Tapdata Connector 实用指南:数据入仓场景之数据实时同步到 BigQuery
【前言】作为中国的 “Fivetran/Airbyte”, Tapdata 是一个以低延迟数据移动为核心优势构建的现代数据平台,内置 60+
数据连接器,拥有稳定的实时采集和传输能力、秒级响应的数据实时计算能力、稳定易用的数据实时服务能力,以及低代码可视化操作等。典型用例包括数据库到数据库的复制、将数据引入数据仓库或数据湖,以及通用
ETL 处理等。随着 Tapdata Connector 的不断增长,我们最新推出《Tapdata Connector
实用指南》系列内容,以文字解析辅以视频演示,还原技术实现细节,模拟实际技术及应用场景需求,提供可以“收藏跟练”的实用专栏。本期实用指南以
SQL Server → BigQuery 为例,演示数据入仓场景下,如何将数据实时同步到 BigQuery。
数据规模仍在持续扩大的今天,为了从中获得可操作的洞察力,进一步实现数据分析策略的现代化转型,越来越多的企业开始把目光投注到 BigQuery 之上,希望通过 BigQuery 来运行大规模关键任务应用,从而达到优化运营、改善客户体验并降低总体拥有成本的目的。
作为自带 ETL 的实时数据平台,我们也看到了很多从传统内部数据仓库向 BigQuery 的数据迁移需求。
一、BigQuery 的云数仓优势
作为一款由 Google Cloud 提供的云原生企业级数据仓库,BigQuery 借助 Google 基础架构的强大处理能力,可以实现海量数据超快速 SQL 查询,以及对 PB 级数据进行安全并可扩展的分析。同时也因其天然具备的无服务器架构、低成本等特性,备受数据分析师和数据工程师的青睐,在数据存储和处理上表现出更出色的便利性。
BigQuery 在企业中通常用于存储来自多个系统的历史与最新数据,作为整体数据集成策略的一部分,也常作为既有数据库的补充存在。其优势在于:
- 在不影响线上业务的情况下进行快速分析:BigQuery 专为快速高效的分析而设计, 通过在 BigQuery 中创建数据的副本, 可以针对该副本执行复杂的分析查询, 而不会影响线上业务。
- 数据集中存储, 提高分析效率:对于分析师而言,使用多个平台耗时费力,如果将来自多个系统的数据组合到一个集中式数据仓库中,可以有效减少这些成本。
- 安全性保障:可以控制对加密项目或数据集的访问,并实施身份访问管理。
- 可扩展性:支持根据公司的规模、性能和成本要求定制数据存储。
- 友好兼容:作为 Google Cloud 的一部分,它与 Google 系产品更兼容,对相关用户更友好。
为了实现上述优势,我们需要首先实现数据向 BigQuery 的同步。
二、SQLServer → BigQuery 的数据入仓任务
👆👆点击查看完整演示
(*本演示视频版本为 Tapdata 本地部署版本)
版本指路:
点击登录 Tapdata Cloud
申请试用 Tapdata 本地部署版
BigQuery 准备工作
-
登录 Google Cloud 凭据页面
-
创建服务账号,该账号将用于后续的身份验证。
a. 在页面顶部,单击创建凭据 > 服务账号。
b. 在服务账号详情区域,填写服务账号的名称、ID 和说明信息,单击创建并继续。

c. 在角色下拉框中输入并选中 BigQuery Admin,单击页面底部的完成。

-
为服务账号创建认证密钥。
a. 在跳转到的凭据页面,单击页面下方刚创建的服务账号。
b. 在密钥标签页,单击添加密钥 > 创建新密钥。

c. 在弹出的对话框中,选择密钥类型为 JSON,然后单击创建。
d. 操作完成后密钥文件将自动下载保存至您的电脑,为保障账户安全性,请妥善保管密钥文件。
e. 登录 Google Cloud 控制台,创建数据集和表,如已存在可跳过本步骤。
i. 创建 BigQuery 数据集(*为保障 Tapdata Cloud 正常读取到数据集信息,创建数据集时,选择位置类型为多区域)
ii. 创建表
操作流程详解(Tapdata Cloud)
① 登录 Tapdata Cloud

- 默认已完成 Tapdata Cloud 账号注册及 Agent 部署
- 确保 Tapdata Agent 所属机器可访问 Google 云服务,例如可将 Agent 安装至海外服务器。
② 创建数据源 SQL Server 的连接


