大数据——spark一文全知道
1、spark概述
spark是专为大规模数据处理而设计的快速通用计算引擎,与Hadoop的MapReduce功能类似,但它是基于内存的分布式计算框架,存储还是采用HDFS。
MapReduce和Spark的区别
- MapReduce的MapReduce之间需要通过磁盘进行数据传递,Spark直接存在内存中,所以速度更快。
- MapReduce的Task调度和启动开销大,而Spark的Task在线程中开销小一些。
- MapReduce编程不够灵活,Spark的API丰富。
- MapReduce的Map和Reduce都要一次shuffle,而Spark可以减少shuffle。
两者框架的区别:
| 功能 | Hadoop组件 | Spark组件 |
|---|---|---|
| 批处理 | MapReduce、Hive或者Pig | Spark Core、Spark SQL |
| 交互式计算 | Impala、presto | Spark SQL |
| 流式计算 | Storm | Spark Streaming |
| 机器学习 | Mahout | Spark ML、Spark MLLib |
Spark具有以下优点:
- 基于内存速度快;
- Java、Python和R语言可以开发spark易用性好;
- spark框架组件丰富,通用性高;
- 可以运行在多种存储结构上,兼容性高。
Spark的缺点:
- 内存消耗大。
2、Spark数据集
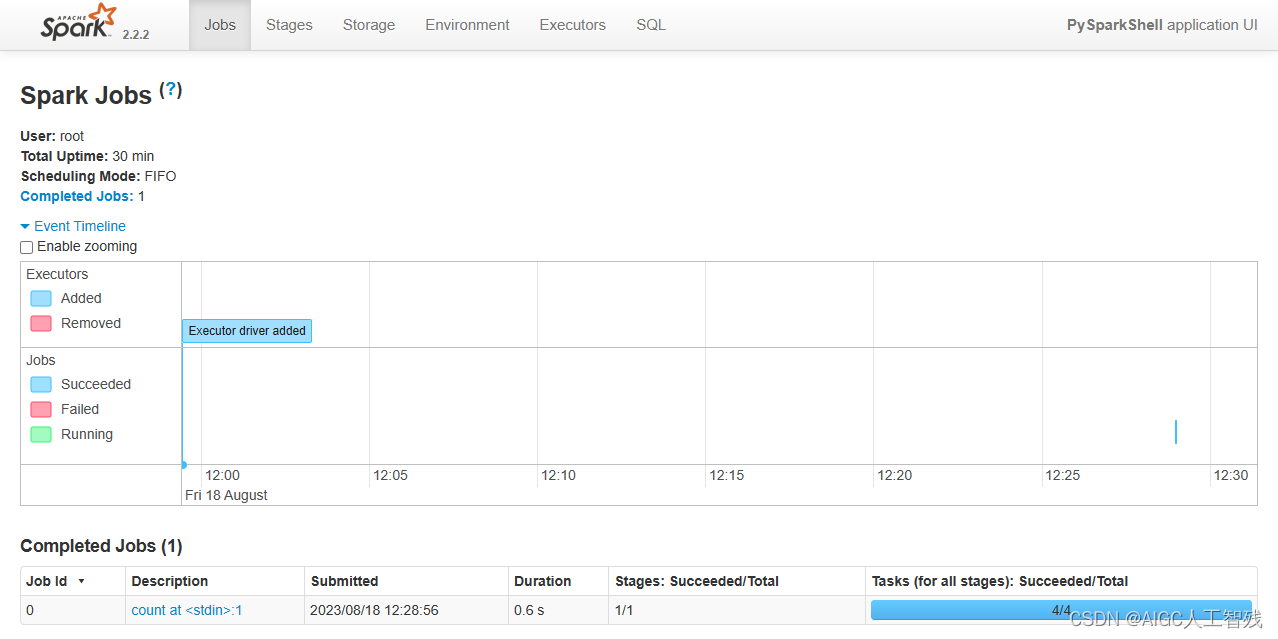
Spark的数据集合采用RDD(Resilient Distributed Dataset)弹性分布式数据集,它是一个不可变、可分区和可并行计算的集合。
- 不可变:RDD1到RDD2时,RDD1任然存在;
- 可分区:可分为多个partition;
- 并行计算;
- Dataset是指数据集,主要用于存放数据;
- Distributed是指分布式存储,并且可以进行分布式计算;
- Resilient弹性的特点:
- 数据可以保存在磁盘中,也可以在内存中;
- 数据分布式存储也是弹性的:
- RDD分在多个节点上存储,与HDFS的分布式存储原理类似:HDFS文件以128M为基准切分为多个block存储在各个节点上,而RDD则会被切分为多个partition,这些partition在不同的节点上;
- spark读取HDFS时,会把HDFS上的block读到内存上对应为partition;
- spark计算结束时,会把数据存储到HDFS上,可以对应到Hive或者HBase上,以HDFS为例:RDD的每一个partition的大小小于128M时,一个partition对应HDFS的block;大于128M时,则会切分为多个block。
3、RDD的数据操作
RDD的数据操作也叫做算子,一共包括三类算子:transformation、action和persist,其中前两种进行数据处理,persist进行数据存储操作。
- transformation:是将一个已经存在的数据集转化为一个新的数据集,map就是一个transformation操作,把数据集的每一个元素传给函数并返回新的RDD
- action:获取数据进行运算后的结果,reduce就是一个action操作,一般聚合RDD所有元素的操作,并返回最终计算结果。
