计算机竞赛 地铁大数据客流分析系统 设计与实现
文章目录
- 1 前言
- 1.1 实现目的
- 2 数据集
- 2.2 数据集概况
- 2.3 数据字段
- 3 实现效果
- 3.1 地铁数据整体概况
- 3.2 平均指标
- 3.3 地铁2018年9月开通运营的线路
- 3.4 客流量相关统计
- 3.4.1 线路客流量排行
- 3.4.2 站点客流量排行
- 3.4.3 入站客流排行
- 3.4.4 整体客流随时间变化趋势
- 3.4.5 不同线路客流随时间变化
- 3.4.6 不同线路的客流组成
- 3.5 收入消费指标统计
- 3.5.1 线路收入排行
- 3.5.2 各个站点对线路收入的贡献
- 3.5.3 不同消费金额次数占比
- 3.6 完整乘车记录中客流统计
- 3.6.1 数据过滤
- 3.6.2 不同乘车区间客流量排行
- 3.6.3 不同线路区间客流排行
- 3.7 实时计算
- 3.7.1 将站点客流数据写入 Hbase 中
- 3.7.2 按照不同的业务场景从Hbase中读取数据
- 4 最后
1 前言
🔥 优质竞赛项目系列,今天要分享的是
地铁大数据客流分析系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1.1 实现目的
使用 Flink 完成数据清洗和聚合,使用 Elasticsearch + Kibana
的的技术路线,完成了客流信息,地铁收入、乘客车费、乘车区间和乘车时间的查询和可视化。
在此基础上,还使用 Flink 实现了计算各线路、站点和乘车区间的客流信息等实时计算功能,并将实时计算的结果写入到Hbase中,供下游业务查询使用。
2 数据集
2.2 数据集概况
- 数据集共用 1337000 条信息,其中包括 447708 条巴士的乘车信息和 781472 条地铁的出入站信息。巴士数据和地铁数据存在明显的不同:
- 乘坐巴士只需要上车的时候刷卡,因此一条记录就是一次乘车记录
- 而地铁在进出站时均需要刷卡,因此需要同时拥有一张交通卡的进出站记录才能构成一条完整的乘车记录
- 由于巴士的乘车记录比较简单,所有本项目中主要针对地铁的乘车记录进行计算和分析
- 地铁部分数据集的日期是北京时间 2018-09-01 05:00 ~ 2018-09-01-11:35
2.3 数据字段

3 实现效果
3.1 地铁数据整体概况
本项目只针对地铁的乘车记录进行分析,下面对数据集的整体概况做介绍,如图 1 所示,当日(2018-09-01 05:00 ~
2018-09-01-11:35)共计有 8 条线路的 170 个站点完成了 781472 人次的出入站,其中入站 415741 人次、出站 365731
人次,实际营业收入 1426697.15 元。因为不是一个完整的运营日所以出入站乘客人次并不相等。

3.2 平均指标

3.3 地铁2018年9月开通运营的线路
2018年9月该地区地铁共计有8条线路投入运行,分别是1号线、2号线、3号线、4号线、5号线、7号线、9号线、11号线,其具体线路图入下所示。


3.4 客流量相关统计
有关使用 Elasticsearch + Kibana实现数据可视化的具体细节。
3.4.1 线路客流量排行
如图所示是线路的客流排行榜,其中蓝色是入站客流,绿色是出站客流,根据图中信息可得到:
-
总客流排名:5 号线、3 号线、1 号线、4 号线、2 号线、7 号线、11 号线、9 号线
-
入站客流排名:5 号线、3 号线、1 号线、4 号线、7 号线、11 号线、9 号线、2 号线
-
出站客流排名:1 号线、5 号线、3 号线、2 号线、4 号线、7 号线、11 号线、9 号线

3.4.2 站点客流量排行
总客流量的排行
从图站点总客流排行可以看出,五和、布吉站(深圳东火车站)、罗湖站(深圳火车站)、深圳北(深圳北高铁站)和民治分列前五,其中五和、布吉和民治入站客流明显多于出站客流,而罗湖站和深圳北则完全相反,这些车站基本都是不同线路的换乘车站。

