Python爬虫解析工具之xpath使用详解
文章目录
- 一、数据解析方式
- 二、xpath介绍
- 三、环境安装
- 1. 插件安装
- 2. 依赖库安装
- 四、xpath语法
- 五、xpath语法在Python代码中的使用
一、数据解析方式
爬虫抓取到整个页面数据之后,我们需要从中提取出有价值的数据,无用的过滤掉。这个过程称为数据解析,也叫数据提取。数据解析的方式有多种,按照网站数据来源是静态还是动态进行分类,如下:
- 动态网站:字典取值。动态网站的数据一般都是JS发过来的,基本都是json格式数据,我们只需要将json格式转换为字典进行取值。
- 静态网站:xpath取值 + 正则取值。
说明:爬虫开发中,用的最多的数据解析方式是字典取值和xpath取值,占到80%以上,其余的少部分是正则取值。
二、xpath介绍
xpath全称XML Path Language,即XML路径语言。它是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
xpath的选择功能十分强大,它提供了非常简明的路径选择表达式。另外,它还提供了众多的内建函数,用于字符串、数值、时间的匹配处理等,几乎所有我们想要定位的节点,都可以用XPath来选择。
三、环境安装
1. 插件安装
很多爬虫的初学者由于对解析工具语法的不熟练,经常会有这种情况:抓来的数据经过解析之后发现不是自己要的,就会多次调试代码,直至提取出精确的价值数据,这样就会导致爬虫多次频繁请求网站,结果自己的IP被网站封掉。那有没有好的办法规避这种情况呢?
有的,Chrome浏览器支持众多插件,其中就有适合xpath语法的元素查找插件:XPath Helper,在谷歌应用商店可以搜索安装,安装好之后图标如下图所示:
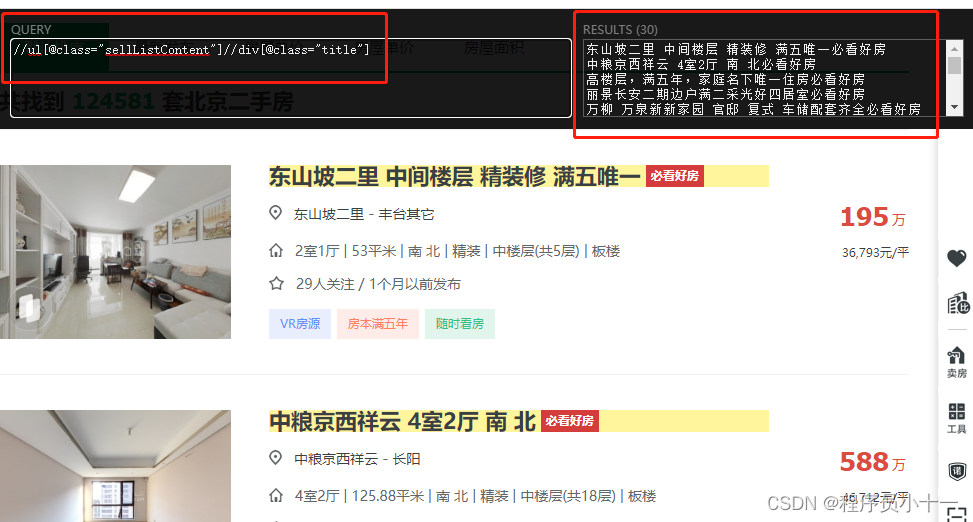
使用该插件的方法很简单,在Chrome浏览器中,打开任意网页之后,同时按下 Ctrl+Shift+X 键就可以看到网页上方的XPath Helper调试窗口,左边窗口是要输入的xpath语法,右边窗口是该xpath语法定位出的结果展示。这样就非常方便我们写爬虫项目,如果不确定解析出的结果是不是我们想要的,就可以先在调试窗口中多次调试,结果没有错误,再直接把该代码复制到我们的爬虫代码中运行,如下图:
2. 依赖库安装
在Python代码中,若要使用xpath解析,需要安装lxml这个第三方库,它对xpath语法提供了良好的支持,安装lxml库步骤如下:
1.同时按下win + R键,打开运行框,在里面输入cmd,点击确定。
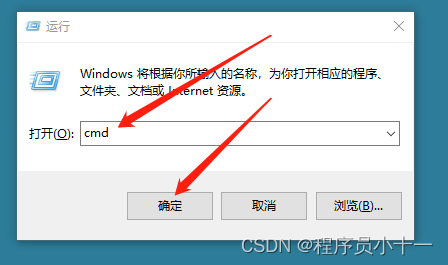
2.来到控制台中,输入安装命令:pip install lxml -i https://mirrors.aliyun.com/pypi/simple/,然后按下回车键,等候安装完成,出现“Successfully installed …”字样即为安装成功。

