(2018,ProGAN)渐进式发展 GAN 以提高质量、稳定性和变化
Progressive Growing of GANs for Improved Quality, Stability, and Variation
公众号:EDPJ
目录
0. 摘要
1. 简介
2. GAN 的渐进式发展
3. 使用小批量标准差增加变化
4. 生成器和判别器的归一化
4.1 均衡学习率
4.2 生成器中的像素特征向量归一化
5. 评估 GAN 结果的多尺度统计相似性
6. 实验
6.1 个人贡献在统计相似性方面的重要性
6.2 收敛性和训练速度
6.3 使用 CELEBA-HQ 数据集生成高分辨率图像
6.4 LSUN 结果
6.5 CIFAR10 IS
7. 讨论
参考
附录
A. 网络结构和训练配置
A.1 用于 CELEBA-HQ 的 1024*1024 网络
S. 总结
S.1 主要思想
S.2 方法
0. 摘要
我们描述了一种新的生成对抗网络训练方法。 关键思想是逐步增长生成器和鉴别器:从低分辨率开始,我们添加新的层,随着训练的进行,建模越来越精细的细节。 这既加快了训练速度,又极大地稳定了训练,使我们能够生成前所未有的质量图像,例如 1024*1024 的 CELEBA 图像。我们还提出了一种简单的方法来增加生成图像的变化,并达到无监督 CIFAR10 中创纪录的 IS 8.80。 此外,我们描述了几个对于阻止生成器和鉴别器之间的不健康竞争非常重要的实现细节。 最后,我们提出了一种评估 GAN 结果的新指标,无论是在图像质量还是变化方面。 作为额外贡献,我们构建了 CELEBA 数据集的更高质量版本。
1. 简介
通常,GAN 由两个网络组成:生成器和判别器(也称为批评器)。 生成器从隐编码生成样本,例如图像,并且这些图像的分布理想情况下应该与训练分布无法区分。 由于设计一个函数来判断是否是这种情况通常是不可行的,因此训练鉴别器网络来进行评估,并且由于网络是可微分的,我们还得到了一个梯度,可以用来将两个网络引导到正确的方向。 通常,生成器是人们最感兴趣的——鉴别器是一个自适应损失函数,一旦生成器被训练,它就会被丢弃。
这种方法存在多个潜在问题。 当我们测量训练分布和生成分布之间的距离时,如果分布没有实质性重叠,即太容易区分,则梯度可能或多或少指向随机方向(Arjovsky & Bottou,2017)。 最初,Jensen-Shannon 散度被用作距离度量(Goodfellow 等人,2014 年),最近那种方法得到了改进(Hjelm 等人,2017 年),并且提出了许多更稳定的替代方案,包括最小二乘法(least squares) (Mao et al., 2016b)、绝对偏差与边距(absolute deviation with margin) (Zhao et al., 2017) 和 Wasserstein 距离 (Arjovsky et al., 2017; Gulrajani et al., 2017)。 我们的贡献很大程度上与正在进行的讨论正交,我们主要使用改进的 Wasserstein 损失,但也尝试了最小二乘损失。
生成高分辨率图像很困难,因为更高的分辨率使得更容易将生成的图像与训练图像区分开来(Odena et al., 2017),从而极大地放大了梯度问题。 由于内存限制,大分辨率还需要使用较小的小批量,这进一步损害了训练稳定性。 我们的主要见解是,我们可以从更简单的低分辨率图像开始逐步发展生成器和鉴别器,并添加新层,随着训练的进行引入更高分辨率的细节。 这极大地加快了训练速度并提高了高分辨率下的稳定性,正如我们将在第 2 节中讨论的那样。
GAN 公式没有明确要求整个训练数据分布由训练好的的生成模型表示。 传统观点认为图像质量和变化之间需要权衡,但这种观点最近受到了挑战(Odena 等人,2017)。 保留变化的程度目前受到关注,并且已经提出了各种测量方法,包括初始评分(IS)(Salimans et al., 2016)、多尺度结构相似性(MS-SSIM)(Odena et al., 2017;Wang 等人,2003),生日悖论(birthday paradox)(Arora&Zhang,2017),以及对发现的离散模式数量的显式测试(Metz等人,2016)。 我们将在第 3 节中描述我们鼓励变化的方法,并在第 5 节中提出一个用于评估质量和变化的新指标。
4.1 节讨论了对网络初始化的微小修改,从而使不同层的学习速度更加平衡。 此外,我们观察到传统上困扰 GAN 的模式崩溃往往会在十几个小批量的过程中很快发生。 通常,当鉴别器超调时,它们就会开始,导致梯度过大,并且当两个网络中的信号幅度不断升级时,就会出现不健康的竞争。 我们提出了一种机制来阻止生成器参与这种升级,从而解决这个问题(第 4.2 节)。
我们使用 CELEBA、LSUN、CIFAR10 数据集评估我们的贡献。 我们提高了 CIFAR10 的最佳已发布 IS。 由于基准生成方法中常用的数据集仅限于相当低的分辨率,因此我们还创建了 CELEBA 数据集的更高质量版本,允许使用高达 1024*1024 像素的输出分辨率进行实验。 该数据集和我们的完整实现可在 https://github.com/tkarras/progressive_forming_of_gans 上找到,经过训练的网络可以在 https://drive.google.com/open?id=0B4qLcYyJmiz0NHFULTdYc05lX0U 上找到,以及结果图像和补充说明数据集、其他结果和隐空间插值的视频位于 https://youtu.be/G06dEcZ-QTg。
2. GAN 的渐进式发展
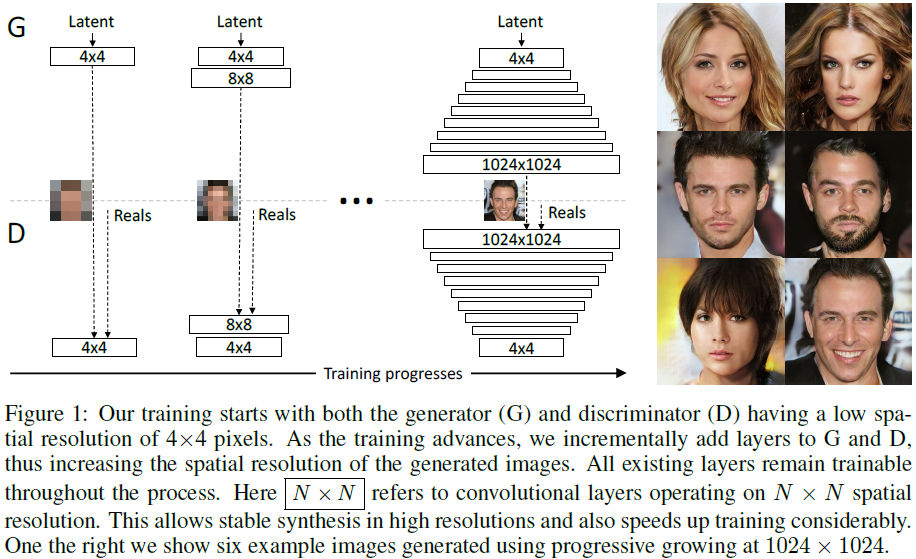
我们的主要贡献是 GAN 的训练方法,我们从低分辨率图像开始,然后通过向网络添加层来逐步提高分辨率,如图 1 所示。这种增量性质允许训练首先发现 GAN 的大规模结构。 图像分布,然后将注意力转移到越来越精细的尺度细节上,而不必同时学习所有尺度。
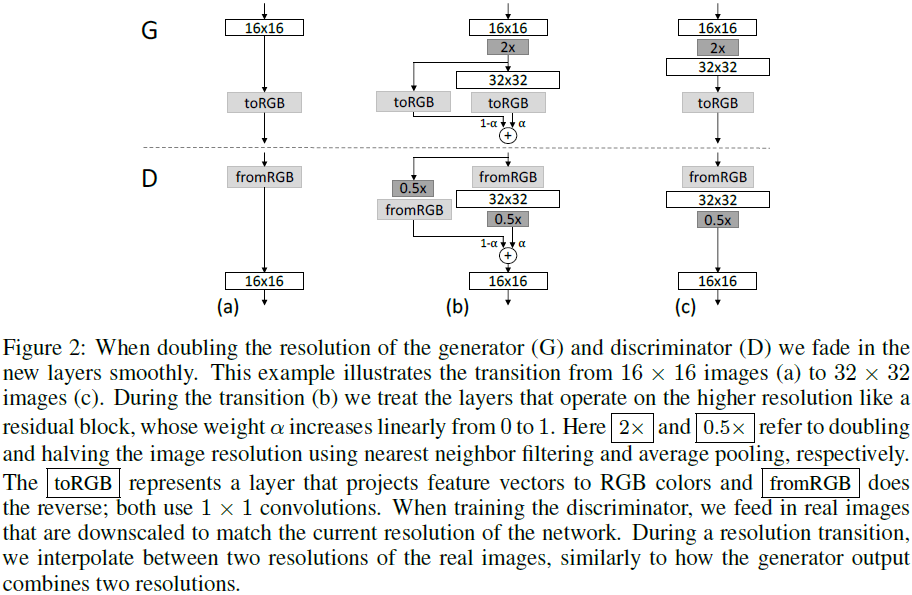
我们使用生成器和鉴别器网络,它们是彼此的镜像,并且始终同步增长。 两个网络中的所有现有层在整个训练过程中都保持可训练状态。 当新层添加到网络中时,我们会平滑地淡入它们,如图 2 所示。这避免了对已经训练有素的较小分辨率层的突然冲击。 附录 A 详细描述了生成器和鉴别器的结构以及其他训练参数。
我们观察到渐进式训练有几个好处。 早期,较小图像的生成基本上更加稳定,因为类别信息和模式较少(Odena 等人,2017)。 通过逐渐提高分辨率,我们不断地提出一个比发现从隐向量到最终目标(例如,1024*1024 图片)映射的更简单的问题。 这种方法与 Chen 和 Koltun (2017) 最近的工作在概念上相似。 在实践中,它足以稳定训练,使我们能够使用 WGAN-GP 损失(Gulrajani 等人,2017)甚至 LSGAN 损失(Mao 等人,2016b)可靠地合成百万像素级图像。
另一个好处是减少训练时间。 随着 GAN 的逐渐增长,大多数迭代都是在较低的分辨率下完成的,并且获得可比较的结果质量的速度通常会快 2-6 倍,具体取决于最终的输出分辨率。
逐步发展 GAN 的想法与 Wang 等人 (2017) 的工作有关,他们使用在不同空间分辨率上运行的多个判别器。 这项工作又是由 Durugkar 等人 (2016) 推动的,同时使用一个生成器和多个判别器。Ghosh 等人(2017)用多个生成器和一个鉴别器做了相反的事情。 分层 GAN(Denton 等人,2015;Huang 等人,2016;Zhang 等人,2017)为图像金字塔的每个级别定义了生成器和鉴别器。 这些方法建立在与我们的工作相同的观察基础上——从隐编码到高分辨率图像的复杂映射更容易逐步学习——但关键的区别在于我们只有一个 GAN,而不是它们的层次结构。 与自适应增长网络的早期工作相比,例如贪婪地增长网络的增长神经气体(growing neural gas)(Fritzke,1995)和增强拓扑的神经进化(neuro evolution of augmenting topologies)(Stanley&Miikkulainen,2002),我们只是推迟了预配置层的引入。 从这个意义上说,我们的方法类似于自编码器的分层训练(Bengio et al., 2007)。
