机器学习基础13-基于集成算法优化模型(基于印第安糖尿病 Pima Indians数据集)
有时提升一个模型的准确度很困难。如果你曾纠结于类似的问题,那
我相信你会同意我的看法。你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善。这时你会觉得无助和困顿,这也是
90%的数据科学家开始放弃的时候。不过,这才是考验真本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在。
前面介绍了一系列算法,每种算法都有不同的适用范围。在现实生活中,常常采用集体智慧来解决问题。那么在机器学习中,能否将多种机器学习算法组合在一起,使计算出来的结果更好呢?这就是集成算法的思想。
集成算法是提高算法准确度的有效方法之一,本节就介绍如何通过scikit-learn来实现集成算法。
本节将会介绍以下几种算法:
- 装袋(Bagging)算法。
- 提升(Boosting)算法。
- 投票(Voting)算法。
集成的方法
下面是三种流行的集成算法的方法。
- 装袋(Bagging)算法:先将训练集分离成多个子集,然后通过各个子集训练多个模型。
- 提升(Boosting)算法:训练多个模型并组成一个序列,序列中的每一个模型都会修正前一个模型的错误。
- 投票(Voting)算法:训练多个模型,并采用样本统计来提高模型的准确度。
在这里采用Pima Indians数据集,并用10折交叉验证来分离数据,再通过相应的评估矩阵来评估算法模型。
装袋算法是一种提高分类准确率的算法,通过给定组合投票的方式获得最优解。比如你生病了,去n个医院看了n个医生,每个医生都给你开了药方,最后哪个药方的出现次数多,就说明这个药方越有可能是最优解,这很好理解,这也是装袋算法的思想。
下面将介绍三种装袋模型:
- 装袋决策树(Bagged Decision Trees)。
- 随机森林(Random Forest)。
- 极端随机树(Extra Trees)。
装袋决策树
装袋算法在数据具有很大的方差时非常有效,最常见的例子就是决策树的装袋算法。下面将在scikit-learn中通过BaggingClassifier实现分类与回归树算法。
本例中创建了100棵决策树,代码如下:
import pandas as pd
from sklearn.ensemble import BaggingClassifierfrom sklearn.model_selection import cross_val_score, KFold
from sklearn.tree import DecisionTreeClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7
kflod =KFold(n_splits=num_folds, random_state=seed, shuffle=True)
#决策树
cart = DecisionTreeClassifier()num_trees = 100model = BaggingClassifier(base_estimator=cart, n_estimators=num_trees, random_state=seed)result = cross_val_score(model, X, Y, cv=kflod)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))
运行结果:
算法评估结果:0.758 (0.039)
与前几节的分类与回归树的结果(0.701708817498)比较,发现结果有了很大的提升。
随机森林
顾名思义,随机森林是用随机的方式建立一个森林,森林由很多的决策树组成,而且每一棵决策树之间是没有关联的。得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行判断,看看这个样本应该属于哪一类,再看看哪一类被选择最多,就预测这个样本为哪一类。
在建立每一棵决策树的过程中,有两点需要注意:采样与完全分裂。首先是两个随机采样的过程,随机森林对输入的数据要进行行、列的采样。对于行采样采用有放回的方式,也就是在采样得到的样本集合中可能有重复的样本。
假设输入样本为N个,那么采样的样本也为 N 个。这样在训练的时候,每一棵树的输入样本都不是全部的样本,就相对不容易出现过拟合。然后进行列采样,从M个feature中选出m个(m<<M)。之后再对采样之后的数据使用完全分裂的方式建立决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么所有样本都指向同一个分类。一般很多的决策树算法都有一个重要的步骤——剪枝,但是这里不这么做,因为之前的两个随机采样过程保证了随机性,所以不剪枝也不会出现过拟合。
这种算法得到的随机森林中的每一棵决策树都是很弱的,但是将它们组合起来就会很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通某一个领域的专家,这样在随机森林中就有了很多个精通不同领域的专家,对于一个新的问题(新的输入数据),可以从不同的角度去看待它,最终由各个专家投票得到结果。
这种算法在scikit-learn中的实现类是RandomForestClassifier。下面的例子是实现了100棵树的随机森林。
代码如下:
import pandas as pd
from sklearn.ensemble import BaggingClassifier, RandomForestClassifierfrom sklearn.model_selection import cross_val_score, KFold#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7
#
kflod =KFold(n_splits=num_folds, random_state=seed, shuffle=True)num_tree = 100max_features = 3model = RandomForestClassifier(n_estimators=num_tree, max_features=max_features)result = cross_val_score(model, X, Y, cv=kflod)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))
算法评估结果:0.777 (0.059)
极端随机树
极端随机树是由PierreGeurts等人于2006年提出的,它与随机森林十分相似,都是由许多决策树构成。
但它与随机森林有两个主要的区别:
(1)随机森林应用的是 Bagging 模型,而极端随机树是使用所有的训练样本得到每棵决策树,也就是每棵决策树应用的是相同的全部训练样本。
(2)随机森林是在一个随机子集内得到最优分叉特征属性,而极端随机树是完全随机地选择分叉特征属性,从而实现对决策树进行分叉的。它在scikit-learn中的实现类是ExtraTreesClassifier。下面的例子是实现了100棵树和7个随机特征的极端随机树。
代码如下:
import pandas as pd
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, ExtraTreesClassifierfrom sklearn.model_selection import cross_val_score, KFold#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7
#
kflod =KFold(n_splits=num_folds, random_state=seed, shuffle=True)num_tree = 100max_features = 7model = ExtraTreesClassifier(n_estimators=num_tree, max_features=max_features)result = cross_val_score(model, X, Y, cv=kflod)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))