四、xpath语法
xpath语法,也叫xpath路径表达式。因为xpath查找内容是按照HTML代码的标签树结构搜索的,每一个标签都有自己的父标签和子标签,比如下图这组HTML代码所示:
<body><div><a href="/ershoufang/dongcheng/" title="北京东城在售二手房 ">东城</a><a href="/ershoufang/xicheng/" title="北京西城在售二手房 ">西城</a><a href="/ershoufang/chaoyang/" title="北京朝阳在售二手房 ">朝阳</a><a href="/ershoufang/haidian/" title="北京海淀在售二手房 ">海淀</a></div>
</body>
代码中的 body 标签就是 div 标签的父标签,同理,div 标签是 body 标签的子标签。标签之间的这种父子关系用xpath语法表示的话就是用 / 分隔,比如我们要找 a 标签,xpath写法就是:div/a,或者 body/div/a。这种就类似我们的电脑上面文件路径表示方法,故而,xpath语法又叫xpath路径表达式。
看到上面这些,有的小伙伴可能会纳闷:既然找 a 标签,干嘛不直接写 a 就行了,怎么写这么多父子关系进行约束呢?是不是多此一举了?

没关系,看看下面这组代码图片:
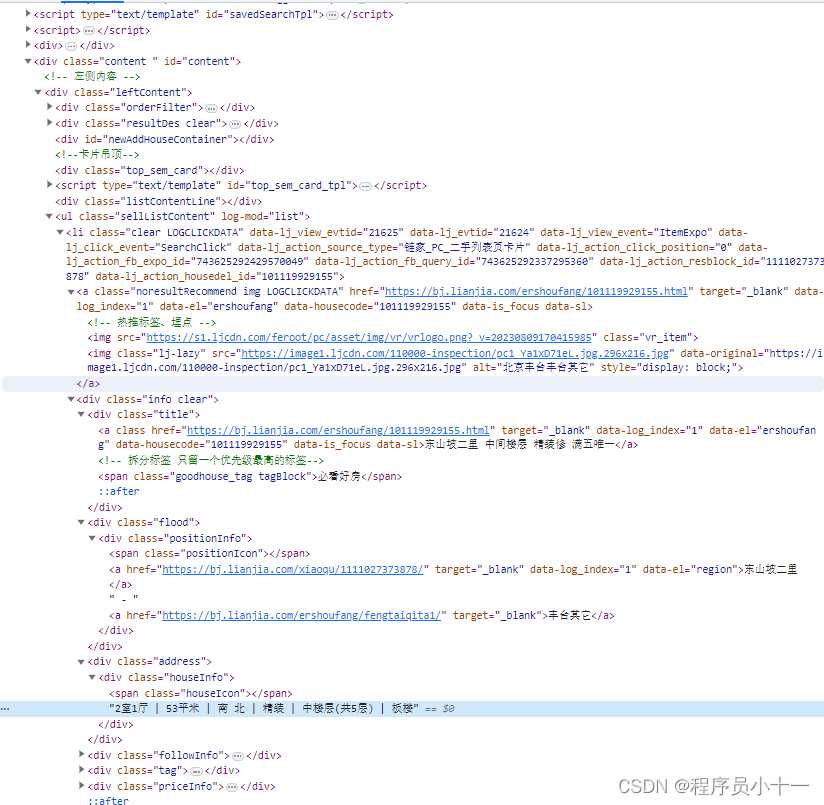
如果说要在上面这组代码中找到高亮显示的这行 “2室1厅 | 53平米 | 南 北 | 精装 | 中楼层(共5层) | 板楼” 文字,单单输入 span 标签能找到吗?显然不能,因为里面有多个 span 标签,所以,使用xpath路径表达式的用意,就是希望使用标签的父子关系约束,来精确定位到我们要找的那个标签。
