【业务功能篇82】微服务SpringCloud-ElasticSearch-Kibanan-docke安装-进阶实战
四、ElasticSearch进阶
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/getting-started-search.html
1.ES中的检索方式
在ElasticSearch中支持两种检索方式
- 通过使用REST request URL 发送检索参数(uri+检索参数)
- 通过使用 REST request body 来发送检索参数 (uri+请求体)
第一种方式
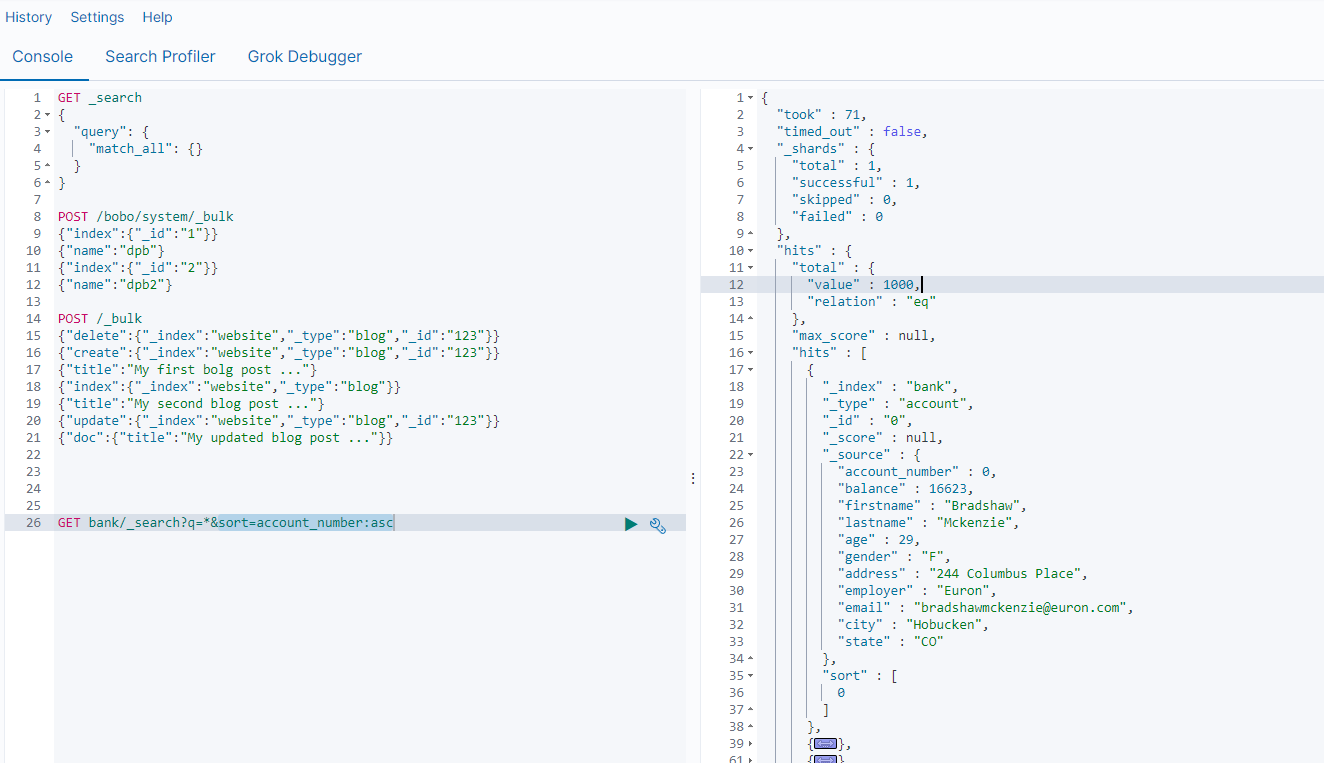
GET bank/_search # 检索bank下的所有信息,包括 type 和 docs
GET bank/_search?q=*&sort=account_number:asc
响应结果信息
| 信息 | 描述 |
|---|---|
| took | ElasticSearch执行搜索的时间(毫秒) |
| time_out | 搜索是否超时 |
| _shards | 有多少个分片被搜索了,统计成功/失败的搜索分片 |
| hits | 搜索结果 |
| hits.total | 搜索结果统计 |
| hits.hits | 实际的搜索结果数组(默认为前10条文档) |
| sort | 结果的排序key,没有就按照score排序 |
| score和max_score | 相关性得分和最高分(全文检索使用) |
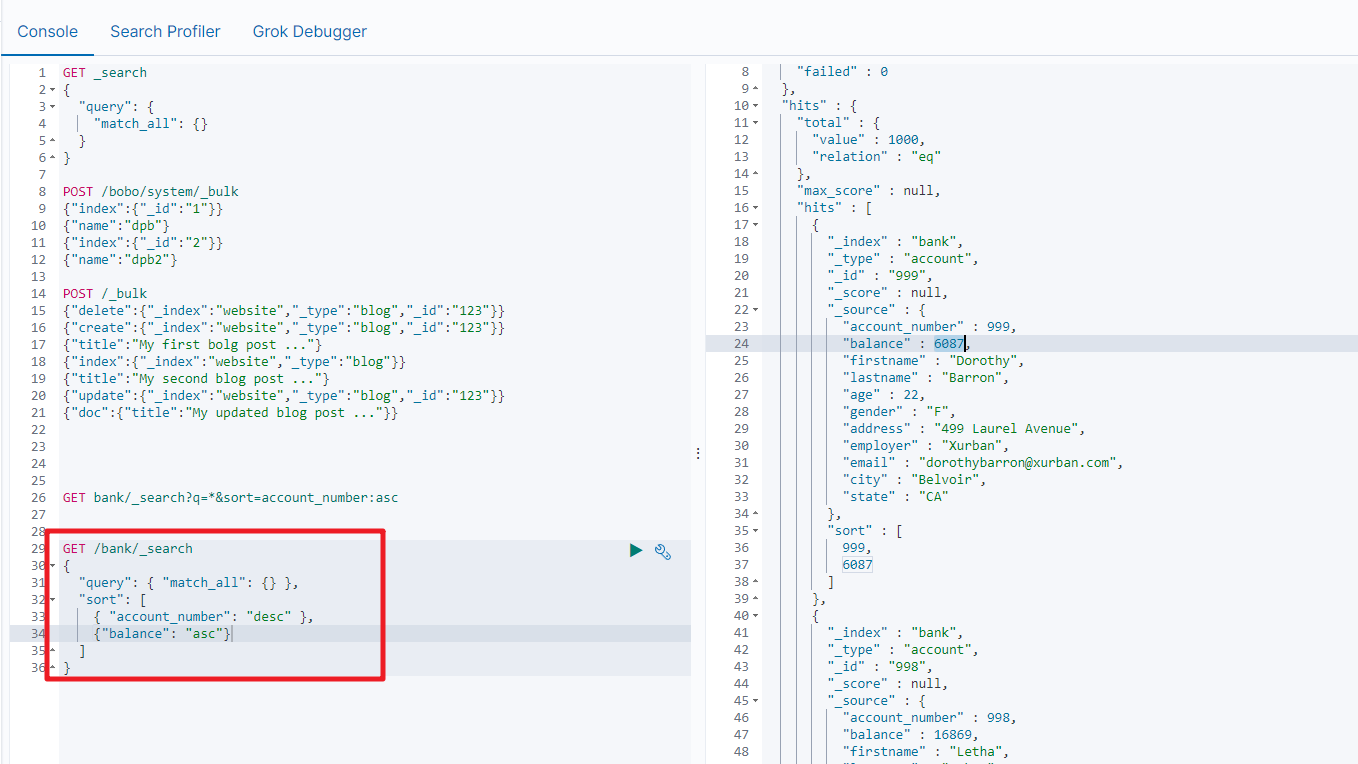
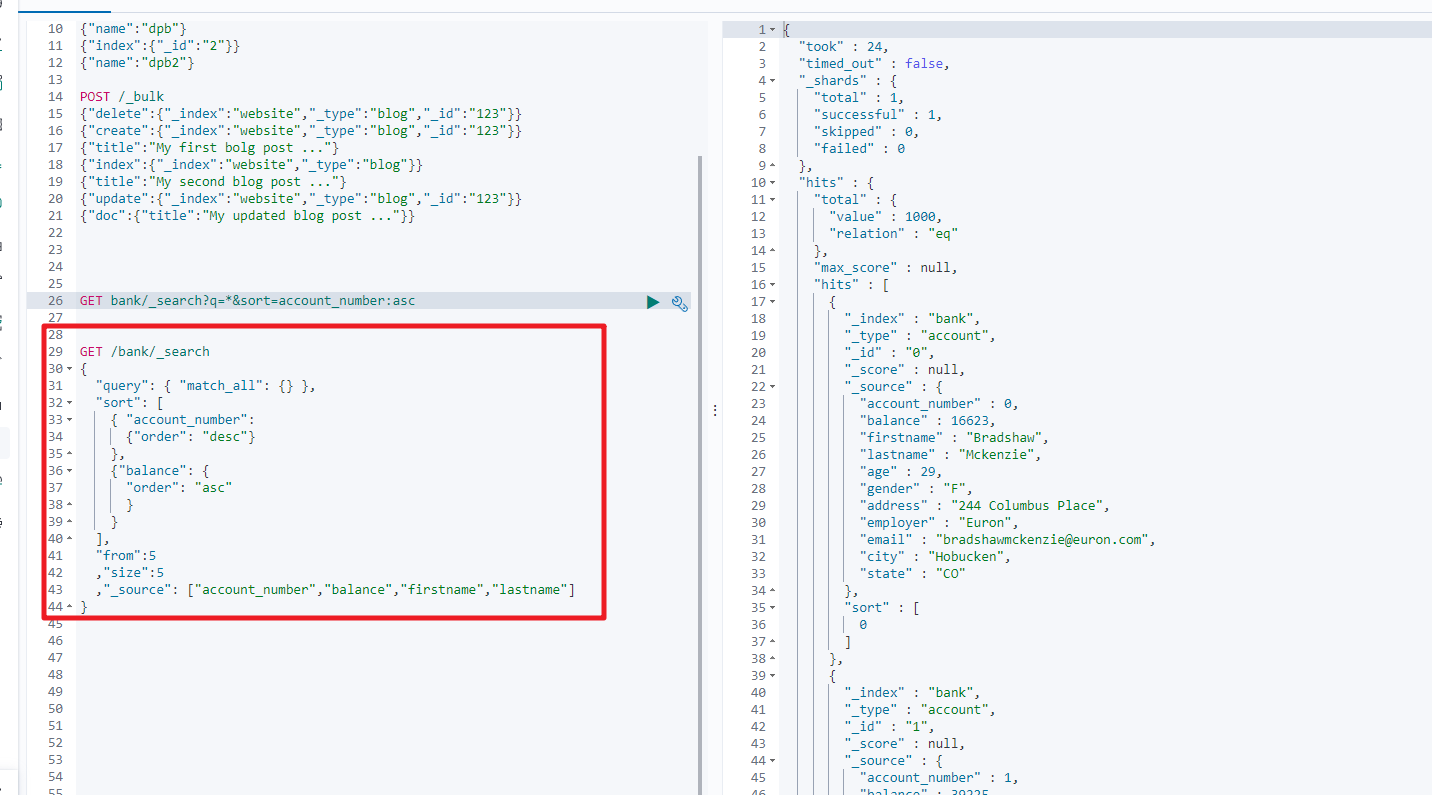
第二种方式
通过使用 REST request body 来反射检索参数 (uri+请求体)
GET bank/_search
{"query":{"match_all":{}},"sort":[{"account_number":"desc" }]
}
2.Query DSL
2.1 基本语法
ElasticSearch提供了一个可以执行的JSON风格的DSL(domain-specific language 领域特定语言),这个被称为Query DSL,该查询语言非常全面,并且刚开始的时候感觉有点复杂,真正学好它的方法就是从一些基础案例开始的。
完整的语法结构
{QUERY_NAME:{ARGUMENT:VALUE,ARGUMENT:VALUE,...}
}
如果是针对某个字段,那么它的结构为
{QUERY_NAME:{FIELD_NAME:{ARGUMENT:VALUE,ARGUMENT:VALUE,...}}
}
2.2 match
上面我们用到来的match_all是匹配所有的数据,而我们现在要讲的match是条件匹配
如果对应的字段是基本类型(非字符串类型),则是精确匹配。
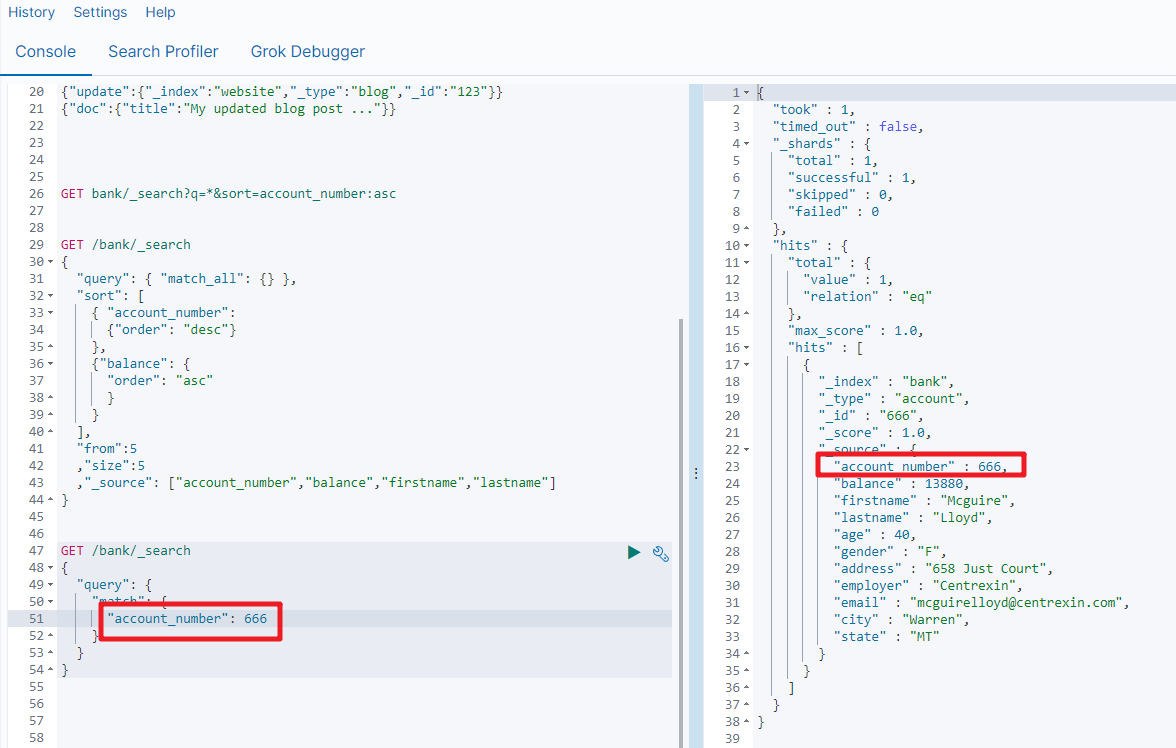
GET bank/_search
{"query":{"match":{"account_number":20}}
}
match返回的是 account_number:20的记录
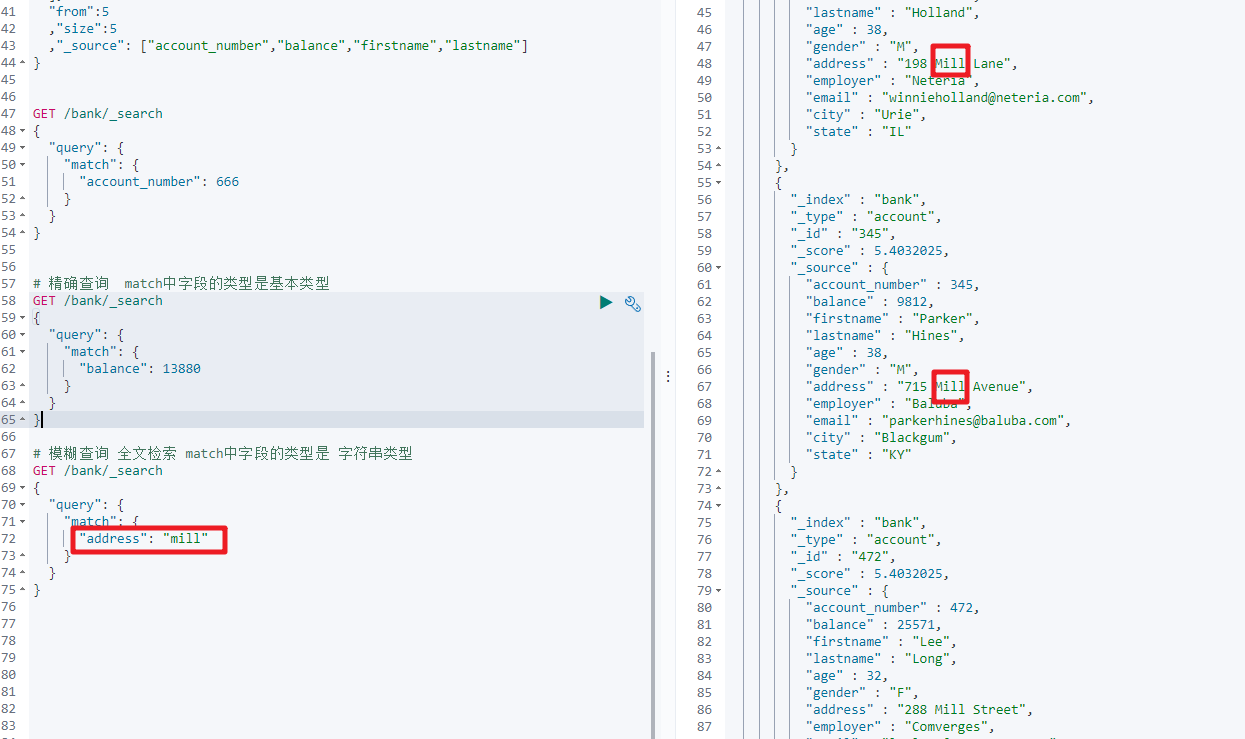
如果对应的字段是字符串类型,则是全文检索
GET bank/_search
{"query":{"match":{"address":"mill"}}
}
match返回的就是address中包含mill字符串的记录
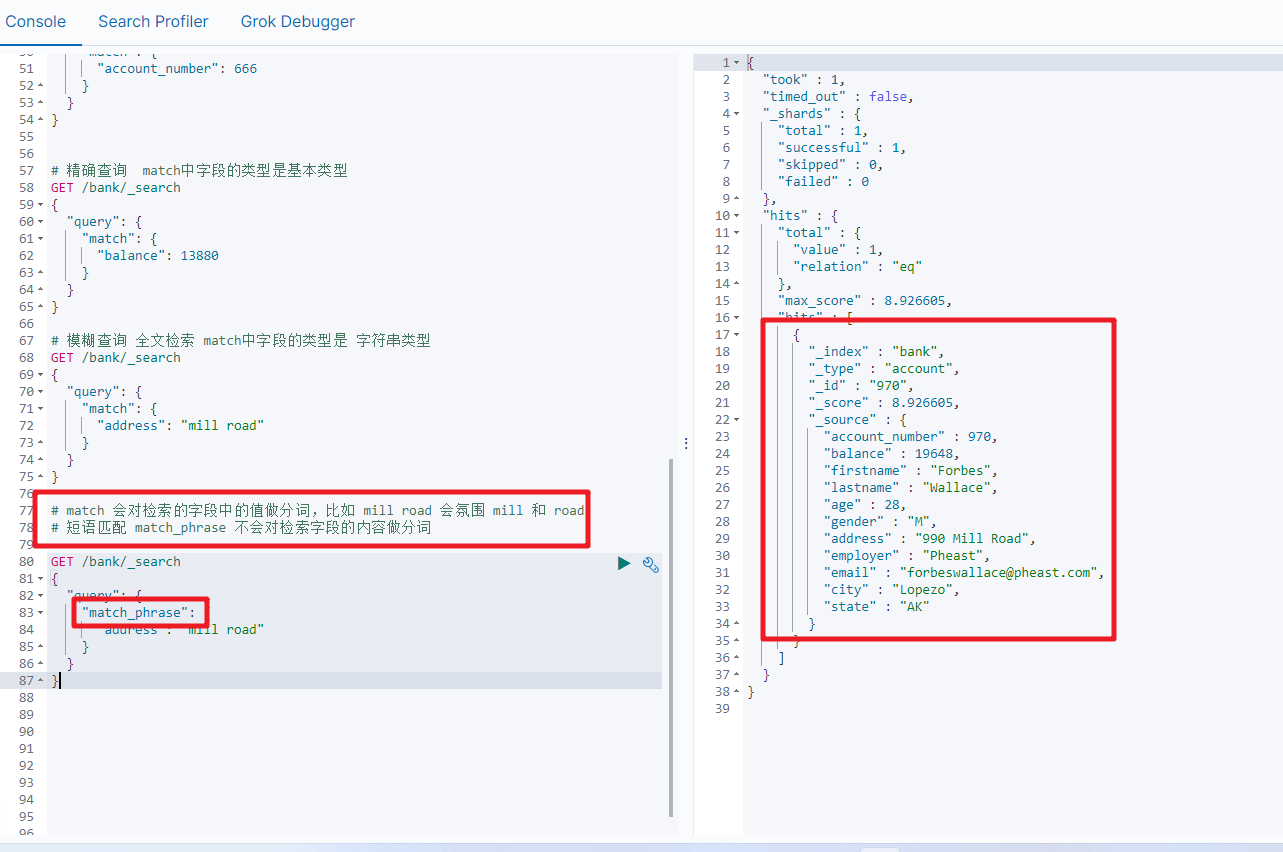
2.3 match_phrase
将需要匹配的值当成一个整体单词(不分词)进行检索,短语匹配
GET bank/_search
{"query":{"match_phrase":{"address":"mill road"}}
