Elasticsearch的安装及常用操作
文章目录
- 一、Elasticsearch的介绍
- 1、Elasticsearch索引
- 2、Elasticsearch的介绍
- 二、Elasticsearch的安装
- 1、安装ES服务
- 2、安装kibana
- 3、Docker安装ES
- 4、Docker安装Kibana
- 三、ES的常用操作
- 1、索引操作
- 2、文档操作
- 3、域的属性
- 3.1 index
- 3.2 type
- 3.3 store
- 总结
一、Elasticsearch的介绍
1、Elasticsearch索引
- Elasticsearch是一个全文检索服务器,全文检索是一种非结构化数据的搜索方式。
结构化数据:指具有固定长度的数据,如数据库中的字段。
非结构化数据:指格式和长度不固定的数据。
结构化数据一般存入数据库,使用sql语句即可快速查询。但由于非结构化数据量大且格式不固定,需要采用全文检索的方式进行搜索。全文检索通过建立倒排索引加快搜索效率。 - 索引:将数据中的一部分信息提取出来,重新组织成一定的数据结构,可以根据该结构进行快速搜索,这样的结构称之为索引。索引分为正排索引和倒排索引。
正排索引(正向索引):将文档id建立为索引,通过id可以快速查找数据。如数据库的主键就是创建的正排索引。
倒排索引(反向索引):非结构化数据中往往会根据关键词查询数据。此时将数据中的关键词建立为索引,指向文档数据,这样的数据称为倒排索引。
2、Elasticsearch的介绍
- Elasticsearch是基于Lucene开发的项目;本质是一个Java语言开发的web项目。 可以通过RESTful风格的接口访问该项目内部的Lucene,从而让全文搜索变得简单。ES内部包含了Lucene。
- Elasticsearch自身带有分布式协调管理功能;solr利用zookeeper进行分布式管理。
Elasticsearch仅支持json文件格式;solr支持很多格式的数据。
Elasticsearch本身更注重于核心功能,高级功能多由第三方插件提供;solr官方提供的功能更多。
solr在传统的搜索应用中表现好于Elasticsearch,但在处理实时搜索应用时(即边添加边搜索)效率明显低于Elasticsearch。
目前ES市场占有率越来越高,solr已经停止维护。 - 文档(Document):是可被查询的最小数据单元,一个文档就是一条数据。类似于关系型数据库中的记录的概念。
类型(Type):具有一组共同字段的文档定义成一个类型,类似于关系型数据库中的数据表的概念。
索引(Index):是多种类型文档的集合,类似于关系型数据库中库的概念。
域(Field):文档由多个域组成,类似于关系型数据库中的字段的概念。
ES7.X之后删除了Type的概念,一个索引不会代表一个库,而是代表一张表。
即原本对应表概念的Type没有了,使用Index代替对应表概念,同时删除了ES中相当于关系型数据库的库的概念。
二、Elasticsearch的安装
1、安装ES服务
- 准备一个CentOS7系统的虚拟机,使用MobaX终端连接虚拟机。
- 关闭防火墙:
systemctl stop firewalld.service
禁止防火墙自启动:systemctl disable firewalld.service - 配置最大可创建文件数大小
1)打开系统文件:vim /etc/sysctl.conf
2)添加一下配置:vm.max_map_count=655360,保存退出
3)在命令行使配置生效:sysctl -p - 因为ES不能以root用户运行,需要创建一个非root用户es:
useradd es - 在官网下载linux的Elasticsearch压缩包:
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.1-linux-x86_64.tar.gz - 通过mobax上传到目录/中,然后解压缩:
tar -zxvf elasticsearch-8.6.1-linux-x86_64.tar.gz - 重命名ES文件:
mv elasticsearch-8.6.1 elasticsearch - 将ES文件移动到目录/usr/local/中:
mv elasticsearch /usr/local/ - 让es用户取得该文件夹权限:
chown -R es:es /usr/local/elasticsearch - 切换为es用户:
su es - 找到/usr/local/elasticsearch/config/目录下面的elasticsearch.yml配置文件,把安全认证开关从原先的true都改成false,即可实现免密登录访问
- 进入到目录/usr/local/elasticsearch/bin:
cd /usr/local/elasticsearch/bin - 启动es服务:
./elasticsearch - 新开一个窗口查询es服务是否启动成功:
curl 127.0.0.1:9200,此时{}内有数据,即非Empty时证明启动成功
2、安装kibana
- 在Elasticsearch官网下载linux版的kibana:
https://artifacts.elastic.co/downloads/kibana/kibana-8.6.1-linux-x86_64.tar.gz - 在目录/中上传该压缩包,然后在目录/下解压缩到目录/usr/local/中:
tar -zxvf kibana-8.6.1-linux-x86_64.tar.gz -C /usr/local/ - 修改配置文件
