第59步 深度学习图像识别:误判病例分析(TensorFlow)
基于WIN10的64位系统演示
一、写在前面
本期内容对等于机器学习二分类系列的误判病例分析(传送门)。既然前面的数据可以这么分析,那么图形识别自然也可以。
本期以mobilenet_v2模型为例,因为它建模速度快。
同样,基于GPT-4辅助编程,后续会分享改写过程。
二、误判病例分析实战
继续使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,肺结核病人700张,健康人900张,分别存入单独的文件夹中。
(a)直接分享代码
######################################导入包###################################
from tensorflow import keras
import tensorflow as tf
from tensorflow.python.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout, Activation, Reshape, Softmax, GlobalAveragePooling2D, BatchNormalization
from tensorflow.python.keras.layers.convolutional import Convolution2D, MaxPooling2D
from tensorflow.python.keras import Sequential
from tensorflow.python.keras import Model
from tensorflow.python.keras.optimizers import adam_v2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator, image_dataset_from_directory
from tensorflow.python.keras.layers.preprocessing.image_preprocessing import RandomFlip, RandomRotation, RandomContrast, RandomZoom, RandomTranslation
import os,PIL,pathlib
import warnings
#设置GPU
gpus = tf.config.list_physical_devices("GPU")warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号################################导入数据集#####################################
data_dir = "./MTB"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)batch_size = 32
img_height = 100
img_width = 100# 创建一个数据集,其中包含所有图像的路径。
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=True)
# 切分为训练集和验证集
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)def get_label(file_path):parts = tf.strings.split(file_path, os.path.sep)one_hot = parts[-2] == class_namesreturn tf.argmax(one_hot)def decode_img(img):img = tf.image.decode_jpeg(img, channels=3)img = tf.image.resize(img, [img_height, img_width])img = img / 255.0 # normalize to [0,1] rangereturn imgdef process_path_with_filename(file_path):label = get_label(file_path)img = tf.io.read_file(file_path)img = decode_img(img)return img, label, file_pathAUTOTUNE = tf.data.AUTOTUNE# 在此处对train_ds和val_ds进行图像处理,包括添加文件名信息
train_ds_with_filenames = train_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)
val_ds_with_filenames = val_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)# 对训练数据集进行批处理和预加载
train_ds_with_filenames = train_ds_with_filenames.batch(batch_size)
train_ds_with_filenames = train_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)# 对验证数据集进行批处理和预加载
val_ds_with_filenames = val_ds_with_filenames.batch(batch_size)
val_ds_with_filenames = val_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))for image, label, path in train_ds_with_filenames.take(1):print("Image shape: ", image.numpy().shape)print("Label: ", label.numpy())print("Path: ", path.numpy())train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")for images, labels, paths in train_ds_with_filenames.take(1):for i in range(15):plt.subplot(4, 5, i + 1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片plt.imshow(images[i])# 显示标签plt.xlabel(class_names[labels[i]])plt.show()######################################数据增强函数################################data_augmentation = Sequential([RandomFlip("horizontal_and_vertical"),RandomRotation(0.2),RandomContrast(1.0),RandomZoom(0.5, 0.2),RandomTranslation(0.3, 0.5),
])def prepare(ds, augment=False):ds = ds.map(lambda x, y, z: (data_augmentation(x, training=True), y, z) if augment else (x, y, z), num_parallel_calls=AUTOTUNE)return dstrain_ds_with_filenames = prepare(train_ds_with_filenames, augment=True)# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)###############################导入mobilenet_v2################################
#获取预训练模型对输入的预处理方法
from tensorflow.python.keras.applications import mobilenet_v2
from tensorflow.python.keras import Input, regularizers
IMG_SIZE = (img_height, img_width, 3)base_model = mobilenet_v2.MobileNetV2(input_shape=IMG_SIZE, include_top=False, #是否包含顶层的全连接层weights='imagenet')inputs = Input(shape=IMG_SIZE)
#模型
x = base_model(inputs, training=False) #参数不变化
#全局池化
x = GlobalAveragePooling2D()(x)
#BatchNormalization
x = BatchNormalization()(x)
#Dropout
x = Dropout(0.8)(x)
#Dense
x = Dense(128, kernel_regularizer=regularizers.l2(0.1))(x) # 全连接层减少到128,添加 L2 正则化
#BatchNormalization
x = BatchNormalization()(x)