运行结果:
算法评估结果:0.764 (0.056)
提升算法
提升算法是一种用来提高弱分类算法准确度的方法,这种方法先构造一个预测函数系列,然后以一定的方式将它们组合成一个预测函数。提升算法也是一种提高任意给定学习算法准确度的方法,它是一种集成算法,主要通过对样本集的操作获得样本子集,然后用弱分类算法在样本子集上训练生成一系列的基分类器。
它可以用来提高其他弱分类算法的识别率,也就是将其他的弱分类算法作为基分类算法放于提升框架中,通过提升框架对训练样本集的操作,得到不同的训练样本子集,再用该样本子集去训练生成基分类器。每得到一个样本集就用该基分类算法在该样本集上产生一个基分类器,这样在给定训练轮数n后,就可产生n个基分类器,然后提升算法将这n个基分类器进行加权融合,产生最后的结果分类器。在这n个基分类器中,每个分类器的识别率不一定很高,但它们联合后的结果有很高的识别率,这样便提高了弱分类算法的识别率。下面是两个非常常见的用于机器学习的提升算法:
- AdaBoost.
- 随机梯度提升(Stochastic Gradient Boosting)。
AdaBoost
AdaBoost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。它将修改过权值的新数据集送给下层分类器进行训练,再将每次训练得到的分类器融合起来,作为最后的决策分类器。使用AdaBoost分类器可以排除一些不必要的训练数据特征,并放在关键的训练数据上面。
在scikit-learn中的实现类是AdaBoostClassifier。
代码如下:
import pandas as pd
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, ExtraTreesClassifier, AdaBoostClassifierfrom sklearn.model_selection import cross_val_score, KFold#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7
#
kflod =KFold(n_splits=num_folds, random_state=seed, shuffle=True)num_tree = 30model = AdaBoostClassifier(n_estimators=num_tree, random_state=seed)result = cross_val_score(model, X, Y, cv=kflod)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.755 (0.037)
随机梯度提升
随机梯度提升法(GBM)基于的思想是:要找到某个函数的最大值,最好的办法就是沿着该函数的梯度方向探寻。梯度算子总是指向函数值增长最快的方向。由于梯度提升算法在每次更新数据集时都需要遍历整个数据集,计算复杂度较高,于是有了一个改进算法——随机梯度提升算法,该算法一次只用一个样本点来更新回归系数,极大地改善了算法的计算复杂度。
在 scikit-learn中的实现类是 GradientBoostingClassifier。
代码如下:
import pandas as pd
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, ExtraTreesClassifier, AdaBoostClassifier, \GradientBoostingClassifierfrom sklearn.model_selection import cross_val_score, KFold#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7
#
kflod =KFold(n_splits=num_folds, random_state=seed, shuffle=True)num_tree = 100model = GradientBoostingClassifier(n_estimators=num_tree, random_state=seed)result = cross_val_score(model, X, Y, cv=kflod)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.758 (0.056)
投票算法
投票算法(Voting)是一个非常简单的多个机器学习算法的集成算
法。投票算法是通过创建两个或多个算法模型,利用投票算法将这些算法包装起来,计算各个子模型的平均预测状况。在实际的应用中,可以对每个子模型的预测结果增加权重,以提高算法的准确度。但是,在scikit-learn中不提供加权算法。下面通过一个例子来展示在scikit-learn中如何实现一个投票算法。
在scikit-learn中的实现类是VotingClassifier。
代码如下:
import pandas as pd
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, ExtraTreesClassifier, AdaBoostClassifier, \GradientBoostingClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import cross_val_score, KFold
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier#数据预处理
path = 'D:\down\\archive\\diabetes.csv'
data = pd.read_csv(path)#将数据转成数组
array = data.values
#分割数据,去掉最后一个标签
X = array[:, 0:8]Y = array[:, 8]num_folds = 10
seed = 7
#
kflod =KFold(n_splits=num_folds, random_state=seed, shuffle=True)cart = DecisionTreeClassifier()models= []model_logistic = LogisticRegression()
models.append(('logistic', model_logistic))model_cart = DecisionTreeClassifier()
models.append(('cart', model_cart))model_svm = SVC()
models.append(('svm', model_svm))ensemble_model = VotingClassifier(estimators=models)result = cross_val_score(ensemble_model, X, Y, cv=kflod)print("算法评估结果:%.3f (%.3f)" % (result.mean(), result.std()))运行结果:
算法评估结果:0.767 (0.047)
本节介绍了三种提高算法准确度的集成算法,下一节将会介绍另外一种提升算法准确度的方法——算法调参。
相关文章:
)
机器学习基础13-基于集成算法优化模型(基于印第安糖尿病 Pima Indians数据集)
有时提升一个模型的准确度很困难。如果你曾纠结于类似的问题,那 我相信你会同意我的看法。你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善。这时你会觉得无助和困顿,这也是 90%的数据科学家开始放弃的时候。不过,这才是…...

