clickhouse-压测
一、数据集准备
数据集可以使用官网数据集,也可以用ssb-dbgen来准备
1.准备数据
这里最后生成表的数据行数为60亿行,数据量为300G左右
git clone https://github.com/vadimtk/ssb-dbgen.git
cd ssb-dbgen/
make
1.1 生成数据
# -s 指生成多少G的数据
$ ./dbgen -s 40 -T c
$ ./dbgen -s 40 -T l
$ ./dbgen -s 40 -T p
$ ./dbgen -s 40 -T s
1.2 创建表
CREATE TABLE customer
(C_CUSTKEY UInt32,C_NAME String,C_ADDRESS String,C_CITY LowCardinality(String),C_NATION LowCardinality(String),C_REGION LowCardinality(String),C_PHONE String,C_MKTSEGMENT LowCardinality(String)
)
ENGINE = MergeTree ORDER BY (C_CUSTKEY);CREATE TABLE lineorder
(LO_ORDERKEY UInt32,LO_LINENUMBER UInt8,LO_CUSTKEY UInt32,LO_PARTKEY UInt32,LO_SUPPKEY UInt32,LO_ORDERDATE Date,LO_ORDERPRIORITY LowCardinality(String),LO_SHIPPRIORITY UInt8,LO_QUANTITY UInt8,LO_EXTENDEDPRICE UInt32,LO_ORDTOTALPRICE UInt32,LO_DISCOUNT UInt8,LO_REVENUE UInt32,LO_SUPPLYCOST UInt32,LO_TAX UInt8,LO_COMMITDATE Date,LO_SHIPMODE LowCardinality(String)
)
ENGINE = MergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY);CREATE TABLE part
(P_PARTKEY UInt32,P_NAME String,P_MFGR LowCardinality(String),P_CATEGORY LowCardinality(String),P_BRAND LowCardinality(String),P_COLOR LowCardinality(String),P_TYPE LowCardinality(String),P_SIZE UInt8,P_CONTAINER LowCardinality(String)
)
ENGINE = MergeTree ORDER BY P_PARTKEY;CREATE TABLE supplier
(S_SUPPKEY UInt32,S_NAME String,S_ADDRESS String,S_CITY LowCardinality(String),S_NATION LowCardinality(String),S_REGION LowCardinality(String),S_PHONE String
)
ENGINE = MergeTree ORDER BY S_SUPPKEY;
1.3 导入数据
$ clickhouse-client --query "INSERT INTO db_bench.customer FORMAT CSV" < customer.tbl
$ clickhouse-client --query "INSERT INTO db_bench.part FORMAT CSV" < part.tbl
$ clickhouse-client --query "INSERT INTO db_bench.supplier FORMAT CSV" < supplier.tbl
$ clickhouse-client --query "INSERT INTO db_bench.lineorder FORMAT CSV" < lineorder.tbl
1.4 join表
这个操作耗时两个小时,占用内存为29G
# 因为这个操作比较耗费内存,所以要事先设置好内存限制
SET max_memory_usage = 30000000000;CREATE TABLE lineorder_flat
ENGINE = MergeTree ORDER BY (LO_ORDERDATE, LO_ORDERKEY)
AS SELECTl.LO_ORDERKEY AS LO_ORDERKEY,l.LO_LINENUMBER AS LO_LINENUMBER,l.LO_CUSTKEY AS LO_CUSTKEY,l.LO_PARTKEY AS LO_PARTKEY,l.LO_SUPPKEY AS LO_SUPPKEY,l.LO_ORDERDATE AS LO_ORDERDATE,l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY,l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY,l.LO_QUANTITY AS LO_QUANTITY,l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE,l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE,l.LO_DISCOUNT AS LO_DISCOUNT,l.LO_REVENUE AS LO_REVENUE,l.LO_SUPPLYCOST AS LO_SUPPLYCOST,l.LO_TAX AS LO_TAX,l.LO_COMMITDATE AS LO_COMMITDATE,l.LO_SHIPMODE AS LO_SHIPMODE,c.C_NAME AS C_NAME,c.C_ADDRESS AS C_ADDRESS,c.C_CITY AS C_CITY,c.C_NATION AS C_NATION,c.C_REGION AS C_REGION,c.C_PHONE AS C_PHONE,c.C_MKTSEGMENT AS C_MKTSEGMENT,s.S_NAME AS S_NAME,s.S_ADDRESS AS S_ADDRESS,s.S_CITY AS S_CITY,s.S_NATION AS S_NATION,s.S_REGION AS S_REGION,s.S_PHONE AS S_PHONE,p.P_NAME AS P_NAME,p.P_MFGR AS P_MFGR,p.P_CATEGORY AS P_CATEGORY,p.P_BRAND AS P_BRAND,p.P_COLOR AS P_COLOR,p.P_TYPE AS P_TYPE,p.P_SIZE AS P_SIZE,p.P_CONTAINER AS P_CONTAINER
