GO——接口(下)
接口
- 接口值
- 警告:一个包含空指针值的接口不是nil接口
- `sort.Interface`接口
- `http.Handler`接口
- 类型断言
- 类型分支
接口值
接口值,由两个部分组成,一个具体的类型和那个类型的值。它们被称为接口的动态类型和动态值。对于像Go语言这种静态类型的语言,类型是编译期的概念;因此一个类型不是一个值。在我们的概念模型中,一些提供每个类型信息的值被称为类型描述符,比如类型的名称和方法。在一个接口值中,类型部分代表与之相关类型的描述符。
var w io.Writer
w = os.Stdout
w = new(bytes.Buffer)
w = nil
-
第一个语句定义了变量w:
var w io.Writer变量总是被一个定义明确的值初始化,即使接口类型也不例外。对于一个接口的零值就是它的类型和值的部分都是nil。
-
第二个语句将一个
*os.File类型的值赋给变量w:w = os.Stdout这个赋值过程调用了一个具体类型到接口类型的隐式转换,这和显式的使用
io.Writer(os.Stdout)是等价的。这类转换不管是显式的还是隐式的,都会刻画出操作到的类型和值。这个接口值的动态类型被设为*os.File指针的类型描述符,它的动态值持有os.Stdout的拷贝;这是一个代表处理标准输出的os.File类型变量的指针。调用一个包含
*os.File类型指针的接口值的Write方法,使得(*os.File).Write方法被调用。效果和下面这个直接调用一样:
os.Stdout.Write([]byte("hello")) // "hello"
接口值可以使用和!=来进行比较。两个接口值相等仅当它们都是nil值,或者它们的动态类型相同并且动态值也根据这个动态类型的操作相等。因为接口值是可比较的,所以它们可以用在map的键或者作为switch语句的操作数。
然而,如果两个接口值的动态类型相同,但是这个动态类型是不可比较的(比如切片),将它们进行比较就会失败并且panic
当我们处理错误或者调试的过程中,得知接口值的动态类型是非常有帮助的。所以我们使用fmt包的%T动作:
var w io.Writer
fmt.Printf("%T\n", w) // "<nil>"
w = os.Stdout
fmt.Printf("%T\n", w) // "*os.File"
警告:一个包含空指针值的接口不是nil接口
关键:一个接口只有动态类型和动态值都是nil,对其进行==nil判断时才为true,否则为false。
针对赋值的时候,如果两者类型不同,那么即使传入的值是nil,但是被赋值(接口)的动态类型会被更改为传入的类型。
比如:
const debug = truefunc main() {var buf *bytes.Bufferif debug {buf = new(bytes.Buffer) // enable collection of output}f(buf) // NOTE: subtly incorrect!if debug {// ...use buf...}
}// If out is non-nil, output will be written to it.
func f(out io.Writer) {// ...do something...if out != nil {out.Write([]byte("done!\n"))}
}
此时如果debug=false,那么调用函数f()时,传入的类型是*bytes.Buffer,与参数类型不一致,那么此时out的动态类型就是*bytes.Buffer。根据前文所说,接口的动态类型不为空,那么此时out!=nil就为true,而不是预期的false了。
修改方式如下:
var buf io.Writer
此时调用f()方法时,传入的类型与参数类型一致,所以此时的out动态类型和动态值都是nil,也就不会出现问题了。
sort.Interface接口
一个内置的排序算法需要知道三个东西:序列的长度,表示两个元素比较的结果,一种交换两个元素的方式;这就是sort.Interface的三个方法:
package sorttype Interface interface {Len() intLess(i, j int) bool // i, j are indices of sequence elementsSwap(i, j int)
}
按照一种类型的某个值排序:
type byArtist []*Track
func (x byArtist) Len() int { return len(x) }
func (x byArtist) Less(i, j int) bool { return x[i].Artist < x[j].Artist }