#激活函数
x = Activation('relu')(x)
#输出层
outputs = Dense(2, kernel_regularizer=regularizers.l2(0.1))(x) # 添加 L2 正则化
#BatchNormalization
outputs = BatchNormalization()(outputs)
#激活函数
outputs = Activation('sigmoid')(outputs)
#整体封装
model = Model(inputs, outputs)
#打印模型结构
print(model.summary())
#############################编译模型#########################################
#定义优化器
from tensorflow.python.keras.optimizers import adam_v2, rmsprop_v2optimizer = adam_v2.Adam()#编译模型
model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])#训练模型
from tensorflow.python.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateSchedulerNO_EPOCHS = 5
PATIENCE = 10
VERBOSE = 1# 设置动态学习率
annealer = LearningRateScheduler(lambda x: 1e-5 * 0.99 ** (x+NO_EPOCHS))# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)#
checkpointer = ModelCheckpoint('mtb_jet_best_model_mobilenetv3samll-1.h5',monitor='val_accuracy',verbose=VERBOSE,save_best_only=True,save_weights_only=True)train_model = model.fit(train_ds,epochs=NO_EPOCHS,verbose=1,validation_data=val_ds,callbacks=[earlystopper, checkpointer, annealer])#保存模型
model.save('mtb_jet_best_model_mobilenet-1.h5')
print("The trained model has been saved.")###########################误判病例分析################################## 训练模型后,现在使用模型对所有图片进行预测,并保存预测结果到csv文件中
import pandas as pd# 保存预测结果的dataframe
result_df = pd.DataFrame(columns=["原始图片的名称", "属于训练集还是验证集", "预测为Tuberculosis的概率值", "判定的组别"])# 对训练集和验证集中的每一批图片进行预测
for dataset, dataset_name in zip([train_ds_with_filenames, val_ds_with_filenames], ["训练集", "验证集"]):for images, labels, paths in dataset:# 使用模型对这一批图片进行预测probabilities = model.predict(images)predictions = tf.math.argmax(probabilities, axis=-1)# 遍历这一批图片for path, label, prediction, probability in zip(paths, labels, predictions, probabilities):# 获取图片名称和真实标签image_name = path.numpy().decode("utf-8").split('/')[-1]original_label = class_names[label]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到dataframe中result_df = result_df.append({"原始图片的名称": image_name,"属于训练集还是验证集": dataset_name,"预测为Tuberculosis的概率值": probability[1],"判定的组别": group}, ignore_index=True)# 保存结果到csv文件
result_df.to_csv("result.csv", index=False)相比于之前的代码,主要有两处变化:
- 导入数据集部分:由之前的“image_dataset_from_directory”改成“tf.data.Dataset”,因为前者不能保存图片的原始路径和名称。而在误判病例分析中,我们需要知道每一张图片的名称、被预测的结果等详细信息。
- 误判病例分析部分:也就是需要知道哪些预测正确,哪些预测错误。
(b)调教GPT-4的过程
(b1)导入数据集部分:“image_dataset_from_directory”改成“tf.data.Dataset”
让GPT-4帮你改写即可,自行尝试:
################################导入数据集#####################################
data_dir = "./MTB"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:", image_count)batch_size = 32
img_height = 100
img_width = 100# 创建一个数据集,其中包含所有图像的路径。
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=True)
# 切分为训练集和验证集
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)def get_label(file_path):parts = tf.strings.split(file_path, os.path.sep)one_hot = parts[-2] == class_namesreturn tf.argmax(one_hot)def decode_img(img):img = tf.image.decode_jpeg(img, channels=3)img = tf.image.resize(img, [img_height, img_width])img = img / 255.0 # normalize to [0,1] rangereturn imgdef process_path_with_filename(file_path):label = get_label(file_path)img = tf.io.read_file(file_path)img = decode_img(img)return img, label, file_pathAUTOTUNE = tf.data.AUTOTUNE# 在此处对train_ds和val_ds进行图像处理,包括添加文件名信息
train_ds_with_filenames = train_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)
val_ds_with_filenames = val_ds.map(process_path_with_filename, num_parallel_calls=AUTOTUNE)# 对训练数据集进行批处理和预加载
train_ds_with_filenames = train_ds_with_filenames.batch(batch_size)
train_ds_with_filenames = train_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)# 对验证数据集进行批处理和预加载
val_ds_with_filenames = val_ds_with_filenames.batch(batch_size)
val_ds_with_filenames = val_ds_with_filenames.prefetch(buffer_size=AUTOTUNE)# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))for image, label, path in train_ds_with_filenames.take(1):print("Image shape: ", image.numpy().shape)print("Label: ", label.numpy())print("Path: ", path.numpy())train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")for images, labels, paths in train_ds_with_filenames.take(1):for i in range(15):plt.subplot(4, 5, i + 1)plt.xticks([])plt.yticks([])plt.grid(False)# 显示图片plt.imshow(images[i])# 显示标签plt.xlabel(class_names[labels[i]])plt.show()######################################数据增强函数################################data_augmentation = Sequential([RandomFlip("horizontal_and_vertical"),RandomRotation(0.2),RandomContrast(1.0),RandomZoom(0.5, 0.2),RandomTranslation(0.3, 0.5),
