[oneAPI] 基于BERT预训练模型的英文文本蕴含任务
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务
- Intel® DevCloud for oneAPI 和 Intel® Optimization for PyTorch
- 基于BERT预训练模型的英文文本蕴含任务
- 语料介绍
- 数据集构建
- 模型训练
- 结果
- 参考资料
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
Intel® DevCloud for oneAPI 和 Intel® Optimization for PyTorch
我们在Intel® DevCloud for oneAPI平台上构建了我们的实验环境,充分利用了其完全虚拟化的特性,使我们能够专注于模型的开发和优化,无需烦心底层环境的配置和维护。为了进一步提升我们的实验效果,我们充分利用了Intel® Optimization for PyTorch,将其应用于我们的PyTorch模型中,从而实现了高效的优化。
基于BERT预训练模型的英文文本蕴含任务
自然语言推理(简称NLI)是自然语言处理领域的一个重要任务,而多种文本蕴含(Textual Entailment)是其一个具体的子任务。MNLI(MultiNLI)是一个广泛使用的NLI数据集,旨在评估模型对于文本蕴含关系的理解能力。
在MNLI任务中,给定一个前提句子(premise)和一个假设句子(hypothesis),模型需要判断假设句子是否可以从前提句子中推断出来。这涉及到三种类别的关系:蕴含(entailment)、中性(neutral)和矛盾(contradiction)。例如,对于前提句子 “A cat is sitting on the couch.” 和假设句子 “A cat is on a piece of furniture.”,模型应该判断这两个句子之间的关系是蕴含。
MNLI的任务设计具有挑战性,要求模型不仅仅理解句子的字面含义,还需要进行逻辑推理和上下文理解。解决MNLI任务对于构建具有深层次语义理解能力的自然语言处理模型具有重要意义,可以应用于问答系统、文本理解和语义推理等领域。
基于BERT的文本蕴含(文本对分类)任务实质上是对一个文本序列进行分类。只是按照BERT模型的思想,文本对分类任务在数据集的构建过程中需要通过Segment Embedding来区分前后两个不同的序列。换句话说,与普通的单文本分类任务相比,文本对的分类任务在构建模型输入上发生了变换。
语料介绍
在这里,我们使用到的是论文中所提到的MNLI(The Multi-Genre Natural Language Inference Corpus, 多类型自然语言推理数据库)自然语言推断任务数据集。也就是给定前提(premise)语句和假设(hypothesis)语句,任务是预测前提语句是否包含假设(蕴含, entailment),与假设矛盾(矛盾,contradiction)或者两者都不(中立,neutral)。
{"annotator_labels": ["entailment", "neutral", "entailment", "neutral", "entailment"], "genre": "oup", "gold_label": "entailment", "pairID": "82890e", "promptID": "82890", "sentence1": " From Home Work to Modern Manufacture", "sentence1_binary_parse": "( From ( ( Home Work ) ( to ( Modern Manufacture ) ) ) )", "sentence1_parse": "(ROOT (PP (IN From) (NP (NP (NNP Home) (NNP Work)) (PP (TO to) (NP (NNP Modern) (NNP Manufacture))))))", "sentence2": "Modern manufacturing has changed over time.", "sentence2_binary_parse": "( ( Modern manufacturing ) ( ( has ( changed ( over time ) ) ) . ) )", "sentence2_parse": "(ROOT (S (NP (NNP Modern) (NN manufacturing)) (VP (VBZ has) (VP (VBN changed) (PP (IN over) (NP (NN time))))) (. .)))" }
{"annotator_labels": ["neutral", "neutral", "entailment", "neutral", "neutral"], "genre": "nineeleven", "gold_label": "neutral", "pairID": "16525n", "promptID": "16525", "sentence1": "They were promptly executed.", "sentence1_binary_parse": "( They ( ( were ( promptly executed ) ) . ) )", "sentence1_parse": "(ROOT (S (NP (PRP They)) (VP (VBD were) (VP (ADVP (RB promptly)) (VBN executed))) (. .)))", "sentence2": "They were executed immediately upon capture.", "sentence2_binary_parse": "( They ( ( were ( ( executed immediately ) ( upon capture ) ) ) . ) )", "sentence2_parse": "(ROOT (S (NP (PRP They)) (VP (VBD were) (VP (VBN executed) (ADVP (RB immediately)) (PP (IN upon) (NP (NN capture))))) (. .)))"}
由于该数据集同时也可用于其它任务中,因此除了我们需要的前提和假设两个句子和标签之外,还有每个句子的语法解析结构等等。在这里,下载完成数据后只需要执行项目中的format.py脚本即可将原始数据划分成训练集、验证集和测试集。格式化后的数据形式如下所示:
From Home Work to Modern Manufacture_!_Modern manufacturing has changed over time._!_1
They were promptly executed._!_They were executed immediately upon capture._!_2
数据集构建
定义一个类,并在类的初始化过程中根据训练语料完成字典的构建等工作
