用python从零开始做一个最简单的小说爬虫带GUI界面(2/3)
目录
前一章博客
前言
主函数的代码实现
逐行代码解析
获取链接
获取标题
获取网页源代码
获取各个文章的链接
函数的代码
导入库文件
获取文章的标题
获取文章的源代码
提取文章目录的各个文章的链接
总代码
下一章内容
前一章博客
用python从零开始做一个最简单的小说爬虫带GUI界面(1/3)_木木em哈哈的博客-CSDN博客而且当时的爬虫代码有许多问题但是最近学了PyQt5想着搞个带界面的爬虫玩玩那就啥也不说开搞!!!https://blog.csdn.net/mumuemhaha/article/details/132394257?spm=1001.2014.3001.5501
前言
前一章博客我们讲了怎么通过PyQt5来制作图形化界面,并且进行一些基本设置
接下来两章我们主要讲核心爬虫代码的实现

主函数的代码实现
前一章中的代码
self.Button_run.clicked.connect(self.F_run)代表点击按钮执行F_run函数(注意这里不要打括号)
那么我们就需要定义这个函数
思路大概就是这样
def F_run(self):link_1=self.line_link.text()title_1=F_gettitle(link_1)self.text_result.setText(f"标题获取成功——{title_1}")# file_1=open(f'{title_1}.txt',mode='w',encoding='utf-8 ')test_1=F_getyuan(link_1)self.text_result.setText("提取源代码成功")time.sleep(1)search_1=F_searchlink(test_1)self.text_result.append("提取文章链接成功")pachong(search_1,title_1)逐行代码解析
获取链接
首先通过
self.line_link.text()命令获取在输入框中输入的链接
并且把它赋值到link_1中
获取标题
同时我会通过爬取网页链接的源代码进行提取关键字获得文章的标题
也就是小说的名字
title_1=F_gettitle(link_1)获取网页源代码
爬取小说文章目录网页的源代码并且赋值为test_1(用于后续提取各个文章的链接)
test_1=F_getyuan(link_1)获取各个文章的链接
search_1=F_searchlink(test_1)把得到的源代码进行提取筛选获得各个文章的链接
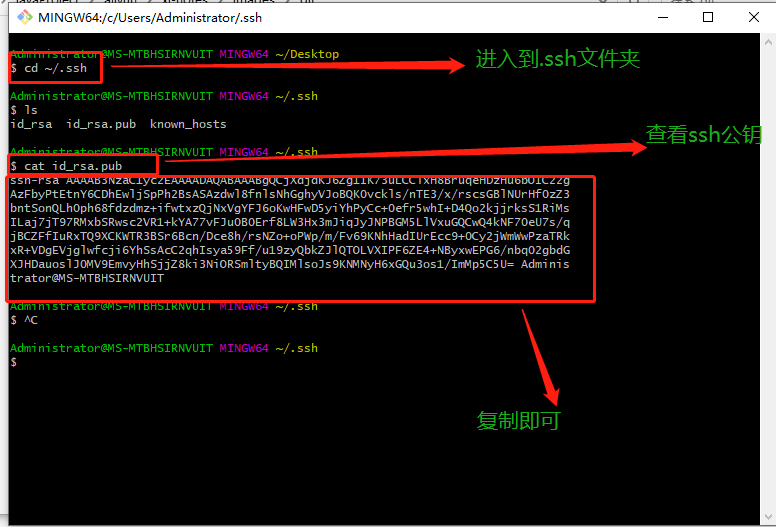
其中self.text_result.setText以及self.text_result.append是在下面红圈中显示的东西
(美观用,可以不加)
函数的代码