}
查询出address中包含 mill road的所有记录,并给出相关性得分
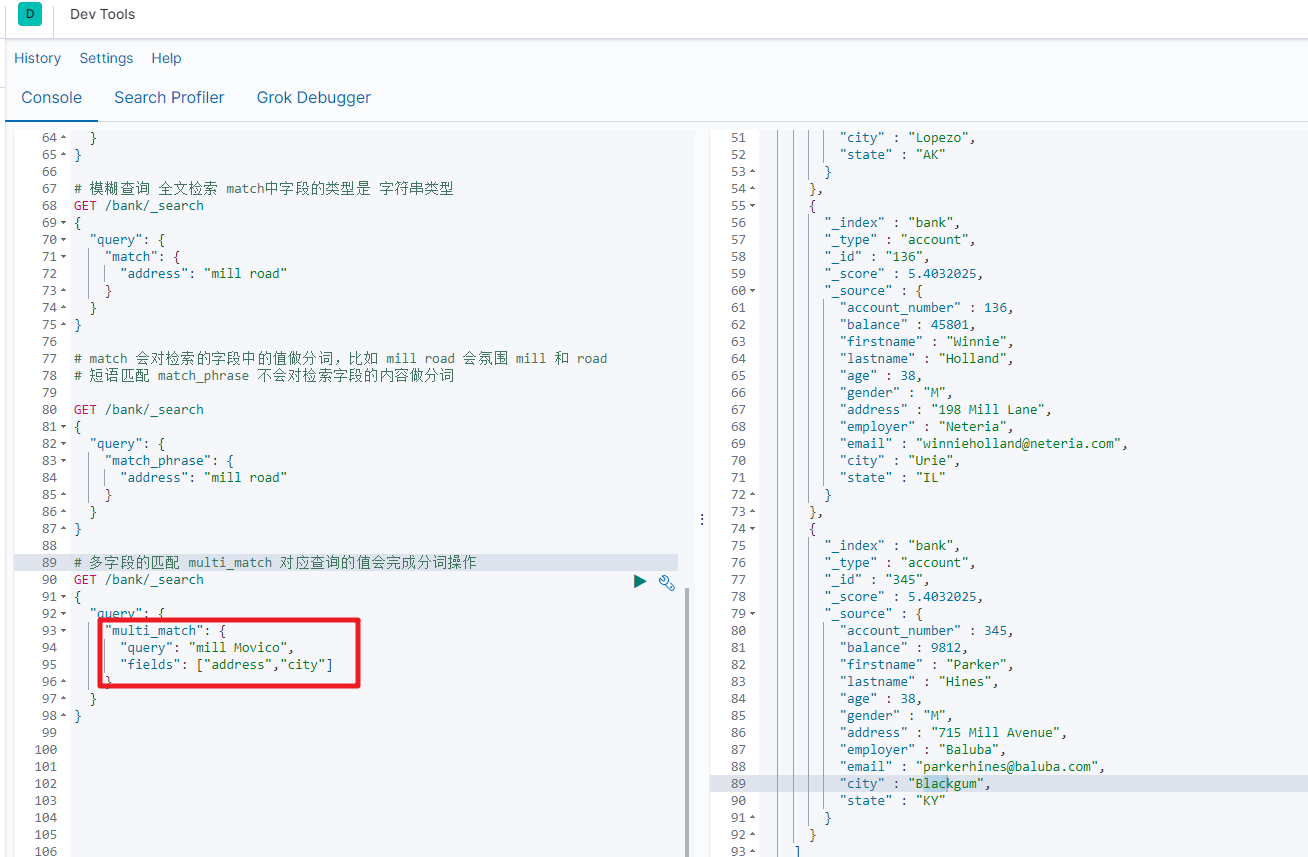
2.4 multi_match[多字段匹配]
GET bank/_search
{"query":{"multi_match":{"query":"mill road","fields":["address","state"]}}
}
查询出state或者address中包含 mill road的记录
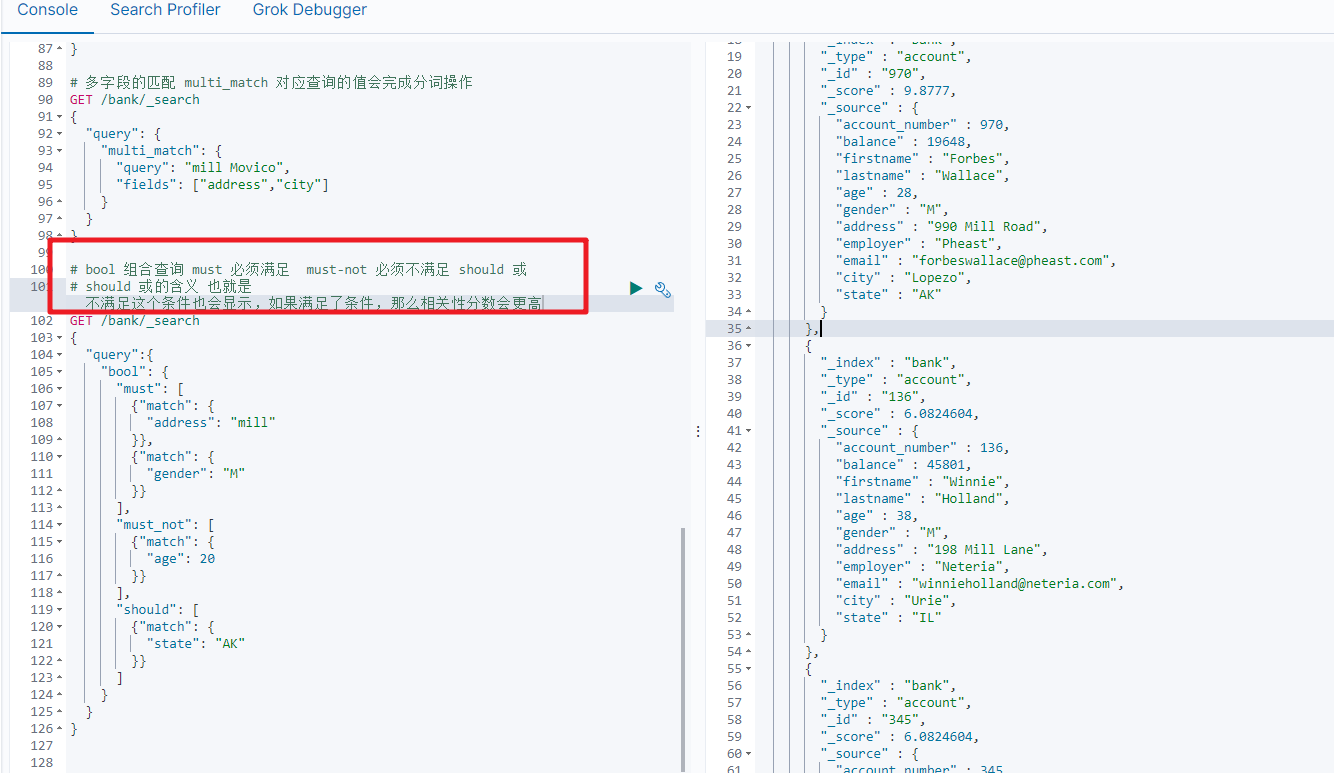
2.5 bool[复合查询]
布尔查询又叫组合查询,bool用来实现复合查询,
bool把各种其它查询通过 must(与)、must_not(非)、should(或)的方式进行组合
复合语句可以合并任何其他查询语句,包括复合语句也可以合并,了解这一点很重要,这意味着,复合语句之间可以相互嵌套,可以表达非常复杂的逻辑。
GET /bank/_search
{"query": {"bool": {"must": [{ "match": { "age": "40" } }],"must_not": [{ "match": { "state": "ID" } }]}}
}
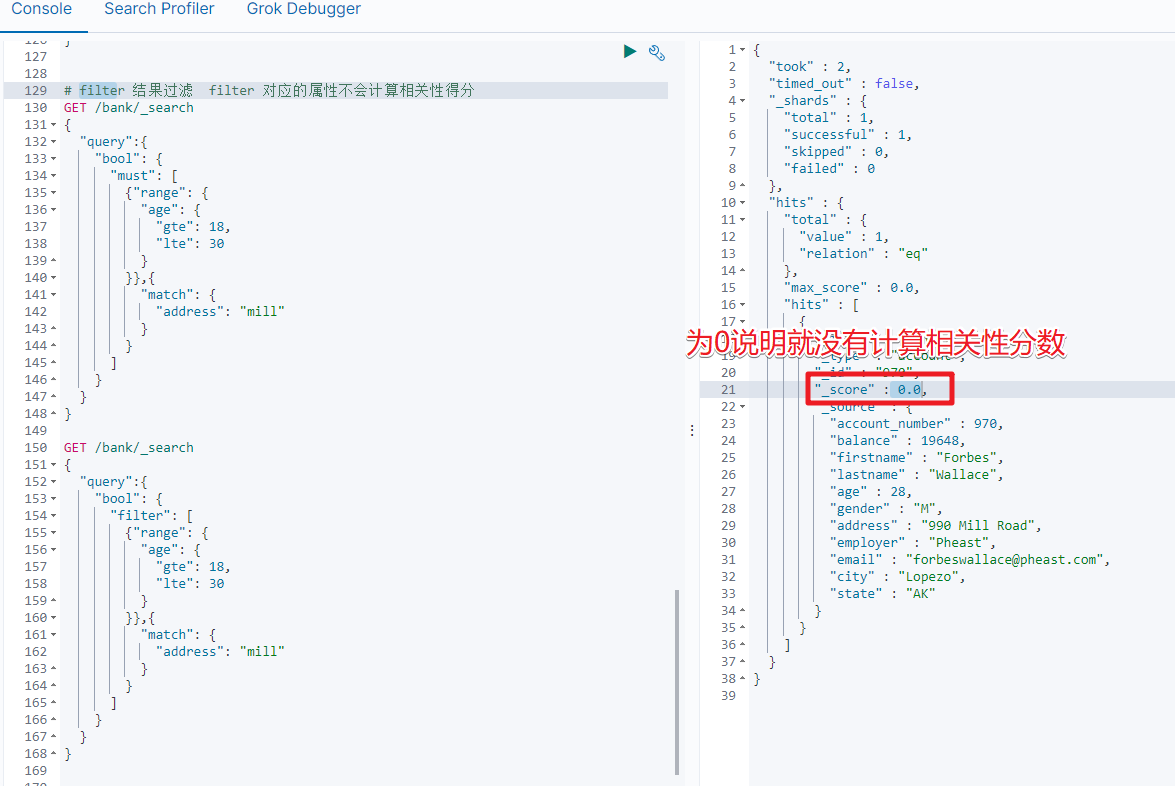
2.6 filter[结果过滤]
并不是所有的查询都需要产生分数,特别是那些仅用于"filtering"的文档,为了不计算分数,ElasticSearch会自动检查场景并且优化查询的执行。
GET /bank/_search
{"query": {"bool": {"must": { "match_all": {} },"filter": {"range": {"balance": {"gte": 20000,"lte": 30000}}}}}
}
2.7 term
和match一样,匹配某个属性的值,全文检索字段用match,其他非text字段匹配用term
GET bank/_search
{"query":{"term":{"account_number":20}}
}
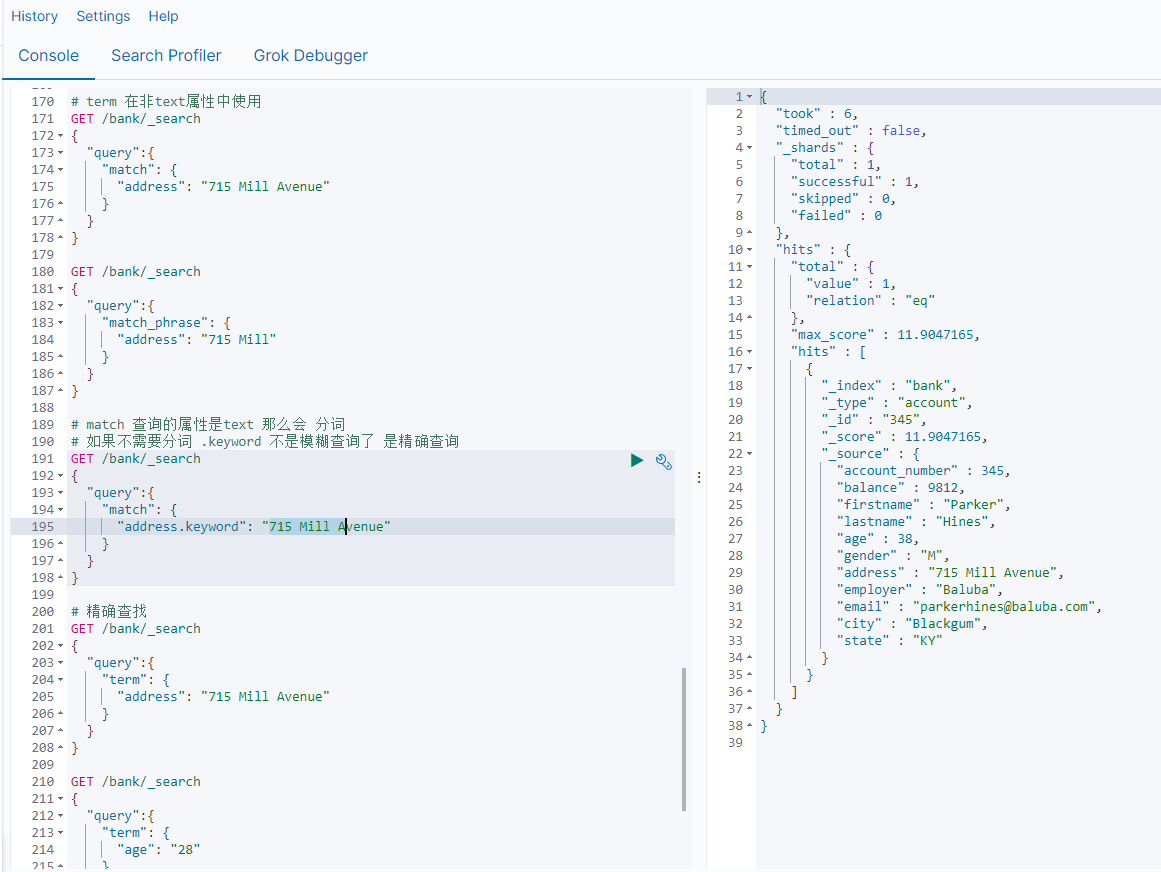
| 检索关键字 | 描述 |
|---|---|
| term | 非text使用 |
| match | 在text中我们实现全文检索-分词 |
| match keyword | 在属性字段后加.keyword 实现精确查询-不分词 |
| match_phrase | 短语查询,不分词,模糊查询 |
3.聚合(aggregations)
聚合可以让我们极其方便的实现对数据的统计、分析。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现实时搜索效果。
语法规则
"aggregations" : {"<aggregation_name>" : {"<aggregation_type>" : {<aggregation_body>}[,"meta" : { [<meta_data_body>] } ]?[,"aggregations" : { [<sub_aggregation>]+ } ]?}[,"<aggregation_name_2>" : { ... } ]*
}
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/search-aggregations.html
3.1 基本概念
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫 桶,一个叫 度量:
桶(bucket)
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个 桶,例如我们根据国籍对人划分,可以得到 中国桶、英国桶,日本桶……或者我们按照年龄段对人进行划分:010,1020,2030,3040等。
