MPP 还是主流架构吗
MPP 架构:
MPP 架构的产品:
-
Impala
-
ClickHouse
-
Druid
-
Doris
很多 OLAP 引擎都采用了 MPP 架构
批处理系统 - 使用场景分钟级、小时级以上的任务,目前很多大型互联网公司都大规模运行这样的系统,稳定可靠,低成本。
MPP系统 - 使用场景秒级、毫秒级以下的任务,主要服务于即席查询场景,对外提供各种数据查询和可视化服务。
MPP 架构针对问题:
MPP解决方案的最原始想法就是消除共享资源。每个执行器有单独的CPU,内存和硬盘资源。一个执行器无法直接访问另一个执行器上的资源,除非通过网络上的受控的数据交换。这种资源独立的概念,对于MPP架构来说很完美的解决了可扩展性的问题。
MPP的第二个主要概念就是并行。每个执行器运行着完全一致的数据处理逻辑,使用着本地存储上的私有数据块。在不同的执行阶段中间有一些同步点(我的理解:了解Java Gc机制的,可以对比GC中stop-the-world,在这个同步点,所有执行器处于等待状态),这些同步点通常被用于进行数据交换(像Spark和MapReduce中的shuffle阶段)。这里有一个经典的MPP查询时间线的例子: 每个垂直的虚线是一个同步点。例如:同步阶段要求在集群中”shuffle”数据以用于join和聚合(aggregations)操作,因此同步阶段可能执行一些数据聚合,表join,数据排序的操作,而每个执行器执行剩下的计算任务。
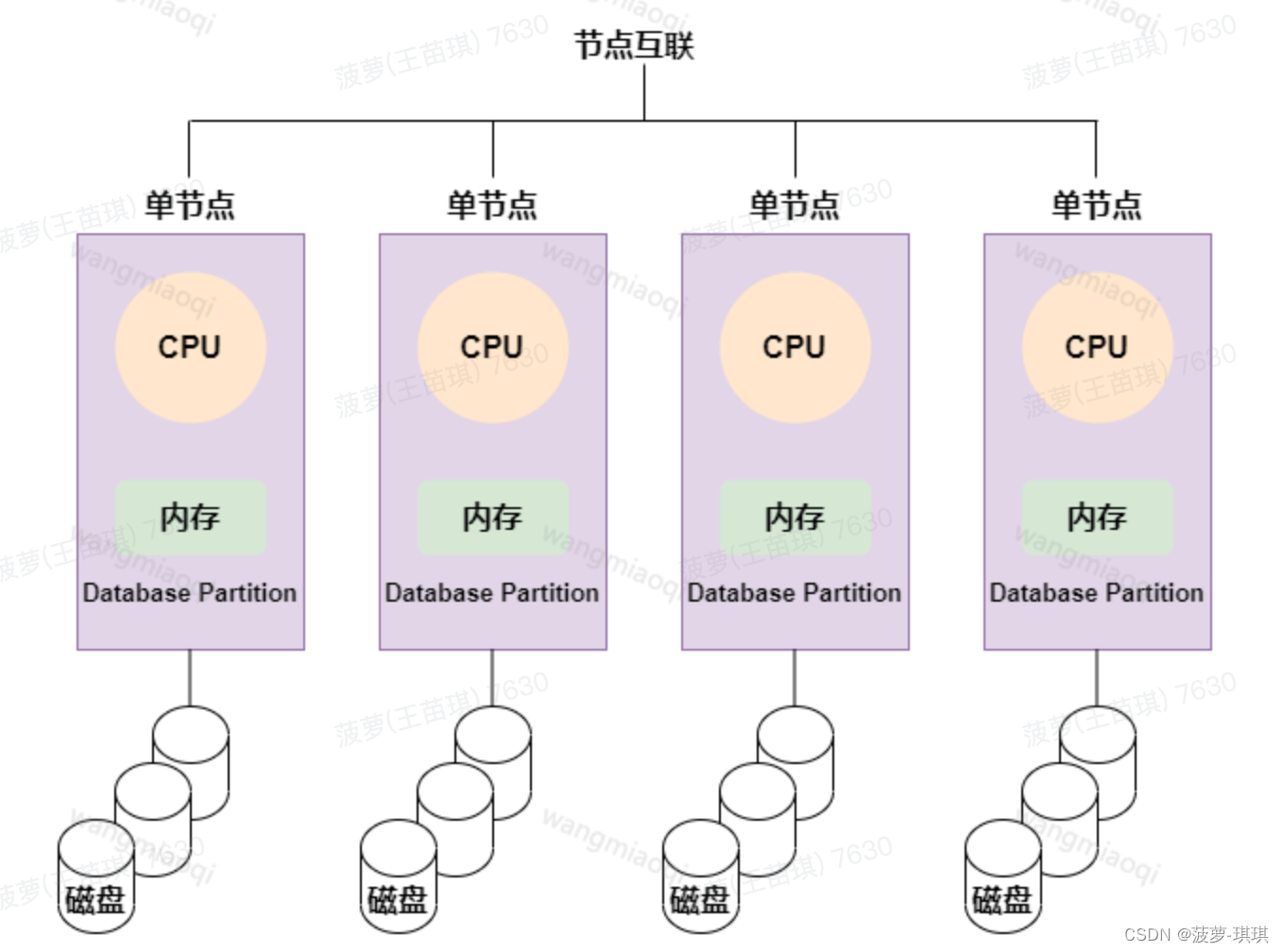
每个节点内的 CPU 不能访问另一个节点的内存,节点之间的信息交互是通过节点互联网络实现的,这个过程称为数据重分配。
NUMA 架构和 MPP 架构很多时候会被搞混,其实区别还是比较明显的。
首先是节点互联机制不同,NUMA 的节点互联是在同一台物理服务器内部实现的,MPP 的节点互联是在不同的 SMP 服务器外部通过 I/O 实现的。
其次是内存访问机制不同,在 NUMA 服务器内部,任何一个 CPU 都可以访问整个系统的内存,但异地内存访问的性能远远低于本地内存访问,因此,在开发应用程序时应该尽量避免异地内存访问。而在 MPP 服务器中,每个节点只访问本地内存,不存在异地内存访问问题。
MPP 架构的优势:
-
任务并行执行;
-
数据分布式存储(本地化);
-
分布式计算;
-
横向扩展,支持集群节点的扩容;
-
Shared Nothing(完全无共享)架构。
MPP的设计缺陷:
所有的MPP解决方案来说都有一个主要的问题——短板效应。如果一个节点总是执行的慢于集群中其他的节点,整个集群的性能就会受限于这个故障节点的执行速度(所谓木桶的短板效应),无论集群有多少节点,都不会有所提高。这里有一个例子展示了故障节点(下图中的Executor 7)是如何降低集群的执行速度的。
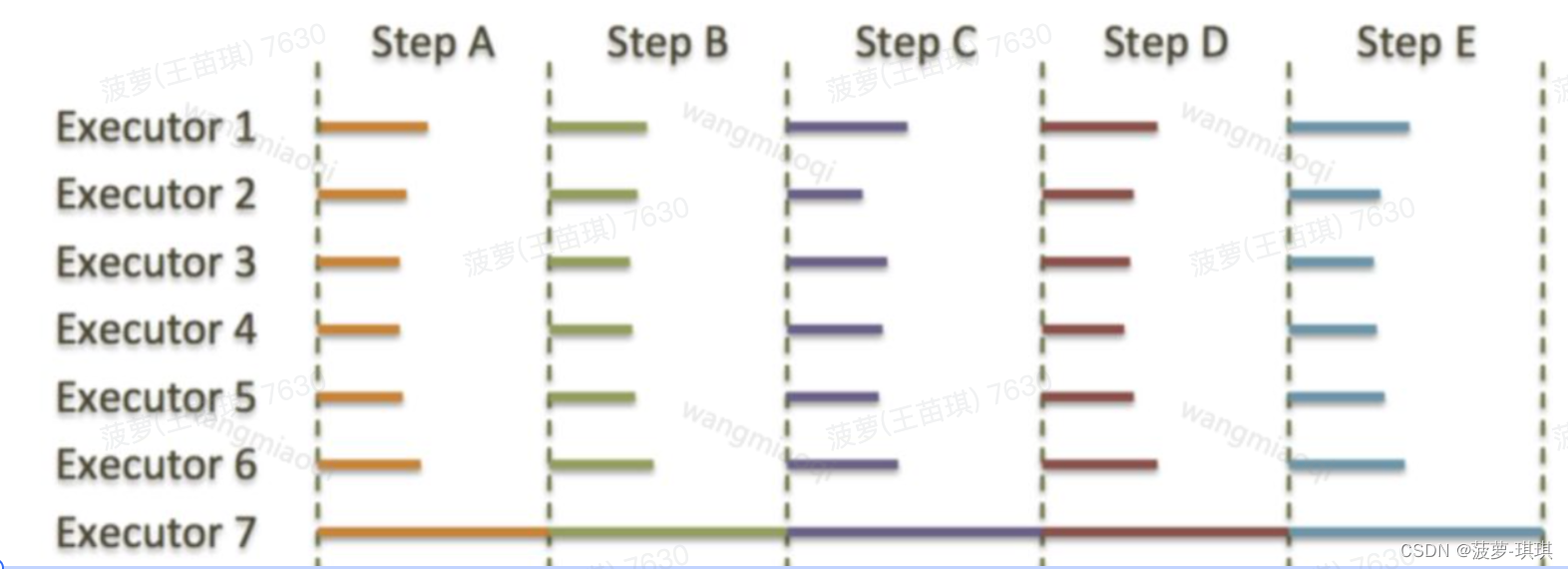
大多数情况下,除了Executor 7 其他的所有执行器都是空闲状态。这是因为他们都在等待Executor 7执行完成后才能执行同步过程,这也是我们的问题的根本。比如,当MPP系统中某个节点的RAID由于磁盘问题导致的性能很慢,或者硬件或者系统问题带来的CPU性能问题等等,都会产生这样的问题。所有的MPP系统都面临这样的问题。
如果你看一下Google的磁盘错误率统计报告,你就能发现观察到的AFR(annualized failure rate,年度故障率)在最好情况下,磁盘在刚开始使用的3个月内有百分之二十会发生故障。
如果一个集群有1000个磁盘,一年中将会有20个出现故障或者说每两周会有一个故障发生。如果有2000个磁盘,你将每周都会有故障发生,如果有4000个,将每周会有两次错误发生。两年的使用之后,你将把这个数字乘以4,也就是说,一个1000个磁盘的集群每周会有两次故障发生。
事实上,在一个确定的量级,你的MPP系统将总会有一个节点的磁盘队列出现问题,这将导致该节点的性能降低,从而像上面所说的那样限制整个集群的性能。这也是为什么在这个世界上没有一个MPP集群是超过50个节点服务器的。
MPP和批处理方案如MapReduce之间有一个更重要的不同就是并发度。并发度就是同一时刻可以高效运行的查询数。MPP是完美对称的,当查询运行的时候,集群中每个节点并发的执行同一个任务。这也就意味着MPP集群的并发度和集群中节点的数量是完全没有关系的。比如说,4个节点的集群和400个节点的集群将支持同一级别的并发度,而且他们性能下降的点基本上是同样。下面是一个例子。
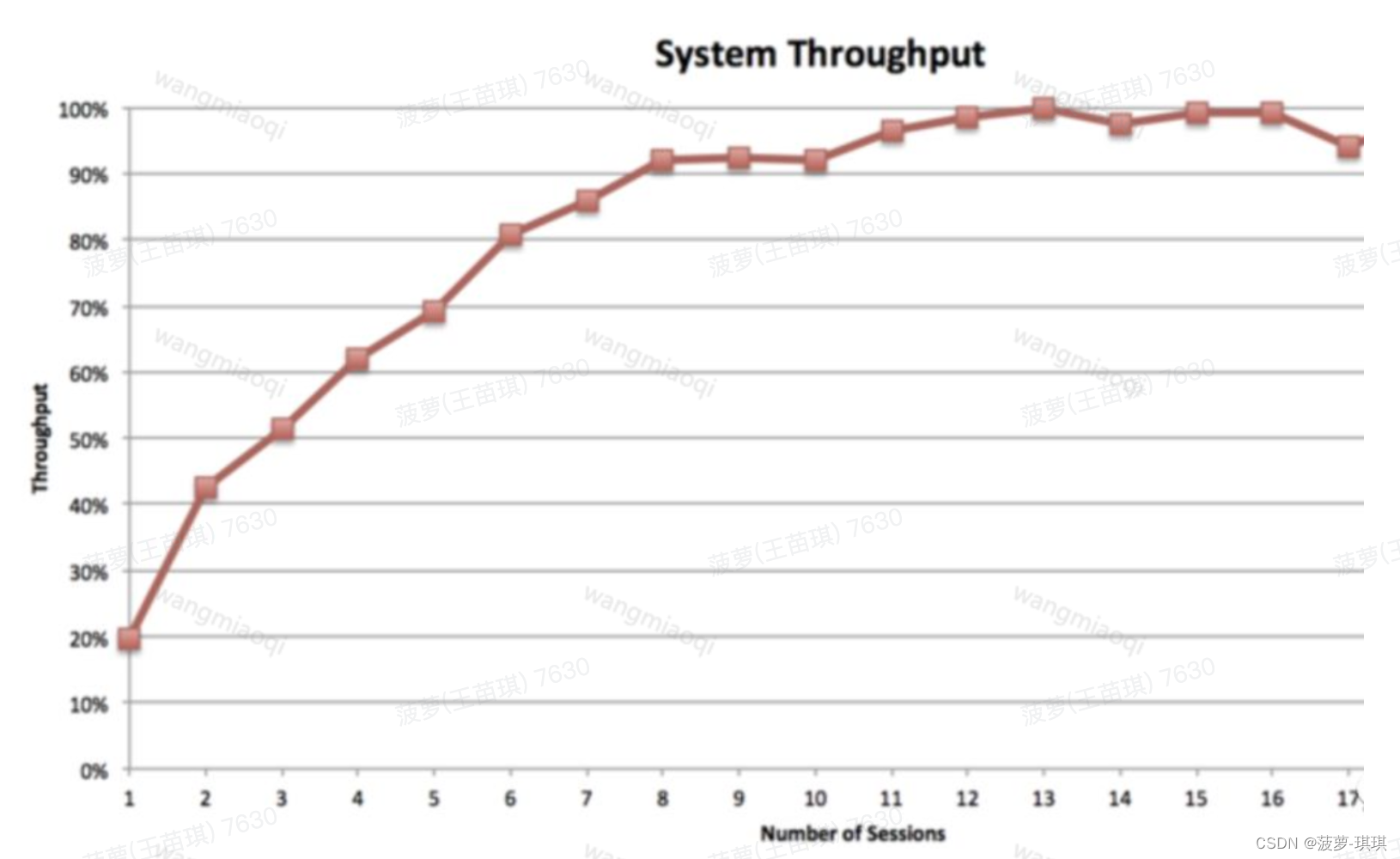