3.4.3 入站客流排行
对于入站客流,五和、布吉(深圳东火车站)、丹竹头、民治和龙华分列前五

3.4.4 整体客流随时间变化趋势
从图 中可以看出,出入站客流随时间变化都出现了明显的高峰,但是具体来说又存在不同:
- 入站客流的高峰在 08:30 附近,早于出站客流高峰的 08:45 附近
- 在 08:37 之前入站的客流都是多于出站客流
- 出站客流在 08:35-08:55 出现了大幅增加,这也与大部分公司固定的 9 点上班相吻合。
- 整体来说入站客流的波动性没有出站客流那么剧烈,因为入站客流相对于地铁到站瞬间大量出站乘客来说相对更平稳没有那么明显的波峰出现。

3.4.5 不同线路客流随时间变化
由于图表篇幅的限制只显示客流量前四的线路。从图 2.8 中可以看出 地铁 5 号线、地铁 3 号线、地铁 1 号线在不同时间段客流量的变化较大,尤其是是 5
号线早高峰十分明显,由此推测人们的工作地点多集中在 5 号线附近,从客流量也可以佐证这个观点。

3.4.6 不同线路的客流组成
以客流量最多的五号线为例,从图 2.9 可以看出五和、深圳北、民治三个站点的客流分别占全线客流的 9.53 9.53% 9.53、 7.96 7.96%
7.96、 7.24 7.24% 7.24,同时这三个站的客流量也排名所以站点客流的第一、第四和第五位,右侧图例从上到下客流量依次减少。

3.5 收入消费指标统计
3.5.1 线路收入排行
从图 可以看出,虽然 1 号线的客流量只能排在 5 号线和 3 号线之后屈居第三,但是其线路的收入却排名第一。而客流量第四的 4 号线其收入只能排在第六位。

3.5.2 各个站点对线路收入的贡献
以收入最多的地铁 1 号线为例,罗湖站、会展中心站和桃园站对全线的收入贡献分列前三,而前海湾则是全线副班长贡献最少。右侧图例从上到下对线路收入贡献依次减少。

3.5.3 不同消费金额次数占比
从图中可以看出、实际消费金额为 2.85、1.9、4.75、3.8和5.7排名总消费次数的前五。
值得注意的是消费金额为0在总消费次数中的占比为 2.13 2.13%
2.13,这个一方面是深圳地铁确实对部分人群免费乘坐,另外一部分是有内部员工卡产生的。

3.6 完整乘车记录中客流统计
3.6.1 数据过滤
数据中存在大量的数据不能构成完整的情况,如
- 对于一张卡只有入站或车站单条记录的显然不能构成一条完整的行程记录
- 对于入站点和出现点相同的情况显然是不合理的数据,同样不能构成一条合理行程记录
- 对于入站时间在 06:00 之前的记录同样不计算在内,因为深圳地铁的所有线路平均首班车时间在06:20左右,所以猜测可站点对外开放时间不会早于6:00。
- 对于按照时间排序之后同一张卡出现,连续两次均为入站或出站的视为不合法数据
入站时间早于06:00和入站点出站点相同的数据
