<SensorReading, Tuple2<String, Double>>() {@Overridepublic Tuple2<String, Double> map(SensorReading sensorReading) throws Exception {return new Tuple2<>(sensorReading.getId(), sensorReading.getTemperature());}});// 6. 将tuple2SingleOutputStreamOperator和low连接ConnectedStreams<Tuple2<String, Double>, SensorReading> connect = tuple2SingleOutputStreamOperator.connect(low);// 7. 调用map传参CoMapFunction将两条流合并成一条流objectSingleOutputStreamOperatorSingleOutputStreamOperator<Object> objectSingleOutputStreamOperator = connect.map(new CoMapFunction<Tuple2<String, Double>, SensorReading, Object>() {// 这是处理high流的方法@Overridepublic Object map1(Tuple2<String, Double> value) throws Exception {return new Tuple3<>(value.getField(0), value.getField(1), "temp is too high");}// 这是处理low流的方法@Overridepublic Object map2(SensorReading value) throws Exception {return new Tuple2<>(value.getTemperature(), "normal");}});objectSingleOutputStreamOperator.print();env.execute();}
}5.5. 多条流合并(union)
之前我们只能合并两条流,那我们要合并多条流呢?这里我们就需要用到union方法。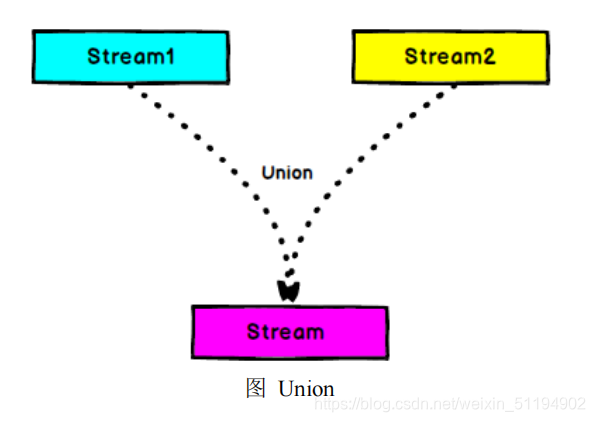
- Connect 与 Union 区别:
- Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap中再去调整成为一样的。
