微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。

一些知识点
llama2相比于前一代,令牌数量增加了40%,达到2T,上下文长度增加了一倍,并应用分组查询注意(GQA)技术来加速在较重的70B模型上的推理。在标准的transformer 体系结构上,使用RMSNorm归一化、SwiGLU激活和旋转位置嵌入,上下文长度达到了4096个,并应用了具有余弦学习率调度、权重衰减0.1和梯度裁剪的Adam优化器。
有监督微调(SFT)阶段的特点是优先考虑质量样本而不是数量,因为许多报告表明,使用高质量数据可以提高最终模型的性能。
最后,通过带有人类反馈的强化学习(RLHF)步骤使模型与用户偏好保持一致。收集了大量示例,其中人类在比较中选择他们首选的模型输出。这些数据被用来训练奖励模型。
最主要的一点是,LLaMA 2-CHAT已经和OpenAI ChatGPT一样好了,所以我们可以使用它作为我们本地的一个替代了
数据集
对于的微调过程,我们将使用大约18,000个示例的数据集,其中要求模型构建解决给定任务的Python代码。这是原始数据集[2]的提取,其中只选择了Python语言示例。每行包含要解决的任务的描述,如果适用的话,任务的数据输入示例,并提供解决任务的生成代码片段[3]。
# Load dataset from the hubdataset = load_dataset(dataset_name, split=dataset_split)# Show dataset sizeprint(f"dataset size: {len(dataset)}")# Show an exampleprint(dataset[randrange(len(dataset))])
创建提示
为了执行指令微调,我们必须将每个数据示例转换为指令,并将其主要部分概述如下:
def format_instruction(sample):return f"""### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the following Task:### Task:{sample['instruction']}### Input:{sample['input']}### Response:{sample['output']}"""
输出的结果是这样的:
### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the following Task:### Task:Develop a Python program that prints "Hello, World!" whenever it is run.### Input:### Response:#Python program to print "Hello World!"print("Hello, World!")
微调模型
为了方便演示,我们使用Google Colab环境,对于第一次测试运行,T4实例就足够了,但是当涉及到运行整个数据集训练,则需要使用A100。
除此以外,还可以登录Huggingface hub ,这样可以上传和共享模型,当然这个是可选项。
from huggingface_hub import loginfrom dotenv import load_dotenvimport os# Load the enviroment variablesload_dotenv()# Login to the Hugging Face Hublogin(token=os.getenv("HF_HUB_TOKEN"))
PEFT、Lora和QLora
训练LLM的通常步骤包括:首先,对数十亿或数万亿个令牌进行预训练得到基础模型,然后对该模型进行微调,使其专门用于下游任务。
参数高效微调(PEFT)允许我们通过微调少量额外参数来大大减少RAM和存储需求,因为所有模型参数都保持冻结状态。并且PEFT还增强了模型的可重用性和可移植性,它很容易将小的检查点添加到基本模型中,通过添加PEFT参数让基础模型在多个场景中重用。最后由于没有调整基本模型,还可以保留在预训练阶段获得的所有知识,从而避免了灾难性遗忘。
PEFT保持预训练的基本模型不变,并在其上添加新的层或参数。这些层被称为“适配器”,我们将这些层添加到预训练的基本模型中,只训练这些新层的参数。但是这种方法的一个严重问题是,这些层会导致推理阶段的延迟增加,从而使流程在许多情况下效率低下。
而在LoRa技术(大型语言模型的低秩适应)中不是添加新的层,而是以一种避免在推理阶段出现这种可怕的延迟问题的方式向模型各层参数添加值。LoRa训练并存储附加权重的变化,同时冻结预训练模型的所有权重。也就是说我们利用预训练模型矩阵的变化训练一个新的权重矩阵,并将这个新矩阵分解为2个低秩矩阵,如下所示:
LoRA[1]的作者提出权值变化矩阵∆W的变化可以分解为两个低秩矩阵A和b。LoRA不直接训练∆W中的参数,而是直接训练A和b中的参数,因此可训练参数的数量要少得多。假设A的维数为100 * 1,B的维数为1 * 100,则∆W中的参数个数为100 * 100 = 10000。在A和B中训练的人数只有100 + 100 = 200,而在∆W中训练的个数是10000
这些低秩矩阵的大小由r参数定义。这个值越小,需要训练的参数就越少,速度更快。但是参数过少可能会损失信息和性能,所以r参数的选择也是需要考虑的问题。
最后,QLoRa[6]则是将量化应用于LoRa方法,通过优化内存使用的技巧,以实现“更轻量”和更便宜的训练。
微调流程
我们的示例中使用QLoRa,所以要指定BitsAndBytes配置,下载4位量化的预训练模型,定义LoraConfig。
# Get the typecompute_dtype = getattr(torch, bnb_4bit_compute_dtype)# BitsAndBytesConfig int-4 configbnb_config = BitsAndBytesConfig(load_in_4bit=use_4bit,bnb_4bit_use_double_quant=use_double_nested_quant,bnb_4bit_quant_type=bnb_4bit_quant_type,bnb_4bit_compute_dtype=compute_dtype)# Load model and tokenizermodel = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, use_cache = False, device_map=device_map)model.config.pretraining_tp = 1# Load the tokenizertokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"
下面是参数定义,
# Activate 4-bit precision base model loadinguse_4bit = True# Compute dtype for 4-bit base modelsbnb_4bit_compute_dtype = "float16"# Quantization type (fp4 or nf4)bnb_4bit_quant_type = "nf4"# Activate nested quantization for 4-bit base models (double quantization)use_double_nested_quant = False# LoRA attention dimensionlora_r = 64# Alpha parameter for LoRA scalinglora_alpha = 16# Dropout probability for LoRA layerslora_dropout = 0.1
接下来的步骤对于所有的Hugging Face用户来说应该都很熟悉了,设置训练参数,创建Trainer。在执行指令微调时,我们调用封装PEFT模型定义和其他步骤的SFTTrainer方法。
# Define the training argumentsargs = TrainingArguments(output_dir=output_dir,num_train_epochs=num_train_epochs,per_device_train_batch_size=per_device_train_batch_size, # 6 if use_flash_attention else 4,gradient_accumulation_steps=gradient_accumulation_steps,gradient_checkpointing=gradient_checkpointing,optim=optim,logging_steps=logging_steps,save_strategy="epoch",learning_rate=learning_rate,weight_decay=weight_decay,fp16=fp16,bf16=bf16,max_grad_norm=max_grad_norm,warmup_ratio=warmup_ratio,group_by_length=group_by_length,lr_scheduler_type=lr_scheduler_type,disable_tqdm=disable_tqdm,report_to="tensorboard",seed=42)# Create the trainertrainer = SFTTrainer(model=model,train_dataset=dataset,peft_config=peft_config,max_seq_length=max_seq_length,tokenizer=tokenizer,packing=packing,formatting_func=format_instruction,args=args,)# train the modeltrainer.train() # there will not be a progress bar since tqdm is disabled# save model in localtrainer.save_model()
这些参数大多数通常用于llm上的其他微调脚本,我们就不做过多的说明了:
# Number of training epochsnum_train_epochs = 1# Enable fp16/bf16 training (set bf16 to True with an A100)fp16 = Falsebf16 = True# Batch size per GPU for trainingper_device_train_batch_size = 4# Number of update steps to accumulate the gradients forgradient_accumulation_steps = 1# Enable gradient checkpointinggradient_checkpointing = True# Maximum gradient normal (gradient clipping)max_grad_norm = 0.3# Initial learning rate (AdamW optimizer)learning_rate = 2e-4# Weight decay to apply to all layers except bias/LayerNorm weightsweight_decay = 0.001# Optimizer to useoptim = "paged_adamw_32bit"# Learning rate schedulelr_scheduler_type = "cosine" #"constant"# Ratio of steps for a linear warmup (from 0 to learning rate)warmup_ratio = 0.03# Group sequences into batches with same length# Saves memory and speeds up training considerablygroup_by_length = False# Save checkpoint every X updates stepssave_steps = 0# Log every X updates stepslogging_steps = 25# Disable tqdmdisable_tqdm= True
合并权重
正如上面我们提到的方法,LoRa在基本模型上训练了“修改权重”,所以最终模型需要将预训练的模型和适配器权重合并到一个模型中。
from peft import AutoPeftModelForCausalLMmodel = AutoPeftModelForCausalLM.from_pretrained(args.output_dir,low_cpu_mem_usage=True,return_dict=True,torch_dtype=torch.float16,device_map=device_map, )# Merge LoRA and base modelmerged_model = model.merge_and_unload()# Save the merged modelmerged_model.save_pretrained("merged_model",safe_serialization=True)tokenizer.save_pretrained("merged_model")# push merged model to the hubmerged_model.push_to_hub(hf_model_repo)tokenizer.push_to_hub(hf_model_repo)
推理
最后就是推理的过程了
import torchfrom transformers import AutoModelForCausalLM, AutoTokenizer# Get the tokenizertokenizer = AutoTokenizer.from_pretrained(hf_model_repo)# Load the modelmodel = AutoModelForCausalLM.from_pretrained(hf_model_repo, load_in_4bit=True, torch_dtype=torch.float16,device_map=device_map)# Create an instructioninstruction="Optimize a code snippet written in Python. The code snippet should create a list of numbers from 0 to 10 that are divisible by 2."input=""prompt = f"""### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the Task.### Task:{instruction}### Input:{input}### Response:"""# Tokenize the inputinput_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()# Run the model to infere an outputoutputs = model.generate(input_ids=input_ids, max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.5)# Print the resultprint(f"Prompt:\n{prompt}\n")print(f"Generated instruction:\n{tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]}")
结果如下:
Prompt:### Instruction:Use the Task below and the Input given to write the Response, which is a programming code that can solve the Task.### Task:Optimize a code snippet written in Python. The code snippet should create a list of numbers from 0 to 10 that are divisible by 2.### Input:arr = []for i in range(10):if i % 2 == 0:arr.append(i)### Response:Generated instruction:arr = [i for i in range(10) if i % 2 == 0]Ground truth:arr = [i for i in range(11) if i % 2 == 0]
看样子还是很不错的
总结
以上就是我们微调llama2的完整过程,这里面的一个最重要的步骤其实是提示的生成,一个好的提示对于模型的性能也是非常有帮助的。
[1] Llama-2 paper https://arxiv.org/pdf/2307.09288.pdf
[2] python code dataset http://sahil2801/code_instructions_120k
[3] 本文使用的数据集 https://huggingface.co/datasets/iamtarun/python_code_instructions_18k_alpaca
[4] LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685
[5]. QLoRa: Efficient Finetuning of QuantizedLLMs arXiv:2305.14314
https://avoid.overfit.cn/post/9794c9eef1df4e55adf514b3d727ee3b
作者:Eduardo Muñoz
相关文章:
微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。 一些知识点 llama2相比于前一代,令牌数量增加了40%࿰…...

