基于亚马逊云科技服务,构建大语言模型问答知识库
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)+知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通用大语言模型的一些短板,解决通用大语言模型在专业领域回答缺乏依据、存在幻觉等问题。其基本思路是把私域知识文档进行切片然后向量化后续通过向量检索进行召回,再作为上下文输入到大语言模型进行归纳总结。
在这个技术方向的具体实践中,知识库可以采取基于倒排和基于向量的两种索引方式进行构建,它对于知识问答流程中的知识召回这步起关键作用,和普通的文档索引或日志索引不同,知识的向量化需要借助深度模型的语义化能力,存在文档切分,向量模型部署&推理等额外步骤。知识向量化建库过程中,不仅仅需要考虑原始的文档量级,还需要考虑切分粒度,向量维度等因素,最终被向量数据库索引的知识条数可能达到一个非常大的量级,可能由以下两方面的原因引起:
-
各个行业的既有文档量很高,如金融、医药、法律领域等,新增量也很大。
-
为了召回效果的追求,对文档的切分常常会采用按句或者按段进行多粒度的冗余存贮。
这些细节对知识向量数据库的写入和查询性能带来一定的挑战,为了优化向量化知识库的构建和管理,基于亚马逊云科技的服务,构建了如下图的知识库构建流程:
-
通过S3 Bucket的Handler实时触发Lambda启动对应知识文件入库的Glue job
-
Glue Job中会进行文档解析和拆分,并调用SageMaker的Embedding模型进行向量化
-
通过Bulk方式注入到Amazon OpenSearch中去