深圳地铁的运营时间都是 6 点以后,所以之前的数据记录,均有内部工作人员活所产生,视为无效数据如卡号为 HHJJAFGAH 的用户在同一条线路的同一站点产生的这 6 条数据,从实际消费金额为 0.0 也可以佐证此推论1535752434000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-109,260036109 2018/9/1 5:53:541535752629000,HHJJAFGAH,2.0,0.0,地铁出站,地铁二号线,0,大剧院,AGM-117,260036117 2018/9/1 5:57:91535754065000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-109,260036109 2018/9/1 6:21:51535754386000,HHJJAFGAH,2.0,0.0,地铁出站,地铁二号线,0,大剧院,AGM-117,260036117 2018/9/1 6:26:261535758541000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-113,2600361131535758687000,HHJJAFGAH,2.0,0.0,地铁出站,地铁二号线,0,大剧院,AGM-105,260036105随然该持卡人极可能是内部用户,但是下面这条数据将被作为有效数据,因为乘车事件是真实发生的从大剧院 -> 晒布1535766418000,HHJJAFGAH,0.0,0.0,地铁入站,地铁二号线,0,大剧院,AGM-117,260036117 2018/9/1 9:46:581535767398000,HHJJAFGAH,2.0,0.0,地铁出站,地铁三号线,0,晒布,AGM-105,261013105 2018/9/1 10:3:18连续两次均为入站的数据1535755820000,CBCGDHCBB,0.0,0.0,地铁入站,地铁五号线,0,太安,AGT-118,2630351181535759424000,CBCGDHCBB,0.0,0.0,地铁入站,地铁四号线,0,清湖,AGM-105,2620111051535759862000,CBCGDHCBB,2.0,1.9,地铁出站,地铁四号线,0,清湖,AGM-108,2620111081535756340000,HHACJJFHE,0.0,0.0,地铁入站,地铁四号线,0,莲花北,AGM-109,2620201091535756926000,HHACJJFHE,0.0,0.0,地铁入站,地铁四号线,0,上梅林,AGM-110,2620191101535757664000,HHACJJFHE,2.0,0.0,地铁出站,地铁四号线,0,上梅林,AGM-104,2620191041535758092000,HHACJJFHE,0.0,0.0,地铁入站,地铁四号线,0,上梅林,AGM-110,2620191101535758342000,HHACJJFHE,2.0,0.0,地铁出站,地铁四号线,0,莲花北,AGM-107,262020107经过以上指标过滤之后得到能够构成完整且合理的出入站记录 572156 条,每两条记录组成一条完整的行程记录 ,因此有 286078
条合法行程记录,其中包含了入站和出站的时间、线路、站点、刷卡设备等,还能计算出单次乘车所用时间。
3.6.2 不同乘车区间客流量排行
排名前三的乘车区间是:赤尾 —> 华强北,福民福田 —> 口岸、五和 —> 深圳北