- Connect 只能操作两个流,Union 可以操作多个。
若我们给出以下代码:
high.union(low,all);那么high,low,all三条流都会合并在一起。
相关文章:
Flink的常用算子以及实例
1.map 特性:接收一个数据,经过处理之后,就返回一个数据 1.1. 源码分析 我们来看看map的源码 map需要接收一个MapFunction<T,R>的对象,其中泛型T表示传入的数据类型,R表示经过处理之后输出的数据类型我们继续往…...
网络安全---负载均衡案例
一、首先环境配置 1.上传文件并解压 2.进入目录下 为了方便解释,我们只用两个节点,启动之后,大家可以看到有 3 个容器(可想像成有 3 台服务器就成)。 二、使用蚁剑去连接 因为两台节点都在相同的位置存在 ant.jsp&…...
解决nginx的负载均衡下上传webshell的问题
目录 环境 问题 访问的ip会变动 执行命令的服务器未知 上传大文件损坏 深入内网 解决方案 环境 ps :现在已经拿下服务器了,要解决的是负载均衡问题, 以下是docker环境: 链接: https://pan.baidu.com/s/1cjMfyFbb50NuUtk6JNfXNQ?pwd1aqw 提…...
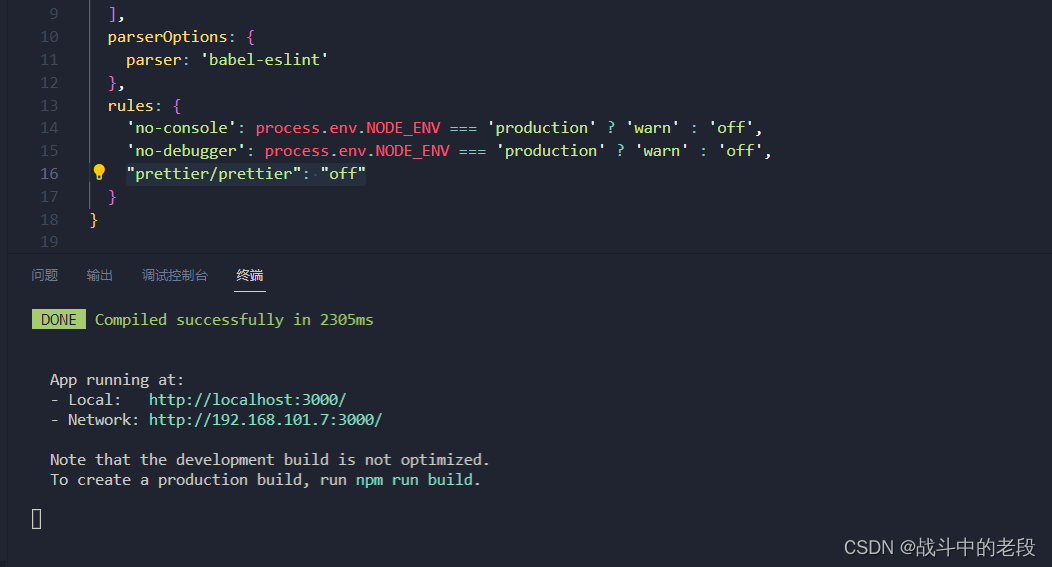
vue 关闭prettier警告warn
这个就是我们创建vue cli的时候 把这个给默认上了 关闭这个只需在.eslintrc.js页面里边添加一行代码"prettier/prettier": "off"...
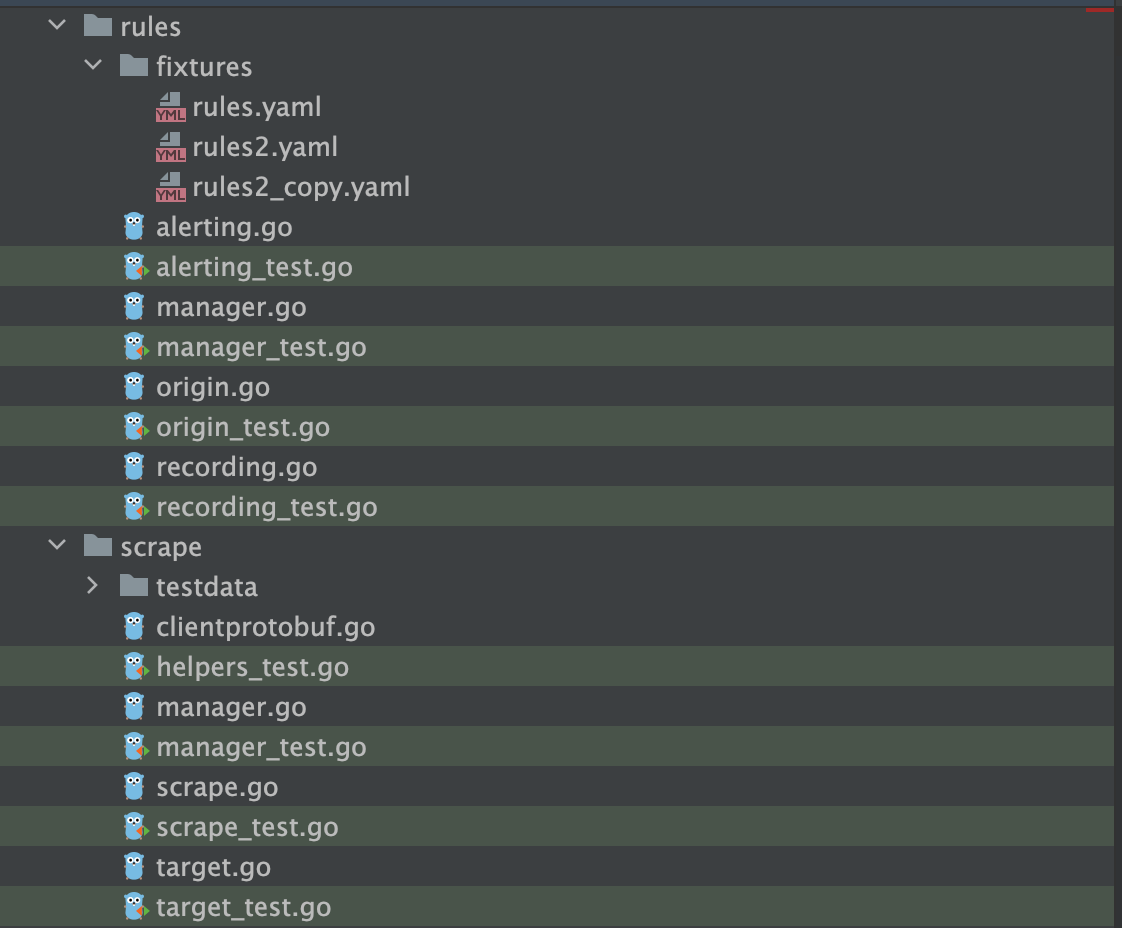
听GPT 讲Prometheus源代码--rules
Prometheus的rules目录主要包含规则引擎和管理规则的文件: engine.go 该文件定义了规则引擎的接口和主要结构,包括Rule,Record,RuleGroup等。它提供了规则的加载、匹配、评估和结果记录的功能。 api.go 定义了用于管理和查询规则的RESTful API,包括获取、添加、删除规则等方法。…...
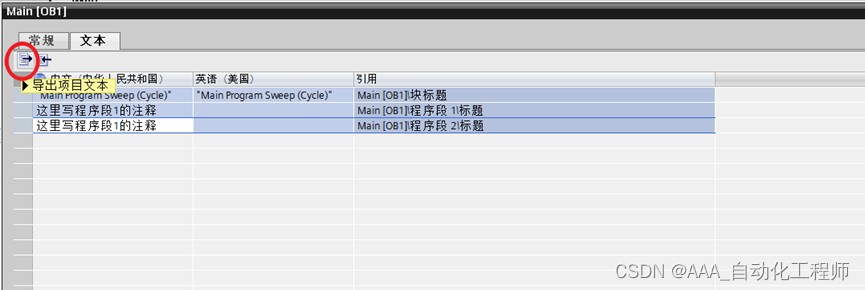
TIA博途_通过EXCEL快速给PLC程序段添加注释信息的方法示例
通过EXCEL快速给PLC程序段添加注释信息的方法示例 如下图所示,以OB1为例,正常情况下,我们可以在博途中直接输入各个程序段的注释信息, 但是如果程序段较多的话,逐个输入的话效率不高,此时可以参考下面这种通过EXCEL进行快速添加的方法。 如下图所示,选中某个OB或FC、FB块…...

