whisper 语音识别项目部署
1.安装anaconda软件
在如下网盘免费获取软件:
链接:https://pan.baidu.com/s/1zOZCQOeiDhx6ebHh5zNasA
提取码:hfnd
2.使用conda命令创建python3.8环境
conda create -n whisper python==3.8
3.进入whisper虚拟环境
conda activate whisper
4.安装cuda10.0的PyTorch环境
pip --trusted-host pypi.tuna.tsinghua.edu.cn install torch==1.10.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
5.使用命令安装whisper库包
pip install -U openai-whisper
6.简单使用命令识别一段语音:
whisper output.wav --model medium --language Chinese
6.安装和配置ffmpeg软件
在如下网盘免费获取软件:
配置只需要解压后将文件里面的bin路径放入系统环境变量Path中即可
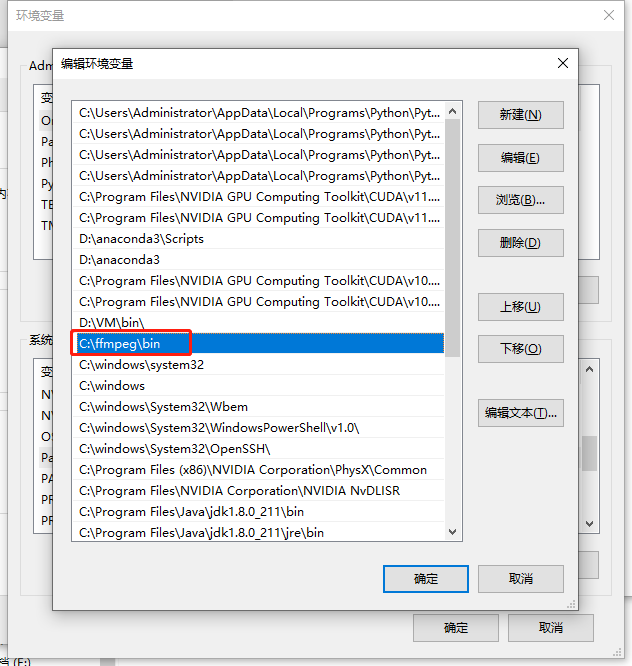
7.安装cuda软件
cuda11.0软件百度网盘获取:
链接:https://pan.baidu.com/s/1KOJfAVR6nKmVafNnmbsYDw
提取码:lblh
cudnn11.0百度网盘获取:
链接:https://pan.baidu.com/s/1CBuq7jflihEDuclSq-RTJA
提取码:efgu
6.打开pycharm软件编写代码
7.可以实时录音并且语音转中文的代码编写(使用cpu运行)
import whisper
import zhconv
import wave # 使用wave库可读、写wav类型的音频文件
import pyaudio # 使用pyaudio库可以进行录音,播放,生成wav文件def record(time): # 录音程序# 定义数据流块CHUNK = 1024 # 音频帧率(也就是每次读取的数据是多少,默认1024)FORMAT = pyaudio.paInt16 # 采样时生成wav文件正常格式CHANNELS = 1 # 音轨数(每条音轨定义了该条音轨的属性,如音轨的音色、音色库、通道数、输入/输出端口、音量等。可以多个音轨,不唯一)RATE = 16000 # 采样率(即每秒采样多少数据)RECORD_SECONDS = time # 录音时间WAVE_OUTPUT_FILENAME = "./output.wav" # 保存音频路径p = pyaudio.PyAudio() # 创建PyAudio对象stream = p.open(format=FORMAT, # 采样生成wav文件的正常格式channels=CHANNELS, # 音轨数rate=RATE, # 采样率input=True, # Ture代表这是一条输入流,False代表这不是输入流frames_per_buffer=CHUNK) # 每个缓冲多少帧print("* recording") # 开始录音标志frames = [] # 定义frames为一个空列表for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 计算要读多少次,每秒的采样率/每次读多少数据*录音时间=需要读多少次data = stream.read(CHUNK) # 每次读chunk个数据frames.append(data) # 将读出的数据保存到列表中print("* done recording") # 结束录音标志stream.stop_stream() # 停止输入流stream.close() # 关闭输入流p.terminate() # 终止pyaudiowf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') # 以’wb‘二进制流写的方式打开一个文件wf.setnchannels(CHANNELS) # 设置音轨数wf.setsampwidth(p.get_sample_size(FORMAT)) # 设置采样点数据的格式,和FOMART保持一致wf.setframerate(RATE) # 设置采样率与RATE要一致wf.writeframes(b''.join(frames)) # 将声音数据写入文件wf.close() # 数据流保存完,关闭文件if __name__ == '__main__':model = whisper.load_model("tiny")record(3) # 定义录音时间,单位/sresult = model.transcribe("output.wav")s = result["text"]s1 = zhconv.convert(s, 'zh-cn')print(s1)8.可以实时录音并且语音转中文的代码编写(使用gpu运行)
import whisper
import zhconv
import wave # 使用wave库可读、写wav类型的音频文件
