2023国赛数学建模思路 - 案例:随机森林
文章目录
- 1 什么是随机森林?
- 2 随机深林构造流程
- 3 随机森林的优缺点
- 3.1 优点
- 3.2 缺点
- 4 随机深林算法实现
- 建模资料
## 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 什么是随机森林?
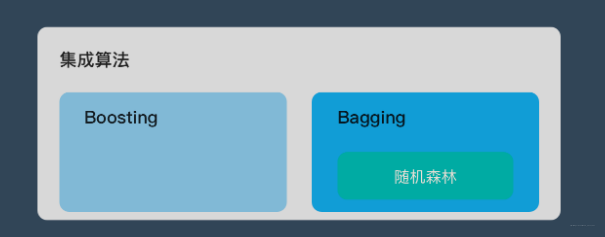
随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之间的关系如下:
决策树 – Decision Tree
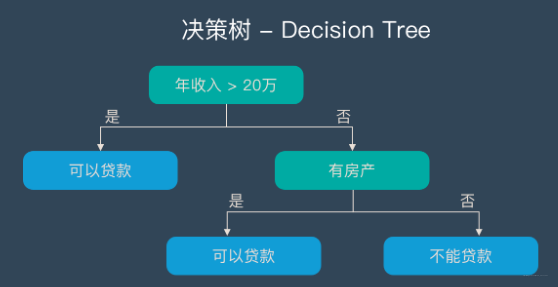
在解释随机森林前,需要先提一下决策树。决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法,上面的图片可以直观的表达决策树的逻辑。
随机森林 – Random Forest | RF
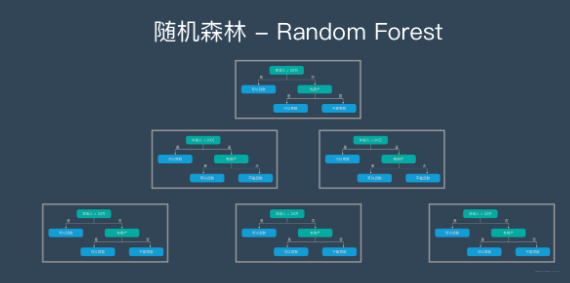
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
2 随机深林构造流程

-
- 一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
-
- 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
-
- 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
-
- 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
3 随机森林的优缺点
3.1 优点
- 它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
3.2 缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
4 随机深林算法实现
数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/
import csv
from random import seed
from random import randrange
from math import sqrtdef loadCSV(filename):#加载数据,一行行的存入列表dataSet = []with open(filename, 'r') as file:csvReader = csv.reader(file)for line in csvReader:dataSet.append(line)return dataSet# 除了标签列,其他列都转换为float类型
def column_to_float(dataSet):featLen = len(dataSet[0]) - 1for data in dataSet:for column in range(featLen):data[column] = float(data[column].strip())# 将数据集随机分成N块,方便交叉验证,其中一块是测试集,其他四块是训练集
def spiltDataSet(dataSet, n_folds):fold_size = int(len(dataSet) / n_folds)dataSet_copy = list(dataSet)dataSet_spilt = []for i in range(n_folds):fold = []while len(fold) < fold_size: # 这里不能用if,if只是在第一次判断时起作用,while执行循环,直到条件不成立index = randrange(len(dataSet_copy))fold.append(dataSet_copy.pop(index)) # pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。dataSet_spilt.append(fold)return dataSet_spilt# 构造数据子集
def get_subsample(dataSet, ratio):subdataSet = []lenSubdata = round(len(dataSet) * ratio)#返回浮点数while len(subdataSet) < lenSubdata:index = randrange(len(dataSet) - 1)subdataSet.append(dataSet[index])# print len(subdataSet)return subdataSet# 分割数据集
def data_spilt(dataSet, index, value):left = []right = []for row in dataSet:if row[index] < value:left.append(row)else:right.append(row)return left, right# 计算分割代价
def spilt_loss(left, right, class_values):loss = 0.0for class_value in class_values:left_size = len(left)if left_size != 0: # 防止除数为零prop = [row[-1] for row in left].count(class_value) / float(left_size)loss += (prop * (1.0 - prop))right_size = len(right)if right_size != 0:prop = [row[-1] for row in right].count(class_value) / float(right_size)loss += (prop * (1.0 - prop))return loss# 选取任意的n个特征,在这n个特征中,选取分割时的最优特征
def get_best_spilt(dataSet, n_features):features = []class_values = list(set(row[-1] for row in dataSet))b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, Nonewhile len(features) < n_features:index = randrange(len(dataSet[0]) - 1)if index not in features:features.append(index)# print 'features:',featuresfor index in features:#找到列的最适合做节点的索引,(损失最小)for row in dataSet:left, right = data_spilt(dataSet, index, row[index])#以它为节点的,左右分支loss = spilt_loss(left, right, class_values)if loss < b_loss:#寻找最小分割代价b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right# print b_loss# print type(b_index)return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right}# 决定输出标签
