前馈神经网络dropout实例
直接看代码。
(一)手动实现
import torch
import torch.nn as nn
import numpy as np
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt#下载MNIST手写数据集
mnist_train = torchvision.datasets.MNIST(root='./MNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./MNIST', train=False,download=True, transform=transforms.ToTensor()) #读取数据
batch_size = 256
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True,num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False,num_workers=0) #初始化参数
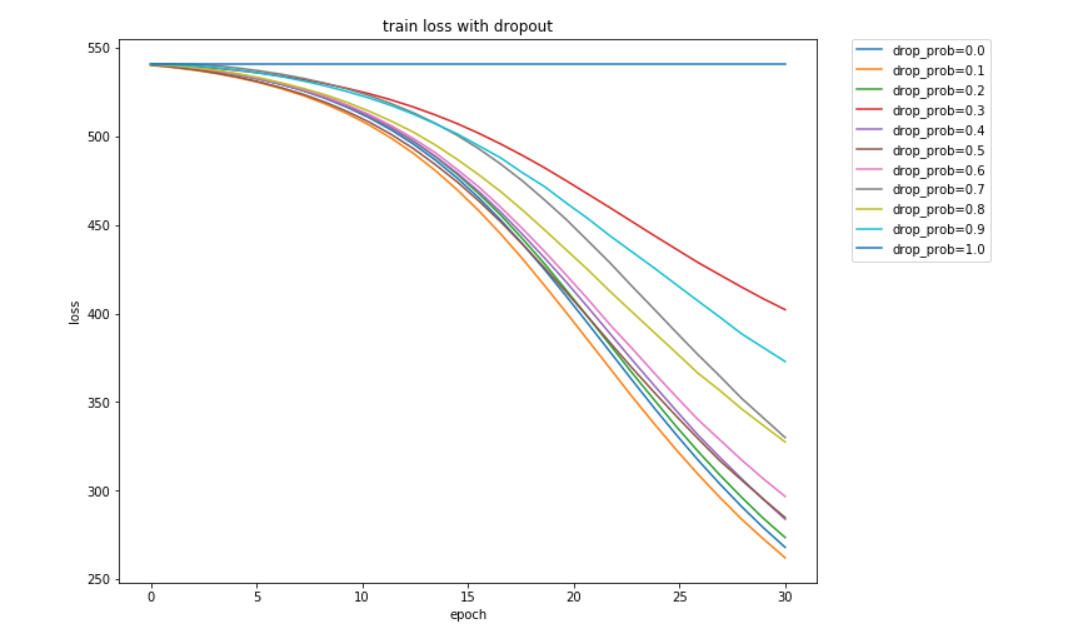
num_inputs,num_hiddens,num_outputs =784, 256,10num_epochs=30lr = 0.001def init_param():W1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens,num_inputs)), dtype=torch.float32) b1 = torch.zeros(1, dtype=torch.float32) W2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs,num_hiddens)), dtype=torch.float32) b2 = torch.zeros(1, dtype=torch.float32) params =[W1,b1,W2,b2]for param in params: param.requires_grad_(requires_grad=True) return W1,b1,W2,b2def dropout(X, drop_prob):X = X.float()assert 0 <= drop_prob <= 1keep_prob = 1 - drop_probif keep_prob == 0:return torch.zeros_like(X)mask = (torch.rand(X.shape) < keep_prob).float()print(mask)return mask * X / keep_probdef net(X, is_training=True):X = X.view(-1, num_inputs)H1 = (torch.matmul(X, W1.t()) + b1).relu()if is_training:H1 = dropout(H1, drop_prob)return (torch.matmul(H1,W2.t()) + b2).relu()def train(net,train_iter,test_iter,loss,num_epochs,batch_size,lr=None,optimizer=None):train_ls, test_ls = [], []for epoch in range(num_epochs):ls, count = 0, 0for X,y in train_iter:l=loss(net(X),y)optimizer.zero_grad()l.backward()optimizer.step()ls += l.item()count += y.shape[0]train_ls.append(ls)ls, count = 0, 0for X,y in test_iter:l=loss(net(X,is_training=False),y)ls += l.item()count += y.shape[0]test_ls.append(ls)if(epoch+1)%10==0:print('epoch: %d, train loss: %f, test loss: %f'%(epoch+1,train_ls[-1],test_ls[-1]))return train_ls,test_lsdrop_probs = np.arange(0,1.1,0.1)Train_ls, Test_ls = [], []for drop_prob in drop_probs:W1,b1,W2,b2 = init_param()loss = nn.CrossEntropyLoss()optimizer = torch.optim.SGD([W1,b1,W2,b2],lr = 0.001)train_ls, test_ls = train(net,train_iter,test_iter,loss,num_epochs,batch_size,lr,optimizer) Train_ls.append(train_ls)Test_ls.append(test_ls)x = np.linspace(0,len(train_ls),len(train_ls))plt.figure(figsize=(10,8))for i in range(0,len(drop_probs)):plt.plot(x,Train_ls[i],label= 'drop_prob=%.1f'%(drop_probs[i]),linewidth=1.5)plt.xlabel('epoch')plt.ylabel('loss')# plt.legend()
plt.legend(loc=2, bbox_to_anchor=(1.05,1.0),borderaxespad = 0.)
plt.title('train loss with dropout')
plt.show()运行结果:
(二)torch.nn实现
import torch
import torch.nn as nn
import numpy as np
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as pltmnist_train = torchvision.datasets.MNIST(root='./MNIST', train=True, download=True, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.MNIST(root='./MNIST', train=False,download=True, transform=transforms.ToTensor())