Elasticsearch中提供的划分桶的方式有很多:
- Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
- Histogram Aggregation:根据数值阶梯分组,与日期类似
- Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
- Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
- ……
bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为 度量
比较常用的一些度量聚合方式:
- Avg Aggregation:求平均值
- Max Aggregation:求最大值
- Min Aggregation:求最小值
- Percentiles Aggregation:求百分比
- Stats Aggregation:同时返回avg、max、min、sum、count等
- Sum Aggregation:求和
- Top hits Aggregation:求前几
- Value Count Aggregation:求总数
- ……
3.2 案例讲解
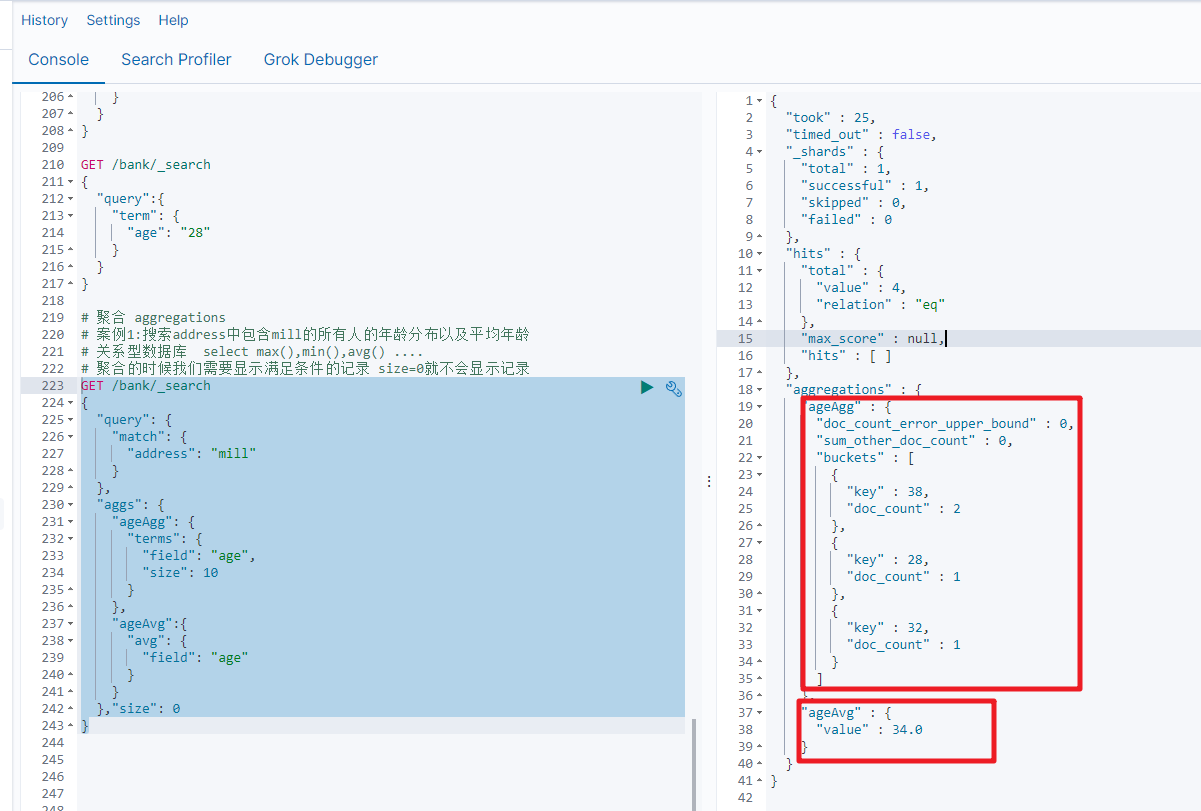
案例1:搜索address中包含mill的所有人的年龄分布以及平均年龄
GET /bank/_search
{"query": {"match": {"address": "mill"}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 10}},"ageAvg":{"avg": {"field": "age"}}},"size": 0
}
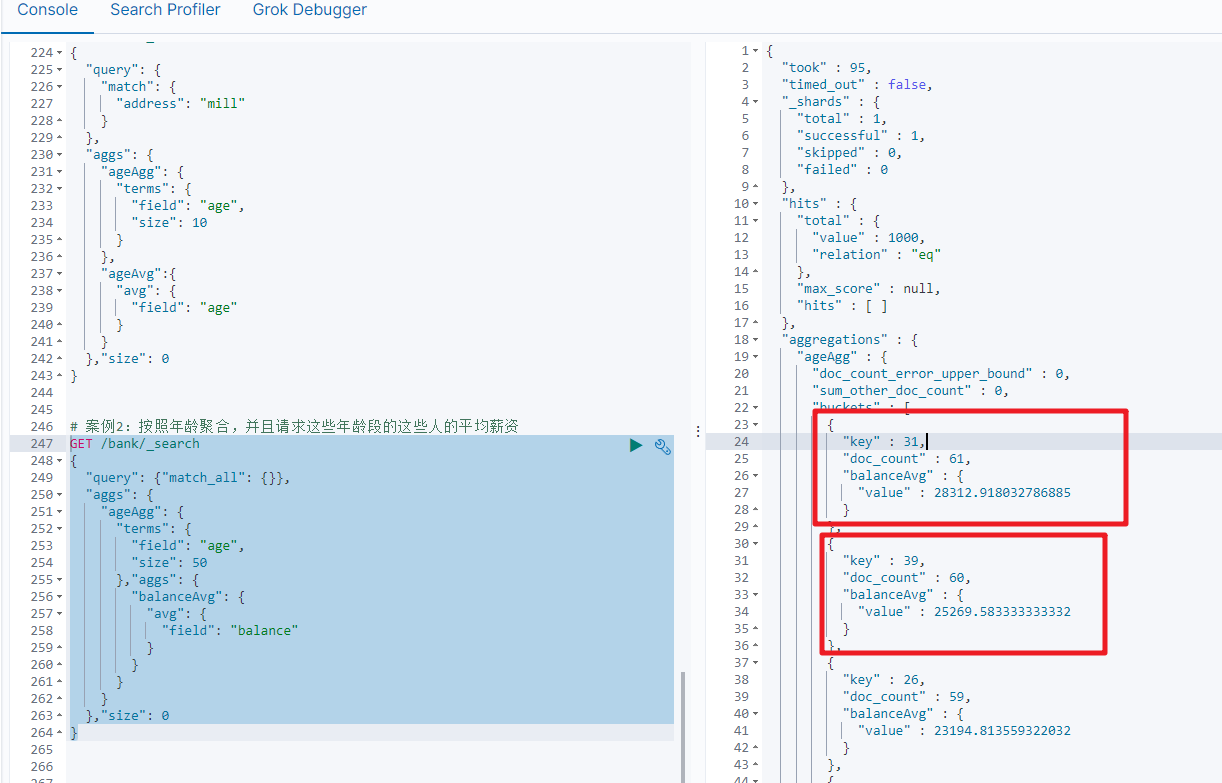
案例2:按照年龄聚合,并且请求这些年龄段的这些人的平均薪资
GET /bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 50},"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}}},"size": 0
}
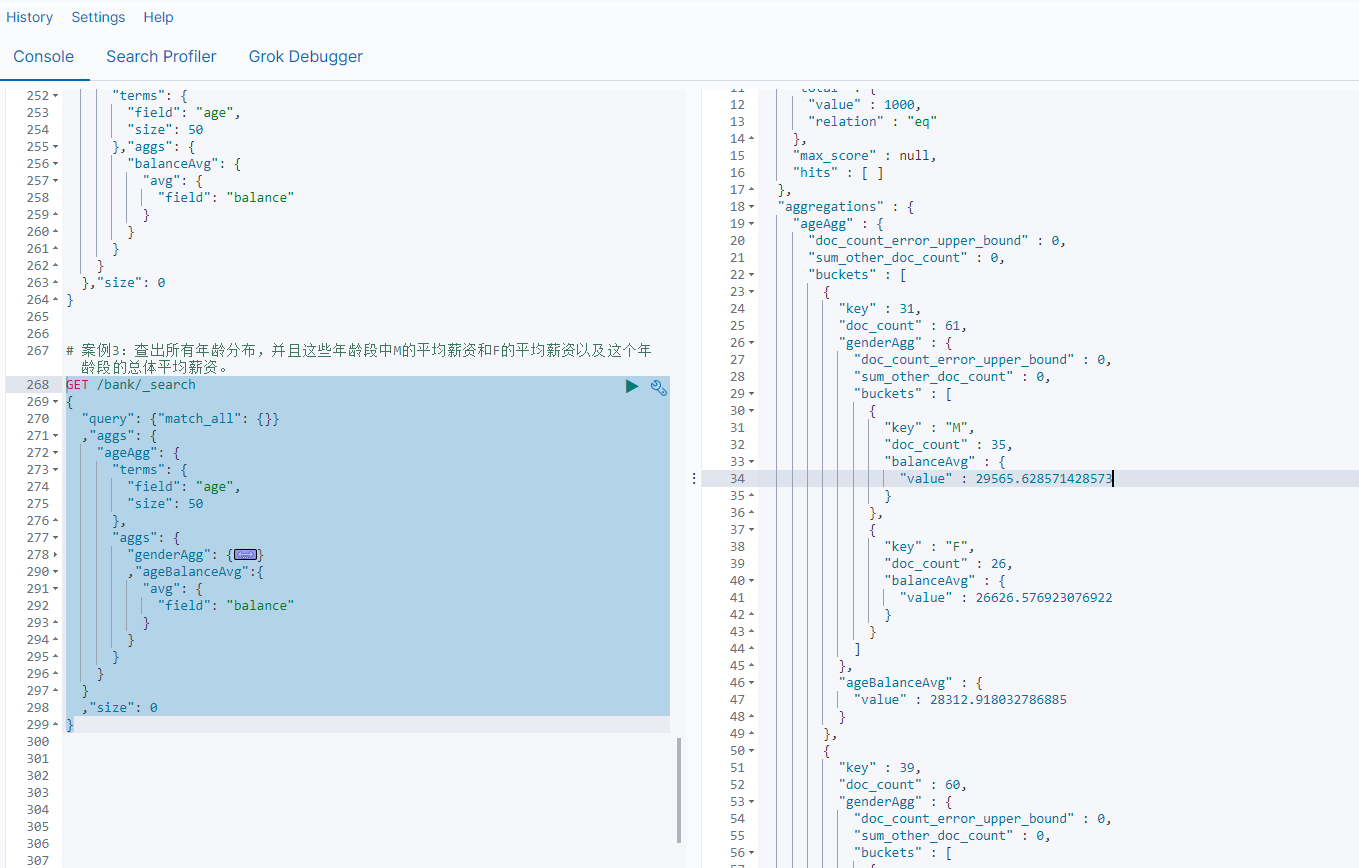
案例3:查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资。
GET /bank/_search
{"query": {"match_all": {}},"aggs": {"ageAgg": {"terms": {"field": "age","size": 50},"aggs": {"genderAgg": {"terms": {"field": "gender.keyword","size": 10},"aggs": {"balanceAvg": {"avg": {"field": "balance"}}}},"ageBalanceAvg":{"avg": {"field": "balance"}}}}},"size": 0
}
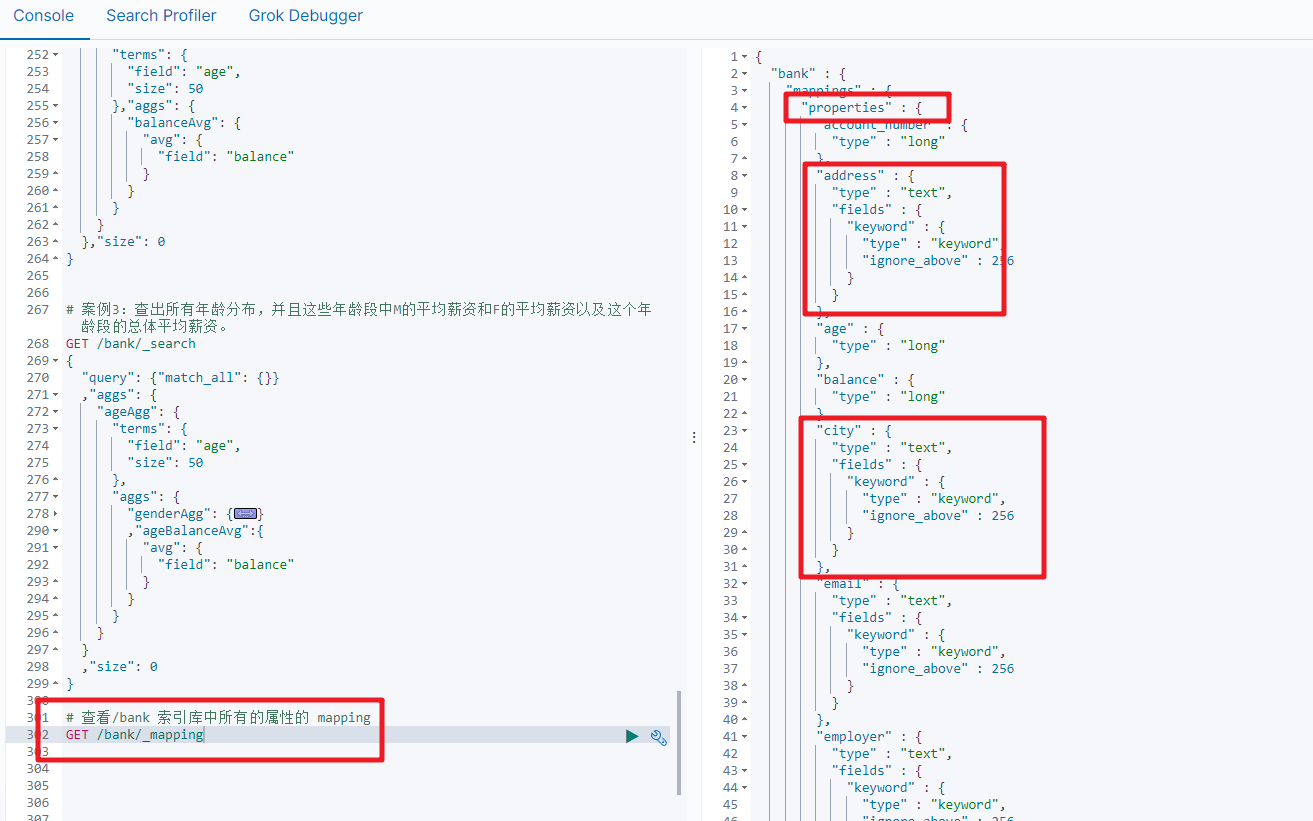
4.映射配置(_mapping)
查看索引库中所有的属性的_mapping
4.1 ElasticSearch7-去掉type概念:
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。
两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type就是为了提高ES处理数据的效率。
Elasticsearch 7.x
URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.x