【力扣】496. 下一个更大元素 I <单调栈、模拟>
【力扣】496. 下一个更大元素 I nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。给你两个没有重复元素的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。 对于每个 0 < i <…...
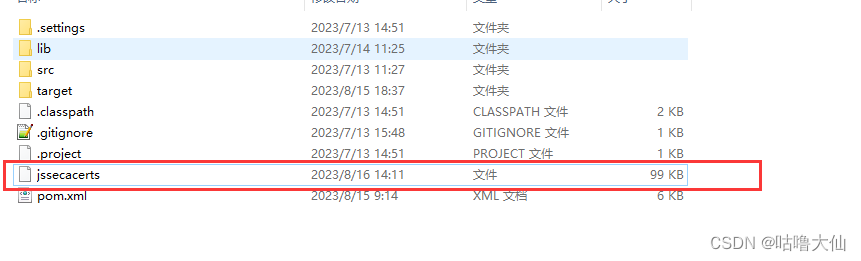
Java调用https接口添加证书
使用InstallCert.Java生成证书 /** Copyright 2006 Sun Microsystems, Inc. All Rights Reserved.** Redistribution and use in source and binary forms, with or without* modification, are permitted provided that the following conditions* are met:** - Redistri…...
C++入门:函数缺省参数与函数重载
目录 1.函数缺省参数 1.1 缺省参数概念 1.2 缺省参数分类 2.函数重载 2.1 函数重载概念 2.2 C支持函数重载的原理 1.函数缺省参数 1.1 缺省参数概念 缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实 参则采用该形参的…...