3.6.3 不同线路区间客流排行
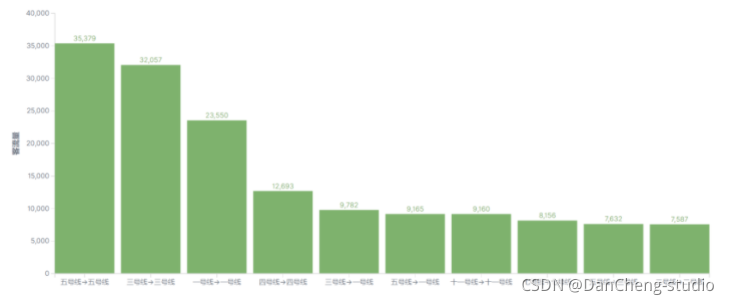
从图可以看出,5 号线直达,3 号线直达和 1 号线直达的客流最多。
3.7 实时计算
通过Flink可以实时计算过去的某个时间段内,个站点的出入站客流量以及总客流量,不同站点区间的客流量,以及不同线路区间的客流量等指标。
对于实时计算的结果可以使用 Redis 或者 Hbase 来进行存储,对于两者的技术特点对比如下:
- Redis作为纯内存NoSQL虽然读写性能十分优秀,但其支持的数据量通常受内存限制,而HBase没有这个限制,可以存储远超内存大小的数据
- HBase采用WAL,先记录日志再写入数据,理论上不会丢失数据。而Redis采用的是异步复制数据,在failover时可能会丢失数据
- 客流信息作为基本不需要再次变动已经固化, 非常适合使用 HBase 来存储。
综上本项目中使用 Hbase 来存储实时计算的数据结果。
3.7.1 将站点客流数据写入 Hbase 中
- 首先在 Hbase shell 中使用以下命令建立存储表
create ‘StationTraffic’, {NAME => ‘traffic’}
- 执行 com.ngt.traffic.HBaseWriterStationTraffic 将站点的客流信息写入 Hbase 中
# 时间 客流排名
2018-09-01 11:30 001 column=traffic:count, timestamp=1609614078234, value=117
2018-09-01 11:30 001 column=traffic:name, timestamp=1609614078234,value=\xE8\x80\x81\xE8\xA1\x97
代码中统计的是,过去五分钟的客流量信息,每一分钟滚动一次
.timeWindow(Time.minutes(5), Time.minutes(1))
3.7.2 按照不同的业务场景从Hbase中读取数据
执行 com.ngt.traffic.HBaseReaderStationTraffic 实现相关功能
需求1:查询 2018-09-01 08:30 - 2018-09-01 08:45 各站点最近五分钟的客流
case class Traffic(time: String, rank: String, station: String, count: String)
val dataStream1: DataStream[(String, String)] =
// 表名,列族名,起始Rowkey,终止Rowkey(取不到)
env.addSource(new HBaseReader(“StationTraffic”, “traffic”,“2018-09-01 08:30”, “2018-09-01 08:46”))
dataStream1.map(x => {val keys: Array[String] = x._1.split(" ")val values: Array[String] = x._2.split("_")Traffic("时间:" + keys(1), "站点:" + values(1), "排名:" + keys(2), "客流量:" + values(0))
})
.map(data => {println(data.time, data.rank, data.station, data.count)
})---------------------------------------
(时间:08:30,排名:001,站点:五和,客流量:548)
(时间:08:30,排名:002,站点:民治,客流量:386)
(时间:08:30,排名:003,站点:布吉,客流量:369)
(时间:08:30,排名:004,站点:丹竹头,客流量:343)
(时间:08:30,排名:005,站点:南山站,客流量:340)
(时间:08:30,排名:006,站点:深圳北,客流量:313)
(时间:08:30,排名:007,站点:罗湖站,客流量:306)
......
需求2:查询 2018-09-01 06:30 - 2018-09-01 11:30 客流量排名前 3 的站点
val dataStream2: DataStream[(String, String)] =
env.addSource(new HBaseReader(“StationTraffic”, “traffic”,“2018-09-01 06:30”, “2018-09-01 11:31”))
dataStream2.map(x => {val keys: Array[String] = x._1.split(" ")val values: Array[String] = x._2.split("_")Traffic("时间:" + keys(1), "排名:" + keys(2), "站点:" + values(1), "客流量:" + values(0))
})
.filter(_.rank.substring(3).toInt <= 3)
.map(data => {println(data.time, data.rank, data.station, data.count)
})
---------------------------------------
(时间:08:30,排名:001,站点:五和,客流量:548)
(时间:08:30,排名:002,站点:民治,客流量:386)
(时间:08:30,排名:003,站点:布吉,客流量:369)
(时间:08:31,排名:001,站点:五和,客流量:577)
(时间:08:31,排名:002,站点:南山站,客流量:436)
(时间:08:31,排名:003,站点:布吉,客流量:405)
(时间:08:32,排名:001,站点:五和,客流量:602)
(时间:08:32,排名:002,站点:南山站,客流量:439)
(时间:08:32,排名:003,站点:布吉,客流量:413)
(时间:08:33,排名:001,站点:五和,客流量:594)
(时间:08:33,排名:002,站点:南山站,客流量:451)
(时间:08:33,排名:003,站点:布吉,客流量:393)
......
不同乘车区间是同样的道理,更多的业务场景不在列举。
4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 地铁大数据客流分析系统 设计与实现
文章目录 1 前言1.1 实现目的 2 数据集2.2 数据集概况2.3 数据字段 3 实现效果3.1 地铁数据整体概况3.2 平均指标3.3 地铁2018年9月开通运营的线路3.4 客流量相关统计3.4.1 线路客流量排行3.4.2 站点客流量排行3.4.3 入站客流排行3.4.4 整体客流随时间变化趋势3.4.5 不同线路客…...

