Kafka 学习笔记
😀😀😀创作不易,各位看官点赞收藏.
文章目录
- Kafka 学习笔记
- 1、消息队列 MQ
- 2、Kafka 下载安装
- 2.1、Zookeeper 方式启动
- 2.2、KRaft 协议启动
- 2.3、Kafka 集群搭建
- 3、Kafka 之生产者
- 3.1、Java 生产者 API
- 3.2、Kafka 生产者生产分区
- 3.3、Kafka 生产者常见问题
- 4、Kafka 之 Broker
- 4.1、Broker 节点上下线
- 4.2、Broker 副本
- 4.3、Broker 文件存储机制
- 5、Kafka 之消费者
- 5.1、消费者组
- 5.2、Java 消费者 API
- 5.3、消费者分区分配
- 5.4、消费者 offset 维护
- 5.5、消费者常见问题
- 6、Kafka-Eagle 监控
- 7、Spring Boot 整合 Kafka
- 7.1、Kafka 生产者
- 7.2、Kafka 消费者
Kafka 学习笔记
Kafka:是一个开源的分布式事件流平台,用于高性能数据管道、流分析、数据集成和关键任务应用。在一些大数据领域中通常使用 kafka 作为消息队列,在 JavaEE 开发中也有 ActiveMQ、RabbitMQ、RocketMQ 等等消息队列。
1、消息队列 MQ
消息队列是一种在分布式系统中用于不用组件之间传递和处理数据的通信机制,基于异步通信模式,允许发送者将消息发送到队列中,接受者从队列中获取消息数据并进行处理。
消息队列几种模式:
点对点模式:消息生产者将消息放入队列,每一条消息只能被一个消费者消费,消费者将消息处理完以后会将消息从队列中移除,这种适合单一消息被一个消费者处理的场景。
发布 - 订阅模式:生产者将消息发布到一个主题中,多个消费者可以订阅主题来接收消息,每一个消费者都会收到相同的消息,消息会被保存即使被消费也不会被删除。
应用场景:
- 限流消峰:MQ 可以将系统超量的请求进行暂存,以便后期系统进行处理调度,从而避免请求的的丢失和系统被压垮。
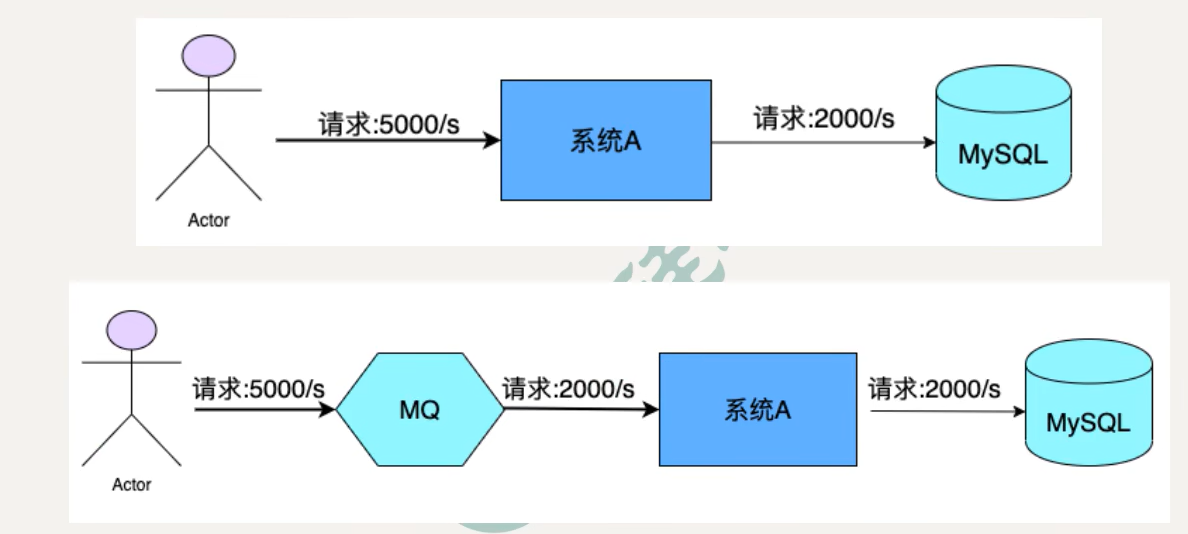
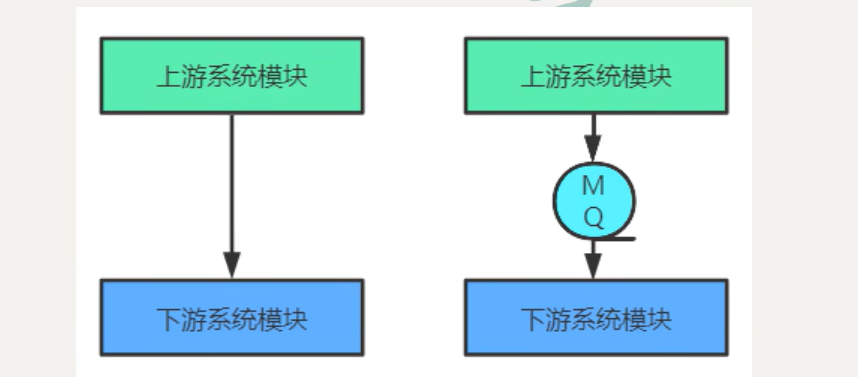
- 异步和解耦:上游系统去调用下游系统时采用同步调用方式,系统的吞吐量会大大降低,并且上下游系统的耦合度增加。一般会在上下游系统之间添加一个MQ,上游系统将消息数据给 MQ 然后直接返回给用户,后面的所有操作由 MQ 进行请求下游操作,如果失败了就进行重试。
- 数据收集:分布式系统会产生大量的数据,例如业务日志、监控数据等。针对这些数据进行实时采集和处理,然后对数据进行分析操作,MQ 也可以完成这类操作。
2、Kafka 下载安装
下载地址https://www.apache.org/dyn/closer.cgi?path=/kafka/3.5.0/kafka_2.13-3.5.0.tgz
# 解压
tar -zxvf kafka_2.13-3.5.0.tgz
cd kafka_2.13-3.5.0
注意:
- 在 kafka2.8.0 之前必须需要依赖 zookeeper 组件,在之后可以选择不依赖 zookeeper 组件,而是以 KRaft 协议启动。
- kafka 需要 Java 环境,需要配置环境变量。
2.1、Zookeeper 方式启动
配置文件 - server.properties :
# 常用配置
# 身份唯一标识,不能重复
broker.id=0
# 数据文件
log.dirs=/tmp/kafka-logs
# 依赖的zookeeper节点地址,一般会加一个kafka节点
zookeeper.connect=localhost:2181/kafka
# 与zookeeper连接超时时间
zookeeper.connection.timeout.ms=18000
启动 kafka 服务:
# 先启动一个 kafka 自带的 zookeeper,-daemon 后台运行
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties# 启动 kafka 服务
bin/kafka-server-start.sh -daemon config/server.properties
2.2、KRaft 协议启动
配置文件:修改
config/KRaft/server.properties文件。
# 生成集群UUID(只执行一次)
KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
# 格式化日志目录(只执行一次)
bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
# 启动kafka服务
bin/kafka-server-start.sh -daemon config/kraft/server.properties
# 停止服务
bin/kafka-server-stop.sh
脚本简单使用:
# 创建一个主题
bin/kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
# 查看某个主题参数信息
bin/kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092# 向主题中写入消息
bin/kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
# 阅读消息
bin/kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
2.3、Kafka 集群搭建
KRaft 方式搭建集群:
- 修改配置文件:
# 每一个节点的唯一标识id,不能重复
node.id=0# 集群中每个 Controller IP地址和端口号
controller.quorum.voters=0@192.168.32.135:9093,1@192.168.32.136:9093,2@192.168.32.137
# 内网监听ip地址
listeners=PLAINTEXT://192.168.32.137:9092,CONTROLLER://192.168.32.137:9093
# 外网监听ip地址
advertised.listeners=PLAINTEXT://192.168.32.137:9092
- 生成集群唯一 UUID:
# 生成uuid,并把uuid记录下来
./bin/kafka-storage.sh random-uuid
gfCReVjpRqWi3RzL-sg7Lw
- 每个节点格式化存储数据目录:
# -t 的参数就是生成的唯一集群id,每个节点都要根据这个id去执行命令
./bin/kafka-storage.sh format -t gfCReVjpRqWi3RzL-sg7Lw -c ./config/kraft/server.properties
- 启动服务:
# 启动 kafka 服务
./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
3、Kafka 之生产者
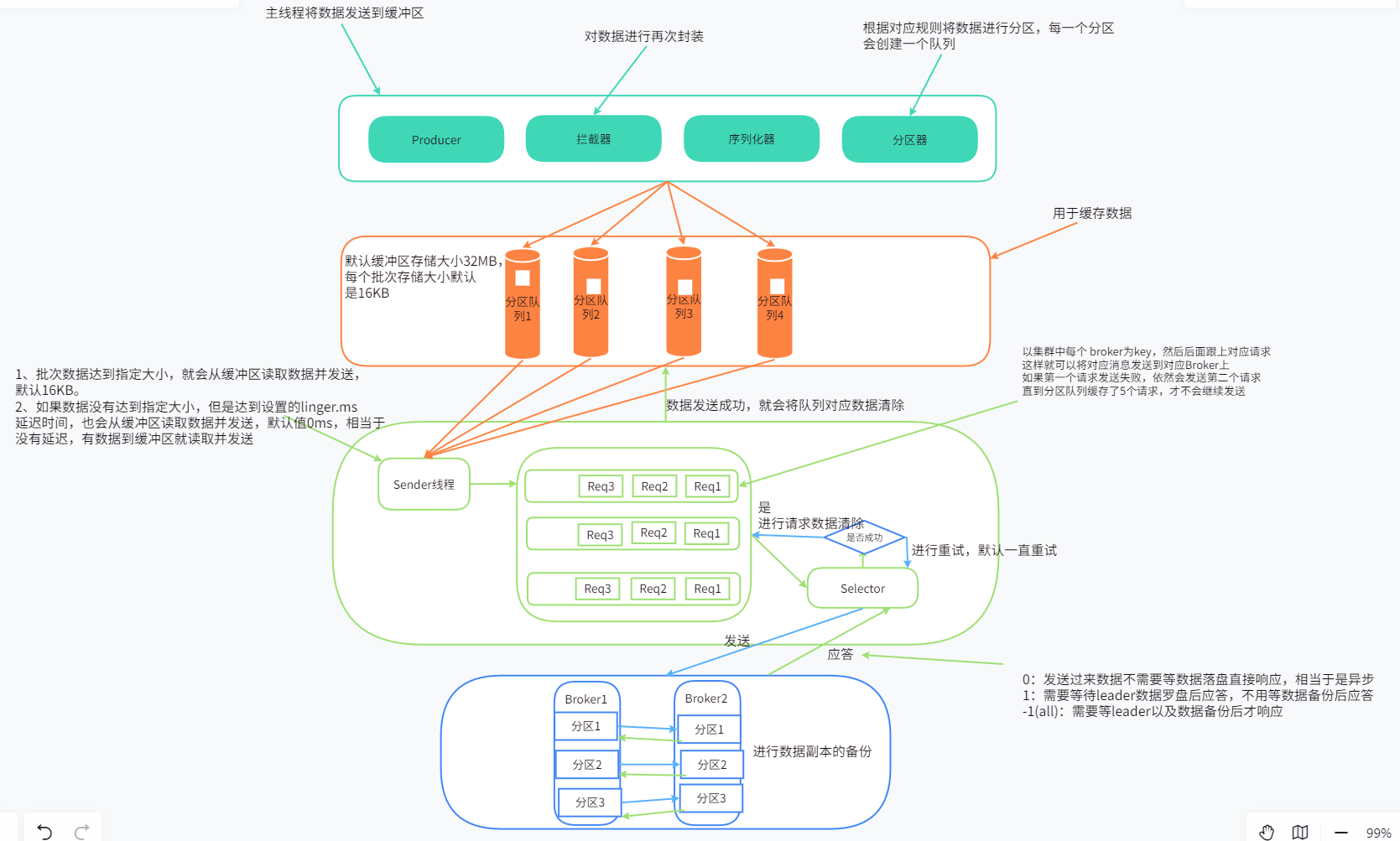
3.1、Java 生产者 API
导入依赖:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.5.1</version>
</dependency>
代码编写:
public static void main(String[] args) throws ExecutionException, InterruptedException {Properties properties = new Properties();// Kafka服务端的主机名和端口号properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.32.135:9092,192.168.32.136:9092,192.168.32.137:9092");// 等待所有副本节点的应答properties.put(ProducerConfig.ACKS_CONFIG, "0");// 消息发送最大尝试次数,默认一直重试properties.put(ProducerConfig.RETRIES_CONFIG, 0);// 一批消息处理大小,默认16KBproperties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// 请求延时,默认0properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// 发送缓存区内存大小,默认32MBproperties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// key序列化properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// value序列化properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// kafka 生产者对象KafkaProducer<String, String> producer = new KafkaProducer<>(properties);// 构建消息ProducerRecord<String, String> message = new ProducerRecord<>("quickstart-events", "key1", "value1");/*** 有两种消息发送方式:* 1:异步方式:send()方法返回一个异步Future对象,* 2:回调异步方式:可以在构建参数时设置一个回调方法* 3:同步发送:根据send()返回的future对象调用其get()方法进行阻塞主线程*/// Future<RecordMetadata> send = producer.send(message); // 异步方式producer.send(message, new Callback() { // 回调异步@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {System.out.println("消息发送成功");}});// 同步发送,get()方法会阻塞线程,知道上一批数据全部发送成功,返回结果包含了消息主题、分区等信息RecordMetadata metadata = producer.send(message).get();producer.close();