])def prepare(ds, augment=False):ds = ds.map(lambda x, y, z: (data_augmentation(x, training=True), y, z) if augment else (x, y, z), num_parallel_calls=AUTOTUNE)return dstrain_ds_with_filenames = prepare(train_ds_with_filenames, augment=True)# 在进行模型训练时,不需要文件名信息,所以在此处移除
train_ds = train_ds_with_filenames.map(lambda x, y, z: (x, y))
val_ds = val_ds_with_filenames.map(lambda x, y, z: (x, y))train_ds = train_ds.prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.prefetch(buffer_size=AUTOTUNE)代码解读:
数据导入:代码首先指定图像数据的存放路径(data_dir),并统计路径下的图像总数(image_count)。之后,它将图片的高度和宽度分别设定为100,并且指定批量处理的大小为32。
数据集创建:使用tf.data.Dataset.list_files创建一个包含所有图像路径的数据集,并通过洗牌(shuffle)打乱数据。然后,将20%的数据作为验证集,其余的作为训练集。
类别标签获取:根据文件夹名称作为类别标签,其中去除了名为"LICENSE.txt"的文件。
图像和标签处理:定义了几个函数来处理图像和标签。get_label函数通过切割文件路径获取类别标签并转为one-hot编码;decode_img函数将图像解码并调整大小,且将像素值归一化到[0,1]范围内;process_path_with_filename函数则通过调用前两个函数处理图像和标签。
并行处理和预加载:使用tf.data.AUTOTUNE对训练集和验证集进行并行处理和预加载,提高数据读取效率。
数据展示:展示了部分训练数据的图片、类别和文件路径,帮助我们对数据有个初步了解。
数据增强:定义了一个数据增强管道,其中包含了随机翻转、旋转、对比度调整、缩放和平移等操作。然后在训练集上应用这个数据增强管道。
(b2)误判病例分析部分
咒语:在{代码1}的基础上续写代码,达到下面要求:
(1)首先,提取出所有图片的“原始图片的名称”、“属于训练集还是验证集”、“预测为Tuberculosis的概率值”;文件的路劲格式为:例如,“MTB\Normal\Normal-690.png”属于Normal,也就是0标签,“MTB\Tuberculosis\Tuberculosis-680.png”属于Tuberculosis,也就是1标签;
(2)其次,由于模型以0.5为阈值,因此可以样本分为三份:(a)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测正确,判定为A组;(b)本来就是Normal的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为B组;(c)本来就是Normal的图片,预测为Tuberculosis的概率值大于等于0.5,则说明预测错误,判定为C组;(d)本来就是Tuberculosis的图片,预测为Tuberculosis的概率值小于0.5,则说明预测正确,判定为D组;
(3)居于以上计算的结果,生成一个名为result.csv表格文件。列名分别为:“原始图片的名称”、“属于训练集还是验证集”、“预测为Tuberculosis的概率值”、“判定的组别”。其中,“原始图片的名称”为所有1600张图片的图片名称;“属于训练集还是验证集”为这个图片属于训练集还是验证集;“预测为Tuberculosis的概率值”为模型预测该样本是Tuberculosis的概率值;“判定的组别”为根据步骤(3)判定的组别,A、B、C和D四组。
(4)需要把所有的图片都进行上面操作,注意是所有图片,而不只是一个批次的图片。
代码1为:{XXXX}
主要是把需求写清楚即可,代码及其解读:
# 训练模型后,现在使用模型对所有图片进行预测,并保存预测结果到csv文件中
import pandas as pd# 保存预测结果的dataframe
result_df = pd.DataFrame(columns=["原始图片的名称", "属于训练集还是验证集", "预测为Tuberculosis的概率值", "判定的组别"])# 对训练集和验证集中的每一批图片进行预测
for dataset, dataset_name in zip([train_ds_with_filenames, val_ds_with_filenames], ["训练集", "验证集"]):for images, labels, paths in dataset:# 使用模型对这一批图片进行预测probabilities = model.predict(images)predictions = tf.math.argmax(probabilities, axis=-1)# 遍历这一批图片for path, label, prediction, probability in zip(paths, labels, predictions, probabilities):# 获取图片名称和真实标签image_name = path.numpy().decode("utf-8").split('/')[-1]original_label = class_names[label]# 根据预测结果和真实标签,判定图片所属的组别group = Noneif original_label == "Tuberculosis" and probability[1] >= 0.5:group = "A"elif original_label == "Normal" and probability[1] < 0.5:group = "B"elif original_label == "Normal" and probability[1] >= 0.5:group = "C"elif original_label == "Tuberculosis" and probability[1] < 0.5:group = "D"# 将结果添加到dataframe中result_df = result_df.append({"原始图片的名称": image_name,"属于训练集还是验证集": dataset_name,"预测为Tuberculosis的概率值": probability[1],"判定的组别": group}, ignore_index=True)# 保存结果到csv文件
result_df.to_csv("result.csv", index=False)代码解读:
首先,代码创建了一个名为result_df的pandas DataFrame,用于存储预测结果。这个DataFrame有四个列,分别为"原始图片的名称"、"属于训练集还是验证集"、"预测为Tuberculosis的概率值"、"判定的组别"。
然后,代码开始遍历训练集和验证集中的每一批图片。对于每一批图片,首先使用训练好的模型进行预测,得到每个样本属于每个类别的概率值(probabilities)。然后,通过取概率值最大的类别作为预测结果(predictions)。
在对一批图片进行预测后,代码遍历这批图片。对于每个图片,代码首先从图片路径中获取图片名称(image_name),并从标签中获取图片的真实标签(original_label)。
然后,代码根据预测结果和真实标签判断图片属于哪个组别("A"、"B"、"C"、"D")。这里假设"Tuberculosis"和"Normal"是所有类别中的两个类别,而且概率值中的第二个元素表示的是预测为"Tuberculosis"的概率。具体的判断规则如下:
--如果真实标签是"Tuberculosis",且预测为"Tuberculosis"的概率值大于等于0.5,则图片属于组别"A"。
--如果真实标签是"Normal",且预测为"Tuberculosis"的概率值小于0.5,则图片属于组别"B"。
--如果真实标签是"Normal",且预测为"Tuberculosis"的概率值大于等于0.5,则图片属于组别"C"。
--如果真实标签是"Tuberculosis",且预测为"Tuberculosis"的概率值小于0.5,则图片属于组别"D"。
最后,代码将预测结果添加到result_df中,其中包含图片名称、数据集名称(训练集或验证集)、预测为"Tuberculosis"的概率值以及判定的组别。当所有图片都进行完预测后,将result_df保存为一个CSV文件。
三、输出结果