1)进入到config目录下:cd /usr/local/kibana-8.6.1/config
2)修改配置文件:vim kibana.yml
3)添加kibana主机ip:server.host: "192.168.126.24"
添加Elasticsearch路径:elasticsearch.hosts: ["http://127.0.0.1:9200"] - 给es用户设置kibana目录权限:
chown -R es:es /usr/local/kibana-8.6.1/ - 切换到es用户:
su es - 进入到kibana的bin目录:
cd /usr/local/kibana-8.6.1/bin/ - 确保启动Elasticsearch后,再启动kibana:
./kibana - 在浏览器中访问kibana:
http://192.168.126.24:5601/
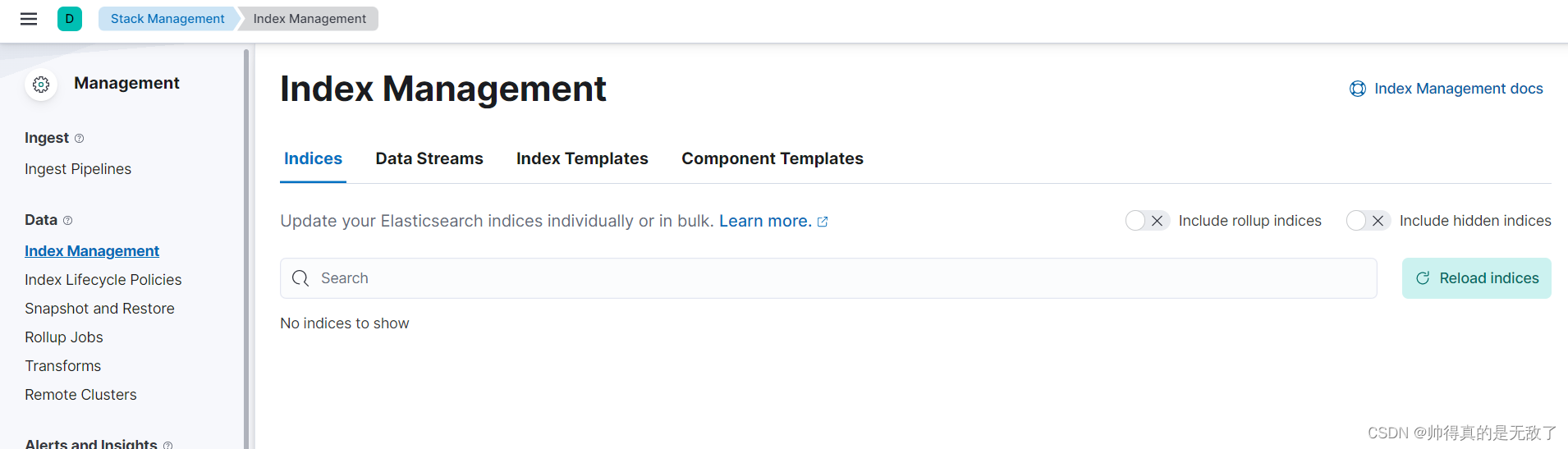
如果google浏览器版本太低的话是访问不到这个页面的 - 在kibana页面中选择Management,再选择Index Management,即可查看Elasticsearch索引信息
3、Docker安装ES
- 安装docker:
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
重复了2次命令,第一次显示获取密钥失败,第二次才安装成功 - 启动docker :
systemctl start docker - 拉取ES镜像:
docker pull elasticsearch:8.6.1 - docker容器间建立通信:
docker network create elastic - 创建ES容器:
docker run --restart=always -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" --name='elasticsearch' --net elastic --cpuset-cpus="1" -m 1G -d elasticsearch:8.6.1
参数:
-p:第一个-p是外部访问时的端口号,第二个-p是ES集群内部通信的端口号
-e:第一个-e是指ES是单节点的,第二个-e是指该ES在JAVA中占用的内存为固定内存512M
–name:指该容量的名字
–net:指使用的网关
–cpuset-cpus:指使用多少个cpu
-m:占用的内存
-d:指被使用的镜像名字 - 修改配置文件(设置免密码登录)
1)将ES容器中的elasticsearch.yml拷贝到当前目录下:docker cp elasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml .
因为相对路径显示找不到文件,此时用的是绝对路径
2)修改yml文件:vim elasticsearch.yml,将所有的true改为false即可
3)将修改后的配置文件拷贝回容器中:docker cp elasticsearch.yml elasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml
4)重启elasticsearch容器:docker restart elasticsearch
4、Docker安装Kibana
- 拉取kibana镜像:
docker pull kibana:8.6.1 - 启动容器:
docker run --name kibana --net elastic --link elasticsearch:elasticsearch -p 5601:5601 -d kibana:8.6.1 - 在浏览器中访问kibana:
192.168.126.24:5601
三、ES的常用操作
1、索引操作
Elasticsearch是使用RESTful风格的http请求访问操作的,请求参数和返回值都是json格式,可以使用kibana发送http请求操作ES。
1)选择Management下的DevTools,即可通过kibana来操作ES
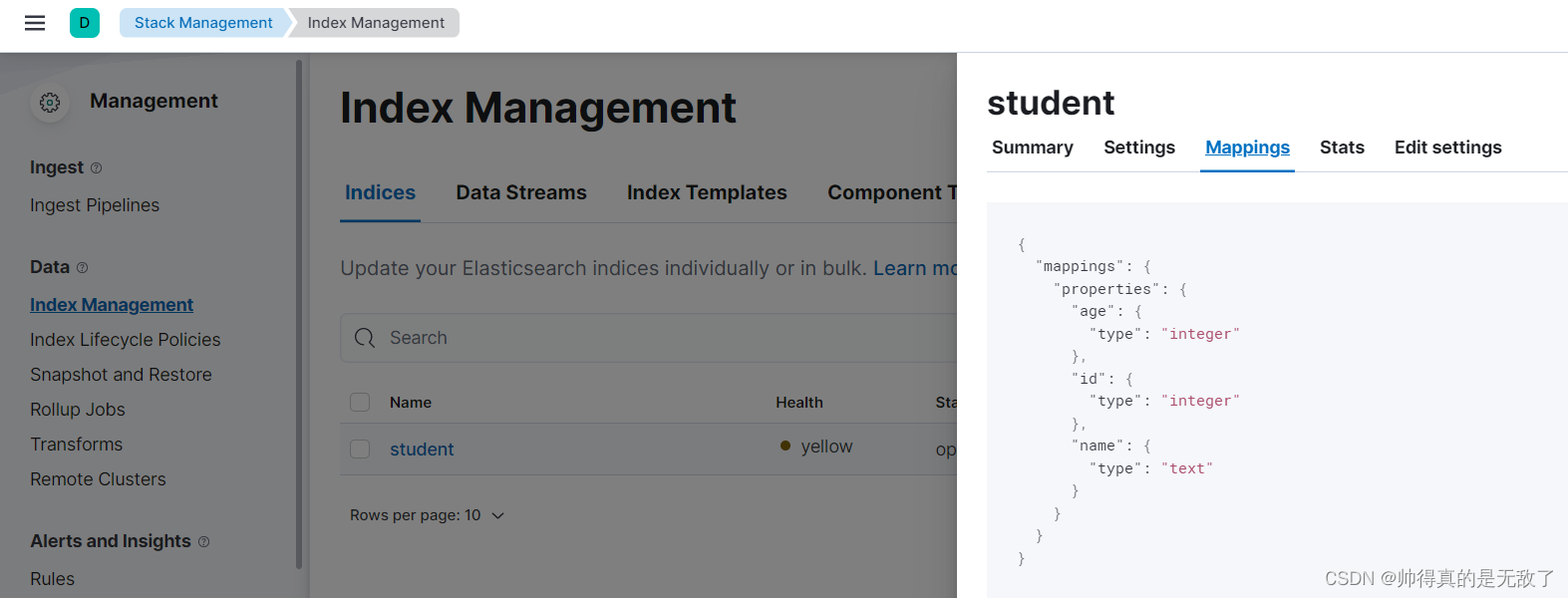
2)在IndexManagement中查看索引
-
创建索引,在kibana中输入下面内容并运行,即可创建student索引
PUT /student {"mappings": {"properties": {"id": {"type": "integer"},"name": {"type": "text"},"age": {"type": "integer"}}} }即创建student索引并添加索引的结构
-
删除索引,在kibana中输入下面内容并运行,即可删除student索引
DELETE /student
2、文档操作
-
新增或修改文档
POST /student/_doc/1 {"id":1,"name":"zzx","age":10}此时文档id设置为1,如果不写id则自动生成文档id,id和已有id重复时修改文档
-
根据文档id查询文档
GET /student/_doc/1 -
根据id删除文档
DELETE /student/_doc/1 -
根据id批量查询文档
GET /student/_mget {"docs":[{"_id":1},{"_id":2}] } -
查询所有文档
GET /student/_search {"query":{"match_all":{}} } -
修改文档
