GAN原理 代码解读
模型架构

代码
数据准备
import os
import time
import matplotlib.pyplot as plt
import numpy as np
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torch.nn as nn
import torch# 创建文件夹存放图片
os.makedirs("data", exist_ok=True)
transform = transforms.Compose([transforms.ToTensor(), #它会进行0-1归一化,h方向/h,w方向/w。 然后将图片格式转换为 (channel,h,w)transforms.Normalize(0.5,0.5),#把数据归一化为均值为0.5,方差为0.5,图像的数值范围变成-1到1
])
# 下载训练数据后对图片进行transform里的toTensor和用均值方差归一化
train_dataset = datasets.MNIST('data',train=True,transform=transform,download=True)
dataloader = torch.utils.data.DataLoader(train_dataset,batch_size=64,shuffle=True)
定义生成器
'''输入:正态分布随机数噪声(长度为100)输出:生成的图片,(1,28,28)中间过程:linear1: 100 -> 256linear2: 256 -> 512linear3: 512 -> 28*28reshape: 28x28 -> (1,28,28)
'''
class Generator(nn.Module):def __init__(self):super(Generator,self).__init__() # super().__init__() 是调用父类的__init__函数self.model = nn.Sequential(nn.Linear(100,256),nn.ReLU(),nn.Linear(256,512),nn.ReLU(),# 最后一层用tanh激活,将数据压缩到-1到1nn.Linear(512,28*28),nn.Tanh())def forward(self,x):img = self.model(x)img = img.view(-1,28,28,1) # 得到的是28*28=784,把它reshape为 (批量,h,w,channel)return img
定义判别器
'''判别器输入:(1,28,28)的图片输出:二分类的概率值 用sigmoid压缩到0-1之间内容:判别器 推荐使用LeakyRelu,因为生成器难以训练,Relu的负值直接变成0没有梯度了
'''
class Discriminator(nn.Module):def __init__(self):super(Discriminator,self).__init__()self.model = nn.Sequential(nn.Linear(28*28,512),nn.LeakyReLU(),nn.Linear(512,256),nn.LeakyReLU(),nn.Linear(256,1),nn.Sigmoid(),)def forward(self,x):x = x.view(-1,28*28)x = self.model(x)return x
初始化模型,优化器及损失计算函数
device = 'cuda' if torch.cuda.is_available() else 'cpu'
gen = Generator().to(device) # 初始化并放到了相应的设备上
dis = Discriminator().to(device)
dis_optim = torch.optim.Adam(dis.parameters(),lr=0.0001)
gen_optim = torch.optim.Adam(gen.parameters(),lr=0.0001)
bce_loss = torch.nn.BCELoss()
画生成器生成的图的绘图函数
def gen_img_plot(model,epoch,test_input):prediction = model(test_input).detach().cpu().numpy() # 放在内存上 并转换为Numpyprediction = np.squeeze(prediction) # np.squeeze是一个numpy函数,删除数组中形状为1的维度fig = plt.figure(figsize=(4,4))for i in range(16): # 迭代这n张图片plt.subplot(4,4,i+1)plt.imshow((prediction[i] + 1) / 2) # 生成器生成的图片是-1到1之间的,无法绘图。通过 (原+1)/2把[-1,1]压缩到[0,1]plt.axis('off')plt.show()
显示图片的函数