- persist:缓存数据,可以把数据缓存在内存上,也可以缓存在磁盘上,甚至可以到磁盘其他节点上。
我们要了解所有的transformation的操作都是lazy:即不会立刻计算结果,而是记录下数据集的transformation操作,只有调用了action操作之后才会计算所有的transformation,这样会让spark运行效率更高。
pyspark启动
进入SPARK_HOME/sbin⽬录下执⾏
pyspark
sparkUI
可以在spark UI中看到当前的Spark作业 在浏览器访问当前centos的4040端⼝192.168.19.137:4040
启动RDD
3.1 transformation算子
- map(func):将func函数作用到数据集的每一个元素上,返回一个新的RDD
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd2 = rdd1.map(lambda x:x+1)
print(rdd2.collect())
[2, 3, 4, 5, 6, 7, 8, 9, 10]
- filter(func):筛选func函数中为true的元素,返回一个新的RDD
rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
rdd2 = rdd1.map(lambda x:x*2)
rdd3 = rdd2.filter(lambda x:x>10)
print(rdd3.collect())
[12, 14, 16, 18]
- flatMap(func):先执行map操作,然后将所有对象合并为一个对象
rdd1 = sc.parallelize(["a b c","d e f","h i j"])
rdd2 = rdd1.flatMap(lambda x:x.split(' '))
rdd3 = rdd1.map(lambda x:x.split(' '))
print('flatmap',rdd2.collect())
print('map',rdd3.collect())
flatmap [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’, ‘h’, ‘i’, ‘j’]
map [[‘a’, ‘b’, ‘c’], [‘d’, ‘e’, ‘f’], [‘h’, ‘i’, ‘j’]]
- union(rdd):两个RDD并集
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
print(rdd3.collect())
[(‘a’, 1), (‘b’, 2), (‘c’, 1), (‘b’, 3)]
- intersection(rdd):两个RDD求交集
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
rdd4 = rdd3.intersection(rdd2)
print(rdd4.collect())
[(‘c’, 1), (‘b’, 3)]
- groupByKey():以元祖中的第0个元素为key,进行分组,返回新的RDD,返回的结果中value是Iterable需要list进行转化