func (x byArtist) Swap(i, j int) { x[i], x[j] = x[j], x[i] }sort.Sort(byArtist(tracks))
对tracks进行逆向排序。然而我们不需要定义一个有颠倒Less方法的新类型byReverseArtist,因为sort包中提供了Reverse函数将排序顺序转换成逆序。Z
sort.Sort(sort.Reverse(byArtist(tracks)))
sort包定义了一个不公开的struct类型reverse,它嵌入了一个sort.Interface。reverse的Less方法调用了内嵌的sort.Interface值的Less方法,但是通过交换索引的方式使排序结果变成逆序。
package sorttype reverse struct{ Interface } // that is, sort.Interfacefunc (r reverse) Less(i, j int) bool { return r.Interface.Less(j, i) }func Reverse(data Interface) Interface { return reverse{data} }
对于我们需要的每个切片元素类型和每个排序函数,我们需要定义一个新的sort.Interface实现。
Len和Swap方法对于所有的切片类型都有相同的定义。下个例子,具体的类型customSort会将一个切片和函数结合,使我们只需要写比较函数就可以定义一个新的排序。
type customSort struct {t []*Trackless func(x, y *Track) bool
}func (x customSort) Len() int { return len(x.t) }
func (x customSort) Less(i, j int) bool { return x.less(x.t[i], x.t[j]) }
func (x customSort) Swap(i, j int) { x.t[i], x.t[j] = x.t[j], x.t[i] }sort.Sort(customSort{tracks, func(x, y *Track) bool {if x.Title != y.Title {return x.Title < y.Title}if x.Year != y.Year {return x.Year < y.Year}if x.Length != y.Length {return x.Length < y.Length}return false
}})
sort包中的IsSorted函数帮我们做这样的检查。
values := []int{3, 1, 4, 1}
fmt.Println(sort.IntsAreSorted(values)) // "false"
//对ints排序
sort.Ints(values)
fmt.Println(values) // "[1 1 3 4]"
fmt.Println(sort.IntsAreSorted(values)) // "true"
//对int切片排序
sort.Sort(sort.Reverse(sort.IntSlice(values)))
fmt.Println(values) // "[4 3 1 1]"
fmt.Println(sort.IntsAreSorted(values)) // "false"
http.Handler接口
package httptype Handler interface {ServeHTTP(w ResponseWriter, r *Request)
}func ListenAndServe(address string, h Handler) error
ListenAndServe函数需要一个例如“localhost:8000”的服务器地址,和一个所有请求都可以分派的Handler接口实例。它会一直运行,直到这个服务因为一个错误而失败(或者启动失败),它的返回值一定是一个非空的错误。
func main() {db := database{"shoes": 50, "socks": 5}log.Fatal(http.ListenAndServe("localhost:8000", db))
}type dollars float32func (d dollars) String() string {return fmt.Sprintf("$%.2f", d)
}type database map[string]dollarsfunc (db database) ServeHTTP(w http.ResponseWriter, req *http.Request) {for item, price := range db {fmt.Fprintf(w, "%s:%s", item, price)}
}