并对整个流程中涉及的多个方面,包括如何进行知识向量化,向量数据库调优总结了一些最佳实践和心得。
知识向量化
文档拆分
知识向量化的前置步骤是进行知识的拆分,语义完整性的保持是最重要的考量。分两个方面展开讨论。该如何选用以下两个关注点分别总结了一些经验:
a. 拆分片段的方法
关于这部分的工作,Langchain作为一种流行的大语言模型集成框架,提供了非常多的Document Loader和Text Spiltters,其中的一些实现具有借鉴意义,但也有不少实现效果是重复的。
目前使用较多的基础方式是采用Langchain中的RecursiveCharacterTextSplitter,属于是Langchain的默认拆分器。它采用这个多级分隔字符列表——[“\n\n”, “\n”, ” “, “”]来进行拆分,默认先按照段落做拆分,如果拆分结果的chunk_size超出,再继续利用下一级分隔字符继续拆分,直到满足chunk_size的要求。
但这种做法相对来说还是比较粗糙,还是可能会造成一些关键内容会被拆开。对于一些其他的文档格式可以有一些更细致的做法。
-
FAQ文件,必须按照一问一答粒度拆分,后续向量化的输入可以仅仅使用问题,也可以使用问题+答案
-
Markdown文件,”#”是用于标识标题的特殊字符,可以采用MarkdownHeaderTextSplitter作为分割器,它能更好的保证内容和标题对应的被提取出来。
PDF文件,会包含更丰富的格式信息。Langchain里面提供了非常多的Loader,但Langchain中的PDFMinerPDFasHTMLLoader的切分效果上会更好,它把PDF转换成HTML,通过HTML的
块进行切分,这种方式能保留每个块的字号信息,从而可以推导出每块内容的隶属关系,把一个段落的标题和上一级父标题关联上,使得信息更加完整。
b. 模型对片段长度的支持
由于拆分的片段后续需要通过向量化模型进行推理,所以必须考虑向量化模型的Max_seq_length的限制,超出这个限制可能会导致出现截断,导致语义不完整。从支持的Max_seq_length来划分,目前主要有两类Embedding模型,如下表所示(这四个是有过实践经验的模型)。
| 模型名称 | Max_seq_length |
| paraphrase-multilingual-mpnet-base-v2(sbert.net) | 128 |
| text2vec-base-chinese(text2vec) | 128 |
| text2vec-large-chinese(text2vec) | 512 |
| text-embedding-ada-002(openai) | 8192 |
这里的Max_seq_length是指Token数,和字符数并不等价。依据之前的测试经验,前三个模型一个token约为1.5个汉字字符左右。而对于大语言模型,如chatglm,一个token一般为2个字符左右。如果在切分时不方便计算token数,也可以简单按照这个比例来简单换算,保证不出现截断的情况。
前三个模型属于基于Bert的Embedding模型,OpenAI的text-embedding-ada-002模型是基于GPT3的模型。前者适合句或者短段落的向量化,后者OpenAI的SAAS化接口,适合长文本的向量化,但不能私有化部署。
可以根据召回效果进行验证选择。从目前的实践经验上看text-embedding-ada-002对于中文的相似性打分排序性可以,但区分度不够(集中0.7左右),不太利于直接通过阈值判断是否有相似知识召回。
另外,对于长度限制的问题也有另外一种改善方法,可以对拆分的片段进行编号,相邻的片段编号也临近,当召回其中一个片段时,可以通过向量数据库的range search把附近的片段也召回回来,也能保证召回内容的语意完整性。
向量化模型选择
前面提到四个模型只是提到了模型对于文本长度的支持差异,效果方面目前并没有非常权威的结论。可以通过leaderboard来了解各个模型的性能,榜上的大多数的模型的评测还是基于公开数据集的benchmark,对于真实生产中的场景benchmark结论是否成立还需要case by case地来看。但原则上有以下几方面的经验可以分享:
-
经过垂直领域Finetune的模型比原始向量模型有明显优势
-
目前的向量化模型分为两类,对称和非对称。未进行微调的情况下,对于FAQ建议走对称召回,也就是Query到Question的召回。对于文档片段知识,建议使用非对称召回模型,也就是Query到Answer(文档片段)的召回。
-
没有效果上的明显的差异的情况下,尽量选择向量维度短的模型,高维向量(如openai的text-embedding-ada-002)会给向量数据库造成检索性能和成本两方面的压力。
向量化并行
真实的业务场景中,文档的规模在百到百万这个数量级之间。按照冗余的多级召回方式,对应的知识条目最高可能达到亿的规模。由于整个离线计算的规模很大,所以必须并发进行,否则无法满足知识新增和向量检索效果迭代的要求。步骤上主要分为以下三个计算阶段。