在 Tapdata Cloud 连接管理菜单栏,点击【创建连接】按钮, 在弹出的窗口中选择 SQL Server 数据库,并点击确定。
参考右侧【连接配置帮助】,完成连接创建:

③ 创建数据目标 BigQuery 的连接
-
在 Tapdata Cloud 连接管理右侧菜单栏,点击【创建连接】按钮,在弹出的窗口中选择 BigQuery,并点击确定
-
根据已获取的服务账号,在配置中输入 Google Cloud 相关信息,详细说明如下:

- 连接名称:填写具有业务意义的独有名称。
- 连接类型:目前仅支持作为目标。
- 访问账号(JSON):用文本编辑器打开您在准备工作中下载的密钥文件,将其复制粘贴进该文本框中。
- 数据集 ID:选择 BigQuery 中已有的数据集。(输入服务账号后, 即可列出全部数据集)
- agent 设置:选择平台自动分配,如有多个 Agent,请手动指定可访问 Google 云服务的 Agent。
- 单击连接测试,测试通过后单击保存。(*如提示连接测试失败,可根据页面提示进行修复)
④ 新建并运行 SQL Server 到 BigQuery 的同步任务

三、Why Tapdata?
借助 Tapdata 出色的实时数据能力和广泛的数据源支持,可以在几分钟内完成从源库到 BigQuery 包括全量、增量等在内的多重数据同步任务。
基于 BigQuery 特性,Tapdata 做出了哪些针对性调整
在开发过程中,Tapdata 发现 BigQuery 存在如下三点不同于传统数据库的特征:
- 如使用 JDBC 进行数据的写入与更新,则性能较差,无法满足实际使用要求;
- 如使用 StreamAPI 进行数据写入,虽然速度较快,但写入的数据在一段时间内无法更新;
- 一些数据操作存在 QPS 限制,无法像传统数据库一样随意对数据进行写入。
为此,Tapdata 选择将 Stream API 与 Merge API 联合使用,既满足了数据高性能写入的需要,又成功将延迟保持在可控范围内,具体实现逻辑如下:
- 在数据全量写入阶段,由于只存在数据的写入,没有变更与删除操作,因此直接使用 Stream API 进行数据导入。
- 在数据增量阶段,先将增量事件写入一张临时表,并按照一定的时间间隔,将临时表与全量的数据表通过一个 SQL 进行批量 Merge,完成更新与删除的同步。
- 两个阶段的 Merge 操作,第一次进行时,强制等待时间为 30min,以避免触发 Stream API 写入的数据无法更新的限制,之后的 Merge 操作时间可以配置,这个时间即为增量的同步延迟时间,一般配置在 5min 以内。
Tapdata 有哪些优势?
此外,对于数据同步任务而言,Tapdata 同时兼具如下优势:
-
内置 60+ 数据连接器,稳定的实时采集和传输能力
以实时的方式从各个数据来源,包括数据库、API、队列、物联网等数据提供者采集或同步最新的数据变化。支持多源异构数据双向同步,自动映射关系型到非关系型。一键实现实时捕获,毫秒内更新。已内置 60+连接器且不断拓展中,覆盖大部分主流的数据库和类型,并支持您自定义数据源。 -
具有强可扩展性的 PDK 架构
4 小时快速对接 SaaS API 系统;16 小时快速对接数据库系统。 -
对源库几乎无影响
基于自研的 CDC 日志解析技术,0入侵实时采集数据,对源库几乎无影响。 -
全链路实时
基于 Pipeline 流式数据处理,以应对基于单条数据记录的即时处理需求,如数据库 CDC、消息、IoT 事件等。不同于传统 ETL,每一条新产生并进入到平台的数据,会在秒级范围被响应,计算,处理并写入到目标表中。同时提供了基于时间窗的统计分析能力,适用于实时分析场景。 -
数据一致性保障
通过多种自研技术,保障目标端数据与源数据的高一致性,并支持通过多种方式完成一致性校验,保障生产要求。 -
可视化任务运行监控和告警
包含 20+ 可观测性指标,包括全量同步进度、增量同步延迟等,能够实时监控在运行任务的最新运行状态、日志信息等,支持任务告警。
【相关阅读】
- Tapdata Cloud 场景通关系列:集成阿里云计算巢,实现一键云上部署真正开箱即用
- Tapdata Cloud 场景通关系列:将数据导入阿里云 Tablestore,获得毫秒级在线查询和检索能力
- Tapdata Cloud 场景通关系列:数据入湖仓之 MySQL → Doris,极简架构,更实时、更简便
原文链接:https://tapdata.net/tapdata-connector-sqlserver-bigquery.html
相关文章:
Tapdata Connector 实用指南:数据入仓场景之数据实时同步到 BigQuery
【前言】作为中国的 “Fivetran/Airbyte”, Tapdata 是一个以低延迟数据移动为核心优势构建的现代数据平台,内置 60 数据连接器,拥有稳定的实时采集和传输能力、秒级响应的数据实时计算能力、稳定易用的数据实时服务能力,以及低代码可视化操作…...