满足同一接口的不同类型是可替换的。
显然我们可以继续向ServeHTTP方法中添加case,但在一个实际的应用中,将每个case中的逻辑定义到一个分开的方法或函数中会很实用。net/http包提供了一个请求多路器ServeMux来简化URL和handlers的联系。一个ServeMux将一批http.Handler聚集到一个单一的http.Handler中。
func main3() {db := database{"shoes": 50, "socks": 5}mux := http.NewServeMux()mux.Handle("/list", http.HandlerFunc(db.list))mux.Handle("price", http.HandlerFunc(db.price))log.Fatal(http.ListenAndServe("localhost:8000", mux))
}func (db database) list(w http.ResponseWriter, req *http.Request) {for item, price := range db {fmt.Fprintf(w, "%s:%s\n", item, price)}
}func (db database) price(w http.ResponseWriter, req *http.Request) {item := req.URL.Query().Get("item")price, ok := db[item]if !ok {w.WriteHeader(http.StatusNotFound)fmt.Fprintf(w, "no such item:%q\n", item)return}fmt.Fprintf(w, "%s\n", price)
}
语句http.HandlerFunc(db.list)是一个转换而非一个函数调用,因为http.HandlerFunc是一个类型。它有如下的定义:
package httptype HandlerFunc func(w ResponseWriter, r *Request)func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {f(w, r)
}
ServeHTTP方法的行为是调用了它的函数本身。因此HandlerFunc是一个让函数值满足一个接口的适配器,这里函数和这个接口仅有的方法有相同的函数签名。
net/http包提供了一个全局的ServeMux实例DefaultServerMux和包级别的http.Handle和http.HandleFunc函数。现在,为了使用DefaultServeMux作为服务器的主handler,我们不需要将它传给ListenAndServe函数;nil值就可以工作。相当于就是如果我们不给ListenAndServe函数传入特定的ServerMux,或者直接调用http.HandlerFunc函数的话,就会去使用特定的全局ServerMux实例。
类型断言
类型断言是一个使用在接口值上的操作。语法上它看起来像x.(T)被称为断言类型,这里x表示一个接口的类型和T表示一个类型。一个类型断言检查它操作对象的动态类型是否和断言的类型匹配。类型断言检查x的动态值类型是否和T相同,返回结果的真实值是x的动态值,类型改为T。
这里有两种可能:
第一种,如果断言的类型T是一个具体类型,然后类型断言检查x的动态类型是否和T相同。换句话说,具体类型的类型断言从它的操作对象中获得具体的值。如果检查失败,接下来这个操作会抛出panic。例如:
var w io.Writer
w = os.Stdout
f := w.(*os.File) // success: f == os.Stdout
c := w.(*bytes.Buffer) // panic: interface holds *os.File, not *bytes.Buffer
第二种,如果断言的类型T是一个接口类型,然后类型断言检查是否x的动态类型满足T。
对一个接口类型的类型断言改变了类型的表述方式,改变了可以获取的方法集合(通常更大),但是它保留了接口值内部的动态类型和值的部分。在下面的第一个类型断言后,w和rw都持有os.Stdout,因此它们都有一个动态类型*os.File,但是变量w是一个io.Writer类型,只对外公开了文件的Write方法,而rw变量还公开了它的Read方法。
var w io.Writer
w = os.Stdout
rw := w.(io.ReadWriter) // success: *os.File has both Read and Write
w = new(ByteCounter)
rw = w.(io.ReadWriter) // panic: *ByteCounter has no Read method