不再支持URL中的type参数。
解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引
4.2 什么是映射?
映射是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等
4.3 创建映射字段
PUT /索引库名/_mapping/类型名称
{"properties": {"字段名": {"type": "类型","index": true,"store": true,"analyzer": "分词器"}}
}
类型名称:就是前面将的type的概念,类似于数据库中的不同表
字段名:类似于列名,properties下可以指定许多字段。
每个字段可以有很多属性。例如:
- type:类型,可以是text、long、short、date、integer、object等
- index:是否索引,默认为true
- store:是否存储,默认为false
- analyzer:分词器,这里使用ik分词器:
ik_max_word或者ik_smart
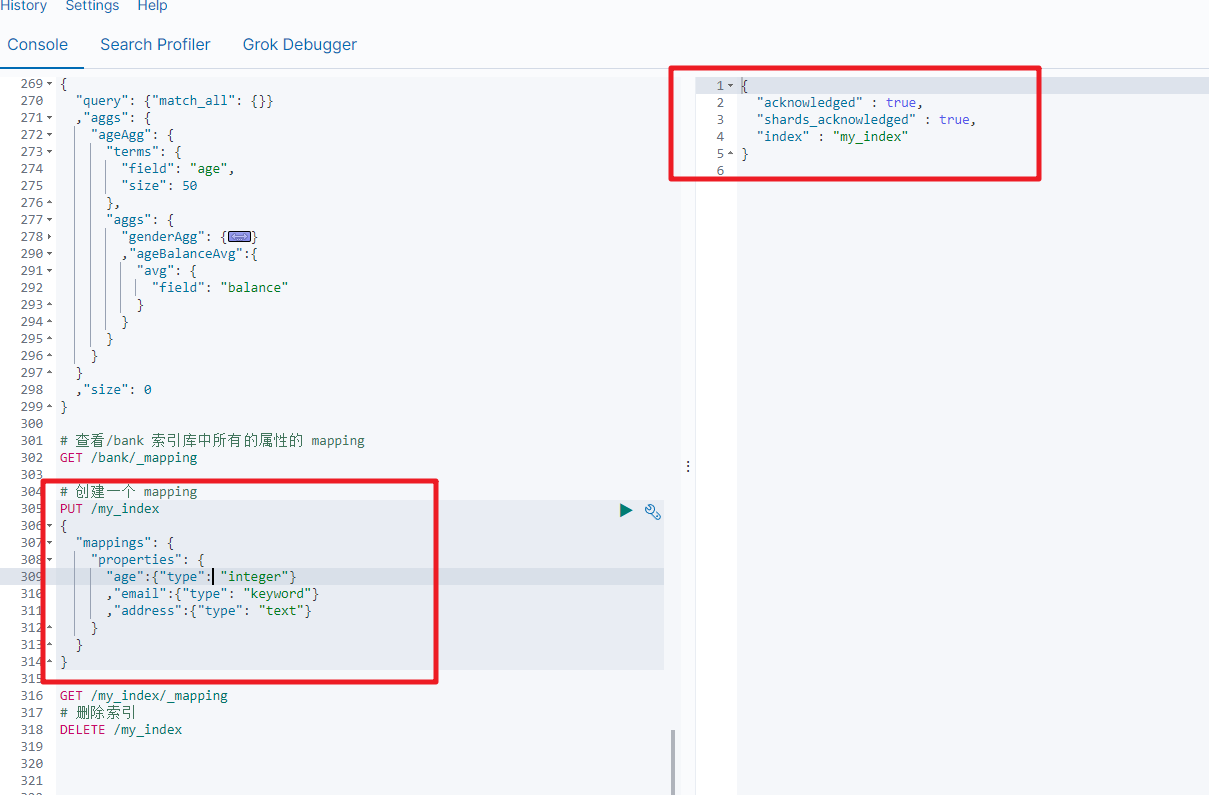
4.4 新增映射字段
如果我们创建完成索引的映射关系后,又要添加新的字段的映射,这时怎么办?第一个就是先删除索引,然后调整后再新建索引映射,还有一个方式就在已有的基础上新增。
PUT /my_index/_mapping
{"properties":{"employee-id":{"type":"keyword","index":false}}
}
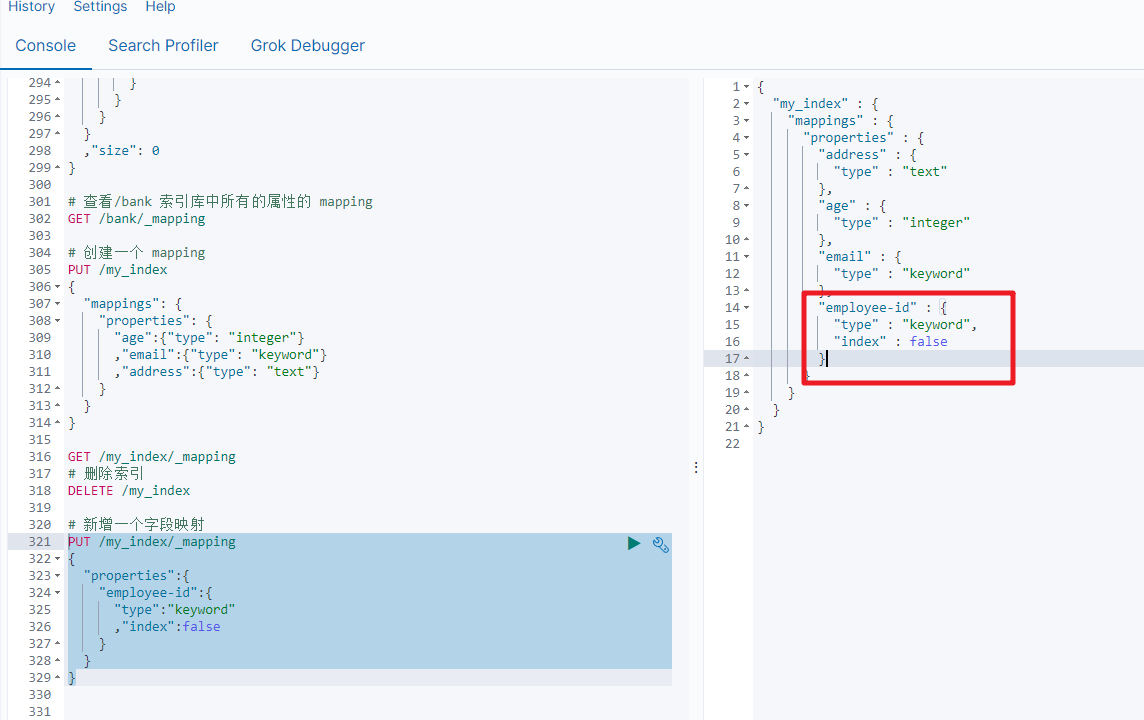
4.5 更新映射
对于存在的映射字段,我们不能更新,更新必须创建新的索引进行数据迁移
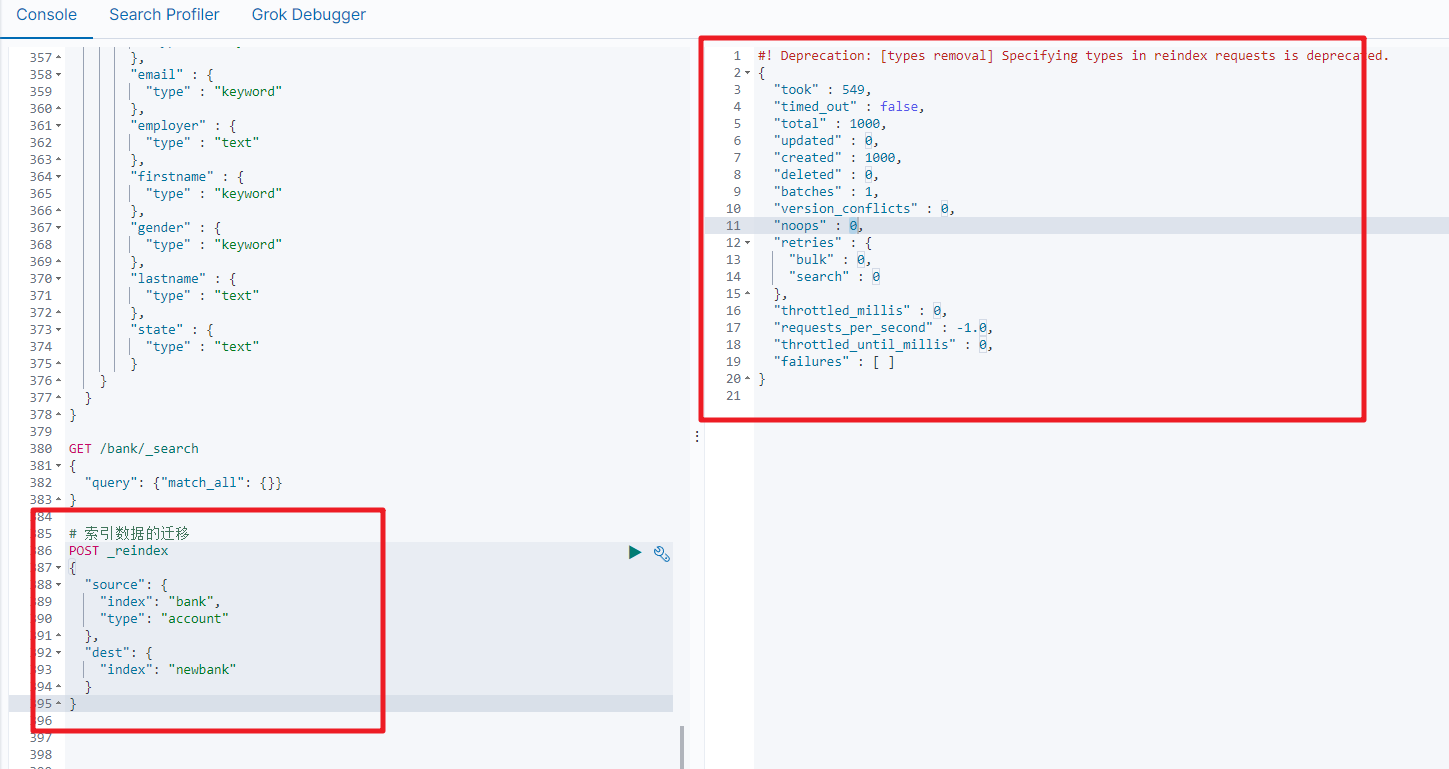
4.6 数据迁移
先创建出正确的索引,然后使用如下的方式来进行数据的迁移
| POST_reindex [固定写法] { “source”:{ “index”:“twitter” }, “dest”:{ “index”:“new_twitter” } } |
|---|
老的数据有type的情况
| POST_reindex [固定写法] { “source”:{ “index”:“twitter”, “type”:“account” }, “dest”:{ “index”:“new_twitter” } } |
|---|
案例:新创建了索引,并指定了映射属性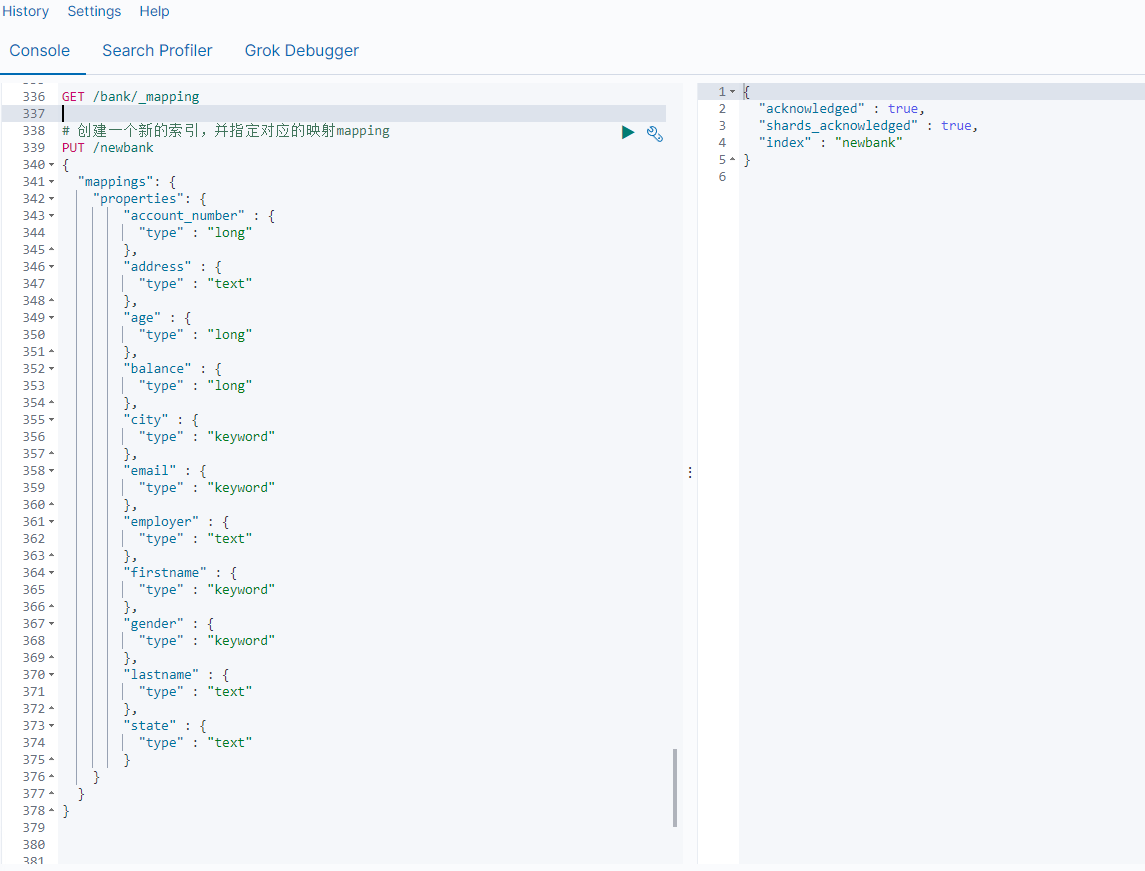
5.分词
所谓的分词就是通过tokenizer(分词器)将一个字符串拆分为多个独立的tokens(词元-独立的单词),然后输出为tokens流的过程。
例如"my name is HanMeiMei"这样一个字符串就会被默认的分词器拆分为[my,name,is HanMeiMei].ElasticSearch中提供了很多默认的分词器,我们可以来演示看看效果
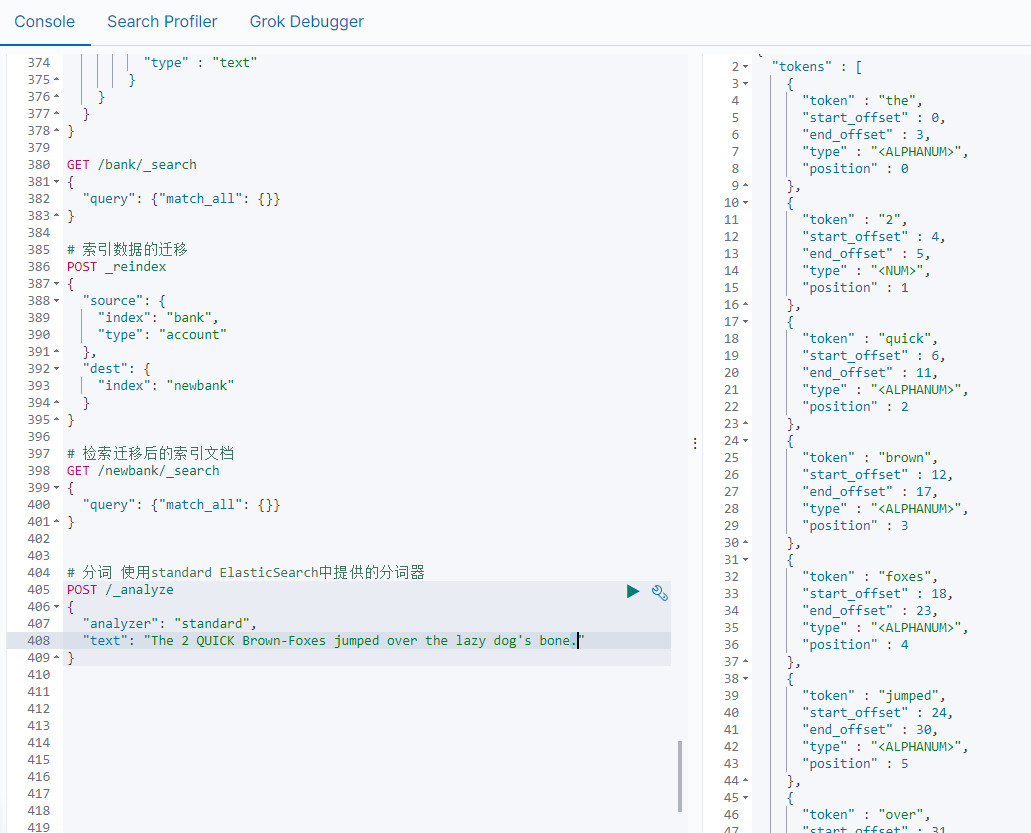
但是在ElasticSearch中提供的分词器对中文的分词效果都不好。
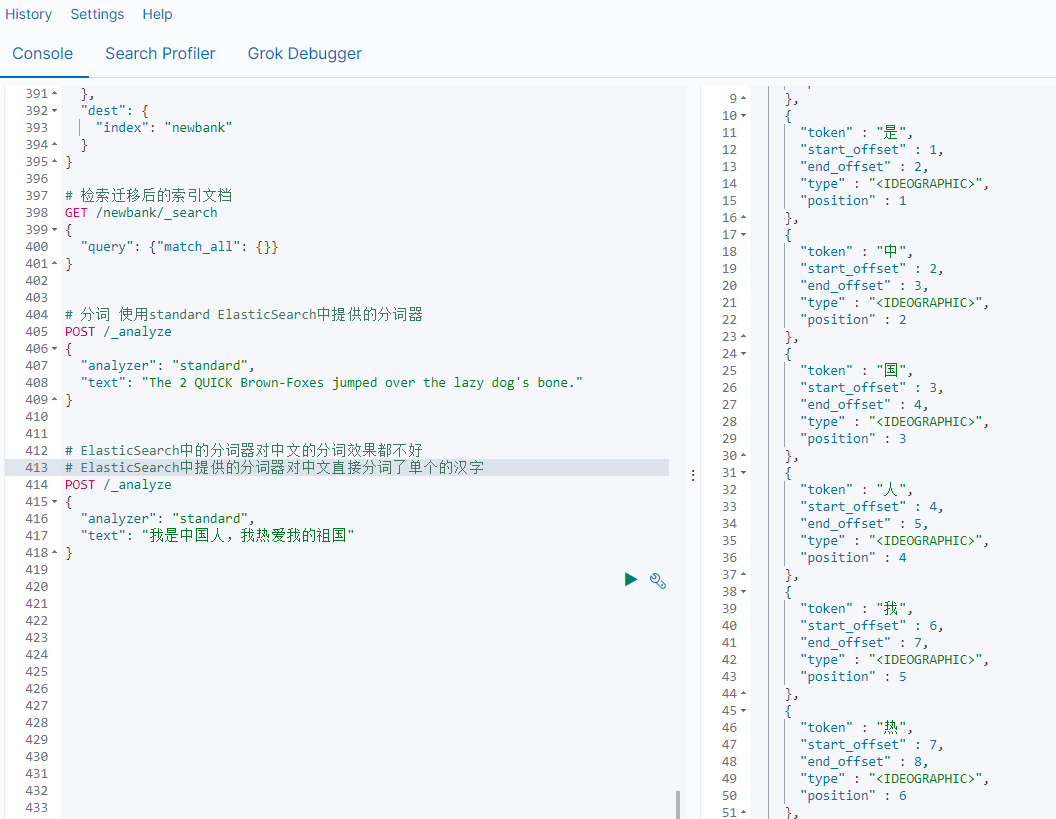
所以这时我们就需要安装特定的分词器 IK
1) 安装ik分词器
https://github.com/medcl/elasticsearch-analysis-ik 下载对应的版本,然后解压缩到plugins目录中
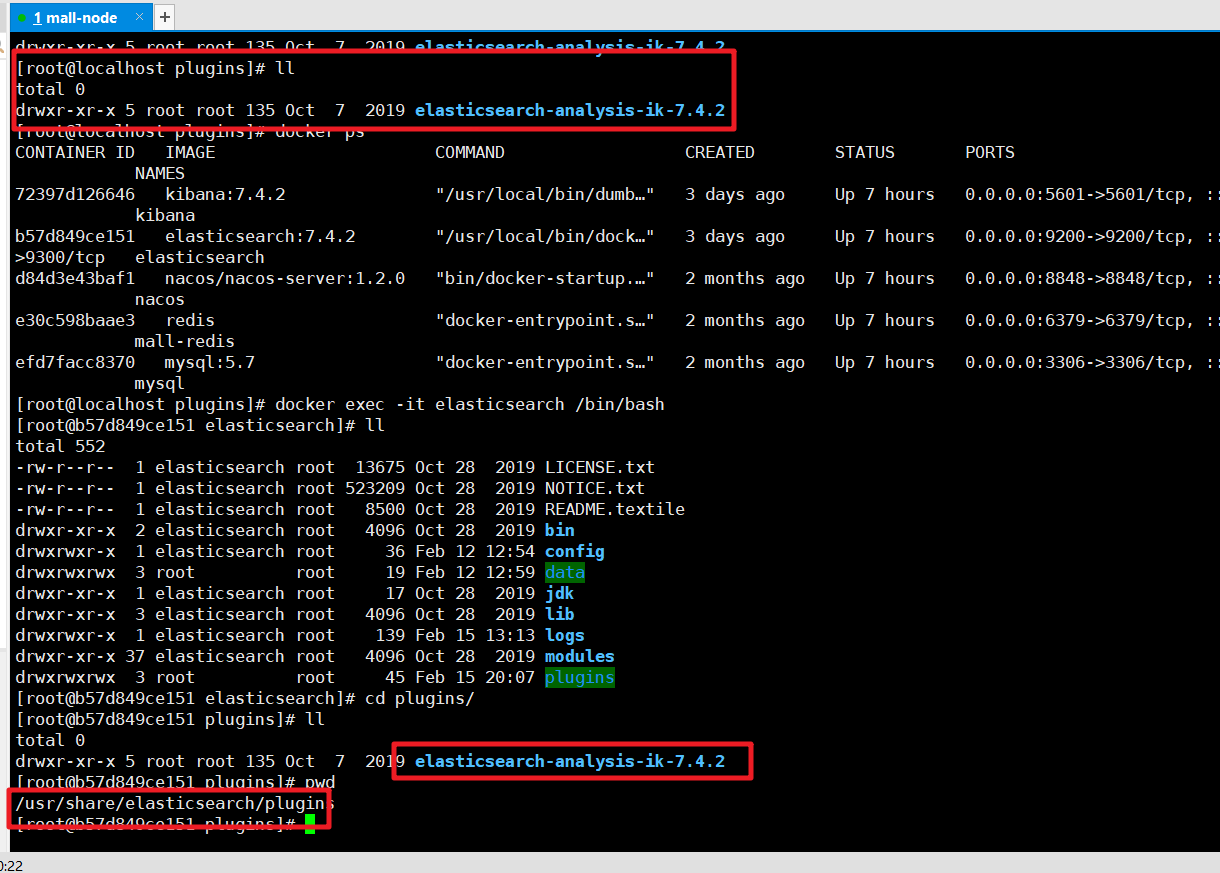
然后检查是否安装成功:进入容器 通过如下命令来检测
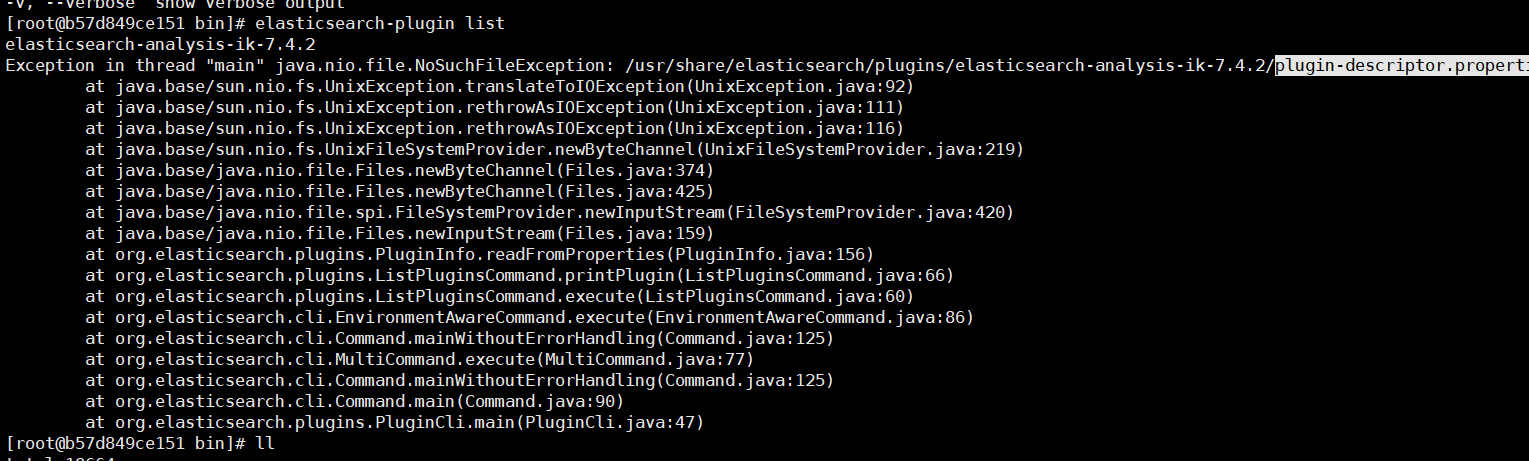
检查下载的文件是否完整,如果不完整就重新下载。