sonarqube报错http status 500-internal server error,什么原因,怎么解决
sonarqube报错http status 500-internal server error,什么原因,怎么解决 答案: SonarQube报错HTTP状态500-内部服务器错误通常是由于服务器端出现了一些问题导致的。这可能是由于配置错误、资源不足、数据库连接问题或其他一些未知的问题引起的。 以下…...

工业设计的四个主要阶段,你都知道吗?优漫动游
一般来说,工业设计有几个基本程序:概念过程——设计创造的意识,即为什么创造。如何使你的想法成为现实,最终形成一个实体;实现过程——在工作消费中创造;行为过程实现其所有价值。在整个设计过程中,设计师需要始终站在…...
【DevOps视频笔记】4.Build 阶段 - Maven安装配置
一、Build 阶段工具 二、Operate阶段工具 三、服务器中安装 四、修改网卡信息 五、安装 jdk 和 maven Stage1 : 安装 JDK Stage 2 : 安装 Maven 2-1 : 更换文件夹名称 2-2 : 替换配置文件 settings.xml- 2-3 : 修改settings.xml详情 A. 修改maven仓库地址 - 阿里云 B…...

linux非GUI模式执行带有jpgc线程组jmeter脚本报错
linux非GUI模式执行jmeter脚本报错 Error in NonGUIDriver java.lang.IllegalArgumentException: Problem loading XML from:/root/fer/xxx.jmx. Cause: CannotResolveClassException: kg.apc.jmeter.vizualizers.CorrectedResultCollectorDetail:com.thoughtworks.xstream.c…...
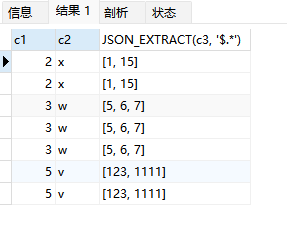
mysql处理json格式的字段,一文搞懂mysql解析json数据
文章目录 一、概述1、什么是JSON2、MySQL的JSON3、varchar、text、json类型字段的区别 二、JSON类型的创建1、建表指定2、修改字段 三、JSON类型的插入1、字符串直接插入2、JSON_ARRAY()函数插入数组3、JSON_OBJECT()函数插入对象4、JSON_ARRAYAGG()和JSON_OBJECTAGG()将查询结…...

测试数据生成
要生成300亿的文本数据,刚开始用python,实在是太慢了,改成c后速度提升了10几倍,看来干大事还是不能用python。代码留一下,以后可能还可以用上。 #include <stdio.h> #include <stdlib.h> #include <ti…...

网安周报|国防承包商Belcan泄露了带有漏洞列表的管理员密码
1.国防承包商Belcan泄露了带有漏洞列表的管理员密码 网络新闻研究团队发现了一个开放的 Kibana 实例,其中包含有关 Belcan、其员工和内部基础设施的敏感信息。Belcan 是一家政府、国防和航空航天承包商,提供全球设计、软件、制造、供应链、信息技术和数字…...
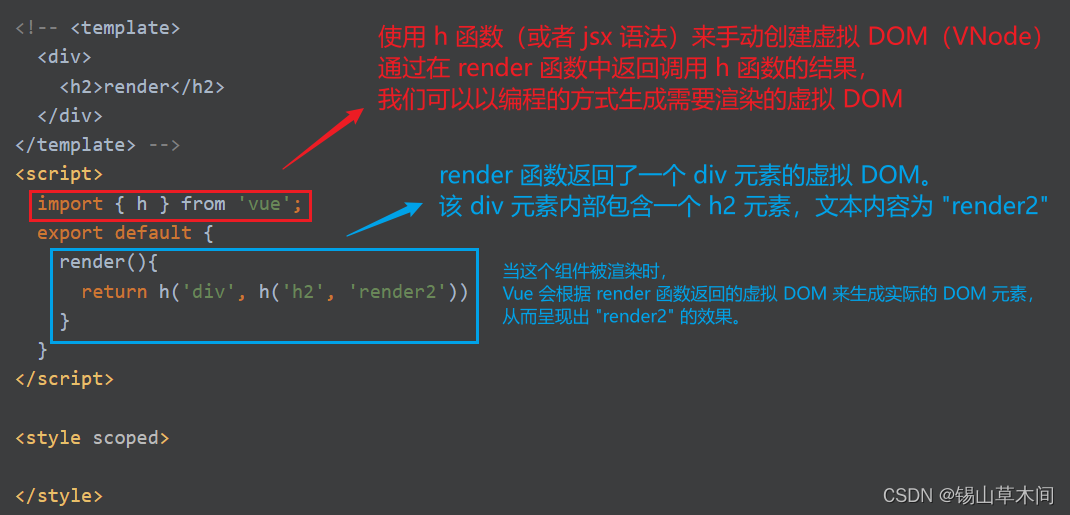
Vue3语法系统进阶 - 全面掌握Vue3特性
目录 01-ref属性在元素和组件上的分别使用02-利用nextTick监听DOM更新后的情况03-自定义指令与自定义全局属性及应用场景04-复用组件功能之Mixin混入05-插件的概念及插件的实现06-transition动画与过渡的实现07-动态组件与keep-alive组件缓存08-异步组件与Suspense一起使用09-跨…...

第9天----【位运算进阶之----按位取反(~)】(附补码,原码讲解)
今天我们来谈谈按位取反这件事。 简单来说,按位取反就是先将一个数写成其二进制表达形式,然后1变0,0变1。下面就让我们展开深入地讨论吧! 文章目录 一、预备知识:1. 原码:定义:优缺点ÿ…...