经常地,对一个接口值的动态类型我们是不确定的,并且我们更愿意去检验它是否是一些特定的类型。如果类型断言出现在一个预期有两个结果的赋值操作中,例如如下的定义,这个操作不会在失败的时候发生panic,但是替代地返回一个额外的第二个结果,这个结果是一个标识成功与否的布尔值:
var w io.Writer = os.Stdout
f, ok := w.(*os.File) // success: ok, f == os.Stdout
b, ok := w.(*bytes.Buffer) // failure: !ok, b == nil
第二个结果通常赋值给一个命名为ok的变量。如果这个操作失败了,那么ok就是false值,第一个结果等于被断言类型的零值,在这个例子中就是一个nil的*bytes.Buffer类型。
这个ok结果经常立即用于决定程序下面做什么。if语句的扩展格式让这个变的很简洁:
if f, ok := w.(*os.File); ok {// ...use f...
}
例子:
func writeString(w io.Writer, s string) (n int, err error) {type stringWriter interface {WriteString(string) (n int, err error)}if sw, ok := w.(stringWriter); ok {return sw.WriteString(s) // avoid a copy}return w.Write([]byte(s)) // allocate temporary copy
}
满足以下接口即可调用:
interface {io.WriterWriteString(s string) (n int, err error)
}
类型分支
接口被以两种不同的方式使用。
在第一个方式中,以io.Reader,io.Writer,fmt.Stringer,sort.Interface,http.Handler和error为典型,一个接口的方法表达了实现这个接口的具体类型间的相似性,但是隐藏了代码的细节和这些具体类型本身的操作。重点在于方法上,而不是具体的类型上。
第二个方式是利用一个接口值可以持有各种具体类型值的能力,将这个接口认为是这些类型的联合。类型断言用来动态地区别这些类型,使得对每一种情况都不一样。在这个方式中,重点在于具体的类型满足这个接口,而不在于接口的方法(如果它确实有一些的话),并且没有任何的信息隐藏。我们将以这种方式使用的接口描述为discriminated unions(可辨识联合)。
一个类型分支像普通的switch语句一样,它的运算对象是x.(type)——它使用了关键词字面量type——并且每个case有一到多个类型。一个类型分支基于这个接口值的动态类型使一个多路分支有效。
switch x.(type) {
case nil: // ...
case int, uint: // ...
case bool: // ...
case string: // ...
default: // ...
}
常见用法:
将提取的值绑定到一个在每个case范围内都有效的新变量。
switch x := x.(type) { /* ... */ }
也就是说当匹配到具体某个单一类型case的时候,变量x和这个case的类型相同
例如:
func sqlQuote(x interface{}) string {switch x := x.(type) {case nil:return "NULL"case int, uint:return fmt.Sprintf("%d", x) // x has type interface{} here.case bool:if x {return "TRUE"}return "FALSE"case string:return sqlQuoteString(x) // (not shown)default:panic(fmt.Sprintf("unexpected type %T: %v", x, x))}
}
变量x在bool的case中是bool类型,在string的case中是string类型。
相关文章:
)
GO——接口(下)
接口接口值警告:一个包含空指针值的接口不是nil接口sort.Interface接口http.Handler接口类型断言类型分支接口值 接口值,由两个部分组成,一个具体的类型和那个类型的值。它们被称为接口的动态类型和动态值。对于像Go语言这种静态类型的语言&…...
计算机网络之http02| HTTPS HTTP1.1的优化
post与get请求的区别 get 是获取资源,Post是向指定URI提交资源,相关信息放在body里 2.http有哪些优点 (1)简单 报文只有报文首部和报文主体,易于理解 (2)灵活易拓展 URI相应码、首部字段都没有…...