讲了这么多,接下来我们就看看xpath路径表达式的常用规则。使用xpath规则匹配查找的源码如下:
<body><div><a href="/ershoufang/dongcheng/" title="北京东城在售二手房 ">东城</a><a href="/ershoufang/xicheng/" title="北京西城在售二手房 ">西城</a><a href="/ershoufang/chaoyang/" title="北京朝阳在售二手房 ">朝阳</a></div>
</body>
/ 表示两个相邻元素节点关系,也可以说父子关系
用法示例:如果要找上述代码中的 a 标签,路径表达式为:div/a
注意:如果当前查找出来的标签有多个,比如上面查找到的 a 标签有3个,我们想要第2个,写法就是 div/a[2],同理,我们需要第几个标签,就在标签后面加上[顺序值]
// 表示两个不相邻元素节点关系,也可以说爷孙这种隔代关系
用法示例:还是从上述代码中找 a 标签,路径表达式还可以写为:body//a
注意:// 也表示从任意位置开始检索,而不考虑它们的位置。xpath查找标签的顺序正常是从HTML文档头部开始查找,当一个HTML文档中标签非常多,我们查找的标签位于文档的中间某位置。如果直接从头部标签开始一级级往下检索,非常繁琐。用 “// + 标签名” 就相当于从该标签开始检索书写。比如我们还是要找 a 标签,可以写成 //a。
. 指代当前节点,比如xpath路径表达式找到某个元素后,想在此元素基础上往后面查找其他元素,那么前面的路径表达式就可以省略,用 . 替换
@ 选取属性,作用就是更精确定位某个标签