Android 场景Scene的使用
Scene 翻译过来是场景,开发者提供起始布局和结束布局,就可以实现布局之间的过渡动画。 具体可参考 使用过渡为布局变化添加动画效果 大白话,在 Activity 的各个页面之间切换,会带有过渡动画。 打个比方,使用起来类似…...
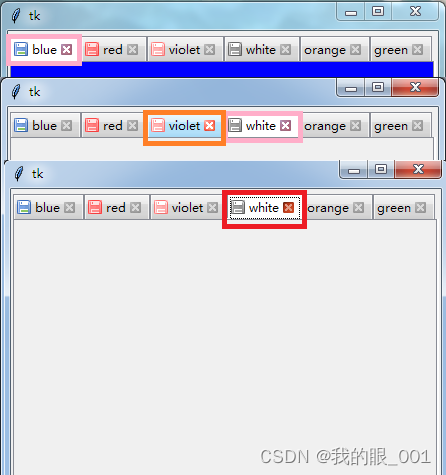
Python tkinter Notebook标签添加关闭按钮元素,及左侧添加存储状态提示图标案例,类似Notepad++页面
效果图展示 粉色框是当前页面,橙色框是鼠标经过,红色框是按下按钮,灰色按钮是其他页面的效果; 存储标识可以用来识别页面是否存储:例如当前页面已经保存用蓝色,未保存用红色,其他页面已经保存用…...
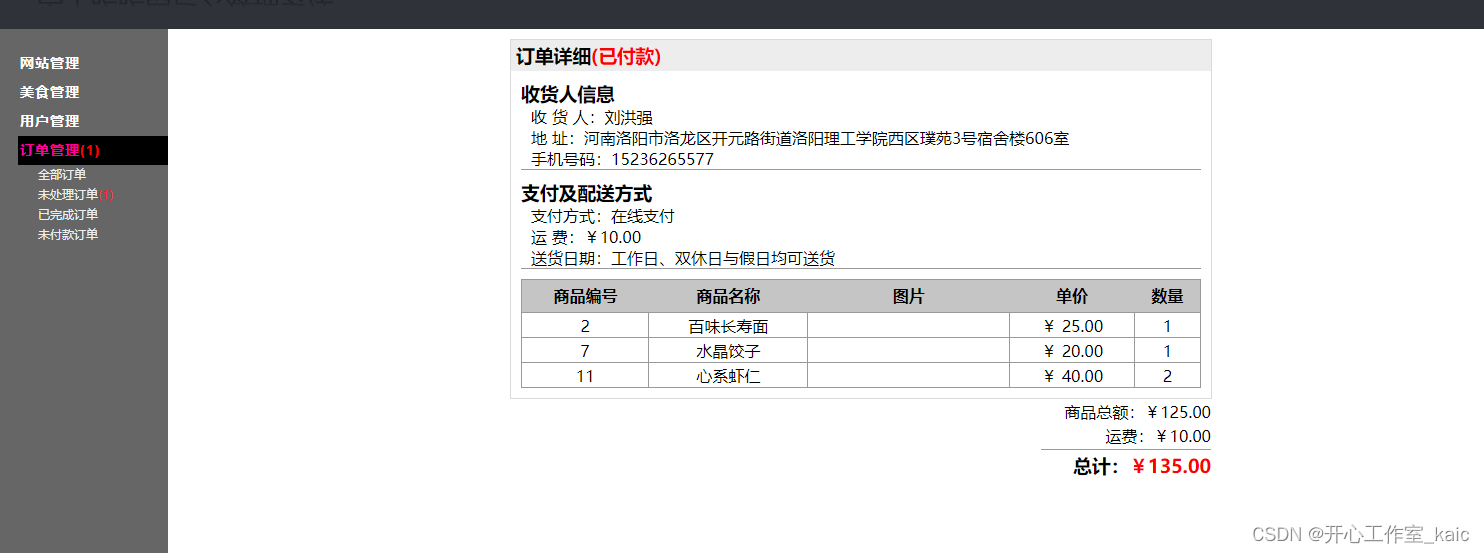
基于web网上订餐系统的设计与实现(论文+源码)_kaic
目录 1绪论 1.1课题研究背景 1.2研究现状 1.3主要内容 1.4本文结构 2网上订餐系统需求分析 2.1系统业务流程分析 2.2消费者用户业务流程分析 2.3商户业务流程分析 2.4管理员用户流程分析消费者用户用例分析 2.5系统用例分析 3网上订餐系统设计 3.1功能概述 3.2订单管理模块概要…...
