自然语言处理从入门到应用——LangChain:链(Chains)-[通用功能:链的保存(序列化)与加载(反序列化)]
分类目录:《自然语言处理从入门到应用》总目录
本文介绍了如何将链保存(序列化)到磁盘和从磁盘加载(反序列化)。我们使用的序列化格式是json或yaml。目前,只有一些链支持这种类型的序列化。随着时间的推移,我们将增加支持的链条数量。
将链保存(序列化)到磁盘
首先,让我们可以使用.save方法将链保存到磁盘,并指定一个带有json或yaml扩展名的文件路径。
from langchain import PromptTemplate, OpenAI, LLMChain
template = """Question: {question}Answer: Let's think step by step."""
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(prompt=prompt, llm=OpenAI(temperature=0), verbose=True)llm_chain.save("llm_chain.json")
现在让我们来看看保存的文件中的内容:
!cat llm_chain.json
输出:
{"memory": null,"verbose": true,"prompt": {"input_variables": ["question"],"output_parser": null,"template": "Question: {question}\n\nAnswer: Let's think step by step.","template_format": "f-string"},"llm": {"model_name": "text-davinci-003","temperature": 0.0,"max_tokens": 256,"top_p": 1,"frequency_penalty": 0,"presence_penalty": 0,"n": 1,"best_of": 1,"request_timeout": null,"logit_bias": {},"_type": "openai"},"output_key": "text","_type": "llm_chain"
}
从磁盘加载(反序列化)链
我们可以使用load_chain方法从磁盘加载链:
from langchain.chains import load_chain
chain = load_chain("llm_chain.json")
chain.run("whats 2 + 2")
日志输出:
> Entering new LLMChain chain...
Prompt after formatting:
Question: whats 2 + 2Answer: Let's think step by step.> Finished chain.
输出:
' 2 + 2 = 4'
分别保存组件
在上面的例子中我们可以看到提示和LLM配置信息与整个链条保存在同一个json中,但我们也可以将它们分开保存。这通常有助于使保存的组件更加模块化。为了做到这一点,我们只需要指定llm_path而不是llm组件,并且指定prompt_path而不是prompt组件。
llm_chain.prompt.save("prompt.json")
输入:
!cat prompt.json
输出:
{"input_variables": ["question"],"output_parser": null,"template": "Question: {question}\n\nAnswer: Let's think step by step.","template_format": "f-string"
}
输入:
llm_chain.llm.save("llm.json")
输入:
!cat llm.json
输出:
{"model_name": "text-davinci-003","temperature": 0.0,"max_tokens": 256,"top_p": 1,"frequency_penalty": 0,"presence_penalty": 0,"n": 1,"best_of": 1,"request_timeout": null,"logit_bias": {},"_type": "openai"
}
输入:
config = {"memory": None,"verbose": True,"prompt_path": "prompt.json","llm_path": "llm.json","output_key": "text","_type": "llm_chain"
}import jsonwith open("llm_chain_separate.json", "w") as f:json.dump(config, f, indent=2)
输入:
!cat llm_chain_separate.json
输出:
{"memory": null,"verbose": true,"prompt_path": "prompt.json","llm_path": "llm.json","output_key": "text","_type": "llm_chain"
}
我们可以以相同的方式加载它:
chain = load_chain("llm_chain_separate.json")
chain.run("whats 2 + 2")
日志输出:
> Entering new LLMChain chain...
Prompt after formatting:
Question: whats 2 + 2Answer: Let's think step by step.> Finished chain.
输出:
' 2 + 2 = 4'
从LangChainHub加载
本节介绍如何从LangChainHub加载链。
from langchain.chains import load_chainchain = load_chain("lc://chains/llm-math/chain.json")
chain.run("whats 2 raised to .12")
日志输出:
> Entering new LLMMathChain chain...
whats 2 raised to .12
Answer: 1.0791812460476249
> Finished chain.
输出:
'Answer: 1.0791812460476249'
有时候链会需要额外的参数,这些参数在链序列化时未包含在内。例如,一个用于对向量数据库进行问答的链条将需要一个向量数据库作为参数。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI, VectorDBQA
from langchain.document_loaders import TextLoader
loader = TextLoader('../../state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(texts, embeddings)
# Running Chroma using direct local API.
# Using DuckDB in-memory for database. Data will be transient.chain = load_chain("lc://chains/vector-db-qa/stuff/chain.json", vectorstore=vectorstore)
query = "What did the president say about Ketanji Brown Jackson"
chain.run(query)
输出:
" The president said that Ketanji Brown Jackson is a Circuit Court of Appeals Judge, one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans, and will continue Justice Breyer's legacy of excellence."
参考文献:
[1] LangChain官方网站:https://www.langchain.com/
[2] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[3] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[通用功能:链的保存(序列化)与加载(反序列化)])
自然语言处理从入门到应用——LangChain:链(Chains)-[通用功能:链的保存(序列化)与加载(反序列化)]
分类目录:《自然语言处理从入门到应用》总目录 本文介绍了如何将链保存(序列化)到磁盘和从磁盘加载(反序列化)。我们使用的序列化格式是json或yaml。目前,只有一些链支持这种类型的序列化。随着时间的推移&…...