}
注意:主线程会先将数据发送到缓冲区,然后由 sender 线程进行异发送,而同步发送是一批数据发送到缓冲区由 sender 线程发送到 kafka 集群才会允许下一批数据进行发送。
3.2、Kafka 生产者生产分区
消息分区:将同一个主题的消息数据分区数据到不同的 broker 机器上。
- 便于合理使用存储资源,每个分区存储在一个 Broker 上,可以将海量数据按照分区分割成一块一块存储在多台 Broker 上。合理控制分区任务,可以实现负载均衡效果。
- 提高并行度,生产者可以以分区单位进行发送,消费者可以以分区单位进行消费,大大提高数据的处理能力。
分区策略:生产者写入消息到 topic,Kafka 将依据不同的策略将数据分配到不同的分区中。
- 轮询分区策略:如果生产消息时,对应 key 值是 null,则使用轮询方式最大限度均匀分配到某个分区。
- key 分区策略:生产消息时,key 值不为 null,但是没有指定具体分区,则按照 key 的 hash 值去取余你的分区数量确定对应分区。
- 指定分区:生产消息时,指定对应的分区则严格按照指定分区存储。
- 自定义分区策略:实现 Partitioner 接口,通过配置可以创建自定义分区策略。
注意:如果发送的分区不存在,则客户端一直会进行等待连接,阻塞线程所有线程。
自定义分区器:可以根据业务需求自定义分区器,实现 Partitioner 接口重写 partition() 方法。
// 自定义分区器
public class CustomerPartitioner implements Partitioner {/*** 重写对应的分区策略* @param topic 主题* @param key key 值* @param keyBytes 序列化后的key字节值* @param value value 值* @param valueBytes 序列化后的value值* @param cluster 一些集群信息,可以通过主题获取有几个分区* @return 数据发送到哪个分区*/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {if (key == null){return 0;}else {return 1;}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
// 配置对象配置对应的自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomerPartitioner.class.getName());
3.3、Kafka 生产者常见问题
提高生产者吞吐量:主要是通过配置属性,结合实际生产环境调整配置。
- batch.size:批次大小,默认 16 KB,可以根据需要修改对应大小。
- linger.ms:缓冲时间,达到这个时间 sender 读取缓冲区数据进行发送,一般 5 ~ 100 ms,如果设置过长数据延迟性就变高。
- buffer.memory:缓冲区大小,默认 32 MB,如果分区较多可以设置大一点,如果设置小了就会出现 sender() 数据不足导致等待。
- compression.type:数据压缩方式,默认不压缩,可以使用压缩方式有:gzip、snappy、lz4、zstd,常用方式 snappy。
// 一批消息处理大小,默认16KB
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 请求延时,默认0
properties.put(ProducerConfig.LINGER_MS_CONFIG, 5);
// 发送缓存区内存大小,默认32MB
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
// 设置数据压缩方式
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "snappy");
数据可靠性:kafka 生产者在生产数据时有三种 ACK 应答级别,不同应答数据可靠性不一样,默认级别是 -1(all)。
- “0”:生产者发送数据不需要等数据落盘直接响应,这样就可能出现数据丢失,但是效率高。
- “1”:生产者发送数据只需要 Leader 落盘成功不用等副本复制就直接响应,也可以出现副本数据丢失,如果 Leader 宕机副本成为 Leader 就会出现数据丢失。对于一些数据量大并且允许少量数据丢失。
- “-1”、“all”:生产者发送数据只有 Leader 和所有副本都落盘才会应答响应,不会出现数据丢失。==但是可能出现数据重复问题,Leader 和副本都落盘成功,但是没给到响应前 Leader 宕机,生成者由于没有收到应答就会重新给新 Leader 发出数据,但是新 Leader 已经存在这条数据。==用于数据可靠性要求较高。
在同步副本数据时,如果某个副本无法应答 Leader,Leader 也不会应答生产者。但是 Leader 维护了 ISR 一个动态副本队列,如果超过默认 30s 没有副本心跳就会把对应副本剔除队列,这样就不会长期去等待无法同步的副本。
最佳实践方式:(ACK 级别为 -1) + (分区副本 >= 2) + (ISR 中应答最小副本 >= 2)。
// ACK 应答级别
properties.put(ProducerConfig.ACKS_CONFIG, "-1");
// ISR 副本超时时间,默认30s
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 1000 * 30);
数据重复问题:
- 至少一次:ACK 级别为 -1,副本和 ISR 队列中数量大于等于2,但是存在数据重复问题。
- 最多一次:ACK 级别为 0,数据不会重复但是可能出现数据丢失问题。
- 精确一次:对于一些重要数据,数据可靠性高并且不能重复。
幂等性: 指生产者向 Broker 发送多少条重复数据,Broker 都只会持久化一条数据。 重复数据判断依据:PID(会话ID)、Partition(分区号)、SeqNumber(自增序列号),三者都不相同则表示不同数据。
- PID:每个客户端启动会生成一个 PID,重启会重新生成。(这就导致只能解决单会话内的数据重复问题)
- Partition:数据存放的分区位置。
- SeqNumber:消息的只增序列号。
/*** 开启幂等性:默认开启* 开启前提条件:max.in.flight.requests.per.connection等待请求数小于等于5* retries:大于等于0* ACK:-1*/
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
生产者事务:开启事务必须先开启幂等性,事务是基于幂等性的。
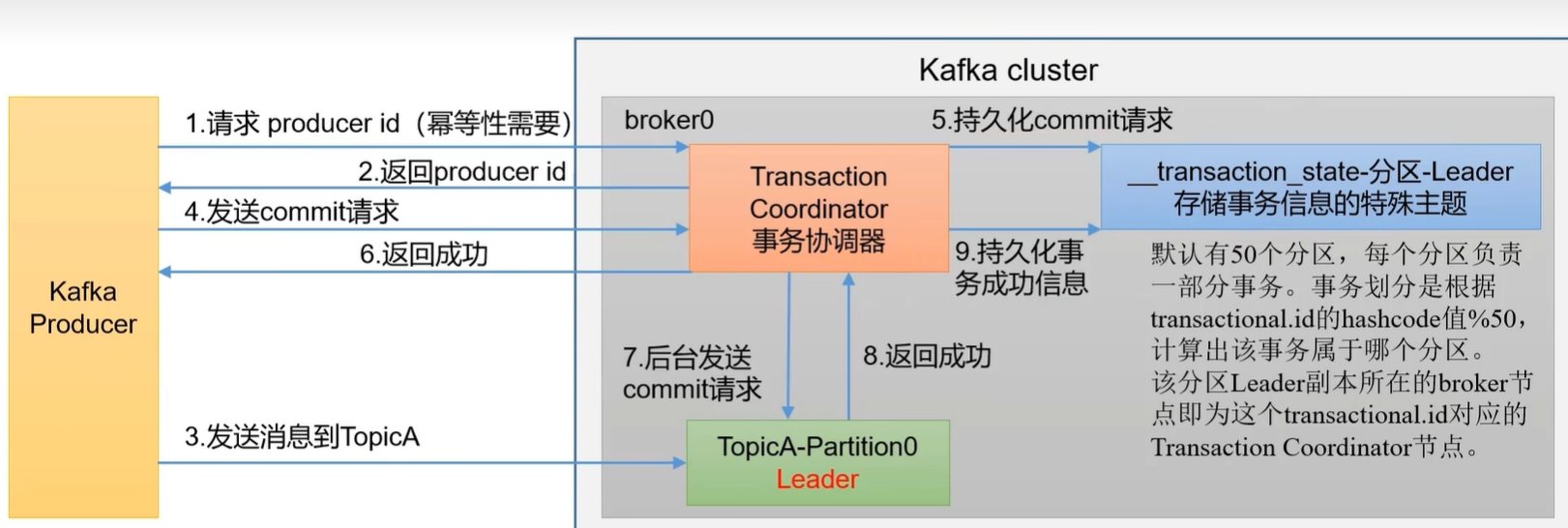
try {// 开启事务producer.beginTransaction();for (int i=0;i<10;i++){ProducerRecord<String, String> message = new ProducerRecord<>("topic-3",UUID.randomUUID().toString(), UUID.randomUUID().toString());producer.send(message);}// 提交事务producer.commitTransaction();
}catch (Exception e){// 回滚事务,如果数据发送出现异常就会回滚所有发送的数据producer.abortTransaction();e.printStackTrace();
}finally {producer.close();
}
注意:生产者在使用事务前需要指定自定义唯一的 transaction-id,在第一次使用事务会初始化一个 __transaction_state 主题数据,默认有 50 个分区,这里面存放着对事务数据的存放。
数据有序性:
- 单分区有序性:单分区会根据数据发送的先后顺序进行排序。
- 多分区有序性:由于是多分区在消费者消费时无法保证取到的数据是有序的,但是可以先把所有数据全部取出来,然后手动进行排序。
单分区有序:由于在 Sender 线程中最多缓存 5 个请求,第一个请求没有应答前可以发送第二个请求,就可能出现第一个请求失败后重试导致数据乱序,但是在 Kafka1.0 之后会缓存生产者发送的最近 5 个请求的元数据,会根据幂等性序列号进行排序然后再进行数据持久化。
/*** 保证单分区数据有序的前提条件:(也可以将最大请求数设置为1,只有一个请求缓存)*/
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// sender 线程缓存最大请求数
properties.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);
4、Kafka 之 Broker
Zookeeper 模式:在 kafka2.8.0 之前是需要依赖 zookeeper 组件,由 zookeeper 负责集群元数据管理、控制器的选举等。