FROM lineorder AS l
INNER JOIN customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN part AS p ON p.P_PARTKEY = l.LO_PARTKEY;
二、基准测试
1.benchmark的使用
1.1 基本用法
# 以下几种写法都可以
$ clickhouse-benchmark --query ["single query"] [keys]
$ echo "single query" | clickhouse-benchmark [keys]
$ clickhouse-benchmark [keys] <<< "single query"
clickhouse-benchmark [keys] < queries_file;
# 比较两个clickhouse性能
$ echo "SELECT * FROM system.numbers LIMIT 10000000 OFFSET 10000000" | clickhouse-benchmark --host=localhost --port=9001 --host=localhost --port=9000 -i 10
1.2 参数详解
--query=QUERY — 要执行的查询。 如果未传递此参数,clickhouse-benchmark 将从标准输入读取查询。
-c N, --concurrency=N — clickhouse-benchmark 同时发送的查询数。 默认值:1。
-d N, --delay=N — 中间报告之间的间隔(以秒为单位)(以禁用报告集 0)。 默认值:1。
-h HOST, --host=HOST — 服务器主机。 默认值:本地主机。 对于比较模式,您可以使用多个 -h 键。
-p N, --port=N — 服务器端口。 默认值:9000。对于比较模式,您可以使用多个 -p 键。
-i N, --iterations=N — 查询总数。 默认值:0(永远重复)。
-r, --randomize — 如果有多个输入查询,则查询执行的随机顺序。
-s, --secure — 使用 TLS 连接。
-t N, --timelimit=N — 时间限制(以秒为单位)。 当达到指定的时间限制时,clickhouse-benchmark 将停止发送查询。 默认值:0(时间限制禁用)。
--confidence=N — T 检验的置信度。 可能的值:0 (80%)、1 (90%)、2 (95%)、3 (98%)、4 (99%)、5 (99.5%)。 默认值:5。在比较模式下,clickhouse-benchmark 执行独立双样本学生 t 检验,以确定两个分布在所选置信水平下是否没有差异。
--cumulative — 打印累积数据而不是每个间隔的数据。
--database=DATABASE_NAME — ClickHouse 数据库名称。 默认值:默认。
--json=FILEPATH — JSON 输出。 设置密钥后,clickhouse-benchmark 会将报告输出到指定的 JSON 文件。
--user=USERNAME — ClickHouse 用户名。 默认值:默认。
--password=PSWD — ClickHouse 用户密码。 默认值:空字符串。
--stacktrace — 堆栈跟踪输出。 设置密钥后,clickhouse-bencmark 会输出异常的堆栈跟踪。
--stage=WORD — 服务器上的查询处理阶段。 ClickHouse 在指定阶段停止查询处理并向 clickhouse-benchmark 返回答案。 可能的值:complete、fetch_columns、with_mergeable_state。 默认值:完整。
--help — 显示帮助消息。
如果要对查询应用某些设置,请将它们作为键传递 --<session setting name>= SETTING_VALUE。 例如,--max_memory_usage=1048576。
1.3 结果分析
# 执行的查询数:字段中的查询数。
Queries executed: 72 (1800.000%).
# ClickHouse 服务器的端点。
# queries:已处理查询的数量。
# QPS:在 --delay 参数指定的时间段内服务器每秒执行的查询数量。
# RPS:在 --delay 参数指定的时间段内服务器每秒读取的行数。
# MiB/s:在 --delay 参数中指定的时间段内,服务器每秒读取多少兆字节。
# result RPS:在 --delay 参数中指定的时间段内,服务器每秒将多少行放入查询结果中。
# result MiB/s。 在 --delay 参数指定的时间段内,服务器每秒向查询结果放置多少兆字节。localhost:9000, queries 2, QPS: 0.156, RPS: 432704682.870, MiB/s: 1370.478, result RPS: 2.185, result MiB/s: 0.000.
# 查询执行时间的百分位数。
0.000% 0.217 sec.
10.000% 0.217 sec.
20.000% 0.217 sec.
30.000% 0.217 sec.
40.000% 0.217 sec.
50.000% 12.594 sec.
60.000% 12.594 sec.
70.000% 12.594 sec.
80.000% 12.594 sec.
90.000% 12.594 sec.
95.000% 12.594 sec.
99.000% 12.594 sec.
99.900% 12.594 sec.
99.990% 12.594 sec.状态字符串包含(按顺序):ClickHouse 服务器的端点。
已处理查询的数量。
QPS:在 --delay 参数指定的时间段内服务器每秒执行的查询数量。
