copy is all you need前向绘图 和疑惑标记
疑惑的起因
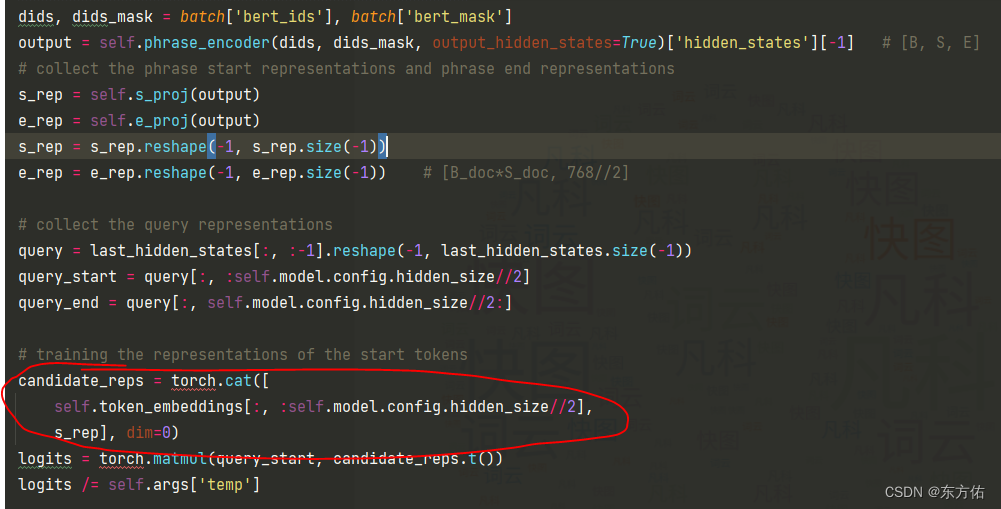
简化前向图
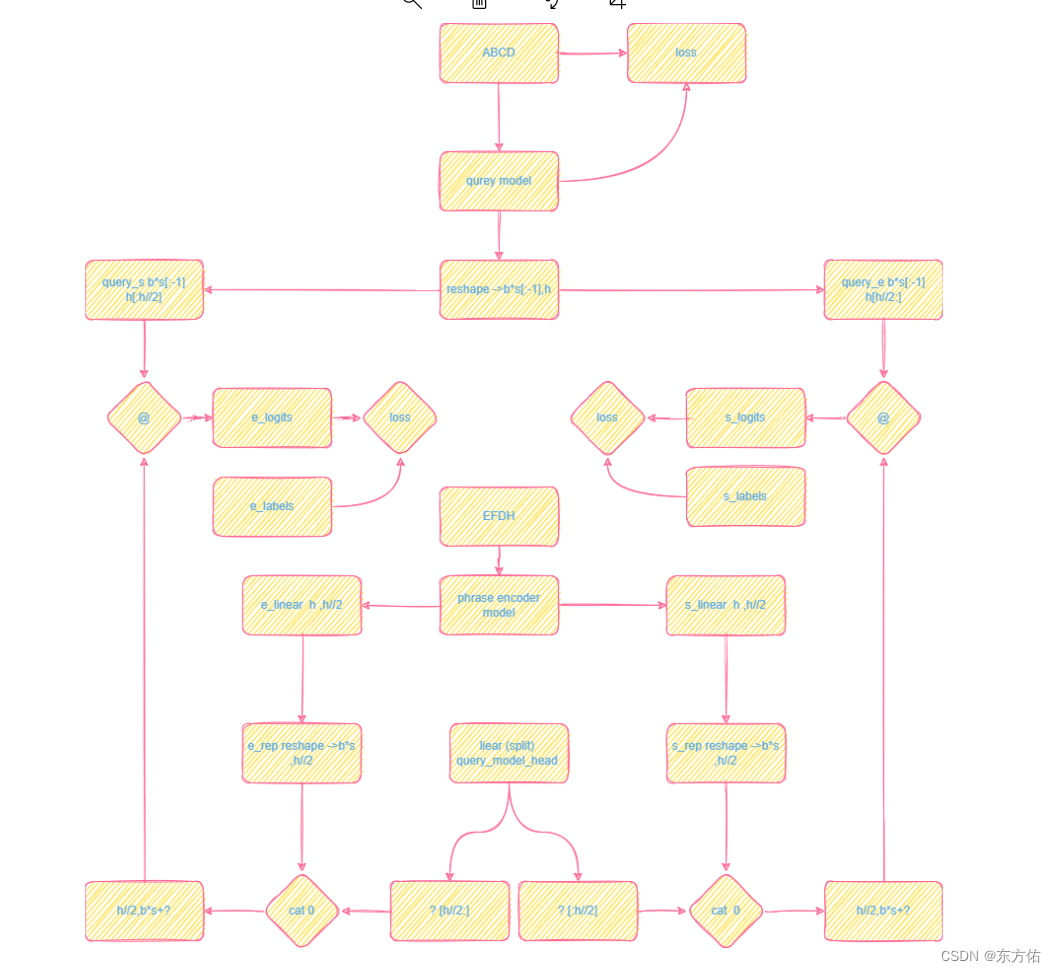
GPT4解释
这段代码实现了一个神经网络模型,包含了BERT、GPT-2和MLP等模块。主要功能是给定一个文本序列和一个查询序列,预测查询序列中的起始和结束位置,使其对应文本序列中的一个短语。具体实现细节如下:
首先,使用BERT将文本序列编码成一个张量作为输入,并从GPT-2模型中提取查询序列的表示。然后,将查询序列的表示拆分为起始和结束两部分,并使用MLP将短语的起始和结束点表示投影到另一个空间中。
接下来,利用生成式模型计算每个查询起始和结束位置之间的所有令牌的概率分布,并根据此生成预测位置。使用交叉熵损失函数来计算这些预测和真实值之间的差距。
最后,计算起始和结束位置的准确性和整个短语的准确性,并返回损失和准确性的值来优化模型的性能。
import torch
from transformers import AutoModel, AutoTokenizer, GPT2LMHeadModel
from torch import nn
from torch.nn import functional as Fclass Copyisallyouneed(nn.Module):def __init__(self, **args):super(Copyisallyouneed, self).__init__()self.args = args# bert-encoder modelself.phrase_encoder = AutoModel.from_pretrained(self.args['phrase_encoder_model'][self.args['lang']])self.bert_tokenizer = AutoTokenizer.from_pretrained(self.args['phrase_encoder_tokenizer'][self.args['lang']])self.bert_tokenizer.add_tokens(['<|endoftext|>', '[PREFIX]'])self.prefix_token_id = self.bert_tokenizer.convert_tokens_to_ids('[PREFIX]')self.phrase_encoder.resize_token_embeddings(self.phrase_encoder.config.vocab_size + 2)# model and tokenizerself.tokenizer = AutoTokenizer.from_pretrained(self.args['prefix_encoder_tokenizer'][self.args['lang']])self.vocab_size = len(self.tokenizer)self.pad = self.tokenizer.pad_token_id if self.args['lang'] == 'zh' else self.tokenizer.bos_token_idself.model = GPT2LMHeadModel.from_pretrained(self.args['prefix_encoder_model'][self.args['lang']])self.token_embeddings = nn.Parameter(list(self.model.lm_head.parameters())[0])# MLP: mapping bert phrase start representationsself.s_proj = nn.Sequential(nn.Dropout(p=args['dropout']),nn.Tanh(),nn.Linear(self.model.config.hidden_size, self.model.config.hidden_size // 2))# MLP: mapping bert phrase end representationsself.e_proj = nn.Sequential(nn.Dropout(p=args['dropout']),nn.Tanh(),nn.Linear(self.model.config.hidden_size, self.model.config.hidden_size // 2))self.gen_loss_fct = nn.CrossEntropyLoss(ignore_index=self.pad)@torch.no_grad()def get_query_rep(self, ids):self.eval()output = self.model(input_ids=ids, output_hidden_states=True)['hidden_states'][-1][:, -1, :]return outputdef get_token_loss(self, ids, hs, ids_mask):# no pad tokenlabel = ids[:, 1:]logits = torch.matmul(hs[:, :-1, :],self.token_embeddings.t())# TODO: inner loss function remove the temperature factorlogits /= self.args['temp']loss = self.gen_loss_fct(logits.view(-1, logits.size(-1)), label.reshape(-1))chosen_tokens = torch.max(logits, dim=-1)[1]gen_acc = (chosen_tokens.reshape(-1) == label.reshape(-1)).to(torch.long)valid_mask = (label != self.pad).reshape(-1)valid_tokens = gen_acc & valid_maskgen_acc = valid_tokens.sum().item() / valid_mask.sum().item()return loss, gen_accdef forward(self, batch):## gpt2 query encoderids, ids_mask = batch['gpt2_ids'], batch['gpt2_mask']last_hidden_states = \self.model(input_ids=ids, attention_mask=ids_mask, output_hidden_states=True).hidden_states[-1]# get token lossloss_0, acc_0 = self.get_token_loss(ids, last_hidden_states, ids_mask)## encode the document with the BERT encoder modeldids, dids_mask = batch['bert_ids'], batch['bert_mask']output = self.phrase_encoder(dids, dids_mask, output_hidden_states=True)['hidden_states'][-1] # [B, S, E]# collect the phrase start representations and phrase end representationss_rep = self.s_proj(output)e_rep = self.e_proj(output)s_rep = s_rep.reshape(-1, s_rep.size(-1))e_rep = e_rep.reshape(-1, e_rep.size(-1)) # [B_doc*S_doc, 768//2]# collect the query representationsquery = last_hidden_states[:, :-1].reshape(-1, last_hidden_states.size(-1))query_start = query[:, :self.model.config.hidden_size // 2]query_end = query[:, self.model.config.hidden_size // 2:]# training the representations of the start tokenscandidate_reps = torch.cat([self.token_embeddings[:, :self.model.config.hidden_size // 2],s_rep], dim=0)logits = torch.matmul(query_start, candidate_reps.t())logits /= self.args['temp']# build the padding mask for query sidequery_padding_mask = ids_mask[:, :-1].reshape(-1).to(torch.bool)# build the padding mask: 1 for valid and 0 for maskattention_mask = (dids_mask.reshape(1, -1).to(torch.bool)).to(torch.long)padding_mask = torch.ones_like(logits).to(torch.long)# Santiy check overpadding_mask[:, self.vocab_size:] = attention_mask# build the position mask: 1 for valid and 0 for maskpos_mask = batch['pos_mask']start_labels, end_labels = batch['start_labels'][:, 1:].reshape(-1), batch['end_labels'][:, 1:].reshape(-1)position_mask = torch.ones_like(logits).to(torch.long)query_pos = start_labels > self.vocab_size# ignore the padding maskposition_mask[query_pos, self.vocab_size:] = pos_maskassert