机器学习:开启智能时代的重要引擎
引言 随着科技的飞速发展,人工智能已经渗透到我们生活的各个领域。而在人工智能的众多领域中,机器学习以其强大的数据处理能力和智能决策能力受到了广泛关注。本文将向您介绍机器学习的概念、工作原理、应用领域以及未来的发展前景。 一、什么是机器学…...
ES搭建集群
一、创建 elasticsearch-cluster 文件夹 创建 elasticsearch-7.8.0-cluster 文件夹,在内部复制三个 elasticsearch 服务。 然后每个文件目录中每个节点的 config/elasticsearch.yml 配置文件 node-1001 节点 #节点 1 的配置信息: #集群名称࿰…...
# Lua与C++交互(二)———— 交互
C 调用lua 基础调用 再来温习一下 myName “beauty girl” C想要获取myName的值,根据规则,它需要把myName压入栈中,这样lua就能看到;lua从堆栈中获取myName的值,此时栈顶为空;lua拿着myName去全局表中查…...

机器人焊接生产线参数监控系统理解需求
机器人焊接生产线参数监控系统是以参数来反映系统状态并以直观的方式表现 出来,及时了解被监视对象的状态和状态的变化情况。其主要目标是为了达到减少 生产线的处理时间,降低故障率,缩短故障排除时间,从而提高生产线的生产效率 …...

前端基础(ES6 模块化)
目录 前言 复习 ES6 模块化导出导入 解构赋值 导入js文件 export default 全局注册 局部注册 前言 前面学习了js,引入方式使用的是<script s"XXX.js">,今天来学习引入文件的其他方式,使用ES6 模块化编程,…...

第七章,文章界面
7.1添加个人专栏 <template><div class="blog-container"><div class="blog-pages"><!-- 用于渲染『文章列表』和『文章内容』 --><router-view/><div class="col-md-3 main-col pull-left"><div cla…...

HJ102 字符统计
描述 输入一个只包含小写英文字母和数字的字符串,按照不同字符统计个数由多到少输出统计结果,如果统计的个数相同,则按照ASCII码由小到大排序输出。 数据范围:字符串长度满足 1≤len(str)≤1000 1≤len(str)≤1000 输入描述&a…...
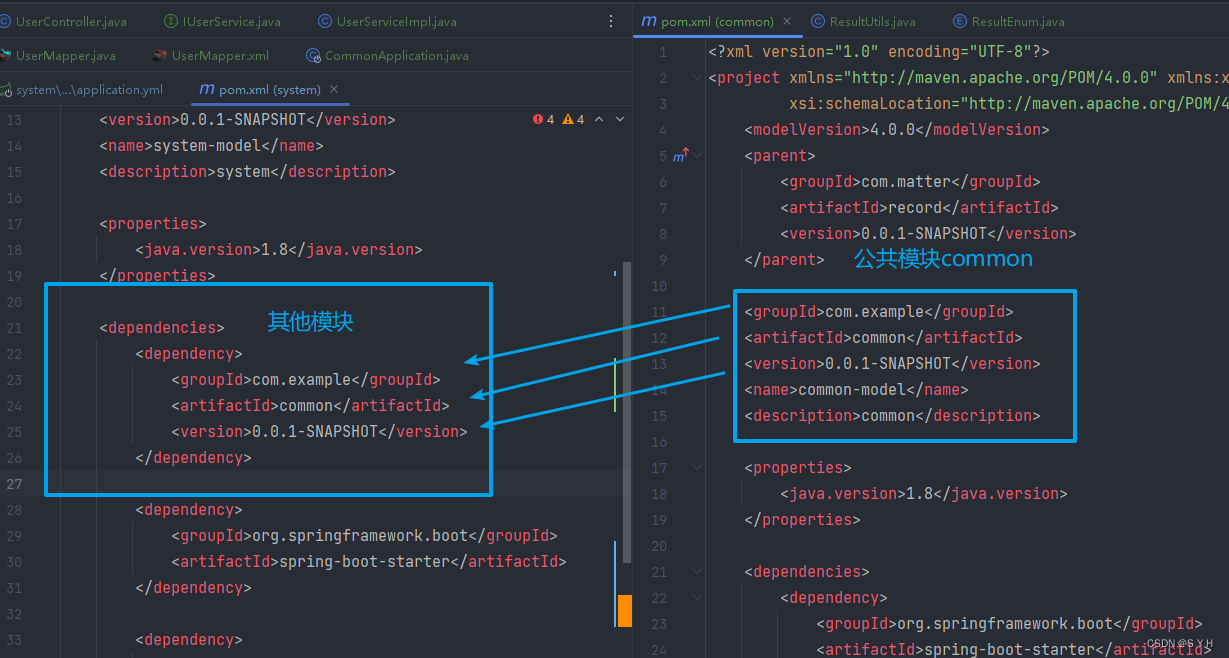
Maven聚合项目(微服务项目)创建流程,以及pom详解
1、首先创建springboot项目作为父项目 只留下pom.xml 文件,删除src目录及其他无用文件 2、创建子项目 子项目可以是maven项目,也可以是springboot项目 3、父子项目关联 4、父项目中依赖管理 <?xml version"1.0" encoding"UTF-8&qu…...