文档切分并行
计算的并发粒度是文件级别的,处理的文件格式也是多样的,如TXT纯文本,Markdown,PDF等,其对应的切分逻辑也有差异。而使用Spark这种大数据框架来并行处理过重,并不合适。使用多核实例进行多进程并发处理则过于原始,任务的观测追踪上不太方便。所以可以选用AWS Glue的Python shell引擎进行处理。主要有如下好处:
-
方便的按照文件粒度进行并发,并发度简单可控。具有重试、超时等机制,方便任务的追踪和观察,日志直接对接到AWS CloudWatch
-
方便的构建运行依赖包,通过参数–additional-python-modules指定即可,同时Glue Python的运行环境中已经自带了opensearch_py等依赖
向量化推理并行
由于切分的段落和句子相对于文档数量也膨胀了很多倍,向量模型的推理吞吐能力决定了整个流程的吞吐能力。这里采用SageMaker Endpoint来部署向量化模型,一般来说为了提供模型的吞吐能力,可以采用GPU实例推理,以及多节点Endpoint/Endpoint弹性伸缩能力,Server-Side/Client-Side Batch推理能力这些都是一些有效措施。具体到离线向量知识库构建这个场景,可以采用如下几种策略:
-
GPU实例部署:向量化模型CPU实例是可以推理的。但离线场景下,推理并发度高,GPU相对于CPU可以达到20倍左右的吞吐量提升。所以离线场景可以采用GPU推理,在线场景CPU推理的策略。
-
多节点Endpoint对于临时的大并发向量生成,通过部署多节点Endpoint进行处理,处理完毕后可以关闭
利用Client-Side Batch推理:离线推理时,Client-side batch构造十分容易。无需开启Server-side Batch推理,一般来说Sever-side batch都会有个等待时间,如50ms或100ms,对于推理延迟比较高的大语言模型比较有效,对于向量化推理则不太适用。
OpenSearch批量注入
Amazon OpenSearch的写入操作,在实现上可以通过bulk批量进行,比单条写入有很大优势。
向量数据库优化
向量数据库选择哪种近似搜索算法,选择合适的集群规模以及集群设置调优对于知识库的读写性能也十分关键,主要需要考虑以下几个方面:
算法选择
在OpenSearch里,提供了两种k-NN的算法:HNSW (Hierarchical Navigable Small World)和IVF(Inverted File)。
在选择k-NN搜索算法时,需要考虑多个因素。如果内存不是限制因素,建议优先考虑使用HNSW算法,因为HNSW算法可以同时保证latency和recall。如果内存使用量需要控制,可以考虑使用IVF算法,它可以在保持类似HNSW的查询速度和质量的同时,减少内存使用量。但是,如果内存是较大的限制因素,可以考虑为HNSW或IVF算法添加PQ编码,以进一步减少内存使用量。需要注意的是,添加PQ编码可能会降低准确率。因此,在选择算法和优化方法时,需要综合考虑多个因素,以满足具体的应用需求。
集群规模预估
选定了算法后,可以根据公式,计算所需的内存进而推导出k-NN集群大小
批量注入优化
在向知识向量库中注入大量数据时,需要关注一些关键的性能优化,以下是一些主要的优化策略:
-
Disable refresh interval
-
增加indexing线程
-
增加knn内存占比
相关文章:
基于亚马逊云科技服务,构建大语言模型问答知识库
随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以很好的弥补通…...
SpingMVC拦截器-用户登录权限控制分析
视频链接:08-SpringMVC拦截器-用户登录权限控制代码实现2_哔哩哔哩_bilibili 114 1、做了一个用户跟角色添加的相关操作 1.1 这个后台工程,没有进行相关操作也能够进行登录: 2、现在我做一个用户的权限控制,如果当前我没有进行操…...
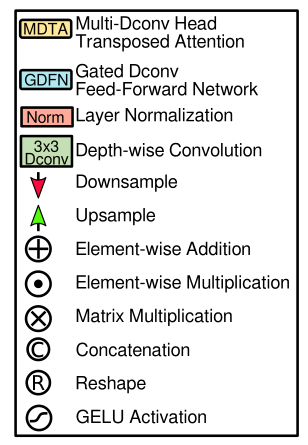
MDTA模块(Restormer)
From a layer normalized tensor Y ∈ R H ^ W ^ C ^ \mathbf{Y} \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}} Y∈RH^W^C^, our MDTA first generates query ( Q ) (\mathbf{Q}) (Q), key ( K ) (\mathbf{K}) (K) and value ( V ) (\mathbf{V}) (V) project…...

C++ 新特性 | C++ 11 | decltype 关键字
一、decltype 关键字 1、介绍 decltype 是 C11 新增的一个用来推导表达式类型的关键字。和 auto 的功能一样,用来在编译时期进行自动类型推导。引入 decltype 是因为 auto 并不适用于所有的自动类型推导场景,在某些特殊情况下 auto 用起来很不方便&…...

2023国赛数学建模思路 - 案例:退火算法
文章目录 1 退火算法原理1.1 物理背景1.2 背后的数学模型 2 退火算法实现2.1 算法流程2.2算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 退火算法原理 1.1 物理背景 在热力学上&a…...
ubuntu20.04 编译安装运行emqx
文章目录 安装依赖编译运行登录dashboard压力测试 安装依赖 Erlang/OTP OTP 24 或 25 版本 apt-get install libncurses5-dev sudo apt-get install erlang如果安装的erlang版本小于24的话,可以使用如下方法自行编译erlang 1.源码获取 wget https://github.com/erla…...