class LoadSingleSentenceClassificationDataset:def __init__(self,vocab_path='./vocab.txt', #tokenizer=None,batch_size=32,max_sen_len=None,split_sep='\n',max_position_embeddings=512,pad_index=0,is_sample_shuffle=True):""":param vocab_path: 本地词表vocab.txt的路径:param tokenizer::param batch_size::param max_sen_len: 在对每个batch进行处理时的配置;当max_sen_len = None时,即以每个batch中最长样本长度为标准,对其它进行padding当max_sen_len = 'same'时,以整个数据集中最长样本为标准,对其它进行padding当max_sen_len = 50, 表示以某个固定长度符样本进行padding,多余的截掉;:param split_sep: 文本和标签之前的分隔符,默认为'\t':param max_position_embeddings: 指定最大样本长度,超过这个长度的部分将本截取掉:param is_sample_shuffle: 是否打乱训练集样本(只针对训练集)在后续构造DataLoader时,验证集和测试集均指定为了固定顺序(即不进行打乱),修改程序时请勿进行打乱因为当shuffle为True时,每次通过for循环遍历data_iter时样本的顺序都不一样,这会导致在模型预测时返回的标签顺序与原始的顺序不一样,不方便处理。"""self.tokenizer = tokenizerself.vocab = build_vocab(vocab_path)self.PAD_IDX = pad_indexself.SEP_IDX = self.vocab['[SEP]']self.CLS_IDX = self.vocab['[CLS]']# self.UNK_IDX = '[UNK]'self.batch_size = batch_sizeself.split_sep = split_sepself.max_position_embeddings = max_position_embeddingsif isinstance(max_sen_len, int) and max_sen_len > max_position_embeddings:max_sen_len = max_position_embeddingsself.max_sen_len = max_sen_lenself.is_sample_shuffle = is_sample_shuffle@cachedef data_process(self, filepath, postfix='cache'):"""将每一句话中的每一个词根据字典转换成索引的形式,同时返回所有样本中最长样本的长度:param filepath: 数据集路径:return:"""raw_iter = open(filepath, encoding="utf8").readlines()data = []max_len = 0for raw in tqdm(raw_iter, ncols=80):line = raw.rstrip("\n").split(self.split_sep)s, l = line[0], line[1]tmp = [self.CLS_IDX] + [self.vocab[token] for token in self.tokenizer(s)]if len(tmp) > self.max_position_embeddings - 1:tmp = tmp[:self.max_position_embeddings - 1] # BERT预训练模型只取前512个字符tmp += [self.SEP_IDX]tensor_ = torch.tensor(tmp, dtype=torch.long)l = torch.tensor(int(l), dtype=torch.long)max_len = max(max_len, tensor_.size(0))data.append((tensor_, l))return data, max_lendef load_train_val_test_data(self, train_file_path=None,val_file_path=None,test_file_path=None,only_test=False):postfix = str(self.max_sen_len)test_data, _ = self.data_process(filepath=test_file_path, postfix=postfix)test_iter = DataLoader(test_data, batch_size=self.batch_size,shuffle=False, collate_fn=self.generate_batch)if only_test:return test_itertrain_data, max_sen_len = self.data_process(filepath=train_file_path,postfix=postfix) # 得到处理好的所有样本if self.max_sen_len == 'same':self.max_sen_len = max_sen_lenval_data, _ = self.data_process(filepath=val_file_path,postfix=postfix)train_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoadershuffle=self.is_sample_shuffle, collate_fn=self.generate_batch)val_iter = DataLoader(val_data, batch_size=self.batch_size,shuffle=False, collate_fn=self.generate_batch)return train_iter, test_iter, val_iterdef generate_batch(self, data_batch):batch_sentence, batch_label = [], []for (sen, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。batch_sentence.append(sen)batch_label.append(label)batch_sentence = pad_sequence(batch_sentence, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len)batch_label = torch.tensor(batch_label, dtype=torch.long)return batch_sentence, batch_labelclass LoadPairSentenceClassificationDataset(LoadSingleSentenceClassificationDataset):def __init__(self, **kwargs):super(LoadPairSentenceClassificationDataset, self).__init__(**kwargs)pass@cachedef data_process(self, filepath, postfix='cache'):"""将每一句话中的每一个词根据字典转换成索引的形式,同时返回所有样本中最长样本的长度:param filepath: 数据集路径:return:"""raw_iter = open(filepath).readlines()data = []max_len = 0for raw in tqdm(raw_iter, ncols=80):line = raw.rstrip("\n").split(self.split_sep)s1, s2, l = line[0], line[1], line[2]token1 = [self.vocab[token] for token in self.tokenizer(s1)]token2 = [self.vocab[token] for token in self.tokenizer(s2)]tmp = [self.CLS_IDX] + token1 + [self.SEP_IDX] + token2if len(tmp) > self.max_position_embeddings - 1:tmp = tmp[:self.max_position_embeddings - 1] # BERT预训练模型只取前512个字符tmp += [self.SEP_IDX]seg1 = [0] * (len(token1) + 2) # 2 表示[CLS]和中间的[SEP]这两个字符seg2 = [1] * (len(tmp) - len(seg1))segs = torch.tensor(seg1 + seg2, dtype=torch.long)tensor_ = torch.tensor(tmp, dtype=torch.long)l = torch.tensor(int(l), dtype=torch.long)max_len = max(max_len, tensor_.size(0))data.append((tensor_, segs, l))return data, max_lendef generate_batch(self, data_batch):batch_sentence, batch_seg, batch_label = [], [], []for (sen, seg, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。batch_sentence.append(sen)batch_seg.append((seg))batch_label.append(label)batch_sentence = pad_sequence(batch_sentence, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len) # [max_len,batch_size]batch_seg = pad_sequence(batch_seg, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len) # [max_len, batch_size]batch_label = torch.tensor(batch_label, dtype=torch.long)return batch_sentence, batch_seg, batch_label
模型训练
TaskForPairSentenceClassification的模块来完成分类模型的微调训练任务。
首先,我们需要定义一个ModelConfig类来对分类模型中的超参数进行管理,代码如下所示:
class BertConfig(object):"""Configuration for `BertModel`."""def __init__(self,vocab_size=21128,hidden_size=768,num_hidden_layers=12,num_attention_heads=12,intermediate_size=3072,pad_token_id=0,hidden_act="gelu",hidden_dropout_prob=0.1,attention_probs_dropout_prob=0.1,max_position_embeddings=512,type_vocab_size=2,initializer_range=0.02):"""Constructs BertConfig.Args:vocab_size: Vocabulary size of `inputs_ids` in `BertModel`.hidden_size: Size of the encoder layers and the pooler layer.num_hidden_layers: Number of hidden layers in the Transformer encoder.num_attention_heads: Number of attention heads for each attention layer inthe Transformer encoder.intermediate_size: The size of the "intermediate" (i.e., feed-forward)layer in the Transformer encoder.hidden_act: The non-linear activation function (function or string) in theencoder and pooler.hidden_dropout_prob: The dropout probability for all fully connectedlayers in the embeddings, encoder, and pooler.attention_probs_dropout_prob: The dropout ratio for the attentionprobabilities.max_position_embeddings: The maximum sequence length that this model mightever be used with. Typically set this to something large just in case(e.g., 512 or 1024 or 2048).type_vocab_size: The vocabulary size of the `token_type_ids` passed into`BertModel`.initializer_range: The stdev of the truncated_normal_initializer forinitializing all weight matrices."""self.vocab_size = vocab_sizeself.hidden_size = hidden_sizeself.num_hidden_layers = num_hidden_layersself.num_attention_heads = num_attention_headsself.hidden_act = hidden_actself.intermediate_size = intermediate_sizeself.pad_token_id = pad_token_idself.hidden_dropout_prob = hidden_dropout_probself.attention_probs_dropout_prob = attention_probs_dropout_probself.max_position_embeddings = max_position_embeddingsself.type_vocab_size = type_vocab_sizeself.initializer_range = initializer_range@classmethoddef from_dict(cls, json_object):"""Constructs a `BertConfig` from a Python dictionary of parameters."""config = BertConfig(vocab_size=None)for (key, value) in six.iteritems(json_object):config.__dict__[key] = valuereturn config@classmethoddef from_json_file(cls, json_file):"""Constructs a `BertConfig` from a json file of parameters.""""""从json配置文件读取配置信息"""with open(json_file, 'r') as reader:text = reader.read()logging.info(f"成功导入BERT配置文件 {json_file}")return cls.from_dict(json.loads(text))def to_dict(self):"""Serializes this instance to a Python dictionary."""output = copy.deepcopy(self.__dict__)return outputdef to_json_string(self):"""Serializes this instance to a JSON string."""return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