关于机器人状态估计(12)-VIO/VSLAM的稀疏与稠密
VIO三相性与世界观室内ALL IN ONE 首先以此链接先对近期工作的视频做个正经的引流,完成得这么好的效果,仅仅是因为知乎限流1分钟以内的视频,导致整个浏览量不到300,让人非常不爽。 这套系统已经完成了,很快将正式发布…...
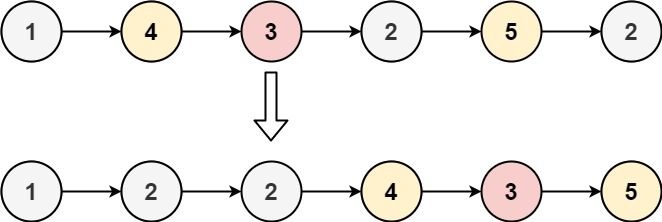
Python每日一练(20230220)
目录 1. 存在重复元素 II 2. 按要求实现程序功能 3. 分割链表 附录 链表 1. 存在重复元素 II 给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] nums [j],并且 i 和 j 的差的 绝对值 至多为 k。 …...

技术总监的“技术提升”
技术负责人的能力要求是什么?成本中心技术负责人最重要的工作是让其他CXO理解、认可并且支持技术部的工作,否则作为成本部门,在公司的地位会很低。技术创新光是让其他部门理解还不行,技术还需要创造价值,所以需要做技术创新。上面…...
kettle安装部署_简单认识_Spoon勺子界面---大数据之kettle工作笔记002
然后我们来看一下这个kettle的安装,很简单,下载解压就可以了 上面的地址是官网很烂 下面的地址好一些 这个是官网可以看到很慢,很不友好 这个是下面那个地址,可以看到 最新的是9.0了,一般都用 一般都用8.2 这里下载这个就可以了 下载以后可以看到有个pdi...
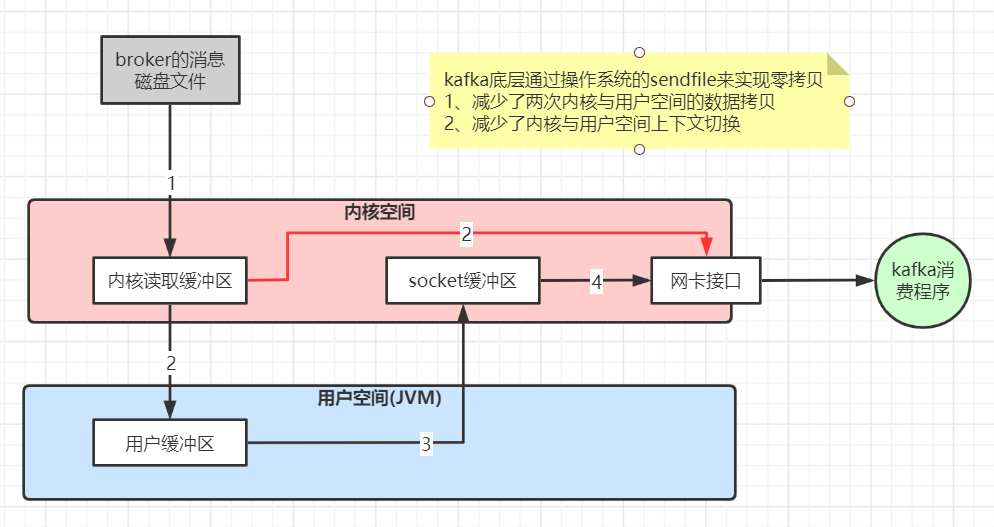
第三章 Kafka生产问题总结及性能优化实践
第三章 Kafka生产问题总结及性能优化实践 1、线上环境规划 JVM参数设置 kafka 是 scala 语言开发,运行在 JVM 上,需要对 JVM 参数合理设置,参看 JVM 调优专题 修改 bin/kafka-start-server.sh 中的 JVM 设置,假设机器是 32G 内…...

