MDTA模块(Restormer)
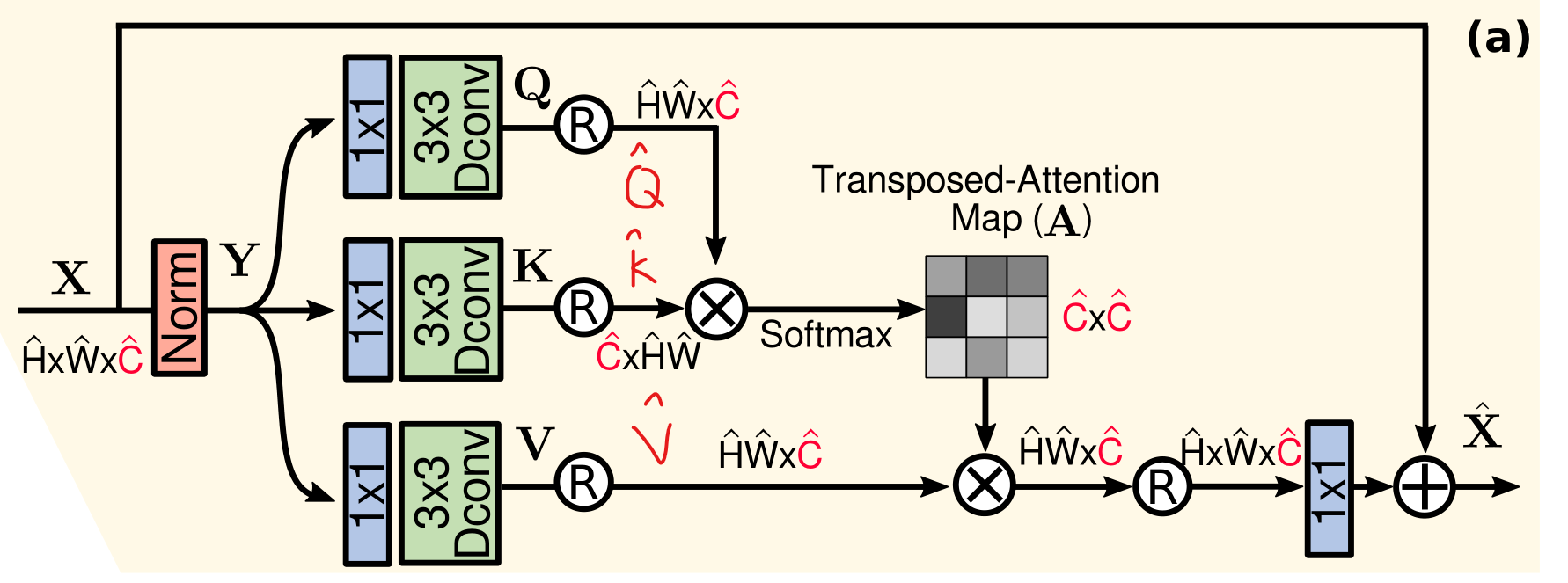
From a layer normalized tensor Y ∈ R H ^ × W ^ × C ^ \mathbf{Y} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} Y∈RH^×W^×C^, our MDTA first generates query ( Q ) (\mathbf{Q}) (Q), key ( K ) (\mathbf{K}) (K) and value ( V ) (\mathbf{V}) (V) projections, enriched with local context. It is achieved by applying 1 × 1 1 \times 1 1×1 convolutions to aggregate pixel-wise cross-channel context followed by 3 × 3 3 \times 3 3×3 depth-wise convolutions to encode channel-wise spatial context, yielding Q = W d Q W p Q Y , K = W d K W p K Y \mathbf{Q}=W_d^Q W_p^Q \mathbf{Y}, \mathbf{K}=W_d^K W_p^K \mathbf{Y} Q=WdQWpQY,K=WdKWpKY and V = W d V W p V Y \mathbf{V}=W_d^V W_p^V \mathbf{Y} V=WdVWpVY. Where W p ( ⋅ ) W_p^{(\cdot)} Wp(⋅) is the 1 × 1 1 \times 1 1×1 point-wise convolution and W d ( ⋅ ) W_d^{(\cdot)} Wd(⋅) is the 3 × 3 3 \times 3 3×3 depth-wise convolution. We use bias-free convolutional layers in the network. Next, we reshape query and key projections such that their dot-product interaction generates a transposed-attention map A \mathbf{A} A of size R C ^ × C ^ \mathbb{R}^{\hat{C} \times \hat{C}} RC^×C^, instead of the huge regular attention map of size R H ^ W ^ × H ^ W ^ \mathbb{R}^{\hat{H} \hat{W} \times \hat{H} \hat{W}} RH^W^×H^W^. Overall, the MDTA process is defined as:
X ^ = W p Attention ( Q ^ , K ^ , V ^ ) + X Attention ( Q ^ , K ^ , V ^ ) = V ^ ⋅ Softmax ( K ^ ⋅ Q ^ / α ) \hat{\mathbf{X}}=W_p \operatorname{Attention}(\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}})+\mathbf{X}\\ \operatorname{Attention}(\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}})=\hat{\mathbf{V}} \cdot \operatorname{Softmax}(\hat{\mathbf{K}} \cdot \hat{\mathbf{Q}} / \alpha) X^=WpAttention(Q^,K^,V^)+XAttention(Q^,K^,V^)=V^⋅Softmax(K^⋅Q^/α)
where X \mathbf{X} X and X ^ \hat{\mathbf{X}} X^ are the input and output feature maps; Q ^ ∈ R H ^ W ^ × C ^ ; K ^ ∈ R C ^ × H ^ W ^ ; \hat{\mathbf{Q}} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}} ; \hat{\mathbf{K}} \in \mathbb{R}^{\hat{C} \times \hat{H} \hat{W}} ; Q^∈RH^W^×C^;K^∈RC^×H^W^; and V ^ ∈ R H ^ W ^ × C ^ \hat{\mathbf{V}} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}} V^∈RH^W^×C^ matrices are obtained after reshaping tensors from the original size R H ^ × W ^ × C ^ \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} RH^×W^×C^. Here, α \alpha α is a learnable scaling parameter to control the magnitude of the dot product of K ^ \hat{\mathbf{K}} K^ and Q ^ \hat{\mathbf{Q}} Q^ before applying the softmax function. Similar to the conventional multi-head SA , we divide the number of channels into ‘heads’ and learn separate attention maps in parallel.
## Multi-DConv Head Transposed Self-Attention (MDTA)
class Attention(nn.Module):def __init__(self, dim, num_heads, bias):super(Attention, self).__init__()self.num_heads = num_headsself.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)def forward(self, x):b, c, h, w = x.shapeqkv = self.qkv_dwconv(self.qkv(x))q, k, v = qkv.chunk(3, dim=1)q = rearrange(q, 'b (head c) h w -> b head c (h w)',head=self.num_heads)k = rearrange(k, 'b (head c) h w -> b head c (h w)',head=self.num_heads)v = rearrange(v, 'b (head c) h w -> b head c (h w)',head=self.num_heads)q = torch.nn.functional.normalize(q, dim=-1)k = torch.nn.functional.normalize(k, dim=-1)attn = (q @ k.transpose(-2, -1)) * self.temperatureattn = attn.softmax(dim=-1)out = (attn @ v)out = rearrange(out, 'b head c (h w) -> b (head c) h w',head=self.num_heads, h=h, w=w)out = self.project_out(out)return out这段代码并没有实现图中的Norm模块,该模块的实现可以参考Layer Normalization(层规范化)。我们看一下Transformer Block是如何包装的:
class TransformerBlock(nn.Module):def __init__(self, dim, num_heads, ffn_expansion_factor, bias, LayerNorm_type):super(TransformerBlock, self).__init__()self.norm1 = LayerNorm(dim, LayerNorm_type)self.attn = Attention(dim, num_heads, bias)self.norm2 = LayerNorm(dim, LayerNorm_type)self.ffn = FeedForward(dim, ffn_expansion_factor, bias)def forward(self, x):x = x + self.attn(self.norm1(x))#MDTAx = x + self.ffn(self.norm2(x))return x
可以看到实现的时候是先Norm,然后通过Attention,最后再残差连接,这整个流程才是上图所示
相关文章:
MDTA模块(Restormer)
From a layer normalized tensor Y ∈ R H ^ W ^ C ^ \mathbf{Y} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} Y∈RH^W^C^, our MDTA first generates query ( Q ) (\mathbf{Q}) (Q), key ( K ) (\mathbf{K}) (K) and value ( V ) (\mathbf{V}) (V) project…...