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
rdd4 = rdd3.groupByKey()
print(rdd4.collect())
print(list(rdd4.collect()[0][1]))
[(‘b’, <pyspark.resultiterable.ResultIterable object at 0x7f23ab41a4a8>),
(‘c’, <pyspark.resultiterable.ResultIterable object at 0x7f23ab41a4e0>),
(‘a’, <pyspark.resultiterable.ResultIterable object at 0x7f23ab41a438>)]
[2, 3]
- reduceByKey(func):将key相同的键值对,按照func进行计算,返回新的RDD
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
rdd2 = rdd.reduceByKey(lambda x,y:x+y)
print(rdd2.collect())
[(‘a’, 2), (‘b’, 1)]
- sortByKey(ascending=True, numPartitions=None, keyfunc=
tmp2 = [('Mary', 1), ('had', 2), ('a', 3), ('little', 4), ('lamb',5)]
tmp2.extend([('whose', 6), ('fleece', 7), ('was', 8), ('white',9)])
rdd1 = sc.parallelize(tmp2)
rdd2 = rdd1.sortByKey(True,3,keyfunc=lambda k:k.lower())
print(rdd2.collect())
[(‘a’, 3), (‘fleece’, 7), (‘had’, 2), (‘lamb’, 5), (‘little’, 4), (‘Mary’, 1), (‘was’, 8), (‘white’, 9), (‘whose’, 6)]
- mapPatitions(func):分块进行map,默认的map是一行行数据进行,该函数是一块块进行的,适合数据量大的情况。
- sparkContext.broadcast(要共享的数据):当某个数据需要反复查询时,不用把数据放进task中,可以通过⼴播变量, 通知当前worker上所有的task, 来共享这个数据,避免数据的多次复制,可以⼤⼤降低内存的开销。
3.2 action算子
- collect():返回⼀个list,list中包含 RDD中的所有元素,建议数量较小时使用,数据较大不会全部显示
rdd1 = sc.parallelize([1,2,3,4,5])
print(rdd1.collect())
[1, 2, 3, 4, 5]
- reduce(func):将RDD中元素两两传递给输⼊函数,同时产⽣⼀个新的值,新产⽣的值与RDD中下⼀个元素再被传递给输⼊函数直到最后只有⼀个值为⽌。
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.reduce(lambda x,y:x+y)