KRaft 模式:在 KRaft 中,一部分 broker 节点被指定为控制器,这些 Controller 提供 Zookeeper 的共识服务,集群的所有元数据以主题方式存储在 kafka 中。

注意:每一个 Broker 节点既可以充当 Broker,也可以充当 Controller 角色,两者也可以同时充当。
4.1、Broker 节点上下线
新建节点:修改新增节点配置,启动节点服务到集群中。
# -t 的参数就是生成的唯一集群id,每个节点都要根据这个id去执行命令
./bin/kafka-storage.sh format -t gfCReVjpRqWi3RzL-sg7Lw -c ./config/kraft/server.properties
# 启动 kafka 服务
./bin/kafka-server-start.sh -daemon ./config/kraft/server.properties
新建负载均衡计划:即使新增了节点,但是以前数据依然不会对新节点做负载均衡,需要我们自己去对旧数据做负载均衡。
- 创建负载均衡计划 json 文件:
vim topic-to-move.json
{"version": 1, // 版本号固定1"topics": [ // 需要做负载均衡的主题名称{"topic": "topic-1"},{"topic": "topic-2"},{"topic": "topic-3"}]
}
- 生成计划:
# --bootstrap-server:连接服务,--topic-to-move-json-file:指定负载均衡计划文件,--broker-list "0,1,2,3":指定负载均衡的broker的id
./bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.32.135:9092 --topics-to-move-json-file ./json/topic-to-move.json --broker-list "0,1,2,3" --generate

- 新计划 json 文件:
vim increase-replication-factor.json,将生成的计划复制进去,然后执行计划。
# 执行计划命令
./bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.32.135:9092 --reassignment-json-file ./json/increase-replication-factor.json --execute
# 验证是否执行成功
./bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.32.135:9092 --reassignment-json-file ./json/increase-replication-factor.json --verify

节点下线:节点下线只需要将在均衡计划中主题对应的节点去掉需要下线节点 id,然后执行对应计划就可以,然后将节点关机。
4.2、Broker 副本
Kafka 副本:用于提高数据的可靠性,默认副本 1 个,生产环境一般配置 2 个。太多副本会增加磁盘存储空间也会增加网络上数据传输,降低效率。Kafka 中副本分为 Leader 副本和 Follower 副本,但是生产者和消费者都只会去操作 Leader 副本,Follower 副本只是用于存放备份数据。
AR = ISR + OSR
- AR:Kafka 分区中所有副本。
- ISR:与 Leader 保持数据同步的 Follower 副本集合,如果 Follower 默认 30s 未向 Leader 副本同步数据,则会被踢出集合。
- OSR:表示 Follower 与 Leader 副本同步超过延迟时间的副本。
Leader 选举:当 Leader 宕机以后,Follower 会根据一定规则选举出新的 Leader,在集群中由某个 Controller 节点用于选举新的 Leader。


Broker 故障:
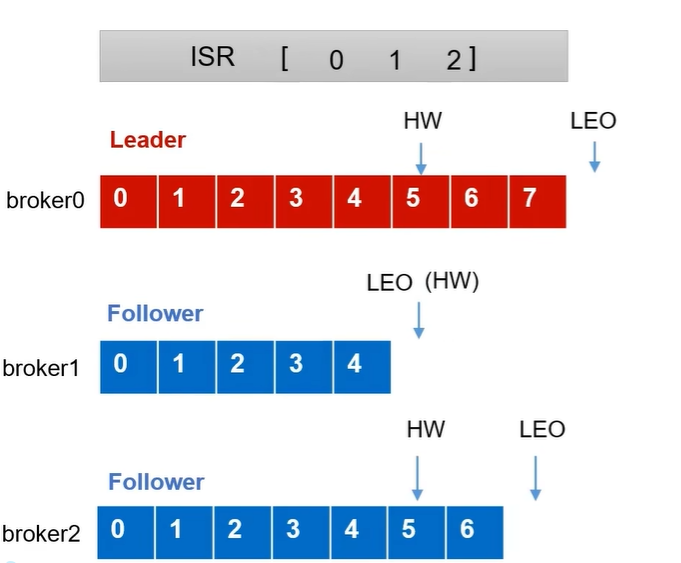
- LEO:每个副本的最后一个 offset,LEO 是每个副本最新的 offset + 1。
- HW(高水位):所有副本中最小的 LEO。
Follower 故障: 首先会被踢出 ISR 队列,其它正常的 Broker 继续同步数据。当故障 Follower 重新上线后,它会读取磁盘记录的上次 HW 记录,并将 log 数据高于 HW 的数据截取掉,然后从 HW 部分开始向后继续从 Leader 同步数据,当数据同步到所有副本的 HW 水平就可以重新加入 ISR 队列。
Leader 故障: 首先会被踢出 ISR 队列,然后选举出新的 Leader,为保证数据一致性,其它的 Follower 会将高于 HW 的数据裁剪掉,然后和新的 Leader 进行同步。
注意:这只能保证副之间数据一致性,但是不能保证数据不丢失或者不重复(旧 Leader 可能存在还未同步的数据)。
手动调整 Broker 副本:kafka 默认副本是均分分配在每个 Broker 上,可能出现指定副本需求。
- 创建副本分配文件:
vim increase-replication-factor.json,将 topic-1 主题的副本放在 0、1 节点上。
{"version":1,"partitions":[{"topic":"topic-1","partition":0,"replicas":[0,1]},{"topic":"topic-1","partition":1,"replicas":[0,1]},{"topic":"topic-1","partition":2,"replicas":[1,0]},{"topic":"topic-1","partition":3,"replicas":[1,0]}]
}
- 执行副本分配计划:
# 执行
./bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.32.135:9092 --reassignment-json-file ./json/increase-replication-factor.json --execute
# 验证
./bin/kafka-reassign-partitions.sh --bootstrap-server 192.168.32.135:9092 --reassignment-json-file ./json/increase-replication-factor.json --verify
Leader Partition 自动平衡:正常情况 kafka 会将分区均匀分配到每一个 Broker 上。当某个 Leader 宕机,新 Leader 可能会集中在其它 几台 Broker 上,这可能造成负载不均衡的情况,但是生产中一般会关闭这个功能,因为触发自动平衡很耗性能。
auto.leader.rebalance.enable:是否开启分区自动平衡,默认开启。leader.imbalance.per.broker.percentage:默认值是10%,broker 中允许 Leader 不平衡比例,如果操过这个比例就会触发自动平衡。leader.imbalance.check.interval.seconds:默认值 300s,检查 Leader 是否平衡的间隔时间。