batch_size = 256
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True,num_workers=0)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False,num_workers=0) class LinearNet(nn.Module):def __init__(self,num_inputs, num_outputs, num_hiddens1, num_hiddens2, drop_prob1,drop_prob2):super(LinearNet,self).__init__()self.linear1 = nn.Linear(num_inputs,num_hiddens1)self.relu = nn.ReLU()self.drop1 = nn.Dropout(drop_prob1)self.linear2 = nn.Linear(num_hiddens1,num_hiddens2)self.drop2 = nn.Dropout(drop_prob2)self.linear3 = nn.Linear(num_hiddens2,num_outputs)self.flatten = nn.Flatten()def forward(self,x):x = self.flatten(x)x = self.linear1(x)x = self.relu(x)x = self.drop1(x)x = self.linear2(x)x = self.relu(x)x = self.drop2(x)x = self.linear3(x)y = self.relu(x)return ydef train(net,train_iter,test_iter,loss,num_epochs,batch_size,params=None,lr=None,optimizer=None):train_ls, test_ls = [], []for epoch in range(num_epochs):ls, count = 0, 0for X,y in train_iter:l=loss(net(X),y)optimizer.zero_grad()l.backward()optimizer.step()ls += l.item()count += y.shape[0]train_ls.append(ls)ls, count = 0, 0for X,y in test_iter:l=loss(net(X),y)ls += l.item()count += y.shape[0]test_ls.append(ls)if(epoch+1)%5==0:print('epoch: %d, train loss: %f, test loss: %f'%(epoch+1,train_ls[-1],test_ls[-1]))return train_ls,test_ls num_inputs,num_hiddens1,num_hiddens2,num_outputs =784, 256,256,10
num_epochs=20
lr = 0.001
drop_probs = np.arange(0,1.1,0.1)
Train_ls, Test_ls = [], []for drop_prob in drop_probs:net = LinearNet(num_inputs, num_outputs, num_hiddens1, num_hiddens2, drop_prob,drop_prob)for param in net.parameters():nn.init.normal_(param,mean=0, std= 0.01)loss = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(),lr)train_ls, test_ls = train(net,train_iter,test_iter,loss,num_epochs,batch_size,net.parameters,lr,optimizer)Train_ls.append(train_ls)Test_ls.append(test_ls)x = np.linspace(0,len(train_ls),len(train_ls))
plt.figure(figsize=(10,8))
for i in range(0,len(drop_probs)):plt.plot(x,Train_ls[i],label= 'drop_prob=%.1f'%(drop_probs[i]),linewidth=1.5)plt.xlabel('epoch')plt.ylabel('loss')
plt.legend(loc=2, bbox_to_anchor=(1.05,1.0),borderaxespad = 0.)
plt.title('train loss with dropout')
plt.show()input = torch.randn(2, 5, 5)
m = nn.Sequential(
nn.Flatten()
)
output = m(input)
output.size()
运行结果:
关于dropout的原理,网上资料很多,一般都是用一个正态分布的矩阵,比较矩阵元素和(1-dropout),大于(1-dropout)的矩阵元素值的修正为1,小于(1-dropout)的改为1,将输入的值乘以修改后的矩阵,再除以(1-dropout)。
疑问:
- 数值经过正态分布矩阵的筛选后,还要除以 (1-dropout),这样做的原因是什么?
- Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。
相关文章:
前馈神经网络dropout实例
直接看代码。 (一)手动实现 import torch import torch.nn as nn import numpy as np import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt#下载MNIST手写数据集 mnist_train torchvision.datasets.MN…...
Android DataStore:安全存储和轻松管理数据
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、使用3.1 Preferences DataStore添加依赖数据读…...