Java【手撕双指针】LeetCode 57. “两数之和“, 图文详解思路分析 + 代码
文章目录 前言一、两数之和1, 题目2, 思路分析3, 代码展示 前言 各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你: 📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等 📗 Java数据结构: 顺序表, 链表…...

大数据(一)定义、特性
大数据(一)定义、特性 本文目录: 一、写在前面的话 二、大数据定义 三、大数据特性 3.1、大数据的大量 (Volume) 特性 3.2、大数据的高速(Velocity)特性 3.3、大数据的多样化 (Variety) 特性 3.4、大数据的价值 (value) 特性 3.5、大…...
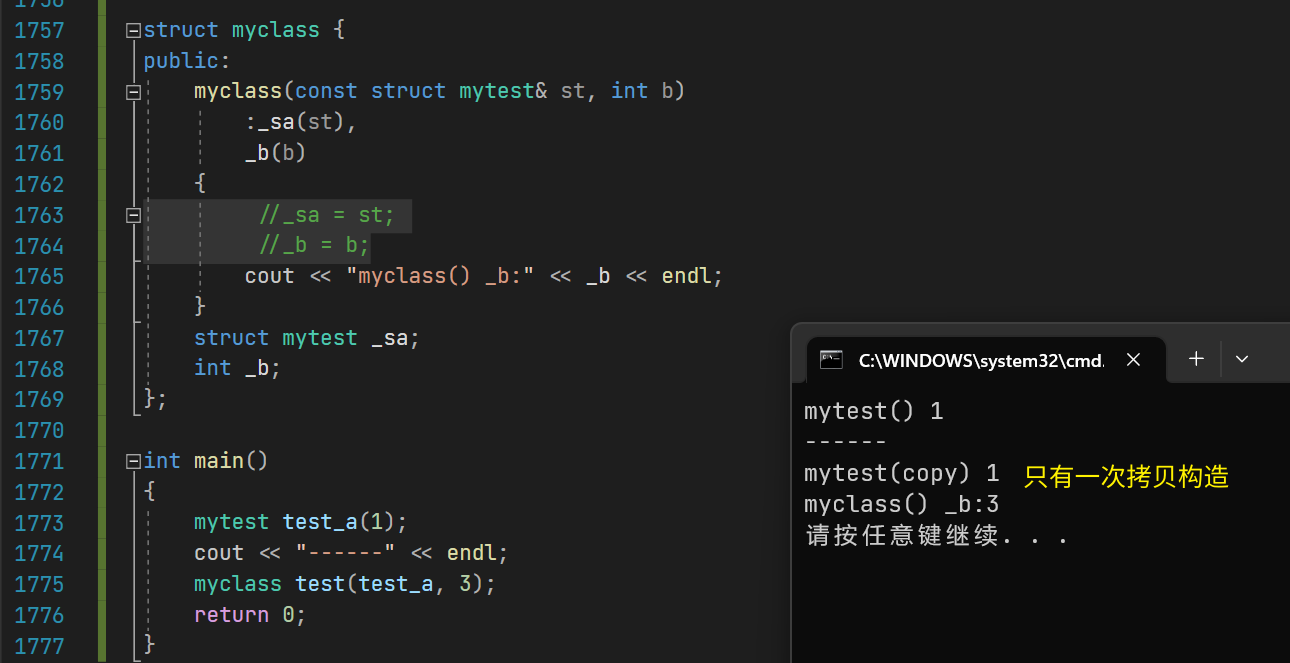
【C++】构造函数和初始化列表的性能差距
构造函数和初始化列表的性能差距对比测试 1.说明 在C类和对象中,你可能听到过更加推荐用初始化列表来初始化类内成员。如果类内成员是自定义类型,则只能在初始化列表中调用自定义类型的构造函数。 但初始化列表和在构造函数体内直接赋值有无性能差距呢…...