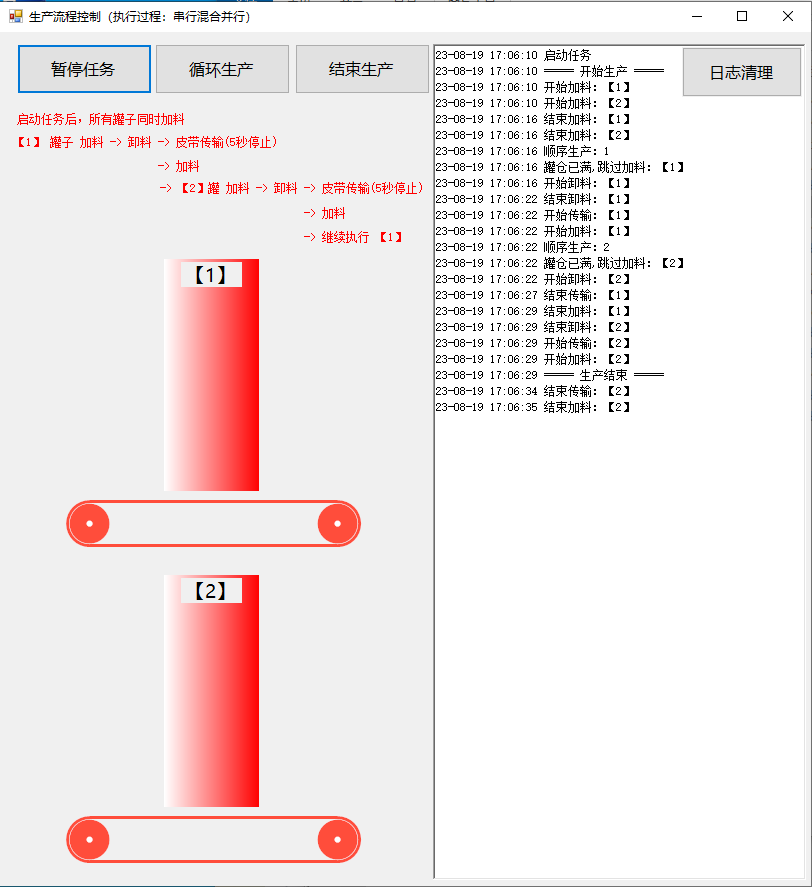
C#生产流程控制(串行,并行混合执行)
开源框架CsGo https://gitee.com/hamasm/CsGo?_fromgitee_search 文档资料: https://blog.csdn.net/aa2528877987/article/details/132139337 实现效果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37…...
【广州华锐视点】VR线上教学资源平台提供定制化虚拟现实学习内容
虚拟现实(VR)技术的出现为我们提供了一种全新的在线教学方式。由广州华锐视点开发的VR线上教学资源平台,作为一个综合性的学习工具,正在教育领域迅速发展,并被越来越多的教育机构和学生所接受。那么,VR线上…...
计算机视觉的应用11-基于pytorch框架的卷积神经网络与注意力机制对街道房屋号码的识别应用
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用11-基于pytorch框架的卷积神经网络与注意力机制对街道房屋号码的识别应用,本文我们借助PyTorch,快速构建和训练卷积神经网络(CNN)等模型,…...

