【Python】强化学习:原理与Python实战

搞懂大模型的智能基因,RLHF系统设计关键问答
RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)虽是热门概念,并非包治百病的万用仙丹。本问答探讨RLHF的适用范围、优缺点和可能遇到的问题,供RLHF系统设计者参考。
📕作者简介:热爱跑步的恒川,致力于C/C++、Java、Python等多编程语言,热爱跑步,喜爱音乐的一位博主。
📗本文收录于恒川的日常汇报系列,大家有兴趣的可以看一看
📘相关专栏C语言初阶、C语言进阶系列、恒川等,大家有兴趣的可以看一看
📙Python零基础入门系列,Java入门篇系列、docker技术篇系列、Apollo的学习录系列正在发展中,喜欢Python、Java、docker的朋友们可以关注一下哦!
原理与Python实战
- 1. RLHF是什么?
- 2. RLHF适用于哪些任务?
- 3. RLHF和其他构建奖励模型的方法相比有何优劣?
- 4. 什么样的人类反馈才是好的反馈
- 5. RLHF算法有哪些类别,各有什么优缺点?
- 6. RLHF采用人类反馈会带来哪些局限?
- 6.1 提供人类反馈的人群可能有偏见或局限性。
- 6.2 人的决策可能没有机器决策那么高明。
- 6.3 没有将提供反馈的人的特征引入到系统。
- 6.4 人性可能导致数据集不完美。
- 7. 如何降低人类反馈带来的负面影响?
1. RLHF是什么?
强化学习利用奖励信号训练智能体。有些任务并没有自带能给出奖励信号的环境,也没有现成的生成奖励信号的方法。为此,可以搭建奖励模型来提供奖励信号。在搭建奖励模型时,可以用数据驱动的机器学习方法来训练奖励模型,并且由人类提供数据。我们把这样的利用人类提供的反馈数据来训练奖励模型以用于强化学习的系统称为人类反馈强化学习,示意图如下。
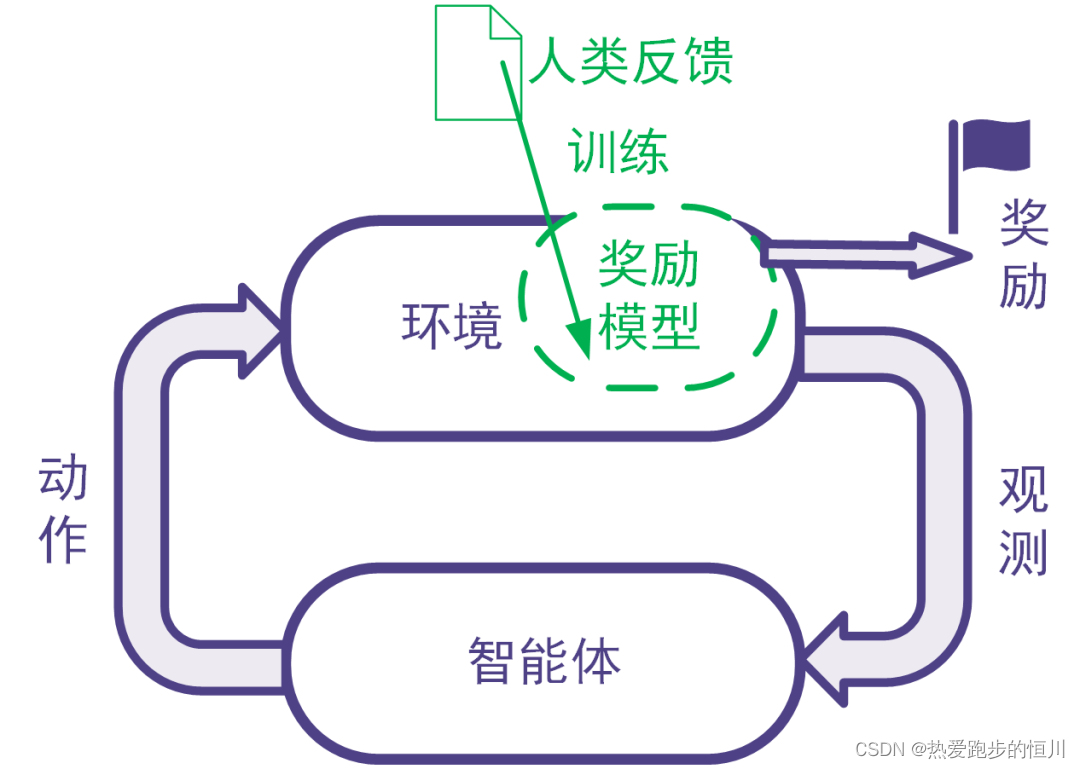
图: 人类反馈强化学习:用人类反馈的数据训练奖励模型,用奖励模型生成奖励信号
2. RLHF适用于哪些任务?
RLHF适合于同时满足下面所有条件的任务:
-
要解决的任务是一个强化学习任务,但是没有现成的奖励信号并且奖励信号的确定方式事先不知道。为了训练强化学习智能体,考虑构建奖励模型来得到奖励信号。
反例:比如电动游戏有游戏得分,那样的游戏程序能够给奖励信号,那我们直接用游戏程序反馈即可,不需要人类反馈。
反例:某些系统奖励信号的确定方式是已知的,比如交易系统的奖励信号可以由赚到的钱完全确定。这时直接可以用已知的数学表达式确定奖励信号,不需要人工反馈。 -
不采用人类反馈的数据难以构建合适的奖励模型,而且人类的反馈可以帮助得到合适的奖励模型,并且人类来提供反馈可以在合理的代价(包括成本代价、时间代价等)内得到。如果用人类反馈得到数据与其他方法采集得到数据相比不具有优势,那么就没有必要让人类来反馈。
3. RLHF和其他构建奖励模型的方法相比有何优劣?
奖励模型可以人工指定,也可以通过有监督模型、逆强化学习等机器学习方法来学习。RLHF使用机器学习方法学习奖励模型,并且在学习过程中采用人类给出的反馈。
比较人工指定奖励模型与采用机器学习方法学习奖励模型的优劣:这与对一般的机器学习优劣的讨论相同。机器学习方法的优点包括不需要太多领域知识、能够处理非常复杂的问题、能够处理快速大量的高维数据、能够随着数据增大提升精度等等。机器学习算法的缺陷包括其训练和使用需要数据时间空间电力等资源、模型和输出的解释型可能不好、模型可能有缺陷、覆盖范围不够或是被攻击(比如大模型里的提示词注入)。