print(result)
15
- first():返回RDD中的第一个元素
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.first()
print(result)
1
- take(num):返回RDD的前num个元素
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.take(3)
print(result)
[1, 2, 3]
- count():返回RDD元素个数
rdd1 = sc.parallelize([1,2,3,4,5])
result = rdd1.count()
print(result)
5
4、Spark架构
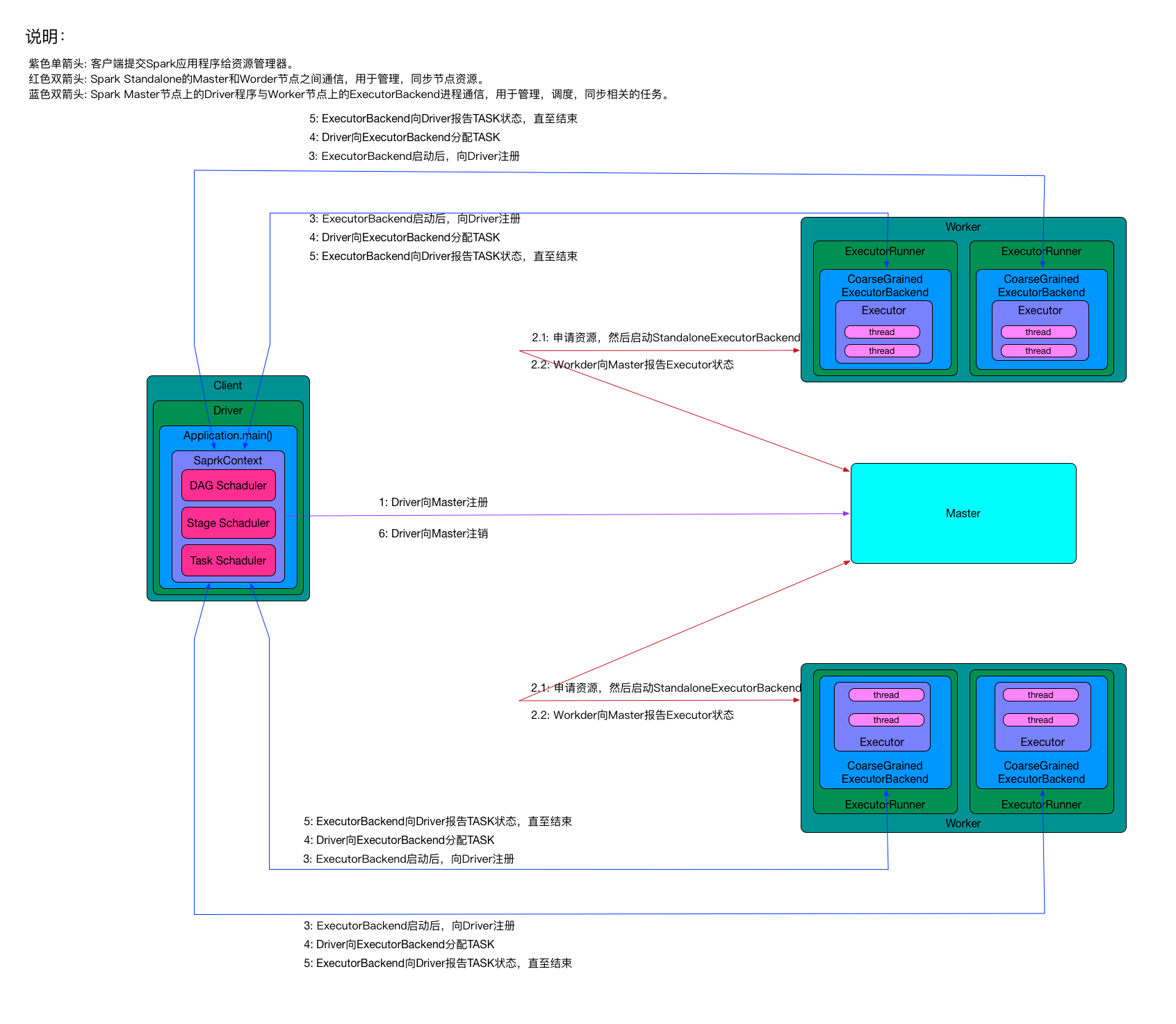
- Client:客户端进程
- Driver:一个Spark作业负责一个Driver进程,负责向Master注册和注销,包括:StageScheduler、TaskSchedule和DAGSchedule。
- StageSchedule:负责生成Stage。
- Stage:一个Spark作业一般包含一到多个Stage。
- DAGSchedule:负责将Spark作业分解成一个多个Stage,将Stage根据RDD的Partition个数决定Task个数,然后放到TaskSchedule中。
- TaskSchedule:将Task分配到ExecutorBackend上执行,并监控Task状态。
- Task:一个Stage包含一个多个Task,多个Task实现并行运行。
- StageSchedule:负责生成Stage。
- Application:Spark应用程序,批处理作业的集合。其中main方法时入口,定义了RDD和RDD的操作。
- Master:Standalone模式中的主控节点,负责接收Client提交的作业,管理Worker,并让Worker启动Driver和Executro。
- Worker:Standalone模式中的salve节点上的守护节点,负责管理本节点的资源,定期向Master汇报心跳,接收Master命令,启动Driver和Executor。
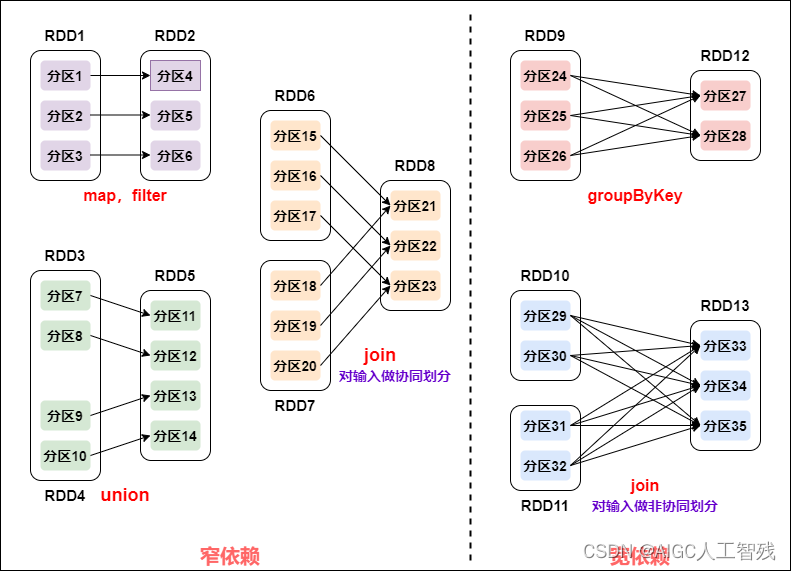
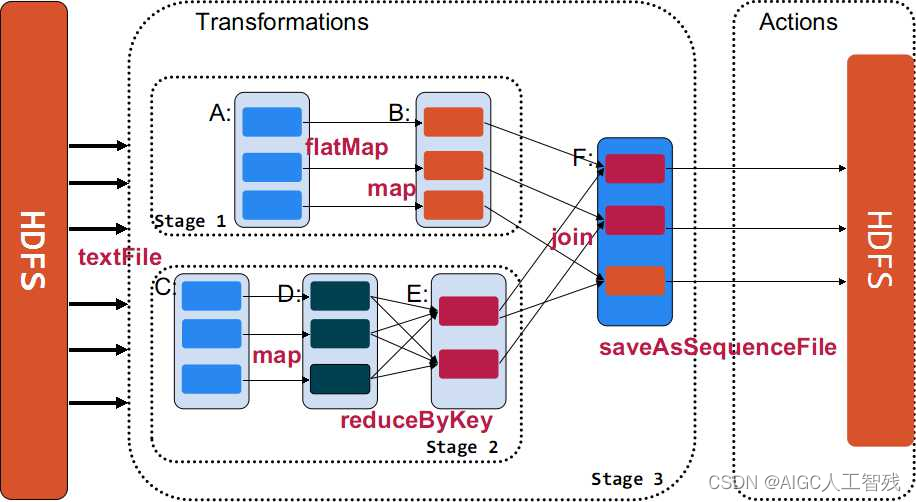
Spark作业的Stage划分
- 窄依赖:父RDD的每个Partition最多被一个子RDD的Partition所使用,即一个父RDD对应一个子RDD。map、filter、union、join对输入做协同划分。
- 宽依赖:子RDD依赖所有父RDD分区。groupByKey、join对输入做非协同划分。
窄依赖的所有RDD作为一个Stage,遇到宽依赖结束。
相关文章:
大数据——spark一文全知道
1、spark概述 spark是专为大规模数据处理而设计的快速通用计算引擎,与Hadoop的MapReduce功能类似,但它是基于内存的分布式计算框架,存储还是采用HDFS。 MapReduce和Spark的区别 MapReduce的MapReduce之间需要通过磁盘进行数据传递…...