这里为了不让代码过于长,我自己有单独新建了两个python文件用于存放python函数
导入库文件
import requests
import re
import numpy as np
from lxml import etreerequest用于网络请求
re以及lxml用于过滤源代码的信息
而numpy用于存储元素
获取文章的标题
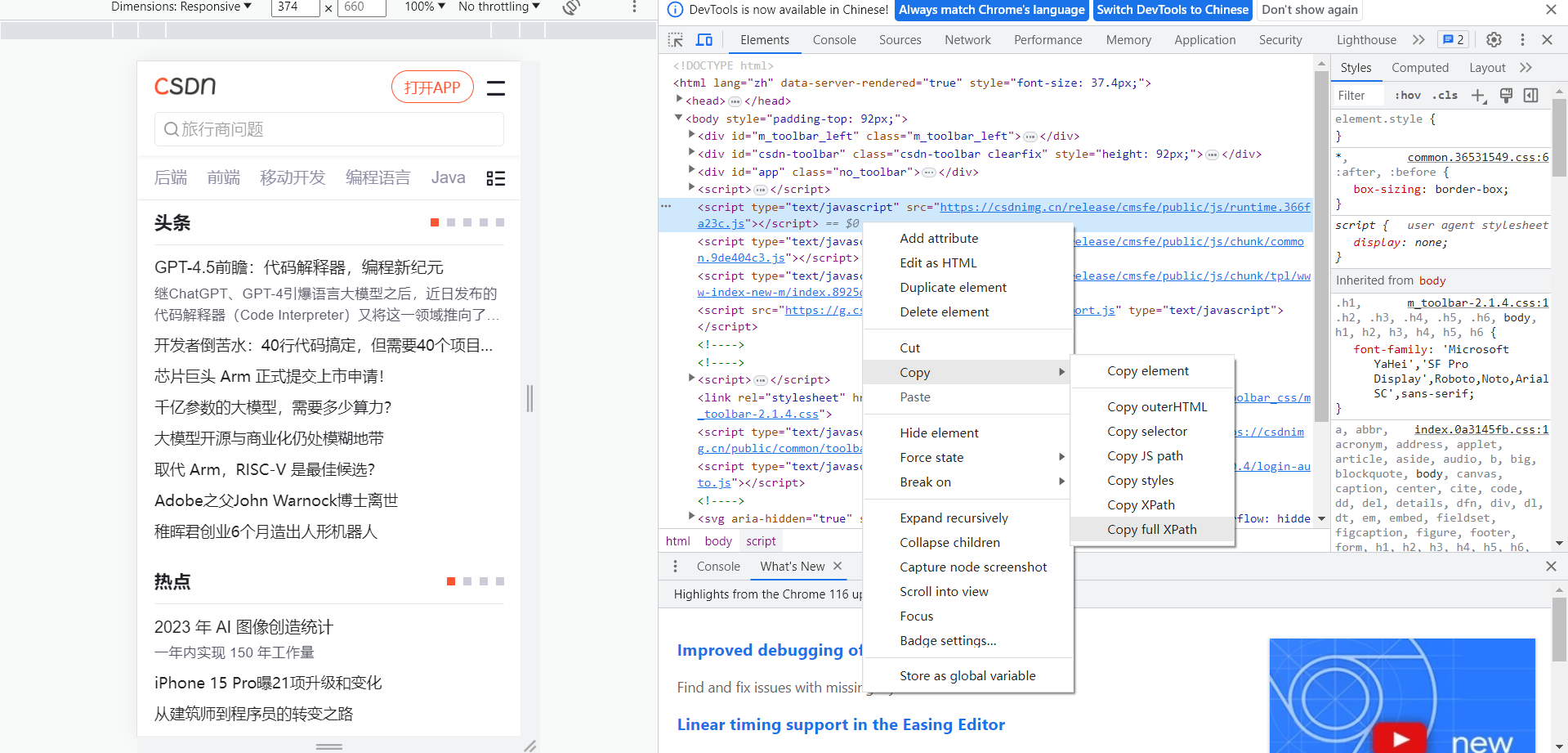
def F_gettitle(link_0):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_0,headers=head_qb)test_yuan=test_1.textdom=etree.HTML(test_yuan)test_2=dom.xpath('/html/body/article[1]/div[2]/div[2]/h1/text()')return test_2[0]很简单的一个的结构
由requests来获取源代码
之后用lxml中的tree来筛选源代码
(用xpath路径时最后要加text()输出文本形式,不然出不了源代码)
xpath路径可以通过按f12控制台来提取
获取文章的源代码
应该很好理解,就直接写代码了
def F_getyuan(link_1):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_1,headers=head_qb)test_yuan=test_1.texttest_yuan=str(test_yuan)return test_yuan提取文章目录的各个文章的链接
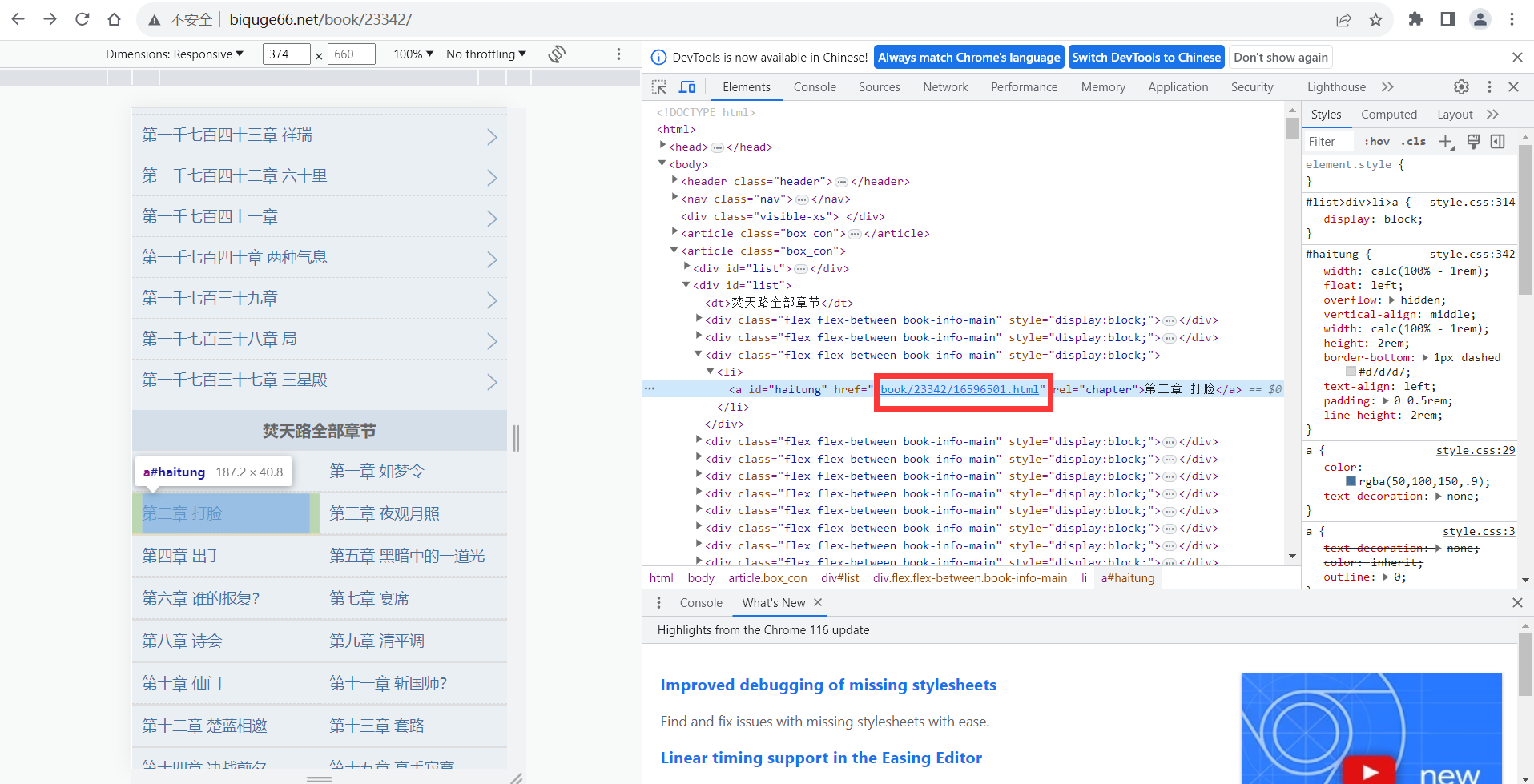
def F_searchlink(link_2):re_1='<a id="haitung" href="(.*?)" rel="chapter">'re_1=re.compile(re_1)link_3=re.findall(re_1,link_2)link_max=np.array([])for link_1 in link_3:link_4=f'http://www.biquge66.net{link_1}'link_max=np.append(link_max,link_4)return link_max这里我直接用re库的正则来进行匹配了匹配的链接
注意由于匹配的链接不是完整链接
所以还需要进行拼接
拼接完成后便可以直接打开
在这里我先存储到数组中方便之后爬取各个文章的源代码
然后进行返回
总代码
main.py
import sys
# PyQt5中使用的基本控件都在PyQt5.QtWidgets模块中
from PyQt5.QtWidgets import QApplication, QMainWindow