import pyaudio # 使用pyaudio库可以进行录音,播放,生成wav文件
def record(time): # 录音程序# 定义数据流块CHUNK = 1024 # 音频帧率(也就是每次读取的数据是多少,默认1024)FORMAT = pyaudio.paInt16 # 采样时生成wav文件正常格式CHANNELS = 1 # 音轨数(每条音轨定义了该条音轨的属性,如音轨的音色、音色库、通道数、输入/输出端口、音量等。可以多个音轨,不唯一)RATE = 16000 # 采样率(即每秒采样多少数据)RECORD_SECONDS = time # 录音时间WAVE_OUTPUT_FILENAME = "./output.wav" # 保存音频路径p = pyaudio.PyAudio() # 创建PyAudio对象stream = p.open(format=FORMAT, # 采样生成wav文件的正常格式channels=CHANNELS, # 音轨数rate=RATE, # 采样率input=True, # Ture代表这是一条输入流,False代表这不是输入流frames_per_buffer=CHUNK) # 每个缓冲多少帧print("* recording") # 开始录音标志frames = [] # 定义frames为一个空列表for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 计算要读多少次,每秒的采样率/每次读多少数据*录音时间=需要读多少次data = stream.read(CHUNK) # 每次读chunk个数据frames.append(data) # 将读出的数据保存到列表中print("* done recording") # 结束录音标志stream.stop_stream() # 停止输入流stream.close() # 关闭输入流p.terminate() # 终止pyaudiowf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') # 以’wb‘二进制流写的方式打开一个文件wf.setnchannels(CHANNELS) # 设置音轨数wf.setsampwidth(p.get_sample_size(FORMAT)) # 设置采样点数据的格式,和FOMART保持一致wf.setframerate(RATE) # 设置采样率与RATE要一致wf.writeframes(b''.join(frames)) # 将声音数据写入文件wf.close() # 数据流保存完,关闭文件if __name__ == '__main__':model = whisper.load_model("base")record(3) # 定义录音时间,单位/saudio = whisper.load_audio("output.wav")audio = whisper.pad_or_trim(audio)mel = whisper.log_mel_spectrogram(audio).to(model.device)_, probs = model.detect_language(mel)print(f"Detected language: {max(probs, key=probs.get)}")options = whisper.DecodingOptions()result = whisper.decode(model, mel, options)s1 = zhconv.convert(result.text, 'zh-cn')print(s1)9.展示实时翻译结果
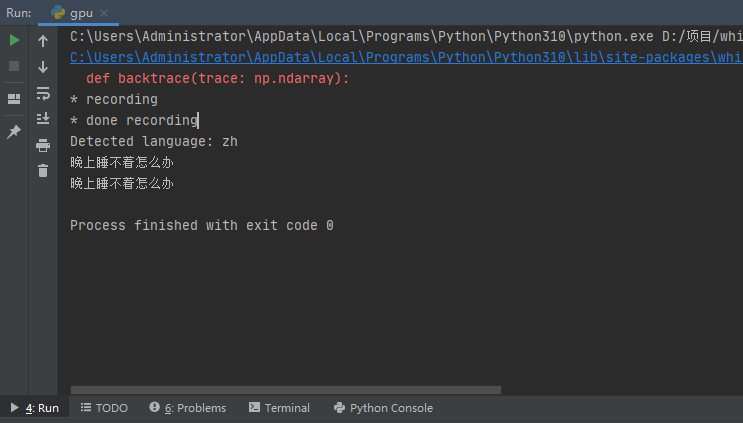
相关文章:
whisper 语音识别项目部署
1.安装anaconda软件 在如下网盘免费获取软件: 链接:https://pan.baidu.com/s/1zOZCQOeiDhx6ebHh5zNasA 提取码:hfnd 2.使用conda命令创建python3.8环境 conda create -n whisper python3.83.进入whisper虚拟环境 conda activate whisper4.…...
实例044 在关闭窗口前加入确认对话框
实例说明 用户对程序进行操作时,难免会有错误操作的情况,例如不小心关闭程序,如果尚有许多资料没有保存,那么损失将非常严重,所以最好使程序具有灵活的交互性。人机交互过程一般都是通过对话框来实现的,对话…...
子查询和事务隔离以及用户管理
一、子查询 子查询是另一个语句中的select语句嵌套在另一个select中。注意子查询语法上必须使用()包起来。 嵌套的那个语句返回的结果有可能是: 一个字段,一行记录,一个列或一个表。嵌套的位置 where / having语句里面作为条件使用在from语…...
)
uniapp 滚动到指定元素的位置(锚点)
需求:在页面中,不管位于何处,点击按钮页面滚动到对应的标题位置。 最简单有效的方式(直接复制改数据就行) 使用 scroll-view 标签的属性:scroll-top(距离值 num) 或 scroll-into-view(子元素的id,不能以…...