基于matlab使用神经网络清除海杂波
一、前言此示例演示如何使用深度学习工具箱™训练和评估卷积神经网络,以消除海上雷达 PPI 图像中的杂波返回。深度学习工具箱提供了一个框架,用于设计和实现具有算法、预训练模型和应用程序的深度神经网络。二、数据集该数据集包含 84 对合成雷达图像。每…...

每天10个前端小知识 【Day 8】
前端面试基础知识题 1. Javascript中如何实现函数缓存?函数缓存有哪些应用场景? 函数缓存,就是将函数运算过的结果进行缓存。本质上就是用空间(缓存存储)换时间(计算过程), 常用于…...
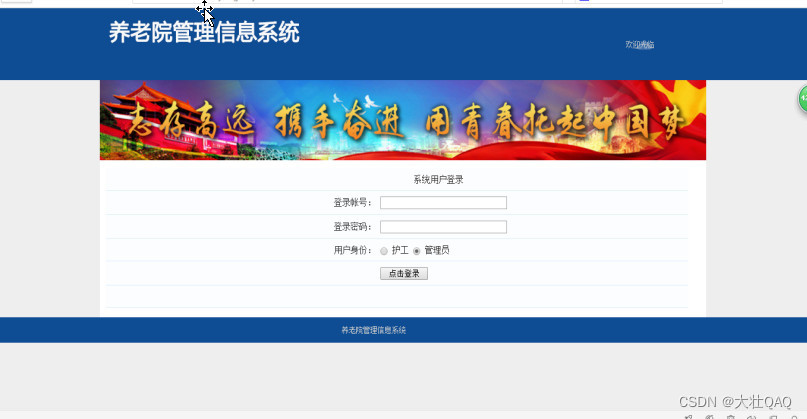
【项目精选】基于Java的敬老院管理系统的设计和实现
本系统主要是针对敬老院工作人员即管理员和员工设计的。敬老院管理系统 将IT技术为养老院提供一个接口便于管理信息,存储老人个人信息和其他信息,查找 和更新信息的养老院档案,节省了员工的劳动时间,大大降低了成本。 其主要功能包括: 系统管理员用户功能介绍&#…...
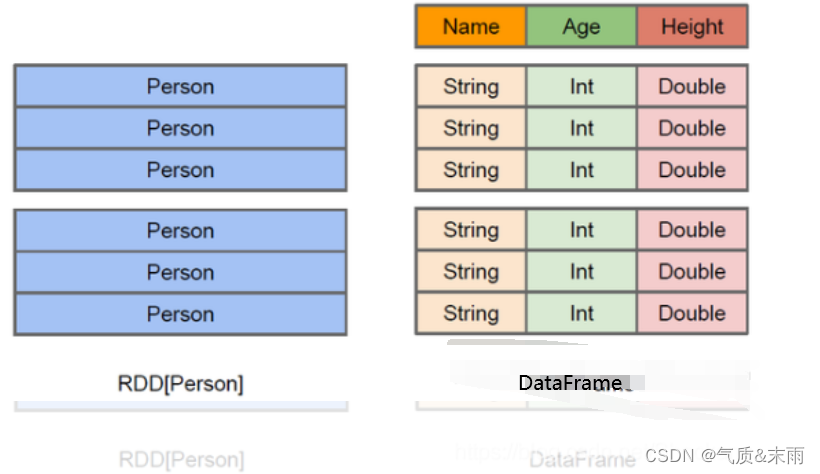
Spark SQL 介绍
文章目录Spark SQL1、Hive on SparkSQL2、SparkSQL 优点3、SparkSQL 特点1) 容易整合2) 统一的数据访问3) 兼容 Hive4) 标准的数据连接4、DataFrame 是什么5、DataSet 是什么Spark SQL Spark SQL 是 Spark 用于结构化数据(structured data) 处理的Spark模块。 1、Hive on Spa…...