opencv进阶12-EigenFaces 人脸识别
EigenFaces 通常也被称为 特征脸,它使用主成分分析(Principal Component Analysis,PCA) 方法将高维的人脸数据处理为低维数据后(降维),再进行数据分析和处理,获取识别结果。 基本原理…...

The internal rate of return (IRR)
内部收益率 NPV(Net Present Value)_spencer_tseng的博客-CSDN博客...

半导体自动化专用静电消除器主要由哪些部分组成
半导体自动化专用静电消除器是一种用于消除半导体生产过程中的静电问题的设备。由于半导体制造过程中对静电的敏感性,静电可能会对半导体器件的质量和可靠性产生很大的影响,甚至造成元件损坏。因此,半导体生产中采用专用的静电消除器是非常重…...

【C++入门到精通】C++入门 —— deque(STL)
阅读导航 前言一、deque简介1. 概念2. 特点 二、deque使用1. 基本操作(增、删、查、改)2. 底层结构 三、deque的缺陷四、 为什么选择deque作为stack和queue的底层默认容器总结温馨提示 前言 文章绑定了VS平台下std::deque的源码,大家可以下载…...

Codeforces Round 893 (Div. 2) D.Trees and Segments
原题链接:Problem - D - Codeforces 题面: 大概意思就是让你在翻转01串不超过k次的情况下,使得a*(0的最大连续长度)(1的最大连续长度)最大(1<a<n)。输出n个数&…...
SpringBoot + Vue 前后端分离项目 微人事(九)
职位管理后端接口设计 在controller包里面新建system包,再在system包里面新建basic包,再在basic包里面创建PositionController类,在定义PositionController类的接口的时候,一定要与数据库的menu中的url地址到一致,不然…...