padding_mask.shape == position_mask.shape# overall maskoverall_mask = padding_mask * position_mask## remove the position mask# overall_mask = padding_masknew_logits = torch.where(overall_mask.to(torch.bool), logits, torch.tensor(-1e4).to(torch.half).cuda())mask = torch.zeros_like(new_logits)mask[range(len(new_logits)), start_labels] = 1.loss_ = F.log_softmax(new_logits[query_padding_mask], dim=-1) * mask[query_padding_mask]loss_1 = (-loss_.sum(dim=-1)).mean()## split the token accuaracy and phrase accuracyphrase_indexes = start_labels > self.vocab_sizephrase_indexes_ = phrase_indexes & query_padding_maskphrase_start_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == start_labels[phrase_indexes_]phrase_start_acc = phrase_start_acc.to(torch.float).mean().item()phrase_indexes_ = ~phrase_indexes & query_padding_masktoken_start_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == start_labels[phrase_indexes_]token_start_acc = token_start_acc.to(torch.float).mean().item()# training the representations of the end tokenscandidate_reps = torch.cat([self.token_embeddings[:, self.model.config.hidden_size // 2:],e_rep], dim=0)logits = torch.matmul(query_end, candidate_reps.t()) # [Q, B*] logits /= self.args['temp']new_logits = torch.where(overall_mask.to(torch.bool), logits, torch.tensor(-1e4).to(torch.half).cuda())mask = torch.zeros_like(new_logits)mask[range(len(new_logits)), end_labels] = 1.loss_ = F.log_softmax(new_logits[query_padding_mask], dim=-1) * mask[query_padding_mask]loss_2 = (-loss_.sum(dim=-1)).mean()# split the phrase and token accuracyphrase_indexes = end_labels > self.vocab_sizephrase_indexes_ = phrase_indexes & query_padding_maskphrase_end_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == end_labels[phrase_indexes_]phrase_end_acc = phrase_end_acc.to(torch.float).mean().item()phrase_indexes_ = ~phrase_indexes & query_padding_masktoken_end_acc = new_logits[phrase_indexes_].max(dim=-1)[1] == end_labels[phrase_indexes_]token_end_acc = token_end_acc.to(torch.float).mean().item()return (loss_0, # token lossloss_1, # token-head lossloss_2, # token-tail lossacc_0, # token accuracyphrase_start_acc,phrase_end_acc,token_start_acc,token_end_acc)相关文章:
copy is all you need前向绘图 和疑惑标记
疑惑的起因 简化前向图 GPT4解释 这段代码实现了一个神经网络模型,包含了BERT、GPT-2和MLP等模块。主要功能是给定一个文本序列和一个查询序列,预测查询序列中的起始和结束位置,使其对应文本序列中的一个短语。具体实现细节如下:…...