Linux下套接字TCP实现网络通信
Linux下套接字TCP实现网络通信 文章目录 Linux下套接字TCP实现网络通信1.引言2.具体实现2.1接口介绍1.socket()2.bind()3.listen()4.accept()5.connect() 2.2 服务器端server.hpp2.3服务端server.cc2.4客户端client.cc 1.引言 套接字(Socket)是计算机网络中实现网络通信的一…...

❤ vue清除定时器Bug
❤ vue清除定时器Bug 页面加载,清除定时器 clearTimeout(intm) 问题 遇见的需求是:webapp 从A页面进入B页面,B页面点击按钮,加载完B页面的加载效果进入c,从C页面返回A页面,仍然显示B页面的加载效果 结果定时器一直…...
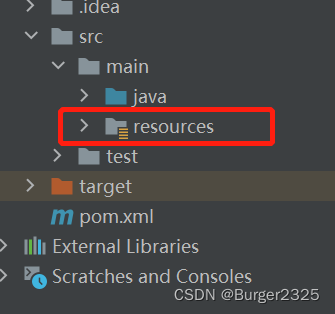
IDEA创建Spring,Maven项目没有resources文件夹
有时新建Spring或Maven项目时,会出现目录中main下无resources文件夹的情况,来一起解决一下: FIles|Project Structure 在Modules模块找到对应路径,在main下创建resources,右键main,选择新文件夹 输入文件…...
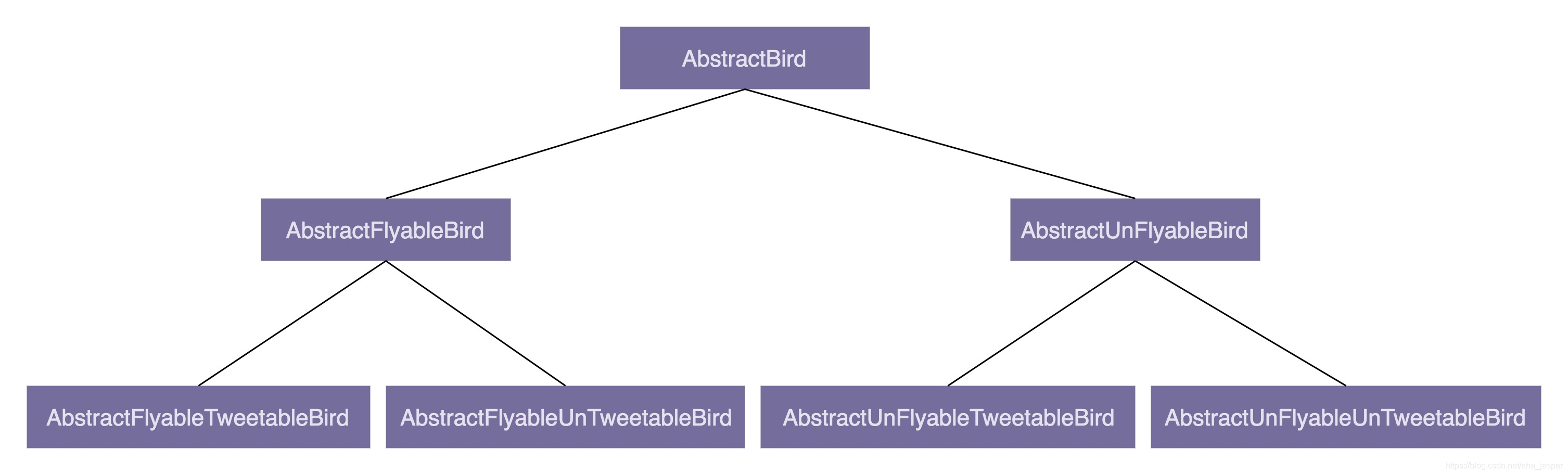
Unity 结构少继承多组合
为什么不推荐使用继承? 继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。所以,对于是否应该在…...