3. 使用小批量标准差增加变化
GAN 倾向于仅捕获训练数据中发现的变化的子集,而 Salimans 等人(2016)建议“小批量鉴别”作为解决方案。 他们不仅计算单个图像的特征统计数据,还计算整个小批量的特征统计数据,从而鼓励生成的和训练图像的小批量显示相似的统计数据。 这是通过在鉴别器末尾添加一个小批量层来实现的,该层学习一个大张量,将输入激活投影到一组统计数据。 为小批量中的每个示例生成一组单独的统计数据,并将其连接到该层的输出,以便鉴别器可以在内部使用这些统计数据。 我们极大地简化了这种方法,同时也改进了变化。
我们的简化解决方案既没有可学习的参数,也没有新的超参数。 我们首先计算小批量上每个空间位置中每个特征的标准差。 然后,我们对所有特征和空间位置的这些估计进行平均,以获得单个值。 我们复制该值并将其连接到所有空间位置和小批量上,产生一个额外的(恒定)特征图。 该层可以插入鉴别器中的任何位置,但我们发现最好将其插入到末尾(详细信息请参阅附录 A.1)。 我们尝试了更丰富的统计数据,但无法进一步改善变化。 在并行工作中,Lin 等人 (2017) 提供了关于向鉴别器显示多个图像的好处的理论见解。
变异问题的替代解决方案包括展开判别器(Metz et al., 2016)来规范其更新,以及“排斥正则化器”(Zhao et al., 2017),它向生成器添加一个新的损失项,试图鼓励它对小批量中的特征向量进行正交化。 Ghosh 等人(2017)的多个生成器也有类似的目标。 我们承认这些解决方案可能会比我们的解决方案增加更多的变化 - 或者可能与其正交 - 但将详细比较留到以后进行。
4. 生成器和判别器的归一化
由于两个网络之间的不健康竞争,GAN 很容易出现信号强度升级的情况。 大多数(如果不是全部)早期解决方案都通过在生成器中(通常也在判别器中)使用批量归一化的变体(Ioffe & Szegedy,2015;Salimans & Kingma,2016;Ba et al.,2016)来阻止这种情况的发生。 这些归一化方法最初是为了消除协变量漂移(covariate shift)而引入的。 然而,我们还没有观察到这成为 GAN 中的一个问题,因此认为 GAN 的实际需求是限制信号幅度和竞争。 我们使用一种不同的方法,该方法由两种成分组成,两者都不包含可学习的参数。
4.1 均衡学习率
我们偏离了当前细致权重初始化的趋势,而是使用简单的 N(0,1) 初始化,然后在运行时显式缩放权重。 准确地说,我们设置 ^w_i = w_i / c,其中 w_i 是权重,c 是 He 初始化器(He et al., 2015)中的每层归一化常数。 动态执行此操作而不是在初始化期间执行此操作的好处有些微妙,并且与常用的自适应随机梯度下降方法中的尺度不变性相关,例如 RMSProp (Tieleman & Hinton, 2012) 和 Adam (Kingma & Ba, 2015)。 这些方法通过估计的标准差对梯度更新进行归一化,从而使更新独立于参数的尺度。 因此,如果某些参数的动态范围比其他参数更大,则调整它们将需要更长的时间。 这是现代初始化程序导致的情况,因此学习率可能同时太大和太小。 我们的方法确保所有权重的动态范围以及学习速度都是相同的。 van Laarhoven (2017) 独立使用了类似的推理。
4.2 生成器中的像素特征向量归一化
为了防止生成器和鉴别器中的幅度由于竞争而失控的情况,我们在每个卷积层之后将每个像素中的特征向量归一化为生成器中的单位长度。 我们使用“局部响应标准化”的变体(Krizhevsky et al., 2012)来做到这一点,配置为
![]()
其中,N 是特征图的数量,a_x,y 和 b_x,y 分别是像素 (x,y) 中的原始特征向量和归一化特征向量。 我们发现令人惊讶的是,这种严厉的约束似乎不会以任何方式损害生成器,并且实际上对于大多数数据集来说,它不会对结果产生太大影响,但它可以在需要时非常有效地防止信号幅度的升级。
5. 评估 GAN 结果的多尺度统计相似性
为了将一个 GAN 的结果与另一个 GAN 的结果进行比较,需要研究大量图像,这可能是乏味、困难且主观的。 因此,需要依靠从大型图像集合中计算一些指示性度量的自动化方法。 我们注意到,MS-SSIM(Odena 等人,2017)等现有方法可以可靠地发现大规模模式崩溃,但无法对较小的影响(例如颜色或纹理变化的损失)做出反应,而且它们也不直接评估图像与训练集的相似性方面的质量。
我们的直觉是,成功的生成器将生成其局部图像结构与所有尺度的训练集相似的样本。 我们建议通过考虑从生成图像和目标图像的拉普拉斯金字塔(Burt&Adelson,1987)表示中绘制的局部图像块的分布之间的多尺度统计相似性来研究这一点,从 16×16 像素的低通分辨率开始。 根据标准实践,金字塔逐渐加倍,直到达到全分辨率,每个连续级别将差异编码为前一级别的上采样版本。
单个拉普拉斯金字塔级别对应于特定的空间频带。 我们随机采样 16384 个图像,并从拉普拉斯金字塔的每个级别提取 128 个描述符,为每个级别提供 2^21 (2.1M) 个描述符。 每个描述符是具有 3 个颜色通道的 7*7 像素邻域,表示为 x ∈ R^7*7*3 = R^147。 我们将训练集和生成集的 l 级 patch 分别表示为
![]()
我们首先对对应于每个颜色通道的平均值和标准差的
![]()
进行标准化,然后通过计算切片 Wasserstein 距离
![]()
来估计统计相似性,这是一种有效计算的推土距离 (earthmovers distance, EMD) 随机近似值,使用 512 个投影(Rabin 等人,2011)。
直观上,小的 Wasserstein 距离表明斑块的分布相似,这意味着训练图像和生成器样本在此空间分辨率下的外观和变化都相似。 特别是,从最低分辨率 16*16 图像中提取的 patch 集之间的距离表明大规模图像结构的相似性,而最精细级别的 patch 编码有关像素级属性的信息,例如边缘的锐度和噪声。
6. 实验
在本节中,我们将讨论一组用于评估结果质量的实验。 请参阅附录 A 了解我们的网络结构和训练配置的详细描述。 我们还邀请读者查阅随附的视频(https://youtu.be/G06dEcZ-QTg)以获取其他结果图像和隐空间插值。 在本节中,我们将区分网络结构(例如,卷积层、调整大小)、训练配置(各种归一化层、小批量相关操作)和训练损失(WGAN-GP、LSGAN)。
6.1 个人贡献在统计相似性方面的重要性
我们将首先使用切片 Wasserstein 距离(SWD)和多尺度结构相似性(MSSSIM)(Odena 等人,2017)来评估我们个人贡献的重要性,并从感知上验证指标本身。 我们将通过在无监督环境中使用 CELEBA (Liu et al., 2015) 和 LSUN 构建先前最先进的损失函数 (WGAN-GP) 和训练配置 (Gulrajani et al., 2017) 来实现这一目标 BEDROOM (Yu et al., 2015) 分辨率为 128*128 的数据集。 CELEBA 特别适合这种比较,因为训练图像包含明显的伪影(锯齿、压缩、模糊),生成器很难忠实地再现这些伪影。 在此测试中,我们通过选择容量相对较低的网络结构(附录 A.2)来放大训练配置之间的差异,并在向鉴别器显示总共 10M 个真实图像后终止训练。 因此,结果并未完全收敛。
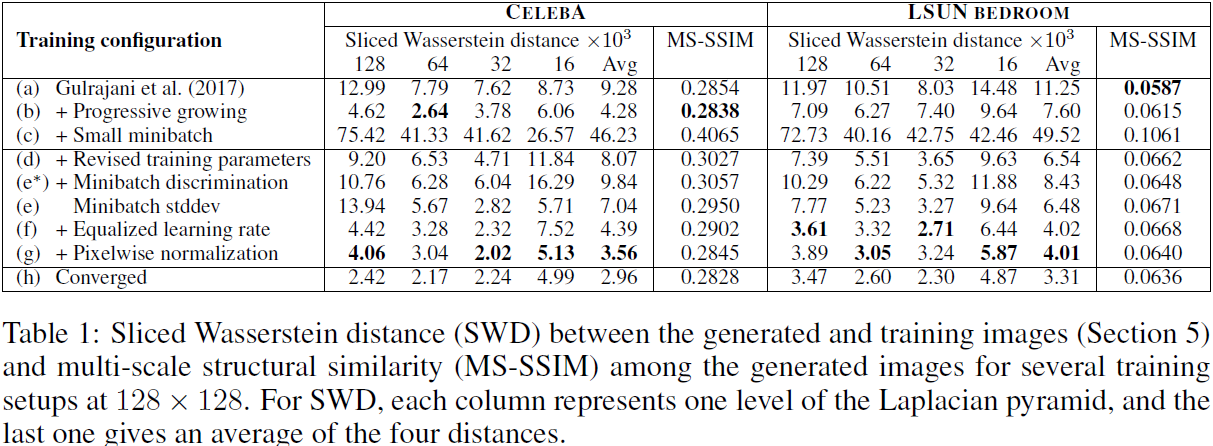