【业务功能篇71】Cglib的BeanCopier进行Bean对象拷贝
选择Cglib的BeanCopier进行Bean拷贝的理由是, 其性能要比Spring的BeanUtils,Apache的BeanUtils和PropertyUtils要好很多, 尤其是数据量比较大的情况下。 BeanCopier的主要作用是将数据库层面的Entity转化成service层的POJO。BeanCopier其实已…...
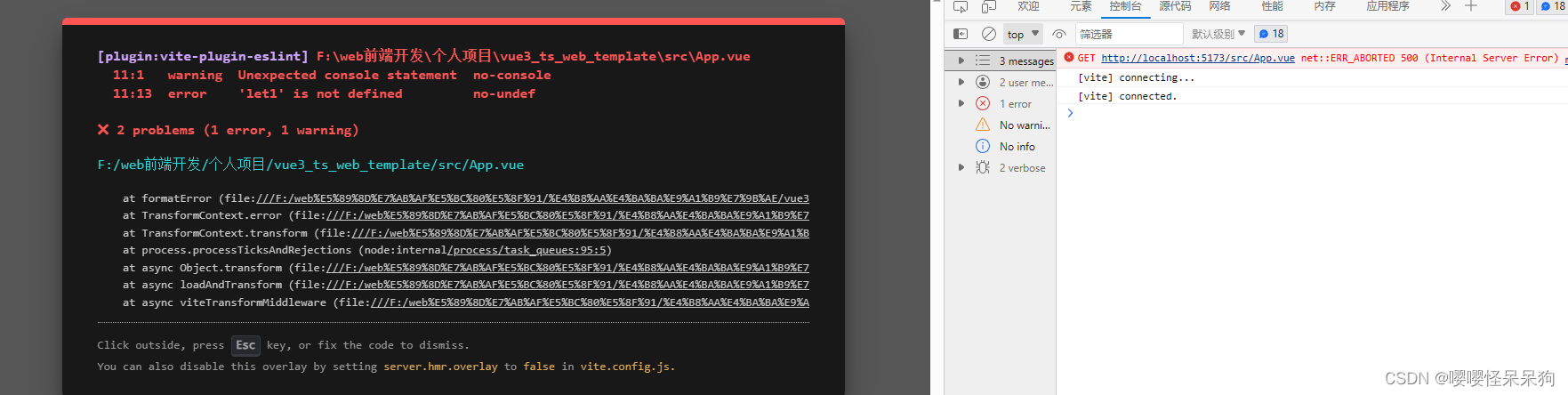
让eslint的错误信息显示在项目界面上
1.需求描述 效果如下 让eslint中的错误,显示在项目界面上 2.问题解决 1.安装 vite-plugin-eslint 插件 npm install vite-plugin-eslint --save-dev2.配置插件 // vite.config.js import { defineConfig } from vite import vue from vitejs/plugin-vue import e…...
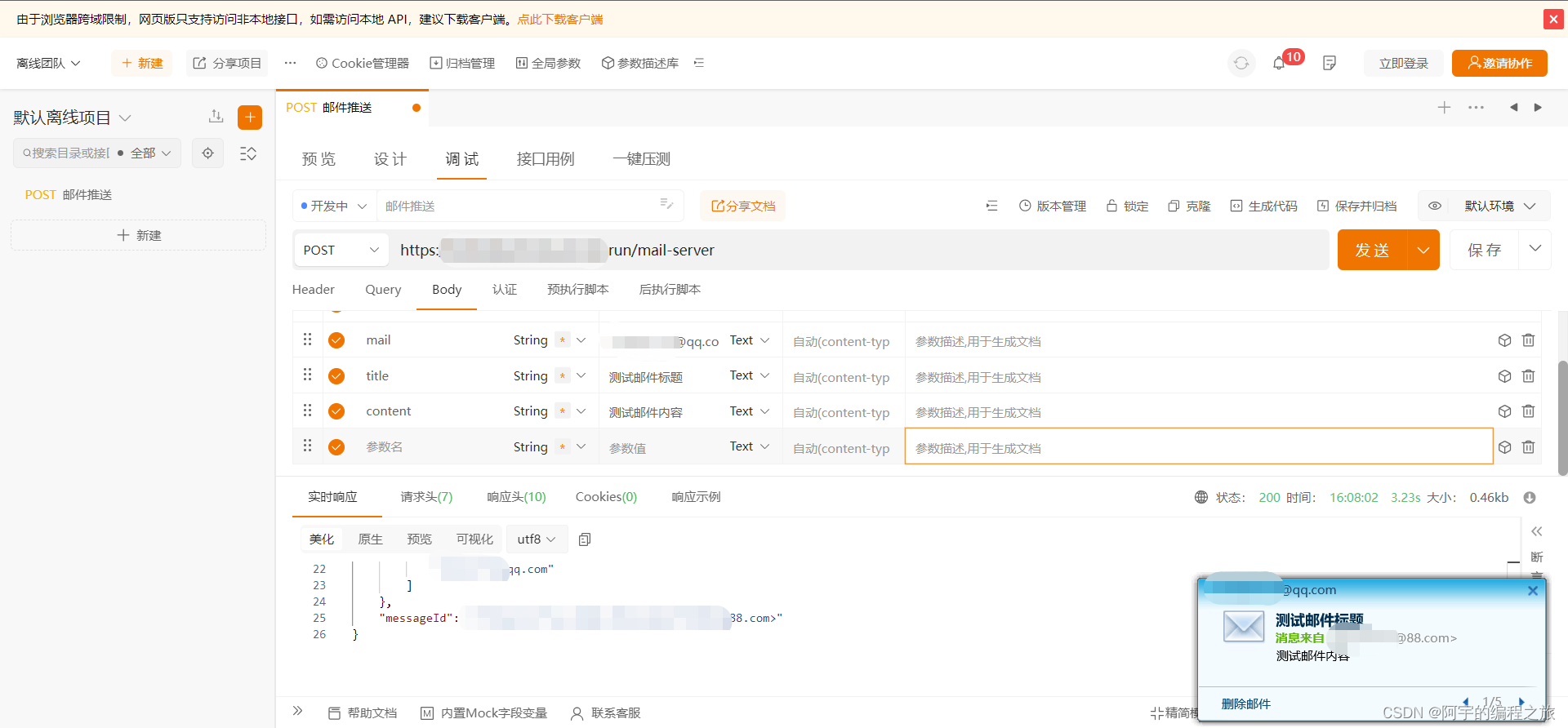
手摸手带你实现一个开箱即用的Node邮件推送服务
目录 编辑 前言 准备工作 邮箱配置 代码实现 服务部署 使用效果 题外话 写在最后 相关代码: 前言 由于邮箱账号和手机号的唯一性,通常实现验证码的校验时比较常用的两种方式是手机短信推送和邮箱推送,此外,邮件推送服…...