# 导入designer工具生成的login模块
from win import Ui_MainWindow
from test_1 import *
import time
class MyMainForm(QMainWindow, Ui_MainWindow):def __init__(self, parent=None):super(MyMainForm, self).__init__(parent)self.setupUi(self)self.Button_close.clicked.connect(self.close)self.Button_run.clicked.connect(self.F_run)def F_run(self):link_1=self.line_link.text()title_1=F_gettitle(link_1)self.text_result.setText(f"标题获取成功——{title_1}")# file_1=open(f'{title_1}.txt',mode='w',encoding='utf-8 ')test_1=F_getyuan(link_1)self.text_result.append("提取源代码成功")time.sleep(1)search_1=F_searchlink(test_1)self.text_result.append("提取文章链接成功")pachong(search_1,title_1)if __name__ == "__main__":# 固定的,PyQt5程序都需要QApplication对象。sys.argv是命令行参数列表,确保程序可以双击运行app = QApplication(sys.argv)# 初始化myWin = MyMainForm()# 将窗口控件显示在屏幕上myWin.show()# 程序运行,sys.exit方法确保程序完整退出。sys.exit(app.exec_())test_1.py
import requests
import re
import numpy as np
from lxml import etree
#获取文章标题
def F_gettitle(link_0):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_0,headers=head_qb)test_yuan=test_1.textdom=etree.HTML(test_yuan)test_2=dom.xpath('/html/body/article[1]/div[2]/div[2]/h1/text()')return test_2[0]#提取源代码
def F_getyuan(link_1):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_1,headers=head_qb)test_yuan=test_1.texttest_yuan=str(test_yuan)return test_yuan#查询所有小说章节链接