最后,我们只需要再定义一个train()函数来完成模型的训练即可,代码如下:
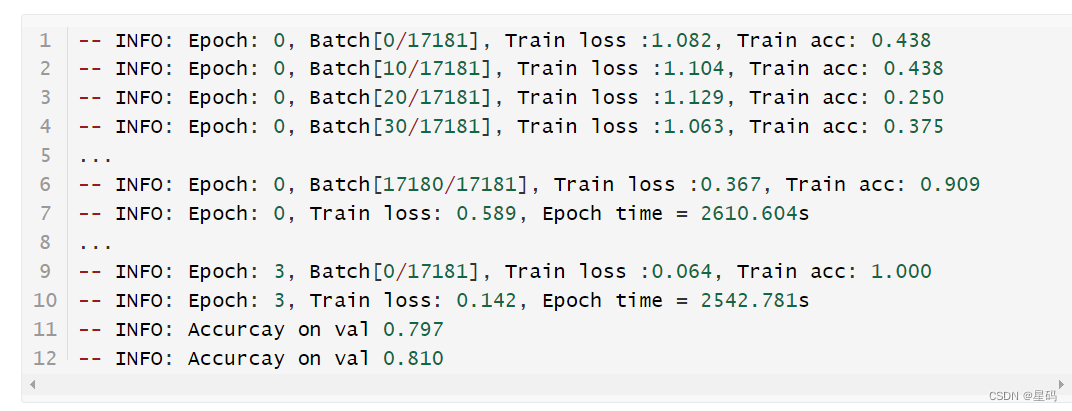
def train(config):model = BertForSentenceClassification(config,config.pretrained_model_dir)model_save_path = os.path.join(config.model_save_dir, 'model.pt')if os.path.exists(model_save_path):loaded_paras = torch.load(model_save_path)model.load_state_dict(loaded_paras)logging.info("## 成功载入已有模型,进行追加训练......")model = model.to(config.device)optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)'''Apply Intel Extension for PyTorch optimization against the model object and optimizer object.'''model, optimizer = ipex.optimize(model, optimizer=optimizer)model.train()bert_tokenize = BertTokenizer.from_pretrained(model_config.pretrained_model_dir).tokenizedata_loader = LoadPairSentenceClassificationDataset(vocab_path=config.vocab_path,tokenizer=bert_tokenize,batch_size=config.batch_size,max_sen_len=config.max_sen_len,split_sep=config.split_sep,max_position_embeddings=config.max_position_embeddings,pad_index=config.pad_token_id)train_iter, test_iter, val_iter = \data_loader.load_train_val_test_data(config.train_file_path,config.val_file_path,config.test_file_path)lr_scheduler = get_scheduler(name='linear',optimizer=optimizer,num_warmup_steps=int(len(train_iter) * 0),num_training_steps=int(config.epochs * len(train_iter)))max_acc = 0for epoch in range(config.epochs):losses = 0start_time = time.time()for idx, (sample, seg, label) in enumerate(train_iter):sample = sample.to(config.device) # [src_len, batch_size]label = label.to(config.device)seg = seg.to(config.device)padding_mask = (sample == data_loader.PAD_IDX).transpose(0, 1)loss, logits = model(input_ids=sample,attention_mask=padding_mask,token_type_ids=seg,position_ids=None,labels=label)optimizer.zero_grad()loss.backward()lr_scheduler.step()optimizer.step()losses += loss.item()acc = (logits.argmax(1) == label).float().mean()if idx % 10 == 0:logging.info(f"Epoch: {epoch}, Batch[{idx}/{len(train_iter)}], "f"Train loss :{loss.item():.3f}, Train acc: {acc:.3f}")end_time = time.time()train_loss = losses / len(train_iter)logging.info(f"Epoch: {epoch}, Train loss: "f"{train_loss:.3f}, Epoch time = {(end_time - start_time):.3f}s")if (epoch + 1) % config.model_val_per_epoch == 0:acc = evaluate(val_iter, model, config.device, data_loader.PAD_IDX)logging.info(f"Accuracy on val {acc:.3f}")if acc > max_acc:max_acc = acctorch.save(model.state_dict(), model_save_path)
结果
参考资料
基于BERT预训练模型的英文文本蕴含任务: https://www.ylkz.life/deeplearning/p10407402/
相关文章:
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务
[oneAPI] 基于BERT预训练模型的英文文本蕴含任务 Intel DevCloud for oneAPI 和 Intel Optimization for PyTorch基于BERT预训练模型的英文文本蕴含任务语料介绍数据集构建 模型训练 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0…...
【洛谷】P1163 银行贷款
原题链接:https://www.luogu.com.cn/problem/P1163 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 这题需要注意的是利率按月累计这句话,也就是相当于“利滚利”。 我们定义sum变量表示贷款原值,money表示每月支付…...
Java版工程行业管理系统源码-专业的工程管理软件-提供一站式服务 em
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工…...
kafka--技术文档--基本docker中安装<单机>-linux
安装zookeeper 阿丹小科普: Kafka在0.11.0.0版本之后不再依赖Zookeeper,而是使用基于Raft协议的Kafka自身的仲裁机制来替代Zookeeper。具体来说,Kafka 2.8.0版本是第一个不需要Zookeeper就可以运行Kafka的版本,这被称为Kafka Raf…...