表 1 列出了几种训练配置中 SWD 和 MS-SSIM 的数值,其中我们的个人贡献在基线之上一一累积启用(Gulrajani 等人,2017)。 MS-SSIM 数量是从 10000 对生成的图像中平均得出的,SWD 的计算方法如第 5 节中所述。从这些配置生成的 CELEBA 图像如图 3 所示。由于空间限制,对于表的每一行,该图仅显示了少量示例 ,但附录 H 中提供了更广泛的集合。直观地说,一个好的评估指标应该奖励在颜色、纹理和视角方面表现出大量变化的合理图像。 然而,MS-SSIM 没有捕捉到这一点:我们可以立即看到配置 (h) 生成的图像明显优于配置 (a),但 MS-SSIM 几乎保持不变,因为它仅测量输出之间的变化,而不测量与输出之间的相似性。 训练集。 另一方面,SWD 确实显示出明显的改善。
第一个训练配置 (a) 对应于 Gulrajani 等人 (2017),具有生成器中的批量归一化、鉴别器中的层归一化以及 64 的小批量大小。(b) 使网络能够逐步增长,从而产生更清晰、更可信的输出图像。 SWD 正确地发现生成的图像的分布与训练集更相似。
我们的主要目标是实现高输出分辨率,这需要减小小批量的大小以保持在可用内存预算之内。 我们在 (c) 中说明了随之而来的挑战,其中我们将小批量大小从 64 减少到 16。生成的图像不自然,这在两个指标中都清晰可见。 在 (d) 中,我们通过调整超参数以及删除批量归一化和层归一化来稳定训练过程(附录 A.2)。 作为中间测试 (e*),我们启用了小批量判别(Salimans et al.,2016),但令人惊讶的是,它未能改进任何指标,包括测量输出变化的 MS-SSIM。 相比之下,我们的小批量标准差 (e) 提高了平均 SWD 分数和图像。 然后,我们在 (f) 和 (g) 中实现剩余的贡献,从而实现 SWD 和主观视觉质量的整体改善。 最后,在(h)中,我们使用了一个完整的网络和更长的训练——我们认为生成的图像的质量至少可以与迄今为止发布的最佳结果相媲美。
6.2 收敛性和训练速度
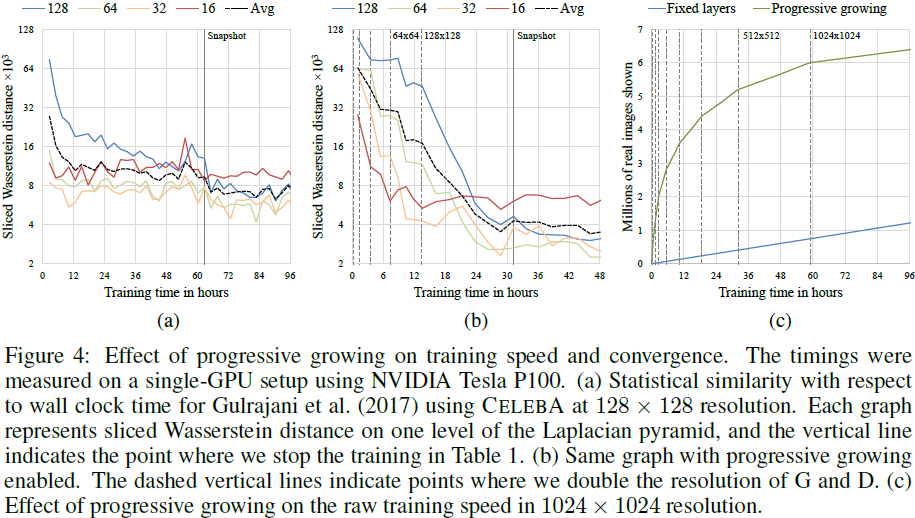
图 4 说明了渐进式增长对 SWD 指标和原始图像吞吐量的影响。 前两张图对应于没有和有渐进式生长的 Gulrajani 等人 (2017)的训练配置。 我们观察到渐进式变体具有两个主要优点:它收敛到更好的最优值,并且还将总训练时间减少了大约两倍。 收敛性的提高可以通过逐渐增加的网络容量所强加的隐式课程学习形式来解释。 如果没有渐进式增长,生成器和鉴别器的所有层的任务就是同时为大规模变化和小规模细节寻找简洁的中间表示。 然而,随着逐渐增长,现有的低分辨率层可能已经很早就收敛了,因此网络的任务只是随着新层的引入而通过越来越小的规模效应来细化表示。 事实上,我们在图 4(b) 中看到,最大规模的统计相似性曲线 (16) 非常快地达到其最佳值,并且在整个训练的其余过程中保持一致。 随着分辨率的增加,较小尺度的曲线(32、64、128)逐渐趋于平稳,但每条曲线的收敛性同样一致。 通过图 4(a) 中的非渐进式训练,SWD 指标的每个尺度大致一致收敛,正如预期的那样。
随着输出分辨率的增加,渐进式增长的加速也会增加。 图 4(c) 显示了当训练一直进行到 1024*1024 分辨率时,训练进度(以向鉴别器显示的真实图像数量来衡量)作为训练时间的函数。 我们看到渐进式增长取得了显着的领先优势,因为网络很浅并且一开始就可以快速评估。 一旦达到全分辨率,两种方法的图像吞吐量就相等。 该图显示渐进式变体在 96 小时内达到约 640 万张图像,而可以推断非渐进式变体需要大约 520 小时才能达到同一点。 在这种情况下,渐进式增长提供了大约 5:4 的加速。
6.3 使用 CELEBA-HQ 数据集生成高分辨率图像
为了在高输出分辨率下有意义地展示我们的结果,我们需要足够多样化的高质量数据集。 然而,几乎所有以前在 GAN 文献中使用的公开数据集都仅限于相对较低的分辨率,从 32*32 到 480*480。为此,我们创建了一个高质量版本的 CELEBA 数据集,其中包含 30000 个分辨率为 1024 1024 的图像 。 有关生成此数据集的更多详细信息,请参阅附录 C。