def F_searchlink(link_2):re_1='<a id="haitung" href="(.*?)" rel="chapter">'re_1=re.compile(re_1)link_3=re.findall(re_1,link_2)link_max=np.array([])for link_1 in link_3:link_4=f'http://www.biquge66.net{link_1}'link_max=np.append(link_max,link_4)return link_max# #输出文章内容
# def F_edittxt(link_3):
# head_qb={
# 'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
# }
# trytimes = 3
# for i in range(trytimes):
# try:
# proxies = None
# test_1=requests.get(url=link_3,headers=head_qb, verify=False, proxies=None, timeout=3)
# if test_1.status_code == 200:
# break
# except:
# print(f'requests failed {i} time')
# #提取文章链接
# re_2='<p>(.*?)</p>'
# re_2=re.compile(re_2)
# #提取文章标题
# re_3='<h1 class="bookname">(.*?)</h1>'
# re.compile(re_3)
# test_2=np.array([])
# test_3=np.array([])
# test_2=re.findall(re_2,test_1.text)
# test_3 = re.findall(re_3, test_1.text)
# #放在数组的最后一个
# test_2=np.append(test_3,test_2)
# return test_2下一章内容
最后获取了所有的章节链接了,接下来就要爬取文章了
本来可以一起写的(可以看到我test_1.py中注释掉的部分),但是后面发现出了一些问题
才有了下一章内容
下一章会详细说明的
相关文章:
用python从零开始做一个最简单的小说爬虫带GUI界面(2/3)
目录 前一章博客 前言 主函数的代码实现 逐行代码解析 获取链接 获取标题 获取网页源代码 获取各个文章的链接 函数的代码 导入库文件 获取文章的标题 获取文章的源代码 提取文章目录的各个文章的链接 总代码 下一章内容 前一章博客 用python从零开始做一个最简单…...