增加分区副本:创建副本分配文件:vim increase-replication-factor.json,将 topic-1 主题的副本进行重新规划,然后执行计划。
4.3、Broker 文件存储机制
Broker 数据存储:一个 topic 可以分在多个 partition 上进行存储,一个 topic 下的分区有一个topic名-partition号的 log 文件夹,在这个文件夹下存储着生产者产生的数据,生产者生产的数据会不断追加在 log 文件末尾。

为了防止 log 文件过大导致数据定位效率低下,kafka 采取分片、索引机制。将 log 分片成一个个 Segment,每个Segment 默认大小是 1GB,每个 Segment 由 .index、.log、.timeindex 以及其它文件组成。(文件名称以当前 Segment 的第一条消息的 offset 命名)
.index:作为稀疏索引,每往 log 文件中写入 4KB 数据,就会向 index 文件中添加一条索引。.log:存放数据文件。.timeindex:时间戳索引文件,默认 kafka 数据保留7天,会根据这个文件去清除数据。
数据删除策略:kafka 默认数据保留7天,可以设置对应参数修改数据删除时间。
log.retention.hours:单位小时,默认168小时(7天),优先级最低。log.retention.minutes:单位分钟,如果设置这个值,小时单位就失效。log.retention.ms:单位毫秒,如果设置这个值,分钟单位失效。log.retention.check.interval.ms:设置检查周期,默认5分钟检查数据是否过期。log.cleanup.policy=delete/compact:设置数据的删除策略。
delete:将过期数据删除。
- 基于时间(默认):以 Segment 中所有记录的最大时间戳作为该文件时间戳,到了时间就把整个 Segment 文件删除。
- 基于大小:当数据超过存储容量,就会删除最早的 Segment 文件。
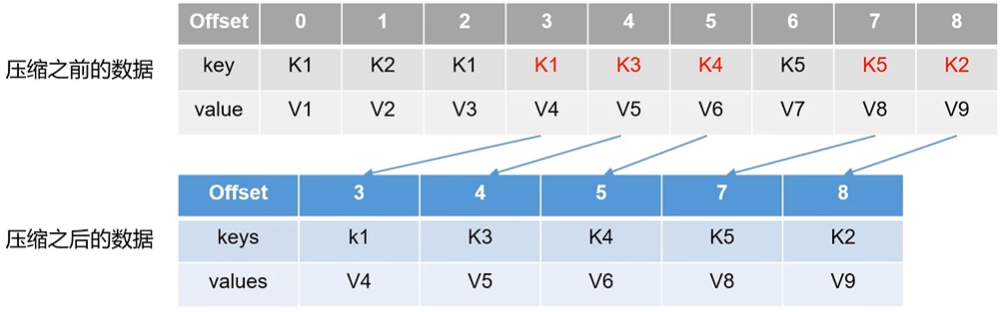
compact:数据压缩,将相同 key 的数据只保留最后一个版本数据,压缩后的 offset 不是连续的,如果不存在对应 offset 的数据就会拿去下一个 offset 的数据。
Kafka 高效读写:
- kafka 本身是一个分布式集群,并且采用分区技术,对于生产者和消费者在操作数据提高了并行度。
- 读数据采用稀疏索引,在
.index文件中存放了数据索引,可以快速定位数据。 - 采用顺序读写磁盘,在
.log文件写入数据是追加数据到文件末端,顺序写数据速度快。 - kafka 采用也缓存技术和零拷贝技术,kafka 应用层不关心存储的数据,不会对数据进行处理,所以保存数据时 kafka 会把数据交给操作系统的页缓存,再由操作系统完成数据持久化。零拷贝指消费者再消费数据时,先会查看页缓存中是否有数据,如果没有数据操作系统会从磁盘中读取数据到页缓存,然后操作系统直接通过网卡发送给消费者,并没有将数据加载到 kafka 的应用内存中。

5、Kafka 之消费者
消费方式:
- pull 拉模式:消费者主动从 broker 拉取数据,kafka 采用该方式可以根据消费者的消费能力自定义数据拉取速度,但是存在 broker 没有数据,导致消费者循环拉取数据为空。
- push 推模式:broker 主动向消费者推送消息,但是每个消费者消费速率不一样,可能出现消息来不及处理。
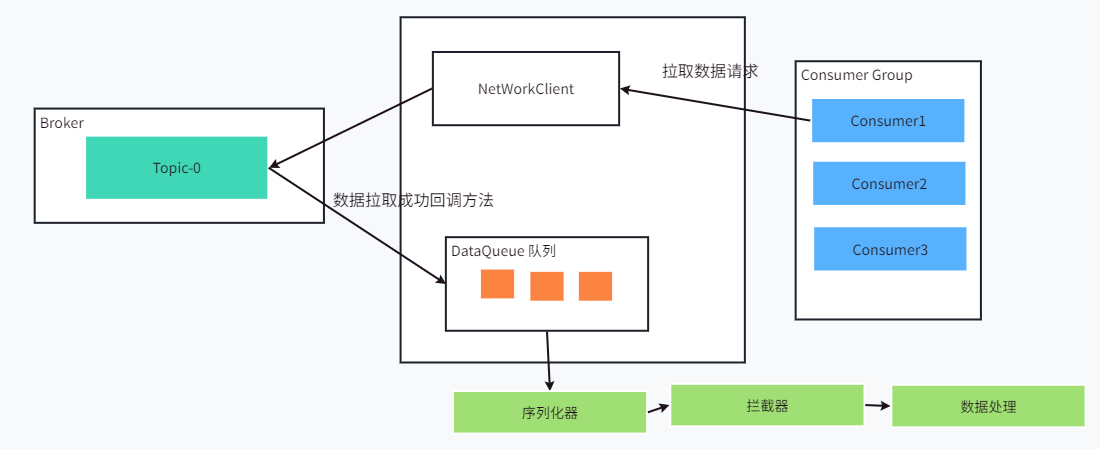
消费者工作流程:
offset:每个消费者对于每个分区都有一个消息偏移量,记录消费者消费到哪个位置了,这个 offset 数据会被持久化到 kafka 的 __consumer_offsets 这个主题中,即使消费者重启,也会从下一个消息进行消费。
5.1、消费者组
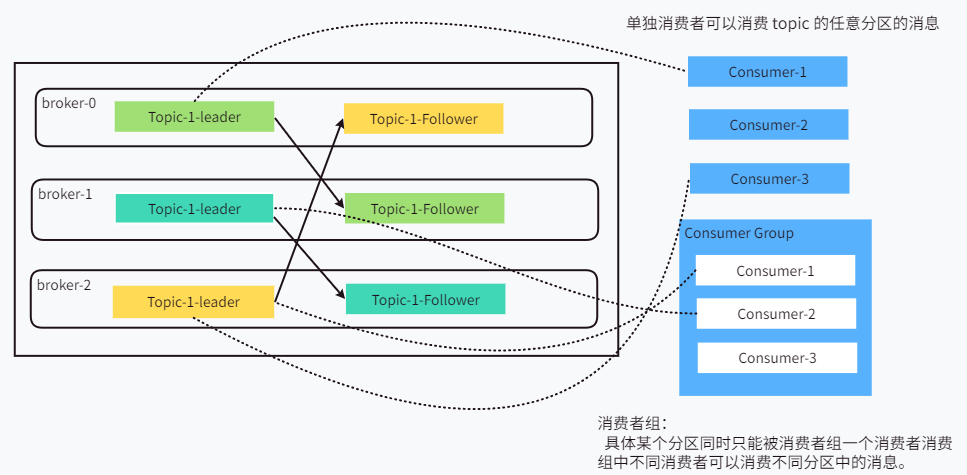
消费者组:由多个 consumer 组成,当消费者的 groupId 相同时这些消费者就属于同一个消费者组。
- 消费者组中的消费者负责消费不同分区数据,一个分区只能由一个组内的一个消费者消费。
- 消费者组之间相互不干扰,组之间可以消费同一个分区。
- 如果消费者数量多于分区数量,则多出来的消费者就会闲置。
消费者组初始化:每个 broker 节点都有一个 coordinator 协调器组件,辅助实现消费者组的初始化和分区分配,指定消费者组中消费者应该消费哪个分区。
- coordinator 的选择:由消费者组 groupId 决定,(groupId 的 hash 值)% 50,(50 是消费者 __consumer_offsets 主题的分区数),找到 __consumer_offsets 在哪个分区上,就由这个分区上的 coordinator 协调器进行负责消费者组消费。
- Consumer Leader 选择:由 coordinator 协调器从消费组中随机选择一个消费者作为 Leader,coordinator 会把消费的 topic 信息发送给 Leader,再由 Leader 分配消费任务,具体哪个消费者消费哪个分区,然后将任务发送给 coordinator。
- coordinator 分配任务:coordinator 会把 Leader 的分配任务发送给消费组中的所有消费者,按照规则进行消费。