16个并行查询会话产生了整个集群最大的吞吐量。如果你将会话数提高到20个以上的时候,吞吐量将慢慢下降到70%甚至更低。在此声明,吞吐量是在一个固定的时间区间内(时间足够长以产生一个代表性的结果),执行的相同种类的查询任务的数量。Yahoo团队调查Impala并发度限制时产生了一个相似的测试结果。Impala是一个基于Hadoop的MPP引擎。因此从根本上来说,较低的并发度是MPP方案必须承担的以提供它的低查询延迟和高数据处理速度。
MPP 架构的 OLAP 引擎
采用 MPP 架构的 OLAP 引擎分为两类,一类是自身不存储数据,只负责计算的引擎;一类是自身既存储数据,也负责计算的引擎。
只计算不存储数据:
-
Impala
Apache Impala 是采用 MPP 架构的查询引擎,本身不存储任何数据,直接使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。
提供了类 SQL(类 Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由 Java 和 C++实现的,Java 提供的查询交互的接口和实现,C++实现了查询引擎部分。
Impala 支持共享 Hive Metastore,但没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。
Impala 经常搭配存储引擎 Kudu 一起提供服务,这么做最大的优势是查询比较快,并且支持数据的 Update 和 Delete。
-
Presto
Presto 是一个分布式的采用 MPP 架构的查询引擎,本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。Presto 是一个 OLAP 的工具,擅长对海量数据进行复杂的分析;但是对于 OLTP 场景,并不是 Presto 所擅长,所以不要把 Presto 当做数据库来使用。
Presto 是一个低延迟高并发的内存计算引擎。需要从其他数据源获取数据来进行运算分析,它可以连接多种数据源,包括 Hive、RDBMS(Mysql、Oracle、Tidb 等)、Kafka、MongoDB、Redis 等。
计算 & 存储数据:
-
ClickHouse
ClickHouse 是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。
它自包含了存储和计算能力,完全自主实现了高可用,而且支持完整的 SQL 语法包括 JOIN 等,技术上有着明显优势。相比于 hadoop 体系,以数据库的方式来做大数据处理更加简单易用,学习成本低且灵活度高。当前社区仍旧在迅猛发展中,并且在国内社区也非常火热,各个大厂纷纷跟进大规模使用。
ClickHouse 在计算层做了非常细致的工作,竭尽所能榨干硬件能力,提升查询速度。它实现了单机多核并行、分布式计算、向量化执行与 SIMD 指令、代码生成等多种重要技术。
ClickHouse 从 OLAP 场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据 Partitioning、TTL、主备复制等丰富功能。以上功能共同为 ClickHouse 极速的分析性能奠定了基础。
-
Doris
Doris 是百度主导的,根据 Google Mesa 论文和 Impala 项目改写的一个大数据分析引擎,是一个海量分布式 KV 存储系统,其设计目标是支持中等规模高可用可伸缩的 KV 存储集群。
Doris 可以实现海量存储,线性伸缩、平滑扩容,自动容错、故障转移,高并发,且运维成本低。部署规模,建议部署 4-100+台服务器。
Doris3 的主要架构: DT(Data Transfer)负责数据导入、DS(Data Seacher)模块负责数据查询、DM(Data Master)模块负责集群元数据管理,数据则存储在 Armor 分布式 Key-Value 引擎中。Doris3 依赖 ZooKeeper 存储元数据,从而其他模块依赖 ZooKeeper 做到了无状态,进而整个系统能够做到无故障单点。
-
Druid
Druid 是一个开源、分布式、面向列式存储的实时分析数据存储系统。
Druid 的关键特性如下:
-
亚秒级的 OLAP 查询分析:采用了列式存储、倒排索引、位图索引等关键技术;
-
在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作;
-
实时流数据分析:Druid 提供了实时流数据分析,以及高效实时写入;
-
实时数据在亚秒级内的可视化;
-
丰富的数据分析功能:Druid 提供了友好的可视化界面;
-
SQL 查询语言;
-
高可用性与高可拓展性:Druid 工作节点功能单一,不相互依赖;Druid 集群在管理、容错、灾备、扩容都很容易;
MPP架构和其他架构数据库的场景对比:

Hadoop和MPP两种技术的特定和适用场景为:
-
Hadoop在处理非结构化和半结构化数据上具备优势,尤其适合海量数据批处理等应用要求。
-
MPP适合替代现有关系数据机构下的大数据处理,具有较高的效率。
MPP适合多维度数据自助分析、数据集市等;Hadoop适合海量数据存储查询、批量数据ETL、非机构化数据分析(日志分析、文本分析)等。
适合场景
-
有上百亿以上离线数据,不更新,结构化数据,需要各种复杂分析的sql语句
-
不需要频繁重复离线计算,不需要大并发量
-
几秒、几十秒立即返回分析结果,即:即席查询。例如sum,count,group by,order
相关文章:
MPP 还是主流架构吗
MPP 架构: MPP 架构的产品: Impala ClickHouse Druid Doris 很多 OLAP 引擎都采用了 MPP 架构 批处理系统 - 使用场景分钟级、小时级以上的任务,目前很多大型互联网公司都大规模运行这样的系统,稳定可靠,低成本。…...
ubuntu查看网速
使用speedomster测试网速 sudo apt-get install speedometer 查询需要测速的网卡 speedometer -r ens33 -t ens33 -r: 指定网卡的接收速度 -t: 指定网卡的发送速度 使用nload测试 sudo apt-get install nload 测速 nload -t 200 -i 1024 -o 128 -U M 参数含义࿰…...