正则表达式:学习使用正则表达式提取网页中的目标数据
使用正则表达式提取网页中的目标数据主要有以下几个步骤: 获取网页内容:首先,你需要使用Python的库(如requests)获取网页的HTML内容。 构建正则表达式:根据你想要提取的目标数据的特征,构建相应…...

最长重复子数组(力扣)动态规划 JAVA
给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。 示例 1: 输入:nums1 [1,2,3,2,1], nums2 [3,2,1,4,7] 输出:3 解释:长度最长的公共子数组是 [3,2,1] 。 示例 2: 输…...
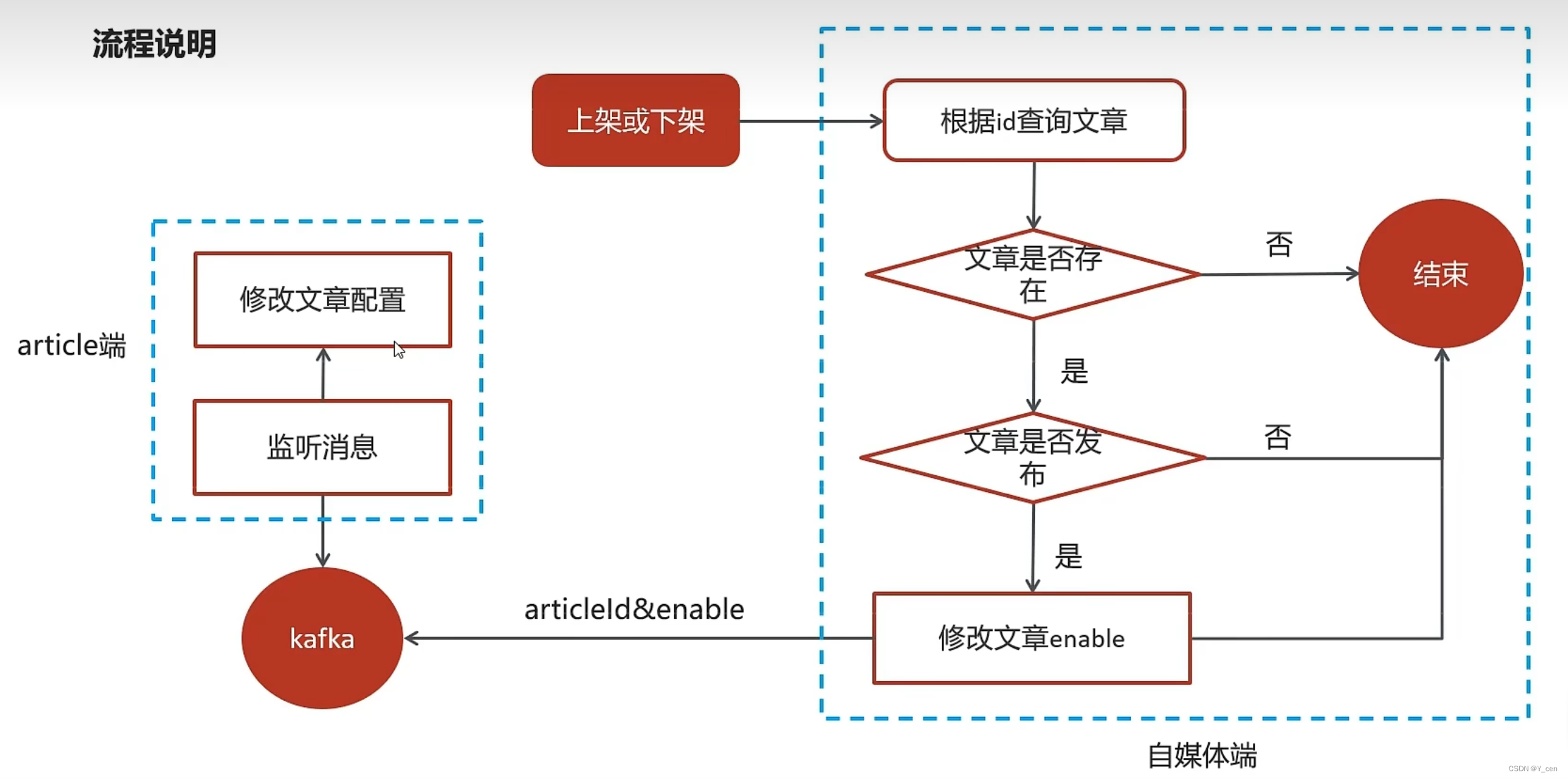
JavaWeb_LeadNews_Day6-Kafka
JavaWeb_LeadNews_Day6-Kafka Kafka概述安装配置kafka入门kafka高可用方案kafka详解生产者同步异步发送消息生产者参数配置消费者同步异步提交偏移量 SpringBoot集成kafka 自媒体文章上下架实现思路具体实现 来源Gitee Kafka 概述 对比 选择 介绍 producer: 发布消息的对象称…...