C++ 新特性 | C++ 11 | decltype 关键字
一、decltype 关键字 1、介绍 decltype 是 C11 新增的一个用来推导表达式类型的关键字。和 auto 的功能一样,用来在编译时期进行自动类型推导。引入 decltype 是因为 auto 并不适用于所有的自动类型推导场景,在某些特殊情况下 auto 用起来很不方便&…...

2023国赛数学建模思路 - 案例:退火算法
文章目录 1 退火算法原理1.1 物理背景1.2 背后的数学模型 2 退火算法实现2.1 算法流程2.2算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 退火算法原理 1.1 物理背景 在热力学上&a…...
ubuntu20.04 编译安装运行emqx
文章目录 安装依赖编译运行登录dashboard压力测试 安装依赖 Erlang/OTP OTP 24 或 25 版本 apt-get install libncurses5-dev sudo apt-get install erlang如果安装的erlang版本小于24的话,可以使用如下方法自行编译erlang 1.源码获取 wget https://github.com/erla…...

ARM linux ALSA 音频驱动开发方法
+他V hezkz17进数字音频系统研究开发交流答疑群(课题组) 一 linux ALSA介绍 ALSA (Advanced Linux Sound Architecture) 是一个用于提供音频功能的开源软件框架。它是Linux操作系统中音频驱动程序和用户空间应用程序之间的接口。ALSA 提供了访问声卡硬件的低级别API,并支持…...
)
设计模式二十三:模板方法模式(Template Method Pattern)
定义了一个算法的框架,将算法的具体步骤延迟到子类中实现。这样可以在不改变算法结构的情况下,允许子类重写算法的特定步骤以满足自己的需求 模版方法使用场景 算法框架固定,但具体步骤可以变化:当你有一个算法的整体结构是固定…...
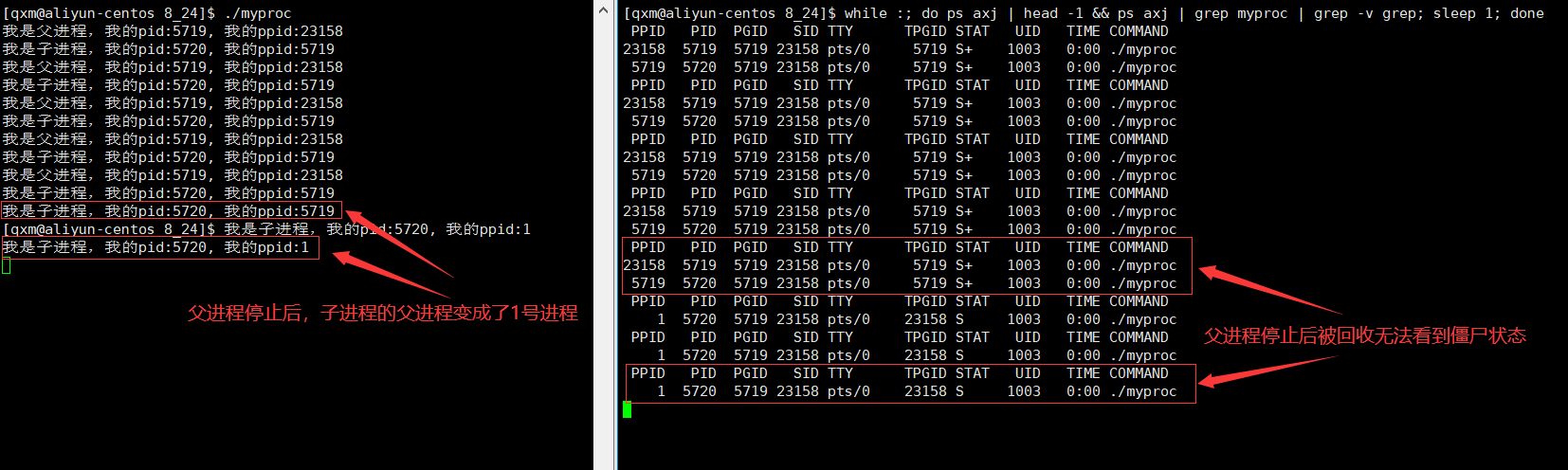
[Linux]进程状态
[Linux]进程状态 文章目录 [Linux]进程状态进程状态的概念阻塞状态挂起状态Linux下的进程状态孤儿进程 进程状态的概念 了解进程状态前,首先要知道一个正在运行的进程不是无时无刻都在CPU上进行运算的,而是在操作系统的管理下,和其他正在运行…...
Python爬虫逆向实战案例(五)——YRX竞赛题第五题
题目:抓取全部5页直播间热度,计算前5名直播间热度的加和 地址:https://match.yuanrenxue.cn/match/5 cookie中m值分析 首先打开开发者工具进行抓包分析,从抓到的包来看,参数传递了查询参数m与f,同时页面中…...