【附安装包】Vred2023安装教程
软件下载 软件:Vred版本:2023语言:简体中文大小:2.39G安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.0GHz 内存4G(或更高)下载通道①百度网盘丨64位下载链接:https://pan.baidu.com…...

ASP.NET Core 中的 Dependency injection
依赖注入(Dependency Injection,简称DI)是为了实现各个类之间的依赖的控制反转(Inversion of Control,简称IoC )。 ASP.NET Core 中的Controller 和 Service 或者其他类都支持依赖注入。 依赖注入术语中&a…...

优化物料编码规则,提升物料管理效率
导 读 ( 文/ 2358 ) 物料是生产过程的必需品。对物料进行身份的唯一标识,可以更好的管理物料库存、库位,更方便的对物料进行追溯。通过编码规则的设计,可以对物料按照不同的属性、类别或特征进行分类,从而更好地进行库存分析、计划…...
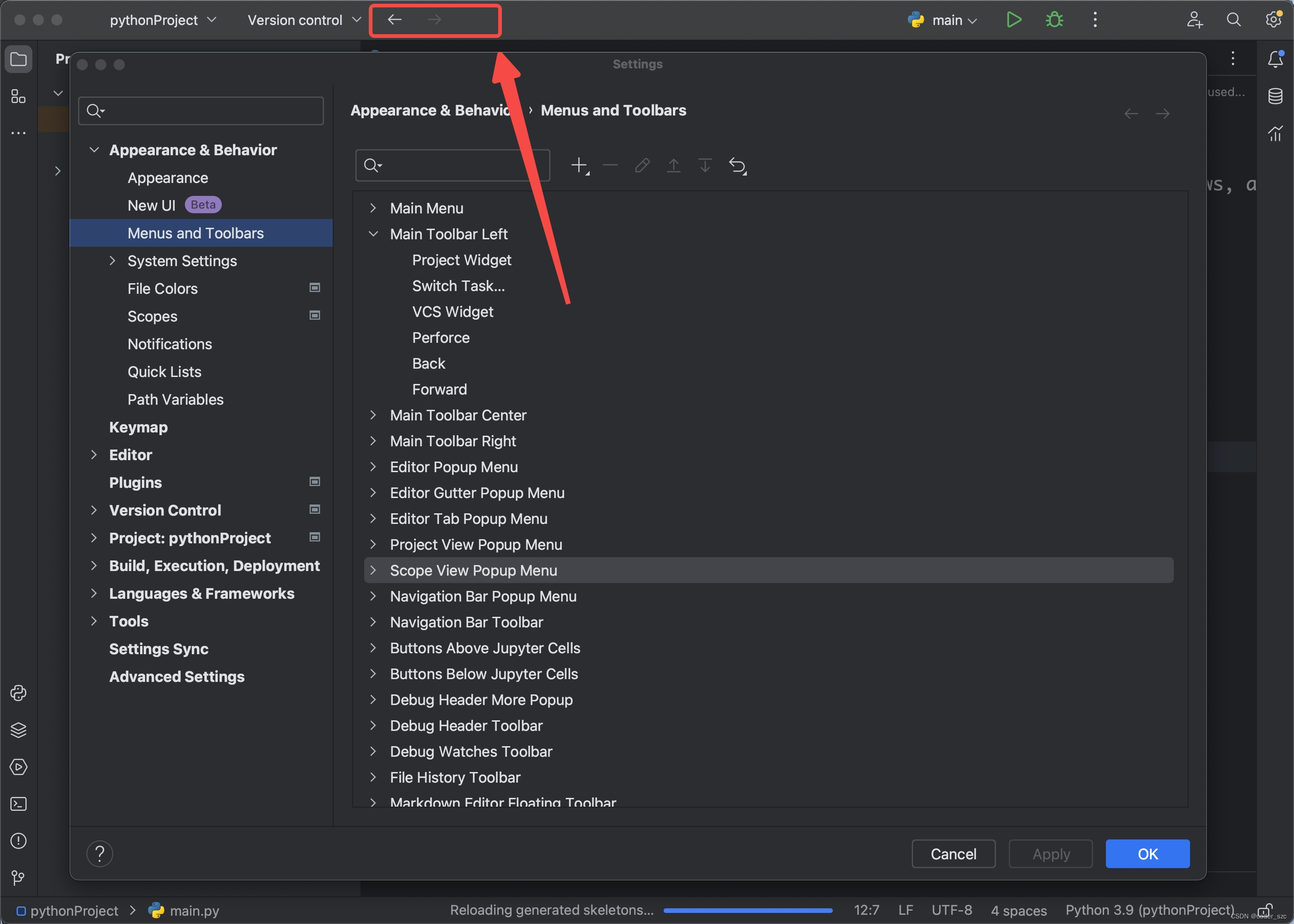
Jetbrains IDE新UI设置前进/后退导航键
背景 2023年6月,Jetbrains在新发布的IDE(Idea、PyCharm等)中开放了新UI选项,我们勾选后重启IDE,便可以使用这一魔性的UI界面了。 但是前进/后退这对常用的导航键却找不到了,以前的设置方式(Vi…...
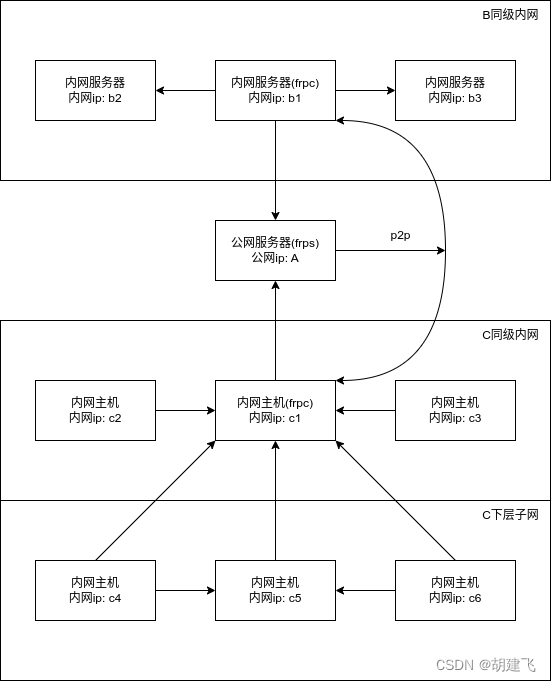
借助frp的xtcp+danted代理打通两边局域网p2p方式访问
最终效果 实现C内网所有设备借助c1内网代理访问B内网所有服务器 配置公网服务端A frps 配置frps.ini [common] # 绑定frp穿透使用的端口 bind_port 7000 # 使用token认证 authentication_method token token xxxx./frps -c frps.ini启动 配置service自启(可选) /etc/…...

