第三章 Kafka生产问题总结及性能优化实践
第三章 Kafka生产问题总结及性能优化实践
1、线上环境规划
JVM参数设置
kafka 是 scala 语言开发,运行在 JVM 上,需要对 JVM 参数合理设置,参看 JVM 调优专题
修改 bin/kafka-start-server.sh 中的 JVM 设置,假设机器是 32G 内存,可以如下设置:
export KAFKA_HEAP_OPTS="-Xmx16G -Xms16G -Xmn10G -XX:MetaspaceSize=256M -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:G1HeapRegionSize=16M"
这种大内存的情况一般都要用 G1 垃圾收集器,因为年轻代内存比较大,用 G1 可以设置 GC 最大停顿时间,不至于一次 minor gc 就花费太长时间,当然,因为像 kafka,rocketmq,es 这些中间件,写数据到磁盘会用到操作系统的 page cache,所以 JVM 内存不宜分配过大,需要给操作系统的缓存留出几个 G。
2、线上问题及优化
消息丢失情况
消息发送端:
1、acks=0: 表示 producer 不需要等待任何 broker 确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。大数据统计报表场景,对性能要求很高,对数据丢失不敏感的情况可以用这种。
2、acks=1: 至少要等待 leader 已经成功将数据写入本地log,但是不需要等待所有 follower 是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower 没有成功备份数据,而此时 leader 又挂掉,则消息会丢失。
3、acks=-1或all: 这意味着leader需要等待所有备份(min.insync.replicas配置的备份个数)都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。当然如果 min.insync.replicas 配置的是1则也可能丢消息,跟acks=1情况类似。
消息消费端:
如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时你consumer直接宕机了,未处理完的数据丢失了,下次也消费不到了。
消息重复消费
消息发送端:
发送消息如果配置了重试机制,比如网络抖动时间过长导致发送端发送超时,实际broker可能已经接收到消息,但发送方会重新发送消息
消息消费端:
如果消费这边配置的是自动提交,刚拉取了一批数据处理了一部分,但还没来得及提交,服务挂了,下次重启又会拉取相同的一批数据重复处理
一般消费端都是要做消费幂等处理的。
消息乱序
如果发送端配置了重试机制,kafka不会等之前那条消息完全发送成功才去发送下一条消息,这样可能会出现,发送了1,2,3条消息,第一条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了。
所以,是否一定要配置重试要根据业务情况而定。也可以用同步发送的模式去发消息,当然acks不能设置为0,这样也能保证消息发送的有序。
kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理消息。
消息积压
1、线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。
此种情况如果积压了上百万未消费消息需要紧急处理,可以修改消费端程序,让其将收到的消息快速转发到其他topic(可以设置很多分区),然后再启动多个消费者同时消费新主题的不同分区。
2、由于消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致 broker 积压大量未消费消息。
此种情况可以将这些消费不成功的消息转发到其它队列里去(类似死信队列),后面再慢慢分析死信队列里的消息处理问题。