POST /student/_doc/1 {"id": 3,"name": "zzx","age": 10 }Elasticsearch执行删除操作时,ES先标记文档为deleted状态,而不是直接物理删除。当ES存储空间不足或者工作空闲时,才会执行物理删除。
Elasticsearch执行修改操作时,ES不会真的修改Document中的数据,而是标记ES中原有的文档为deleted状态,再创建一个新的文档来存储数据。
3、域的属性
3.1 index
只有域中的index的值为true时,才能根据该域的关键词查询文档。
-
创建两个索引,其中一个索引的域中的index值为true,另一个为false。
PUT /student1 {"mappings": {"properties": {"name": {"type": "text","index":true}}} } PUT /student2 {"mappings": {"properties": {"name": {"type": "text","index":false}}} } -
创建2个域的值相同的文档
POST /student1/_doc/1 {"name":"zzx 111" } POST /student2/_doc/1 {"name":"zzx 111" } -
在这两个文档中,都按name域查找
GET /student1/_search {"query":{"term":{"name": "zzx"}} } GET /student2/_search {"query":{"term":{"name": "zzx"}} }此时student1的name域的index为true,能找到,但是student2是false,直接报错。并且按域查找时,text类型是以空格符为分割符,即如果是zz的话,也是找不到。
3.2 type
- 字符串类型:text
- 整数类型:long,integer,short,byte
- 浮点型:double,float
- 日期类型:date
- 布尔类型:boolean
- 数组类型:array
- 对象类型:object
- 不分词的字符串:keyword
1)创建一个student3
PUT /student3{"mappings": {"properties": {"name": {"type": "keyword","index":true}}}}
2)进行查询
GET /student3/_search{"query":{"term":{"name": "zzx"}}}此时因为keyword类型是不分词的,所以找不到
3.3 store
域中store的值为true,则为单独存储,即该域能够单独查询。
-
创建2个索引
PUT /student1 {"mappings": {"properties": {"age": {"type":"integer"},"name": {"type": "text","index":true,"store": true}}} } PUT /student2 {"mappings": {"properties": {"age": {"type":"integer"},"name": {"type": "text","index":true,"store": false}}} } -
给俩个索引赋值
POST /student1/_doc/1 {"age":11,"name":"zzx 111" } POST /student2/_doc/1 {"age":11,"name":"zzx 111" } -
分别按域单独查找
GET /student1/_search {"stored_fields":["name"] } GET /student2/_search {"stored_fields":["name"] }其中student1的store值为true,student2为false,索引student1单独查找时能找到域值,而索引student2单独查找时没有找到域值。
总结
- Elasticsearch是一个全文检索服务器,全文检索是一种非结构化数据的搜索方式。
全文检索通过建立倒排索引加快搜索效率。
docker安装ES及Kibana,拉取ES镜像后,创建ES通信用的网关,创建ES容器,将配置文件修改为免密码登录即可;拉取Kibana镜像后,创建Kibana容器后即可通过Kibana访问ES服务。
在使用docker的cp指令时,遇到一个问题,就是不能通过相对路径找到文件,而是用绝对路径才能找到文件。 - ES在执行删除和修改操作时,不会马上删除,而是先标记为deleted状态,在内存不足或工作空闲时,才会执行物理删除操作。
- index为true时,在查询文档时,可以根据域值查找文档。
store为true时,将该域进行单独存储,可以按域名单独查询到。
相关文章:
Elasticsearch的安装及常用操作
文章目录一、Elasticsearch的介绍1、Elasticsearch索引2、Elasticsearch的介绍二、Elasticsearch的安装1、安装ES服务2、安装kibana3、Docker安装ES4、Docker安装Kibana三、ES的常用操作1、索引操作2、文档操作3、域的属性3.1 index3.2 type3.3 store总结一、Elasticsearch的介…...
网络安全应急响应服务方案怎么写?包含哪些阶段?一文带你了解!
文章目录一、服务范围及流程1.1 服务范围1.2 服务流程及内容二、准备阶段2.1 负责人准备内容2.2 技术人员准备内容(一)服务需求界定(二)主机和网络设备安全初始化快照和备份2.3市场人员准备内容(1)预防和预…...