CEF 缓存处理:清理缓存、禁用缓存、忽略缓存
目录 一、CEF缓存处理 1、指定缓存路径 2、清理缓存 3、禁用缓存 1)、原理分析...
Android 系统桌面 App —— Launcher 开发(1)
Android 系统桌面 App —— Launcher 开发(1) Launcher简介 Launcher就是Android系统的桌面,俗称“HomeScreen”也就是我们开机后看到的第一个App。launcher其实就是一个app,它的作用是显示和管理手机上其他App。目前市场上有很…...
一个程序员的工作日记--每天就干两件事,一年后让别人刮目相看
文章目录 成功源于专注一、早上布局二、晚上复盘三、技术细节四、专注与成功五、专注的重要性六、忙碌和赚钱七、结论以嵌入式开发为例:一、早上布局二、晚上复盘三、技术细节四、专注与成功五、忙碌和赚钱六、结论在嵌入式软件开发中,我们需要按照以下步…...

Linux虚拟机安装(Ubuntu 20)
最近这段时间使用VMWare安装了一下Ubuntu版本的Linux虚拟机,在这里记录一下安装时参考的文章以及需要注意的细节 参考链接: VMware虚拟机下安装Ubuntu20.04(保姆级教程) 一、安装VMWare 下载链接:VMware Workstatio…...

1.6 服务器处理客户端请求
客户端进程向服务器进程发送一段文本(MySQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果)。 从图中我们可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别…...

火山引擎发布自研视频编解码芯片 压缩效率提升30%
8月22日,火山引擎视频云宣布其自研的视频编解码芯片已成功出片。经验证,该芯片的视频压缩效率相比行业主流硬件编码器可提升30%以上,未来将服务于抖音、西瓜视频等视频业务,并将通过火山引擎视频云开放给企业客户。 火山引擎总裁…...
从头开始:将新项目上传至Git仓库的简易指南
无论您是一个经验丰富的开发者还是一个刚刚起步的新手,使用Git来管理您的项目是一个明智的选择。Git是一个强大的版本控制系统,它可以帮助您跟踪项目的变化、合并代码以及与团队成员协作。在本文中,我们将为您提供一步步的指南,教…...

数据库的增量备份与差异备份
在当今数字时代,数据已经成为公司的主要资产。为了维护这些珍贵的数据,公司通常会采取各种数据保护措施,其中增量备份是一种很有效的方法。本文将详细介绍什么是数据库的增量备份,以及如何帮助企业更有效地维护数据。 我们需要…...

视频云存储/安防监控视频智能分析网关V3:占道经营功能详解
违规占道经营者经常会在人流量大、车辆集中的道路两旁摆摊,导致公路交通堵塞,给居民出行的造成不便,而且违规占路密集的地方都是交通事故频频发生的区域。 TSINGSEE青犀视频云存储/安防监控视频/AI智能分析网关V3运用视频AI智能分析技术&…...

卡尔曼滤波学习笔记
Kalman Filter Ⅰ、直观理解1、描述2、例子 Ⅱ、适用范围1、线性系统2、噪声服从高斯分布 Ⅲ、相关公式1、原始公式2、预测公式3、更新公式4、初值赋予5、总结 Ⅳ、应用例子Ⅴ、代码实现Ⅵ、公式理解1、协方差矩阵的理解1.1 协方差1.2 协方差矩阵1.3、相关数学公式 2、状态方程…...

NLP预训练模型超大规模探索
总共从四方面来进行比较。 第一个方面,高层次方法(自监督的预训练方法)对比,总共三种方式。 语言模型式,就是 GPT-2 那种方式,从左到右预测;BERT-style 式,就是像 BERT 一样将一部…...
)
OpenCV实战系列总目录(更新中)
1、openCV实战-系列教程1:基本操作(环境配置/图像读取打印/视频读取打印/图像裁剪/颜色通道提取/边界填充/数值计算)、源码解读 openCV实战-系列教程1:基本操作(环境配置/图像读取打印/视频读取打印/图像裁剪/颜色通道…...