Rancher部署k8s集群
Rancher部署 Rancher是一个开源的企业级容器管理平台。通过Rancher,企业再也不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用的管理Docker和Kubernetes的全栈化容器部署与管理平台。 首先所有节点部署docker 安装docker 安…...

前端油猴脚本开发小技巧笔记
调试模式下,单击选中某dom代码,控制台里可以用$0访问到该dom对象。 $0.__vue___ 可以访问到该dom对应的vue对象。 jquery 对象 a,a[0]是对应的原生dom对象,$(原生对象) 得到对应的 jquery 对象。 jquery 选择器,加空格是匹配下…...

软考高级系统架构设计师系列之:搭建论文写作的万能模版
软考高级系统架构设计师系列之:搭建论文写作的万能模版 一、选择合适的模版二、论文摘要模版1.论文摘要模版一2.论文摘要模版二3.论文摘要模版三4.论文摘要模版四三、项目背景四、正文写作五、论文结尾六、论文万能模版一、选择合适的模版 选择中、大型商业项目,一般金额在2…...

多线程常见面试题
常见的锁策略 这里讨论的锁策略,不仅仅局限于 Java 乐观锁 vs 悲观锁 锁冲突: 两个线程尝试获取一把锁,一个线程能获取成功,另一个线程阻塞等待。 乐观锁: 预该场景中,不太会出现锁冲突的情况。后续做的工作会更少。 悲观锁: 预测该场景,非常容易出现锁冲突。后…...

Java接收json参数
JSON 并不是唯一能够实现在互联网中传输数据的方式,除此之外还有一种 XML 格式。JSON 和 XML 能够执行许多相同的任务,那么我们为什么要使用 JSON,而不是 XML 呢? 之所以使用 JSON,最主要的原因是 JavaScript。众所周知…...

赤峰100吨每天医院污水处理设备产品特点
赤峰100吨每天医院污水处理设备产品特点 设备调试要求: 1、要清洗水池内所有的赃物、杂物。 2、对水泵及空压机等需要润滑部位进行加油滑。 3、通电源,启动水泵,检查转向是否与箭头所标方向一致。用水动控制启动空压机,检查空压机…...

nodejs+vue+elementui健身房教练预约管理系统nt5mp
运用新技术,构建了以vue.js为基础的私人健身和教练预约管理信息化管理体系。根据需求分析结果进行了系统的设计,并将其划分为管理员,教练和用户三种角色:主要功能包括首页,个人中心,用户管理,教…...
视频分割合并工具说明
使用说明书:视频分割合并工具 欢迎使用视频生成工具!本工具旨在帮助您将视频文件按照指定的规则分割并合并,以生成您所需的视频。 本程序还自带提高分辨率1920:1080,以及增加10db声音的功能 软件下载地址 https://github.com/c…...