【官方中文文档】Mybatis-Spring #使用 MyBatis API
使用 MyBatis API 使用 MyBatis-Spring,你可以继续直接使用 MyBatis 的 API。只需简单地使用 SqlSessionFactoryBean 在 Spring 中创建一个 SqlSessionFactory,然后按你的方式在代码中使用工厂即可。 public class UserDaoImpl implements UserDao {//…...

go gorm belong to也就是多对一的情况
多位员工属于同一个公司,一个公司包含多个人,关系放在多的那一部分 belongs to 会与另一个模型建立了一对一的连接。 这种模型的每一个实例都“属于”另一个模型的一个实例。 例如,您的应用包含 user 和 company,并且每个 user 能…...

亚马逊云科技 云技能孵化营——机器学习心得
亚马逊云科技 云技能孵化营机器学习心得 前言什么是机器学习?机器学习如何解决业务问题?什么时候适合使用机器学习模型?总结 前言 很荣幸参加了本次亚马逊云科技云技能孵化营,再本期的《亚马逊云科技云技能孵化营》中,…...
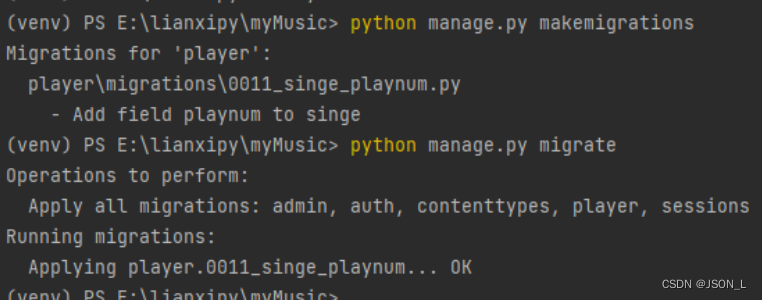
Django实现音乐网站 ⒀
使用Python Django框架制作一个音乐网站, 本篇主要是推荐页-推荐排行榜、推荐歌手功能开发。 目录 推荐页开发 推荐排行榜 单曲表增加播放量 表模型增加播放量字段 执行表操作 模板中显示外键对应值 表模型外键设置 获取外键对应模型值 推荐排行榜视图 推…...
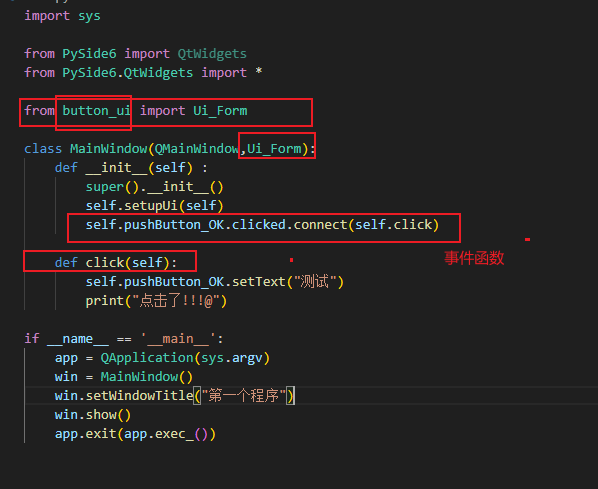
PySide6学习笔记--基础环境的安装配置
PySide6介绍 QT官方发布Qt6.0之后,紧接着于2020年12月10日发布了PySide 6,对应C版的Qt6。从PySide6开始,PySide的命名也会与Qt的大版本号保持一致。需要注意的是使用PySide6开发的程序在默认情况下,不兼容Windows7系统,…...