插件安装OK后我们重新启动ElasticSearch服务
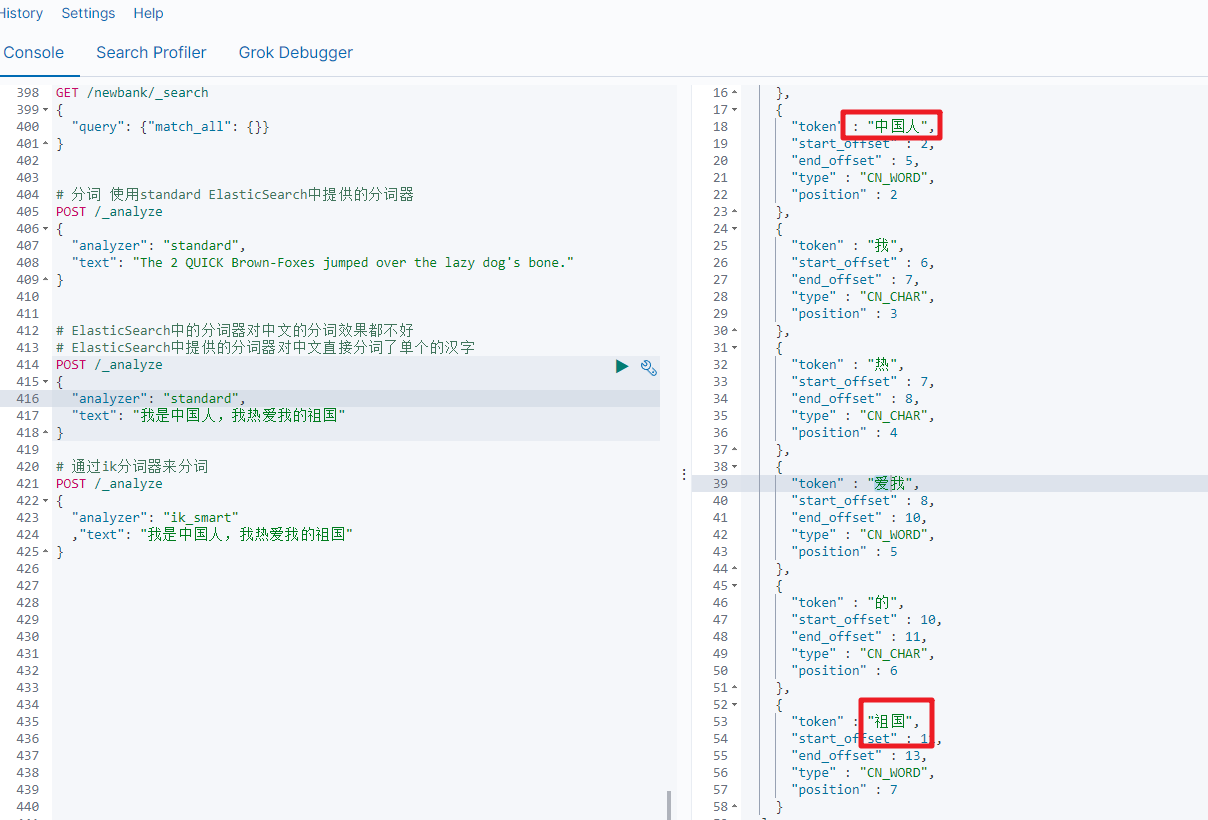
2) ik分词演示
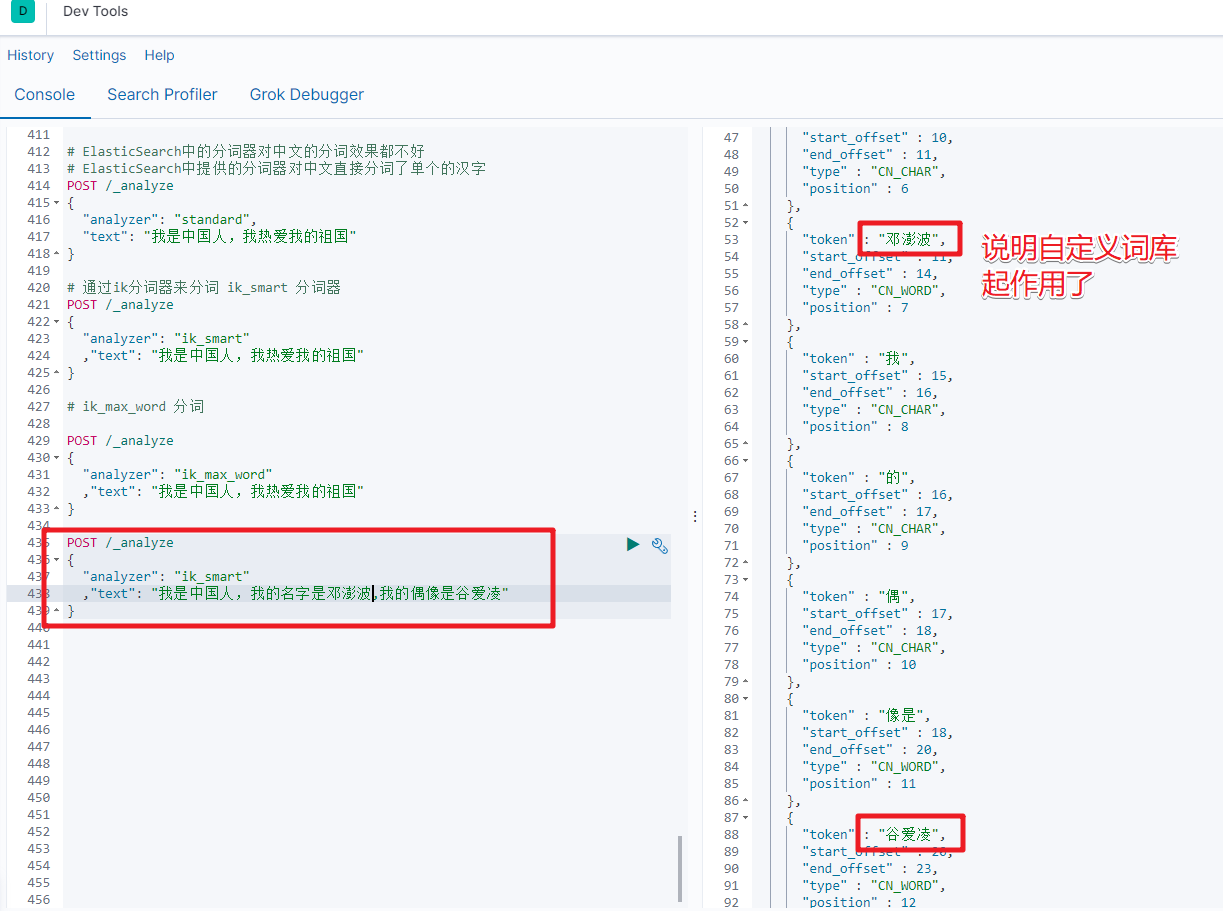
ik_smart分词
# 通过ik分词器来分词
POST /_analyze
{"analyzer": "ik_smart","text": "我是中国人,我热爱我的祖国"
}
ik_max_word
POST /_analyze
{"analyzer": "ik_max_word","text": "我是中国人,我热爱我的祖国"
}
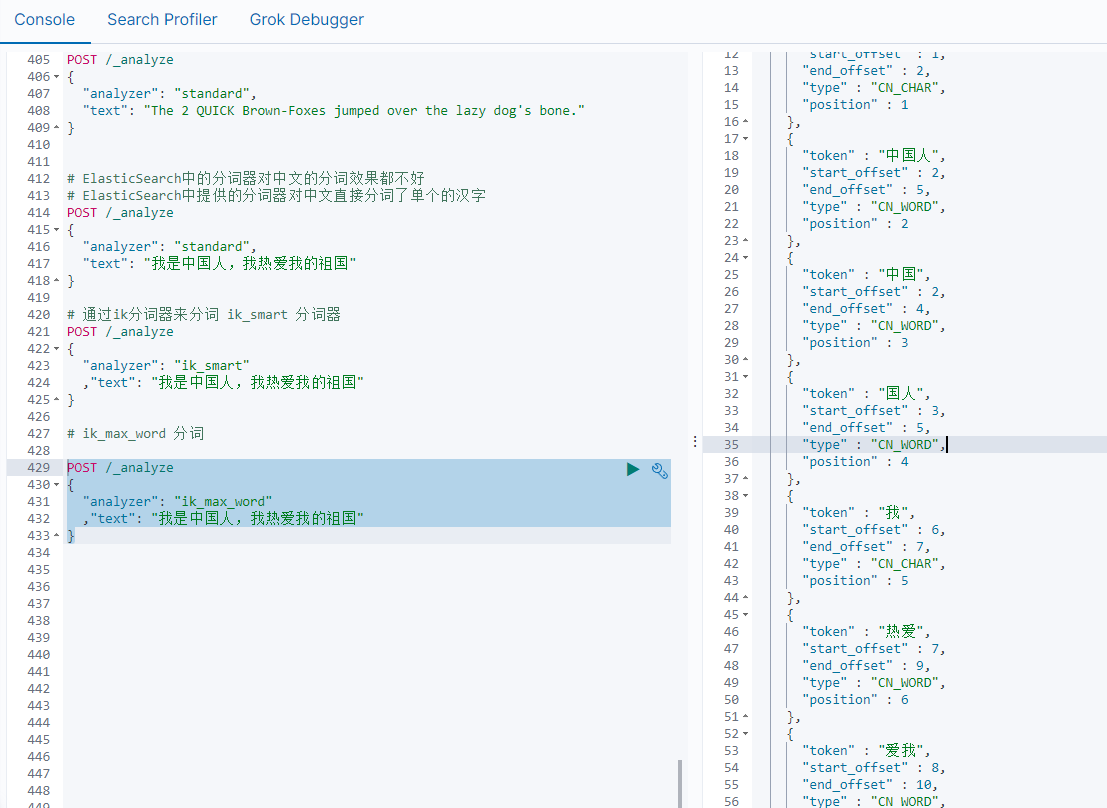
通过ik分词器的使用我们发现:如果使用ElasticSearch中默认提供的分词器是不支持中文分词的,也就是我们在定义一个索引的使用不能使用默认的mapping,而是要手动的来建立对应的mapping,在mapping我们需要选择对应的分词器。
3) 自定义词库
虚拟机扩容
安装的软件越来越多,虚拟机的空间有限,这时我们可以关闭虚拟机后扩容