我们的贡献使我们能够以稳健且高效的方式处理高输出分辨率。 图 5 显示了我们的网络生成的选定 1024*1024 个图像。 虽然百万像素 GAN 结果之前已在另一个数据集中显示过(Marchesi,2017),但我们的结果更加多样化且具有更高的感知质量。 请参阅附录 F 了解更多结果图像以及从训练数据中找到的最近邻图像。 随附的视频显示了隐空间插值并可视化了渐进式训练。 插值的工作原理是,我们首先随机化每个帧的隐编码(从 N(0,1) 中单独采样的 512 个分量),然后使用高斯 (= 45 帧 @ 60Hz) 随时间模糊隐编码,最后归一化每个向量到一个超球面上。
我们在 8 个 Tesla V100 GPU 上对网络进行了 4 天的训练,之后我们不再观察到连续训练迭代结果之间的质的差异。 我们的实现根据当前输出分辨率使用自适应小批量大小,以便最佳地利用可用内存预算。
为了证明我们的贡献在很大程度上与损失函数的选择正交,我们还使用 LSGAN 损失而不是 WGAN-GP 损失来训练相同的网络。 图 1 显示了使用我们的 LSGAN 方法生成的 1024*1024 图像的六个示例。 附录 B 中给出了此设置的更多详细信息。
6.4 LSUN 结果