比较采用人工反馈数据和采用非人工反馈数据的优劣:人工反馈往往更费时费力,并且不同人在不同时候的表现可能不一致,并且人还会有意无意地犯错,或是人类反馈的结果还不如用其他方法生成数据来的有效,等等。我们在后文会详细探讨人工反馈的局限性。采用机器收集数据等非人工反馈数据则对收集的数据类型有局限性。有些数据只能靠人类收集,或是用机器难以收集。这样的数据包括是主观的、人文的数据(比如判断艺术作品的艺术性),或是某些机器还做不了的事情(比如玩一个AI暂时还不如人类的游戏)。
4. 什么样的人类反馈才是好的反馈
-
好的反馈需要够用:反馈数据可以用来学成奖励模型,并且数据足够正确、量足够大、覆盖足够全面,使得奖励模型足够好,进而在后续的强化学习中得到令人满意的智能体。
这个部分涉及的评价指标包括:对数据本身的评价指标(正确性、数据量、覆盖率、一致性),对奖励模型及其训练过程的评价指标、对强化学习训练过程和训练得到的智能体的评价指标。 -
好的反馈需要是可得的反馈。反馈需要可以在合理的时间花费和金钱花费的情况下得到,并且在成本可控的同时不会引发其他风险(如法律上的风险)。
涉及的评价指标包括:数据准备时间、数据准备涉及的人员数量、数据准备成本、是否引发其他风险的判断。
5. RLHF算法有哪些类别,各有什么优缺点?
RLHF算法有以下两大类:用监督学习的思路训练奖励模型的RLHF、用逆强化学习的思路训练奖励模型的RLHF。
-
在用监督学习的思路训练奖励模型的RLHF系统中,人类的反馈是奖励信号或是奖励信号的衍生量(如奖励信号的排序)。
直接反馈奖励信号和反馈奖励信号衍生量各有优缺点。这个优点在于获得奖励参考值后可以直接把它用作有监督学习的标签。缺点在于不同人在不同时候给出的奖励信号可能不一致,甚至矛盾。反馈奖励信号的衍生量,比如奖励模型输入的比较或排序。有些任务给出评价一致的奖励值有困难,但是比较大小容易得多。但是没有密集程度的信息。在大量类似情况导致某部分奖励对应的样本过于密集的情况下,甚至可能不收敛。
一般认为,采用比较类型的反馈可以得到更好的性能中位数,但是并不能得到更好的性能平均值。 -
在用逆强化学习的思路训练奖励模型的RLHF系统中,人类的反馈并不是奖励信号,而是使得奖励更大的奖励模型输入。即人类给出了较为正确的数量、文本、分类、物理动作等,告诉奖励模型在这时候奖励应该比较大。这其实就是逆强化学习的思想。
这种方法与用监督学习训练奖励模型的RLHF相比,其优点在于,训练奖励模型的样本点不再拘泥于系统给出的需要评判的样本。因为系统给出的需要评估奖励的样本可能具有局限性(因为系统没有找到最优的区间)。
在系统搭建初期,还可以将用户提供的参考答案用于把最初的强化学习问题转化成模仿学习问题。
这类设计还可以根据反馈的类型进一步分类,一类是让人类独立给出专家意见,另一类是在让人类在已有数据的基础上进行改进。让人类提供意见就类似于让人类提供模仿学习里的专家策略(当然可能略有不同,毕竟奖励模型的输入不只有动作)。让用户在已有的参考内容上修改可以减少人类每个标注的成本,但是已有的参考内容可能会干扰到人类的独立判断(这个干扰可能是正面的也可能是负面的)。
6. RLHF采用人类反馈会带来哪些局限?
前面已经提到,人类反馈可能更费时费力,并且不一定能够保证准确性和一致性。除此之外,下面几点会导致奖励模型不完整不正确,导致后续强化学习训练得到的智能体行为不能令人满意。