【Linux网络】网络编程套接字 -- 基于socket实现一个简单UDP网络程序
认识端口号网络字节序处理字节序函数 htonl、htons、ntohl、ntohs socketsocket编程接口sockaddr结构结尾实现UDP程序的socket接口使用解析socket处理 IP 地址的函数初始化sockaddr_inbindrecvfromsendto 实现一个简单的UDP网络程序封装服务器相关代码封装客户端相关代码实验结…...
)
Python学习笔记第六十四天(Matplotlib 网格线)
Python学习笔记第六十四天 Matplotlib 网格线普通网格线样式网格线 后记 Matplotlib 网格线 我们可以使用 pyplot 中的 grid() 方法来设置图表中的网格线。 grid() 方法语法格式如下: matplotlib.pyplot.grid(bNone, whichmajor, axisboth, )参数说明:…...
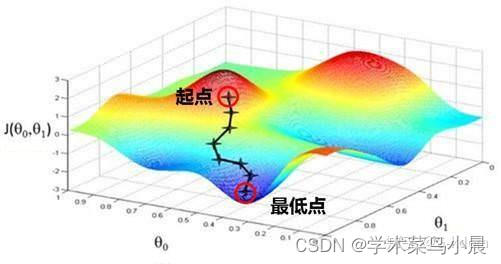
机器学习与模式识别3(线性回归与逻辑回归)
一、线性回归与逻辑回归简介 线性回归主要功能是拟合数据,常用平方误差函数。 逻辑回归主要功能是区分数据,找到决策边界,常用交叉熵。 二、线性回归与逻辑回归的实现 1.线性回归 利用回归方程对一个或多个特征值和目标值之间的关系进行建模…...
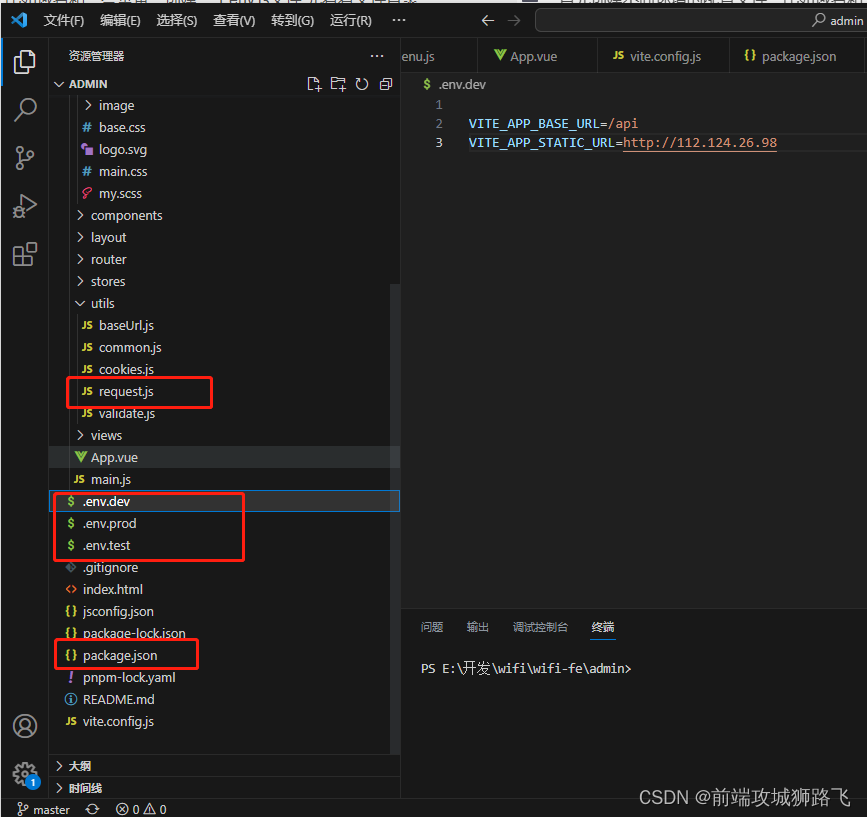
vue启动配置npm run serve,动态环境变量,根据不同环境访问不同域名
首先创建不同环境的配置文件,比如域名和一些常量,创建一个env文件,先看看文件目录 env.dev就是dev环境的域名,.test就是test环境域名,其他同理,然后配置package.json文件 {"name": "require-admin&qu…...