Linux命令200例:telnet用于远程登录的网络协议(常用)
🏆作者简介,黑夜开发者,全栈领域新星创作者✌。CSDN专家博主,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。 &…...

使用 eBPF 在云中实现网络可观测性
可观测性是一种了解和解释应用当前状态的能力,也是一种知道何时出现问题的方法。随着在 Kubernetes 和 OpenShift 上以微服务形式进行云部署的应用程序越来越多,可观察性受到了广泛关注。许多应用程序都有严格的承诺,比如在停机时间、延迟和吞…...
linux安装部署gitlab全教程,包含配置中文
linux安装部署gitlab全教程,包含配置中文 大家好,我是酷酷的韩~ 1.前期准备 安装包下载地址 https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/ 我这里选择的这个gitlab-ce-15.7.3-ce.0.el7.x86_64.rpm 还有一些相关依赖包(地址等审核过我放到…...

软考高级系统架构设计师系列论文八十:论企业信息化战略规划技术
软考高级系统架构设计师系列论文八十:论企业信息化战略规划技术 一、企业信息化相关知识点二、摘要三、正文四、总结一、企业信息化相关知识点 软考高级系统架构设计师:企业信息化战略与实施...

使用ChatGPT构建一个AIML聊天机器人是什么体验
使用ChatGPT构建一个AIML聊天机器人是什么体验,使用ChatGPT将C#代码转换为Swift代码以实现Swift版的Aiml聊天机器人,AIML(全名为Artificial Intelligence Markup Language)是一种基于XML模式匹配的人工智能标记语言,…...
[JavaWeb]【九】web后端开发-SpringBootWeb案例(菜单)
目录 一、准备工作 1.1 需求 1.2 环境搭建 1.2.1 准备数据库&表 1.2.2 创建springboot工程 1.2.3 配置application.properties & 准备对应实体类 1.2.3.1 application.properties 1.2.3.2 实体类 1.2.3.2.1 Emp类 1.2.3.2.2 Dept类 1.2.4 准备对应的Mapper、…...