Android OkHttp 源码浅析一
演进之路:原生Android框架不好用 ---- HttpUrlConnect 和 Apache HTTPClient 第一版 底层使用HTTPURLConnect 第二版 Square构建 从Android4.4开始 基本使用: val okhttp OkHttpClient()val request Request.Builder().url("http://www.baidu.com").buil…...

【Redis】——Redis基础的数据结构以及应用场景
什么是redis数据库 Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景。,Redis 还支持 事务 、持久化、Lua 脚本、多种集群方案(主…...
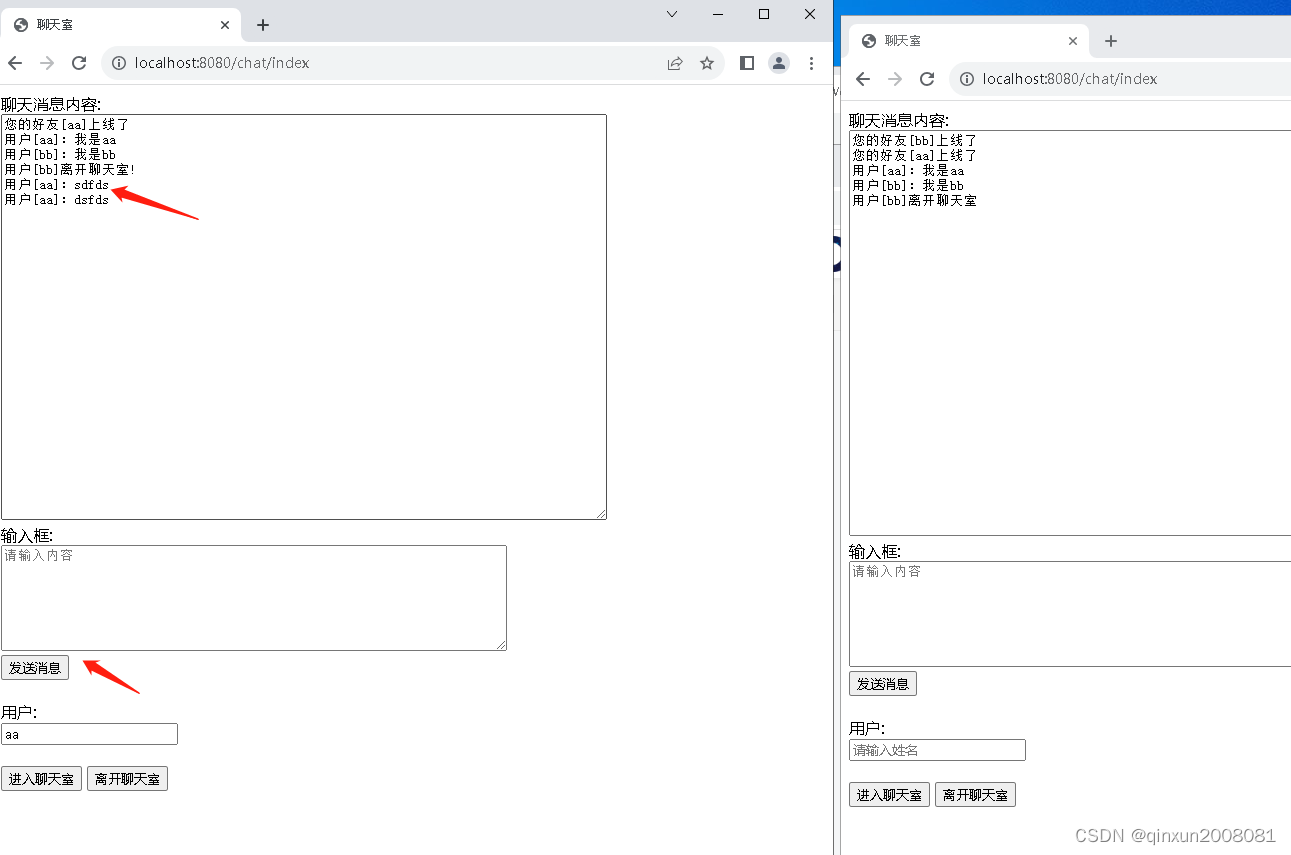
SpringBoot+WebSocket搭建多人在线聊天环境
一、WebSocket是什么? WebSocket是在单个TCP连接上进行全双工通信的协议,可以在服务器和客户端之间建立双向通信通道。 WebSocket 首先与服务器建立常规 HTTP 连接,然后通过发送Upgrade标头将其升级为双向 WebSocket 连接。 WebSocket使得…...
推荐适用于不同规模企业的会计软件:选择最适合您企业的解决方案
高效的会计软件不仅可以协助企业进行财务管理,做出科学的财务决策,还可以对企业数字化转型提供助力。不同规模的企业需要根据其特定需求选择适合的会计软件。那么有什么适合不同规模企业的会计软件推荐吗? 小型企业的选择 对于小型企业而言&…...