如何获取当前 JAR 包的存放位置?
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言代码中如何获取打包后的jar包存放的位置? 前言 代码中如何获取打包后的jar包存放的位置? 要获取当前运行的 JAR 包所存放的位置&#…...

微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。 一些知识点 llama2相比于前一代,令牌数量增加了40%࿰…...

Java【手撕双指针】LeetCode 57. “两数之和“, 图文详解思路分析 + 代码
文章目录 前言一、两数之和1, 题目2, 思路分析3, 代码展示 前言 各位读者好, 我是小陈, 这是我的个人主页, 希望我的专栏能够帮助到你: 📕 JavaSE基础: 基础语法, 类和对象, 封装继承多态, 接口, 综合小练习图书管理系统等 📗 Java数据结构: 顺序表, 链表…...

大数据(一)定义、特性
大数据(一)定义、特性 本文目录: 一、写在前面的话 二、大数据定义 三、大数据特性 3.1、大数据的大量 (Volume) 特性 3.2、大数据的高速(Velocity)特性 3.3、大数据的多样化 (Variety) 特性 3.4、大数据的价值 (value) 特性 3.5、大…...
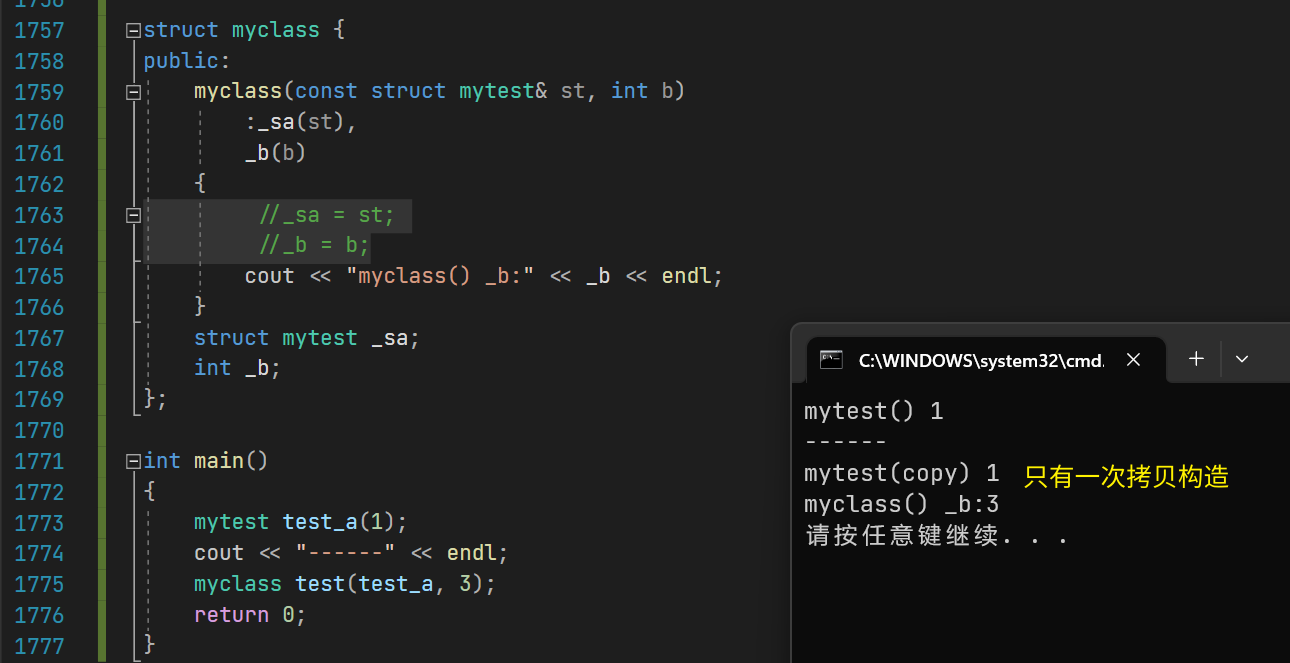
【C++】构造函数和初始化列表的性能差距
构造函数和初始化列表的性能差距对比测试 1.说明 在C类和对象中,你可能听到过更加推荐用初始化列表来初始化类内成员。如果类内成员是自定义类型,则只能在初始化列表中调用自定义类型的构造函数。 但初始化列表和在构造函数体内直接赋值有无性能差距呢…...