def img_plot(img):img = np.squeeze(img) # np.squeeze是一个numpy函数,删除数组中形状为1的维度fig = plt.figure(figsize=(4,4))for i in range(16): # 迭代这n张图片plt.subplot(4,4,i+1)plt.imshow((img[i] + 1) / 2) # 生成器生成的图片是-1到1之间的,无法绘图。通过 (原+1)/2把[-1,1]压缩到[0,1]plt.axis('off')plt.show()
定义训练函数
def train(num_epoch,test_input):D_loss = []G_loss = []# 训练循环for epoch in range(num_epoch):d_epoch_loss = 0g_epoch_loss = 0count = len(dataloader) # 返回批次数for step,(img,_) in enumerate(dataloader): # _是标签数据,img是(批次,h,w),每次取的img形状为(64,1,28,28)# print(f'step={step},img.shape={img.shape}')# img_plot(img)img = img.to(device)size = img.size(0) # 得到一个批次的图片random_noise = torch.randn(size,100,device=device) # 生成器的输入'''一. 训练判别器''''''用真实图片训练判别器'''dis_optim.zero_grad()real_output = dis(img) # 对判别取输入真实的图片,输出对真实图片的预测结果# 判别器在真实图像上的损失d_real_loss = bce_loss(real_output,# torch.ones_like(real_output) 创建一个根real_loss一样形状的全1数组,作为标签。torch.ones_like(real_output))d_real_loss.backward()'''用生成的图片训练判别器'''gen_img = gen(random_noise)# 因为此时是为了训练判别器,所以不能让生成器的梯度参与进来。所以用detach()取出无梯度的tensorfake_output = dis(gen_img.detach())d_fake_loss = bce_loss(fake_output,torch.zeros_like(fake_output))d_fake_loss.backward()d_loss = d_real_loss+d_fake_lossdis_optim.step() # 对参数进行优化'''二.训练生成器'''gen_optim.zero_grad()# 刚才是去掉生成器生成的图片的梯度,来训练判别器。此处不需要去掉梯度。让判别器进行判别fake_output = dis(gen_img)# 思想:目的是生成越来越逼真的图片瞒过判别器,让判别器判定生成的图片是真实的图片。# 实现方法:把判别器的结果输入到bce_loss,用1作为标签,看判别器把生成的图片判别为真的损失。g_loss = bce_loss(fake_output,torch.ones_like(fake_output))g_loss.backward()gen_optim.step()# 计算一个epoch的损失with torch.no_grad(): # 禁止梯度计算和参数更新d_epoch_loss +=d_lossg_epoch_loss +=g_loss# 计算整体loss每个epoch的平均Losswith torch.no_grad(): # 禁止梯度计算和参数更新d_epoch_loss /= countg_epoch_loss /= countD_loss.append(d_epoch_loss)G_loss.append(g_epoch_loss)print('Epoch:', epoch+1)print(f'd_epoch_loss={d_epoch_loss}')print(f'g_epoch_loss={g_epoch_loss}')# 将16个长度为100的噪音输入到生成器并画图gen_img_plot(gen,test_input)
开始训练
'''开始计时'''
start_time = time.time()'''开始训练'''
test_input = torch.randn(16,100,device=device) # 生成16个 长度为100的正太分布随机数。放到GPU中 作为输入
print(test_input)
num_epoch = 50
train(num_epoch,test_input)
# 保存训练50次的参数
torch.save(gen.state_dict(),'gen_weights.pth')
torch.save(dis.state_dict(),'dis_weights.pth')'''计时结束'''
end_time = time.time()
run_time = end_time - start_time
# 将输出的秒数保留两位小数
if int(run_time)<60:print(f'{round(run_time,2)}s')
else:print(f'{round(run_time/60,2)}minutes')
结果可视化