6.1 提供人类反馈的人群可能有偏见或局限性。
这个问题和数理统计里的对样本进行抽样方法可能遇到的问题类型。为RLHF系统提供反馈的人群可能并不是最佳的人群。有的时候出于成本、可得性等因素,会选择人力成本低的团队,但是这样的团队可能在专业度不够,或是有着不同的法律、道德和宗教观念,包括歧视性信息。反馈人中可能有恶意者,会提供有误导性的反馈。
6.2 人的决策可能没有机器决策那么高明。
在一些问题上,机器可以比人做的更好,比如对于象棋围棋等棋盘游戏,真人就比不过人工智能程序。在一些问题上,人能够处理的信息没有数据驱动的程序处理的信息全面。比如对于自动驾驶的应用,人类只能根据二维画面和声音进行决策,而程序能够处理连续时间内三维空间的信息。所以在理论上人类反馈的质量是不如程序的。
6.3 没有将提供反馈的人的特征引入到系统。
每个人都是独一无二的:每个人有自己的成长环境、宗教信仰、道德观念、学习和工作经历、知识储备等,我们不可能把每个人的所有特征都引入到系统。在这种情况下,如果忽略不同的人之间在某个特征维度上的差别,那么就会损失到许多有效信息,导致奖励模型性能下降。
以大规模语言模型为例,用户可以通过提示工程指定模型以某种特定的角色或沟通方式来沟通,比如有时要求语言模型的输出文字更有礼貌更客套多奉承套,有时需要输出文字内容掷地有声言之有物少客套;有时要求输出文字更有创造性,有时要求输出文字尊重事实更严谨;有时要求输出简洁扼要,有时要求输出详尽完备提供更多细节;有时要求输出中立客观仅在纯自然科学范围内讨论,有时要求输出多考虑人文社会的环境背景。而提供反馈数据的人的不同身份背景和沟通习惯可能正好对应于不同情况下的输出要求。这种情况下,反馈人的特性就非常重要。
6.4 人性可能导致数据集不完美。
比如语言模型可能会通过拍马屁、戴高帽等行为获得高分评价,但是这样的高分评价可能并没有真正解决问题,有违系统设计的初衷。看似得分很高,但是高得分可能是通过避免争议性话题或是拍马屁拍出来的,而不是真正解决了需要解决问题,没有达到系统设计的初衷。
此外,人类提供反馈还有其他非技术上面的风险,比如泄密等安全性风险、监管法律风险等。
7. 如何降低人类反馈带来的负面影响?
针对人类反馈费时费力且可能导致奖励模型不完整不正确的问题,可以在收集人类反馈数据的同时就训练奖励模型、训练智能体,并全面评估奖励模型和智能体,以便于尽早发现人类反馈的缺陷。发现缺陷后,及时进行调整。
针对人类反馈中出现的反馈质量问题以及错误反馈,可以对人类反馈进行校验和审计,如引入已知奖励的校验样本来校验人类反馈的质量,或为同一样本多次索取反馈并比较多次反馈的结果等。
针对反馈人的选择不当的问题,可以在有效控制人力成本的基础上,采用科学的方法选定提供反馈的人。可以参考数理统计里的抽样方法,如分层抽样、整群抽样等,使得反馈人群更加合理。
对于反馈数据中未包括反馈人特征导致奖励模型不够好的问题,可以收集反馈人的特征,并将这些特征用于奖励模型的训练。比如,在大规模语言模型的训练中可以记录反馈人的职业背景(如律师、医生等),并在训练奖励模型时加以考虑。当用户要求智能体像律师一样工作时,更应该利用由律师提供的数据学成的那部分奖励模型来提供奖励信号;当用户要求智能体像医生一样工作时,更应该利用由医生提供的数据学成的那部分奖励模型来提供奖励信号。
另外,在整个系统的实施过程中,可以征求专业人士意见,以减小其中法律和安全风险。
本文内容摘编自《强化学习:原理与Python实战》,经出版方授权发布。
好书推荐
《强化学习:原理与Python实战》