Apache Zookeeper架构和选举机制
ZooKeeper是一个开源的分布式协调服务,旨在解决分布式系统中的一致性、配置管理、领导者选举等问题。它由Apache软件基金会维护,是Hadoop生态系统的一部分,被广泛用于构建高可用、可靠和具有一致性的分布式应用程序和服务。 ZooKeeper提供了一个层次化的命名空间,类似于文…...

车联网TCU USB的配置和使用
1 usb_composition命令 # cat /sbin/usb/target # cd /sys/class/android_usb/android0 # cat functions console shows that QCOM’s default configuration Usage: usb_composition [Pid] [HSIC] [PERSISTENT] [IMMEDIATE] [FROM_ADBD] usb_composition 9025 n y y Then this…...
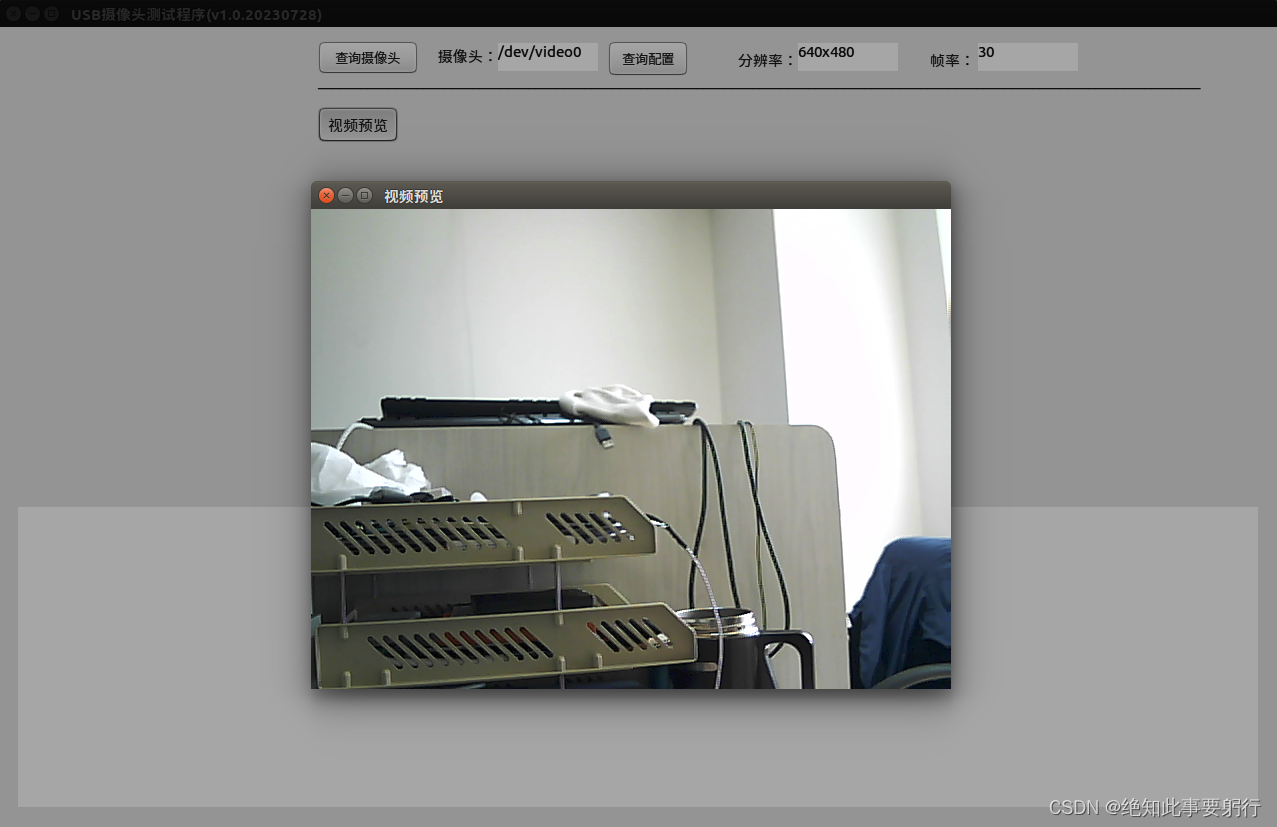
Linux系统USB摄像头测试程序(三)_视频预览
这是在linux上usb摄像头视频预览程序,此程序用到了ffmpeg、sdl2、gtk3组件,程序编译之前应先安装他们。 #include <sys/ioctl.h> #include <sys/stat.h> #include <sys/types.h> #include <fcntl.h> #include <zconf.h> …...