《华为认证》6to4自动隧道
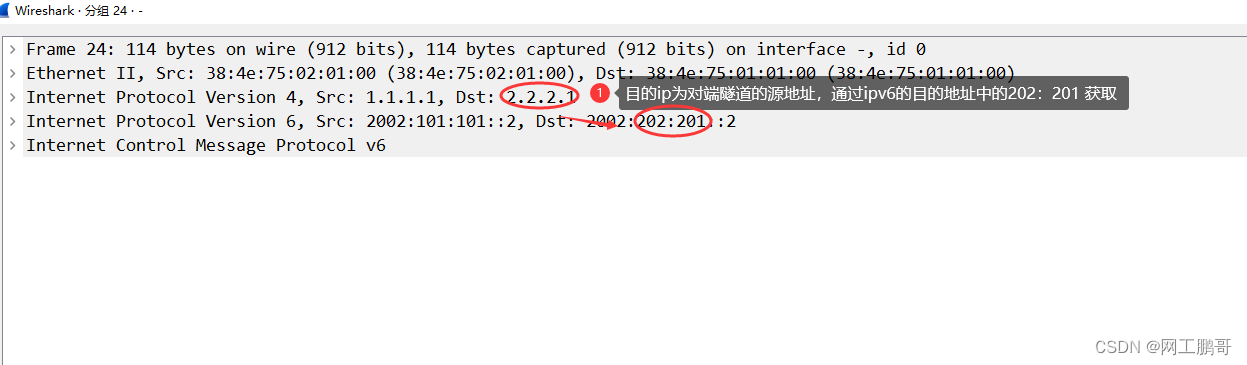
实验需求: 在NE1和NE3之间使用tunnel 口创建6to4自动隧道,实现PC1和PC2互访。 步骤1:配置ipv4地址,如图所示: 步骤2:配置NE1和NE3的ipv4路由,是两端的ipv4网络能够互访 R1: ip route-static 0.0.0.0 0…...
Java课题笔记~Element UI
Element:是饿了么公司前端开发团队提供的一套基于 Vue 的网站组件库,用于快速构建网页。 Element 提供了很多组件(组成网页的部件)供我们使用。例如 超链接、按钮、图片、表格等等~ 如下图左边的是我们编写页面看到的按钮&#…...
[论文笔记]ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE
引言 这是论文ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE的阅读笔记。本篇论文提出了通过Pre-LN的方式可以省掉Warm-up环节,并且可以加快Transformer的训练速度。 通常训练Transformer需要一个仔细设计的学习率warm-up(预热)阶段:在训练开始阶段学习率需要设…...

h5逻辑_调用手机拨号功能
有时点击页面某个按钮,希望能掉起手机拨号页,实现步骤如下: [1] 在index.html中添加如下代码<meta name"format-detection" content"telephoneyes" />[2] 点击按钮调用函数callPhone (phoneNumber) {window.locat…...
字节一面:post为什么会发送两次请求?
前言 最近博主在字节面试中遇到这样一个面试题,这个问题也是前端面试的高频问题,因为在前端开发的日常开发中我们总是会与post请求打交道,一个小小的post请求也是牵扯到很多知识点的,博主在这给大家细细道来。 🚀 作者…...