升级到 CDP 后Hive on Tez 性能调整和故障排除指南
优化Hive on Tez查询永远不能以一种万能的方法来完成。查询的性能取决于数据的大小、文件类型、查询设计和查询模式。在性能测试期间,要评估和验证配置参数和任何 SQL 修改。建议在工作负载的性能测试期间一次进行一项更改,并且最好在生产环境中使用它们…...

理解HDFS工作流程与机制,看这篇文章就够了
HDFS(The Hadoop Distributed File System) 是最初由Yahoo提出的分布式文件系统,它主要用来: 1)存储大数据 2)为应用提供大数据高速读取的能力 重点是掌握HDFS的文件读写流程,体会这种机制对整个分布式系统性能提升…...

Intel处理器分页机制
分页模式 Intel 64位处理器支持3种分页模式: 32-bit分页PAE分页IA-32e分页 32-bit分页 32-bit分页模式支持两种页面大小:4KB以及4MB。 4KB页面的线性地址转换 4MB页面的线性地址转换 PAE分页模式 PAE分页模式支持两种页面大小:4KB以及…...
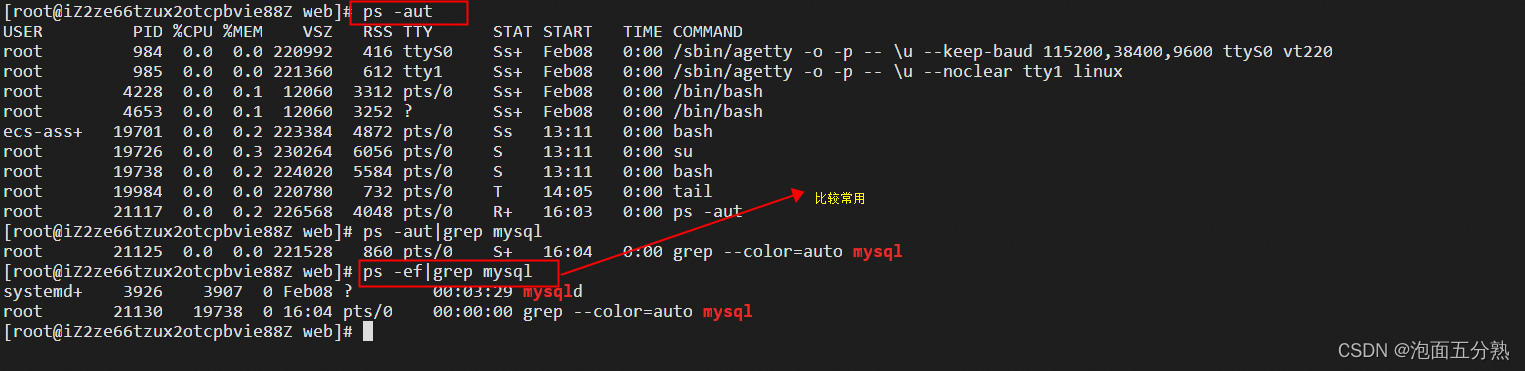
Linux常用命令
linux常用命令创建一个目录mkdir 命令可以创建新目录。mkdir 是 make directory 的缩写。[rootiZ2ze66tzux2otcpbvie88Z ~]# ls [rootiZ2ze66tzux2otcpbvie88Z ~]# mkdir web [rootiZ2ze66tzux2otcpbvie88Z ~]# ls web [rootiZ2ze66tzux2otcpbvie88Z ~]# 创建一个文件2.1 在 Li…...

基于STM32设计的音乐播放器
一、项目背景与设计思路 1.1 项目背景 时代进步,科学技术的不断创新,促进电子产品的不断更迭换代,各种新功能和新技术的电子产品牵引着消费者的眼球。人们生活水平的逐渐提高,对娱乐消费市场需求日益扩大,而其消费电子产品在市场中的占有份额越来越举足轻重。目前消费电…...

微服务开发
目录 微服务配置管理 权限认证 批处理 定时任务 异步 微服务调用 (协议)...
【(C语言)数据结构奋斗100天】二叉树(上)
【(C语言)数据结构奋斗100天】二叉树(上) 🏠个人主页:泡泡牛奶 🌵系列专栏:数据结构奋斗100天 本期所介绍的是二叉树,那么什么是二叉树呢?在知道答案之前,请大家思考一下…...
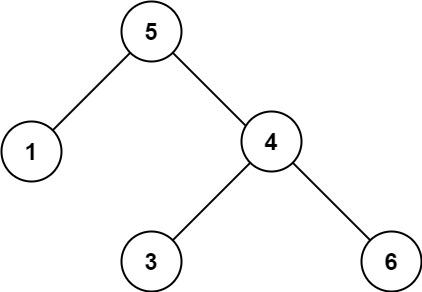
Java 验证二叉搜索树
验证二叉搜索树中等给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。有效 二叉搜索树定义如下:节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。示例 1&…...