def decide_label(data):output = [row[-1] for row in data]return max(set(output), key=output.count)# 子分割,不断地构建叶节点的过程对对对
def sub_spilt(root, n_features, max_depth, min_size, depth):left = root['left']# print leftright = root['right']del (root['left'])del (root['right'])# print depthif not left or not right:root['left'] = root['right'] = decide_label(left + right)# print 'testing'returnif depth > max_depth:root['left'] = decide_label(left)root['right'] = decide_label(right)returnif len(left) < min_size:root['left'] = decide_label(left)else:root['left'] = get_best_spilt(left, n_features)# print 'testing_left'sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1)if len(right) < min_size:root['right'] = decide_label(right)else:root['right'] = get_best_spilt(right, n_features)# print 'testing_right'sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1)# 构造决策树
def build_tree(dataSet, n_features, max_depth, min_size):root = get_best_spilt(dataSet, n_features)sub_spilt(root, n_features, max_depth, min_size, 1)return root
# 预测测试集结果
def predict(tree, row):predictions = []if row[tree['index']] < tree['value']:if isinstance(tree['left'], dict):return predict(tree['left'], row)else:return tree['left']else:if isinstance(tree['right'], dict):return predict(tree['right'], row)else:return tree['right']# predictions=set(predictions)
def bagging_predict(trees, row):predictions = [predict(tree, row) for tree in trees]return max(set(predictions), key=predictions.count)
# 创建随机森林
def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees):trees = []for i in range(n_trees):train = get_subsample(train, ratio)#从切割的数据集中选取子集tree = build_tree(train, n_features, max_depth, min_size)# print 'tree %d: '%i,treetrees.append(tree)# predict_values = [predict(trees,row) for row in test]predict_values = [bagging_predict(trees, row) for row in test]return predict_values
# 计算准确率
def accuracy(predict_values, actual):correct = 0for i in range(len(actual)):if actual[i] == predict_values[i]:correct += 1return correct / float(len(actual))if __name__ == '__main__':seed(1) dataSet = loadCSV('sonar-all-data.csv')column_to_float(dataSet)#dataSetn_folds = 5max_depth = 15min_size = 1ratio = 1.0# n_features=sqrt(len(dataSet)-1)n_features = 15n_trees = 10folds = spiltDataSet(dataSet, n_folds)#先是切割数据集scores = []for fold in folds:train_set = folds[:] # 此处不能简单地用train_set=folds,这样用属于引用,那么当train_set的值改变的时候,folds的值也会改变,所以要用复制的形式。(L[:])能够复制序列,D.copy() 能够复制字典,list能够生成拷贝 list(L)train_set.remove(fold)#选好训练集# print len(folds)train_set = sum(train_set, []) # 将多个fold列表组合成一个train_set列表# print len(train_set)test_set = []for row in fold:row_copy = list(row)row_copy[-1] = Nonetest_set.append(row_copy)# for row in test_set:# print row[-1]actual = [row[-1] for row in fold]predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees)accur = accuracy(predict_values, actual)scores.append(accur)print ('Trees is %d' % n_trees)print ('scores:%s' % scores)print ('mean score:%s' % (sum(scores) / float(len(scores))))
建模资料
资料分享: 最强建模资料


相关文章:
2023国赛数学建模思路 - 案例:随机森林
文章目录 1 什么是随机森林?2 随机深林构造流程3 随机森林的优缺点3.1 优点3.2 缺点 4 随机深林算法实现 建模资料 ## 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 什么是随机森林ÿ…...
wxpython:wx.html2 是好用的 WebView 组件
wxpython : wx.html2 是好用的 WebView 组件。 pip install wxpython4.2 wxPython-4.2.0-cp37-cp37m-win_amd64.whl (18.0 MB) Successfully installed wxpython-4.2.0 cd \Python37\Scripts wxdemo.exe 取得 wxPython-demo-4.2.0.tar.gz wxdocs.exe 取得 wxPython-docs-4.…...