Linux下套接字TCP实现网络通信
Linux下套接字TCP实现网络通信 文章目录 Linux下套接字TCP实现网络通信1.引言2.具体实现2.1接口介绍1.socket()2.bind()3.listen()4.accept()5.connect() 2.2 服务器端server.hpp2.3服务端server.cc2.4客户端client.cc 1.引言 套接字(Socket)是计算机网络中实现网络通信的一…...

❤ vue清除定时器Bug
❤ vue清除定时器Bug 页面加载,清除定时器 clearTimeout(intm) 问题 遇见的需求是:webapp 从A页面进入B页面,B页面点击按钮,加载完B页面的加载效果进入c,从C页面返回A页面,仍然显示B页面的加载效果 结果定时器一直…...
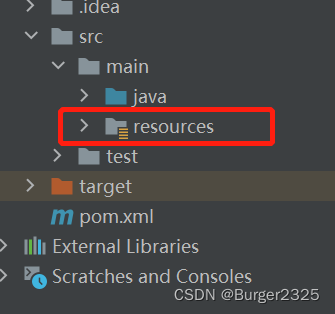
IDEA创建Spring,Maven项目没有resources文件夹
有时新建Spring或Maven项目时,会出现目录中main下无resources文件夹的情况,来一起解决一下: FIles|Project Structure 在Modules模块找到对应路径,在main下创建resources,右键main,选择新文件夹 输入文件…...
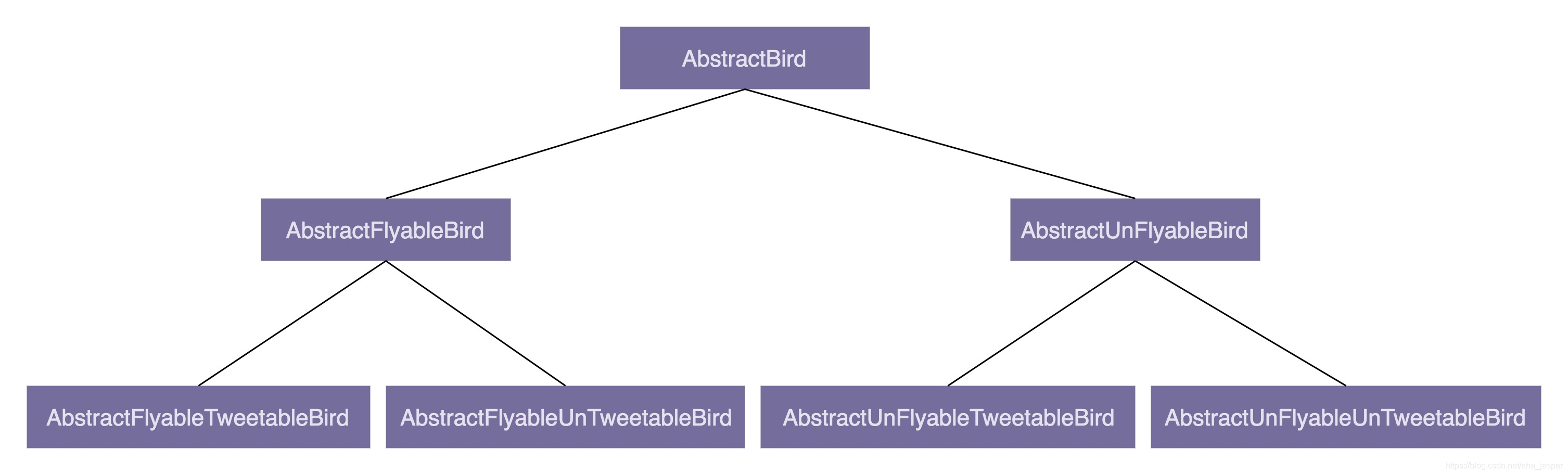
Unity 结构少继承多组合
为什么不推荐使用继承? 继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。所以,对于是否应该在…...

保研之旅2:中科院声学所“声学和信息学科”夏令营
💥💥💞💞欢迎来到本博客❤️❤️💥💥 本人持续分享更多关于电子通信专业内容以及嵌入式和单片机的知识,如果大家喜欢,别忘点个赞加个关注哦,让我们一起共同进步~ &#x…...