Spring AOP 的 afterReturing 返回值是否能修改问题
文章目录 结论举例子原因外传 结论 最近要搞脱敏信息,所以,想了几种方案,最后使用全局的接口拦截,但是,又不能用注解的方式,毕竟是几年的老产品,有很多限制。 中间尝试过使用Spring AOP 的 aft…...

MyBatis分页插件PageHelper的使用及特殊字符的处理
目录 一、PageHelper简介 1.什么是分页 2.PageHelper是什么 3.使用PageHelper的优点 二、PageHelper插件的使用 原生limit查询 1. 导入pom依赖 2. Mybatis.cfg.xml 配置拦截器 3. 使用PageHelper进行分页 三、特殊字符的处理 1.SQL注入: 2.XML转义&#…...
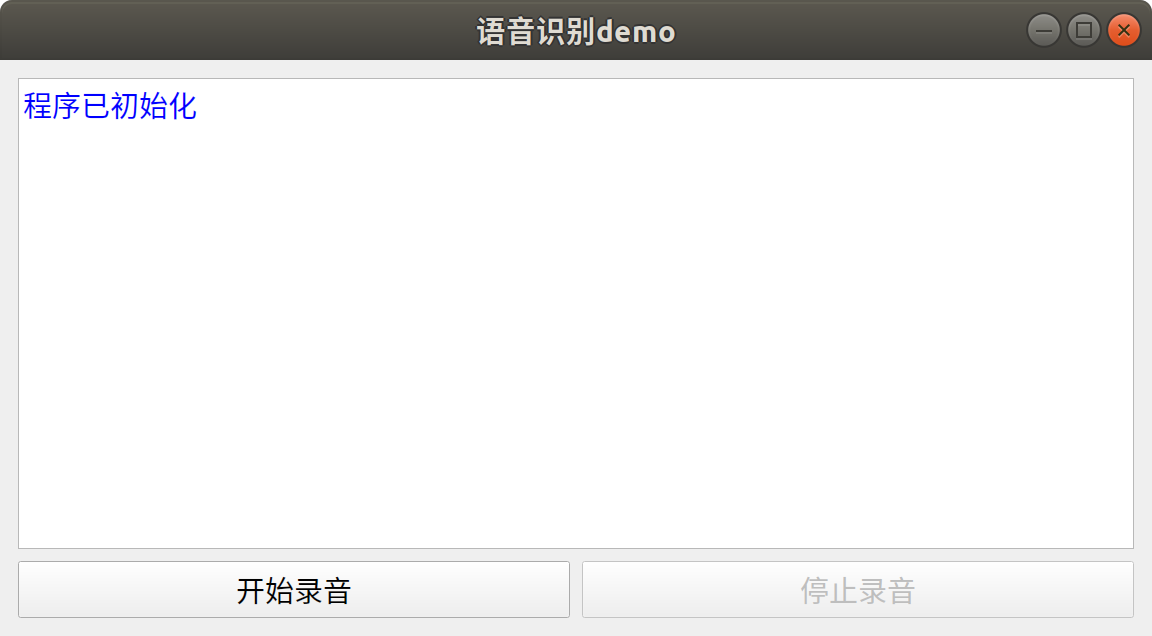
[语音识别] 基于Python构建简易的音频录制与语音识别应用
语音识别技术的快速发展为实现更多智能化应用提供了无限可能。本文旨在介绍一个基于Python实现的简易音频录制与语音识别应用。文章简要介绍相关技术的应用,重点放在音频录制方面,而语音识别则关注于调用相关的语音识别库。本文将首先概述一些音频基础概…...