RPS:在 --delay 参数指定的时间段内服务器每秒读取的行数。
MiB/s:在 --delay 参数中指定的时间段内,服务器每秒读取多少兆字节。
结果 RPS:在 --delay 参数中指定的时间段内,服务器每秒将多少行放入查询结果中。
结果 MiB/s。 在 --delay 参数指定的时间段内,服务器每秒向查询结果放置多少兆字节。
查询执行时间的百分位数。
2.基本测试
基准测试的内容可以看官网,具体的sql在这里查看。我是共写了4个sql文件,内容如下
# test1.sql
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue FROM db_bench.lineorder_flat WHERE toYear(LO_ORDERDATE) = 1993 AND LO_DISCOUNT BETWEEN 1 AND 3 AND LO_QUANTITY < 25;
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue FROM db_bench.lineorder_flat WHERE toYYYYMM(LO_ORDERDATE) = 199401 AND LO_DISCOUNT BETWEEN 4 AND 6 AND LO_QUANTITY BETWEEN 26 AND 35;
SELECT sum(LO_EXTENDEDPRICE * LO_DISCOUNT) AS revenue FROM db_bench.lineorder_flat WHERE toISOWeek(LO_ORDERDATE) = 6 AND toYear(LO_ORDERDATE) = 1994 AND LO_DISCOUNT BETWEEN 5 AND 7 AND LO_QUANTITY BETWEEN 26 AND 35;# test2.sql
SELECT sum(LO_REVENUE),toYear(LO_ORDERDATE) AS year,P_BRAND FROM db_bench.lineorder_flat WHERE P_CATEGORY = 'MFGR#12' AND S_REGION = 'AMERICA' GROUP BY year,P_BRAND ORDER BY year,P_BRAND;
SELECT sum(LO_REVENUE),toYear(LO_ORDERDATE) AS year,P_BRAND FROM db_bench.lineorder_flat WHERE P_BRAND >= 'MFGR#2221' AND P_BRAND <= 'MFGR#2228' AND S_REGION = 'ASIA' GROUP BY year,P_BRAND ORDER BY year,P_BRAND;
SELECT sum(LO_REVENUE), toYear(LO_ORDERDATE) AS year, P_BRAND FROM db_bench.lineorder_flat WHERE P_BRAND = 'MFGR#2239' AND S_REGION = 'EUROPE' GROUP BY year, P_BRAND ORDER BY year, P_BRAND;# test3.sql
SELECT C_NATION, S_NATION, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE C_REGION = 'ASIA' AND S_REGION = 'ASIA' AND year >= 1992 AND year <= 1997 GROUP BY C_NATION, S_NATION, year ORDER BY year ASC, revenue DESC;
SELECT C_CITY, S_CITY, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE C_NATION = 'UNITED STATES' AND S_NATION = 'UNITED STATES' AND year >= 1992 AND year <= 1997 GROUP BY C_CITY, S_CITY, year ORDER BY year ASC, revenue DESC;
SELECT C_CITY, S_CITY, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE (C_CITY = 'UNITED KI1' OR C_CITY = 'UNITED KI5') AND (S_CITY = 'UNITED KI1' OR S_CITY = 'UNITED KI5') AND year >= 1992 AND year <= 1997 GROUP BY C_CITY, S_CITY, year ORDER BY year ASC, revenue DESC;
SELECT C_CITY, S_CITY, toYear(LO_ORDERDATE) AS year, sum(LO_REVENUE) AS revenue FROM db_bench.lineorder_flat WHERE (C_CITY = 'UNITED KI1' OR C_CITY = 'UNITED KI5') AND (S_CITY = 'UNITED KI1' OR S_CITY = 'UNITED KI5') AND toYYYYMM(LO_ORDERDATE) = 199712 GROUP BY C_CITY, S_CITY, year ORDER BY year ASC, revenue DESC;# test4.sql
SELECT toYear(LO_ORDERDATE) AS year, C_NATION, sum(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM db_bench.lineorder_flat WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND (P_MFGR = 'MFGR#1' OR P_MFGR = 'MFGR#2') GROUP BY year, C_NATION ORDER BY year ASC, C_NATION ASC;