js识别图片中的文字插件 tesseract.js
使用方法及步骤 1.安装依赖 npm i tesseract.js 2.引入插件 import { createWorker } from tesseract.js;//worker多线程引入这个import Tesseract from tesseract.js;//js单线程引入这个 3.使用插件识别图片 //使用worker线程识别(async () > {console.time()const wo…...
)
Linux设备驱动移植(设备数)
一、设备数 设备树是一种描述硬件信息的数据结构,Linux内核运行时可以通过设备树将硬件信息直接传递给Linux内核,而不再需要在Linux内核中包含大量的冗余编码 设备数语法概述 设备树文件 dts 设备树源文件 dtsi 类似于头文件,包含一些公共的…...

【移动端开发】鸿蒙系统开发入门:代码示例与详解
一、引言 随着华为鸿蒙系统的日益成熟,越来越多的开发者开始关注这一新兴的操作平台。本文旨在为初学者提供一份详尽的鸿蒙系统开发入门指南,通过具体的代码示例,引导大家逐步掌握鸿蒙开发的基本概念和技术。 二、鸿蒙系统开发基础 鸿蒙系…...

Jenkins的流水线详解
来源:u.kubeinfo.cn/ozoxBB 什么是流水线 声明式流水线 Jenkinsfile 的使用 什么是流水线 jenkins 有 2 种流水线分为声明式流水线与脚本化流水线,脚本化流水线是 jenkins 旧版本使用的流水线脚本,新版本 Jenkins 推荐使用声明式流水线。…...

DIFFEDIT-图像编辑论文解读
文章目录 摘要算法Step1:计算编辑maskStep2:编码Step3:使用mask引导进行解码理论分析: 实验数据集:扩散模型:ImageNet数据集上实验消融实验IMAGEN数据集上实验COCO数据集上实验 结论 论文: 《D…...

【优选算法】—— 字符串匹配算法
在本期的字符串匹配算法中,我将给大家带来常见的两种经典的示例: 1、暴力匹配(BF)算法 2、KMP算法 目录 (一)暴力匹配(BF)算法 1、思想 2、演示 3、代码展示 (二&…...

Docker容器:docker consul的注册与发现及consul-template守护进程
文章目录 一.docker consul的注册与发现介绍1.什么是服务注册与发现2.什么是consul3.docker consul的应用场景4.consul提供的一些关键特性5.数据流向 二.consul部署1.consul服务器(192.168.198.12)(1)建立 Consul 服务启动consul后…...
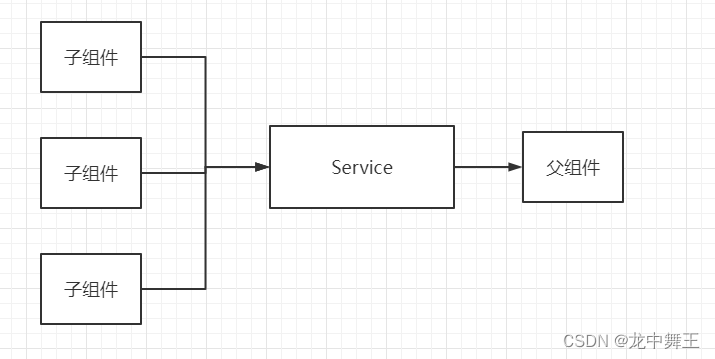
Blazor 依赖注入妙用:巧设回调
文章目录 前言依赖注入特性需求解决方案示意图 前言 依赖注入我之前写过一篇文章,没看过的可以看看这个。 C# Blazor 学习笔记(10):依赖注入 依赖注入特性 只能Razor组件中注入所有Razor组件在作用域注入的都是同一个依赖。作用域可以看看我之前的文章。 需求 …...
)
Python 基础 -- Tutorial(三)
7、输入和输出 有几种方法可以表示程序的输出;数据可以以人类可读的形式打印出来,或者写入文件以备将来使用。本章将讨论其中的一些可能性。 7.1 更花哨的输出格式 到目前为止,我们已经遇到了两种写值的方法:表达式语句和print()函数。(第三种方法是使…...
基于STM32的四旋翼无人机项目(二):MPU6050姿态解算(含上位机3D姿态显示教学)
前言:本文为手把手教学飞控核心知识点之一的姿态解算——MPU6050 姿态解算(飞控专栏第2篇)。项目中飞行器使用 MPU6050 传感器对飞行器的姿态进行解算(四元数方法),搭配设计的卡尔曼滤波器与一阶低通滤波器…...