加载训练好的参数
gen.load_state_dict(torch.load('/opt/software/computer_vision/codes/My_codes/paper_codes/GAN/weights/gen_weights.pth'))
用训练好的生成器生成图片并画图
test_new_input = torch.randn(16,100,device=device) # 生成16个 长度为100的正太分布随机数。放到GPU中 作为输入
gen_img_plot(gen,test_new_input)

GAN的生成是随机的,不同的噪声,生成不同的数字
相关文章:
GAN原理 代码解读
模型架构 代码 数据准备 import os import time import matplotlib.pyplot as plt import numpy as np import torchvision.transforms as transforms from torch.utils.data import DataLoader from torchvision import datasets import torch.nn as nn import torch# 创建文…...
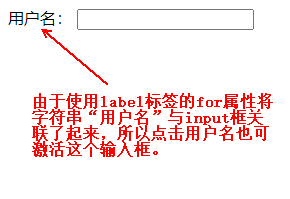
HTML的label标签有什么用?
当你想要将表单元素(如输入框、复选框、单选按钮等)与其描述文本关联起来,以便提供更好的用户界面和可访问性时,就可以使用HTML中的<label>标签。<label>标签用于为表单元素提供标签或标识,使用户能够更清…...
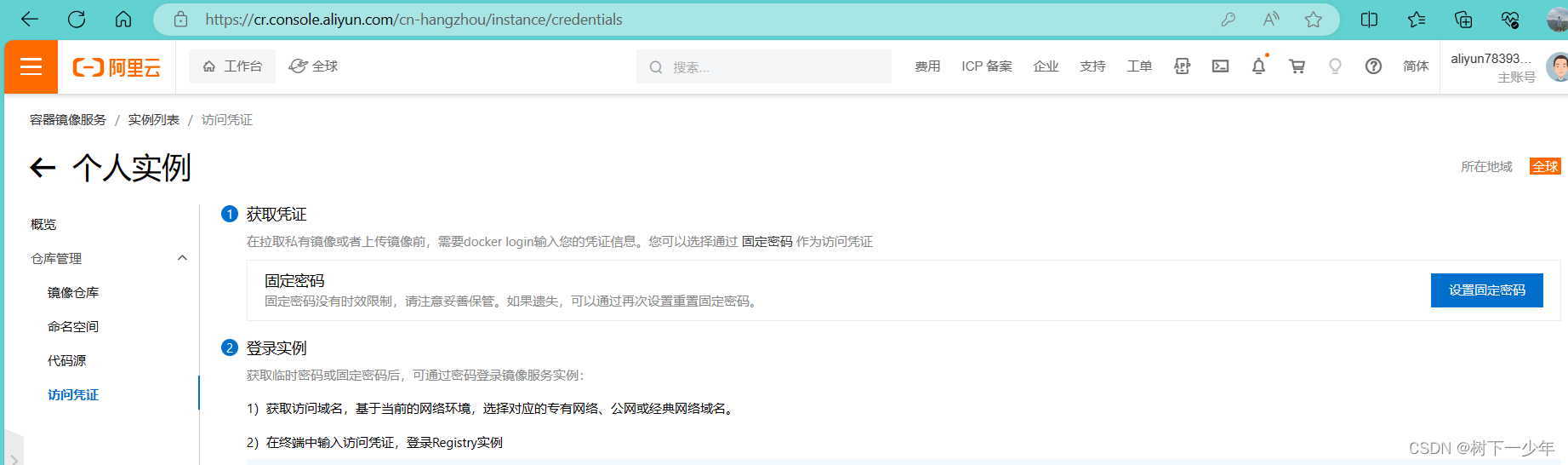
docker在阿里云上的镜像仓库管理
目录 一.登录进入阿里云网站,点击个人实例进行创建 二.创建仓库,填写相关信息 三.在访问凭证中设置固定密码用于登录,登录时用户名是使用你注册阿里云的账号名称,密码使用设置的固定密码 四.为镜像打标签并推送到仓库 五.拉取…...

html-dom核心内容--四要素
1、结构 HTML DOM (文档对象模型) 当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。 2、核心关注的内容:“元素”,“属性”,“修改样式”,“事件反应”。>四要素…...

golang的继承
golang中并没有继承以及oop,但是我们可以通过struct嵌套来完成这个操作。 定义struct 以下定义了一个Person结构体,这个结构体有Eat方法以及三个属性 type Person struct {Name stringAge uint16Phone string }func (recv *Person) Eat() {fmt.Prin…...

Google Play商店优化排名因素之应用截图与视频
屏幕截图是影响转化率的最重要的视觉效果之一。大多数人只需查看应用程序屏幕截图,就会决定是否尝试去下载我们的应用程序。 1、在Google Play商店中,搜索结果页面根据我们搜索的关键词有不同的样式。 展示应用程序中最好的部分,添加一些文字…...

fastadmin iis伪静态应用入口文件index.php
<?xml version"1.0" encoding"UTF-8"?> <configuration><system.webServer><rewrite><rules><rule name"OrgPage" stopProcessing"true"><match url"^(.*)$" /><conditions…...
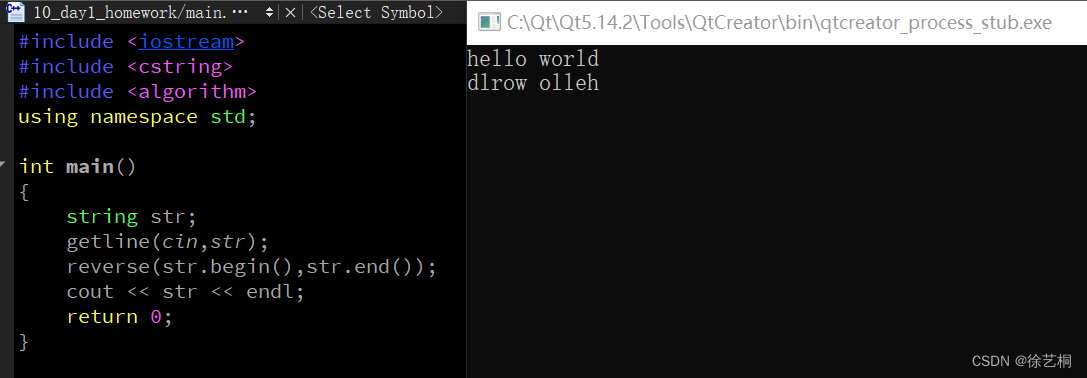
0821|C++day1 初步认识C++
一、思维导图 二、知识点回顾 【1】QT软件的使用 1)创建文件 创建文件时,文件的路径一定是全英文 2)修改编码 工具--->选项--->行为--->默认编码:system 【2】C和C的区别 C又叫C plus plus,C是对C的扩充&…...