vue 主组件把日期选择器给子组件props传obj值, 与子组件监听 watch对象或对象属性
1 主组件 1.1 :passObj 这种 非v-model ; change"DateChange"触发事件 <template> <div class"date-picker-panel"><el-date-picker v-model"value2" type"datetimerange" :picker-options"pickerOptions"…...

WebDAV之π-Disk派盘 + 一刻日记
一刻日记是一款日记、笔记和备忘录应用程序,旨在提供一个简单而专注的日记写作工具。它提供了一个干净、直观的界面,允许用户记录和管理他们的日常事务、个人情感、成就和目标等内容。 一刻日记的主要功能包括: – 创建和编辑日记、用户可以撰写和编辑自己的日记,记录重要…...

springboot aop实现接口防重复操作
一、前言 有时在项目开发中某些接口逻辑比较复杂,响应时间长,那么可能导致重复提交问题。 二、如何解决 1.先定义一个防重复提交的注解。 import java.lang.annotation.*;Inherited Target(ElementType.METHOD) Retention(RetentionPolicy.RUNTIME) Do…...

ubuntu18.04复现yolo v8环境配置之CUDA与pytorch版本问题以及多CUDA版本安装及切换
最近在复现yolo v8的程序,特记录一下过程 环境:ubuntu18.04ros melodic 小知识:GPU并行计算能力高于CPU—B站UP主说的 Ubuntu可以安装多个版本的CUDA。如果某个程序的Pyorch需要不同版本的CUDA,不必删除之前的CUDA,…...

Yaml配置文件读取方法
在日常的代码中,有一些值是配置文件中定义的,这些值可以根据用户的要求进行调整和改变。这往往会写在yaml格式的文件中。这样开放程序给用户时,就可以不必开放对应的源码,只开放yaml格式的配置文件即可。 将配置文件中的值读入程…...