回归预测 | MATLAB实现WOA-RF鲸鱼优化算法优化随机森林算法多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现WOA-RF鲸鱼优化算法优化随机森林算法多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现WOA-RF鲸鱼优化算法优化随机森林算法多输入单输出回归预测(多指标,多图)效果一览…...

Linux系统安全——NAT(SNAT、DNAT)
目录 NAT SNAT SNAT实际操作 DNAT DNAT实际操作 NAT NAT: network address translation,支持PREROUTING,INPUT,OUTPUT,POSTROUTING四个链 请求报文:修改源/目标IP, 响应报文:修改源/目标…...

uniapp项目添加人脸识别功能,可用作登录,付款,流程审批前的安全校验
本案例使用了hbuilder插件商城中的活体检验插件,可自行前往作者处下载查看, 效果图如下 此插件需要在manifest.json中勾选 实现流程 1:前往hbuilder插件市场下载插件 2:在页面中导入import face from "/uni_modules/mcc-…...

SpringBoot面试题
Spring Boot的启动流程主要分为以下几个步骤: 加载Spring Boot配置文件,初始化Spring Boot环境和核心组件,如ApplicationContext上下文环境、自动装配机制等。 执行SpringApplication.run()方法,执行所有Spring Boot自动配置的Be…...
Git相关命令
SSH密钥文件 Github里面S设置SH公钥有两者选择方式 账号下的每个仓库都设置一个公钥,因为GitHub官方要求每个仓库的公钥都不能相同,所以每个账号都要搞一个密钥(很麻烦)给账号分配一个公钥,然后这个公钥就可以在这个…...
《HeadFirst设计模式(第二版)》第八章代码——模板方法模式
代码文件目录: CaffeineBeverage package Chapter8_TemplateMethodPattern;/*** Author 竹心* Date 2023/8/17**/public abstract class CaffeineBeverage {final void prepareRecipe(){boilWater();brew();pourInCup();//这里使用钩子customerWantsCondiments()来…...