延时队列
延时队列存储的对象是延时消息。所谓的“延时消息”是指消息被发送以后,并不想让消费者立刻获取,而是等待特定的时间后,消费者才能获取这个消息进行消费,延时队列的使用场景有很多, 比如 :
1、在订单系统中, 一个用户下单之后通常有 30 分钟的时间进行支付,如果 30 分钟之内没有支付成功,那么这个订单将进行异常处理,这时就可以使用延时队列来处理这些订单了。
2、订单完成 1 小时后通知用户进行评价。
实现思路:
发送延时消息时先把消息按照不同的延迟时间段发送到指定的队列中(topic_1s,topic_5s,topic_10s,…topic_2h,这个一般不能支持任意时间段的延时),然后通过定时器进行轮训消费这些 topic,查看消息是否到期,如果到期就把这个消息发送到具体业务处理的 topic 中,队列中消息越靠前的到期时间越早,具体来说就是定时器在一次消费过程中,对消息的发送时间做判断,看下是否延迟到对应时间了,如果到了就转发,如果还没到这一次定时任务就可以提前结束了。
消息回溯
如果某段时间对已消费消息计算的结果觉得有问题,可能是由于程序 bug 导致的计算错误,当程序 bug 修复后,这时可能需要对之前已消费的消息进行重新消费,可以指定从多久之前的消息回溯消费,这种可以用 consumer 的 offsetsForTimes、seek 等方法指定从某个 offset 偏移的消息开始消费,参见上节课的内容。
分区数越多吞吐量越高吗
可以用 kafka 压测工具自己测试分区数不同,各种情况下的吞吐量:
# 往 test 里发送一百万条消息,每条消息设置 1 KB
# throughput 用来进行限流控制,当设定的值小于 0 时不限流,当设定的值大于 0 时,当发送的吞吐量大于该值时就会被阻塞一段时间
bin/kafka-producer-perf-test.sh --topic test --num-records 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=192.168.65.60:9092 acks=1
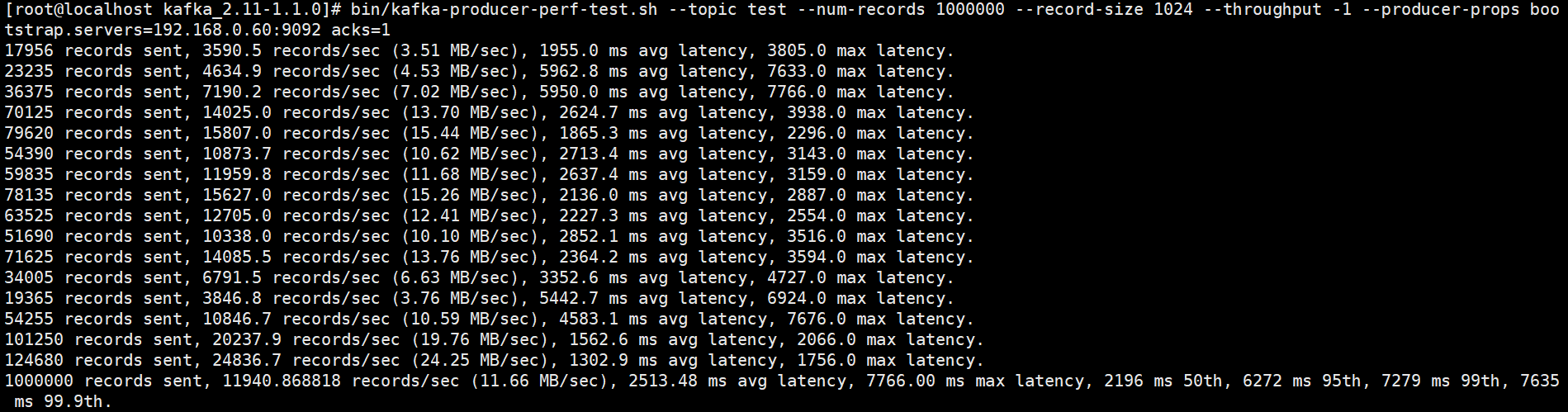
网络上很多资料都说分区数越多吞吐量越高 , 但从压测结果来看,分区数到达某个值时吞吐量反而开始下降,实际上很多事情都会有一个临界值,当超过这个临界值之后,很多原本符合既定逻辑的走向又会变得不同。一般情况下分区数跟集群机器数量相当就差不多了。
当然吞吐量的数值和走势还会和磁盘、文件系统、 I/O调度策略等因素相关。
注意:如果分区数设置过大,比如设置10000,可能会设置不成功,后台会报错"java.io.IOException : Too many open files"。
异常中最关键的信息是“ Too many open flies”,这是一种常见的 Linux 系统错误,通常意味着文件描述符不足,它一般发生在创建线程、创建 Socket、打开文件这些场景下 。 在 Linux 系统的默认设置下,这个文件描述符的个数不是很多 ,通过 ulimit -n 命令可以查看:一般默认是1024,可以将该值增大,比如:ulimit -n 65535
消息传递保障
- at most once(消费者最多收到一次消息,0–1次):acks = 0 可以实现。
- at least once(消费者至少收到一次消息,1–多次):ack = all 可以实现。
- exactly once(消费者刚好收到一次消息):at least once 加上消费者幂等性可以实现,还可以用 kafka 生产者的幂等性来实现。
kafka 生产者的幂等性:
因为发送端重试导致的消息重复发送问题,kafka 的幂等性可以保证重复发送的消息只接收一次,只需在生产者加上参数 props.put(“enable.idempotence”, true) 即可,默认是 false 不开启。
具体实现原理是:
kafka 每次发送消息会生成 PID 和 Sequence Number,并将这两个属性一起发送给 broker,broker 会将 PID 和 Sequence Number 跟消息绑定一起存起来,下次如果生产者重发相同消息,broker 会检查 PID 和 Sequence Number,如果相同则不会再接收。
PID:每个新的 Producer 在初始化的时候会被分配一个唯一的 PID,这个PID 对用户完全是透明的。生产者如果重启则会生成新的PID。
Sequence Number:对于每个 PID,该 Producer 发送到每个 Partition 的数据都有对应的序列号,这些序列号是从0开始单调递增的。
kafka的事务
Kafka 的事务不同于 Rocketmq,Rocketmq是保障本地事务(比如数据库)与 mq 消息发送的事务一致性,Kafka 的事务主要是保障一次发送多条消息的事务一致性(要么同时成功要么同时失败),一般在 kafka 的流式计算场景用得多一点,比如,kafka 需要对一个 topic 里的消息做不同的流式计算处理,处理完分别发到不同的 topic 里,这些 topic 分别被不同的下游系统消费(比如hbase,redis,es等),这种我们肯定希望系统发送到多个 topic 的数据保持事务一致性。Kafka 要实现类似 Rocketmq 的分布式事务需要额外开发功能。
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("transactional.id", "my-transactional-id");Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());//初始化事务producer.initTransactions();try {//开启事务producer.beginTransaction();for (int i = 0; i < 100; i++){//发到不同的主题的不同分区producer.send(new ProducerRecord<>("hdfs-topic", Integer.toString(i), Integer.toString(i)));producer.send(new ProducerRecord<>("es-topic", Integer.toString(i), Integer.toString(i)));producer.send(new ProducerRecord<>("redis-topic", Integer.toString(i), Integer.toString(i)));}//提交事务producer.commitTransaction();} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {// We can't recover from these exceptions, so our only option is to close the producer and exit.producer.close();} catch (KafkaException e) {// For all other exceptions, just abort the transaction and try again.//回滚事务producer.abortTransaction();}producer.close();
3、 kafka高性能的原因
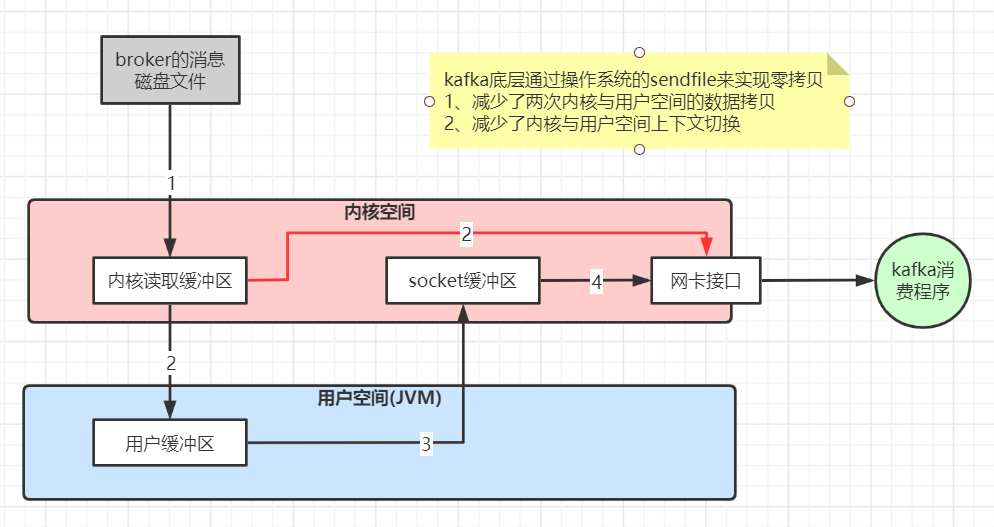
相关文章:
第三章 Kafka生产问题总结及性能优化实践
第三章 Kafka生产问题总结及性能优化实践 1、线上环境规划 JVM参数设置 kafka 是 scala 语言开发,运行在 JVM 上,需要对 JVM 参数合理设置,参看 JVM 调优专题 修改 bin/kafka-start-server.sh 中的 JVM 设置,假设机器是 32G 内…...