Python3 lambda 函数入门示例 Python lambda 函数
Python lambda 函数 首先,这个语法跟C的语法几乎一样; 通常称 lambda 函数为匿名函数,也称为 丢弃函数,因为应一下子就不要了,不会长期凝结下来形成SDK API;本人觉得它有点类似 inline 函数,或者…...
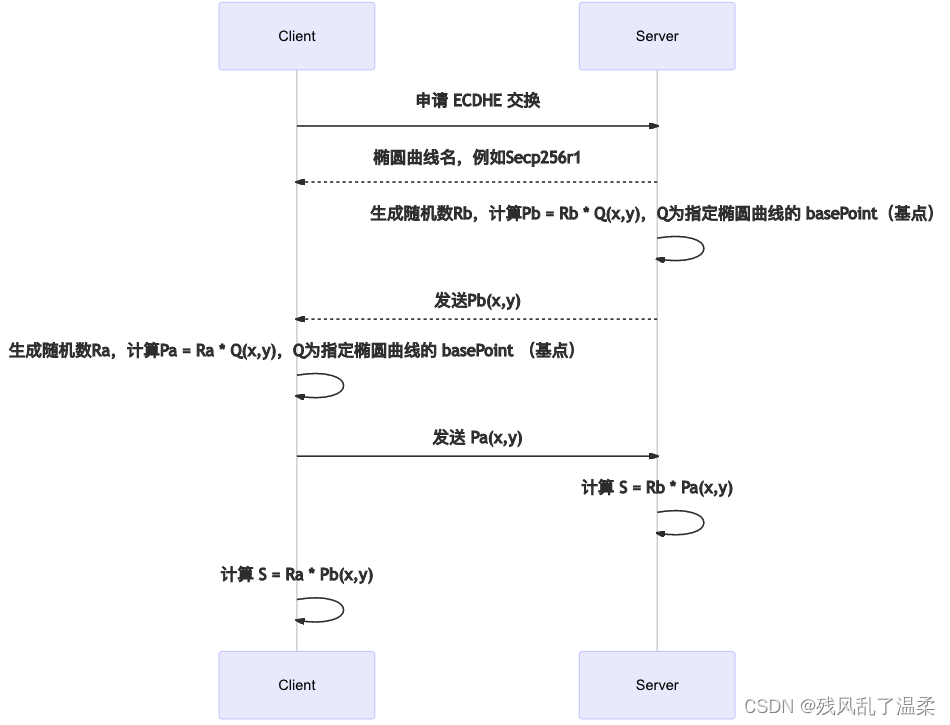
【计算机网络】HTTPs 传输流程
HTTPS和HTTP的区别 1、HTTP协议传输的数据都是未加密的,是明文的,使用HTTP协议传输隐私信息非常不安 HTTPS协议是由SSLHTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。 2、HTTPS协议需要到CA申请证书,一般…...
)
【Linux】国产深度系统装机必备(开发、日常使用)
开发相关工具 IDE推荐官网下载JetBrains Toolbox,后续所有与jetbrains直接全部到toolbox中下载,这里默认所有的app全部放在个人用户下(/data/home/计算机用户名/.local/share/JetBrains/Toolbox/apps)终端可视化工具:…...

动态规划入门:斐波那契数列模型以及多状态(C++)
斐波那契数列模型以及多状态 动态规划简述斐波那契数列模型1.第 N 个泰波那契数(简单)2.三步问题(简单)3.使⽤最⼩花费爬楼梯(简单)4.解码方法(中等) 简单多状态1.打家劫舍ÿ…...

LeetCode438.找到字符串中所有字母异位词
因为之前写过一道找字母异位词分组的题,所以这道题做起来还是比较得心应手。我像做之前那道字母异位词分组一样,先把模板p排序,然后拿滑动窗口去s中从头到尾滑动,窗口中的这段字串也给他排序,然后拿这两个排完序的stri…...

【微服务】03-HttpClientFactory与gRpc
文章目录 1.HttpClientFactory :管理外向请求的最佳实践1.1 核心能力1.2 核心对象1.3 HttpClient创建模式 2.gRPC:内部服务间通讯利器2.1 什么是gRPC2.2 特点gRPC特点2.3.NET生态对gRPC的支持情况2.4 服务端核心包2.5 客户端核心包2.5 .proto文件2.6 gRP…...
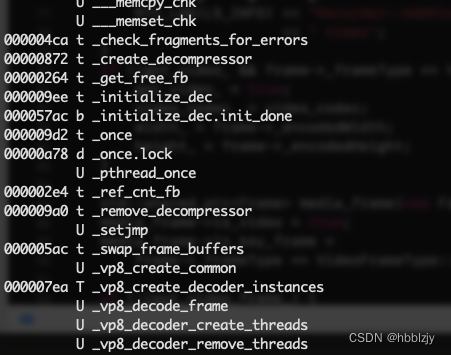
iOS开发之查看静态库(.a/.framework)中包含的.o文件和函数符号(ar,nm命令)
.a/.framework其实是把编译生成的.o文件,打包成一个.a/.framework文件。a的意思是archive/归档的意思。 查看静态库.a文件包含的内容用下面的命令解压: ar x xxx.a 用ar命令打包静态库: 参数r是将后面的*.o或者*.a文件添加到目标文件中 参数…...