2023年高教社杯数学建模思路 - 案例:FPTree-频繁模式树算法
文章目录 算法介绍FP树表示法构建FP树实现代码 建模资料 ## 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 算法介绍 FP-Tree算法全称是FrequentPattern Tree算法,就是频繁模式树算法,…...

批量根据excel数据绘制饼状图
要使用Python批量根据Excel数据绘制饼状图,可以使用pandas和matplotlib库来实现。以下是一个基本的代码示例: import pandas as pd import matplotlib.pyplot as plt # 读取Excel文件 data pd.read_excel(data.xlsx) # 提取需要用于绘制饼状图的数据列…...

C++头文件和std命名空间
C 是在C语言的基础上开发的,早期的 C 还不完善,不支持命名空间,没有自己的编译器,而是将 C 代码翻译成C代码,再通过C编译器完成编译。 这个时候的 C 仍然在使用C语言的库,stdio.h、stdlib.h、string.h 等头…...

浏览器有哪几种缓存?各种缓存之间的优先级
在浏览器中,有以下几种常见的缓存: 1、强制缓存:通过设置 Cache-Control 和 Expires 等响应头实现,可以让浏览器直接从本地缓存中读取资源而不发起请求。2、协商缓存:通过设置 Last-Modified 和 ETag 等响应头实现&am…...
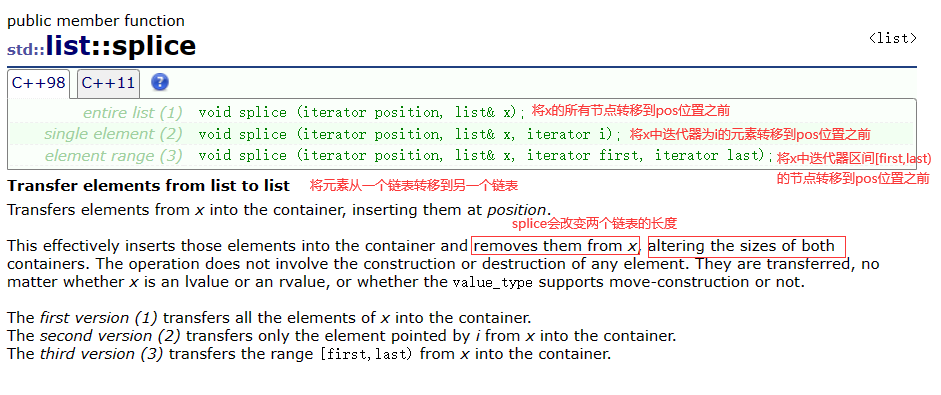
【C++】list
list 1. 简单了解list2. list的常见接口3. 简单实现list4. vector和list比较 1. 简单了解list list的底层是带头双向循环列表。因此list支持任意位置的插入和删除,且效率较高。但其缺陷也很明显,由于各节点在物理空间是不连续的,所以不支持对…...

剪枝基础与实战(2): L1和L2正则化及BatchNormalization讲解
1. CIFAR10 数据集 CIFAR10 是深度学习入门最先接触到的数据集之一,主要用于图像分类任务中,该数据集总共有10个类别。 图片数量:6w 张图片宽高:32x32图片类别:10Trainset: 5w 张,5 个训练块Testset: 1w 张,1 个测试块Pytorch 集成了很多常见数据集的API, 可以通过py…...

C语言学习笔记---指针进阶01
C语言程序设计笔记---016 C语言指针进阶前篇1、字符指针2、指针数组2.1、指针数组例程1 -- 模拟一个二维数组2.2、指针数组例程2 3、数组指针3.1、回顾数组名?3.2、数组指针定义与初始化(格式)3.3、数组指针的作用 --- 常用于二维数组3.4、数…...

【Go 基础篇】Go 语言字符串函数详解:处理字符串进阶
大家好!继续我们关于Go语言中字符串函数的探索。字符串是编程中常用的数据类型,而Go语言为我们提供了一系列实用的字符串函数,方便我们进行各种操作,如查找、截取、替换等。在上一篇博客的基础上,我们将继续介绍更多字…...