Comparable和Comparator的区别
一、概述 Comparable和Comparator都是用来实现比较的,一般用于集合中元素的比较 基本包装类型,Integer、Long以及String都实现了Comparable接口,该接口的排序逻辑必须写在比较对象中,所以又叫自然排序 我们一般集合排序使用的Col…...

全15万字丨PyTorch 深度学习实践、基础知识体系全集;忘记时,请时常回顾。
✨ ✨我们抬头便看到星光,星星却穿越了万年. ✨ ✨ 🎯作者主页:追光者♂ 🌸个人简介:在读计算机专业硕士研究生、CSDN-人工智能领域新星创作者🏆、2022年度博客之星人工智能领域TOP4🌟、阿里云…...
简洁易用的记账小程序——微点记账
背景 由于每个月的信用卡账单太过吓人,记性也不是特别的好,加上微信支付宝账单中有些明细不是很明确。比如在京东花销的明细不会记录用户购买了什么,只会记录那个通道支出的。所以,才会有了想自己开发一款记账小程序,…...

Windows平台上达梦数据库的ODBC安装与配置
文章目录概述安装包准备安装ODBC驱动配置ODBC数据源概述 最近很多公司都在响应信创,需要切换到国产数据库,然而很多数据库的一些基础组件的使用都没有一个很明确的官方文档。为了避免更多的人踩坑,本人将踩过的坑总结成博文,分享…...

哈希表的介绍
1.哈希表的介绍 在哈希表中插入、删除或查找一个元素都只需要O(1)的时间,因此经常被用来优化时间效率。 在Java中,哈希表有两个对应的类型,即HashSet和HashMap。 2.HashSet的应用 若每个元素都只有一个值,则用HashSet…...

spring cloud gateway 实现redis动态路由及自动项目路由上报
前言 spring cloud gateway默认为内存存储策略,通过配置文件加载的方式生成路由定义信息 可以看到,RouteDefinitionRepository继承了两个父接口,分别为RouteDefinitionLocator和RouteDefinitionWriter,RouteDefinitionLocator定…...

c++函数对象(仿函数)、谓词、内建函数对象
1、函数对象 1.1 概念 重载函数调用操作符的类,这个类的对象就是函数对象,在使用这个函数对象对应使用重载的()符号时,行为类似于函数调用,因此这个函数也叫仿函数。 注意:函数对象࿰…...

物联网对供应链管理的影响
物联网对于许多行业来说都是一项革命性技术,其应用领域涉及零售、交通、金融、医疗保健和能源等行业。物联网在供应链等流程中已经展示了其深度的潜力。管理、预测和监督应用程序有助于车队运输经理提高配送的运营效率,并增加决策的准确性。如今…...
c++ 那些事 笔记
GitHub - Light-City/CPlusPlusThings: C那些事 1. ① extern extern关键字,C语言extern关键字用法详解 如果全局变量不在文件的开头定义,其有效的作用范围只限于其定义处到文件结束。如果在定义点之前的函数想引用该全局变量,则应该在…...
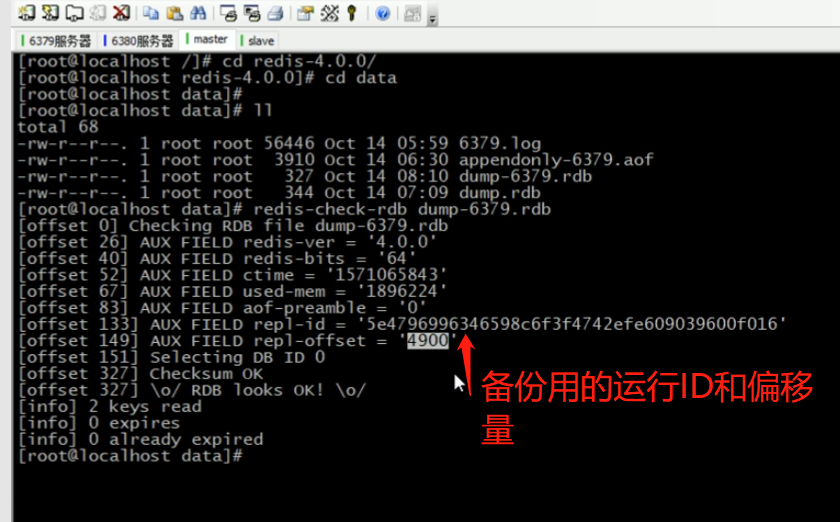
心跳机制Redis
进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线 master心跳: 指令:PING 周期:由repl-ping-slave-period决定,默认10秒 作用&#…...