HTML <strike> 标签
HTML5 中不支持 <strike> 标签在 HTML 4 中用于定义删除线文本。 定义和用法 <strike> 标签可定义加删除线文本定义。 浏览器支持 元素ChromeIEFirefoxSafariOpera<strike>YesYesYesYesYes 所有浏览器都支持 <strike> 标签。 HTML 与 XHTML 之间…...
)
数学建模-模型详解(1)
规划模型 线性规划模型: 当涉及到线性规划模型实例时,以下是一个简单的示例: 假设我们有两个变量 x 和 y,并且我们希望最大化目标函数 Z 5x 3y,同时满足以下约束条件: x > 0y > 02x y < 10…...

MySQL 数据库表的基本操作
一、数据库表概述 在数据库中,数据表是数据库中最重要、最基本的操作对象,是数据存储的基本单位。数据表被定义为列的集合,数据在表中是按照行和列的格式来存储的。每一行代表一条唯一的记录,每一列代表记录中的一个域。 二、数…...
企业微信电脑端开启chrome调试
首先: Mac端调试开启的快捷键:control shift command d Window端调试开启的快捷键: control shift alt d 这边以Mac为例,我们可以在电脑顶部看到调试的入口: 然后我们点击 『浏览器、webView相关』菜单,勾选上…...
Maven官网下载配置新仓库
1.Maven的下载 Maven的官网地址:Maven – Download Apache Maven 点击Download,查找 Files下的版本并下载如下图: 2.Maven的配置 自己在D盘或者E盘创建一个文件夹,作为本地仓库,存放项目依赖。 将下载好的zip文件进行解…...