ATTCK覆盖度97.1%!360终端安全管理系统获赛可达认证
近日,国际知名第三方网络安全检测服务机构——赛可达实验室(SKD Labs)发布最新测试报告,360终端安全管理系统以ATT&CK V12框架攻击技术覆盖面377个、覆盖度97.1%,勒索病毒、挖矿病毒检出率100%,误报率0…...
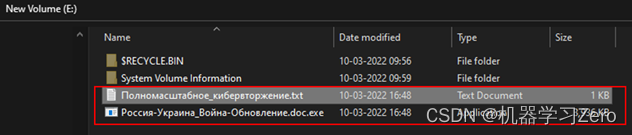
透视俄乌网络战之一:数据擦除软件
数据擦除破坏 1. WhisperGate2. HermeticWiper3. IsaacWiper4. WhisperKill5. CaddyWiper6. DoubleZero7. AcidRain8. RURansom 数据是政府、社会和企业组织运行的关键要素。数据擦除软件可以在不留任何痕迹的情况下擦除数据并阻止操作系统恢复摧,达到摧毁或目标系统…...

别再死记硬背了!我用700多页图解八股文,帮你把Java面试考点画成故事
用视觉叙事重构Java面试:700页图解背后的认知科学实践 翻开任何一本Java面试指南,你大概率会看到密密麻麻的文字罗列——"JVM内存结构分为哪几部分?""Synchronized和ReentrantLock有什么区别?"这些被称为&quo…...

用STM32 HAL库和MPU6050 DIY平衡小车:PID参数整定实战与小车‘站起来’的调试日记
STM32平衡小车PID调参实战:从剧烈抖动到稳定站立的调试手记 1. 平衡小车的核心挑战 当我第一次按下电源开关,看着这个小家伙像醉汉一样左右摇摆然后轰然倒下时,才真正理解到平衡控制的精妙之处。基于STM32和MPU6050的平衡小车项目,…...

别再死记硬背了!用MATLAB的`strel`函数玩转形态学:从结构元素选择到开闭运算除噪
别再死记硬背了!用MATLAB的strel函数玩转形态学:从结构元素选择到开闭运算除噪 在数字图像处理的学习过程中,很多初学者都会陷入一个误区:机械地记忆膨胀、腐蚀、开运算、闭运算的定义,却忽略了形态学操作中最关键的一…...

【UEFI实战】GOP协议详解:从模式查询到像素操作
1. GOP协议基础:UEFI图形显示的核心机制 第一次接触UEFI图形编程时,我被屏幕上突然出现的红色进度条震撼到了——原来在系统启动的早期阶段就能实现图形化显示。这背后的关键就是EFI_GRAPHICS_OUTPUT_PROTOCOL(简称GOP)࿰…...

9.5%复合增长率强势领航!2025年全球甲酸真空回流焊炉市场规模1.2亿美元,2032年剑指2.24亿,高增长动能全面释放
QYResearch调研显示,2025年全球甲酸真空回流焊炉市场规模大约为1.2亿美元,预计2032年将达到2.24亿美元,2026-2032期间年复合增长率(CAGR)为9.5%。结合QYResearch数据及行业深耕经验,当前甲酸真空回流焊炉行…...

【NotebookLM考古学研究辅助实战指南】:20年文博技术专家亲授3大冷启动技巧,让田野笔记秒变学术论文
更多请点击: https://intelliparadigm.com 第一章:NotebookLM考古学研究辅助的范式革命 NotebookLM 作为 Google 推出的基于文档理解的 AI 助手,正悄然重塑考古学研究的信息处理范式。传统考古工作依赖大量手写笔记、田野报告、碳十四测年数…...

RT-Thread中断管理实战:从Cortex-M硬件机制到线程通信
1. 项目概述:从内核到中断,RT-Thread的实战拼图搞嵌入式开发,尤其是用RTOS,中断处理是绕不开的一道坎。之前我们聊RT-Thread的线程、IPC、内存管理,都是在“太平盛世”下进行的,线程们按部就班地运行、等待…...

3分钟让你的Obsidian代码块告别混乱:专业开发者的笔记美化秘籍
3分钟让你的Obsidian代码块告别混乱:专业开发者的笔记美化秘籍 【免费下载链接】obsidian-better-codeblock Add title, line number to Obsidian code block 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-better-codeblock 还在为Obsidian中密密麻…...

视觉暂留与嵌入式编程:打造动态LED光影艺术装置
1. 项目概述:当LED阵列在空中“作画”如果你见过夜晚挥舞的LED光剑在空中留下绚烂的图案,或者火舞者手中的Poi(火球)划出复杂的光轨,那么你已经亲眼目睹了动态成像(Kinetic Persistence of Vision, Kinetic…...

从赛博朋克到量子有机体,未来主义风格演进全图谱,深度解析MJ 5.2→6.2→NijiV6的渲染范式跃迁
更多请点击: https://intelliparadigm.com 第一章:赛博朋克到量子有机体:未来主义视觉范式的哲学跃迁 当霓虹雨巷中的义体少女凝视全息广告牌,她瞳孔倒映的已不仅是资本编码的欲望图景,而是意识与拓扑量子态耦合的初始…...