理论完备,涵盖强化学习主干理论和常见算法,带你参透ChatGPT技术要点;
实战性强,每章都有编程案例,深度强化学习算法提供TenorFlow和PyTorch对照实现;
配套丰富,逐章提供知识点总结,章后习题形式丰富多样。还有Gym源码解读、开发环境搭建指南、习题答案等在线资源助力自学。
⭐京东链接:https://item.jd.com/13815337.html

参考资料:
肖智清。强化学习:原理与Python实战。机械工业出版社。2023. P. Christiano et. al., Deep
reinforcement learning from human preferences. arxiv: 1706.03741. S.
Casper, et. al. Open problems and fundamental limitations of
reinforcement learning from human feedback. arxiv: 2307.15217.
了解数学思想,本质尽在掌握
如果这份博客对大家有帮助,希望各位给恒川一个免费的点赞👍作为鼓励,并评论收藏一下⭐,谢谢大家!!!
制作不易,如果大家有什么疑问或给恒川的意见,欢迎评论区留言。
相关文章:
【Python】强化学习:原理与Python实战
搞懂大模型的智能基因,RLHF系统设计关键问答 RLHF(Reinforcement Learning with Human Feedback,人类反馈强化学习)虽是热门概念,并非包治百病的万用仙丹。本问答探讨RLHF的适用范围、优缺点和可能遇到的问题ÿ…...

设计模式——合成复用原则
文章目录 合成复用原则设计原则核心思想合成案例聚合案例继承案例优缺点 合成复用原则 原则是尽量使用合成/聚合的方式,而不是使用继承 设计原则核心思想 找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起。…...