11、事务原理和实战,MVCC
事务原理和实战 1. 认识事务2. 事务控制语句2.1 开启事务2.2 事务提交2.3 事务回滚3. 事务的实现方式3.1 原子性3.2 一致性3.3 隔离性3.3 持久性4purge thread线程5事务统计QPS与TPS5.1 QPS5.2 TPS6. 事务隔离级别6.1 隔离级别6.2 查看隔离级别6.3 设置隔离级别6.4 不同隔离级别…...
Robust Self-Augmentation for Named Entity Recognition with Meta Reweighting
摘要 近年来,自我增强成为在低资源场景下提升命名实体识别性能的研究热点。Token substitution and mixup (token替换和表征混合)是两种有效提升NER性能的自增强方法。明显,自增强方法得到的增强数据可能由潜在的噪声。先前的研究…...

Java基础-xml
1.xml 1.1概述 万维网联盟(W3C) 万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。 建立者: Tim Berners-Lee (蒂姆伯纳斯李)。 是Web技术领域最具权威和影响力的国际中立性技术标准机构。 到目前为止&#…...

TCP的Nagle算法和delayed ack---延时发送和延时应答与稍带应答选项
本文目录提高TCP的网络利用率的二个思考解决方案:Nagle算法和delayed ack(延时发送和延时应答与稍带应答选项)Nagle算法和delayed ack算法同时启动可能会导致的问题提高TCP的网络利用率的二个思考 我们都知道,TCP是一个基于字节流…...
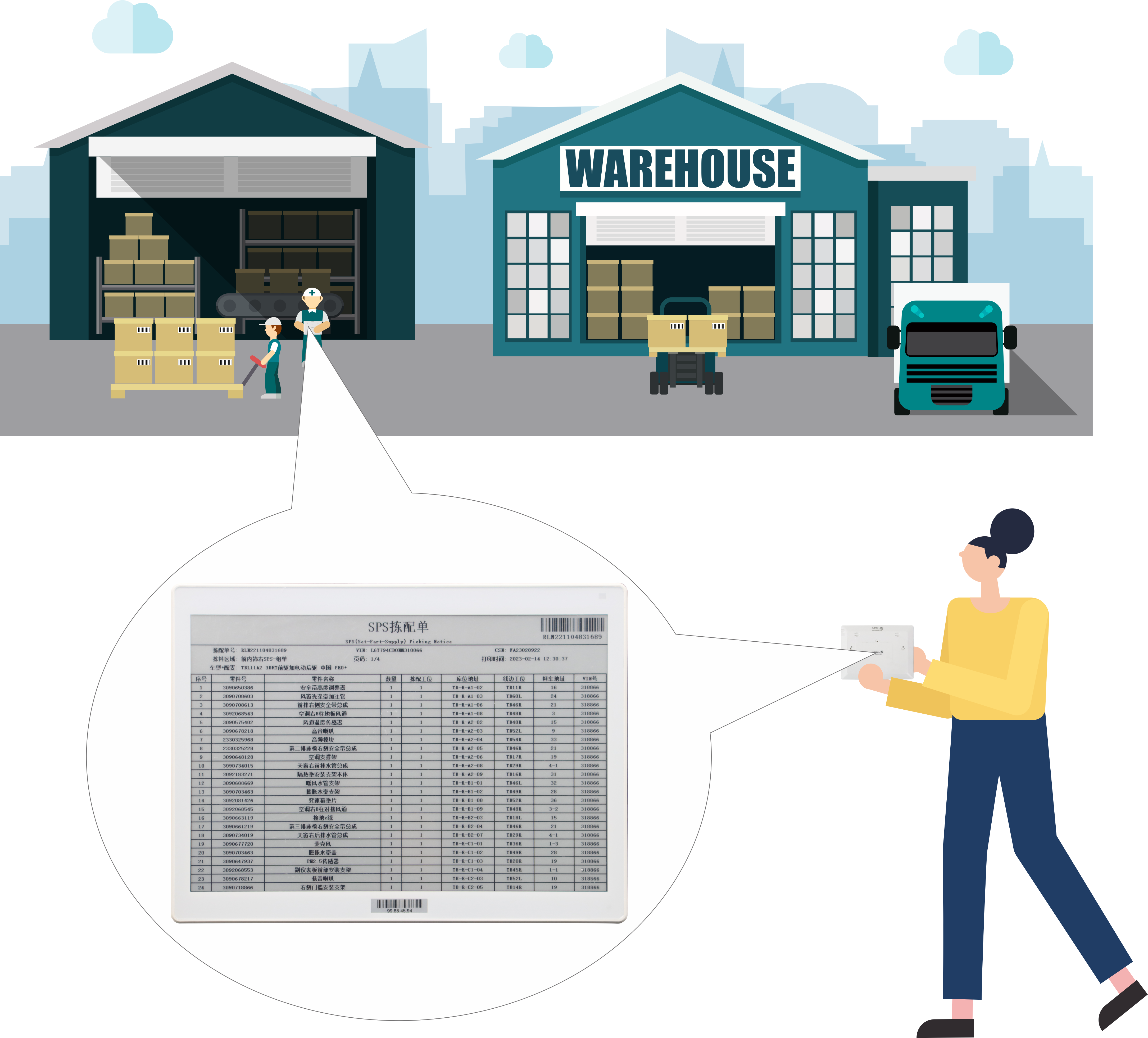
智能拣配单解决方案
电子货架标签系统(ESLs),是一种放置在货架上、可替代传统纸质价格标签的电子显示装置, 每一个电子货架标签通过有线或者无线网络与商场计算机数据库相连, 并将最新的商品价格通过电子货架标签上的屏显示出来。 电子…...