保研之旅2:中科院声学所“声学和信息学科”夏令营
💥💥💞💞欢迎来到本博客❤️❤️💥💥 本人持续分享更多关于电子通信专业内容以及嵌入式和单片机的知识,如果大家喜欢,别忘点个赞加个关注哦,让我们一起共同进步~ &#x…...

android adb自动连接手机安装apk bat
1.新建bat文件adb echo off:apk文件名称 在setting.txt获取 set apkFileName"":设置文件 set settingFileE:\apk\bat\setting.txt:启动页面 applicationid/启动页面路径 set startActivitycom.aaa.aaa/com.aaa.aaa.ui.common.SplashActivity:读取settingFile第一行的…...

用心维护好电脑,提高学习工作效率
无论是学习还是工作,电脑都是IT人必不可少的重要武器,一台好电脑除了自身配置要经得起考验,后期主人对它的维护也是决定它寿命的重要因素! 一、我的电脑 系统制造商: ASUSTeK COMPUTER INC. 系统型号: ZenBook UX481FAY 1.1 如…...

以太坊硬分叉后的可重入漏洞攻击
以太坊硬分叉后的可重入漏洞攻击 以太坊君士坦丁堡升级将降低部分 SSTORE 指令的 gas 费用。然而,这次升级也有一个副作用,在 Solidity 语言编写的智能合约中调用 address.transfer()函数或 address.send()函数时存在可重入漏洞。在目前版本的以太坊网络…...
k8s 常用命令(三)
1、查看版本信息:kubectl version [rootmaster ~]# kubectl version [rootmaster ~]# kubectl version Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.3", GitCommit:"ca643a4d1f7bfe34773c74f7952…...

API 网关基础
目录 一、网关概述二、网关提供的功能三、常见网关系统3.1 Netflix Zuul3.2 Spring Cloud Gateway3.3 Kong3.4 APISIX3.5 Shenyu 一、网关概述 API网关是一个服务器,是系统的唯一入口。 从面向对象设计的角度看,它与外观模式类似。API网关封装了系统内部…...

【Linux】权限问题
Linux权限 一、Linux 权限的概念二、Linux 权限管理1. 文件访问者的分类2. 文件类型和访问权限(事物属性)3. 文件访问权限的相关设置方法 三、默认权限1. 对文件和目录进行操作需要的权限2. 文件和目录的默认权限3. 粘滞位 一、Linux 权限的概念 Linux …...
线性代数的学习和整理10:各种特殊类型的矩阵(草稿-----未完成 建设ing)
目录 1 图形化分类 1.1对称矩阵 1.2 梯形矩阵 1.3 三角矩阵 1.3.1 上三角矩阵 1.4 对角线矩阵 2 按各自功能分 2.1 等价矩阵 2.2 增广矩阵 2.3 伴随矩阵 2.4 正交矩阵 2.5 正交矩阵 2.6 相似矩阵 1 图形化分类 1.1对称矩阵 1.2 梯形矩阵 1.3 三角矩阵 1.3.1 上…...