GAN原理 代码解读
模型架构 代码 数据准备 import os import time import matplotlib.pyplot as plt import numpy as np import torchvision.transforms as transforms from torch.utils.data import DataLoader from torchvision import datasets import torch.nn as nn import torch# 创建文…...
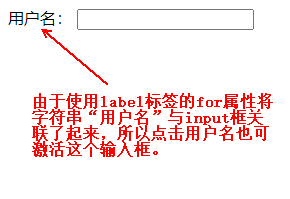
HTML的label标签有什么用?
当你想要将表单元素(如输入框、复选框、单选按钮等)与其描述文本关联起来,以便提供更好的用户界面和可访问性时,就可以使用HTML中的<label>标签。<label>标签用于为表单元素提供标签或标识,使用户能够更清…...
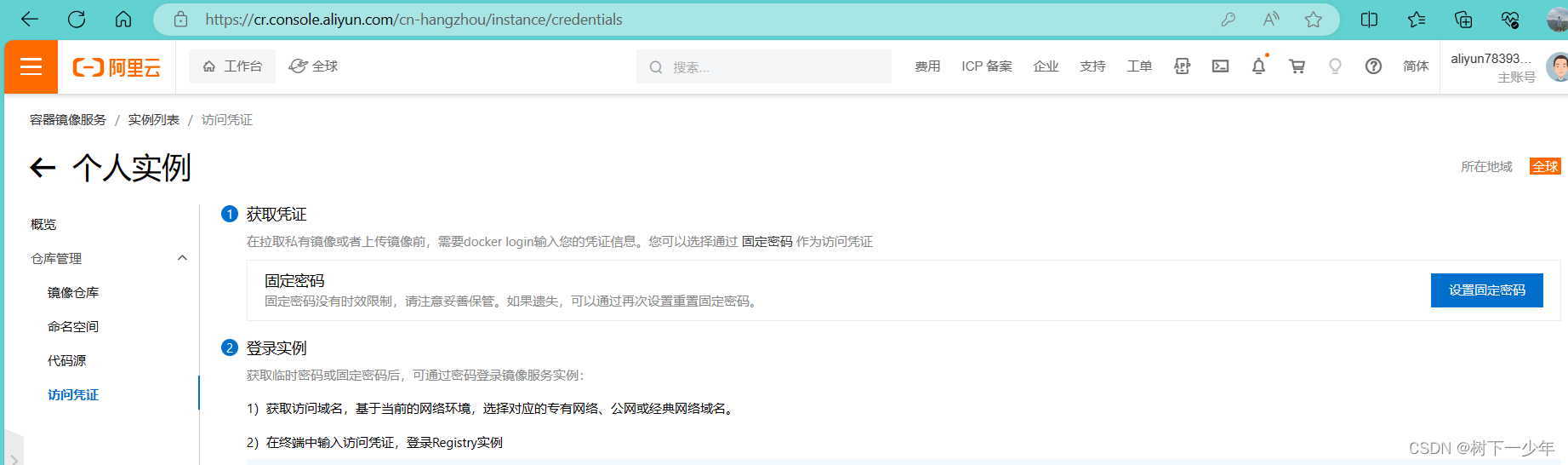
docker在阿里云上的镜像仓库管理
目录 一.登录进入阿里云网站,点击个人实例进行创建 二.创建仓库,填写相关信息 三.在访问凭证中设置固定密码用于登录,登录时用户名是使用你注册阿里云的账号名称,密码使用设置的固定密码 四.为镜像打标签并推送到仓库 五.拉取…...

html-dom核心内容--四要素
1、结构 HTML DOM (文档对象模型) 当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。 2、核心关注的内容:“元素”,“属性”,“修改样式”,“事件反应”。>四要素…...

golang的继承
golang中并没有继承以及oop,但是我们可以通过struct嵌套来完成这个操作。 定义struct 以下定义了一个Person结构体,这个结构体有Eat方法以及三个属性 type Person struct {Name stringAge uint16Phone string }func (recv *Person) Eat() {fmt.Prin…...

Google Play商店优化排名因素之应用截图与视频
屏幕截图是影响转化率的最重要的视觉效果之一。大多数人只需查看应用程序屏幕截图,就会决定是否尝试去下载我们的应用程序。 1、在Google Play商店中,搜索结果页面根据我们搜索的关键词有不同的样式。 展示应用程序中最好的部分,添加一些文字…...

告别道路预测老套路:用ParkPredict+模型思路,解决停车场里的‘鬼探头’难题
破解泊车场景预测困局:ParkPredict模型的技术革新与实践停车场里的每一次转向、倒车和避让,都是对自动驾驶系统预测能力的极限挑战。与开放道路的规则明确不同,这里没有清晰的车道线指引,没有统一的行驶方向,只有随时可…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

INT8量化下TVA注意力对齐精度保障方案
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

03 - 变量与数据类型
03 - 变量与数据类型 变量是编程里最基础的概念,相当于你往电脑里存东西的"容器"。这章我们把变量的命名规则、Python 的几种基本数据类型都过一遍。 变量是什么 说白了,变量就是一个有名字的盒子。你往里面放个东西,以后想用这个…...

揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式
更多请点击: https://intelliparadigm.com 第一章:揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式 Midjourney V6 在启用云雾(mist/fog/haze)类视觉效果时,…...

NsEmuTools:10分钟搞定NS模拟器配置,让你专注游戏乐趣
NsEmuTools:10分钟搞定NS模拟器配置,让你专注游戏乐趣 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 还在为NS模拟器的复杂配置而头疼吗?每次想玩Swit…...
)
为什么你的DeepSeek总漏检重构后代码?4步反混淆预处理法(附LLM辅助去装饰器Python脚本)
更多请点击: https://codechina.net 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

ThingLinks-IoT:一站式物联网平台解决方案
ThingLinks-IoT 物联网平台 | 多协议接入物模型告警联动视频接入AI 助手 一体化方案 一个面向项目交付与企业生产场景的国产物联网中台——把"设备接入 → 数据处理 → 告警联动 → 业务集成"这条链路上的通用能力一次性做完做稳,让你只关心自己的业务。 …...