Linux上实现分片压缩及解压分片zip压缩包 - 及zip、unzip命令详解
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支…...

概率论作业啊啊啊
1 数据位置 (Measures of location) 对于数据集: 7 , 9 , 9 , 10 , 10 , 11 , 11 , 12 , 12 , 12 , 13 , 14 , 14 , 15 , 16 7,9,9,10,10,11,11,12,12,12,13,14,14,15,16 7,9,9,10,10,11,11,12,12,12,13,14,14,15,16 计算加权平均数,其中权重为: 2 , 1 , 3 , 2 ,…...

React re-render
What is? react的渲染分为两个阶段: render,组件第一次出现在屏幕上的时候触发re-render, 组件第一次渲染之后的渲染 当app的数据更新时(用户手动更新、或异步请求)。 When? re-render发生有四种可能: state改变…...
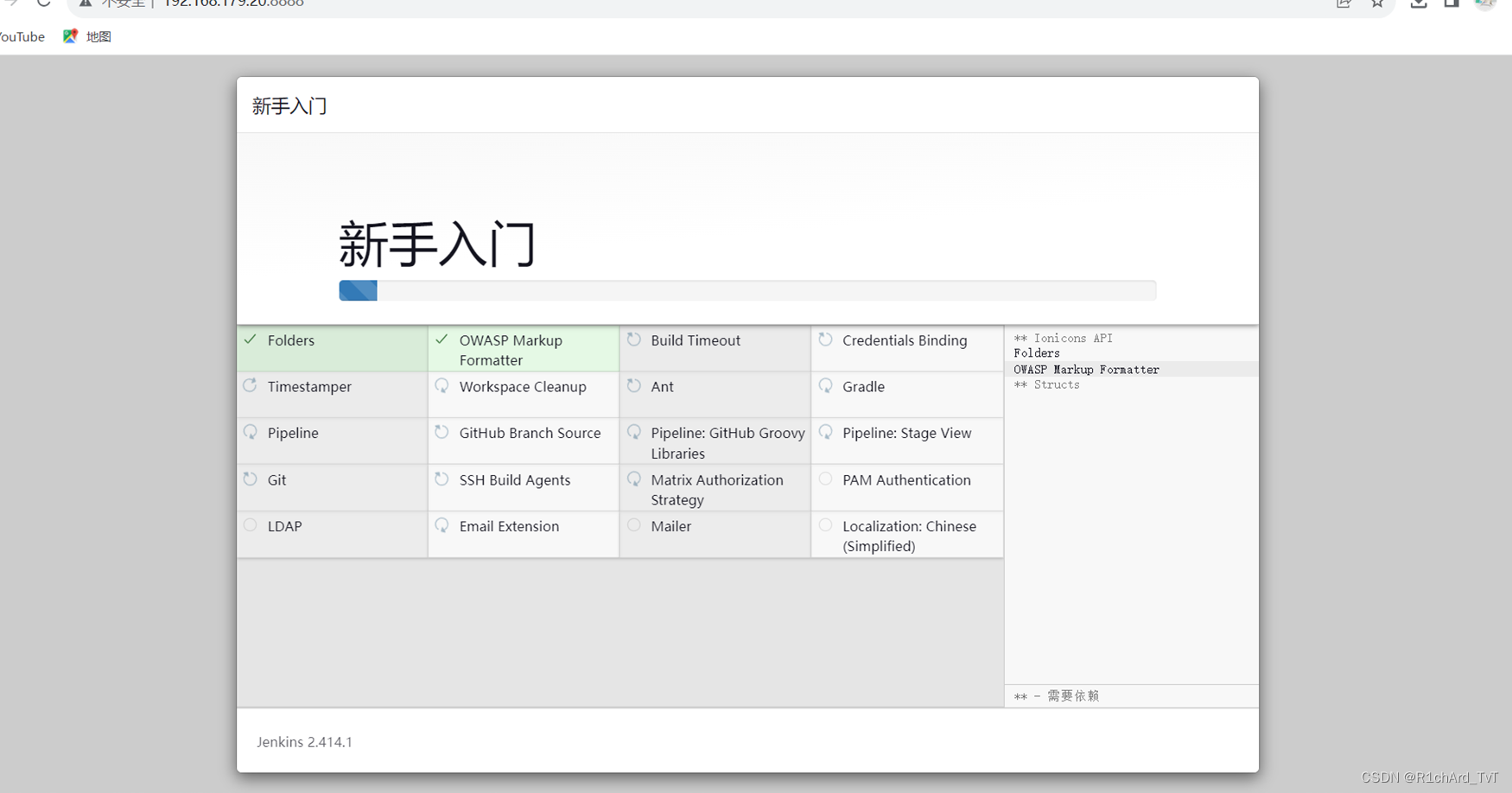
从零开始配置Jenkins与GitLab集成:一步步实现持续集成
在软件开发中,持续集成是确保高效协作和可靠交付的核心实践。以下是在CentOS上安装配置Jenkins与GitLab集成的详细步骤: 1.安装JDK 解压JDK安装包并设置环境变量: JDK下载网址 Java Downloads | Oracle 台灣 tar zxvf jdk-11.0.5_linux-x64_b…...
高效多用的群集-Haproxy搭建Web集群
Haproxy搭建 Web 群集 一、Haproxy前言 HAProxy是一个使用c语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TcP和HrrP的应用程序代理。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。…...