图 6 显示了我们的解决方案与 LSUN BEDROOM 中早期结果之间的纯粹视觉比较。 图 7 给出了 256*256 分辨率 7 个截然不同的 LSUN 类别中的选定示例。附录 G 中提供了来自所有 30 个 LSUN 类别的更大的非策划结果集,并且视频演示了插值。 我们不知道大多数类别的早期结果,虽然某些类别比其他类别效果更好,但我们认为整体质量很高。
6.5 CIFAR10 IS
我们知道,CIFAR10(10 个类别,32 32 个 RGB 图像)的最佳 IS 对于无监督设置为 7.90,对于标签条件设置为 8.87(Grinblat 等人,2017)。 这两个数字之间的巨大差异主要是由无监督环境中类别之间必然出现的“幽灵”引起的,而标签调节可以消除许多此类转换。
当我们所有的贡献都启用后,我们在无监督的设置中得到 IS 8.80。 附录 D 显示了一组代表性的生成图像以及更全面的早期方法结果列表。 网络和训练设置与 CELEBA 相同,当然级数限制为 32*32。 唯一的定制是 WGAN-GP 的正则化项
![]()
Gulrajani (2017) 等人使用 γ= 1.0,对应于 1-Lipschitz,但我们注意到实际上更喜欢快速过渡 (γ= 750) 以最大限度地减少重影。 我们还没有在其他数据集上尝试过这个技巧。
7. 讨论
虽然与早期的 GAN 工作相比,我们的结果质量普遍较高,并且训练在大分辨率下也很稳定,但距离真正的照片级真实感还有很长的路要走。 语义敏感性和理解数据集相关的约束(例如某些对象是直的而不是弯曲的)还有很多不足之处。 图像的微观结构也有改进的空间。 也就是说,我们认为令人信服的现实主义现在可能已经触手可及,尤其是在 CELEBA-HQ。
参考
Karras T, Aila T, Laine S, et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation[C]//International Conference on Learning Representations. 2018.
附录
A. 网络结构和训练配置
A.1 用于 CELEBA-HQ 的 1024*1024 网络
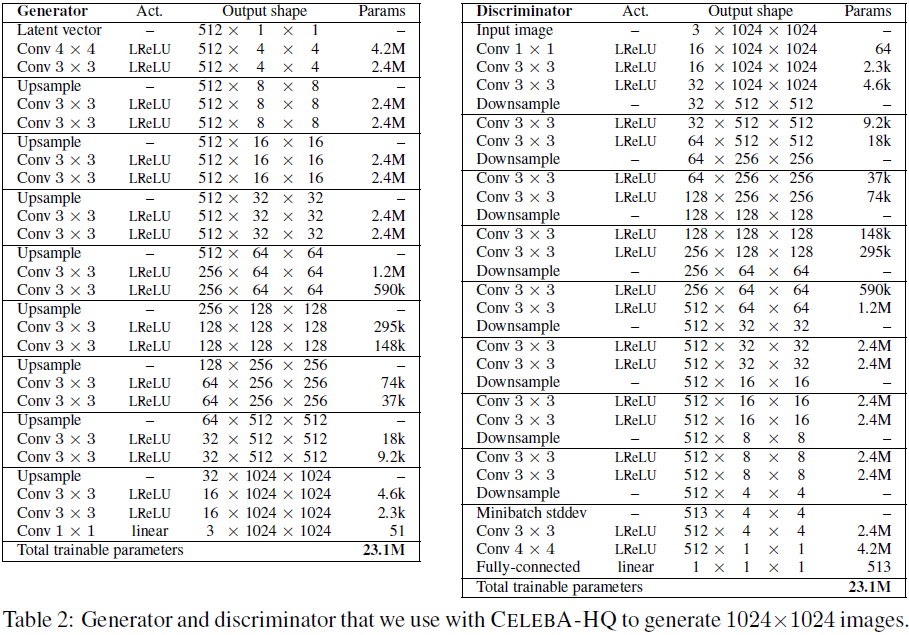
表 2 显示了我们与 CELEBA-HQ 数据集一起使用的全分辨率生成器和鉴别器的网络架构。 这两个网络主要由复制的 3 层块组成,我们在训练过程中将它们一一引入。 生成器的最后一个 Conv 1x1 层对应于图 2 中的 toRGB 块,鉴别器的第一个 Conv 1x1 层同样对应于 fromRGB。 我们从 4×4 分辨率开始训练网络,直到我们向鉴别器展示总共 800k 个真实图像。 然后,我们在两个阶段之间交替:在接下来的 800k 图像期间淡入第一个 3 层块,稳定 800k 图像的网络,在 800k 图像期间淡入下一个 3 层块,等等。
我们的隐向量对应于 512 维超球面上的随机点,并且我们在 [-1,1] 中表示训练和生成的图像。 我们在两个网络的所有层中都使用 leakiness 为 0.2 的 Leaky ReLU,除了使用线性激活的最后一层。 我们不在这两个网络中采用批量归一化、层归一化或权重归一化,但我们在生成器中的每个 Conv 3x3 层之后对特征向量执行像素归一化,如第 4.2 节所述。 我们将所有偏差参数初始化为零,并根据单位方差的正态分布将所有权重初始化。 然而,我们在运行时使用特定于层的常量来缩放权重,如第 4.1 节所述。 我们将跨小批量标准差作为附加特征图以 4x4 分辨率注入到判别器的末尾,如第 3 节中所述。表 2 中的上采样和下采样操作分别对应于 2x2 元素复制和平均池化 。
S. 总结
S.1 主要思想
逐步增长生成器和鉴别器:从低分辨率开始,添加新的层,随着训练的进行,建模越来越精细的细节。 这既加快了训练速度,又极大地稳定了训练,能够生成前所未有的高分辨率图像。
使用小批量标准差增加变化。打破质量与变化的权衡。
使用网络归一化限制生成器和判别器的信号幅度,从而避免模式崩溃。
S.2 方法
小批量标准差。简化的小批量鉴别:首先计算小批量上每个空间位置中每个特征的标准差。 然后,对所有特征和空间位置的这些估计进行平均,以获得单个值。 复制该值并将其连接到所有空间位置和小批量上,产生一个额外的(恒定)特征图。该层可以插入鉴别器中的任何位置,但最好将其插入到末尾。
归一化。为了防止生成器和鉴别器中的幅度由于竞争而失控的情况,在每个卷积层之后将每个像素中的特征向量归一化为生成器中的单位长度。
相关文章:
(2018,ProGAN)渐进式发展 GAN 以提高质量、稳定性和变化
Progressive Growing of GANs for Improved Quality, Stability, and Variation 公众号:EDPJ 目录 0. 摘要 1. 简介 2. GAN 的渐进式发展 3. 使用小批量标准差增加变化 4. 生成器和判别器的归一化 4.1 均衡学习率 4.2 生成器中的像素特征向量归一化 5. 评…...
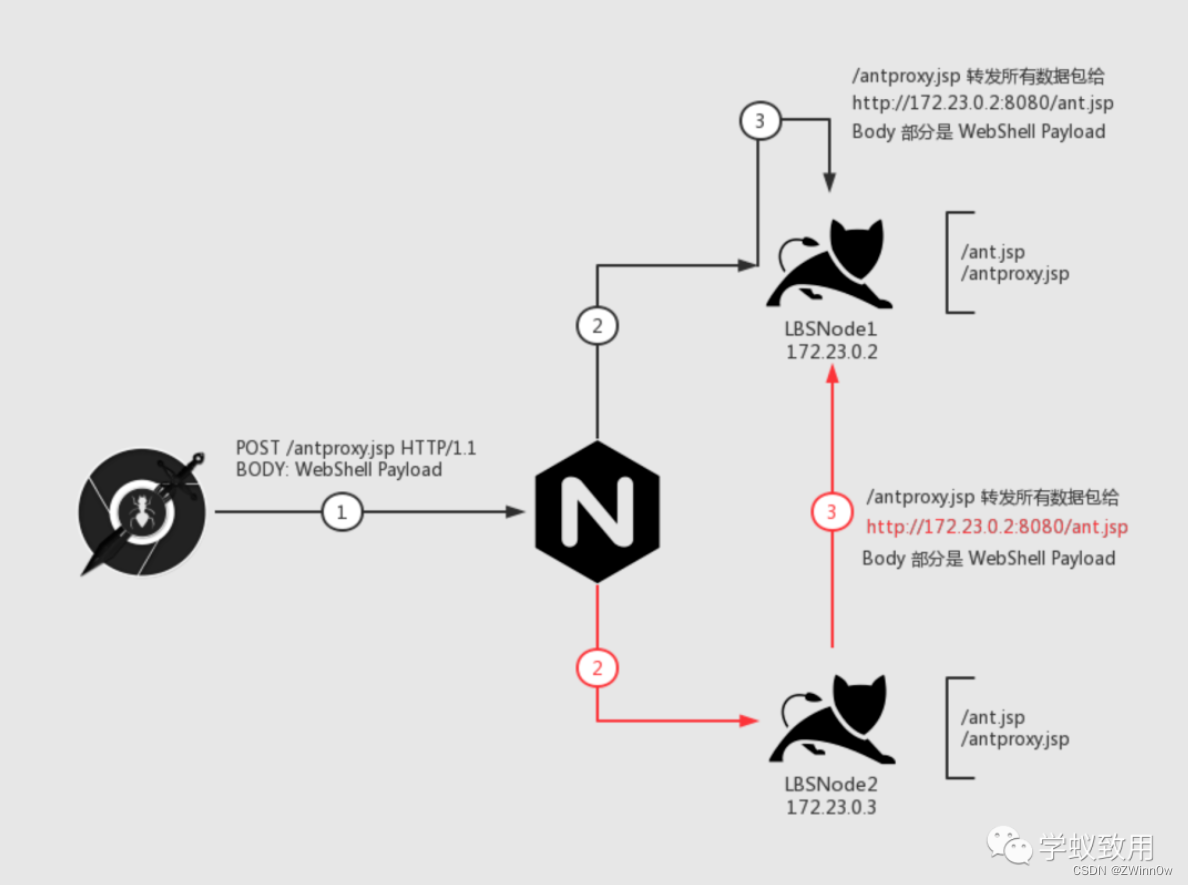
负载均衡下的 WebShell 连接
目录 负载均衡简介负载均衡的分类网络通信分类 负载均衡下的 WebShell 连接场景描述难点介绍解决方法**Plan A** **关掉其中一台机器**(作死)**Plan B** **执行前先判断要不要执行****Plan C** 在Web 层做一次 HTTP 流量转发 (重点࿰…...