ElasticSearch中原来分配的空间比较小,虚拟机空间增大后我们可以调整ElasticSearch的空间。
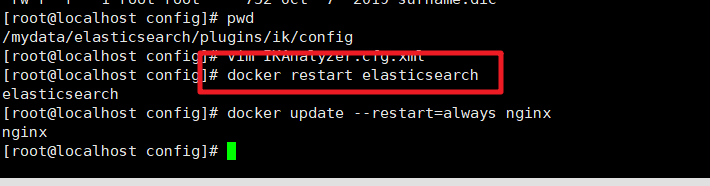
调整ElasticSearch的虚拟机内存,我们没办法直接修改,需要先删除原来的容器,然后创建新的容器。
调整JVM参数后重新启动容器:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \-e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx512m" -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2
Nginx安装
先安装一个简单的Nginx实例,来获取对应的配置信息
拉取Nginx的镜像
启动Nginx服务
docker run -d -p 80:80 --name nginx nginx:1.10
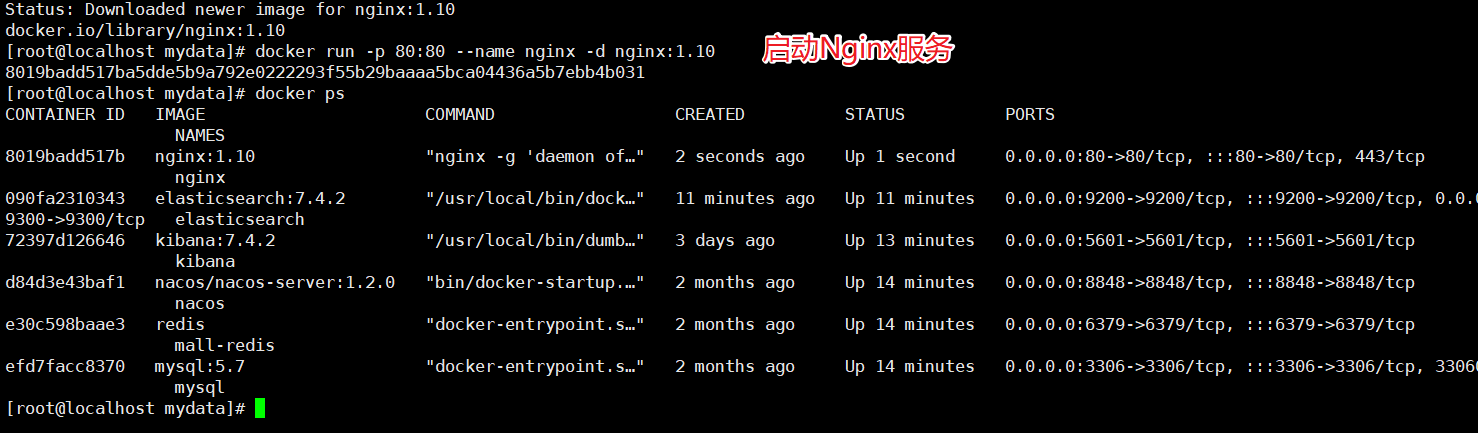
把容器中的配置文件拷贝到/mydata/nginx目录中
docker container cp nginx:/etc/nginx .
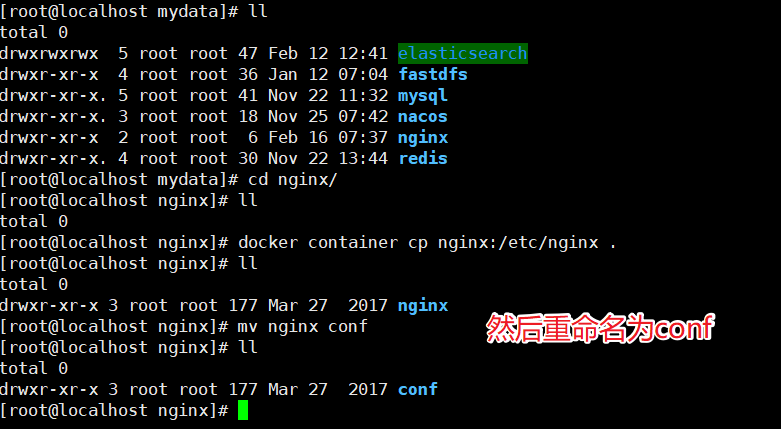
有了这个对应的配置文件夹后我们就可以删除掉之前的Nginx服务了
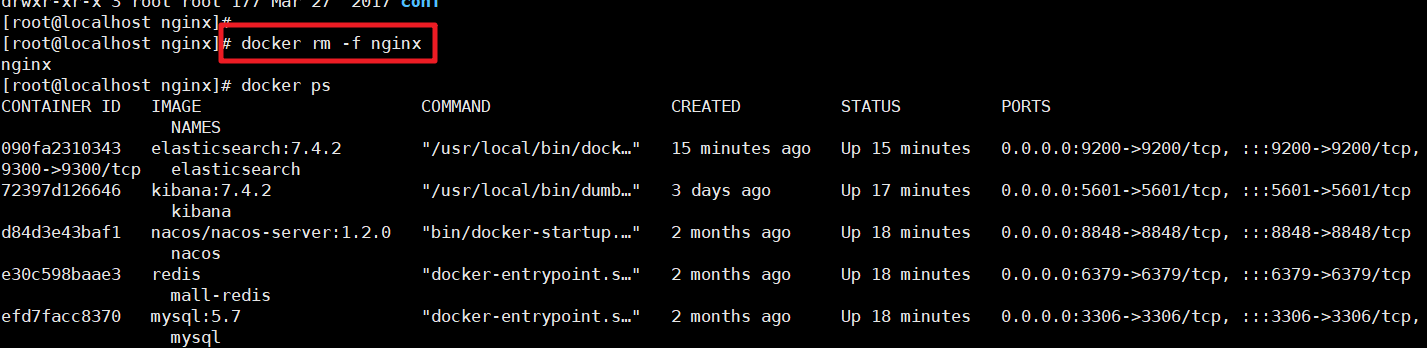
然后创建新的Nginx服务
docker run -d -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
nginx:1.10
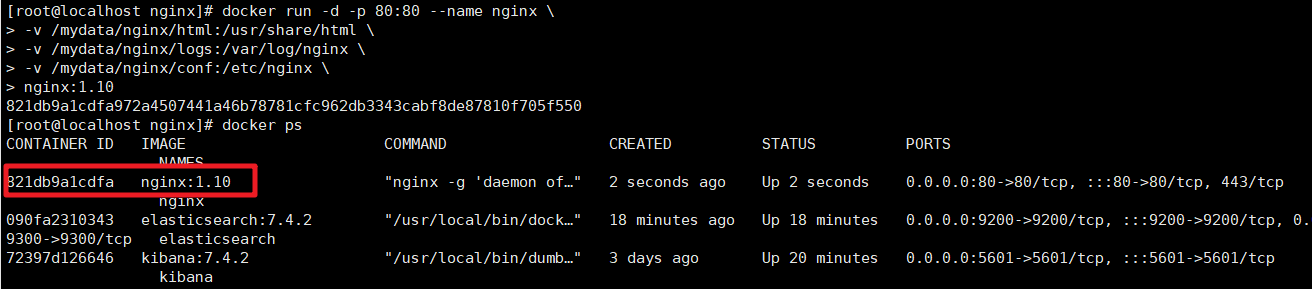
测试访问:
实现自定义词库
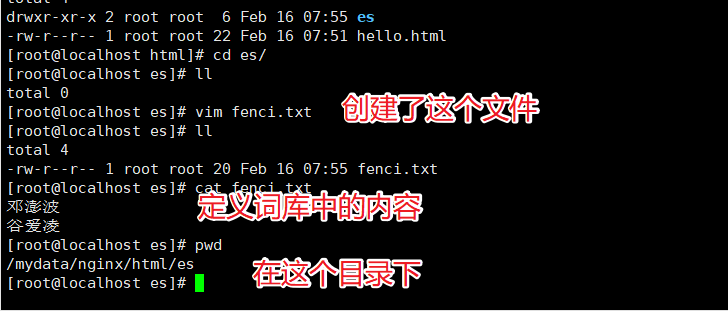
我们需要在Nginx中创建对应的词库文件
然后我们在ik分词器的插件的配置文件中修改远程词库的地址
/mydata/elasticsearch/plugins/ik/config
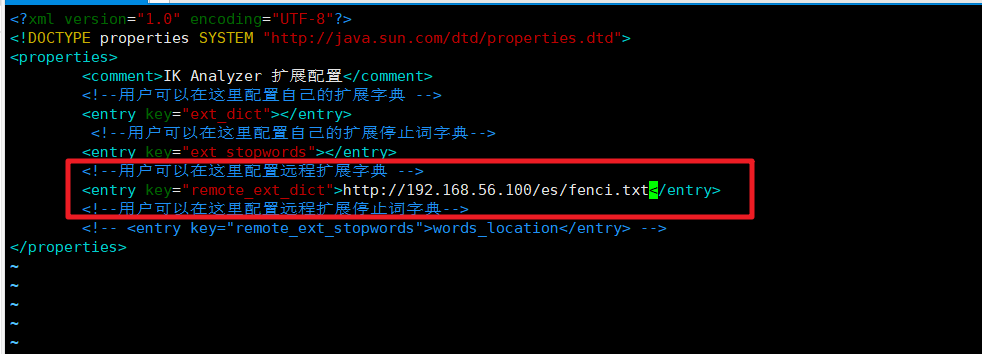
然后保存文件重启ElasticSearch服务即可
然后在Kibana中检索测试即可
相关文章:
【业务功能篇82】微服务SpringCloud-ElasticSearch-Kibanan-docke安装-进阶实战
四、ElasticSearch进阶 https://www.elastic.co/guide/en/elasticsearch/reference/7.4/getting-started-search.html 1.ES中的检索方式 在ElasticSearch中支持两种检索方式 通过使用REST request URL 发送检索参数(uri检索参数)通过使用 REST request body 来发送检索参数…...