微信小程序开发教学系列(1)- 开发入门
第一章:微信小程序简介与入门 1.1 简介 微信小程序是一种基于微信平台的应用程序,可以在微信内直接使用,无需下载和安装。它具有小巧、高效、便捷的特点,可以满足用户在微信中获取信息、使用服务的需求。 微信小程序采用前端技…...
Nginx虚拟主机(server块)部署Vue项目
需求 配置虚拟主机,实现一个Nginx运行多个服务。 实现 使用Server块。不同的端口号,表示不同的服务;同时在配置中指定,Vue安装包所在的位置。 配置 Vue项目,放在 html/test 目录下。 config中的配置如下…...

数据血缘是什么?怎么建设数据血缘?
今年跟十几个企业老板聊AI落地,发现大家都有一个共识:不上AI是等死,乱上AI是找死。为什么?因为AI这玩意儿就像顶级厨师,食材不新鲜、来历不明,做出来的菜照样能毒倒一片。这里的食材,就是数据。…...

Godot引擎集成Box2D物理插件:提升2D游戏物理模拟精度与稳定性
1. 项目概述:当Godot遇上Box2D如果你是一个用过Godot引擎,特别是做过2D物理游戏的开发者,大概率对它的默认物理引擎有过又爱又恨的复杂感情。Godot内置的物理引擎在处理一些简单碰撞、刚体运动时非常方便,但一旦项目需求变得复杂—…...
)
【绝密级】航天科研院所NotebookLM部署红线清单:绕过敏感数据泄露风险的6层沙箱隔离架构(附工信部备案编号参考)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM航天科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,其核心能力在于对用户上传的私有文档进行深度语义理解与上下文关联推理。在航天科学研究场景中,…...

探索SillyTavern:为AI角色注入灵魂的PNG元数据魔法
探索SillyTavern:为AI角色注入灵魂的PNG元数据魔法 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 想象一下,当你分享一张角色图片时,你实际上是在分享一…...

如何在卡片悬停时添加内边距而不引起布局偏移
本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略,在卡片 hover 时安全添加 padding,避免因盒模型计算导致的布局抖动或相邻卡片位移。 本文详解如何通过 box-sizing: border-box、合理设置宽高约束及子元素尺寸策略&am…...

开源可观测性平台SigNoz:一体化监控与分布式链路追踪实战
1. 项目概述:从可观测性痛点出发,为什么我们需要SigNoz在云原生和微服务架构成为主流的今天,一个应用可能由数十甚至上百个服务组成,它们分布在不同的容器、节点甚至云区域中。当用户反馈“页面加载慢”或“功能报错”时ÿ…...

独立开发者如何借助Taotoken模型广场为不同任务选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken模型广场为不同任务选型 作为一名独立开发者,日常工作中常需处理多种类型的任务࿱…...

实在Agent物流对账全流程自动化方案与落地案例:2026智享财务新标杆
在2026年5月这个生成式AI深度重构实体经济的关键周期,全球物流行业已全面跨入“智能体(Agent)常态化运营”时代。根据《2026年全球供应链数字化趋势报告》显示,超过65%的大型物流企业已部署了具备自主决策能力的智能体来替代传统的…...

Warcraft Helper完整指南:3步解决魔兽争霸3在Win10/Win11的兼容性问题
Warcraft Helper完整指南:3步解决魔兽争霸3在Win10/Win11的兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在W…...

aivectormemory:轻量级向量记忆库,为AI应用开发提供灵活存储方案
1. 项目概述:向量记忆库的“新玩家”最近在折腾AI应用开发,特别是涉及到需要让模型“记住”大量私有知识或者进行复杂对话的场景时,一个绕不开的核心组件就是向量数据库。大家熟知的Pinecone、Weaviate、Milvus这些方案固然强大,但…...