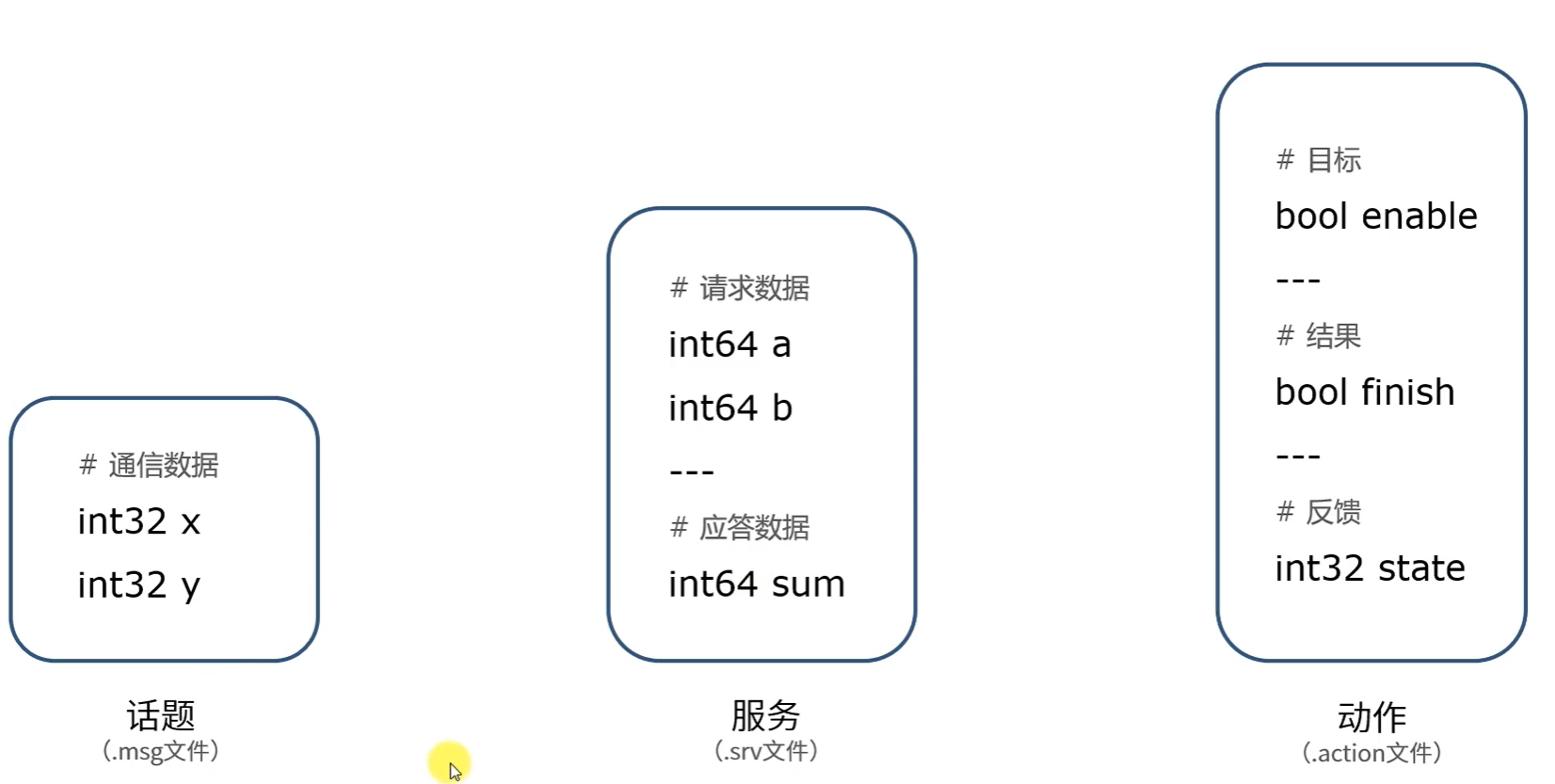
ROS2 学习(五)接口,动作
接口 通信双方统一规定好接口。比如图像 img,控制运动的线速度和角速度…… 我们也不用了解具体实现,基本就是了解接口会去用就行。 $ ros2 interface list # 展示所有 interfaces $ ros2 interface show ... # 显示具体一个 interface $ ros2 package…...