Postman的高级用法—Runner的使用
1.首先在postman新建要批量运行的接口文件夹,新建一个接口,并设置好全局变量。 2.然后在Test里面设置好要断言的方法 如: tests["Status code is 200"] responseCode.code 200; tests["Response time is less than 10000…...
spring如何进行依赖注入,通过set方法把Dao注入到serves
1、选择Generate右键鼠标 你在service层后面方法的这些: 2、UserService配置文件的写法是怎样的: 3、我们在UserController中执行一下具体写法: 最后我们执行一下 : 4、这里可能出现空指针,因为你当前web层,因为你new这个对象根…...
和NumPy库来比较两副图像的相似度)
Python使用图像处理库PIL(Python Imaging Library)和NumPy库来比较两副图像的相似度
目录 1、解释说明: 2、使用示例: 3、注意事项: 1、解释说明: 在Python中,我们可以使用图像处理库PIL(Python Imaging Library)和NumPy库来比较两副图像的相似度。常用的图像相似度计算方法有…...

clickhouse扩缩容
一、背景 我们之前已经学会了搭建clickhouse集群,我们搭建的是一套单分片两副本的集群,接下来我们来测试下clickhouse的扩缩容情况 二、扩容 扩容相对来说比较简单,我们原来的架构如下 hostshardreplica192.169.1.111192.169.1.212 现在…...

动漫3D虚拟人物制作为企业数字化转型提供强大动力
一个 3D 虚拟数字人角色的制作流程,可以分为概念设定-3D 建模-贴图-蒙皮-动画-引擎测试六个步骤,涉及到的岗位有原画师、模型师、动画师等。角色概念设定、贴图绘制一般是由视觉设计师来完成;而建模、装配(骨骼绑定)、渲染动画是由三维设计师来制作完成。…...
数据同步工具比较:选择适合您业务需求的解决方案
在当今数字化时代,数据已经成为企业的核心资产。然而,随着业务的扩展和设备的增多,如何实现数据的高效管理和同步成为了一个亟待解决的问题。本文将介绍几种常见的数据同步工具,并对比它们的功能、性能和适用场景,帮助…...

Python中数据结构列表详解
列表是最常用的 Python 数据类型,它用一个方括号内的逗号分隔值出现,列表的数据项不需要具有相同的类型。 列表中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。列表都可…...

引领行业高质量发展|云畅科技参编《低代码开发平台创新发展路线图(2023)》
8月8日-9日,中国电子技术标准化研究院于北京顺利召开《低代码开发平台创新发展路线图(2023)》封闭编制会。云畅科技、浪潮、百度、广域铭岛等来自低代码开发平台解决方案供应商、用户方、科研院所等近30家相关单位的40余位专家参与了现场编制…...

Ubuntu22.04编译Nginx源码
执行如下命令 # ./configure --sbin-path/usr/local/nginx/nginx --conf-path/usr/local/nginx/nginx.conf --pid-path/usr/local/nginx/nginx.pid输出结果,出现如下: Configuration summary using system PCRE2 library OpenSSL library is not used …...

视频上传,限制时长,获取视频时长
使用element的upload上传文件时,除了类型和大小,需求需要限制只能长传18秒内的视频,这里通过upload的before-upload,以及创建一个音频元素对象拿到durtaion时长属性来实现。 getVideoTime(file) {return new Promise(async (resol…...

Open3D 进阶(5)变分贝叶斯高斯混合点云聚类
目录 一、算法原理二、代码实现三、结果展示四、测试数据本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫。 系列文章(连载中。。。爬虫,你倒是爬个完整的呀?): Open3D 进阶(1) MeanShift点云聚类Open3D 进阶(2)DB…...