注意:所有消费者都和协调器保存 3s 的心跳包,也会有一个连接超时时间,默认 45 s 超过 45s 没有心跳包,那么这个消费者就会被移除,就会触发自动平衡重新分配任务。如果某个消费者某次处理数据时间超过 5 分钟,也会触发自动平衡,将任务交给其它消费者。
消费者消费流程:
- fetch.min.bytes:每批次拉取最小大小,默认 1KB,如果不满足这个大小即使有消息也不会拉取。
- fetch.max.wait.ms:一批数据未到达超时时间,默认500ms,超过这个时间就会拉取一次数据,即使没有达到最小拉取大小。
- fetch.max.bytes:每批次最大抓取大小,默认50MB。
- max.poll.records:一次拉取数据返回消息的最大条数,默认 500 条。
5.2、Java 消费者 API
消费者消费一个主题:
public static void main(String[] args) {Properties properties = new Properties();// 连接集群properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.32.135:9092,192.168.32.136:9092");// 设置消费者的消费组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test2");// 设置key和value的反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);ArrayList<String> topics = new ArrayList<>();topics.add("topic-1");// 设置订阅的主题consumer.subscribe(topics);// 进行拉取数据while (true){// 间隔多少秒拉取一次数据ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));// 拉取的数据for (ConsumerRecord<String, String> record : records) {System.out.println(record);}}
}
消费某一个分区:
// 消费某个主题下的某个分区
List<TopicPartition> topicPartitions = new ArrayList<>();
// 指定主题和分区
TopicPartition partition = new TopicPartition("topic-1", 0);
topicPartitions.add(partition);
consumer.assign(topicPartitions);// 执行消费
while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> record : records) {System.out.println(record);}
}
5.3、消费者分区分配
消费分区策略:在消费者 Leader 分配消费任务时,会根据对应的分配策略分配任务。kafka 中主要分配策略:Range、RoundRobin、Sticky、CooperativeSticky,默认使用
Range + CooperativeSticky,可以使用组合分配策略。
// 设置消费分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RangeAssignor.class.getName() + "," + CooperativeStickyAssignor.class.getName());
Range:
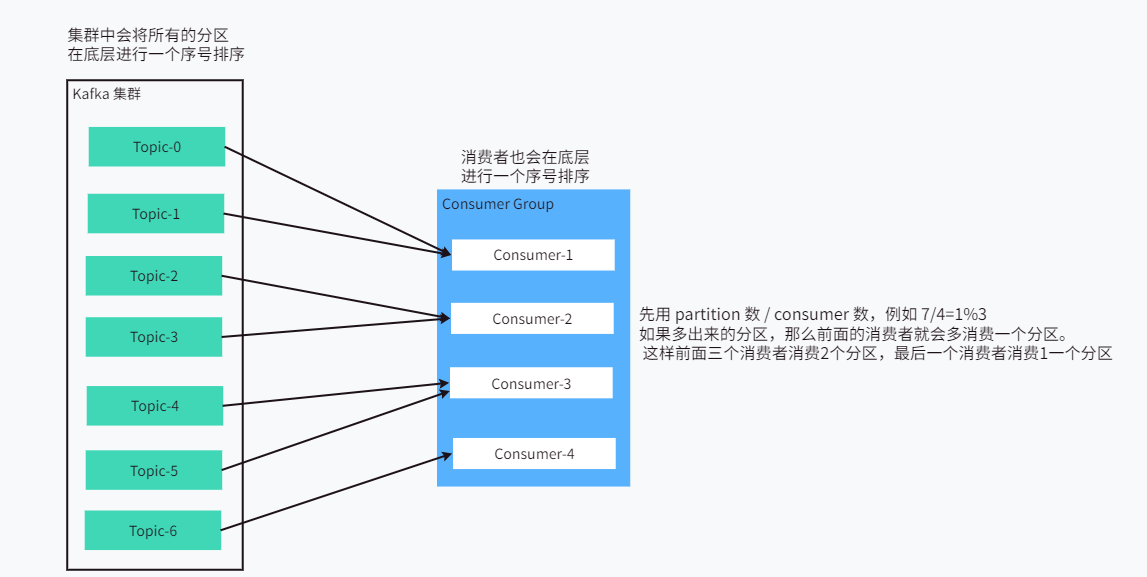
注意:如果消费者组去消费多个主题,就可能存在数据倾斜问题,每个主题多出来的分区就会全部由前面的消费者进行消费。
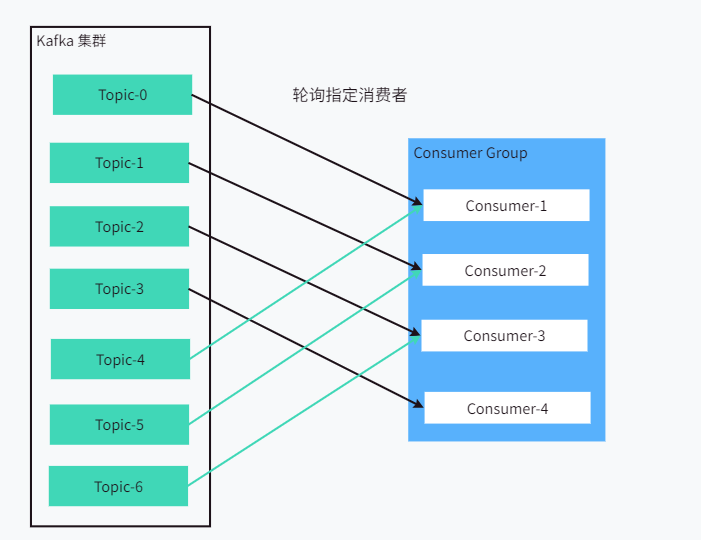
RoundRobin:轮询消费,所有主题的所有分区和所有消费者进行排序,然后针对分区轮询指定消费者进行消费。
Sticky:粘性分配,尽量均衡分配分区,与 Range 相似,但是不是按照顺序进行分配分区,而是随机将分区分配给消费者。
5.4、消费者 offset 维护
消费者 offset :表示消费者消费分区已经消费的位置,0.9版本之前,offset 是存放在 Zookeeper 中,o.9 版本之后是存放在 kafka 的 __consumer_offset 这个主题下的。主题的 key:groupId + tpoic + 分区号,value:offset 值,每隔一段时间就会将这个 topic 进行 compact 数据压缩。
自动 offset 维护:kafka 提供了自动提交 offset 功能,每当消费者消费数据,消费者可以自动向 __consumer_offset 主题提交 offset 数据。
enbale.auto.commit:是否开启自动提交 offset 功能,默认是 true。auto.commit.interval.ms:自动提交 offset 的时间间隔,默认是 5s,单位是毫秒。
// 设置是否自动提交 offset
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, true);
// 设置自动提交的时间
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
手动提交 offset 维护:自动提交 offset 不能掌握提交的时间,有时候需要手动去提交 offset。
- 同步提交:需要将最新一批消息提交完成才会继续拉取数据,提交 offset 并且会自动失败重试。
- 异步提交:处理数据完成后,发出提交 offset 请求后,就继续拉取数据,不会等 offset 提交是是否成功。
// 关闭自动提交
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, false);
// 进行拉取数据
while (true){// 间隔多少秒拉取一次数据ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));// 拉取的数据for (ConsumerRecord<String, String> record : records) {System.out.println(record);}// 提交 offsetconsumer.commitSync(); // 同步提交consumer.commitAsync(); // 异步提交,可以指定异步提交后的回调方法
}
指定 offset 消费:
- earliest:对于同一个消费组,如果从未提交过 offset,自动将偏移量重置为最早偏移量,从头开始消费。但是如果这个消费组提交过 offset,那么效果和 lastest 效果一样。
- latest(默认值):如果没有提交过 offset,只能消费最新的消息,对于历史消息不能消费;如果提交过 offset,那么就从 offset 位置继续消费。
- none:如果消费者组从未提交过 offset,那么就向消费者推送错误,如果有就继续按照 offset 消费数据。
指定 offset 进行消费:直接指定 offset 不行,需要等消费者分区完成后再指定 offset 才会生效。
// 设置订阅的主题,设置消费者分区事件
consumer.subscribe(topics, new ConsumerRebalanceListener() {// 消费者分区前,例如提交偏移量、释放资源@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {}// 设置偏移量、初始化资源@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {// 指定消费的偏移量for (TopicPartition partition : partitions) {// 手动指定消费者从分区哪个 offset 开始消费consumer.seek(partition, 100);}}
});
// 进行拉取数据
while (true){// 间隔多少秒拉取一次数据ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));// 拉取的数据for (ConsumerRecord<String, String> record : records) {System.out.println(record);}
}
按照时间消费:指定开始消费的时间,可以根据时间去获取 offset 值。
Map<TopicPartition, Long> timeForOffset = new HashMap<>();
// 设置消费者分区事件
consumer.subscribe(topics, new ConsumerRebalanceListener() {// 消费者分区前,例如提交偏移量、释放资源@Overridepublic void onPartitionsRevoked(Collection<TopicPartition> partitions) {}// 设置偏移量、初始化资源@Overridepublic void onPartitionsAssigned(Collection<TopicPartition> partitions) {// 指定消费的偏移量for (TopicPartition partition : partitions) {// 设置对应消费的时间戳,key:指定分区,value:消费开始位置的时间戳,从当前时间前一天的消息进行消费timeForOffset.put(partition, System.currentTimeMillis() - 1000 * 60 * 60 * 24 * 10);}// 将时间转换成 offsetMap<TopicPartition, OffsetAndTimestamp> offsets = consumer.offsetsForTimes(timeForOffset);// 将转换后的 offset 指定给消费者for (TopicPartition partition : partitions) {OffsetAndTimestamp offsetAndTimestamp = offsets.get(partition);consumer.seek(partition, offsetAndTimestamp.offset());}}
});// 进行拉取数据
while (true){// 间隔多少秒拉取一次数据ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));// 拉取的数据for (ConsumerRecord<String, String> record : records) {System.out.println(record);}
}
5.5、消费者常见问题
重复消费:消费者消费消息后但是没有到自动提交时间,这时消费者宕机后面重启后就会从上一次自动提交的位置进行消费,就会出现重复消费。
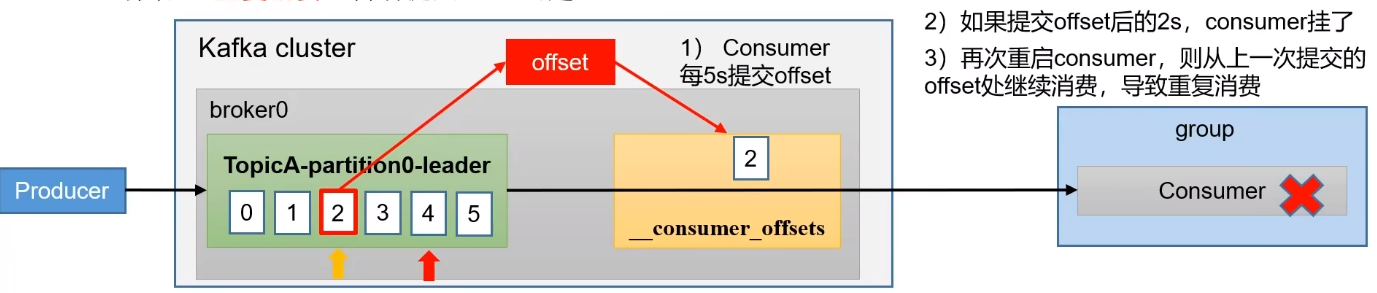
漏消费:设置为手动提交时,当消费者拉取数据后就手动提交 offset,但是消费者在进行处理数据时出现宕机,并没有正常消费数据,但是已经手动提交了 offset 下一次重启就会跳过没有正常消费的数据。