用法示例:比如上面我们正常查找的 a 标签是有3个,我们还是要找第2个 a 标签,已经学了一种方法就是 a 标签后面加上[顺序值]。但是如果 a 标签有几十个呢,我们就要一个个数顺序,很繁琐也容易出错。这时候就可以通过标签自身的属性值来精确定位某个标签。我们仔细可以看出上面的每个 a 标签里面的 href 和 title 两个属性值都是彼此不同的,那我们要找第2个,可以这样写://a[@href=“/ershoufang/xicheng/”] 或者 //a[@title="北京西城在售二手房 "]。格式就是:标签名[@属性名=属性值]
text() 提取标签中的文本内容
用法示例:上面的几种方式定位的都是某个标签,如果要拿到标签中的详细内容,比如要拿到第2个 a 标签的文本内容 “西城”这两个字,写法是://a[@title="北京西城在售二手房 "]/text()。格式是:标签/text()
注意:/text()一定要写在标签及标签属性值后面,因为属性值是修饰该标签的,可以精确定位到某个标签,其次后面才加/text(),表示该标签的文本内容。当然定位的标签如果无需属性值作为修饰即可找到,则直接就是标签名加上/text()。
@属性名 提取标签内指定属性名的属性值
用法示例:上面我们提取了标签的文本内容,但是有时候可能需要提取标签内的某个属性名对应的属性值。比如要提取第2个 a 标签中 title 的属性值 “北京西城在售二手房” 这句话,写法是://a[@title="北京西城在售二手房 "]/@title 或者 //a[2]/@title 都可以。格式是:标签/@属性名
以上就是开发中最常见的xpath表达式,记住这些对于日后解析爬虫来说就完全够用了。当然xpath还有许多其他路径表达式,有兴趣的小伙伴也可以额外探索。
五、xpath语法在Python代码中的使用
上面介绍的只是xpath路径表达式,但是如何实际在Python代码中使用呢?这就需要用到上面提到的依赖库 lxml 了。因为我们用爬虫抓取到的网页源码虽然是HTML文档,但是其实是字符串类型的数据,如下图抓取房源信息代码所示:
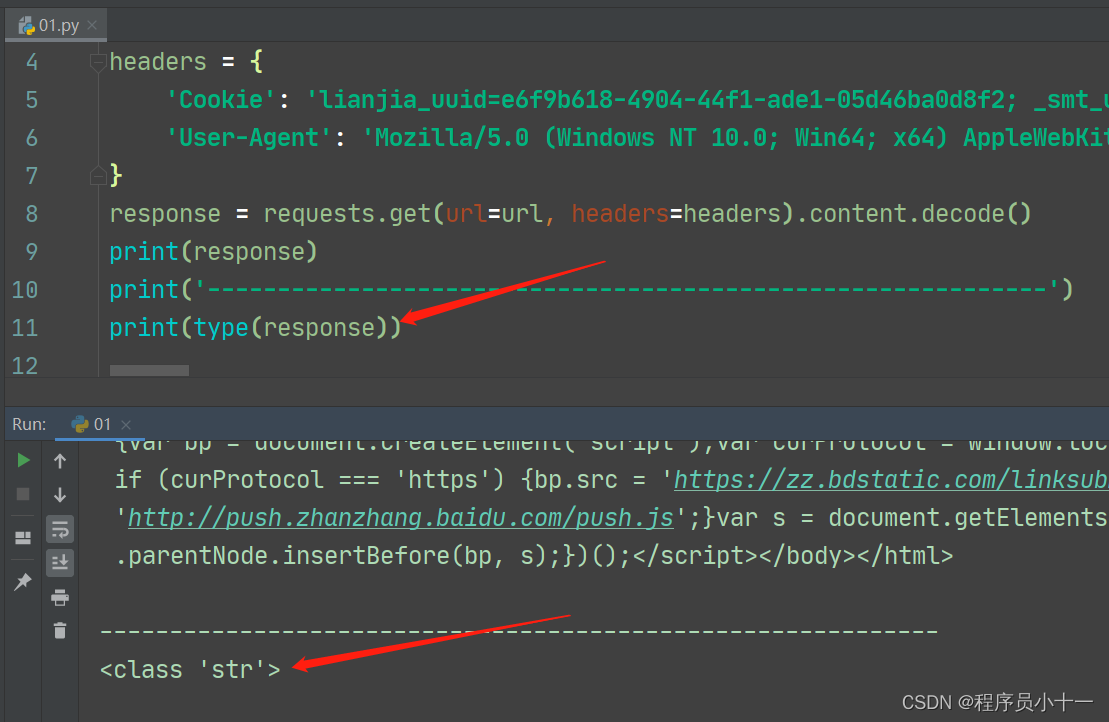
而xpath解析的是html或者lxml文档中的标签元素对象,不是字符串。我们就需要将抓到的字符串类型源码转换为html或者lxml文档中的标签元素对象,然后就可以正常使用xpath路径表达式进行解析查找。
如何将字符串内容转换成标签元素对象,要使用 lxml 库里面的 etree 模块中的 HTML() 方法,语法格式如下:
from lxml import etree # 导入 lxml 库中的 etree 模块
变量名 = etree.HTML(网页源码) # 使用 etree 模块的 HTML() 方法,括号中就是爬虫拿到的字符串类型的网页源码,将转换后的标签对象用变量保存
代码示例如下图所示:
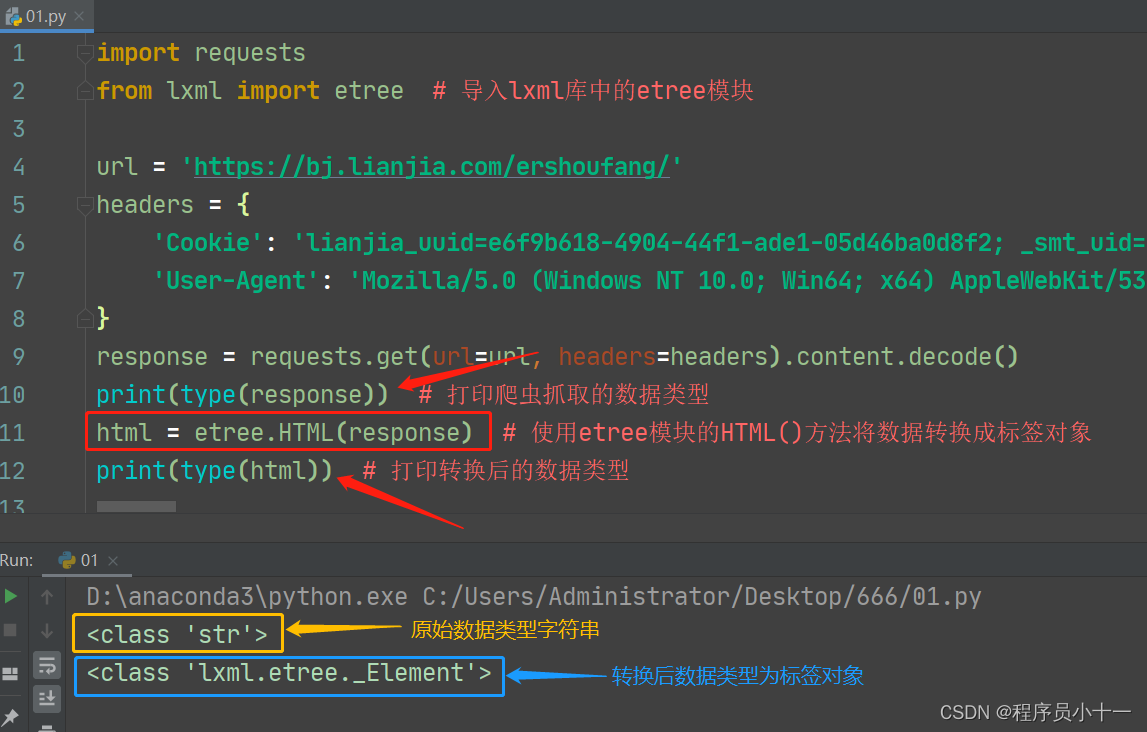
转换为标签元素对象之后,就可以正常使用上面介绍的xpath路径表达式了,语法格式如下:
标签元素对象.xpath('路径表达式') # 标签元素对象就是我们刚刚转换好的,括号里面的是双引号或者单引号都可以,包裹的就是路径表达式
代码示例如下图所示:
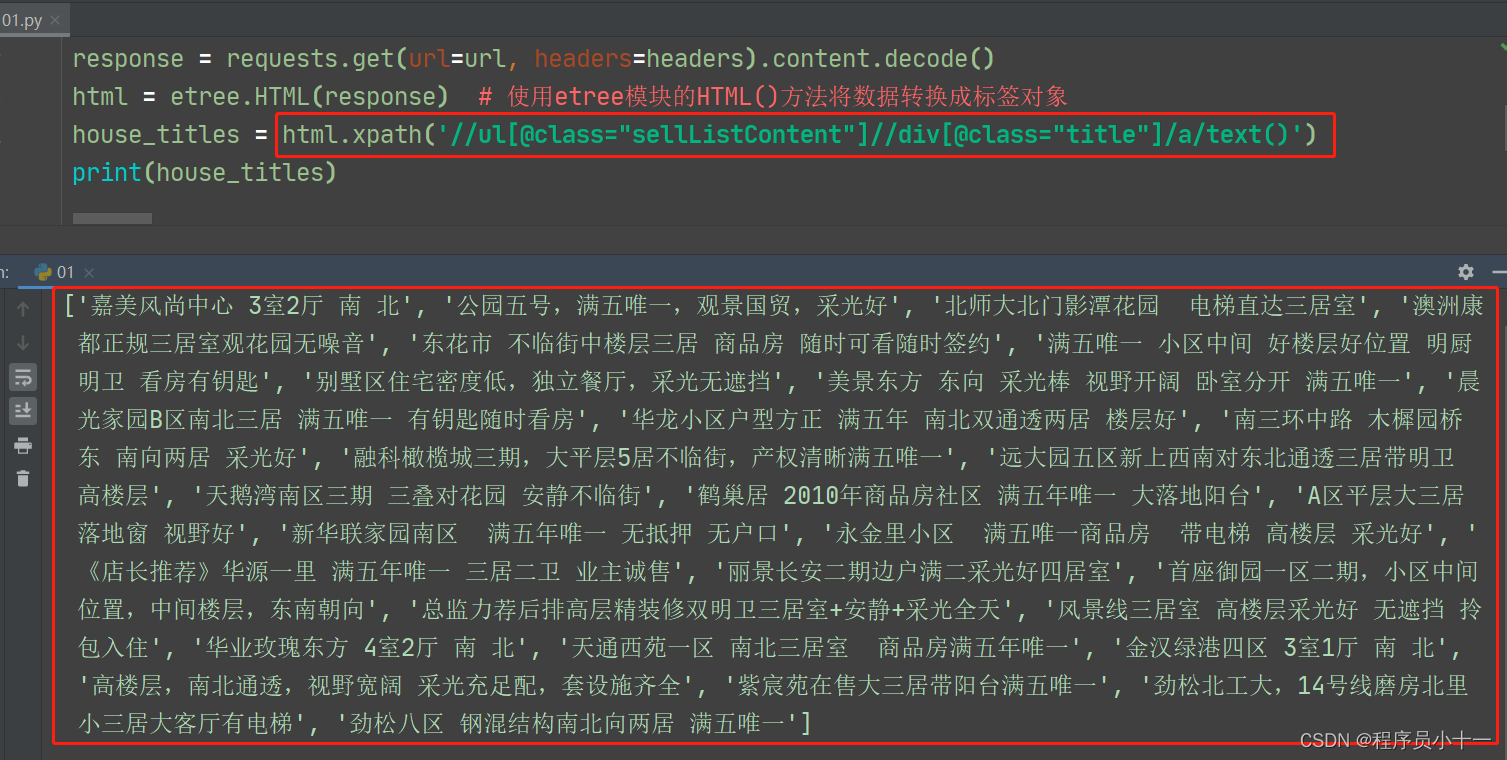
注意:在Python代码中,xpath路径表达式最终拿到的解析结果是以列表形式返回的,如果没有解析到目标数据,结果为空列表。
相关文章:
Python爬虫解析工具之xpath使用详解
文章目录 一、数据解析方式二、xpath介绍三、环境安装1. 插件安装2. 依赖库安装 四、xpath语法五、xpath语法在Python代码中的使用 一、数据解析方式 爬虫抓取到整个页面数据之后,我们需要从中提取出有价值的数据,无用的过滤掉。这个过程称为数据解析&a…...