5、css学习5(链接、列表)
1、css可以设置链接的四种状态样式。 a:link - 正常,未访问过的链接a:visited - 用户已访问过的链接a:hover - 当用户鼠标放在链接上时a:active - 链接被点击的那一刻 2、 a:hover 必须在 a:link 和 a:visited 之后, a:active 必须在 a:hover 之后&…...
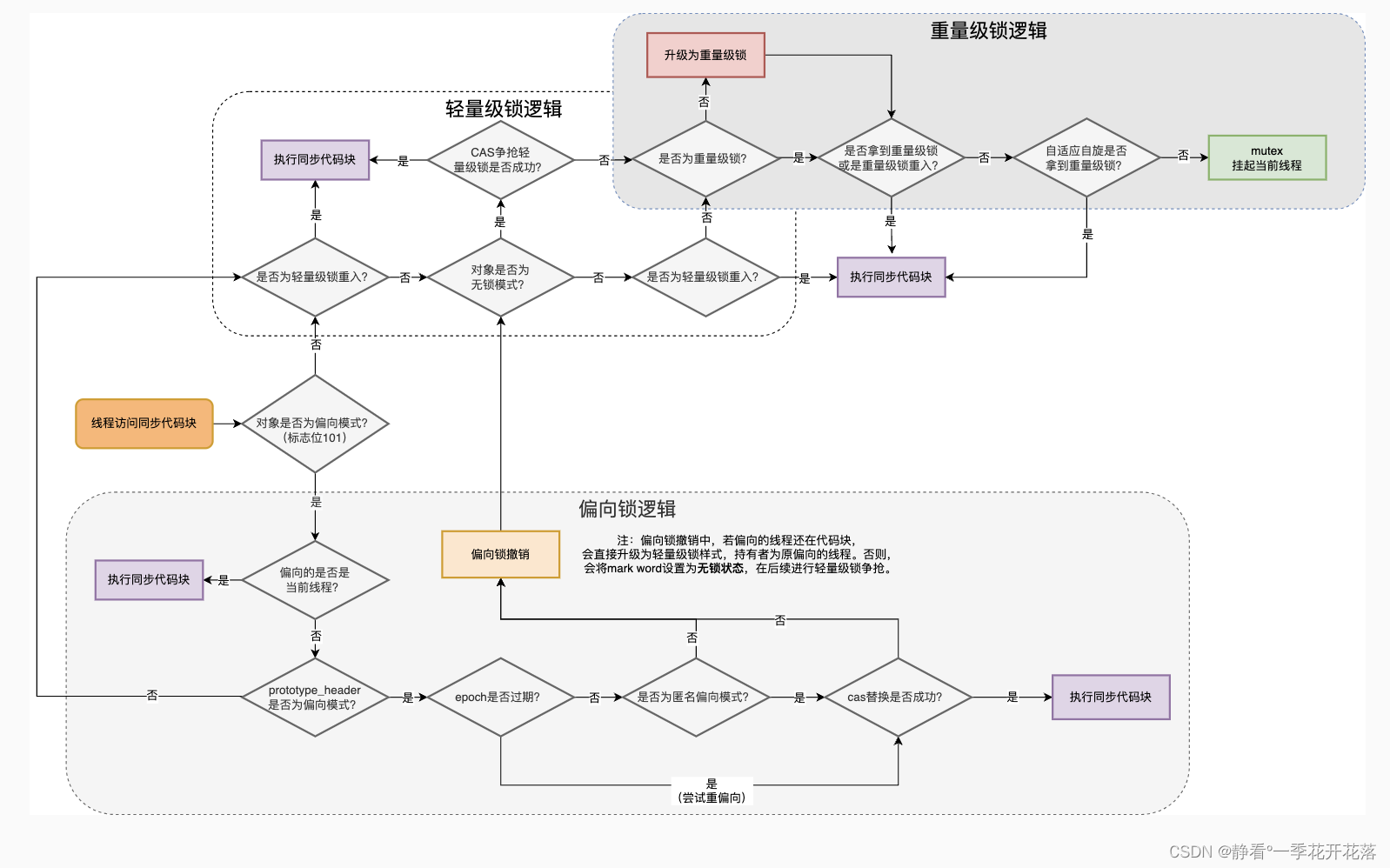
Synchronized与Java线程的关系
前言 Java多线程处理任务时,为了线程安全,通常会对共享资源进行加锁,拿到锁的线程才能进行访问共享资源。而加锁方式通过都是Synchronized锁或者Lock锁。 那么多线程在协同工作的时候,线程状态的变化都与锁对象有关系。 …...
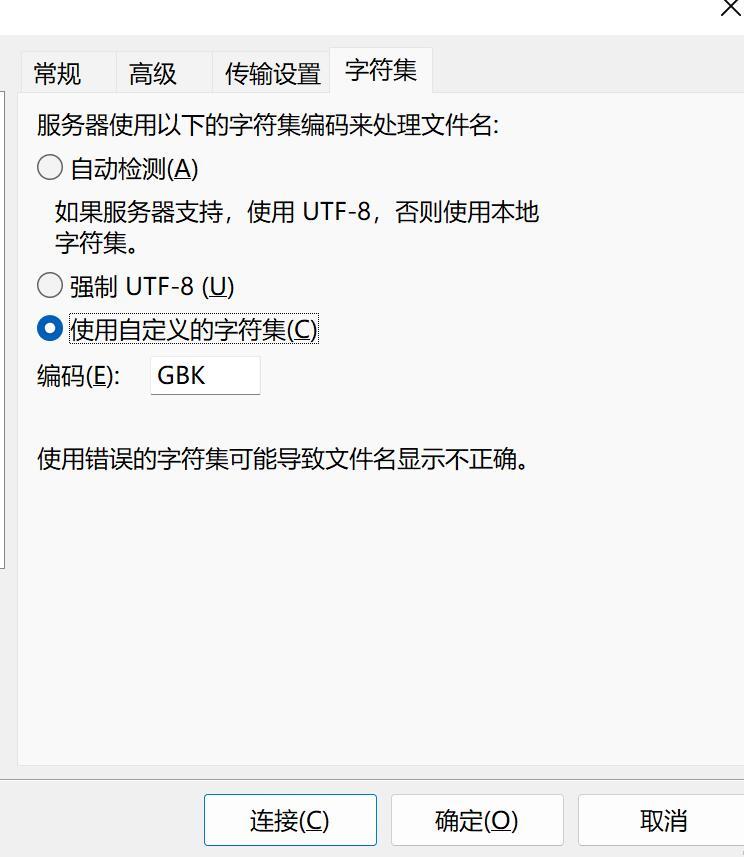
使用本地电脑搭建可以远程访问的SFTP服务器
文章目录 1. 搭建SFTP服务器1.1 下载 freesshd 服务器软件1.3 启动SFTP服务1.4 添加用户1.5 保存所有配置 2. 安装SFTP客户端FileZilla测试2.1 配置一个本地SFTP站点2.2 内网连接测试成功 3. 使用cpolar内网穿透3.1 创建SFTP隧道3.2 查看在线隧道列表 4. 使用SFTP客户端&#x…...
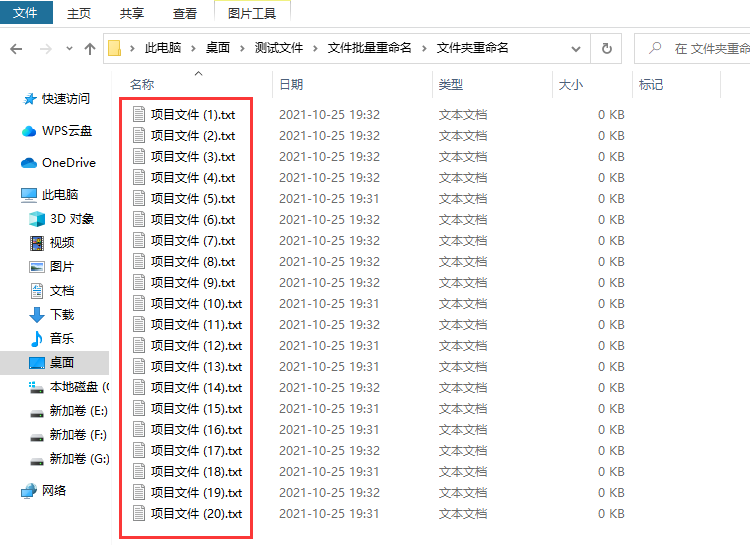
批量修改文件名怎么操作?
批量修改文件名怎么操作?不管你使用电脑处理工作还是进行学习,都会在电脑中产生很多的文件,时间一久电脑里的文件更加杂乱无章,这时候如果不对电脑中的文件进行及时的管理,那么很可能出现文件丢失而你自己还发现不了的…...
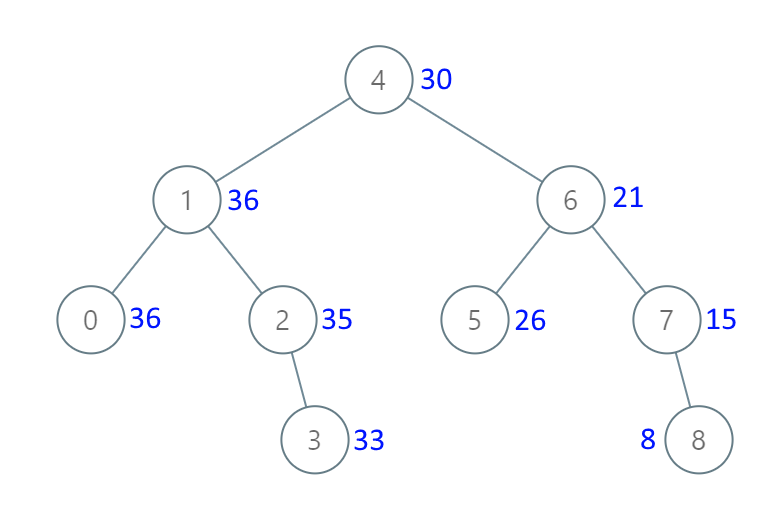
【LeetCode】538.把二叉搜索树转换为累加树
题目 给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。 提醒一下,二叉搜索树满足下列约束条件…...
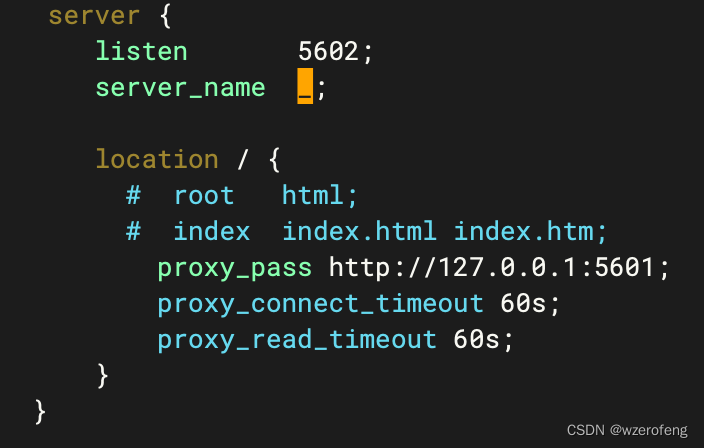
linux 安装 kibana
首先下载 kibana https://www.elastic.co/cn/downloads/kibana 然后上传到linux /usr/local 目录下解压安装 修改config/kibana.yml 配置文件,将elasticsearch.hosts 然后再nginx 中做一个端口映射,实现在浏览器中输入后xxxx:5602 nginx 可以将请求转发…...
STM32入门——IIC通讯
江科大STM32学习记录 I2C通信 I2C(Inter IC Bus)是由Philips公司开发的一种通用数据总线两根通信线:SCL(Serial Clock)、SDA(Serial Data)同步,半双工带数据应答支持总线挂载多设备…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...
:含12组经大英博物馆湿版藏品验证的Reference Prompt库)
Midjourney湿版摄影风格实战手册(从胶片化学原理到Prompt工程):含12组经大英博物馆湿版藏品验证的Reference Prompt库
更多请点击: https://intelliparadigm.com 第一章:湿版摄影的历史溯源与Midjourney风格化转译本质 湿版摄影(Wet Plate Collodion Process)诞生于1851年,由弗雷德里克斯科特阿彻(Frederick Scott Archer&a…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