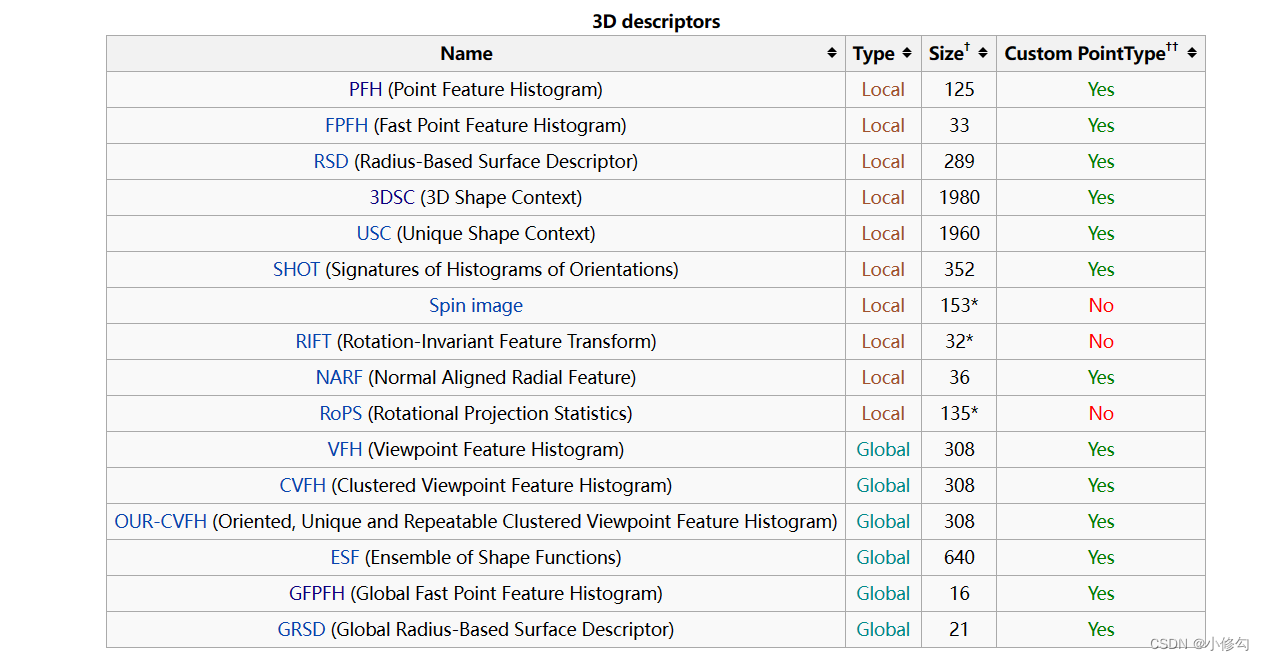
《QT+PCL 第五章》点云特征-PFH
QT增加点云特征PFH 代码用法代码 #include <pcl/io/pcd_io.h> #include <pcl/features/normal_3d.h> #include <pcl/features/pfh.h>int main...
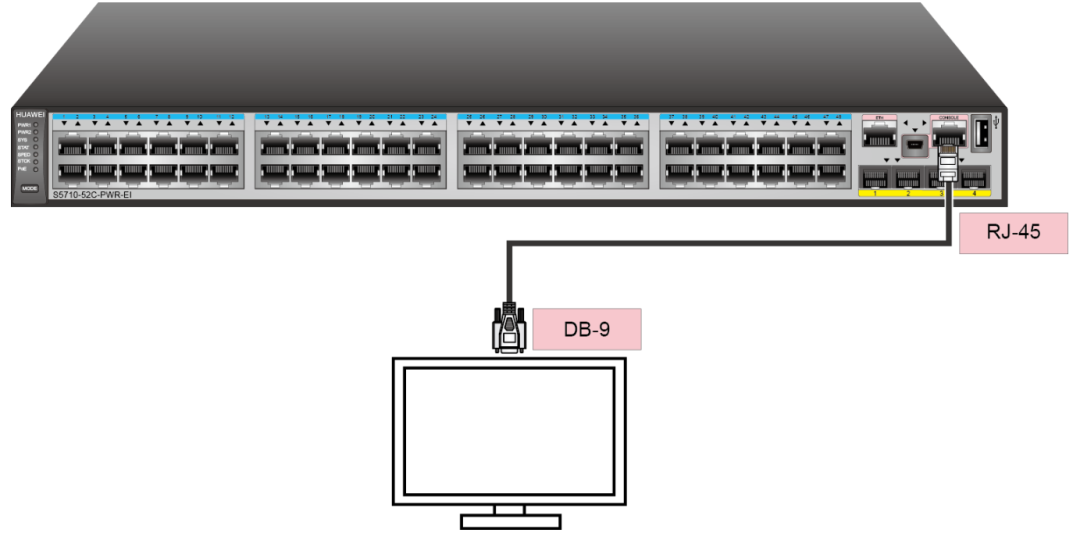
【分享】小型园区组网场景
小型园区组网图 在小型园区中,S2700&S3700通常部署在网络的接入层,S5700&S6700通常部署在网络的核心,出口路由器一般选用AR系列路由器。 接入交换机与核心交换机通过Eth-Trunk组网保证可靠性。 每个部门业务划分到一个VLAN中&#…...