Idea常用快捷键--让你代码效率提升一倍(一)
一、代码编辑相关快捷键 1.单行复制(实现快速创建多个对象)CtrlD 2.空出下一行 ShiftEnter 3.单行注释快捷键 ctrl / 4.快速构建构造函数,setter,getter、toString方法 AltInsert 4.显示快速修复和操作的菜单 altenter 5.格式化代码:C…...

FinRL_Podracer:基于深度强化学习的高性能量化交易框架解析
1. 项目概述:当强化学习遇上量化交易最近几年,量化交易圈子里有个词儿越来越热,那就是“强化学习”。你可能听说过AlphaGo下围棋,或者AI在星际争霸里打败人类高手,这些背后都是强化学习在发力。简单来说,它…...
)
Perplexity Nature检索实战手册:9类典型查询失败场景+对应Prompt工程模板(含IEEE/ACS/Nature交叉验证结果)
更多请点击: https://intelliparadigm.com 第一章:Perplexity Nature文章检索实战手册导论 Perplexity Nature 是面向科研人员与技术从业者设计的智能学术检索增强工具,它融合了语义理解、引用图谱分析与跨源文献聚合能力,专为高…...

oh-my-prompt:打造高效终端提示符的模块化方案与实战配置
1. 项目概述:为什么我们需要一个现代化的终端提示符?如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那么终端提示符(Prompt)就是你最熟悉的“工作台面”。默认…...

Epsilla向量数据库实战:10倍性能提升的RAG系统核心架构解析
1. 项目概述:为什么我们需要另一个向量数据库?如果你最近在折腾大语言模型应用,尤其是RAG(检索增强生成)系统,那你肯定对向量数据库这个概念不陌生。从Pinecone、Weaviate到Milvus、Qdrant,市面…...

ClawSuite:模块化网络安全工具集在渗透测试中的实战应用
1. 项目概述:ClawSuite,一个被低估的网络安全工具集如果你在网络安全领域摸爬滚打了一段时间,尤其是在渗透测试或者红队评估的圈子里,你大概率听说过或者用过像 Metasploit、Nmap、Burp Suite 这些耳熟能详的“瑞士军刀”。但今天…...

MCP协议实战:构建AI智能体任务管理服务器与二次开发指南
1. 项目概述:一个为AI智能体“开眼”的MCP服务器最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解为给大模型(比如Claude、GPT-4&am…...

如何在30秒内获取国家中小学智慧教育平台电子课本:终极解析工具指南
如何在30秒内获取国家中小学智慧教育平台电子课本:终极解析工具指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容…...

别再乱装驱动了!Ubuntu 20.04显卡驱动‘掉了’的终极排查与修复思路
Ubuntu 20.04显卡驱动失效的系统化诊断与修复指南 当你正专注于一个重要项目时,突然发现Ubuntu的NVIDIA显卡驱动"神秘消失"——这种体验对Linux用户来说简直像一场噩梦。nvidia-smi命令返回"驱动未加载",外接显示器黑屏,…...

对lsof、tcpdump、strace命令的简单记录
1. lsof (List Open Files) —— “谁占用了资源?” 核心哲学:Linux 中一切皆文件(包括磁盘文件、网络 Socket、设备)。 常用操作:lsof -i :15000:查看指定端口的进程占用及连接状态(LISTEN/EST…...

国家级数据仓库构建:从爬取到应用的全流程实践指南
1. 项目概述与核心价值最近在整理一个数据项目时,我偶然发现了一个名为“national_data”的仓库,作者是Ddhjx。这个项目名听起来平平无奇,但点进去之后,我发现它远不止是一个简单的数据集合。它本质上是一个结构化的、持续更新的国…...