ARM linux ALSA 音频驱动开发方法
+他V hezkz17进数字音频系统研究开发交流答疑群(课题组) 一 linux ALSA介绍 ALSA (Advanced Linux Sound Architecture) 是一个用于提供音频功能的开源软件框架。它是Linux操作系统中音频驱动程序和用户空间应用程序之间的接口。ALSA 提供了访问声卡硬件的低级别API,并支持…...
)
设计模式二十三:模板方法模式(Template Method Pattern)
定义了一个算法的框架,将算法的具体步骤延迟到子类中实现。这样可以在不改变算法结构的情况下,允许子类重写算法的特定步骤以满足自己的需求 模版方法使用场景 算法框架固定,但具体步骤可以变化:当你有一个算法的整体结构是固定…...
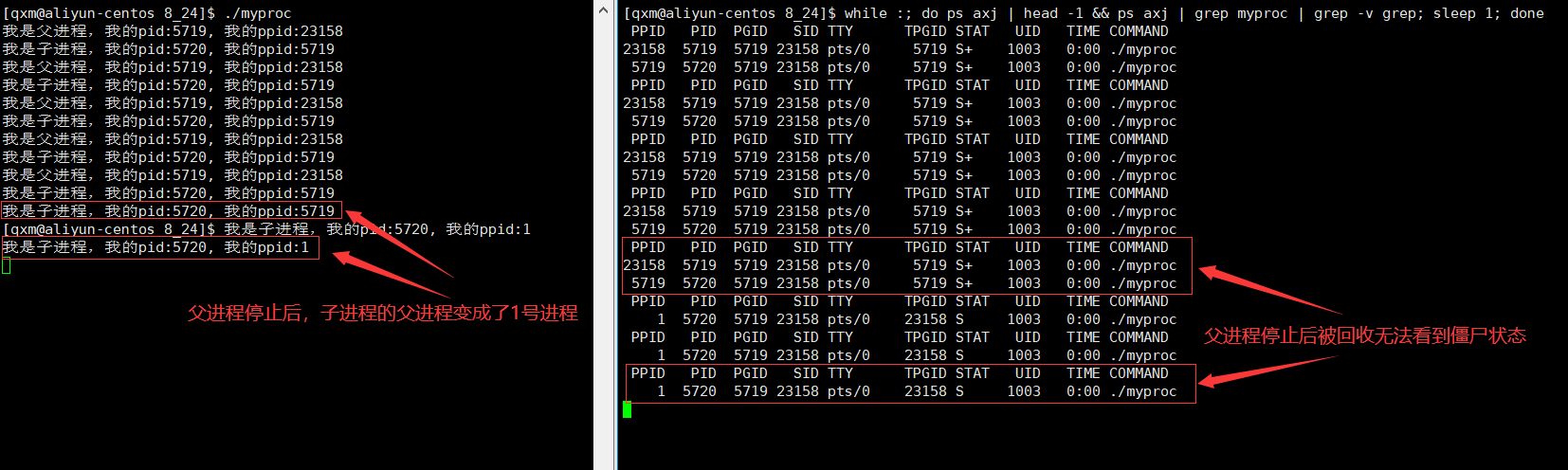
[Linux]进程状态
[Linux]进程状态 文章目录 [Linux]进程状态进程状态的概念阻塞状态挂起状态Linux下的进程状态孤儿进程 进程状态的概念 了解进程状态前,首先要知道一个正在运行的进程不是无时无刻都在CPU上进行运算的,而是在操作系统的管理下,和其他正在运行…...
Python爬虫逆向实战案例(五)——YRX竞赛题第五题
题目:抓取全部5页直播间热度,计算前5名直播间热度的加和 地址:https://match.yuanrenxue.cn/match/5 cookie中m值分析 首先打开开发者工具进行抓包分析,从抓到的包来看,参数传递了查询参数m与f,同时页面中…...