Comparable和Comparator的区别
一、概述 Comparable和Comparator都是用来实现比较的,一般用于集合中元素的比较 基本包装类型,Integer、Long以及String都实现了Comparable接口,该接口的排序逻辑必须写在比较对象中,所以又叫自然排序 我们一般集合排序使用的Col…...

全15万字丨PyTorch 深度学习实践、基础知识体系全集;忘记时,请时常回顾。
✨ ✨我们抬头便看到星光,星星却穿越了万年. ✨ ✨ 🎯作者主页:追光者♂ 🌸个人简介:在读计算机专业硕士研究生、CSDN-人工智能领域新星创作者🏆、2022年度博客之星人工智能领域TOP4🌟、阿里云…...
简洁易用的记账小程序——微点记账
背景 由于每个月的信用卡账单太过吓人,记性也不是特别的好,加上微信支付宝账单中有些明细不是很明确。比如在京东花销的明细不会记录用户购买了什么,只会记录那个通道支出的。所以,才会有了想自己开发一款记账小程序,…...

Windows平台上达梦数据库的ODBC安装与配置
文章目录概述安装包准备安装ODBC驱动配置ODBC数据源概述 最近很多公司都在响应信创,需要切换到国产数据库,然而很多数据库的一些基础组件的使用都没有一个很明确的官方文档。为了避免更多的人踩坑,本人将踩过的坑总结成博文,分享…...

哈希表的介绍
1.哈希表的介绍 在哈希表中插入、删除或查找一个元素都只需要O(1)的时间,因此经常被用来优化时间效率。 在Java中,哈希表有两个对应的类型,即HashSet和HashMap。 2.HashSet的应用 若每个元素都只有一个值,则用HashSet…...

spring cloud gateway 实现redis动态路由及自动项目路由上报
前言 spring cloud gateway默认为内存存储策略,通过配置文件加载的方式生成路由定义信息 可以看到,RouteDefinitionRepository继承了两个父接口,分别为RouteDefinitionLocator和RouteDefinitionWriter,RouteDefinitionLocator定…...

c++函数对象(仿函数)、谓词、内建函数对象
1、函数对象 1.1 概念 重载函数调用操作符的类,这个类的对象就是函数对象,在使用这个函数对象对应使用重载的()符号时,行为类似于函数调用,因此这个函数也叫仿函数。 注意:函数对象࿰…...