SELECT toYear(LO_ORDERDATE) AS year, S_NATION, P_CATEGORY, sum(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM db_bench.lineorder_flat WHERE C_REGION = 'AMERICA' AND S_REGION = 'AMERICA' AND (year = 1997 OR year = 1998) AND (P_MFGR = 'MFGR#1' OR P_MFGR = 'MFGR#2') GROUP BY year, S_NATION, P_CATEGORY ORDER BY year ASC, S_NATION ASC, P_CATEGORY ASC;
SELECT toYear(LO_ORDERDATE) AS year, S_CITY, P_BRAND, sum(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM db_bench.lineorder_flat WHERE S_NATION = 'UNITED STATES' AND (year = 1997 OR year = 1998) AND P_CATEGORY = 'MFGR#14' GROUP BY year, S_CITY, P_BRAND ORDER BY year ASC, S_CITY ASC, P_BRAND ASC;
2.1 测试方法
clickhouse-benchmark < test1.sql
clickhouse-benchmark < test2.sql
clickhouse-benchmark < test3.sql
clickhouse-benchmark < test4.sql
2.2 测试结果
# test1
Queries executed: 921 (30700.000%).localhost:9000, queries 2, QPS: 5.558, RPS: 263878534.377, MiB/s: 2012.050, result RPS: 5.558, result MiB/s: 0.000.0.000% 0.091 sec.
10.000% 0.091 sec.
20.000% 0.091 sec.
30.000% 0.091 sec.
40.000% 0.091 sec.
50.000% 0.268 sec.
60.000% 0.268 sec.
70.000% 0.268 sec.
80.000% 0.268 sec.
90.000% 0.268 sec.
95.000% 0.268 sec.
99.000% 0.268 sec.
99.900% 0.268 sec.# test2
Queries executed: 32 (1066.667%).localhost:9000, queries 1, QPS: 0.054, RPS: 326066467.053, MiB/s: 2797.293, result RPS: 3.043, result MiB/s: 0.000.0.000% 18.401 sec.
10.000% 18.401 sec.
20.000% 18.401 sec.
30.000% 18.401 sec.
40.000% 18.401 sec.
50.000% 18.401 sec.
60.000% 18.401 sec.
70.000% 18.401 sec.
80.000% 18.401 sec.
90.000% 18.401 sec.
95.000% 18.401 sec.
99.000% 18.401 sec.
99.900% 18.401 sec.
99.990% 18.401 sec.# test3
localhost:9000, queries 73, QPS: 0.082, RPS: 340111314.396, MiB/s: 2527.187, result RPS: 15.938, result MiB/s: 0.000.0.000% 0.182 sec.
10.000% 0.217 sec.
20.000% 0.230 sec.
30.000% 10.547 sec.
40.000% 12.614 sec.
50.000% 14.860 sec.
60.000% 16.560 sec.
70.000% 18.072 sec.
80.000% 18.285 sec.
90.000% 19.915 sec.
95.000% 19.962 sec.
99.000% 20.011 sec.
99.900% 20.059 sec.
99.990% 20.059 sec.# test4
Queries executed: 3 (100.000%).localhost:9000, queries 1, QPS: 0.474, RPS: 683988835.693, MiB/s: 9777.042, result RPS: 378.949, result MiB/s: 0.004.0.000% 2.111 sec.
10.000% 2.111 sec.
20.000% 2.111 sec.
30.000% 2.111 sec.
40.000% 2.111 sec.
50.000% 2.111 sec.
60.000% 2.111 sec.
70.000% 2.111 sec.
80.000% 2.111 sec.
90.000% 2.111 sec.
95.000% 2.111 sec.
99.000% 2.111 sec.
99.900% 2.111 sec.
99.990% 2.111 sec.
2.3 cpu情况
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND7031 999 20 0 0.257t 1.470g 99080 S 4656 0.8 3643:13 clickhouse-serv
2.4 读取数据情况
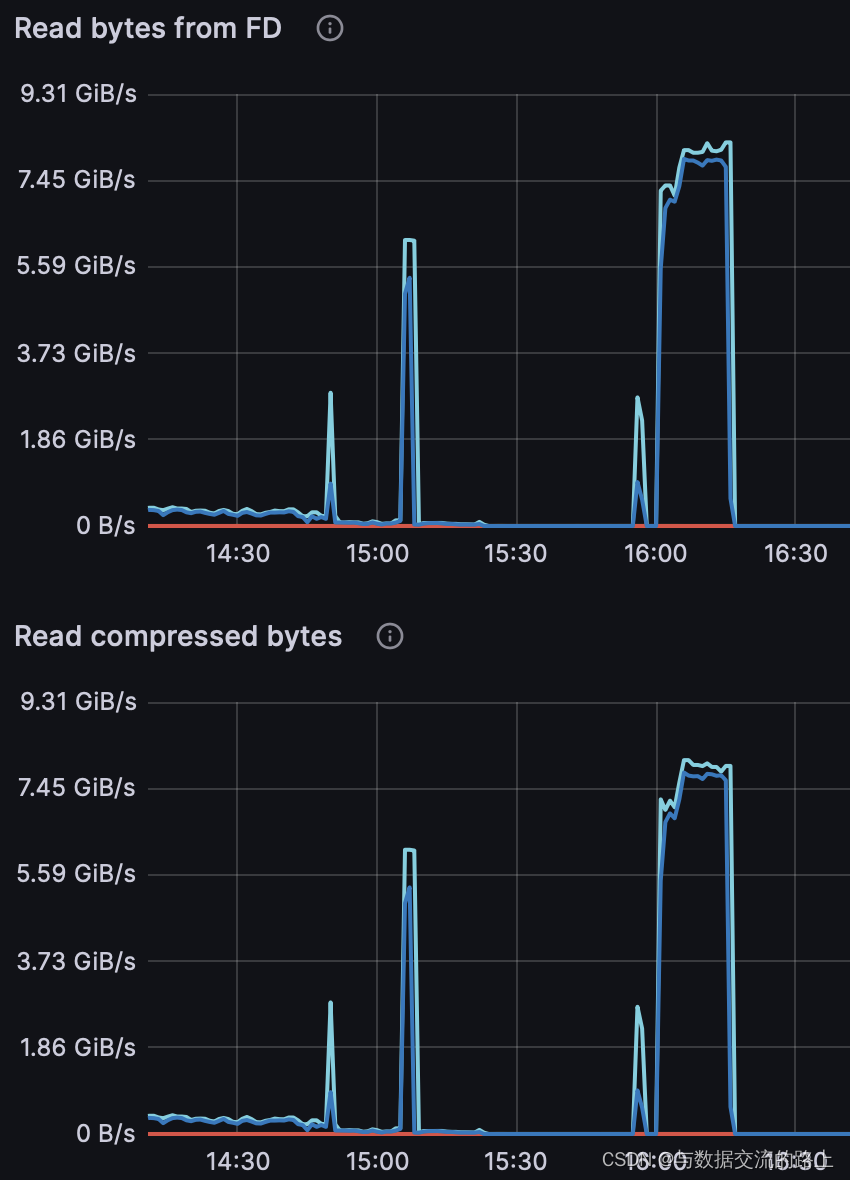
结论: 可以看到读取数据的速度还是非常快的,每秒读取的行数和数据量都很大,读取时非常耗cpu资源,但内存占用缺极少
相关文章:
clickhouse-压测
一、数据集准备 数据集可以使用官网数据集,也可以用ssb-dbgen来准备 1.准备数据 这里最后生成表的数据行数为60亿行,数据量为300G左右 git clone https://github.com/vadimtk/ssb-dbgen.git cd ssb-dbgen/ make1.1 生成数据 # -s 指生成多少G的数据…...