数据积压:当 kafka 中数据过多,消费者端不能够及时消费,导致数据时间过期会删除数据。例如:kafka 有三天数据需要消费,但是消费者消费这些数据需要4天,有些数据消费不及时就会丢失。
- 增加 topic 的分区数量,同时增加消费者数量。消费者=分区数,并行消费。
- 修改
fetch.min.bytes单次拉取大小,提高拉取效率。 - 修改
max.poll.records单次最多拉取消息条数,默认 500 条并且对应修改拉取的最大大小。
6、Kafka-Eagle 监控
- 安装 MySQL 环境。
- 停止 kafka 集群,并修改 kafka 启动运行内存。
# 修改启动命令
vim ./bin/kafka-server-stop.sh# 修改对应内存
# 内存参数
export KAFKA_ HEAP_OPTS="-server -Xms2G -Xmx2G --XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
# Eagle 监控端口
export JMX_PORT="9999"
- 下载安装包并解压,官网地址:https://www.kafka-eagle.org/。
- 配置 Java 环境变量和 EFAK 环境变量。
# java 环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin# EFAK 环境变量
vi /etc/profile
export KE_HOME=/data/soft/new/efak
export PATH=$PATH:$KE_HOME/bin
- 修改配置,
vim ./config/system-config.properties。
# Zookeeper 配置方式
efak.zk.cluster.alias=cluster2
cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181# 端口
efak.webui.port=8048######################################
# kafka mysql jdbc driver address
######################################
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://192.168.32.143:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=xxxxcluster1.efak.offset.storage=kafka
- 启动
./bin/ke.sh start,然后通过 ip地址:端口可以直接访问。
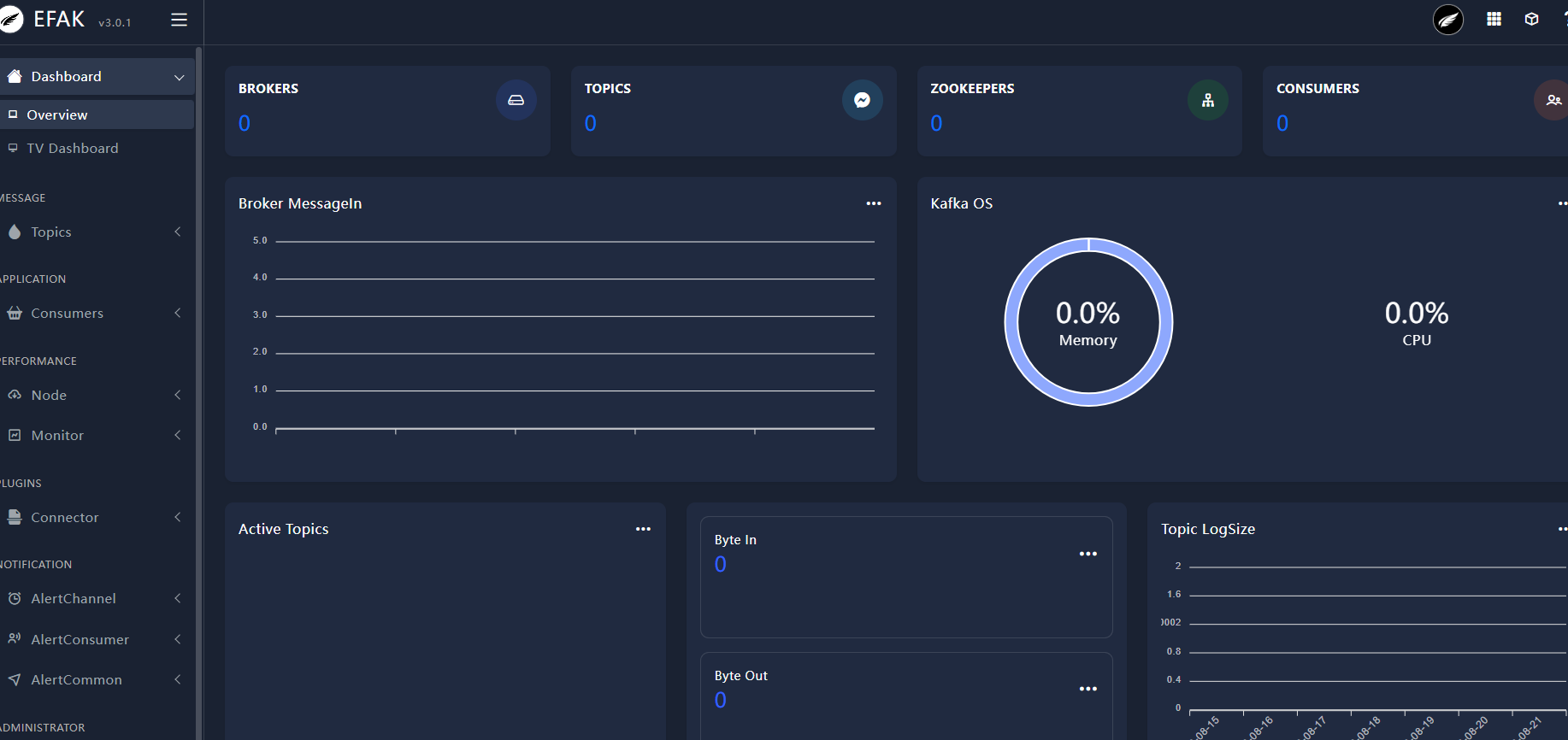
注意:kafka-eagle 暂时只支持 kafka 的 Zookeeper 方式,不支持 Kraft 协议的方式。
Docker 安装 kafka-ui:
# 安装命令
docker run -p 9876:8080 \--name kafka-ui \-e KAFKA_CLUSTERS_0_NAME=kafka-1 \-e KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=192.168.32.135:9092,192.168.32.136:9092 \-e TZ=Asia/Shanghai \-e SERVER_SERVLET_CONTEXT_PATH="/" \-e AUTH_TYPE="LOGIN_FORM" \-e SPRING_SECURITY_USER_NAME=admin \-e SPRING_SECURITY_USER_PASSWORD="admin" \-e LANG=C.UTF-8 \-d provectuslabs/kafka-ui:latest
7、Spring Boot 整合 Kafka
导入依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.7.13</version>
</dependency>
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.8.0</version>
</dependency>
7.1、Kafka 生产者
修改配置:
spring:# kafka 相关配置kafka:bootstrap-servers: 192.168.32.135:9092,192.168.32.136:9092,192.168.32.136:9092# 生产者配置producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerretries: 3acks: -1compression-type: snappybuffer-memory: 64MBbatch-size: 32KB
编写生产者代码:
// 注入kafka
@Resource
private KafkaTemplate<String, String> kafkaTemplate;@GetMapping("/test1")
public void produce(String msg){for (int i=0;i<1000;i++){kafkaTemplate.send("topic-boot", UUID.randomUUID().toString() + i, UUID.randomUUID().toString());}
}
7.2、Kafka 消费者
修改配置:
spring:# kafka 相关配置kafka:bootstrap-servers: 192.168.32.135:9092,192.168.32.136:9092,192.168.32.137:9092# 消费者配置consumer:group-id: testkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer
编写代码:
// 消费者进行消费,id:全局唯一标识
@KafkaListener(id = "consumer1", groupId = "test-1", topics = {"topic-boot","topic-1"})
public void consumer(ConsumerRecord<?, ?> record){// msg:接收到的数据System.out.println(record);
}
相关文章:
Kafka 学习笔记
😀😀😀创作不易,各位看官点赞收藏. 文章目录 Kafka 学习笔记1、消息队列 MQ2、Kafka 下载安装2.1、Zookeeper 方式启动2.2、KRaft 协议启动2.3、Kafka 集群搭建 3、Kafka 之生产者3.1、Java 生产者 API3.2、Kafka 生产者生产分区3…...
vue实现表格的动态高度
需求:表格能够根据窗口的大小自动适配页面高度 防抖和节流函数的使用场景是当需要对频繁触发的事件进行限制时,例如: 防抖函数常用于限制用户在短时间内多次触发某一事件,例如搜索框输入并搜索,当用户一直在输入时,我们可以使用防抖函数来避免多次请求搜索结果,减轻服…...

HodlSoftware-免费在线PDF工具箱 加解密PDF 集成隐私保护功能
HodlSoftware是什么 HodlSoftware是一款免费在线PDF工具箱,集合编辑 PDF 的简单功能,可以对PDF进行加解密、优化压缩PDF、PDF 合并、PDF旋转、PDF页面移除和分割PDF等操作,而且工具集成隐私保护功能,文件只在浏览器本地完成&…...