C/C++单项选择题标准化考试系统[2023-02-09]
C/C单项选择题标准化考试系统[2023-02-09] ©3.17 单项选择题标准化考试系统 【难度系数】5级 【任务描述】 设计一个单项选择题的考试系统,可实现试题维护、自动组卷等功能。 【功能描述】 (1)管理员功能: 试题管理:每个试题包括题干、四个备选答案标准答案…...
爱了爱了,这些顶级的 Python 工具包太棒了
Python 语言向来以丰富的第三方库而闻名,今天来介绍几个非常nice的库,有趣好玩且强大!推荐好好学习。 文章目录技术交流数据采集AKShareTuShareGoPUPGeneralNewsExtractor爬虫playwright-pythonawesome-python-login-modelDecryptLoginScylla…...
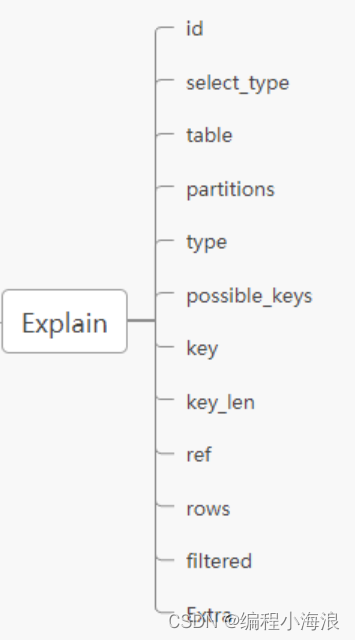
【Explain详解与索引优化最佳实践】
摘要 explain命令是查看MySQL查询优化器如何执行查询的主要方法,可以很好的分析SQL语句的执行情况。每当遇到执行慢(在业务角度)的SQL,都可以使用explain检查SQL的执行情况,并根据explain的结果相应的去调优SQL等。 …...
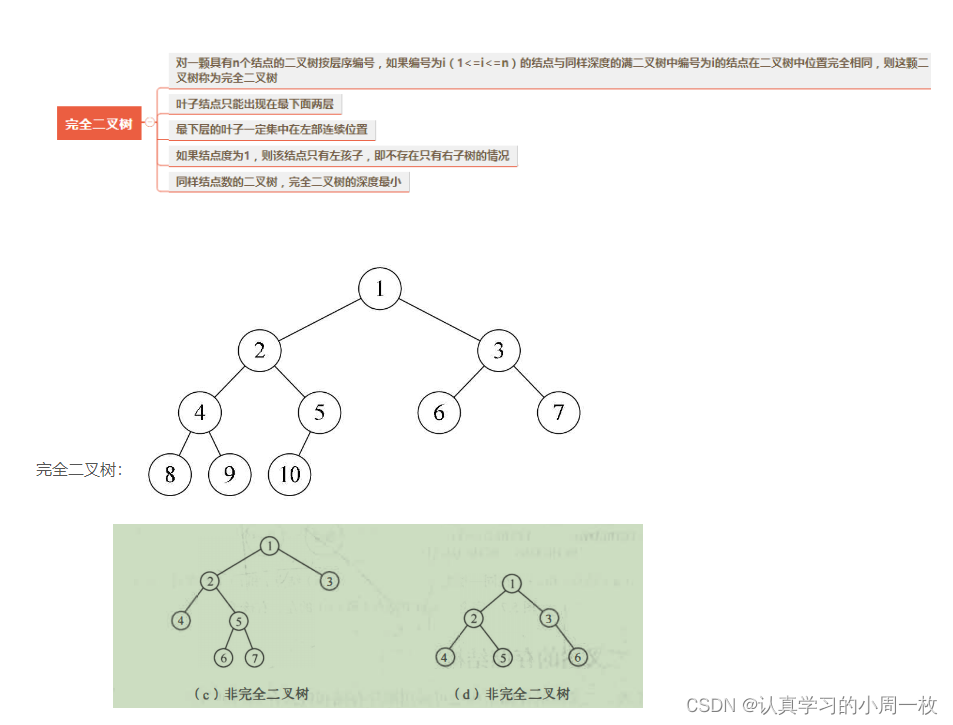
【树和二叉树】数据结构二叉树和树的概念认识
前言:在之前,我们已经把栈和队列的相关概念以及实现的方法进行了学习,今天我们将认识一个新的知识“树”!!! 目录1.树概念及结构1.1树的概念1.2树的结构1.3树的相关概念1.4 树的表示1.5 树在实际中的运用&a…...