基于OpenCV实战(基础知识一)
目录 简介 1.计算机眼中的图像 2.图片的读取、显示与保存 3.视频的读取与显示 简介 OpenCV是一个流行的开源计算机视觉库,由英特尔公司发起发展。它提供了超过2500个优化算法和许多工具包,可用于灰度、彩色、深度、基于特征和运动跟踪等的图像处理和…...

如何高效的接入第三方接口
作为程序员的我们,经常会接到领导的安排,接入某某的接口,方面我们如何如何, 例如:领导在1号时给作为员工的你说,最近系统需要增加一个新的支付方式,一会和对方技术组建一个群,有什么问题,可以直接在群里说,最近还说,尽快接入,客户等着用,让你在5号前,完成接入工…...

docker pip下载依赖超时或失败问题解决
Docker容器使用pip安装Python库时超时,可能是由于多种原因。以下是一些建议和解决方法: 使用国内镜像源: 如果你位于中国,可以尝试更换到国内的镜像源。例如,可以使用阿里云、腾讯云、清华大学提供的镜像。 你可以在Dockerfile中添…...

python并发编程
一、程序提速的方法 二、python对并发编程的支持 多线程:threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成;多进程:multiprocess,利用多核CPU的能力,真正的并行执行任务&am…...

【面试题】:前端怎么实现权限设计及遇到的bug
一.权限的概念 前端权限分为页面权限、按钮权限、API权限。 二.页面权限的实现过程 ①用户登录进去调用获取用户信息接口,后端会给我们返回一个权限标识符 ②在获取到数据之后,我们就要判断用户能访问到哪些页面,我们可以在vuex中permission模块中的action…...

Vue 2 插槽
可以先阅读组件基础-简单了解通过插槽分发内容。 一、插槽定义 插槽将子组件标签间的内容分发到子组件模板的<slot>标签位置。 如果没有<slot>标签,那么该内容将被丢弃。 二、编译作用域 内容在哪个作用域编译,就可以访问哪个作用域的数据…...

Spring 容器启动耗时统计
为了了解 Spring 为什么会启动那么久,于是看了看怎么统计一下加载 Bean 的耗时。 极简版 几行代码搞定。 import org.springframework.beans.BeansException; import org.springframework.beans.factory.config.BeanPostProcessor;import java.util.HashMap; imp…...

1. 优化算法学习
参考文献 1609:An overview of gradient descent optimization algorithms 从 SGD 到 Adam —— 深度学习优化算法概览(一) - 知乎 机器学习札记 - 知乎...

再获荣誉丨通付盾WAAP解决方案获“金鼎奖”优秀金融科技解决方案
今年四月,2023中国国际金融展在首钢会展中心成功落下帷幕。中国国际金融展作为金融开放创新成果的展示、交流、传播平台,历经多年发展,已成为展示中国金融发展成就、宣传金融改革成果、促进金融产业创新和推动金融信息化发展的有效平台。 “金鼎奖”评选…...

【腾讯云 TDSQL-C Serverless 产品测评】“橡皮筋“一样的数据库『MySQL高压篇』
【腾讯云 TDSQL-C Serverless 产品测评】"橡皮筋"一样的数据库 活动介绍服务一览何为TDSQL ?Serverless 似曾相识? 降本增效,不再口号?动手环节 --- "压力"山大实验前瞻稍作简介资源扩缩范围(CCU&…...

python http文件上传
server端代码 import os import cgi from http.server import SimpleHTTPRequestHandler, HTTPServer# 服务器地址和端口 host = 0.0.0.0 port = 8080# 处理文件上传的请求 class FileUploadHandler(SimpleHTTPRequestHandler):def do_POST(self):# 解析多部分表单数据form = …...