物联网对供应链管理的影响
物联网对于许多行业来说都是一项革命性技术,其应用领域涉及零售、交通、金融、医疗保健和能源等行业。物联网在供应链等流程中已经展示了其深度的潜力。管理、预测和监督应用程序有助于车队运输经理提高配送的运营效率,并增加决策的准确性。如今…...
c++ 那些事 笔记
GitHub - Light-City/CPlusPlusThings: C那些事 1. ① extern extern关键字,C语言extern关键字用法详解 如果全局变量不在文件的开头定义,其有效的作用范围只限于其定义处到文件结束。如果在定义点之前的函数想引用该全局变量,则应该在…...
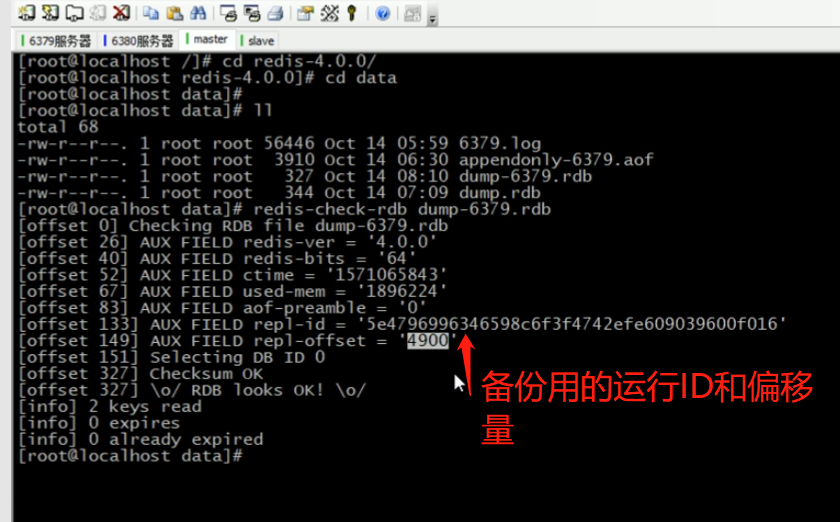
心跳机制Redis
进入命令传播阶段候,master与slave间需要进行信息交换,使用心跳机制进行维护,实现双方连接保持在线 master心跳: 指令:PING 周期:由repl-ping-slave-period决定,默认10秒 作用&#…...

蓝桥杯算法训练合集十七 1.数字反转2.试题39713.矮人采金子4.筛法5.机器指令
目录 1.数字反转 2.试题3971 3.矮人采金子 4.筛法 5.机器指令 1.数字反转 问题描述 给定一个整数,请将该数各个位上数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零&…...
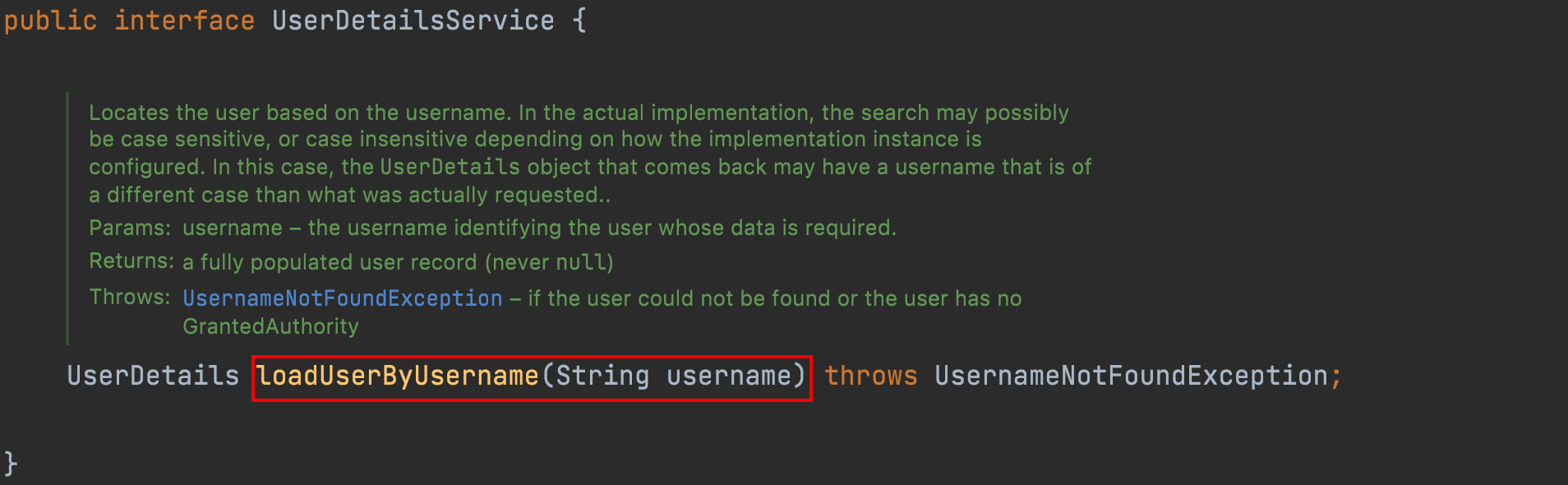
第一章 初识 Spring Security
第一章 初识 Spring Security 1、权限管理 权限管理 基本上涉及到用户参与的系统都要进行权限管理,权限管理属于系统安全的范畴,权限管理实现了对用户访问系统的控制,按照安全规则或者安全策略控制用户可以访问而且只能访问自己被授权的资…...