有了这个表,又可以水不少图了。
四、数据
链接:https://pan.baidu.com/s/15vSVhz1rQBtqNkNp2GQyVw?pwd=x3jf
提取码:x3jf
相关文章:
第59步 深度学习图像识别:误判病例分析(TensorFlow)
基于WIN10的64位系统演示 一、写在前面 本期内容对等于机器学习二分类系列的误判病例分析(传送门)。既然前面的数据可以这么分析,那么图形识别自然也可以。 本期以mobilenet_v2模型为例,因为它建模速度快。 同样,基…...
【Vue框架】基本的login登录
前言 最近事情比较多,只能抽时间看了,放几天就把之前弄的都忘了,现在只挑着核心的部分看。现在铺垫了这么久,终于可以看前端最基本的登录了😂。 1、views\login\index.vue 由于代码比较长,这里将vue和js…...
)
Python21天打卡Day16-内置方法map()
在 Python 中,map() 方法是一个内置的函数,用于将函数应用于可迭代对象(如列表、元组等)中的每个元素,返回一个包含结果的迭代器。 map() 方法的语法如下: map(function, iterable)function:表…...
伦敦银和伦敦金的区别
伦敦银河伦敦金并称贵金属交易市场的双璧,一般投资贵金属的投资者其实不是交易伦敦金就是交易伦敦银。相信经过一段时间的学习和投资,不少投资者都能分辨二者的区别。下面我们就来谈谈伦敦银和伦敦金有什么异同,他们在投资上是否有差别。 交易…...