Matlab彩色图像转索引图像
索引图像 索引图像是一种把像素值直接作为RGB调色板下标的图像。索引图像包括一个数据矩阵X,一个调色板矩阵map,也称为颜色映像矩阵。其中,数据矩阵X可以是8位无符号整型、16位无符号整型或双精度类型。调色板矩阵map是一个m3的数据阵列&…...

测试框架pytest教程(11)-pytestAPI
常量 pytest.__version__ #输出pytest版本 pytest.version_tuple #输出版本的元组形式 功能 pytest.approx pytest.approx 是一个用于进行数值近似比较的 pytest 断言工具。 在测试中,有时候需要对浮点数或其他具有小数部分的数值进行比较。然而,由于…...

Docker自学:利用FastAPI建立一个简单的web app
环境配置:下载Docker Desktop 文件一:main.py from typing import Unionfrom fastapi import FastAPIimport uvicornapp FastAPI()app.get("/") def read_root():return {"Hello": "World"}app.get("/items/{item…...
)
微调bert做学术论文分类(以科大讯飞学术论文分类挑战赛为例)
代码 12-How to Fine-Tune BERT for Text Classification:链接:https://pan.baidu.com/s/1EKggbyC4ZW-ufnDW45eKzA 提取码:k3b2 baseline 链接:https://pan.baidu.com/s/12hkZNJjQ__FGAHiF3fifvQ 提取码:88tb 数据…...

Springboot中sharding-jdbc的API模式并使用自定义算法
Springboot中sharding-jdbc的API模式并使用自定义算法 可配合AbstractRoutingData使用切换数据源 程序用到了AbstractRoutingData来切换数据源(数据源是自定义的格式编写并没有用springboot的自动装配的格式写),但是又用到sharding-jdbc进行…...

MySQL回表是什么?哪些情况下会回表
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...