2023-02-20 关于回朔的思考
摘要: 考虑命运来回动荡交织,一些新的规划在不断的扩充, 而一些历史则开始陷入回朔。 有必要对历史和过往做一些规划和思考。 需要注意在这个阶段, 第一优先级是在反刍中将其最大化。 理论层: 一. 数据库的基础理论 ANSI SQL到词法解析和语法解析mysql的SQL层对…...
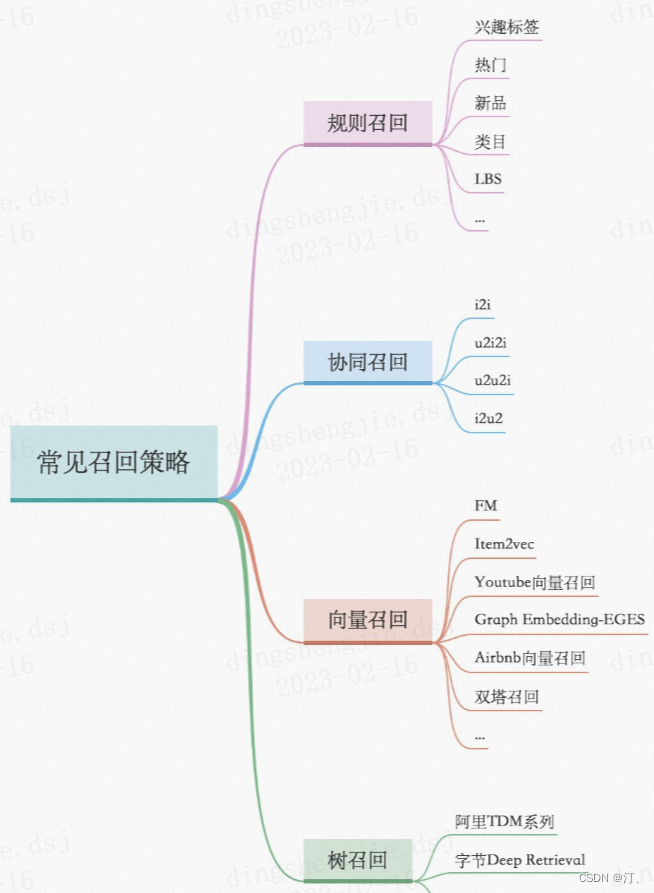
推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
0.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回、粗排、精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板;粗排是初筛,一般不会上复杂模型;精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;重排,一般是做打散或满足…...

适合初学者的超详细实用调试技巧(下)
我们日常写代码的时候,常常会遇到bug的情况,这个时候像我这样的初学者就会像无头苍蝇一样这里改改那里删删,调试的重要性也就显现出来,这篇文章接着上文来讲解。 上文地址:(8条消息) 适合初学者的超详细实用调试技巧&…...

C# String与StringBuilder 的区分
重点 1)它是比较的栈里面的值是否相等(值比较) 2)Equals它比较的是堆里面的值是否相等(引用地址值比较) 3)Object.ReferenceEquals(obj1,obj2)它是比较的是内存地址是否相等 问题描述: 今日提交代码时候,被检测工具发出修改建议。遂补充一下知识 1.什么…...

【麒麟】基于GPS北斗卫星技术的NTP网络时间服务器
【麒麟】基于GPS北斗卫星技术的NTP网络时间服务器 【麒麟】基于GPS北斗卫星技术的NTP网络时间服务器 麒麟系统NTP授时方案 设计思路: 在通用的麒麟服务器内部固定一块北斗卫星接收模块并引出卫星天线接口,卫星模块接收北斗卫星数据并解码输出时间数据&…...