算法通关村第九关——中序遍历与搜索树
1 中序遍历和搜索树原理 二叉搜索树按照中序遍历正好是一个递增序列。其比较规范的定义是: 若它的左子树不为空,则左子树上所有节点的值均小于它的根节点的值;若它的右子树不为空,则右子树所有节点的值均大于它的根节点的值&…...
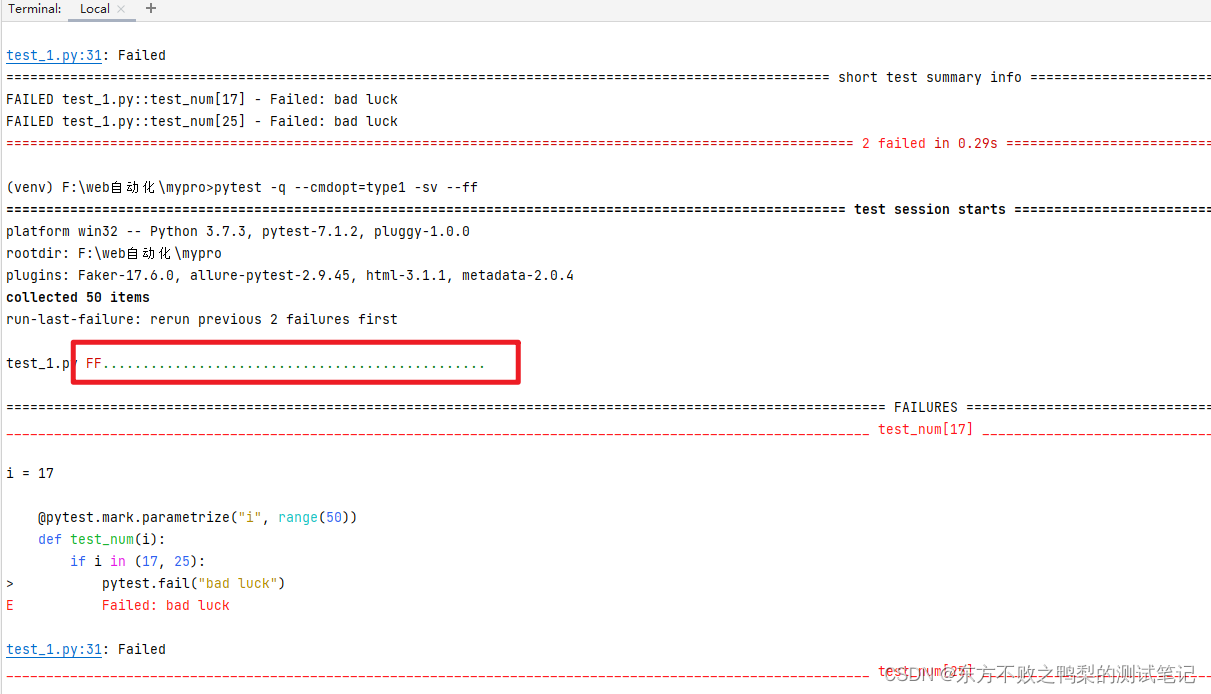
测试框架pytest教程(5)运行失败用例-rerun failed tests
# content of test_50.py import pytestpytest.mark.parametrize("i", range(50)) def test_num(i):if i in (17, 25):pytest.fail("bad luck") 运行这个文件,2个失败,48个通过。 要运行上次失败的测试用例,可以使用--l…...
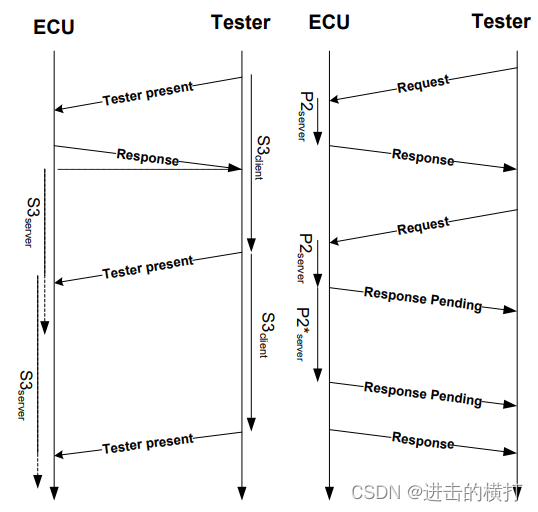
【车载开发系列】UDS当中的时间参数
【车载开发系列】UDS当中的时间参数 UDS当中的时间参数 【车载开发系列】UDS当中的时间参数一. 术语定义二. 网络层时间调整参数三. ECU诊断层与会话层参数 一. 术语定义 缩写全称中文说明BSBlock Size块大小STminSeparation time min时间间隙SIService Identifier服务标识符S…...

PDF中的表格怎么转换为Excel?这两个工具一定得收藏!
PDF是一种常见的文件格式,它可以保持文件的原始样式和内容,但是也有一些缺点,比如不易编辑和处理数据。如果你想要将PDF中的表格或数据导出到Excel中,以便进行分析、计算或制作图表,那么你可能需要一个专业的PDF转Exce…...