通达信收费接口查询可申购新股c++源码分享
有很多股民在做股票交易时为了实现盈利会借助第三三方炒股工具帮助自己,那么通达信收费接口就是人们常用到的,今天小编来分享一下通达信收费接口查询可申购新股c源码: std::cout << " 查询可申购新股: category 12 \n"; c…...
。)
【C#设计模式】创建型设计模式 (单例,工厂)。
c# 创建型设计模式 1.单例设计模式c# 单例JS 单例(ES6)c# 扩展方法c# 如果窗体非单例(tips:窗口可以容器化)2.工厂设计模式JS 简单工厂(ES6)C# 简单工厂C# params关键词(自定义参数个数)JS 手写JQuery(委托,工厂方式隐藏细节)JS ...四种用法C# 偷懒工厂1.单例设计模式 …...

osModa:基于NixOS与AI智能体的下一代服务器操作系统
1. 项目概述:为AI智能体而生的操作系统如果你和我一样,长期在服务器运维和AI应用部署的一线摸爬滚打,那你一定对这样的场景深有体会:凌晨三点,手机突然响起刺耳的告警,你睡眼惺忪地爬起来,SSH连…...
图神经网络与图Transformer在计算机视觉中的原理、应用与实战
1. 引言:当视觉任务遇上“关系”思维在计算机视觉领域,我们早已习惯了卷积神经网络(CNN)的统治地位。从ImageNet的图像分类,到Mask R-CNN的实例分割,CNN凭借其强大的局部特征提取能力,在像素网格…...
)
保姆级教程:用正点原子MFG_TOOL给I.MX6U开发板烧录出厂系统(附常见问题排查)
嵌入式Linux开发板系统烧录全流程指南:从零开始到成功启动 第一次拿到嵌入式开发板时的兴奋感,往往会被复杂的系统烧录过程冲淡不少。特别是对于刚接触嵌入式Linux的开发者来说,如何把系统镜像正确烧录到开发板上,常常成为第一个需…...

从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机
从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机 虚拟样机技术正在彻底改变传统机电系统的开发流程。想象一下,你刚刚在SolidWorks中完成了一个精巧的自动门闭锁装置的设计,现在不需要花费数周时间加工金…...

chatgpt.js:纯客户端集成ChatGPT,构建浏览器AI应用实战
1. 项目概述:一个专为浏览器环境打造的ChatGPT交互库如果你是一名前端开发者,或者经常需要在自己的网页项目中集成智能对话功能,那么你一定对调用大型语言模型的API不陌生。传统的做法是,在自己的后端服务器上封装一个接口&#x…...

RapidIO多播技术原理与应用实践
1. RapidIO多播技术概述 在分布式计算和高速互连系统中,多播(Multicast)技术扮演着至关重要的角色。简单来说,多播就像是在会议室里用广播系统发布通知——只需说一次,所有打开扬声器的房间都能同时听到。RapidIO作为高…...

别再盲目刷LeetCode了!先把这5个编程基础打牢
文章目录前言一、代码规范:不是“洁癖”,是保命的底线二、函数式编程:不是玄学,是现代开发的通用语言三、Python基础工具:sys模块与可变参数,效率提升10倍的利器四、任务拆解能力:从“写代码”到…...

FastGithub终极提速方案:3步让GitHub访问速度翻倍
FastGithub终极提速方案:3步让GitHub访问速度翻倍 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub 对于开发者而言,GitHub访问缓慢已经成为日常开…...
)
别再死记公式了!用Python的NumPy和Matplotlib玩转坐标转换(附象限处理代码)
用Python实战坐标转换:从数学公式到可视化应用 坐标转换是计算机图形学、机器人学和数据可视化中的基础操作。传统教学中,我们往往被要求死记硬背转换公式,却很少有机会直观理解其实际应用场景。本文将带你用NumPy和Matplotlib这两个Python利…...

从内核恐慌到系统恢复:一次NMI watchdog触发的soft lockup深度诊断
1. 当服务器突然卡死:从NMI watchdog错误说起 那天下午3点,机房警报突然响起。我冲到服务器前,屏幕上赫然显示着刺眼的红色错误:"NMI watchdog: BUG: soft lockup - CPU#2 stuck for 23s!"。这台承载着核心业务的服务器…...