Pandrator:基于Python的自动化内容生成与数据转换工具实践
1. 项目概述与核心价值最近在折腾一些自动化数据处理和内容生成的工作流,发现了一个挺有意思的开源项目,叫Pandrator。乍一看这个名字,可能会联想到“潘多拉”和“生成器”的结合,实际上它也确实是一个功能强大的内容转换与生成工…...

基于RP2040与I2C总线打造可编程合成器吉他:从硬件到固件的完整实践
1. 项目概述:打造你的第一把可编程合成器吉他 如果你对电子音乐制作和嵌入式硬件开发都感兴趣,那么将两者结合的DIY项目无疑是最迷人的领域。今天要分享的,就是基于Adafruit RP2040 PropMaker Feather微控制器,从零开始打造一把功…...
CircuitPython与NeoPixel实战:从硬件连接到动态灯光效果
1. 项目概述:用Python点亮你的硬件创意如果你玩过Arduino,可能会觉得C/C的语法和库管理有点门槛;如果你熟悉Python,又觉得它和硬件之间隔着一层纱。那么,当Raspberry Pi Pico这块性价比极高的微控制器,遇上…...

大语言模型可靠性监测与压缩的谱方法研究
1. 大语言模型可靠性监测与压缩的谱方法研究概述在深度学习领域,大语言模型(LLM)和视觉语言模型(VLM)的可靠性问题与计算效率挑战日益凸显。模型幻觉(生成与输入无关或错误的内容)和分布偏移(面对训练数据分布外的输入时性能下降)会严重损害用户信任,而庞…...

AI原生编程语言Reia:为LLM设计的编程范式变革
1. 项目概述:Reia,一个面向未来的AI原生编程语言最近在AI和编程语言交叉领域,一个名为Reia的项目引起了我的注意。它来自Quaint-Studios,定位是“AI原生”的编程语言。这听起来有点抽象,但简单来说,Reia试图…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...

轻量级Web框架Oli:从核心原理到生产实践
1. 项目概述:一个轻量级、可扩展的Web应用框架最近在梳理手头几个小项目的技术栈时,我又把amrit110/oli这个仓库翻了出来。这是一个在GitHub上由开发者amrit110创建并维护的名为oli的项目。乍一看标题,你可能会有点懵,oli是什么&a…...