Go 自学:变量、函数、结构体、接口、错误处理
1. 打印变量数据类型 package mainimport "fmt"func main() {penniesPerText : 2.0fmt.Printf("The type of penniesPerText is %T\n", penniesPerText) }输出为: The type of penniesPerText is float64 2. 同时给多个变量赋值 package mai…...

pyqt Pyton VTK 使用 滑块 改变 VTK Actor 颜色
使用 PyQt5 vtk vtk球体 使用滑块 RGB 改变 Actor 颜色 CODE import sys from PyQt5.QtWidgets import * from PyQt5.QtWidgets import (QApplication, QCheckBox, QGridLayout, QGroupBox,QMenu, QPushButton, QRadioButton, QVBoxLayout, QWidget, QSlider,QLineEdit,QLabe…...

春秋云镜 CVE-2019-16113
春秋云镜 CVE-2019-16113 Bludit目录穿越漏洞 靶标介绍 在Bludit<3.9.2的版本中,攻击者可以通过定制uuid值将文件上传到指定的路径,然后通过bl-kernel/ajax/upload-images.php远程执行任意代码。 启动场景 漏洞利用 exp https://github.com/Kenun…...

【JavaEE基础学习打卡06】JDBC之进阶学习PreparedStatement
目录 前言一、PreparedStatement是什么二、重点理解预编译三、PreparedStatement基本使用四、Statement和PreparedStatement比较1.PreparedStatement效率高2.PreparedStatement无需拼接参数3.PreparedStatement防止SQL注入 总结 前言 📜 本系列教程适用于JavaWeb初学…...
:解决合并冲突,处理“代码打架”)
分支管理(二):解决合并冲突,处理“代码打架”
1. 问题场景 你已经学会了创建分支和合并分支。在上一篇文章里,合并过程顺滑得像切黄油——Git 自动完成了所有工作。但真实世界里,你和一个同事可能同时修改了同一个文件的同一处代码。当你试图把两个分支合并在一起时,Git 会停下来…...

SteamAutoCrack完整指南:一键移除游戏DRM保护
SteamAutoCrack完整指南:一键移除游戏DRM保护 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack SteamAutoCrack是一款专业的开源游戏DRM移除工具,能够自动解除Ste…...

AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过
AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过 很多同学不理解——为什么 2024 年用换同义词就能降下 AI 率、2025 年开始这招就半失效了、2026 年完全没用了?真相是——AIGC 检测算法从 1.0 升级到 4.0 经历了 4 次大…...

Win10下通过桥接网卡实现QEMU虚拟机与宿主机及外网的无缝互联
1. 为什么需要桥接网卡? 在Windows 10环境下使用QEMU创建虚拟机时,很多朋友都会遇到一个头疼的问题:虚拟机虽然能上网,但宿主机和虚拟机之间就是无法互相访问。这种情况我遇到过太多次了,特别是需要调试web服务或者进行…...
)
从零开始用vnpy搭建你的第一个量化交易机器人(保姆级Python教程)
从零开始用vnpy搭建你的第一个量化交易机器人(保姆级Python教程) 第一次接触量化交易时,我被那些复杂的术语和代码吓得不轻。直到发现vnpy这个Python框架,才真正找到了入门的方向。vnpy就像是为Python开发者量身定制的量化交易工具…...

【亲测免费】 Python Qt 图形界面编程资源下载
Python Qt 图形界面编程资源下载 【下载地址】PythonQt图形界面编程资源下载 《Python Qt 图形界面编程》课程涵盖了PySide2、PyQt5、PyQt和PySide等框架的使用,帮助学习者掌握Python图形化界面编程的核心知识。课程内容详实,适合初学者入门,…...

LeetCode热题100-从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,15,7] 思…...

专业级LaTeX排版:深度解析中国科学技术大学学位论文模板括号使用的最佳实践
专业级LaTeX排版:深度解析中国科学技术大学学位论文模板括号使用的最佳实践 【免费下载链接】ustcthesis LaTeX template for USTC thesis 项目地址: https://gitcode.com/gh_mirrors/us/ustcthesis 在学术论文写作中,细节决定专业水准。中国科学…...

终极免费二维码修复方案:QRazyBox专业工具完全指南
终极免费二维码修复方案:QRazyBox专业工具完全指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox这款强大的QR二维码修…...

WindowResizer:如何打破Windows窗口尺寸限制,实现桌面布局自由?
WindowResizer:如何打破Windows窗口尺寸限制,实现桌面布局自由? 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 在Windows日常使用中࿰…...