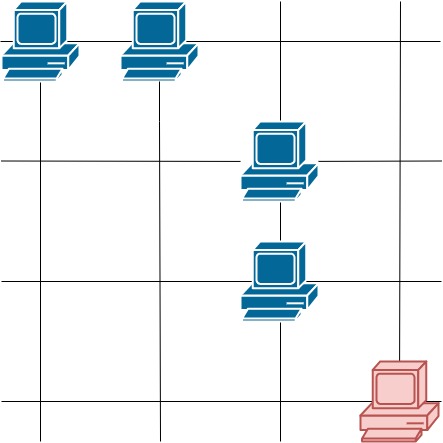
LeetCode 1267. 统计参与通信的服务器
【LetMeFly】1267.统计参与通信的服务器 力扣题目链接:https://leetcode.cn/problems/count-servers-that-communicate/ 这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表…...
)
169. 多数元素(哈希表)
169. 多数元素 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 class Solution { public:int majorityElement(vector<int&…...
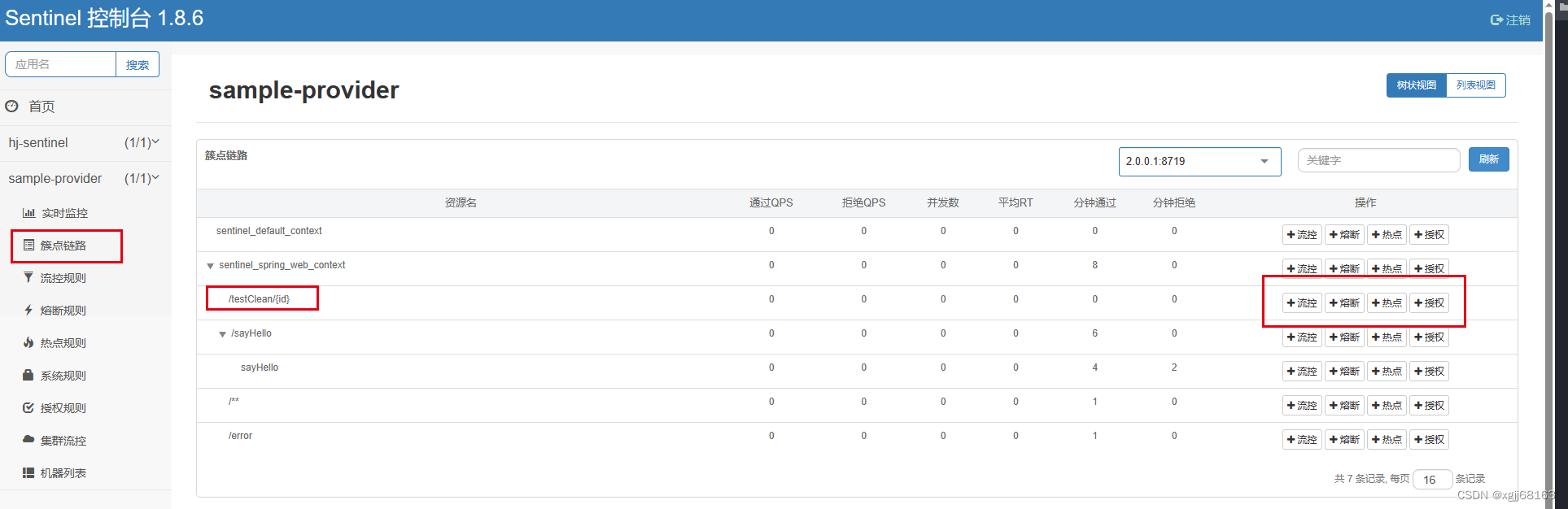
微服务集成spring cloud sentinel
目录 1. sentinel使用场景 2. sentinel组成 3. sentinel dashboard搭建 4. sentinel客户端详细使用 4.1 引入依赖 4.2 application.properties增加dashboard注册地址 4.3 手动增加限流配置类 4.4 rest接口及service类 4.5 通过dashboard动态配置限流规则 1. sentinel使…...