SuperMap GIS集成天地图服务:从协议解析到多端应用实战
1. 天地图服务与SuperMap GIS集成基础 第一次接触天地图服务集成时,我被各种参数和协议搞得晕头转向。后来在智慧城市项目中反复实践才发现,理解这些基础概念就像学做菜要先认识调料一样重要。 天地图服务主要分为国家版和地方版两种。国家天地图采用449…...

从FLAG_ONE_SHOT到FLAG_IMMUTABLE:深入解析Android S+版本PendingIntent的强制变革
1. 当PendingIntent遇上Android S:崩溃背后的安全升级 最近不少开发者在升级targetSdkVersion到31(Android 12)后,突然遭遇这样的崩溃提示:"Targeting S requires that one of FLAG_IMMUTABLE or FLAG_MUTABLE be…...

Cortex-R52处理器不可预测行为解析与安全设计
1. Cortex-R52处理器不可预测行为深度解析在嵌入式实时系统开发领域,处理器行为的确定性直接关系到系统的可靠性。Arm Cortex-R52作为面向功能安全应用的实时处理器,其对架构规范中"不可预测行为(UNPREDICTABLE Behaviors)"的实现方式颇具特色…...

VMware Unlocker 3.0:5分钟快速配置macOS虚拟机终极指南
VMware Unlocker 3.0:5分钟快速配置macOS虚拟机终极指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker VMware Unlocker 3.0是一款专为破解VMware限制而设计的开源工具,让您能在…...

基于OpenAI API与社交平台集成的智能聊天机器人构建指南
1. 项目概述:一个整合社交与AI的自动化工具箱最近在GitHub上看到一个挺有意思的项目,叫“Whatsapp_Instagram_Messanger_ChatGPT_OpenAI”。光看这个标题,你大概就能猜到它的野心不小——它试图把WhatsApp、Instagram、Messenger这几个主流社…...

尤克里里的前世今生:这把“跳蚤小吉他”,凭什么火遍全世界?
提到尤克里里,大家脑海里瞬间浮现的,一定是阳光、沙滩、草裙舞、海风与欢快旋律的画面!这把小小的四弦乐器,颜值清新、音色治愈,上手零门槛,不管是小朋友启蒙、成年人解压,还是旅行随手弹&#…...
)
面试记录 (2026/5/12)
问题一:java并发包下的AQS,了解多少? 这个真是没看过源码,就不班门弄斧了 直接学习下 大佬的经验 https://blog.csdn.net/qq_45772447/article/details/149126295?fromshareblogdetail&sharetypeblogdetail&sharerId149126295&…...

STM32F103 IAP实战:从Bootloader设计到远程固件更新
1. 为什么你的STM32需要IAP升级? 第一次接触IAP(In-Application Programming)这个概念时,我正蹲在工厂车间的设备旁边,手里拿着需要升级的STM32板子发愁。产线上30台设备需要更新程序,而每台设备都要拆外壳…...

LLM长文本处理实战:模块化分割策略与向量化预处理指南
1. 项目概述:一个为LLM打造的文本处理中心如果你和我一样,经常和大型语言模型打交道,无论是用它来总结文档、分析代码,还是处理客服对话,那你肯定遇到过这个痛点:喂给模型的文本太长了怎么办?模…...

从零构建ESP32+ILI9341触摸屏LVGL交互界面实战
1. 硬件选型与连接指南 第一次接触ESP32和ILI9341触摸屏时,最让我头疼的就是如何正确选择硬件并完成连接。经过多次实践,我总结出一套适合新手的硬件配置方案。ESP32开发板建议选择带有USB转串口芯片的版本,比如ESP32-DevKitC,这样…...