目标检测任务数据集的数据增强中,图像水平翻转和xml标注文件坐标调整
需求: 数据集的数据增强中,有时需要用到图像水平翻转的操作,图像水平翻转后,对应的xml标注文件也需要做坐标的调整。 解决方法: 使用pythonopencvimport xml.etree.ElementTree对图像水平翻转和xml标注…...

系统架构的演变
随着互联网的发展,网站应用的规模不断扩大,常规的应用架构已无法应对,分布式服务架构以及微服务架构势在必行,必需一个治理系统确保架构有条不紊的演进。 单体应用架构 Web应用程序发展的早期,大部分web工程(包含前端…...
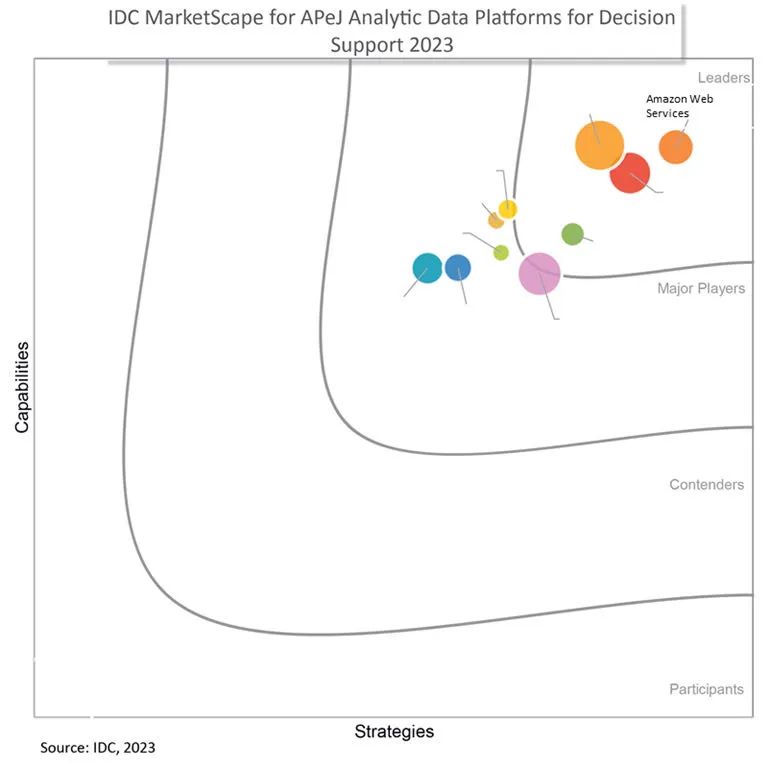
IDC发布《亚太决策支持型分析数据平台评估》报告,亚马逊云科技位列“领导者”类别
日前,领先的IT市场研究和咨询公司IDC发布《2023年亚太地区(不含日本)决策支持型分析数据平台供应商评估》1报告,亚马逊云科技位列“领导者”类别。IDC认为,亚马逊云科技在解决方案的协同性、敏捷性、完整性、及时性、经…...