js识别图片中的文字插件 tesseract.js
使用方法及步骤 1.安装依赖 npm i tesseract.js 2.引入插件 import { createWorker } from tesseract.js;//worker多线程引入这个import Tesseract from tesseract.js;//js单线程引入这个 3.使用插件识别图片 //使用worker线程识别(async () > {console.time()const wo…...
)
Linux设备驱动移植(设备数)
一、设备数 设备树是一种描述硬件信息的数据结构,Linux内核运行时可以通过设备树将硬件信息直接传递给Linux内核,而不再需要在Linux内核中包含大量的冗余编码 设备数语法概述 设备树文件 dts 设备树源文件 dtsi 类似于头文件,包含一些公共的…...

【移动端开发】鸿蒙系统开发入门:代码示例与详解
一、引言 随着华为鸿蒙系统的日益成熟,越来越多的开发者开始关注这一新兴的操作平台。本文旨在为初学者提供一份详尽的鸿蒙系统开发入门指南,通过具体的代码示例,引导大家逐步掌握鸿蒙开发的基本概念和技术。 二、鸿蒙系统开发基础 鸿蒙系…...

Jenkins的流水线详解
来源:u.kubeinfo.cn/ozoxBB 什么是流水线 声明式流水线 Jenkinsfile 的使用 什么是流水线 jenkins 有 2 种流水线分为声明式流水线与脚本化流水线,脚本化流水线是 jenkins 旧版本使用的流水线脚本,新版本 Jenkins 推荐使用声明式流水线。…...

DIFFEDIT-图像编辑论文解读
文章目录 摘要算法Step1:计算编辑maskStep2:编码Step3:使用mask引导进行解码理论分析: 实验数据集:扩散模型:ImageNet数据集上实验消融实验IMAGEN数据集上实验COCO数据集上实验 结论 论文: 《D…...

【优选算法】—— 字符串匹配算法
在本期的字符串匹配算法中,我将给大家带来常见的两种经典的示例: 1、暴力匹配(BF)算法 2、KMP算法 目录 (一)暴力匹配(BF)算法 1、思想 2、演示 3、代码展示 (二&…...

Docker容器:docker consul的注册与发现及consul-template守护进程
文章目录 一.docker consul的注册与发现介绍1.什么是服务注册与发现2.什么是consul3.docker consul的应用场景4.consul提供的一些关键特性5.数据流向 二.consul部署1.consul服务器(192.168.198.12)(1)建立 Consul 服务启动consul后…...
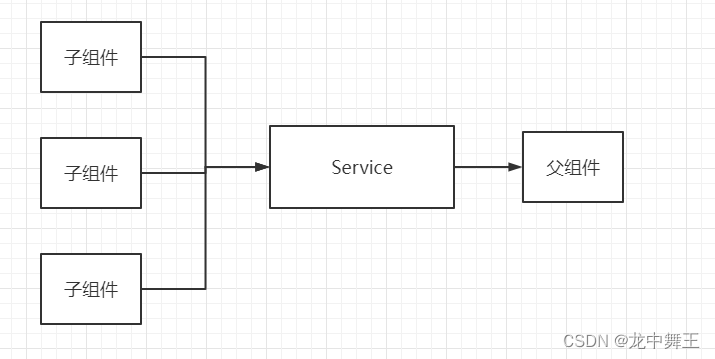
Blazor 依赖注入妙用:巧设回调
文章目录 前言依赖注入特性需求解决方案示意图 前言 依赖注入我之前写过一篇文章,没看过的可以看看这个。 C# Blazor 学习笔记(10):依赖注入 依赖注入特性 只能Razor组件中注入所有Razor组件在作用域注入的都是同一个依赖。作用域可以看看我之前的文章。 需求 …...
)
Python 基础 -- Tutorial(三)
7、输入和输出 有几种方法可以表示程序的输出;数据可以以人类可读的形式打印出来,或者写入文件以备将来使用。本章将讨论其中的一些可能性。 7.1 更花哨的输出格式 到目前为止,我们已经遇到了两种写值的方法:表达式语句和print()函数。(第三种方法是使…...
基于STM32的四旋翼无人机项目(二):MPU6050姿态解算(含上位机3D姿态显示教学)
前言:本文为手把手教学飞控核心知识点之一的姿态解算——MPU6050 姿态解算(飞控专栏第2篇)。项目中飞行器使用 MPU6050 传感器对飞行器的姿态进行解算(四元数方法),搭配设计的卡尔曼滤波器与一阶低通滤波器…...