AI夏令营第三期用户新增挑战赛学习笔记
1、数据可视化 1.数据探索和理解:数据可视化可以帮助我们更好地理解数据集的特征、分布和关系。通过可视化数据,我们可以发现数据中的模式、异常值、缺失值等信息,从而更好地了解数据的特点和结构。2.特征工程:数据可视化可以帮助…...
pdf转ppt软件哪个好用?推荐一个好用的pdf转ppt软件
在日常工作和学习中,我们经常会遇到需要将PDF文件转换为PPT格式的情况。PDF格式的文件通常用于展示和保留文档的原始格式,而PPT格式则更适合用于演示和展示。为了满足这一需求,许多软件提供了PDF转PPT的功能,使我们能够方便地将PD…...

Linux 内核函数kallsyms_lookup_name
文章目录 一、API使用二、源码解析2.1 kallsyms_lookup_name2.2 kallsyms_expand_symbol2.3 kallsyms_sym_address2.3.1 x86_642.3.2 arm642.3.3 CONFIG_KALLSYMS_ABSOLUTE_PERCPU 参考资料 一、API使用 kallsyms_lookup_name 是一个内核函数,用于通过符号名称查找…...

强化学习在游戏AI中的应用与挑战
文章目录 1. 强化学习简介2. 强化学习在游戏AI中的应用2.1 游戏智能体训练2.2 游戏AI决策2.3 游戏测试和优化 3. 强化学习在游戏AI中的挑战3.1 探索与利用的平衡3.2 多样性的应对 4. 解决方法与展望4.1 深度强化学习4.2 奖励设计和函数逼近 5. 总结 🎉欢迎来到AIGC人…...