C#之OpenFileDialog创建和管理文件选择对话框
OpenFileDialog 是用于图形用户界面(GUI)编程的一个类,它用于显示一个对话框,允许用户选择要打开的文件。在需要用户加载或打开文件的应用程序中(如文本编辑器、图像查看器或文档处理器),这是一…...
)
Midjourney V6 acrylic paint提示词工程:从模糊描述到精准输出的12个专业级Prompt模板(含色彩层厚/笔触硬度/画布纹理三重控制)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6丙烯画风格的核心演进与底层渲染机制 Midjourney V6 对丙烯画(Acrylic Painting)风格的建模已脱离早期依赖纹理叠加与后处理滤镜的粗粒度模拟,转向基于…...

3步解锁联想刃7000k BIOS隐藏功能:安全提升硬件性能的完整指南
3步解锁联想刃7000k BIOS隐藏功能:安全提升硬件性能的完整指南 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 联想刃7…...
)
别再花钱买服务器了!手把手教你用Sakura Frp免费搞定内网穿透(Windows保姆级教程)
零成本实现内网穿透:Windows平台实战指南 在个人开发和小型项目测试阶段,许多开发者都面临一个共同难题——如何将本地服务暴露到公网供临时访问?传统解决方案往往需要租用云服务器,不仅成本高昂,配置过程也相当复杂。…...

题目五:抽象类 + 接口 混合实现
编程要求:抽象类 Machine:抽象方法 work(),普通方法 start();接口 Clean:抽象方法 clean();类 Robot继承抽象类 Machine 实现接口 Clean;实现所有未实现的方法;测试创建机器人对象&…...

Flutter Provider 状态管理完全指南
Flutter Provider 状态管理完全指南 引言 Provider 是 Flutter 中最流行的状态管理方案之一,它基于 InheritedWidget 实现,提供了简单而强大的状态管理方式。本文将深入探讨 Provider 的各种用法和高级技巧。 基础概念回顾 Provider 类型 Provider - 最基…...

【Gemini赋能Google Meet实时字幕】:2024企业级会议无障碍升级的5大落地陷阱与避坑指南
更多请点击: https://intelliparadigm.com 第一章:Gemini赋能Google Meet实时字幕的技术演进与企业价值定位 Google Meet 的实时字幕能力已从早期基于传统语音识别(ASR)的静态模型,跃迁至由 Gemini 多模态大模型深度驱…...

SkillForge:构建可复用技能模块的标准化框架与实践指南
1. 项目概述与核心价值 最近在开源社区里,一个名为 SkillForge 的项目引起了我的注意。它的仓库地址是 kographh/skillforge ,这个名字本身就很有意思——“技能锻造”。作为一名长期在技术一线摸爬滚打的开发者,我见过太多号称能“提升效…...
)
别再搞混了!海康威视工业相机SDK和安防SDK开发环境配置避坑指南(VS2019+MVS3.2)
海康威视工业相机开发避坑指南:从硬件选型到SDK环境配置全解析 第一次接触海康威视工业相机的开发者,往往会被网上铺天盖地的安防相机教程带偏方向。我曾亲眼见过团队花费三天时间尝试用iVMS-4200客户端激活一台根本不需要密码的工业相机,也调…...

【音频精修】Melodyne 核心工具实战:从音高微调到节奏重塑
1. Melodyne入门:音频精修的瑞士军刀 第一次打开Melodyne时,我完全被它那些密密麻麻的音符块吓到了。这玩意儿看起来比钢琴卷帘窗还复杂,但用顺手后才发现,它简直是拯救车祸现场录音的神器。作为业内公认的音高校正标杆࿰…...

DO-254标准下的航空电子硬件需求追溯实践
1. DO-254标准与需求追踪的核心价值在航空电子硬件开发领域,RTCA/DO-254标准(在欧洲称为ED-80)是确保机载电子硬件(AEH)功能安全的关键规范。该标准于2005年获得FAA(美国联邦航空管理局)和EASA(欧洲航空安全…...