ssh scp sshpass
ssh命令用于远程连接主机 ssh usernamehostname更多用法参考: ssh常用用法 scp 命令是用于通过 SSH 协议安全地将文件复制到远程系统和从远程系统复制文件到本地的命令 比如: scp /data/log/a.txt root192.168.1.100:/data/log该命令就就将本地的a.t…...
)
leetcode 1996. 游戏中弱角色的数量(排序的魅力)
题目 题意: 给定n个人的攻击力和防御力,对于一个人来说,如果存在某个人的攻击力和防御力都比他高,那么称这个人为弱角色。统计弱角色的数量 思路: 排序,攻击力按从大到小排序,这样遍历的时候某个数时前边的攻击力都比他…...
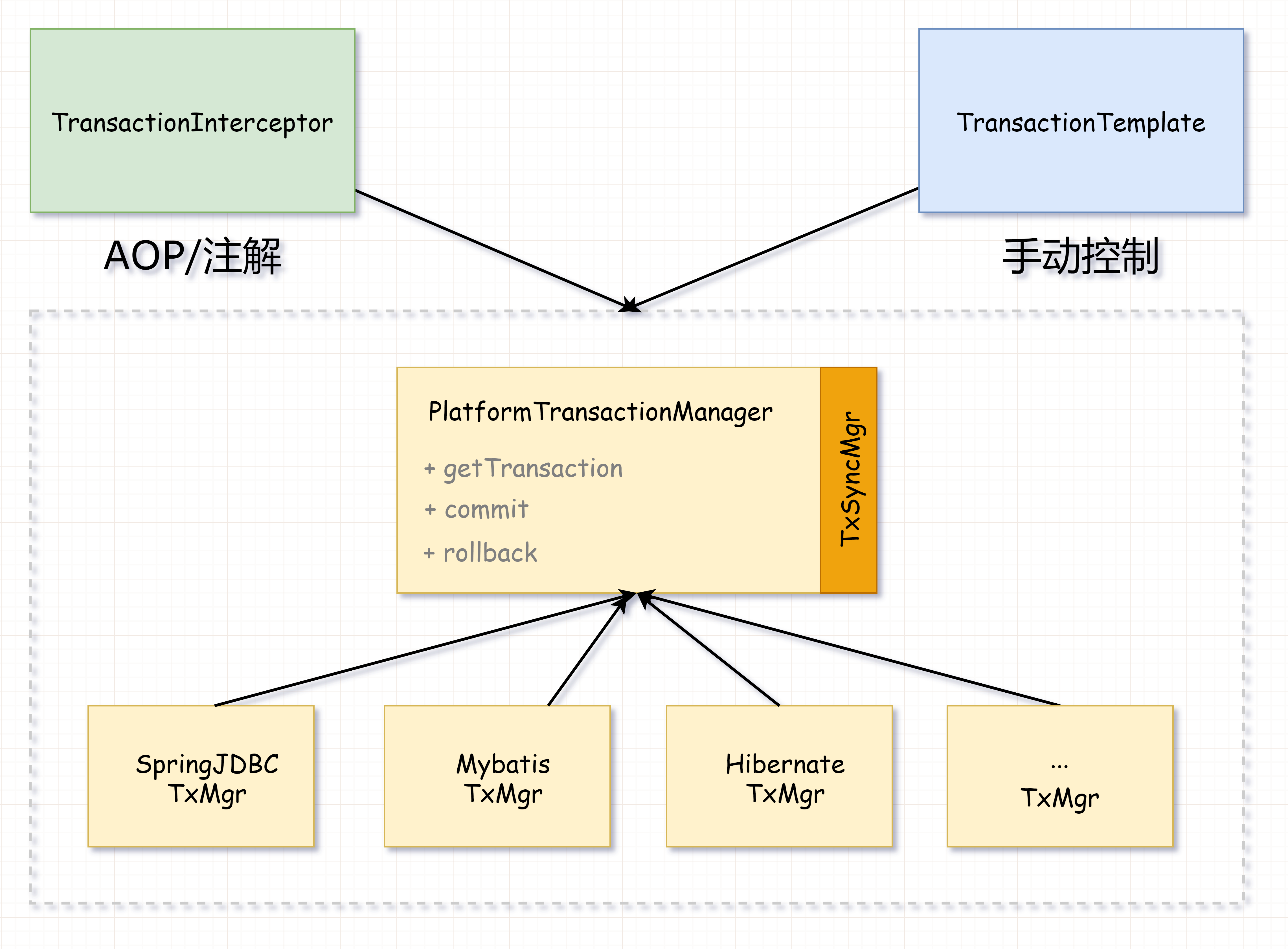
从头到尾说一次 Spring 事务管理(器) | 京东云技术团队
事务管理,一个被说烂的也被看烂的话题,还是八股文中的基础股之一。 本文会从设计角度,一步步的剖析 Spring 事务管理的设计思路(都会设计事务管理器了,还能玩不转?) 为什么需要事务管理&…...
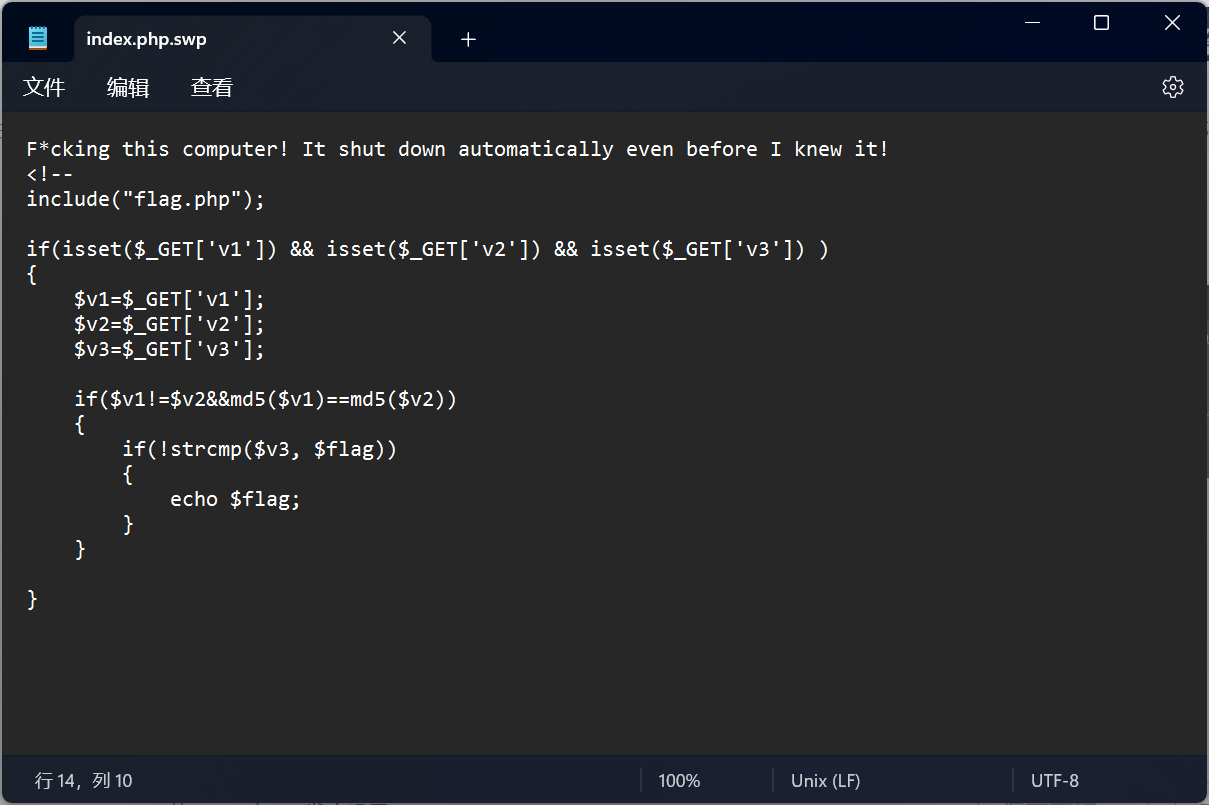
php 系列题目,包含查看后端源代码
一、弱类型比较问题 原则: 1.字符串和数字比较,字符串回被转换成数字。 "admin" 0(true) admin被转换成数字,由于admin是字符串,转换失败,变成0 int(admin)0,所以比较结果是ture 2.混合字符串转…...