6 Python的异常处理
概述 在上一节,我们介绍了Python的面向对象编程,包括:类的定义、类的使用、类变量、实例变量、实例方法、类方法、静态方法、类的运算符重载、继承等内容。在这一节中,我们将介绍Python的异常处理。异常是指程序在运行过程中出现的…...

【跨语言通讯】
传统的跨语言通讯方案: 基于SOAP消息格式的WebService 基于JSON消息格式的RESTful 服务 主要弊端: XML体积太大,解析性能极差 JSON体积相对较小,解析相对较快,但表达能力较弱 如今比较流行的跨语言通讯方案&…...

Android 基础知识
一、Activity 1、onSaveInstanceState(),onRestoreInstanceState的调用时机 onSaveInstanceState 调用时机 从最近应用中选择运行其他程序时 但用户按下Home键时 屏幕方向切换时 按下电源案件时 从当前activity启动一个新的activity时 onRestorInstanceState调用时机 只…...

Linux常用命令_帮助命令、用户管理命令、压缩解压命令
文章目录 1. 帮助命令1.1 帮助命令:man1.2 帮助命令:help1.3 其他帮助命令 2. 用户管理命令2.1 用户管理命令: useradd2.2 用户管理命令: passwd2.3 用户管理命令: who2.4 用户管理命令: w 3. 压缩解压命令3.1 压缩解压命令: gzip3.2 压缩解压命令: gunzip3.3 压缩解压命令: ta…...