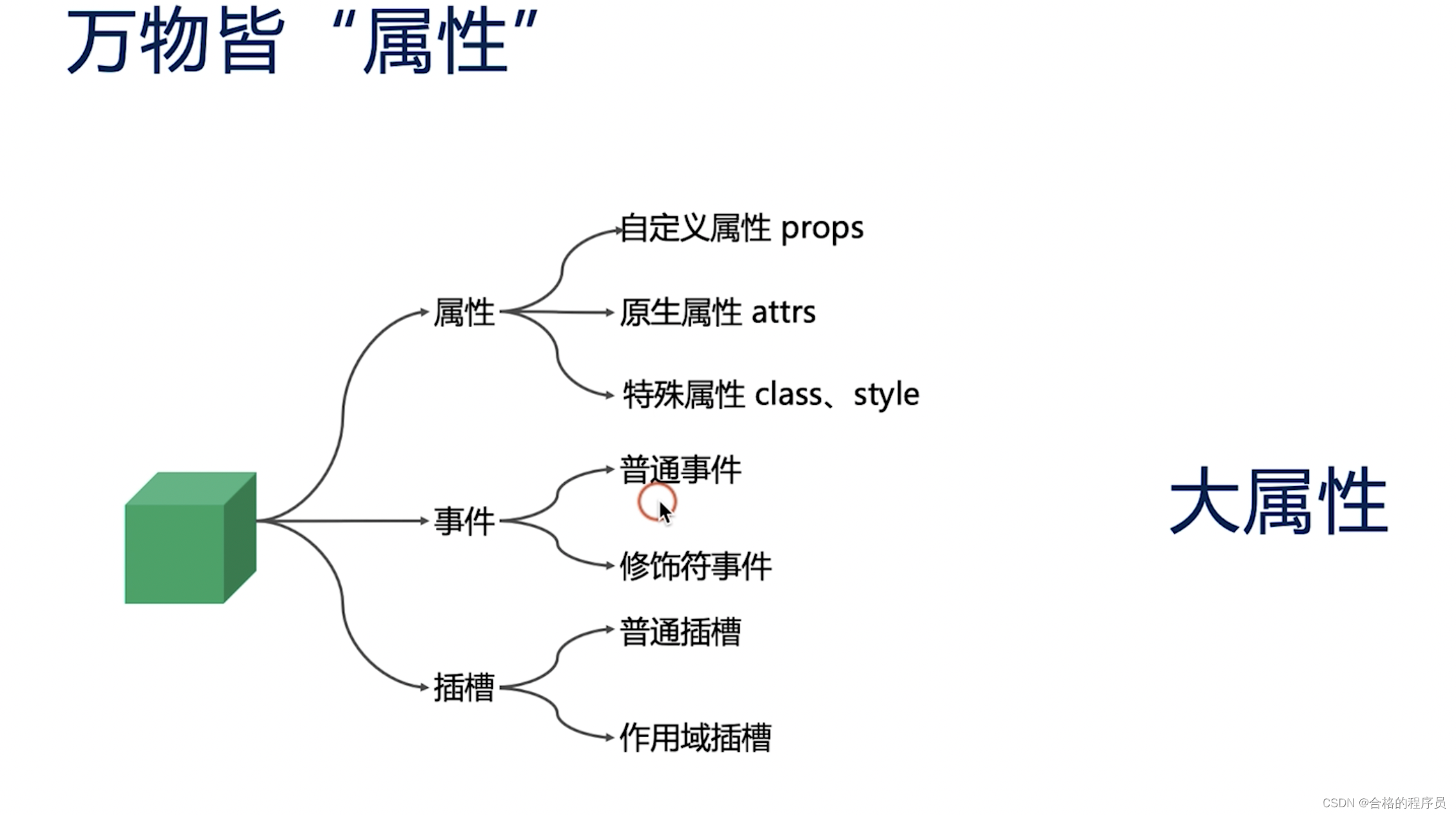
Vue学习之Vue组件的核心概念
组件是什么 vue组件就是一个个独立的小型的ui模块,整个大型的系统就是由一个个小型的UI模块拼接而成的 vue组件就是vue实例,通过new Vue函数来创建的一个vue实例,不同的组件只不过是options的不同,我们基本百分之90的开发工作都…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

NanaZip:现代Windows文件压缩问题的终极解决方案
NanaZip:现代Windows文件压缩问题的终极解决方案 【免费下载链接】NanaZip The 7-Zip derivative intended for the modern Windows experience 项目地址: https://gitcode.com/gh_mirrors/na/NanaZip 还在为Windows文件压缩工具界面老旧、功能单一而烦恼吗&…...