2023java面试深入探析Nginx的处理流程
推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 史上最全文档AI绘画stablediffusion资料分享 「java、python面试题」来自UC网盘app分享,打开手…...
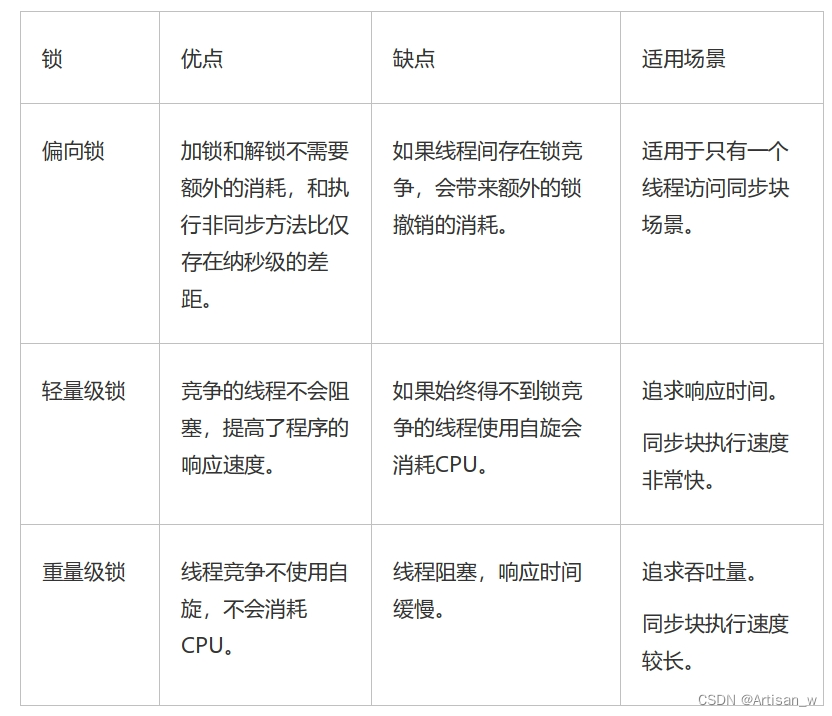
Java的锁大全
Java的锁 各种锁的类型 乐观锁 VS 悲观锁 乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度。在Java和数据库中都有此概念对应的实际应用。 先说概念。对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数…...

Leetcode80. 删除有序数组中的重复项 II
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。 不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。 class Solu…...
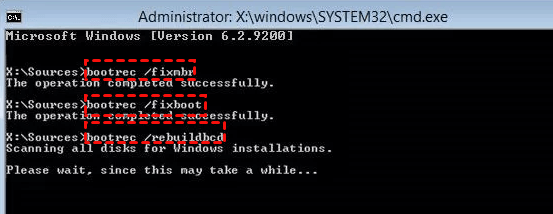
电脑显示“Operating System not found”该怎么办?
“Operating System not found”是一种常见的电脑错误提示,这类错误会导致你无法成功启动Windows。那么电脑显示“Operating System not found”该怎么办呢? 方法1. 检查硬盘 首先,您可以测试硬盘是否存在问题。为此,您可以采取以…...

简析SCTP开发指南
目录 前言一、SCTP基本概念二、SCTP开发步骤1. **环境配置**:2. **建立Socket**:3. **绑定和监听**:4. **接收和发送数据**:5. **关闭连接**: 三、 C语言实现SCTP3.1SCTP客户端代码:3.2 SCTP服务器端代码&a…...
把Android手机变成电脑摄像头
一、使用 DroidCam 使用 DroidCam,你可以将手机作为电脑摄像头和麦克风。一则省钱,二则可以在紧急情况下使用,比如要在电脑端参加一个紧急会议,但电脑却没有摄像头和麦克风。 DroidCam 的安卓端分为免费的 DroidCam 版和收费的 …...

Linux线程篇(中)
有了之前对线程的初步了解我们学习了什么是线程,线程的原理及其控制。这篇文章将继续讲解关于线程的内容以及重要的知识点。 线程的优缺点: 线程的缺点 在这里我们来谈一谈线程健壮性: 首先我们先思考一个问题,如果一个线程出现…...
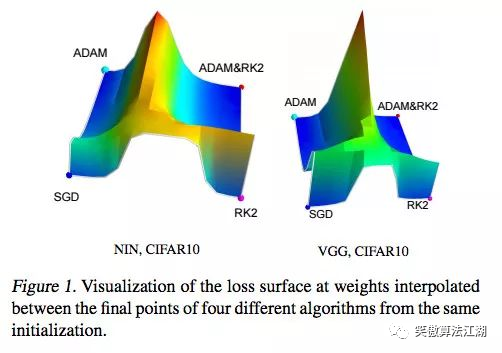
深度学习优化入门:Momentum、RMSProp 和 Adam
目录 深度学习优化入门:Momentum、RMSProp 和 Adam 病态曲率 1牛顿法 2 Momentum:动量 3Adam 深度学习优化入门:Momentum、RMSProp 和 Adam 本文,我们讨论一个困扰神经网络训练的问题,病态曲率。 虽然局部极小值和鞍点会阻碍…...