Android学习之路(9) Intent
Intent 是一个消息传递对象,您可以用来从其他应用组件请求操作。尽管 Intent 可以通过多种方式促进组件之间的通信,但其基本用例主要包括以下三个: 启动 Activity Activity 表示应用中的一个屏幕。通过将 Intent 传递给 startActivity()&…...
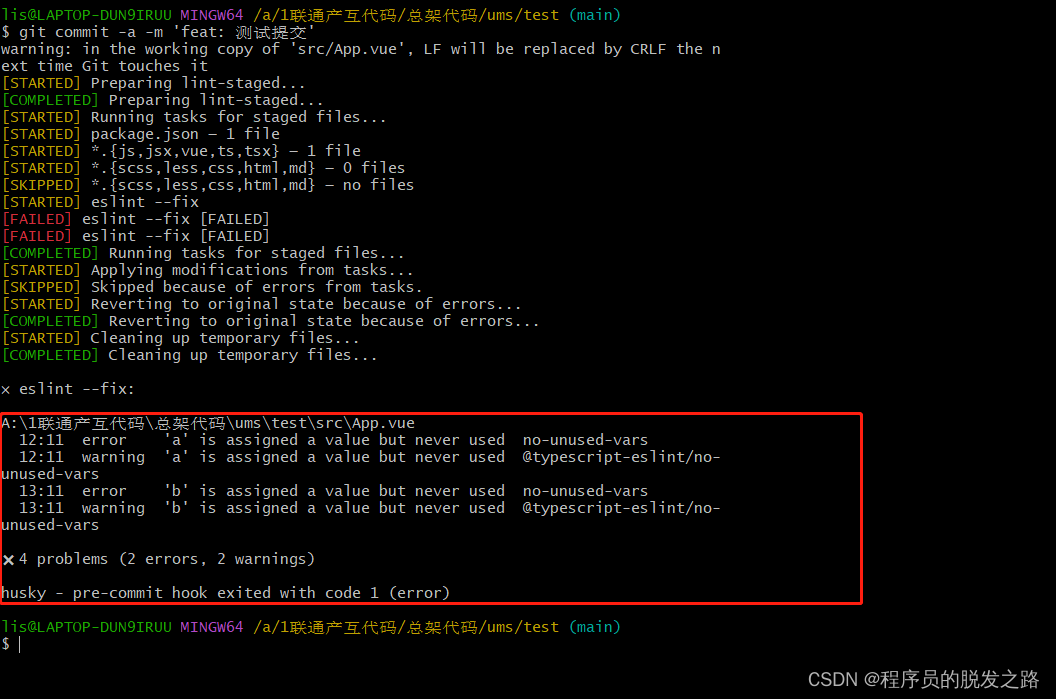
vue项目配置git提交规范
vue项目配置git提交规范 一、背景介绍二、husky、lint-staged、commitlint/cli1.husky2.lint-staged3.commitlint/cli 三、具体使用1.安装依赖2.运行初始化脚本3.在package.json中配置lint-staged4.根目录新增 commitlint.config.js 4.提交测试1.提示信息格式错误时2.eslint校验…...

影响交叉导轨运行速度的因素有哪些?
交叉导轨具有精度高,速度快,承载能力大、结构简单等特点,被广泛应用在固晶机、点胶设备、自动化设备、OA机器及其周边机器、测定器、印刷基板开孔机,精密机器,光学测试仪、光学工作台、操纵机构、X 射缐装置等的滑座部…...

List转Map
一、list转map Map<Long, User> maps userList.stream().collect(Collectors.toMap(User::getId,Function.identity())); 看来还是使用JDK 1.8方便一些。 二、另外,转换成map的时候,可能出现key一样的情况,如果不指定一个覆盖规则&…...

ES:一次分片设计问题导致的故障
### 现象: 1. 单节点CPU持续高 2.写入骤降 3.线程池队列积压,但没有reject 4.使用方没有记录日志 ### 排查 1.ES监控 只能看到相应的结果指标,无法反应出原因。 2.ES日志:大量日志打印相关异常(routate等调用栈&a…...
vue 简单实验 自定义组件 综合应用 传参数 循环
1.代码 <script src"https://unpkg.com/vuenext" rel"external nofollow" ></script> <div id"todo-list-app"><ol><!--现在我们为每个 todo-item 提供 todo 对象todo 对象是变量,即其内容可以是动态的。…...