【从零学习python 】92.使用Python的requests库发送HTTP请求和处理响应
文章目录 URL参数传递方式一:使用字典传递参数URL参数传递方式二:直接在URL中拼接参数获取响应头信息获取响应体数据a. 获取二进制数据b. 获取字符数据c. 获取JSON数据 进阶案例 URL参数传递方式一:使用字典传递参数 url https://www.apiop…...

Python requests实现图片上传接口自动化测试
最近帮别人写个小需求,需要本地自动化截图,然后图片自动化上传到又拍云,实现自动截图非常简单,在这里就不详细介绍了,主要和大家写下,如何通过Pythonrequests实现上传本地图片到又拍云服务器。 话不多说&a…...

【LeetCode-面试经典150题-day13】
目录 141.环形链表 2.两数相加 21.合并两个有序链表 138.复制带随机指针的链表 92.反转链表Ⅱ 141.环形链表 题意: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,…...

taro.js和nutui实现商品选择页面
1. 首先安装 Taro.js 和 NutUI: npm install -g tarojs/cli npm install taro-ui 2. 创建 Taro 项目并进入项目目录: taro init myapp cd myapp 3. 选用 Taro 模板一并安装依赖: npm install 4. 在页面目录中创建商品选择页: taro cre…...

数据结构--算法的时间复杂度和空间复杂度
文章目录 算法效率时间复杂度时间复杂度的概念大O的渐进表示法计算实例 时间复杂度实例 常见复杂度对比例题 算法效率 算法效率是指算法在计算机上运行时所消耗的时间和资源。这是衡量算法执行速度和资源利用情况的重要指标。 例子: long long Fib(int N) {if(N …...
Vue中使用element-plus中的el-dialog定义弹窗-内部样式修改-v-model实现-demo
效果图 实现代码 <template><el-dialog class"no-code-dialog" v-model"isShow" title"没有收到验证码?"><div class"nocode-body"><div class"tips">请尝试一下操作</div><d…...
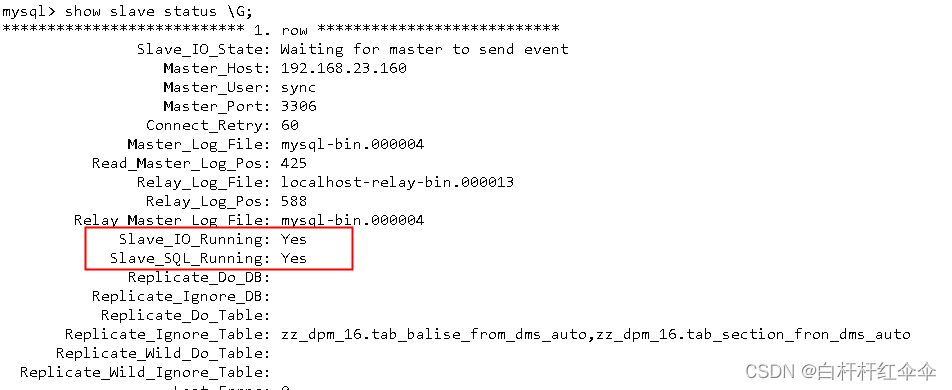
MySQL 主从配置
环境 centos6.7 虚拟机两台 主:192.168.23.160 从:192.168.23.163 准备 在两台机器上分别安装mysql5.6.23,安装完成后利用临时密码登录mysql数据修改root的密码;将my.cnf配置文件放至/etc/my.cnf,重启mysql服务进…...