蓝桥杯算法训练合集十七 1.数字反转2.试题39713.矮人采金子4.筛法5.机器指令
目录 1.数字反转 2.试题3971 3.矮人采金子 4.筛法 5.机器指令 1.数字反转 问题描述 给定一个整数,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零&…...
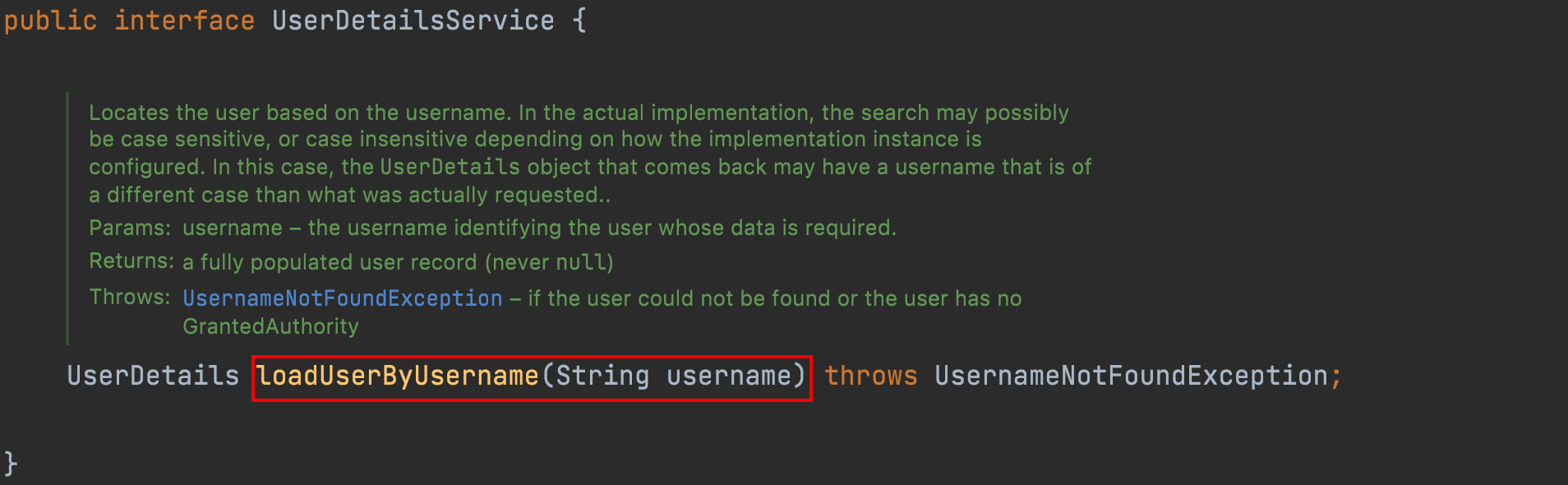
第一章 初识 Spring Security
第一章 初识 Spring Security 1、权限管理 权限管理 基本上涉及到用户参与的系统都要进行权限管理,权限管理属于系统安全的范畴,权限管理实现了对用户访问系统的控制,按照安全规则或者安全策略控制用户可以访问而且只能访问自己被授权的资…...