令牌桶C语言代码实现
令牌桶实例 令牌桶三要素 cps 每秒钟传输字节数 burst 令牌桶内最多能传输的字节数,token的最大值 token 令牌的个数 之前是一个令牌(token)对应一个字节,现在将一个token变为一个cps,cps是解码速率,每攒到一个令牌ÿ…...
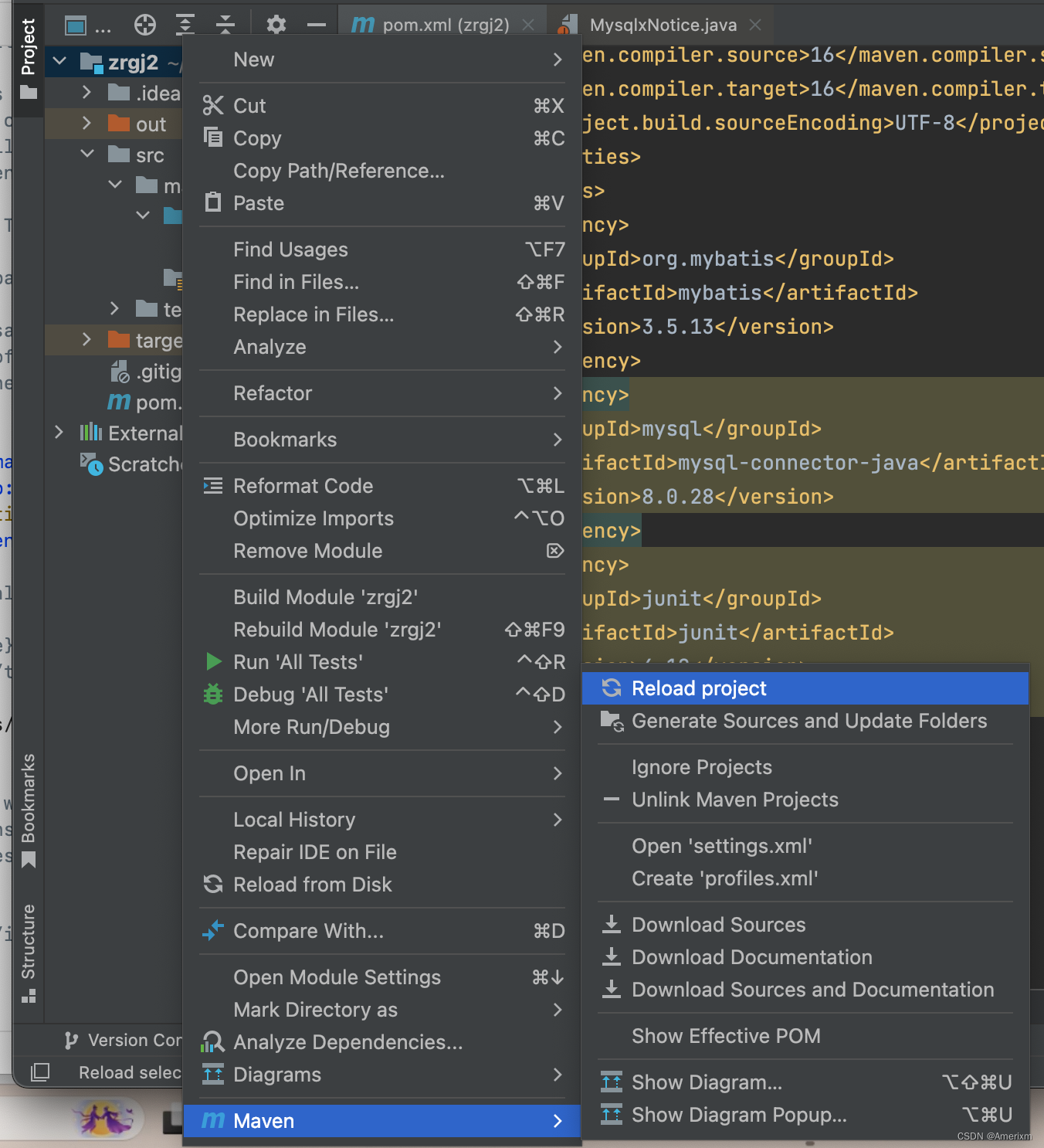
Mybatis 建立依赖失败:报错Dependency ‘mysql:mysql-connector-java:8.0.28‘ not found
Mybatis 建立依赖失败:报错Dependency ‘mysql:mysql-connector-java:8.0.28’ not found 解决办法: 写完依赖代码,直接重构,下载依赖。 图片: 
多线程+隧道代理:提升爬虫速度
在进行大规模数据爬取时,爬虫速度往往是一个关键问题。本文将介绍一个提升爬虫速度的秘密武器:多线程隧道代理。通过合理地利用多线程技术和使用隧道代理,我们可以显著提高爬虫的效率和稳定性。本文将为你提供详细的解决方案和实际操作价值&a…...