Linux防火墙报错:Failed to start firewalld.service Unit is masked
Linux防火墙报错:Failed to start firewalld.service: Unit is masked. 1、故障现象: 启动防火墙失败,报错情况如下: systemctl start firewalld # 报错: Failed to start firewalld.service: Unit is masked.原因是…...

前端面试:【Vuex】Vue.js的状态管理利器
嗨,亲爱的Vuex探险家!在Vue.js开发的旅程中,有一个强大的状态管理库,那就是Vuex。Vuex是Vue.js的官方状态管理工具,通过State、Mutation、Action和Module等核心概念,协助你轻松管理应用的状态。 1. 什么是V…...
Kotlin协程runBlocking并发launch,Semaphore同步1个launch任务运行
Kotlin协程runBlocking并发launch,Semaphore同步1个launch任务运行 <dependency><groupId>org.jetbrains.kotlinx</groupId><artifactId>kotlinx-coroutines-core</artifactId><version>1.7.3</version><type>pom&…...

c++ Union之妙用
union的作用基本是它里面的变量都用了同一块内存,跟起了别名一样,类型不一样的别名。 基本用法: struct Union{union {float a;int b;};};Union u;u.a 2.0f;std::cout << u.a << "," << u.b << std::endl…...

JSON的处理
1、JSON JSON(JavaScript Object Notation):是一种轻量级的数据交换格式。 它是基于 ECMAScript 规范的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。 简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。易于人阅读和编写&#…...
matlab使用教程(20)—插值基础
1.网格和散点样本数据 插值是在位于一组样本数据点域中的查询位置进行函数值估算的方法。函数值是根据最接近查询点的样本数据点计算的。MATLAB 根据样本数据的结构,可以执行两种插值。样本数据可以形成网格,也可以是分散的。 网格化的样本数据使得插值…...
Python功能制作之简单的3D特效
需要导入的库: pygame: 这是一个游戏开发库,用于创建多媒体应用程序,提供了处理图形、声音和输入的功能。 from pygame.locals import *: 导入pygame库中的常量和函数,用于处理事件和输入。 OpenGL.GL: 这是OpenGL的Python绑定…...

leetcode-5-最长回文串
题目描述 给你一个字符串 s,找到 s 中最长的回文子串。 如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。 示例 1: 输入:s “babad” 输出:“bab” 解释:“aba” 同样是符合题意的答案。 示…...

二、Oracle 数据库安装集
一、CentOS 安装 OCI下载地址 1. 启动 # 1. 登录服务器,切换到oracle用户,或者以oracle用户登录 su - oracle# 2. 打开监听服务 lsnrctl start# 3. 查看Oracle监听器运行状况 lsnrctl status# 4. 以sys用户身份登录 sqlplus /nolog# 5. 切换用户conn 用…...

【Python】Python中的常用函数及用法
目录 输入输出类型转换引用哈希字符串常用操作判断类型查找替换大小写转换文本对齐去除空白字符拆分和连接 列表常用操作增删改查增删改统计排序 元组常用操作 字典常用操作 范围随机数学比较常用函数三角函数数学常量 输入 input():从键盘等待用户的输入࿰…...
基于JavaEE的ssm公司员工信息管理系统的设计与实现
基于JavaEE的ssm公司员工信息管理系统的设计与实现043 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存…...
)
cornerstoneJS加载图片(base、矩阵)
cornerstoneJS默认加载dicom影像数据,将识别到的dicom数据转换成imageData数据,在界面上展示。故,cornerstoneJS也可直接加载imageData。 imageData数据的data是一个数组,每四个元素代表一个点,四个元素分别表示R、G、…...
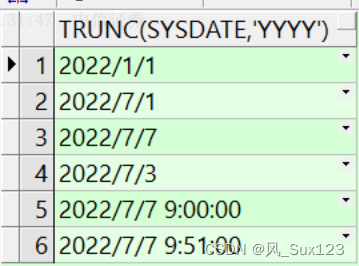
3.Trunc截断函数用法
TRUNC函数用于对值进行截断 用法有两种:TRUNC(NUMBER)表示截断数字,TRUNC(date)表示截断日期 (1)截断数字 格式:TRUNC(n1,n2),n1表示被截断的数字…...

腾讯云 CODING 荣获 TiD 质量竞争力大会 2023 软件研发优秀案例
点击链接了解详情 8 月 13-16 日,由中关村智联软件服务业质量创新联盟主办的第十届 TiD 2023 质量竞争力大会在北京国家会议中心召开。本次大会以“聚焦数字化转型 探索智能软件研发”为主题,聚焦智能化测试工程、数据要素、元宇宙、数字化转型、产融合作…...