【OpenCV实战】2.OpenCV基本数据类型实战
OpenCV基本数据类型实战 〇、实战内容1 OpenCV helloworld1.1 文件结构类型1.2 CMakeList.txt1.3 Helloworld 2. Image的基本操作3. OpenCV 基本数据类型4. 读取图片的像素 & 遍历图片4.1 获取制定像素4.2 遍历图片 5. 图片反色5.1 方法1 :遍历5.2 方法2 &#…...
)
保姆级教程:用kitti2bag把KITTI数据集转成ROS bag,新手避坑指南(附2011_09_26小数据集下载)
从KITTI到ROS Bag:零基础实战转换指南 第一次接触KITTI数据集和ROS时,我完全被那些复杂的文件结构和专业术语搞晕了。作为一个计算机视觉和机器人领域的经典数据集,KITTI包含了丰富的传感器数据,但直接使用这些原始数据对新手来说…...

LLaMA论文里没细说的三个“小”改进:RMSNorm、SwiGLU和RoPE到底强在哪?
LLaMA模型三大底层优化技术解析:RMSNorm、SwiGLU与RoPE的设计哲学 当大多数人关注大语言模型的参数量级时,LLaMA团队却在微观架构层面做了一系列精妙改进。这些看似微小的技术选择,实则是支撑模型高效运行的关键支柱。本文将带您深入LLaMA的&…...

免费扩展Windows虚拟显示器:5分钟打造高效多屏工作空间
免费扩展Windows虚拟显示器:5分钟打造高效多屏工作空间 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc 项目地址: https://gitco…...

BOTW-Save-Editor-GUI 完整技术指南:Nintendo Switch 塞尔达传说存档编辑终极方案
BOTW-Save-Editor-GUI 完整技术指南:Nintendo Switch 塞尔达传说存档编辑终极方案 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI BOTW-Save-Editor-GU…...

DriverStore Explorer:Windows驱动存储管理的终极解决方案与实战指南
DriverStore Explorer:Windows驱动存储管理的终极解决方案与实战指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer DriverStore Explorer(简称RAPR)…...

信步SV1a-13714P嵌入式主板拆解:工业边缘计算硬件选型与实战部署指南
1. 项目概述:一块嵌入式主板的深度拆解最近在整理一个工业边缘计算的项目资料,翻出了几块之前用过的“信步科技SV1a-13714P”嵌入式主板。这块板子虽然不是什么新潮的玩意儿,但在特定的工业场景里,它就像一颗“定心丸”࿰…...

【Android】CloneTTS最强朗读听书引擎-可克隆一切音色
【Android】CloneTTS最强朗读听书引擎-可克隆一切音色 链接:https://pan.xunlei.com/s/VOsu4mh3O_d7zjeERkKPfcG4A1?pwddi3y# CloneTTS 是一款运行在安卓系统本地的文字转语音(TTS)原生引擎,允许用户离线克隆所需的声音并直接使用该声音来朗读书籍或长…...

STK Connectors接口函数全解析:如何用MATLAB脚本自动化你的航天仿真流程
STK Connectors接口函数全解析:如何用MATLAB脚本自动化你的航天仿真流程 航天仿真领域的工作者常常面临一个矛盾:STK提供了强大的轨道计算和场景可视化能力,但手动操作界面进行复杂任务时效率低下;MATLAB擅长处理复杂逻辑和批量计…...

【亲测免费】 工业自动化+Modbus通讯协议+libmodbus开源库+Windows x64编译教程
工业自动化Modbus通讯协议libmodbus开源库Windows x64编译教程 【下载地址】工业自动化Modbus通讯协议libmodbus开源库Windowsx64编译教程 本资源适用于使用libmodbus开源库进行数据通信过程中的环境搭建过程。由于最新版本的libmodbus并不能通过官网提供的教程实现Windows下的…...

3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放
3分钟解锁音乐自由:ncmdump让网易云音乐NCM文件随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的歌曲只能在特定客户端播放而烦恼吗?当您精心收藏的音乐被NCM加密格式束缚&…...