如何防御入侵服务器
根据中华人民共和国刑法: 第二百八十六条违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的ÿ…...
[软件工程导论(第六版)]第4章 形式化说明技术(课后习题详解)
文章目录1. 举例对比形式化方法和欠形式化方法的优缺点。2. 在什么情况下应该使用形式化说明技术?使用形式化说明技术时应遵守哪些准则?3. 一个浮点二进制数的构成是:一个可选的符号(+或-)&…...
Premiere基础操作
一:设置缓存二:ctrI导入素材三:导入图像序列四:打开吸附。打开吸附后素材会对齐。五:按~键可以全屏窗口。六:向前选择轨道工具。在时间线上点击,向前选中时间线上素材。向后选择轨道工具&#x…...
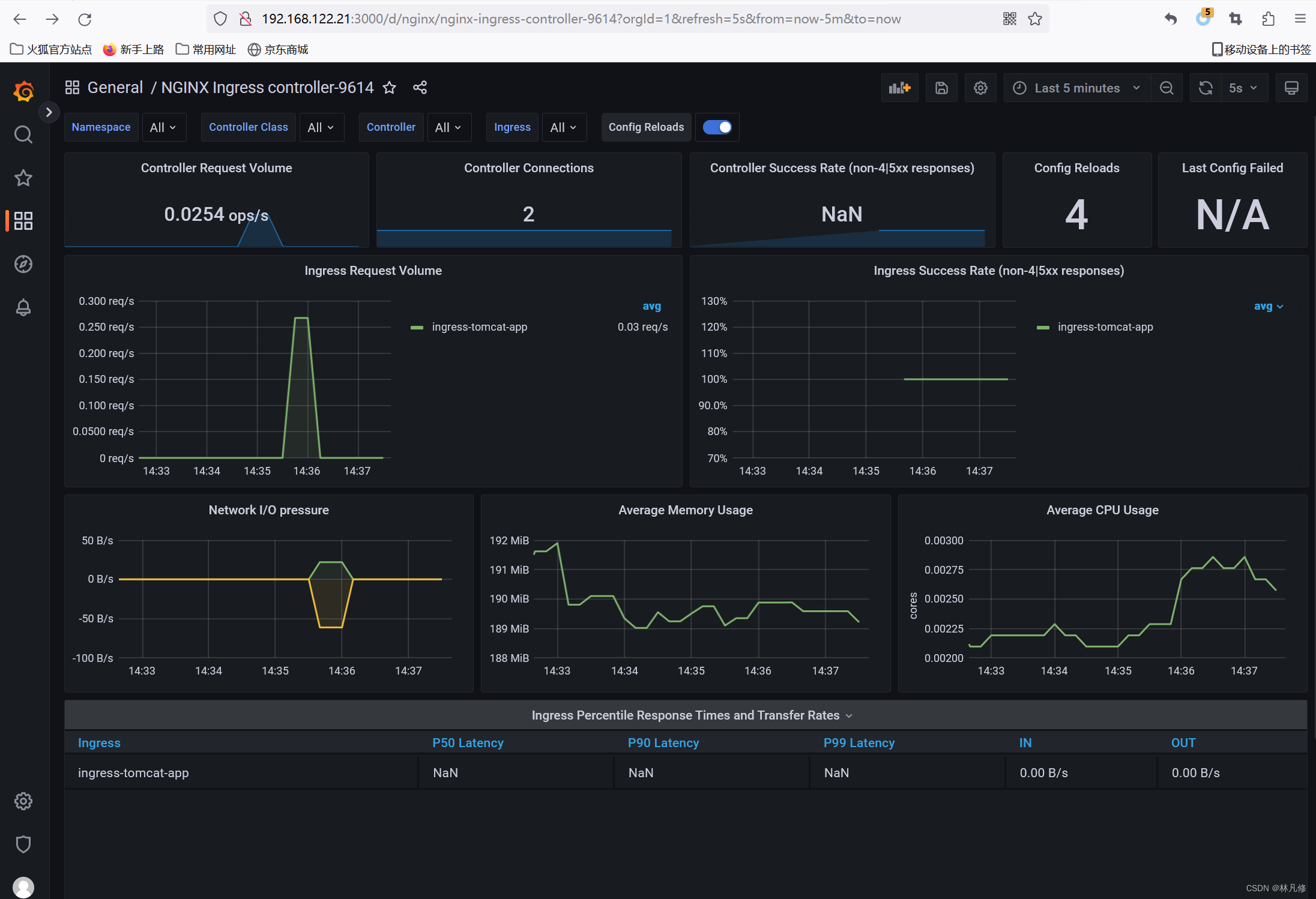
Prometheus监控案例-tomcat、mysql、redis、haproxy、nginx
监控tomcat tomcat自身并不能提供监控指标数据,需要借助第三方exporter实现:https://github.com/nlighten/tomcat_exporter 构建镜像 基于tomcat官方镜像,重新制作一个镜像,将tomcat-exporter和tomcat整合到一起。Ddockerfile如…...
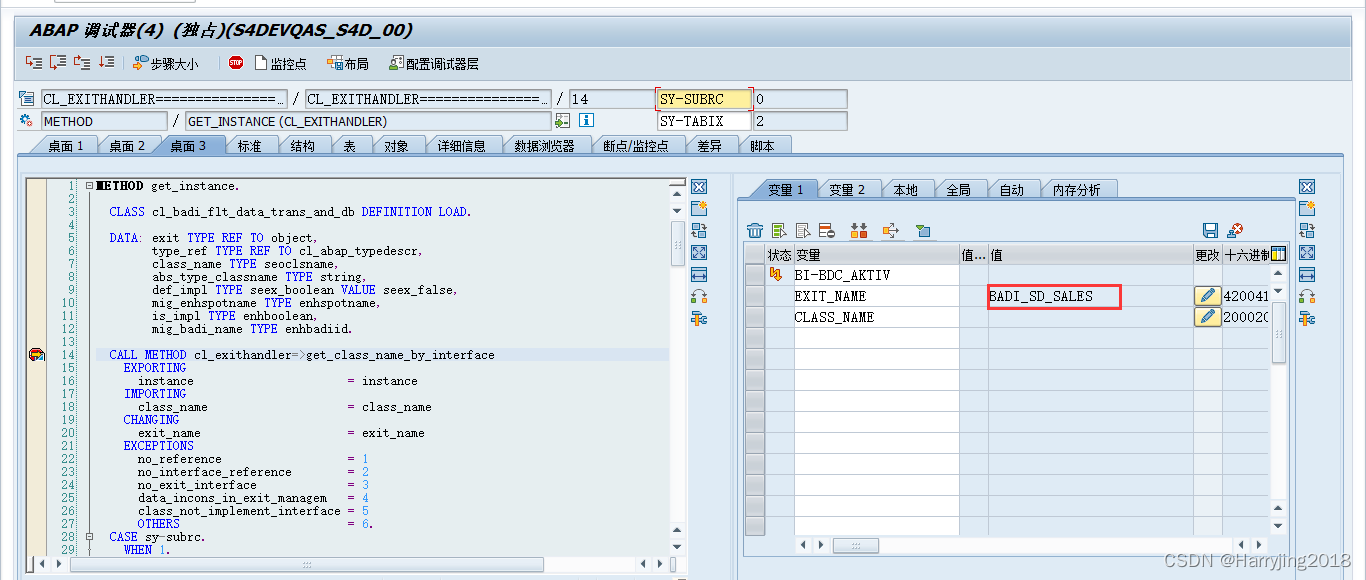
如何寻找SAP中的增强
文章目录0 简介1 寻找一代增强2 寻找二代增强2.2 在包里也可以看到2.3 在出口对象里输入包的名字也可以找到2.4 通过以下函数可以发现已有的增强2.5 也可以在cmod里直接找2.6 总结3 寻找第三代增强0 简介 在SAP中,对原代码的修改最不容易的是找增强,以下…...