上海亚商投顾:创业板指反弹大涨1.26% 核污染概念股午后全线走强
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 三大指数今日集体反弹,沪指午后冲高回落,创业板指盘中涨超2%,尾盘涨幅也有所收…...

Mysql数据库管理
一、数据库基本概念 数据 使用一些介质进行存储,例如文字存在文档中 数据库可以完成数据持久化保存快速提取 那么想要实现以上功能,需要编写一系列的规则--》SQL语句 SQL语句 按功能分类: 增删改查 数据库类型:关系型数据库、非关系型数据库…...
【java安全】FastJson反序列化漏洞浅析
文章目录 【java安全】FastJson反序列化漏洞浅析0x00.前言0x01.FastJson概述0x02.FastJson使用序列化与反序列化 0x03.反序列化漏洞0x04.漏洞触发条件0x05.漏洞攻击方式JdbcRowSetImpl利用链TemplatesImpl利用链**漏洞版本**POC漏洞分析 【java安全】FastJson反序列化漏洞浅析 …...
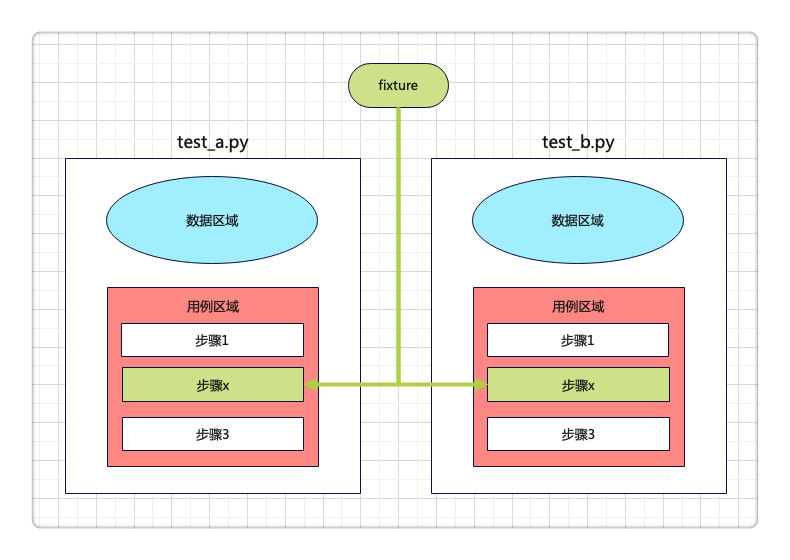
pytestx重新定义接口框架设计
概览 脚手架: 目录: 用例代码: """ 测试登录到下单流程,需要先启动后端服务 """test_data {"查询SKU": {"skuName": "电子书"},"添加购物车": {"sk…...

【文生图系列】Stable Diffusion原理篇
文章目录 Stable Diffusion的组成什么是扩散扩散是如何工作的去噪声绘制图像将文本信息添加到图像生成器中参考 “文生图”,或者AI绘画,最近异常火爆,输入一些描述性的语句,AI就能够生成相应的画作。甚至引发了一个问题࿱…...
ARM-汇编指令
一,map.lds文件 链接脚本文件 作用:给编译器进行使用,告诉编译器各个段,如何进行分布 /*输出格式:32位可执行程序,小端对齐*/ OUTPUT_FORMAT("elf32-littlearm", "elf32-littlearm",…...

Java相关知识对应leetcode
力扣账号:华为邮箱 类知识点力扣链接Integer转为String Character 判断字符是否是字母或者数字转为小写字母 不可修改 String 转为字符串数组 是否包含某个字符或者字符位置 可修改 StringBuffer 单个字符获取 string转为StringBufferStringBuffer转为String字符…...

js中?.、??、??=的用法及使用场景
上面这个错误,相信前端开发工程师应该经常遇到吧,要么是自己考虑不全造成的,要么是后端开发人员丢失数据或者传输错误数据类型造成的。因此对数据访问时的非空判断就变成了一件很繁琐且重要的事情,下面就介绍ES6一些新的语法来方便…...