09 数据库开发-MySQL
文章目录 1 数据库概述2 MySQL概述2.1 MySQL安装2.1.1 解压&添加环境变量2.1.2 初始化MySQL2.1.3 注册MySQL服务2.1.4 启动MySQL服务2.1.5 修改默认账户密码2.1.6 登录MySQL 2.2 卸载MySQL2.3 连接服务器上部署的数据库2.4 数据模型2.5 SQL简介2.5.1 SQL通用语法2.3.2 分类…...
QT通过ODBC连接GBase 8s数据库(Windows)示例
示例环境: 操作系统:Windows 10 64位数据库及CSDK版本:GBase 8s V8.8_3.0.0_1 64位QT:5.12.0 64位 1,CSDK安装及ODBC配置 1.1,免安装版CSDK 下载免安装版的CSDK驱动,地址:https:…...

Java-三个算法冒泡-选择排序,二分查找
Java算法: 冒泡排序; 解析:将前后两个数对比,将大的数(或小的)调换至后面,每轮将对比过程中的最大(或最小)数,调到最后面。每轮对比数减一;初始对比数为数组…...

docker版jxTMS使用指南:使用jxTMS提供数据
本文讲解了如何jxTMS的数据访问框架,整个系列的文章请查看:docker版jxTMS使用指南:4.4版升级内容 docker版本的使用,请查看:docker版jxTMS使用指南 4.0版jxTMS的说明,请查看:4.0版升级内容 4…...

阿里 MySQL 规范
阿里 MySQL 规范 1. 建库建表规范 【推荐】库名与应用/服务名称尽量一致。 【强制】表名不使用复数名词。 说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于DO类名也是单数形式,符合表达习惯。 【推荐】表的…...

C++ Primer阅读笔记--动态内存和智能指针
目录 1--动态内存管理 2--shared_ptr类 2-1--make_shared 函数 2-2--引用计数 2-3--get 3--new和delete 4--shared_ptr和new结合使用 5--unique_ptr 6--weak_ptr 1--动态内存管理 new:在动态内存中为对象分配空间并返回一个指向该对象的指…...
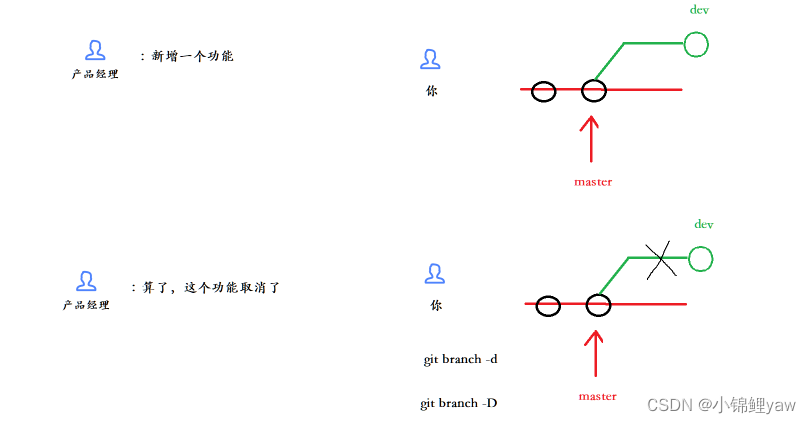
git分支管理策略
git的基础操作以及常用命令在上篇博客哦~ git原理与基本使用 1.分支管理 1.主分支 在版本回退⾥,我们已经知道,每次提交,Git都把它们串成⼀条时间线,这条时间线就可以理解为是⼀个分⽀。截⽌到⽬前,只有⼀条时间线&…...
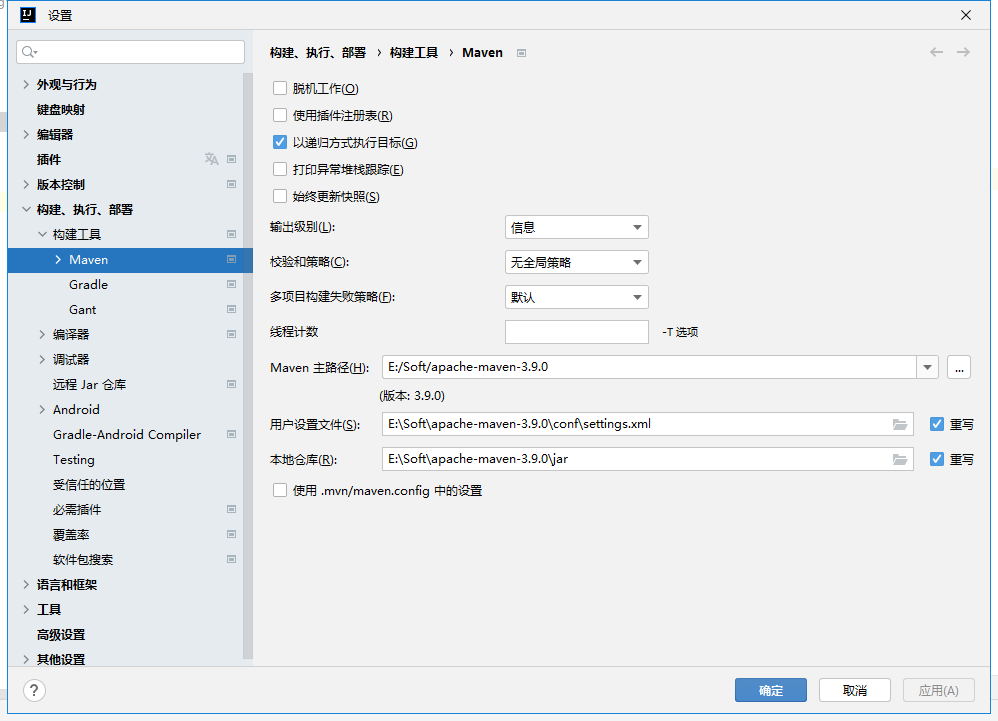
IntelliJ IDEA maven配置,设置pom.xml的配置文件
IntelliJ IDEA项目,选择 文件 设置,弹窗 构建、执行、部署 构建工具 Maven就可以 maven配置好以后,在pom.xml的配置文件中就可以设置对应的jar包了,这样构建的时候自动需要的jar,在项目中导入即 settings.xml文件apa…...
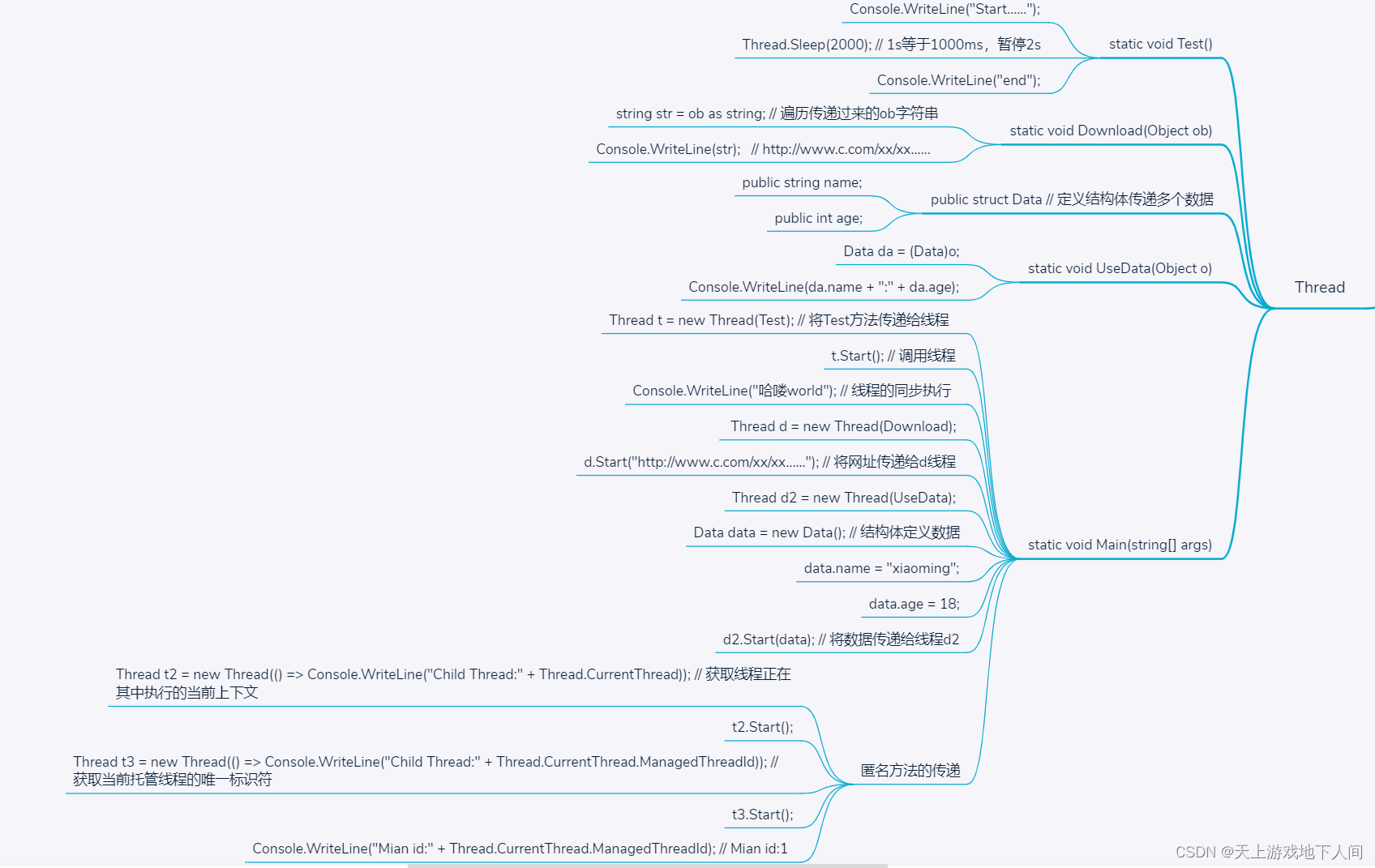
C#__使用Thread启动线程和传输数据
class Program{static void Test(){Console.WriteLine("Start……");Thread.Sleep(2000); // 1s等于1000ms,暂停2sConsole.WriteLine("end");}static void Download(Object ob){string str ob as string; // 遍历传递过来的ob字符串Console.Wr…...