免费照片怎样去水印?2026年去水印app优缺点对比与4款工具推荐
在日常生活和内容创作中,我们经常会遇到需要去除照片水印的情况。无论是整理素材库、处理工作资料,还是保存喜欢的图片,一款好用的免费去水印软件可以大大提高效率。2026年市场上的去水印app选择众多,每款工具都有不同的特点和适用…...

告别论文焦虑:百考通AI,让你的本科毕业论文像“闯关升级”一样简单
又到了一年毕业季,对于广大本科生而言,那座名为“毕业论文”的大山,是否又一次压得你喘不过气?面对空白的Word文档,你是否感到无从下手?导师的催促、复杂的格式、浩如烟海的文献、以及令人心慌的查重……这…...

良品铺子卖菜:OEM模式的极限与宿命
一家卖零食的公司开始卖菜,听起来像是一个关于“内卷”的黑色幽默。2026年5月,良品铺子在武汉开出首家“良品铺子鲜生活”超市。这家门店不再陈列整齐的包装零食,而是摆上了新鲜蔬菜、现制熟食、现烤面包和冷藏冷冻品。公司将其定位为“社区厨…...
)
别再死磕PI参数了!用MATLAB/Simulink手把手教你搭建异步电机FOC仿真(附模型下载)
异步电机FOC仿真实战:从零搭建到参数调优全指南 在电机控制领域,矢量控制(FOC)技术因其优异的动态性能和效率表现,已成为工业应用中的主流方案。然而从理论到实践的跨越往往充满挑战——许多工程师能够理解Park变换、空间矢量调制等概念&…...

ESP32-C3深度睡眠唤醒踩坑记:GPIO0~5始终低电平?手把手教你用Arduino框架正确配置RTC GPIO
ESP32-C3深度睡眠唤醒实战指南:破解GPIO0~5低电平陷阱 凌晨三点的调试灯依然亮着,这是我本周第三次被ESP32-C3的深度睡眠唤醒问题折磨到深夜。作为一款主打低功耗的物联网芯片,ESP32-C3的深度睡眠模式本该是电池供电设备的福音,但…...

基于金橙子MarkEzd.dll的激光打标二次开发实战:从函数解析到自动化标刻系统构建
1. 金橙子MarkEzd.dll开发入门指南 第一次接触激光打标二次开发的朋友可能会被各种专业术语吓到,但其实只要掌握几个核心概念就能快速上手。MarkEzd.dll是北京金橙子科技为EZCAD2激光打标软件提供的开发接口,相当于给开发者开了一个"后门"&…...

ESP32-S3-DevKitC-1驱动3.5寸ILI9488 TFT:从零构建LVGL音乐播放器UI
1. 硬件准备与环境搭建 拿到ESP32-S3-DevKitC-1开发板和3.5寸ILI9488屏幕时,我第一反应是检查引脚兼容性。这块480x320分辨率的SPI屏需要连接6个关键引脚:SCK、MOSI、MISO、CS、DC和RST。实际接线时有个坑要注意——开发板的默认SPI引脚可能与屏幕要求不…...

保姆级拆解:Smoke3D的DLA34 Backbone如何一步步输出1/4特征图
深入解析Smoke3D中DLA34 Backbone的特征图生成机制 在计算机视觉领域,3D目标检测一直是极具挑战性的研究方向。Smoke3D作为单目3D检测的代表性框架,其核心架构DLA34 Backbone的特征提取过程值得深入探讨。本文将聚焦于输入图像如何通过DLA34的五次下采样…...

AM62A1-Q1汽车视觉处理器:低功耗、高集成度的车载视觉解决方案
1. 项目概述:为什么我们需要一颗“小而美”的汽车视觉处理器?最近在做一个车载环视和DMS(驾驶员监控系统)的预研项目,客户对成本和功耗卡得非常死,但功能要求却一点没降:需要同时处理1到2路摄像…...

终极指南:5步掌握MPh,让COMSOL仿真效率提升300%
终极指南:5步掌握MPh,让COMSOL仿真效率提升300% 【免费下载链接】MPh Pythonic scripting interface for Comsol Multiphysics 项目地址: https://gitcode.com/gh_mirrors/mp/MPh MPh(Pythonic scripting interface for Comsol Multip…...