【工具】XML和JSON互相转换
1、JSON解析为XML function parseJSONToXML(json) {let xmlDoc document.implementation.createDocument(null, );function parseValue(value, parentElement) {if (Array.isArray(value)) {for (let item of value) {let arrayElement xmlDoc.createElement(parentElement.…...

前端面试:【浏览器与渲染引擎】Web APIs - DOM、XHR、Fetch、Canvas
嗨,亲爱的读者!当我们在浏览器中浏览网页时,我们常常会与各种Web API打交道。这些API允许我们与网页内容、服务器资源和图形进行交互。本文将深入探讨一些常见的Web API,包括DOM、XHR、Fetch和Canvas,以帮助你了解它们…...

编码基础一:侵入式链表
一、简介概述 1、普通链表数据结构 每个节点的next指针指向下一个节点的首地址。这样会有如下的限制: 一条链表上的所有节点的数据类型需要完全一致。对某条链表的操作如插入,删除等只能对这种类型的链表进行操作,如果链表的类型换了&#…...

深圳IT行业供需:蓬勃发展的科技中心
深圳作为中国的科技中心之一,IT行业在这座城市蓬勃发展。本文将探讨深圳IT行业的供需状况,包括就业机会、技能需求以及行业前景展望。 近年来,深圳IT行业迅速发展,成为全球科技创新的重要枢纽之一。随着大量的科技企业和初创公司在…...