解决 KylinOS “Could not get lock /var/lib/dpkg/lock”错误
最近,我遇到了 “Could not get lock /var/lib/dpkg/lock”的错误,我既不能安装任何软件包,也不能更新系统。此错误也与“Could not get lock /var/lib/apt/lists/lock”错误密切相关。以下是 Ubuntu 20.04 上的一些样本输出。 Reading package lists… Done E: Could not…...

PHP pdf 自动填写表单
一、下载github上的项目,地址 二、下载pdftk 地址 // 转化PDF模板 pdftk modele.pdf output modele2.pdf# 填充pdf文件中的表单 require(fpdm.php); $fields array(name > My name,address > My address,city > My city,phone > My phone nu…...

Win2016Server绑定多网卡实现负载均衡
一、服务器端: 1、输入ncpa.cpl打开网络连接,对要绑定的网卡勾掉IPV4,IPV4地址选择自动 2、输入servermanager.exe,打开服务器管理器 3、在 [本地服务器] 中,点后边的 “已禁用” ,在 [适配器和接口] 小窗口…...
微软宣布在 Excel 中使用 Python:结合了 Python 的强大功能和 Excel 的灵活性。
文章目录 Excel 中的 Python 有何独特之处?1. Excel 中的 Python 是为分析师构建的。高级可视化机器学习、预测分析和预测数据清理 2. Excel 中的 Python 通过 Anaconda 展示了最好的 Python 分析功能。3. Excel 中的 Python 在 Microsoft 云上安全运行,…...

学习心得03:OpenCV
数学真是不可思议,不管什么东西,都能用数学来处理。OpenCV以前也接触过,这次是系统学习一下。 颜色模型 RGB,YUV,HSV,Lab,GRAY 颜色转换cvtColor()/convertTo(),通道分离split()&…...

ubuntu学习(五)----读取文件以及光标的移动
1、读取文件函数原型介绍 ssize_t read(int fd,void*buf,size_t count) 参数说明: fd: 是文件描述符 buf:为读出数据的缓冲区; count: 为每次读取的字节数(是请求读取的字节数,读上来的数据保存在缓冲区buf中,同时文…...

Python 数据分析——matplotlib 快速绘图
matplotlib采用面向对象的技术来实现,因此组成图表的各个元素都是对象,在编写较大的应用程序时通过面向对象的方式使用matplotlib将更加有效。但是使用这种面向对象的调用接口进行绘图比较烦琐,因此matplotlib还提供了快速绘图的pyplot模块。…...
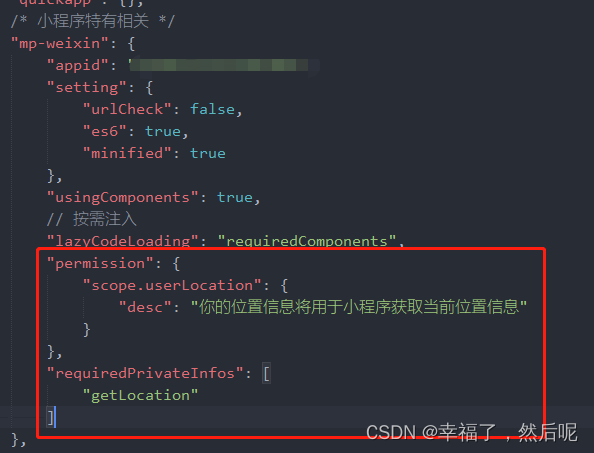
uniapp小程序位置信息配置
uniapp 小程序获取当前位置信息报错 报错信息: getLocation:fail the api need to be declared in the requiredPrivateInfos field in app.json/ext.json 需要在manifest.json配置文件中进行配置:...

《基于 Vue 组件库 的 Webpack5 配置》1.模式 Mode 和 vue-loader
一定要配置 模式 Mode,这里有个小知识点,环境变量 process.env.NODE_ENV module.exports {mode: production,// process.env.NODE_ENV 或 development, }一定要配置 vue-loader Vue Loader v15 现在需要配合一个 webpack 插件才能正确使用; …...
01.sqlite3学习——数据库概述
目录 重点概述总结 数据库标准介绍 什么是数据库? 数据库是如何存储数据的? 数据库是如何管理数据的? 数据库系统结构 常见关系型数据库管理系统 关系型数据库相关知识点 数据库与文件存储数据对比 重点概述总结 数据库可以理解为操…...