VR、AR、MR 傻傻分不清楚?区别的底层逻辑?
VR是一种能够制作虚拟物体并与人互动的基础技术。它与操作者所处的环境无关。AR可以让在特定位置出现或消失。MR可以让虚拟物体与真实物体进行互动。 AR和MR的大部分应用场景都是随机的,所以硬件基本都采用手机和眼镜。提升了便携性。牺牲了性能。这就导致了AR与MR…...
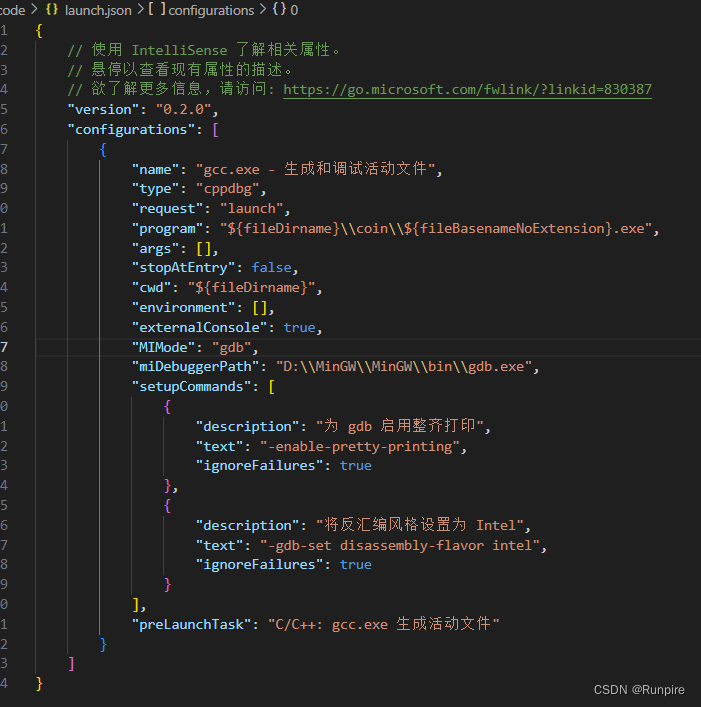
VScode运行C语言出现的调试问题 lauch:program does not exist 解决方法
"lauch:program does not exist"错误通常表示编译器或调试器无法找到指定的可执行文件。这可能是由于几个原因引起的。首先,确保你的源代码文件夹路径不包含中文字符,因为这可能导致编译器无法识别文件。其次,检查你的launch.json文…...

云原生安全:保护现代化应用的新一代安全策略
随着云计算和容器技术的快速发展,云原生应用已成为现代化软件开发和部署的主流趋势。然而,随之而来的安全挑战也变得更加复杂和严峻。本文将深入探讨云原生安全的概念、原则和最佳实践,帮助您理解如何有效保护云原生应用和敏感数据。 第一部…...

mysql操作
1、字符转Decimal CAST(column AS DECIMAL(9,2)) 2、将计算结果取两位小数: round(column, 2) 3、查询非空 select * from table_XX where id is not null; 4、连表update更新 update a inner join (select yy from b) c on a.id c.id set a.xx c.yy...

前端(十四)——DOM节点操作手册:你需要了解的一切
🙂博主:小猫娃来啦 🙂文章核心:DOM节点操作手册:你需要了解的一切 文章目录 前言DOM基础知识操作现有节点创建新节点遍历节点树修改节点属性和样式事件处理实践应用动态创建表格动态更新列表 前言 DOM(文档…...
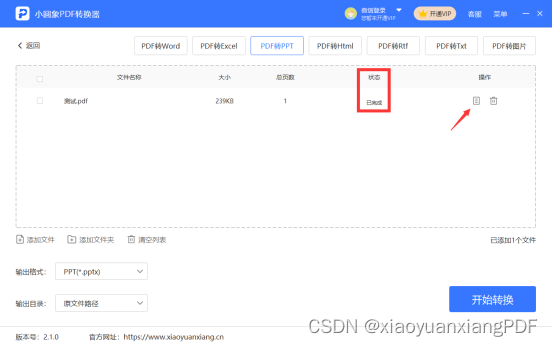
PDF怎么转成PPT文件免费?一个软件解决
随着科技的不断发展和进步,电子文档已经成为我们日常工作和学习中不可或缺的一部分。PDF作为一种跨平台的文件格式,以其可靠性和易读性而备受推崇。然而,在某些情况下,我们可能需要PDF怎么转成PPT文件免费,以便更好地展…...
数据结构基础:P3-树(上)----编程作业02:List Leaves
本系列文章为浙江大学陈越、何钦铭数据结构学习笔记,系列文章链接如下: 数据结构(陈越、何钦铭)学习笔记 文章目录 一、题目描述二、整体思路与实现代码 一、题目描述 题目描述: 给定一棵树,按照从上到下、从左到右的顺序列出所有…...