“互联网+”下劳动关系认定的现状
1. 劳动关系的认定标准。依据目前我国法律的有关规定, 判定劳动关系存在两种情况:其一, 在有书面劳动合同的情况下, 这时应以书面合同作为认定标准;其二, 在没有书面合同的情况下, 则依据2005年劳社部的《关于确立劳动关系有关事项的通知》来认定, 其中第一条:“用人单位招用劳…...
LPWAN及高效弹性工业物联网核心技术方案
20多年前的一辆拖拉机就是一个纯机械的产品,里面可能并没有电子或者软件的构成;而随后随着软件的发展,拖拉机中嵌入了软件,它能控制发动机的功率及拖拉机防抱死系统;接下来,通过融入各种软件,拖…...

Poppins字体完整指南:免费获取专业级多语言排版解决方案
Poppins字体完整指南:免费获取专业级多语言排版解决方案 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 你是否正在寻找一款既美观又支持多语言的免费字体来提升设计…...

游戏开发中的乒乓缓存实战:Unity双缓冲技术如何提升渲染性能
游戏开发中的乒乓缓存实战:Unity双缓冲技术如何提升渲染性能 在Unity游戏开发中,渲染性能优化一直是开发者关注的焦点。当画面复杂度和特效层级不断提升时,传统的单缓冲机制往往难以满足流畅渲染的需求,这时乒乓缓存(P…...

用Python模拟随机游走:从一维到三维,直观理解马尔可夫链的常返性
用Python模拟随机游走:从一维到三维,直观理解马尔可夫链的常返性 随机游走是概率论中最迷人的概念之一,它像一面镜子,映照出微观粒子运动、金融市场波动甚至社交网络传播的底层规律。当我第一次在Jupyter Notebook中模拟出随机游走…...
)
TVA在汽车零部件焊接点检测中的实操启示录(3)
TVA系统在汽车零部件焊接点检测的落地,并非简单的“设备安装调试”,而是一个涉及流程优化、人员适配、技术衔接的系统工程。不少企业技术主管因忽视落地全流程管控,出现“系统安装后无法正常运行”“员工不会操作”“检测流程与生产流程脱节”…...

一键生成专业工资条:工资条生成器功能详解
在当今数字化办公的时代,一款好的工具能够让工作效率得到质的提升。 工资条生成器就是这样一款专门为财务人员打造的专业工具,它集成了多项实用功能。 下面,就让我们来详细了解一下这款软件的各项功能特性。 首先要介绍的是软件的核心功能…...

雷赛HBS86闭环步进驱动方案代码功能说明
某雷赛86闭环步进驱动方案 HBS86H 86闭环电机驱动器/混合伺服驱动器。原理图PCB代码。整体方案打包。代码无错误无警告。一、方案概述 雷赛HBS86闭环步进驱动方案基于TI的DSP2803x系列芯片构建,该方案整合了原理图、PCB设计以及配套代码,形成一套完整的…...

智能家居集成新方案:Home Assistant与小米设备的跨平台控制实现
智能家居集成新方案:Home Assistant与小米设备的跨平台控制实现 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 【突破生态限制】智能家居跨平台集成方案 …...

WeChatExporter:让微信聊天记录导出实现数据自主权的开源方案
WeChatExporter:让微信聊天记录导出实现数据自主权的开源方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 在数字时代,微信聊天记录已成为个人…...

ai辅助开发新体验:向快马平台描述你的pencil设计,智能生成动态官网
今天想和大家分享一个特别有意思的体验——用AI辅助开发工具快速把设计稿变成可交互的官网。最近我在设计一个科技公司的官网,用了Pencil画原型,但要把设计变成代码时发现了一个超好用的平台。 设计需求分析 这个官网需要体现强烈的科技感,我…...

探索无桥PFC与逆变方案:从原理到实现
无桥PFC和逆变方案(原理图pdfPCBstm源码两份仿真等文件) 1.输入电压AC220V,50Hz交流电 2.PFC输出390V,150KHz开关频率 3.PFC输出最大功率400瓦,输入电流最大2A,最小负载电流0.1A 输出功率越大PF值越高,电流…...