使用@Configuration和@Bean给spring容器中注入组件
Confguration->告诉spring这是一个配置类 以前我们是使用配置文件来注册bean的,现如今可以用Configuration 来代替配置文件。 //配置配配置文件 Configuration // 告诉Spring这是一个配置类,等同于以前的配置文件 public class MainConfig {// Bean注解是给IOC…...
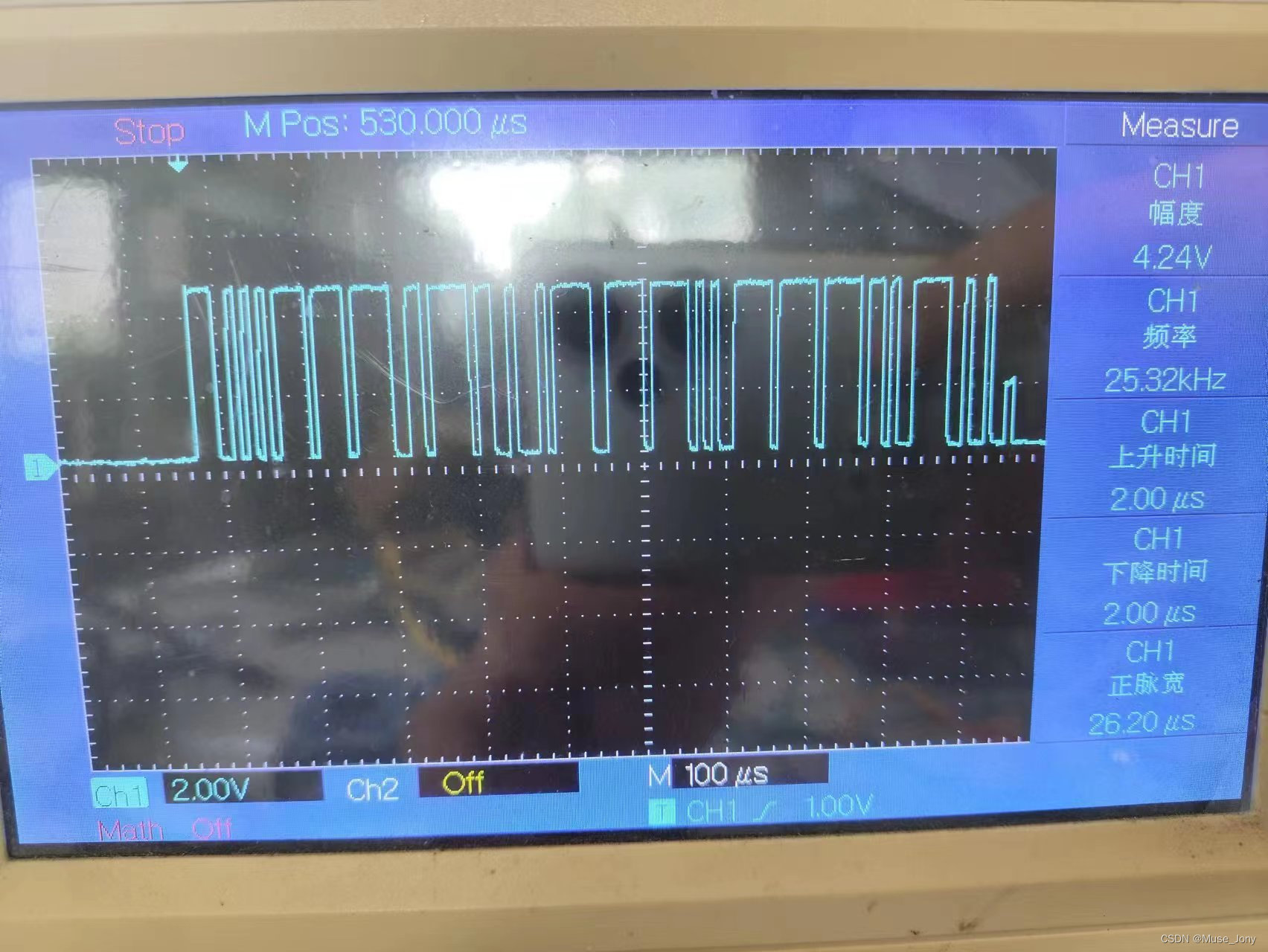
信号波形解读
can波形解读 实际波形 标准帧 发送数据 仲裁段 0x1AA 数据长度为8字节 内容为:0x41, 0x20, 0x38, 0x41, 0x00, 0x16, 0x00, 0x00 波特率 111K...

0301国产光刻机突围全景:双工件台+纳米级精密运动控制 1. 双工件台工作逻辑
国产光刻机突围全景:双工件台纳米级精密运动控制 第三卷 双工件台纳米级精密运动控制(A级 中期集中攻坚) 1. 双工件台工作逻辑(喂饭级实操版带量化参数企业单字脱敏) 一、核心定义:先搞懂“双工件台”的本质…...
别再手动翻译了!用Python的googletrans库5分钟搞定批量文件翻译(附实战代码)
用Python自动化批量翻译:googletrans实战进阶指南 当你面对上百页的外文文档需要翻译时,是否还在复制粘贴到网页翻译工具?作为开发者,我们完全可以用Python的googletrans库构建自动化翻译流水线。本文将带你超越基础的单句翻译&am…...

linux学习进展 I/O复用函数——poll详解
在前几篇笔记中,我们学习了I/O复用的基础概念以及select函数的使用,了解到select通过监视多个文件描述符的读写状态,实现了单进程处理多I/O事件的需求。但select存在明显的局限性,比如最大文件描述符数量限制、参数传递繁琐、内核…...

ThinkPad风扇控制终极指南:TPFanCtrl2让你的笔记本更安静高效 [特殊字符]
ThinkPad风扇控制终极指南:TPFanCtrl2让你的笔记本更安静高效 🚀 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 作为ThinkPad用户,…...

AMD Ryzen处理器深度调试:5个关键功能助你完全掌控硬件性能
AMD Ryzen处理器深度调试:5个关键功能助你完全掌控硬件性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https…...

Vivado 2018.3联合Modelsim SE 10.6d仿真全流程:从库编译到成功调用IP核的实战记录
Vivado与Modelsim联合仿真全流程:从环境配置到IP核验证的深度实践 在FPGA开发领域,仿真验证环节往往决定着项目成败。作为Xilinx官方工具链的核心组合,Vivado与Modelsim的联合使用既能发挥Vivado在综合与实现阶段的优势,又能利用M…...

三步构建专业级抖音内容管理系统:douyin-downloader架构解析与实践指南
三步构建专业级抖音内容管理系统:douyin-downloader架构解析与实践指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browse…...

对比自行维护多个API密钥,Taotoken的密钥管理与审计日志更省心
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个API密钥,Taotoken的密钥管理与审计日志更省心 在构建基于大模型的应用时,项目管理者常常需…...

创优必看!鲁班奖工程的八项基本要求
创优必看!鲁班奖工程的八项基本要求 作为建筑工程行业的最高级别奖项,鲁班奖的评选工作严格贯彻执行国家有关基本建设的法律、法规和方针政策,以及国家、行业现行的技术标准、施工规范和技术规程。那么,什么样的工程才能荣获鲁班奖呢? 本文根据《鲁班奖评选工作细则》总…...

TikTok评论采集终极指南:5分钟学会免费批量提取用户评论
TikTok评论采集终极指南:5分钟学会免费批量提取用户评论 【免费下载链接】TikTokCommentScraper 项目地址: https://gitcode.com/gh_mirrors/ti/TikTokCommentScraper 想要快速获取TikTok视频下的所有用户评论进行数据分析?TikTokCommentScraper…...