5分钟搞定虚拟显示器:ParsecVDD终极指南,解锁4K游戏串流新境界
5分钟搞定虚拟显示器:ParsecVDD终极指南,解锁4K游戏串流新境界 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否曾经因为物理显示器限制而无法获得完…...

华硕笔记本性能革命:G-Helper轻量控制工具深度评测
华硕笔记本性能革命:G-Helper轻量控制工具深度评测 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exper…...

SystemC随机验证环境构建:从约束生成到覆盖率驱动的自动化测试
1. 项目概述:从确定性仿真到随机验证的跨越在芯片设计和验证领域,SystemC 早已不是陌生的名字。它作为 C 的类库扩展,为系统级建模和硬件/软件协同验证提供了强大的框架。然而,很多刚接触 SystemC 验证的朋友,往往止步…...
)
告别树莓派5?手把手教你用OrangePi 5搭建家庭媒体中心(基于RK3588)
告别树莓派5?手把手教你用OrangePi 5搭建家庭媒体中心(基于RK3588) 在智能家居日益普及的今天,家庭媒体中心已成为许多科技爱好者的必备设备。传统的解决方案往往依赖于昂贵的商业NAS或性能有限的树莓派,而基于RK3588芯…...

影像技术实战11:视频封面生成黑屏、模糊、重复?FFmpeg + OpenCV 构建高质量缩略图自动优选方案
影像技术实战11:视频封面生成黑屏、模糊、重复?FFmpeg OpenCV 构建高质量缩略图自动优选方案 一、问题场景:封面不是“随便截一帧” 在视频平台、素材管理系统、内容审核后台、AI 剪辑工具里,视频上传后自动生成封面是一个很常见…...

用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现
用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现 数字电路设计中最精妙的概念之一,莫过于补码表示法。它不仅解决了计算机中正负数的统一表示问题,还让加减法运算可以用同一套电路完成。但你是否好奇过,这个看似简单…...

从点击到意图:鸿蒙 App 的 AI 进化
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

STM32 SPI驱动W25Q128避坑指南:CubeMX配置、时序模式与读写超时那些事儿
STM32 SPI驱动W25Q128实战避坑指南:从时序陷阱到性能调优 1. 当SPI遇上Flash:硬件工程师的暗礁地带 在嵌入式存储解决方案中,W25Q128系列SPI Flash凭借其紧凑封装和简单接口,已成为众多STM32项目的标配外设。但看似简单的四线接口…...

别再只调参了!深入pix2pixHD的多尺度鉴别器与实例地图,解决你的图像合成‘塑料感’难题
突破图像合成瓶颈:pix2pixHD多尺度鉴别器与实例地图的实战精要 当你在深夜调试生成对抗网络,屏幕上的合成图像却始终带着难以消除的"塑料感"——表面过于光滑、边缘模糊、纹理缺乏层次。这种挫败感或许正是促使你点开本文的原因。作为GAN领域的…...

Gemini 垂直行业模型路由:按意图选择不同Prompt与参数集
在AI开发社区里,不少工程师都在尝试把多个大模型接入实际项目。工具整合站点作为AI模型聚合平台,让开发者能快速对比Gemini与其他模型在不同行业场景下的表现。今天我们来聊聊如何为Gemini搭建一套垂直行业模型路由机制,根据用户意图自动选择…...