2023-02-20 关于回朔的思考
摘要: 考虑命运来回动荡交织,一些新的规划在不断的扩充, 而一些历史则开始陷入回朔。 有必要对历史和过往做一些规划和思考。 需要注意在这个阶段, 第一优先级是在反刍中将其最大化。 理论层: 一. 数据库的基础理论 ANSI SQL到词法解析和语法解析mysql的SQL层对…...
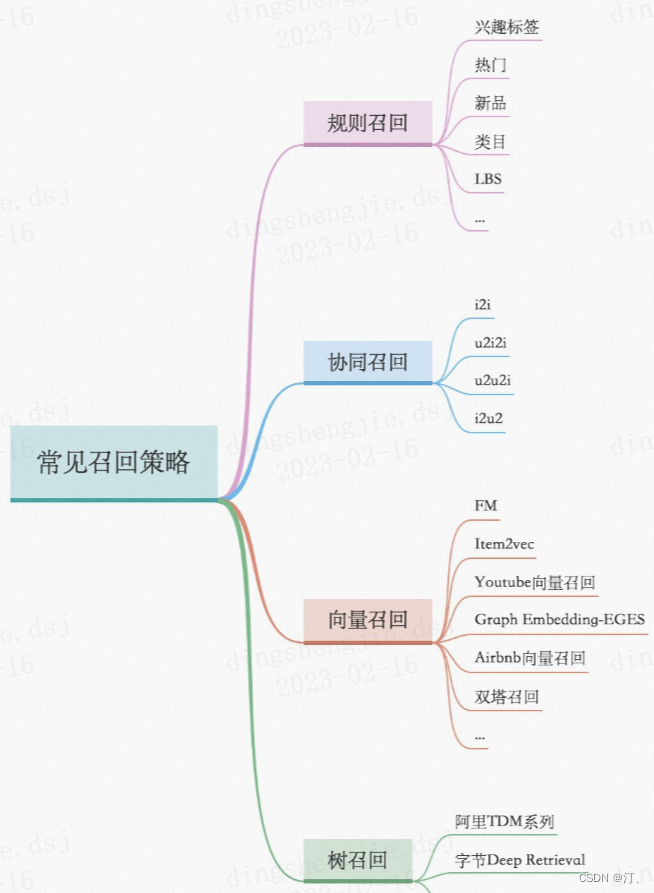
推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
0.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回、粗排、精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板;粗排是初筛,一般不会上复杂模型;精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;重排,一般是做打散或满足…...

PADS 铜箔区域规则与技巧
铜箔一定要非直角 直角会向外辐射 然后能走直线不走斜线方显布局的落落大方铜箔布好后可以选择任选去选择铜箔的边沿去拉它的形状 还可以通过打断去让他多几个拐点直接分割一个...

AI逆向实战:构建MCP工具链赋能Cursor自动化App动态分析
1. 为什么需要AI辅助App逆向分析 逆向工程一直是安全研究和移动应用开发中的重要环节。传统的逆向流程通常需要手动操作adb命令、反编译工具、抓包软件等,不仅效率低下,而且对操作者的技术要求极高。我曾在一次商业App的安全评估中,花了整整三…...

2026最权威的六大降重复率网站实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 要降低AIGC(人工智能生成内容)的检测率,关键之处在于提升…...

利用快马平台快速将notepad++笔记构思转化为可交互网页应用原型
今天想和大家分享一个特别实用的开发经验——如何用InsCode(快马)平台快速把Notepad里的笔记构思变成可交互的网页应用。作为一个经常用Notepad写代码片段和笔记的人,我一直在寻找能快速验证想法的工具,直到发现了这个平台。 为什么选择网页应用原型 N…...

APK Installer:在Windows上直接安装Android应用的3种实用方法
APK Installer:在Windows上直接安装Android应用的3种实用方法 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上运行Android应用…...

DRM子系统深度探索:从drm_minor到connector属性文件的完整设备树解析
DRM子系统深度探索:从drm_minor到connector属性文件的完整设备树解析 在嵌入式显示系统开发中,DRM(Direct Rendering Manager)子系统作为Linux内核显示框架的核心,其设备树形结构体系的理解对于调试显示异常至关重要。…...

用快马AI快速构建编译原理教学工具:十分钟实现词法分析器原型
最近在准备编译原理的课程演示时,发现学生经常对词法分析这个抽象概念感到困惑。传统的PPT讲解效果有限,如果能有个实时互动的演示工具就好了。于是尝试用InsCode(快马)平台快速搭建了一个简易词法分析器原型,整个过程比想象中顺利得多。 需求…...

CANoe.Diva CDD文件配置避坑指南:DTC导入、会话迁移与NRC设置详解
CANoe.Diva CDD文件高阶配置实战:从DTC陷阱到NRC优化的深度解析 当诊断测试用例在CANoe.Diva环境中频繁失败时,往往不是基础配置出错,而是那些隐藏在CDD文件深处的"高级选项"在作祟。本文将带您穿透表面配置,直击五个最…...
)
OpenClaw环境搭建:Mac系统下龙虾智能体快速部署教程(M1/M2芯片适配)
OpenClaw环境搭建:Mac系统下龙虾智能体快速部署教程(M1/M2芯片适配)📚 本章学习目标:深入理解OpenClaw环境搭建的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《…...
)
麒麟系统根目录权限误改777?3步快速修复(附完整命令)
麒麟系统根目录权限误改777?3步快速修复(附完整命令) 当你在深夜维护麒麟系统时,一个不经意的chmod -R 777 /命令可能让整个系统陷入权限混乱。作为经历过这种噩梦的运维老兵,我总结出一套最快能在15分钟内恢复系统权限…...