算法刷题打卡第95天: 最大平均通过率
最大平均通过率 难度:中等 一所学校里有一些班级,每个班级里有一些学生,现在每个班都会进行一场期末考试。给你一个二维数组 classes ,其中 classes[i] [passi, totali] ,表示你提前知道了第 i 个班级总共有 totali…...
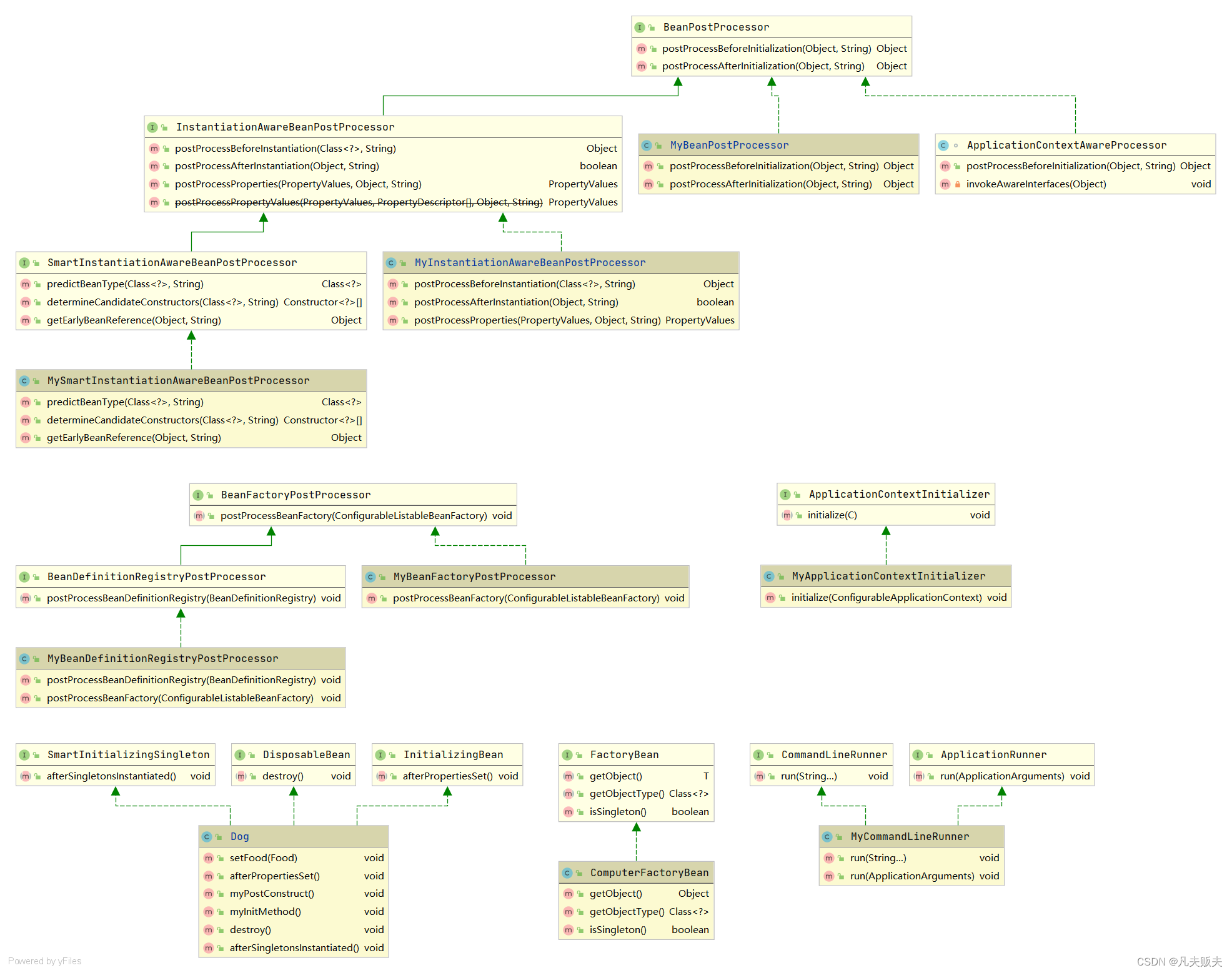
Springboot扩展点系列之终结篇:Bean的生命周期
前言关于Springboot扩展点系列已经输出了13篇文章,分别梳理出了各个扩展点的功能特性、实现方式和工作原理,为什么要花这么多时间来梳理这些内容?根本原因就是这篇文章:Spring bean的生命周期。你了解Spring bean生命周期…...
OnGUI Color 控件||Unity 3D GUI 简介||OnGUI TextField 控件
Unity 3D Color 控件与 Background Color 控件类似,都是渲染 GUI 颜色的,但是两者不同的是 Color 不但会渲染 GUI 的背景颜色,同时还会影响 GUI.Text 的颜色。具体使用时,要作如下定义:public static var color:Color;…...