单例模式深度解析:从基础实现到生产级避坑指南
1. 单例模式:为什么它既是基石又是“坑”在软件开发的江湖里,单例模式(Singleton Pattern)的名号,几乎无人不知。它被写进教科书,是设计模式中最容易理解、也最常被提及的模式之一。但有趣的是,…...

2026春招AI人才争夺战白热化!小白程序员如何抓住13万高薪机遇?速收藏!
2026年春招显示AI领域岗位量同比增长8.7倍,成为职场新风口。具身智能岗位薪资暴增,AI科学家月薪高达13.2万元。高薪AI岗位紧缺,程序员需拥抱AI工具提升竞争力,否则面临被替代风险。AI能力已成为职场基础设施,不学AI可能…...

免费开源AMD Ryzen处理器调试工具:SMUDebugTool终极指南
免费开源AMD Ryzen处理器调试工具:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://…...

信步NSE SVX-C2304嵌入式主板拆解:Elkhart Lake平台在工业边缘计算的应用
1. 项目概述:一块嵌入式主板的深度拆解最近在整理一个工业边缘计算项目的硬件选型方案,手头拿到了一块信步科技(Seavo)的NSE SVX-C2304嵌入式主板。这名字听起来可能有点“板正”,不像消费级产品那样花哨,但…...

OmenSuperHub:惠普OMEN游戏本性能优化终极指南 - 完全免费开源解决方案
OmenSuperHub:惠普OMEN游戏本性能优化终极指南 - 完全免费开源解决方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官…...

量子错误校正与机器学习中的辅助比特影响研究
1. 量子错误校正与量子机器学习的基础概念量子计算的核心挑战之一是量子态的脆弱性。与环境相互作用导致的退相干效应会迅速破坏量子信息,这使得量子错误校正(QEC)成为实现实用量子计算的关键技术。在传统量子计算中,QEC通过冗余编…...

Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器
Rviz Publish Point进阶玩法:打造你的交互式机器人任务编辑器 在仓储巡检、展厅导览等场景中,机器人需要频繁执行多目标点任务序列。传统编程方式每次修改路径都需要重新编译代码,而Rviz的Publish Point功能配合定制化开发,可以将…...

使用taotoken后matlab调用大模型api的延迟与稳定性体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken后matlab调用大模型api的延迟与稳定性体验分享 1. 背景与接入动机 在数据处理与科学计算项目中,我们经常…...

Power BI主题模板完全指南:35+ JSON模板快速构建专业数据可视化方案
Power BI主题模板完全指南:35 JSON模板快速构建专业数据可视化方案 【免费下载链接】PowerBI-ThemeTemplates Snippets for assembling Power BI Themes 项目地址: https://gitcode.com/gh_mirrors/po/PowerBI-ThemeTemplates 在数据驱动的商业决策时代&…...

基于本体论的技能知识图谱:从理论到工程实践
1. 项目概述:当技能遇上本体论最近在整理个人知识库和团队技能矩阵时,我遇到了一个老生常谈的难题:如何用一种结构化的、机器可读的方式,清晰地定义和关联“技能”这个概念?我们通常用Excel表格、标签云或者简单的列表…...