LeetCode 面试题 01.09. 字符串轮转
文章目录 一、题目二、C# 题解 一、题目 字符串轮转。给定两个字符串 s1 和 s2,请编写代码检查 s2 是否为 s1 旋转而成(比如,waterbottle 是 erbottlewat 旋转后的字符串)。 点击此处跳转题目。 示例1: 输入:s1 “wa…...

系统上线安全测评需要做哪些内容?
电力信息系统、航空航天、交通运输、银行金融、地图绘画、政府官网等系统再正式上线前需要做安全测试。避免造成数据泄露从而引起的各种严重问题。 那么系统上线前需要做哪些测试内容呢?下面由我给大家介绍 1、安全机制检测-应用安全 身份鉴别 登录控制模块 应提供…...
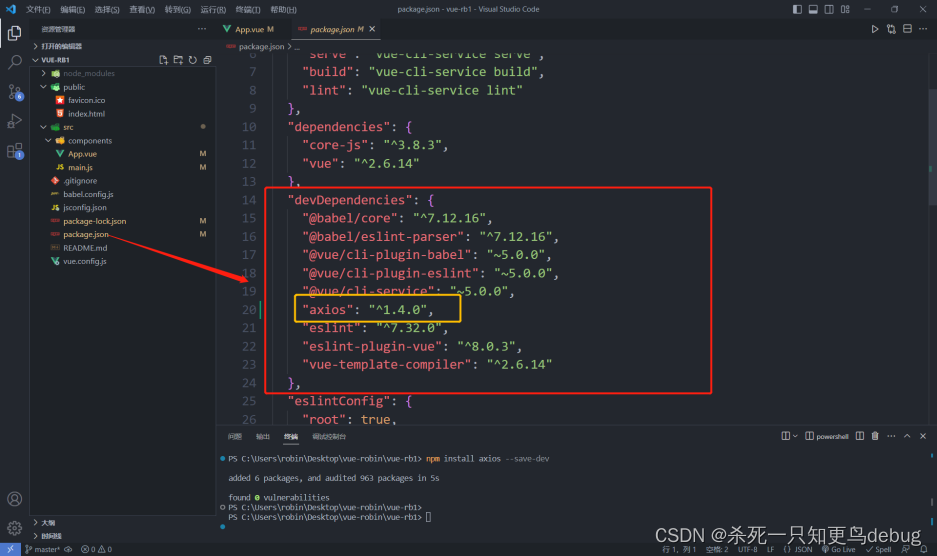
vue 中 axios 的安装及使用
vue 中 axios 的安装及使用 1. axios 安装2. axios使用 1. axios 安装 首先,打开当前的项目终端,输入 npm install axios --save-dev验证是否安装成功,检查项目根目录下的 package.json,其中的 devDependencies 里面会多出一个axios及其版本…...
)
告别网盘客户端!用Alist+RaiDrive把百度云盘变成电脑本地文件夹(保姆级图文教程)
用AlistRaiDrive实现网盘本地化管理的终极方案 你是否厌倦了电脑上安装多个网盘客户端,不仅占用系统资源,操作还繁琐割裂?每次上传下载文件都要在不同客户端间切换,效率低下。现在,通过Alist和RaiDrive的组合…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

微信小程序3D开发框架技术对比:XR-Frame与threejs-miniprogram
随着微信小程序逐步支持3D渲染与AR能力,开发者面临两个主要官方方案:自研的XR-Frame和适配Three.js的threejs-miniprogram。本文将从架构设计、渲染机制、功能集成、开发模式及适用场景等维度进行技术分析,为技术选型提供参考。一、XR-Frame&…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流
3步解锁专业级MMD创作:Blender插件如何重塑二次元动画工作流 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools …...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

Hindsight测试策略:单元测试、集成测试和端到端测试
Hindsight测试策略:单元测试、集成测试和端到端测试 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight作为一款专注于Agent Memory的开源项目,其可…...