【日刻一诗】
日刻一诗 1)LeetCode总结(线性表)_链表类 2)LeetCode总结(线性表)_栈队列类 3)LeetCode总结(线性表)_滑动窗口 4)LeetCode总结(线性表&#x…...
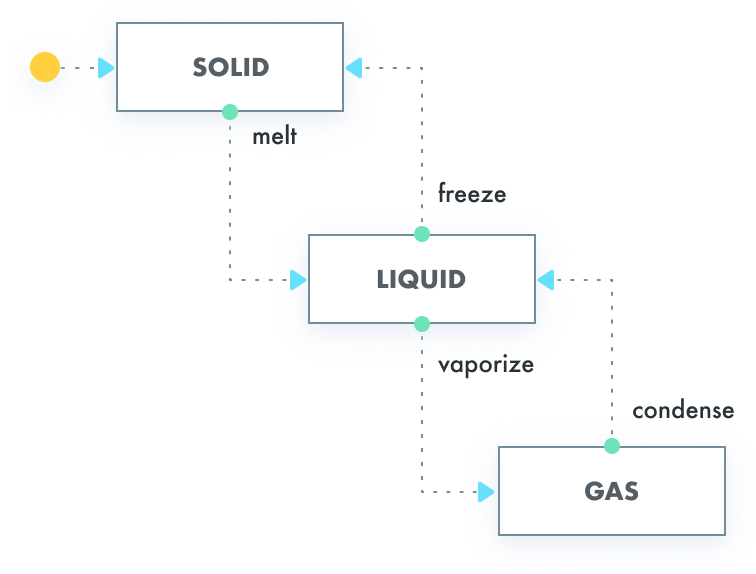
设计模式 状态机
前言 本文梳理状态机概念,在实操中状态机和状态模式类似,只是被封装起来,可以很方便的实现状态初始化和状态转换。 概念 有限状态机(finite-state machine)又称有限状态自动机(英语:finite-s…...