RESTful API,以及如何使用它构建 web 应用程序
RESTful API是一种基于HTTP协议的API设计风格,它的核心思想是将资源作为 API 的核心,使用 HTTP 的 GET、POST、PUT、DELETE 等方法对这些资源进行操作,并通过 URL 来定位资源。 RESTful API的特点包括: 资源是 API 的核心使用 H…...
Git+Gitee使用分享
GitGitee快速入门 创建仓库 初始化本地仓库 验证本地git是否安装好 打开cmd窗口,输入git 这样就OK。 Git 全局设置:(只需要设置一次) 这台电脑如果是第一次使用git,就需要这样初始化一下,这样才知道是谁提交到仓库了。 git confi…...

【3D激光SLAM】LOAM源代码解析--transformMaintenance.cpp
系列文章目录 【3D激光SLAM】LOAM源代码解析–scanRegistration.cpp 【3D激光SLAM】LOAM源代码解析–laserOdometry.cpp 【3D激光SLAM】LOAM源代码解析–laserMapping.cpp 【3D激光SLAM】LOAM源代码解析–transformMaintenance.cpp 写在前面 本系列文章将对LOAM源代码进行讲解…...

DiscuzQ 二开教程(7)——二次开发版本部署文档
DiscuzQ 二开教程(7)——二次开发版本部署文档 源码:Discuz-Q-V3: 本仓库为Discuz-Q V3.0.211111 版本的二次开发版本,是将DiscuzQ官方仓库进行合并代码(All in One)整理后的仓库,使用更方便。…...
u盘数据丢失但占内存如何恢复?不要着急,这里有拯救方案
U盘数据丢失但占内存如何恢复?数据丢失是一种让人非常头疼的问题,尤其是当我们的U盘数据丢失了,但内存仍然被占用时,更令人困惑和焦虑。然而,不要慌张!在本文中,将为大家介绍一些有效的方法来恢…...

springboot日志文件名称为什么叫logback-spring.xml
如题,为什么springboot日志配置文件叫logback-spring.xml? 在整个项目中搜索 logback-spring.xml 并没有搜索到。 先看一下 org.springframework.boot.context.logging.LoggingApplicationListener#initialize protected void initialize(ConfigurableEn…...
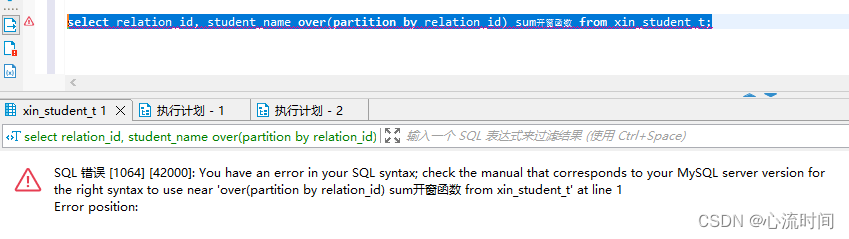
Mysql 开窗函数(窗口函数)
文章目录 全部数据示例1(说明)开窗函数可以比groupby多查出条件列外的字段,开窗函数主要是为了跟聚合函数一起使用,达到分组统计效果,并且开窗函数的结果集基本都是跟总行数一样示例2示例3示例4错误示例1错误示例2错误…...

计算机视觉之图像特征提取
图像特征提取是计算机视觉中的重要任务,它有助于识别、分类、检测和跟踪对象。以下是一些常用的图像特征提取算法及其简介: 颜色直方图(Color Histogram): 简介:颜色直方图表示图像中各种颜色的分布情况。通…...

【面试经典150题】移除元素·JavaScript版
题目来源 大致思路:遍历数组,如果遇到值为val的元素,使用数组最后一个元素替换它。详细过程: /*** param {number[]} nums* param {number} val* return {number}*/ var removeElement function(nums, val) {let i0,nnums.leng…...