每日一题:leetcode 1109 航班预订统计
这里有 n 个航班,它们分别从 1 到 n 进行编号。 有一份航班预订表 bookings ,表中第 i 条预订记录 bookings[i] [firsti, lasti, seatsi] 意味着在从 firsti 到 lasti (包含 firsti 和 lasti )的 每个航班 上预订了 seatsi 个座…...
)
用STM32F103C8T6做个触摸感应示波器?手把手教你ADC采集+OLED波形显示(附完整代码)
用STM32F103C8T6打造触摸感应示波器:从ADC采集到OLED波形显示的趣味实践 在嵌入式开发领域,将枯燥的技术参数转化为可视化的交互体验,往往能激发学习者的深层兴趣。今天我们要实现的,不仅是一个简单的信号采集系统,而是…...

OpenClaw 上下文瘦身:3 个实验
这篇不是讲“提示词怎么写得更优雅”。我只看一个更硬的问题:Agent 跑久以后,上下文到底是怎么胖起来的,哪一刀最值得先砍。实验脚本和结果都放在本地目录里,可以复跑。你大概见过这种故障: Agent 前 10 分钟很听话&am…...

从混乱到清晰:用Nacos用户权限管理,为微服务团队划清‘责任田’
从混乱到清晰:用Nacos用户权限管理为微服务团队划清‘责任田’ 在数字化转型浪潮中,中大型企业往往面临微服务架构下的协作困境。想象一个典型场景:电商促销季来临,支付团队紧急调整流水线配置时,却意外覆盖了用户中心…...

对比ubuntu本地直接调用与通过taotoken调用的开发便捷性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Ubuntu 本地直接调用与通过 Taotoken 调用的开发便捷性 在 Ubuntu 等 Linux 开发环境中集成大模型能力,开发者通常…...

【NotebookLM内容可信度跃迁关键】:如何用“证据锚定法”让讨论部分通过专家级评审?
更多请点击: https://intelliparadigm.com 第一章:NotebookLM讨论部分的可信度本质与评审标准 可信度的本质:语义对齐与溯源可验证性 NotebookLM 的讨论部分并非传统意义上的“生成式问答”,而是基于用户上传文档构建的语义索引…...

Hi3516DV300鸿蒙时钟应用开发:从环境搭建到驱动调试全流程
1. 项目概述:从零到一,在Hi3516DV300上跑通一个鸿蒙时钟最近在捣鼓OpenHarmony,手头正好有一块海思的Hi3516DV300开发板。这块板子性能不错,带屏显,很适合做点有意思的应用。我琢磨着,与其跑个现成的Demo&a…...

Redis Sentinel:主从架构的自动保镖详解
Redis 哨兵(Sentinel):主从架构的「自动保镖」 在 Redis 主从复制经典架构当中,主节点(Master)全权负责集群读写核心请求处理,从节点(Slave)仅专注于实时同步主节点数据&…...

告别重复劳动:用这个Maya Mel脚本插件,5分钟搞定Arnold材质批量调节
告别重复劳动:Maya Mel脚本插件在Arnold材质批量调节中的高效应用 在三维动画和视觉特效制作中,材质调节往往是项目后期最耗时的环节之一。当导演皱着眉头说"这个场景的金属感太强了"或者客户反馈"整体色调需要更暖一些"时…...

电子项目布线指南:从导线、电缆到连接器的核心选型与避坑
1. 项目概述:为什么“线”比“电路”本身更重要?干了十几年电子项目,从学生时代的第一个闪烁LED,到后来复杂的机器人系统和工业控制器,我踩过最多的坑,往往不是芯片选型或代码逻辑,而是那些看起…...

共享内存概述
共享内存,就是在内存里开辟一块公共空间,多个进程可以同时映射到自己的虚拟地址空间,大家直接读写同一块物理内存。是 Linux 进程间通信 IPC 最快 的一种方式。1️⃣创建共享内存空间2️⃣映射到自己的进程3️⃣strcpy写数据4️⃣断开与共享内…...