LeetCode 面试题 02.01. 移除重复节点
文章目录 一、题目二、C# 题解 一、题目 编写代码,移除未排序链表中的重复节点。保留最开始出现的节点。 点击此处跳转题目。 示例1: 输入:[1, 2, 3, 3, 2, 1] 输出:[1, 2, 3] 示例2: 输入:[1, 1, 1, 1, 2] 输出:[1, …...

【Java8特性】——Stream API
一、概述 <1> 是什么 是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。 Stream 不会存储数据Stream 不会改变数据源,相反,会返回一个持有结果的新Stream。Stream 操作是延迟执行的,这意…...

grep命令的用法
文章目录 前言一、使用说明二、应用举例 前言 grep 命令用于查找文件里符合条件的字符串。 一、使用说明 -r: 如果需要搜索目录中的文件内容, 需要进行递归操作, 必须指定该参数 -i: 对应要搜索的关键字, 忽略字符大小写的差别 -n: 在显示符合样式的那一行之前,标…...
【无标题】jenkins消息模板(飞书)
这里写目录标题 Jenkins 安装的插件 发送消息到飞书预览 1 (单Job)预览 2 (多Job,概览) Jenkins 安装的插件 插件名称作用Rebuilder Rebuilder。 官方地址:https://plugins.jenkins.io/rebuild 安装方式&a…...

2023年国赛 高教社杯数学建模思路 - 案例:随机森林
文章目录 1 什么是随机森林?2 随机深林构造流程3 随机森林的优缺点3.1 优点3.2 缺点 4 随机深林算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是随机森林ÿ…...

element Collapse 折叠面板 绑定事件
1. 点击面板触发事件 change <el-collapse accordion v-model"activeNames" change"handleChange"><el-collapse-item title"一致性 Consistency"><div>与现实生活一致:与现实生活的流程、逻辑保持一致,…...

CSS :mix-blend-mode、aspect-ratio
mix-blend-mode 元素的内容应该与元素的直系父元素的内容和元素的背景如何混合。 mix-blend-mode: normal; // 正常mix-blend-mode: multiply; // 正片叠底mix-blend-mode: screen; // 滤色mix-blend-mode: overlay; // 叠加mix-blend-mode: darken; // 变暗mix-blend-mode: …...
Module not found: Error: Can‘t resolve ‘less-loader‘解决办法
前言: 主要是在自我提升方面,感觉自己做后端还是需要继续努力,争取炮筒前后端,作为一个全栈软阿金开发人员,所以还是需要努力下,找个方面,目前是计划学会Vue,这样后端有java和pytho…...

量化QAT QLoRA GPTQ
模型量化的思路可以分为PTQ(Post-Training Quantization,训练后量化)和QAT(Quantization Aware Training,在量化过程中进行梯度反传更新权重,例如QLoRA),GPTQ是一种PTQ的思路。 QAT…...

CentOS下查看 ssd 寿命
SSD写入量达到设计极限,颗粒擦写寿命耗尽后会导致磁盘写入速度非常缓慢,读取正常。 使用smartctl及raid卡管理软件查看硬盘smart信息可以发现Media_Wearout_Indicator值降为1,表明寿命完全耗尽。 涉及范围 所有SSD处理方案 查看SSD smart信…...

Node基础--npm相关内容
下面,我们一起来看看Node中的至关重要的一个知识点-----npm 1.npm概述 npm(Node Package Manager),CommonJS包规范是理论,npm是其中一种实践。 对于Node而言,NPM帮助其完成了第三方模块的发布、安装和依赖等。借助npm,Node与第三方模块之间形成了很好的一个 生态系统。(类…...

Python图片爬虫工具
不废话了,直接上代码: import re import os import requests import tqdmheader{User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36}def getImg(url,idx,path):imgre…...

制造执行系统(MES)在汽车行业中的应用
汽车行业在不断发展中仍然面临一些挑战和痛点。以下是一些当前汽车行业可能面临的问题: 1.电动化和可持续性转型:汽车行业正逐渐向电动化和可持续性转型,但这需要投入大量资金和资源,包括电池技术、充电基础设施等,同时…...

Spring与Mybatis集成且Aop整合
目录 一、集成 1.1 集成的概述 1.2 集成的优点 1.3 代码示例 二、整合 2.1 整合概述 2.2 整合进行分页 一、集成 1.1 集成的概述 集成是指将不同的组件、部分或系统组合在一起,以形成一个整体功能完整的解决方案。它是通过连接、交互和协调组件之间的关系来实…...

【nonebot-plugin-mystool】快速安装使用nonebot-plugin-mystool
快速安装使用nonebot-plugin-mystool,以qq为主 前期准备:注册一个QQ号,python3.9以上的版本安装,go-cqhttp下载 用管理员模式打开powershell,并输入以下命令 #先排查是否有安装过的nonebot,若有则删除 pip uninstal…...

CentOS7下SSD性能调优实战:iostat与dd命令的黄金组合
CentOS7下SSD性能调优实战:iostat与dd命令的黄金组合 在当今数据驱动的时代,存储性能往往成为系统瓶颈的关键所在。对于使用CentOS7系统的运维工程师来说,如何充分释放SSD硬件的性能潜力,是一个既具挑战性又充满成就感的技术课题。…...

LWIP内存管理踩坑实录:从pbuf泄漏到pcb耗尽,我的嵌入式网络调试日记
LWIP内存管理踩坑实录:从pbuf泄漏到pcb耗尽,我的嵌入式网络调试日记 凌晨三点,调试器上的红色LED还在闪烁。这是我连续第三个通宵追踪LWIP的内存问题——设备在运行48小时后必然崩溃,日志里满是"pbuf_alloc failed"和&q…...

从GTS-800到GTS-400:手把手教你移植C#点胶机程序到不同固高控制卡
从GTS-800到GTS-400:工业点胶系统迁移实战指南 当生产线上的点胶机控制卡需要从GTS-800更换为GTS-400时,许多工程师会发现"使用方法类似"这个说法背后隐藏着大量细节差异。去年我们团队完成了一个医疗设备点胶系统的迁移项目,原计划…...
)
Windows Server远程管理新选择:一键脚本部署noVNC服务端(含开机自启配置)
Windows Server远程管理新选择:一键脚本部署noVNC服务端(含开机自启配置) 对于需要管理Windows Server的系统管理员来说,远程访问是不可或缺的功能。传统的RDP虽然稳定,但在某些场景下可能受限,比如网络环境…...

python-flask-djangol框架的高校毕业生就业信息实习管理系统
目录需求分析与功能规划技术选型与架构设计数据库模型设计功能模块实现数据统计与可视化测试与部署文档与维护项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与功能规划 明确系统核心目标为管理高校毕业生就业和实习信…...

别再为版本兼容头疼了!手把手教你搞定Matlab R2014b与NI VeriStand的联合仿真环境
别再为版本兼容头疼了!手把手教你搞定Matlab R2014b与NI VeriStand的联合仿真环境 在硬件在环(HIL)测试领域,Matlab与NI VeriStand的联合仿真环境搭建是许多工程师的必经之路。然而,版本兼容性问题常常成为拦路虎&…...

Win11Debloat:终极Windows系统清理工具,一键提升电脑性能的完整指南
Win11Debloat:终极Windows系统清理工具,一键提升电脑性能的完整指南 【免费下载链接】Win11Debloat 一个简单的PowerShell脚本,用于从Windows中移除预装的无用软件,禁用遥测,从Windows搜索中移除Bing,以及执…...

HunyuanVideo-Foley音效生成:支持中文prompt理解的城市环境音效精准生成
HunyuanVideo-Foley音效生成:支持中文prompt理解的城市环境音效精准生成 1. 产品概述 HunyuanVideo-Foley是一款专为视频内容创作设计的AI音效生成工具,能够根据中文文本描述精准生成各类环境音效。本镜像为RTX 4090D 24GB显存显卡深度优化的私有部署版…...
 API!立即备份旧版+迁移至PyO3 0.21+手动GC管理方案(附自动化迁移脚本))
【紧急预警】Mojo nightly build已悄然移除PyModule::import() API!立即备份旧版+迁移至PyO3 0.21+手动GC管理方案(附自动化迁移脚本)
第一章:【紧急预警】Mojo nightly build已悄然移除PyModule::import() API!立即备份旧版迁移至PyO3 0.21手动GC管理方案(附自动化迁移脚本)Mojo nightly build v2024.06.12 起,PyModule::import() 已被彻底移除&#x…...

如何用PPTist快速创建专业演示文稿:免费在线PPT制作完全指南
如何用PPTist快速创建专业演示文稿:免费在线PPT制作完全指南 【免费下载链接】PPTist 基于 Vue3.x TypeScript 的在线演示文稿(幻灯片)应用,还原了大部分 Office PowerPoint 常用功能,实现在线PPT的编辑、演示。支持导…...