VSCode如何为远程安装预设(固定)扩展
背景 在使用VSCode进行远程开发时(python开发之远程开发工具选择_CodingInCV的博客-CSDN博客),特别是远程的机器经常变化时(如机器来源于动态分配),每次连接新的远程时,都不得不手动安装一些开…...

一文解析HTTP与HTTPS,它们的区别和联系
一文解析HTTP与HTTPS,它们的区别和联系 HTTP和HTTPS之间不同点 尽管HTTP和HTTPS在安全性方面存在差异,但它们仍然共享许多相同的基本特征和功能。这些相同点使得HTTP成为广泛应用的标准协议,并且HTTPS作为更安全的替代方案被广泛采用。HTTP…...
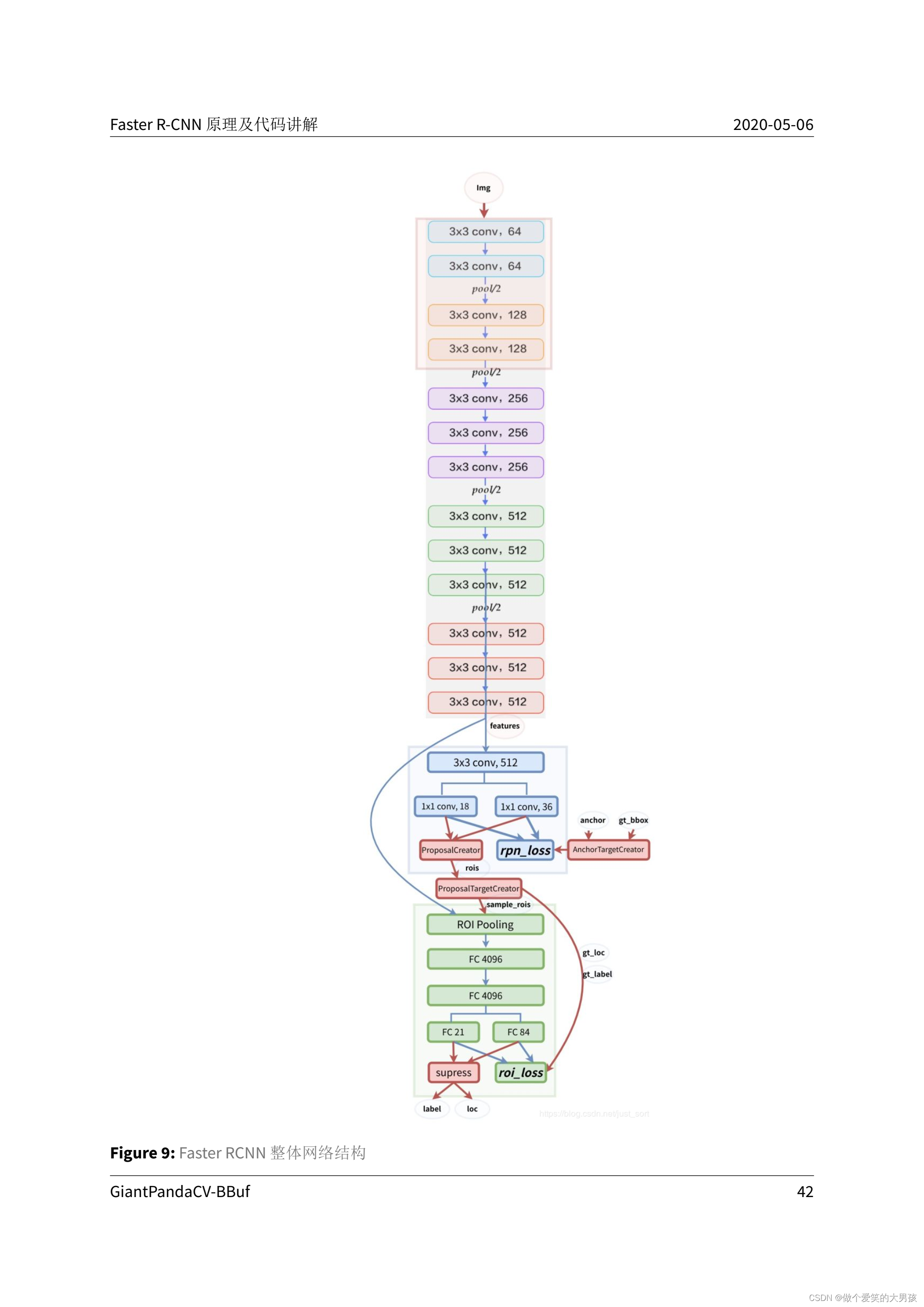
Faster RCNN网络数据流总结
前言 在学习Faster RCNN时,看了许多别人写的博客。看了以后,对Faster RCNN整理有了一个大概的了解,但是对训练时网络内部的数据流还不是很清楚,所以在结合这个版本的faster rcnn代码情况下,对网络数据流进行总结。以便…...