React源码分析(二)渲染机制
准备工作 为了方便讲解,假设我们有下面这样一段代码: function App(){const [count, setCount] useState(0)useEffect(() > {setCount(1)}, [])const handleClick () > setCount(count > count)return (<div>勇敢牛牛, <sp…...

Object.defineProperty 和 Proxy 的区别
区别:Object.defineProperty是一个用来定义对象的属性或者修改对象现有的属性的函数,,而 Proxy 是一个用来包装普通对象的对象的对象。Object.defineProperty是vue2响应式的原理, Proxy 是vue3响应式的原理1)参数不同Object.defineProperty参数obj: 要定…...

Python基础4——面向对象
目录 1. 认识对象 2. 成员方法 2.1 成员方法的定义语法 3. 构造方法 4. 其他的一些内置方法 4.1 __str__字符串方法 4.2 __lt__小于符号比较方法 4.3 __le__小于等于符号比较方法 4.4 __eq__等号比较方法 5. 封装特性 6. 继承特性 6.1 单继承 6.2 多继承 6.3 pas…...

mbed OS USB串口缓冲库:线程安全环形缓冲设计
1. 项目概述buffered-serial0是一个专为 ARM mbed OS 平台设计的轻量级串口缓冲封装库,其核心目标是为 mbed 平台默认的主 USB 虚拟串口(即UART0,在 mbed 中通常映射为Serial pc(USBTX, USBRX))提供可靠、线程安全、零拷贝倾向的底…...

终极指南:php-webdriver弹窗处理与WebDriverAlert对话框管理技巧
终极指南:php-webdriver弹窗处理与WebDriverAlert对话框管理技巧 【免费下载链接】php-webdriver PHP client for Selenium/WebDriver protocol. Previously facebook/php-webdriver 项目地址: https://gitcode.com/gh_mirrors/ph/php-webdriver 想要掌握PHP…...

React Native Interactable跨平台开发终极指南:iOS与Android差异处理技巧
React Native Interactable跨平台开发终极指南:iOS与Android差异处理技巧 【免费下载链接】react-native-interactable Experimental implementation of high performance interactable views in React Native 项目地址: https://gitcode.com/gh_mirrors/re/react…...

EmonLibCM:嵌入式电能监测连续采样库解析
1. EmonLibCM:面向嵌入式电能监测的连续采样库深度解析EmonLibCM(Energy Monitoring Continuous Sampling Library)是一个专为资源受限嵌入式平台设计的开源电能监测库,其核心目标是实现高精度、低开销、免中断依赖的交流电参数连…...

《YOLOv11 实战:从入门到深度优化》003、数据集准备:自定义数据集的标注、整理与增强
003、数据集准备:自定义数据集的标注、整理与增强 上周调一个产线缺陷检测项目,模型在测试集上mAP冲到0.92,产线一跑直接崩了——传送带反光、零件旋转、背景杂物,现实世界从来不会按着COCO数据集的规矩来。这才痛定思痛ÿ…...
:重构科学本质的公理化范式)
贾子科学定理(Kucius Science Theorem):重构科学本质的公理化范式
贾子科学定理:重构科学本质的公理化范式摘要:贾子科学定理由贾子邓于2026年4月提出,颠覆传统“可证伪性”标准,以“公理驱动可结构化”重新定义科学本质,构建TMM三层体系与四大定律(真理硬度、名实分离、逻…...

OpenClaw 太难装了?试试 LangTARS:一行命令部署 + WebUI 管理面板,还能接入 Dify/Coze/nn??
1. 什么是 Apache SeaTunnel? Apache SeaTunnel 是一个非常易于使用、高性能、支持实时流式和离线批处理的海量数据集成平台。它的目标是解决常见的数据集成问题,如数据源多样性、同步场景复杂性以及资源消耗高的问题。 核心特性 丰富的数据源支持&#…...

药流和人流哪个恢复快?术后修护行业洞察与实用指南
意外怀孕后,药流和人流的恢复差异及术后修护,是女性关注的核心话题,也是孕产修护领域的重点议题。术后修护作为缩短恢复周期、减少并发症的关键,其科学合理性直接影响女性生殖健康。本文结合行业现状与实用经验,探讨药…...

当绩效开始算Token:AI时代打工人的新KPI
你的公司开始算Token了吗?最近,多家大厂传出消息:绩效考核开始和Token消耗挂钩。有的部门把Token额度作为「生产力指标」,有的甚至直接影响转正晋升。AI时代,打工人的KPI正在被重新定义。 为什么算Token?公…...

Go语言的gRPC服务开发
Go语言的gRPC服务开发 1. gRPC简介 gRPC是Google开发的高性能、开源的RPC框架,基于HTTP/2协议和Protocol Buffers序列化格式。它支持多种语言,包括Go、Java、C、Python等,非常适合构建微服务架构。 gRPC的优势 高性能:基于HTTP/2协…...