视频集中存储/云存储平台EasyCVR国标GB28181协议接入的报文交互数据包分析
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚融合管理…...
:动态数据流与交互优化实战)
QT 基于qcustomplot实现热力图(四):动态数据流与交互优化实战
1. 动态数据流的核心实现策略 在实时监控系统中,热力图的数据往往需要持续更新。我遇到过不少开发者直接粗暴地全量刷新整个数据集,结果界面卡顿得像老式幻灯片。这里分享三种经过实战检验的动态更新方案,每种都有其适用场景。 增量更新法最适…...

3分钟掌握的网盘密码解析黑科技:让提取码自动获取效率提升10倍
3分钟掌握的网盘密码解析黑科技:让提取码自动获取效率提升10倍 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾经因为寻找百度网盘分享链接的提取码而浪费大量时间?传统方式下,用户…...

小爱音响音乐服务:如何让智能音箱变身私人音乐管家?
小爱音响音乐服务:如何让智能音箱变身私人音乐管家? 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 你是否曾经想过,家里的小爱音…...

Fun-ASR语音识别新手入门:3步启动Web服务,麦克风实时转文字实测
Fun-ASR语音识别新手入门:3步启动Web服务,麦克风实时转文字实测 1. 快速认识Fun-ASR Fun-ASR是由钉钉与通义实验室联合推出的语音识别系统,专为中文场景优化设计。与市面上常见的云端语音识别服务不同,它最大的特点是支持本地化…...
)
Arcgis符号化实战:用矢量文件制作专业级统计地图(附最新配色方案)
ArcGIS符号化实战:用矢量文件制作专业级统计地图(附最新配色方案) 当你面对一叠枯燥的表格数据时,是否想过如何让这些数字"活"起来?统计地图正是将抽象数据转化为直观视觉表达的利器。作为地理信息系统领域的…...
Pixel Aurora Engine实战落地:为像素RPG自动生成NPC对话头像与场景贴图
Pixel Aurora Engine实战落地:为像素RPG自动生成NPC对话头像与场景贴图 1. 像素游戏开发者的新利器 想象一下这样的场景:你正在开发一款像素风格的RPG游戏,需要为上百个NPC设计独特的对话头像,还要制作大量场景贴图。传统方法下…...

丹青识画部署教程:Nginx反向代理+HTTPS保障书法API安全
丹青识画部署教程:Nginx反向代理HTTPS保障书法API安全 1. 引言:当AI艺术遇见生产环境 想象一下,你开发了一个能看懂画作、还能用行草书法题跋的AI应用。它优雅、智能,充满了东方美学韵味。但当你准备把它开放给更多人使用时&…...

从产品质量到A/B测试:聊聊高斯分布在真实业务场景中的10个应用与常见误区
高斯分布实战手册:10个业务场景中的智能决策与避坑指南 当你发现某电商平台上的用户购买金额呈现"中间多、两头少"的分布时,当A/B测试结果出现微妙的5%转化率差异时,当工厂质检数据出现异常波动时——这些看似无关的业务问题背后&a…...

Qwen3-1.7B推理模式切换体验:思考模式与非思考模式效果对比
Qwen3-1.7B推理模式切换体验:思考模式与非思考模式效果对比 1. 引言:双模式推理的创新价值 在边缘计算和轻量化AI模型快速发展的今天,Qwen3-1.7B通过独特的动态双模式架构,为用户提供了灵活的推理选择。这款17亿参数的轻量级大语…...

IEEE会议论文避雷指南:如何用GSview+Photoshop搞定EPS图片压缩与特殊字符命名
IEEE会议论文图片处理全攻略:从格式转换到命名规范 第一次投稿IEEE会议的新手研究者们,往往会在图片处理环节栽跟头——明明内容扎实、实验充分,却因为技术细节问题被编辑退回修改。这不是学术能力的问题,而是对印刷出版标准的不熟…...