Cesium 相机的三种放置方式
文章目录 Cesium 相机的三种放置方式第一种:setView 计算视角1. Cartesian3 方式2. Rectangle 方式 第二种:flyTo第三种:lookAt Cesium 相机的三种放置方式 Cesium 提供了三种方式对相机的位置进行摆放 第一种:setView 计算视角 …...
)
手把手教你:没有ST-LINK,如何用USB给STM32烧录程序(DFU模式保姆级教程)
零成本玩转STM32:USB-DFU模式烧录全攻略 当你深夜调试STM32项目时,突然发现手边没有ST-LINK,而快递至少要等三天——这种场景我经历过太多次。直到发现DFU模式这个隐藏技能,所有问题迎刃而解。本文将分享如何仅用一根USB线完成固件…...

RFID电动车智能门禁管理系统技术采用四层架构设计,实现电动车智能化管理。感知层采用防水防撕RFID电子车牌;识别层配置3-4米远距离读卡器;控制层集成ARM7处理器;执行层通过电动道闸或摆闸或广告门
RFID电动车智能门禁管理系统技术方案一、系统架构概览层级设备/组件功能说明感知层RFID电子车牌(DDC-RFID)车辆身份标识,防水防撕带刀口识别层RFID读卡器一体机(DAIC-DDC-RFID)3-4米远距离识别,920-925MHz频…...
)
Gemini Deep Research调用失败?5类报错代码详解+官方未公开的API绕过方案(限时技术内参)
更多请点击: https://intelliparadigm.com 第一章:Gemini Deep Research功能怎么用 Gemini Deep Research 是 Google 推出的面向专业研究者的增强型推理能力模块,专为长上下文分析、跨文档信息整合与假设验证设计。启用该功能需通过 Gemini …...

Midjourney V6水彩模式突然失效?紧急修复方案:3个隐藏--style参数+2个替代性sref锚点+1键重置工作流
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6水彩模式失效的真相溯源 Midjourney V6 发布后,大量用户反馈 --style watercolor 参数不再触发预期的水彩渲染效果,生成图像趋于写实或默认风格。这一现象并非 UI …...

CSS如何实现一致的圆角半径设计_通过CSS变量存储border-radius
能,但需注意变量作用域、fallback机制及单位完整性;推荐:root定义基础值并用var(--radius-md, 8px),避免嵌套覆盖与无单位变量,旧浏览器需前置静态值。border-radius 用 CSS 变量统一管理,真能省事?能&…...

潜变量模型完全指南:从高斯混合模型到变分自编码器
潜变量模型完全指南:从高斯混合模型到变分自编码器 【免费下载链接】bayesian-machine-learning Notebooks about Bayesian methods for machine learning 项目地址: https://gitcode.com/gh_mirrors/ba/bayesian-machine-learning 潜变量模型是机器学习领域…...

C语言核心知识体系总结
C语言核心知识体系总结本文旨在系统梳理C语言的基础与进阶知识点,帮助读者建立清晰的知识框架。内容涵盖:程序编译过程、数据类型与变量、运算符与表达式、控制结构、函数、指针、结构体与共用体、动态内存分配、文件操作等。适合复习巩固或查漏补缺。第…...
)
SpringCloud微服务里,用Zuul网关聚合Swagger文档的完整配置流程(含踩坑记录)
SpringCloud微服务架构下Zuul网关聚合Swagger文档的实战指南 在微服务架构中,API文档的管理一直是个令人头疼的问题。想象一下,当你的系统由十几个甚至几十个微服务组成时,开发人员要记住每个服务的接口地址和文档路径几乎是不可能的任务。更…...

Unity中Spine混合模式插槽的Shader实现与优化
1. Spine混合模式插槽的核心问题解析 当你把Spine动画导入Unity后,发现角色颜色变得灰蒙蒙的,就像蒙了一层雾。这种情况在游戏开发中特别常见,尤其是当美术同学在Spine编辑器中精心调制的渐变效果,到了Unity里却完全走样。问题的根…...

3分钟掌握百度网盘秒传技术:彻底解决文件分享失效难题
3分钟掌握百度网盘秒传技术:彻底解决文件分享失效难题 【免费下载链接】rapid-upload-userscript-doc 秒传链接提取脚本 - 文档&教程 项目地址: https://gitcode.com/gh_mirrors/ra/rapid-upload-userscript-doc 在数字化协作时代,百度网盘秒…...