aws的s3匿名公开访问
点击桶权限 ,添加策略 {"Version": "2012-10-17","Statement": [{"Sid": "AddPerm","Effect": "Allow","Principal": "*","Action": "s3:GetObject&qu…...
2023科隆游戏展:虚幻5游戏百花齐放,云渲染助力虚幻5高速渲染
8月23日,欧洲权威级游戏展示会——科隆游戏展拉开帷幕。今年的参展游戏也相当给力,数十款游戏新预告片在展会上公布,其中有不少游戏使用虚幻5引擎制作,开创了游戏开发新纪元。 虚幻5游戏百花齐放,渲染堪比电影级效果 …...

Spark大数据分析与实战笔记(第一章 Scala语言基础-2)
文章目录 章节概要1.2 Scala的基础语法1.2.1 声明值和变量1.2.2 数据类型1.2.3 算术和操作符重载1.2.4 控制结构语句1.2.5 方法和函数 章节概要 Spark是专为大规模数据处理而设计的快速通用的计算引擎,它是由Scala语言开发实现的,关于大数据技术…...

Linux 下 Mysql 的使用(Ubuntu20.04)
文章目录 一、安装二、使用2.1 登录2.2 数据库操作2.2.1 创建数据库2.2.2 删除数据库2.2.3 创建数据表 参考文档 一、安装 Linux 下 Mysql 的安装非常简单,一个命令即可: sudo apt install mysql-server检查安装是否成功,输入: …...
牛客练习赛114
A.最后有0得数肯定是10得倍数,然后直接排序即可 #include<bits/stdc.h> using namespace std; const int N 1e610,mod1e97; int n; void solve(){cin>>n;vector<int> a(n);for(auto&i:a) cin>>i;sort(a.begin(),a.end(),greater<&g…...

Http与Https
1.简单介绍 HTTP:最广泛应用的网络通信协议,基于TCP,数据传输简单高效,数据是明文。 HTTPS:是HTTP的加强版,是HTTPSSL。在HTTP的基础上加了安全机制,一方面保证数据的安全传输,另一…...
前端通信(渲染、http、缓存、异步、跨域)自用笔记
SSR/CSR:HTML拼接?网页源码?SEO/交互性 SSR (server side render)服务端渲染,是指由服务侧(server side)完成页面的DOM结构拼接,然后发送到浏览器,为其绑定状…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...

微信小程序项目实战:从npm安装Vant Weapp到解决样式冲突的完整避坑指南
微信小程序工程化实战:Vant Weapp集成与样式冲突解决方案全解析 第一次在小程序里引入Vant Weapp时,我对着满屏错位的组件样式发呆了半小时——原本优雅的按钮变成了扭曲的色块,表单元素叠在一起像抽象画。这不是个例,根据社区反…...