拒绝摆烂!C语言练习打卡第五天
🔥博客主页:小王又困了 📚系列专栏:每日一练 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、选择题 📝1.第一题 📝2.第二题 Ὅ…...
导致错误)
关于LambdaQueryWrapper.or()导致错误
这个是原始的代码,到导致一个问题,后面所有的内容,都在这个or的右边,也就是整个查询语句就这一个or,而很明显( xxx or xxx)and()这才是我们要的,所以需要将这…...

开放式耳机什么牌子好用又实惠?2026开放式耳机性价比推荐前十
如今开放式耳机早已不是“小众单品”,不入耳、不闷汗、能兼顾环境音的优势,让它成为通勤、运动、办公人群的首选。但大家选购时最纠结的问题始终是:开放式耳机什么牌子好用又实惠?市面上产品从百元到千元参差不齐,有的…...

工业视觉检测算法和系统 实时检测芯片引脚的缺陷 使用计算机视觉YOLOV8模型训练芯片缺陷检测数据集 识别检测芯片中的污染引脚 损坏引脚 划痕 自动识别引脚缺陷
工业视觉检测算法和系统 实时检测芯片引脚的缺陷 使用计算机视觉YOLOV8模型训练芯片缺陷检测数据集 识别检测芯片中的污染引脚 损坏引脚 划痕 自动识别引脚缺陷 文章目录芯片引脚缺陷数据集信息表数据集概述类别标签及样本分布统计表数据集特点总结✅ 一、环境搭建(…...

RTL8762DK蓝牙广播数据包全解析:从nRF Connect截图到SIG官网查表实战
RTL8762DK蓝牙广播数据包全解析:从nRF Connect截图到SIG官网查表实战 当你用nRF Connect扫描到一个RTL8762DK设备时,那一串看似天书的十六进制广播数据(Raw Data)背后隐藏着哪些秘密?本文将带你像侦探破案一样&#x…...

Noto Emoji终极指南:3步解决跨平台表情符号显示问题
Noto Emoji终极指南:3步解决跨平台表情符号显示问题 【免费下载链接】noto-emoji Noto Emoji fonts 项目地址: https://gitcode.com/gh_mirrors/no/noto-emoji 你是否曾在不同设备上看到同一个表情符号显示为"□□"乱码?或者在不同操作…...

面试之关系型数据库
数据库设计三范式第一范式。任何一张表必须有主键,每一个字段具有原子性不可再分。第二范式。所有非主键字段完全依赖主键字段,不存在部分依赖(复合主键可能存在此情况)。第三范式。所有非主键字段直接依赖于主键字段,…...

Kubescape命令行自动补全:提升安全扫描效率的技巧
Kubescape命令行自动补全:提升安全扫描效率的技巧 【免费下载链接】kubescape Kubescape is an open-source Kubernetes security platform for your IDE, CI/CD pipelines, and clusters. It includes risk analysis, security, compliance, and misconfiguration …...
)
3.3 直连进阶:群晖与PC万兆/2.5G直连配置全解(兼顾内网高速与外网访问)
1. 为什么需要群晖与PC直连? 家里有NAS的朋友应该都遇到过这样的场景:想从PC往群晖里传几个大文件,结果发现速度只有100MB/s左右,一个10GB的电影要传将近两分钟。这其实就是千兆网络的瓶颈在作祟。传统的千兆网络理论速度是125MB…...

开源远程开发者职位目录:架构设计与社区驱动实践
1. 项目概述:一份远程开发者工作目录的诞生与价值 如果你是一名开发者,并且正在寻找一份可以摆脱地理限制、拥抱灵活工作方式的远程职位,那么你很可能已经体会过在各大招聘网站、社交媒体和零散论坛中“大海捞针”的痛苦。信息分散、质量参差…...

OpenClaw QQ机器人一键接入指南
准备工作 软件环境 已成功安装并运行 OpenClaw Windows 版本OpenClaw Gateway 运行状态正常(建议保持在线状态) 账号准备 已准备好有效的 QQ 账号(用于平台扫码登录)已安装 QQ 手机客户端(用于扫码登录及机器人功…...

Windows窗口置顶终极指南:PinWin让你的多任务处理效率翻倍
Windows窗口置顶终极指南:PinWin让你的多任务处理效率翻倍 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin 你是否曾因频繁切换窗口而打断工作流程?是否需要在多…...