appium2.0+ 单点触控和多点触控新的解决方案
在 appium2.0 之前,在移动端设备上的触屏操作,单手指触屏和多手指触屏分别是由 TouchAction 类,Multiaction 类实现的。 在 appium2.0 之后,这 2 个方法将会被舍弃。 "[Deprecated] TouchAction action is deprecated. Ple…...
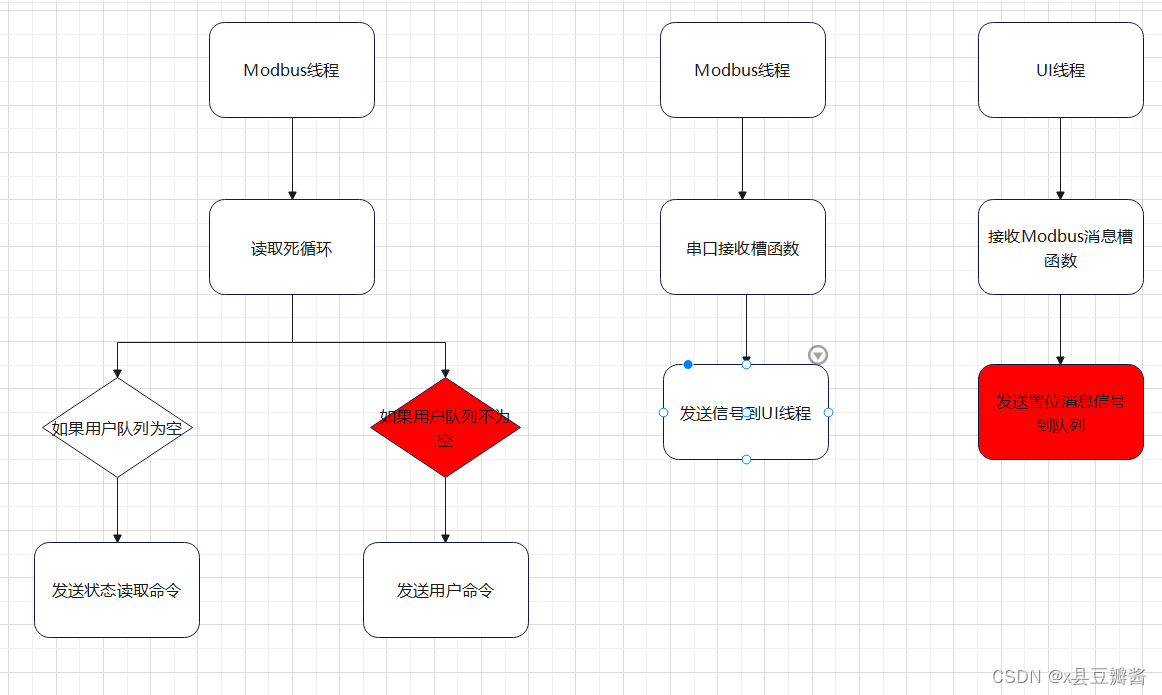
记录一次Modbus通信的置位错误
老套路,一图胜千言,框图可能有点随意,后面我会解释 先描述下背景,在Modbus线程内有一个死循环,一直在读8个线圈的状态,该线程内读到的消息会直接发送给UI线程,UI线程会解析Modbus数据帧…...
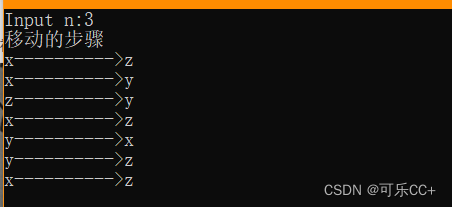
数据结构--递归与分治
汉诺塔分析: 以三层进行分析,大于三层分析情况是一样的。 #include <stdio.h>void move(int n,char x,char y,char z) {if(1 n){printf("%c---------->%c\n",x,z);}else{move(n-1,x,z,y);//将第n-1个盘子从x借助z移动到y printf(&q…...

spring cloud gateway中出现503
spring cloud gateway中出现503 当搭建网关模块的时候出现503的错误的最大的可能就是没有设置负载均衡的依赖包 原先搭建的时候采用的是下面的方式进行设置的 gateway:discovery:locator:enabled: true #可以从nacos进行服务的发现 上面的这种方式可以直接进行注册和发现&…...

战略在集体学习过程中涌现
战略学习派:战略是涌现的学习过程,中国人的话,要交学习费!【安志强趣讲269期】 趣讲大白话:出来混总要交学费 **************************** 中国人有这个意识 新进一个领域,要交学费,有学习过程…...

html动态爱心代码【四】(附源码)
目录 前言 特效 完整代码 总结 前言 情人节马上就要到了,为了帮助大家高效表白,下面再给大家带来了实用的HTML浪漫表白代码(附源码)背景音乐,可用于520,情人节,生日,表白等场景,可直接使用。…...

如何利用SLF4J扩展模块实现高效的日志记录
如何利用SLF4J扩展模块实现高效的日志记录 摘要:SLF4J(Simple Logging Facade for Java)是一个用于 Java 程序中记录日志的简单门面,它提供了一种统一的日志记录接口,可以方便地切换底层的日志实现。SLF4J 还…...
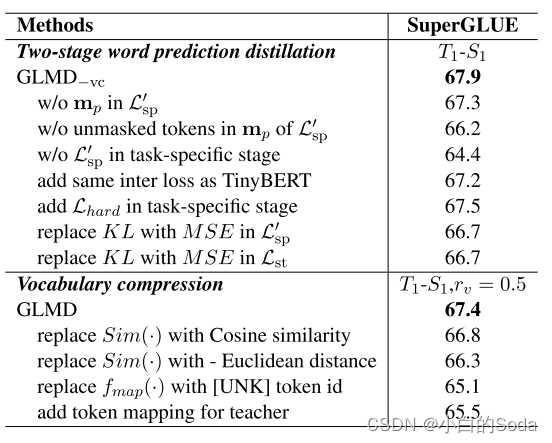
通用语言模型蒸馏-GLMD
文章目录 GLMD一、PPT内容论文背景P1 BackgroundP2 Approach 相关知识P3 知识蒸馏P4 语言建模词预测逻辑 方法P5 两阶段词汇预测蒸馏P6P7 词汇压缩 实验结果P8 results 二、论文泛读2.1 论文要解决什么问题?2.2 论文采用了什么方法?2.4 论文达到什么效果…...

技术解密:Godot RE Tools - 游戏逆向工程的智能解决方案
技术解密:Godot RE Tools - 游戏逆向工程的智能解决方案 【免费下载链接】gdsdecomp Godot reverse engineering tools 项目地址: https://gitcode.com/GitHub_Trending/gd/gdsdecomp Godot RE Tools 是一款专业的Godot游戏逆向工程工具,能够从AP…...

5分钟快速上手:TegraRcmGUI Switch注入图形化工具终极指南
5分钟快速上手:TegraRcmGUI Switch注入图形化工具终极指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI TegraRcmGUI是一款专为Nintendo Switc…...

WhatsNew vs 其他更新提示库:为什么它是iOS开发者的首选
WhatsNew vs 其他更新提示库:为什么它是iOS开发者的首选 【免费下载链接】WhatsNew Showcase new features after an app update similar to Pages, Numbers and Keynote. 项目地址: https://gitcode.com/gh_mirrors/wh/WhatsNew 在iOS应用开发中,…...

Webdash社区贡献指南:如何参与开源项目并开发优质插件
Webdash社区贡献指南:如何参与开源项目并开发优质插件 【免费下载链接】webdash 🔥 Orchestrate your web project with Webdash the customizable web dashboard 项目地址: https://gitcode.com/gh_mirrors/we/webdash Webdash作为一款可定制的W…...

Arm处理器HPA漏洞CVE-2024-5660解析与防护
1. CVE-2024-5660漏洞深度解析在2024年12月首次披露的CVE-2024-5660漏洞,影响了Arm多款主流处理器架构。这个漏洞的核心在于硬件页聚合(Hardware Page Aggregation, HPA)功能与内存转换机制交互时产生的安全问题。当系统同时启用HPA和Stage-1/Stage-2地址转换时&…...

边缘视觉模型实战指南:ViT优化、多模态对齐与事件相机融合
1. 项目概述:这不是一份“论文清单”,而是一份实战派视觉工程师的周度技术雷达上周(2023年8月28日至9月3日)我像往常一样,在晨会前半小时打开arXiv、CVPR官网和几所顶尖实验室的GitHub更新页,准备快速扫一遍…...

微信小程序逆向工程终极指南:wxappUnpacker完整实战解析
微信小程序逆向工程终极指南:wxappUnpacker完整实战解析 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序逆向工程是安全研究人员和技…...
)
手把手教你用AD9834 DDS模块DIY一个可调信号源(附AD原理图/PCB/程序)
从零构建AD9834 DDS可调信号源:硬件搭建与软件调优全指南 在电子设计与射频实验中,一个稳定可靠的可调信号源是不可或缺的工具。商用信号发生器往往价格昂贵,而基于AD9834 DDS模块的DIY方案,能以极低成本实现0-10MHz频率范围内的高…...

Windows到Linux数据传输实战:WinSCP、SCP、Samba与rsync全解析
1. 项目概述:跨越操作系统的数据搬运在混合开发或运维环境中,从Windows向Linux服务器传输数据,是每个开发者、运维工程师甚至数据分析师都绕不开的日常操作。这看似简单的“复制粘贴”,背后却涉及网络协议、权限管理、文件系统差异…...

拒绝盲从:从“上岸村”公考笔试机构推荐谈个性化备考路径
2026 年公考竞争持续升温,国考报名人数再创新高,考生群体日趋多元,需求正从 “有没有课上” 转向 “课程适配性与教学实效性”。行业正告别粗放式扩张,精细化深耕、价值化回归、场景化适配成为新的发展主线。在此背景下࿰…...