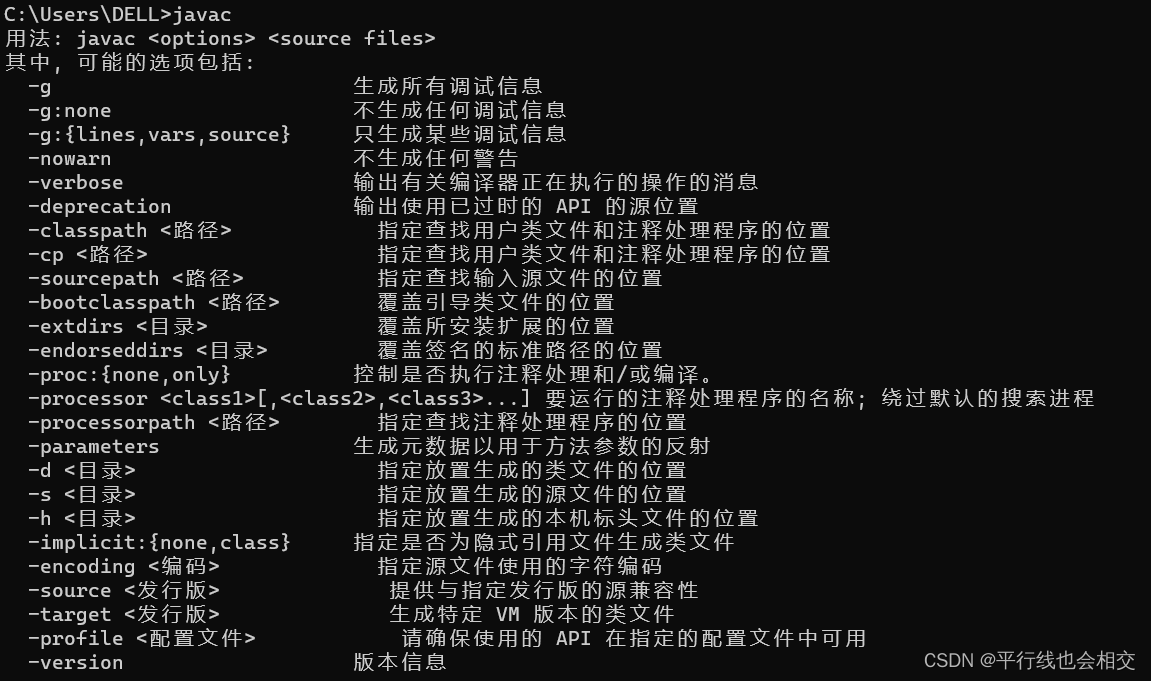
2023年最新版Windows环境下|Java8(jdk1.8)安装教程
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【JavaSE_primary】 jdk1.8的下载和使用总共分为3个步骤: jdk1.8的下载、jdk1.8的安装、配置环境变量。 目录 一、jdk1.8下载…...

linux -- jdk 的安装
jdk 的安装 jdk包下载 链接: https://pan.baidu.com/s/1wa1TJGtCPKQqeCGDZWaP6g 密码: 8el6 安装及验证 ## jdk包上传次目录 /usr/local/software cd /usr/local/software tar -zxvf /usr/local/software/jdk-8u212-linux-x64.tar.gz -C /usr/local cd /usr/local mv jdk1…...

网络安全—黑客技术(学习笔记)
1.网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 2.网络安全市场 一、是市场需求量高; 二、则是发展相对成熟…...
Java入职第十一天,深入了解静态代理和动态代理(jdk、cglib)
一、代理模式 一个类代表另一个类去完成扩展功能,在主体类的基础上,新增一个代理类,扩展主体类功能,不影响主体,完成额外功能。比如买车票,可以去代理点买,不用去火车站,主要包括静态代理和动态代理两种模式。 代理类中包含了主体类 二、静态代理 无法根据业务扩展,…...

Snappy算法:高速压缩和解压缩技术的顶尖玩家
文章首发地址 Snappy是一种快速压缩和解压缩数据的算法。它是由Google开发的,旨在提供高速的压缩和解压缩速度,同时保持较高的压缩比。 Snappy算法的设计目标是追求速度而不是最高的压缩率。相比于其他压缩算法(如Gzip或LZ77)&am…...
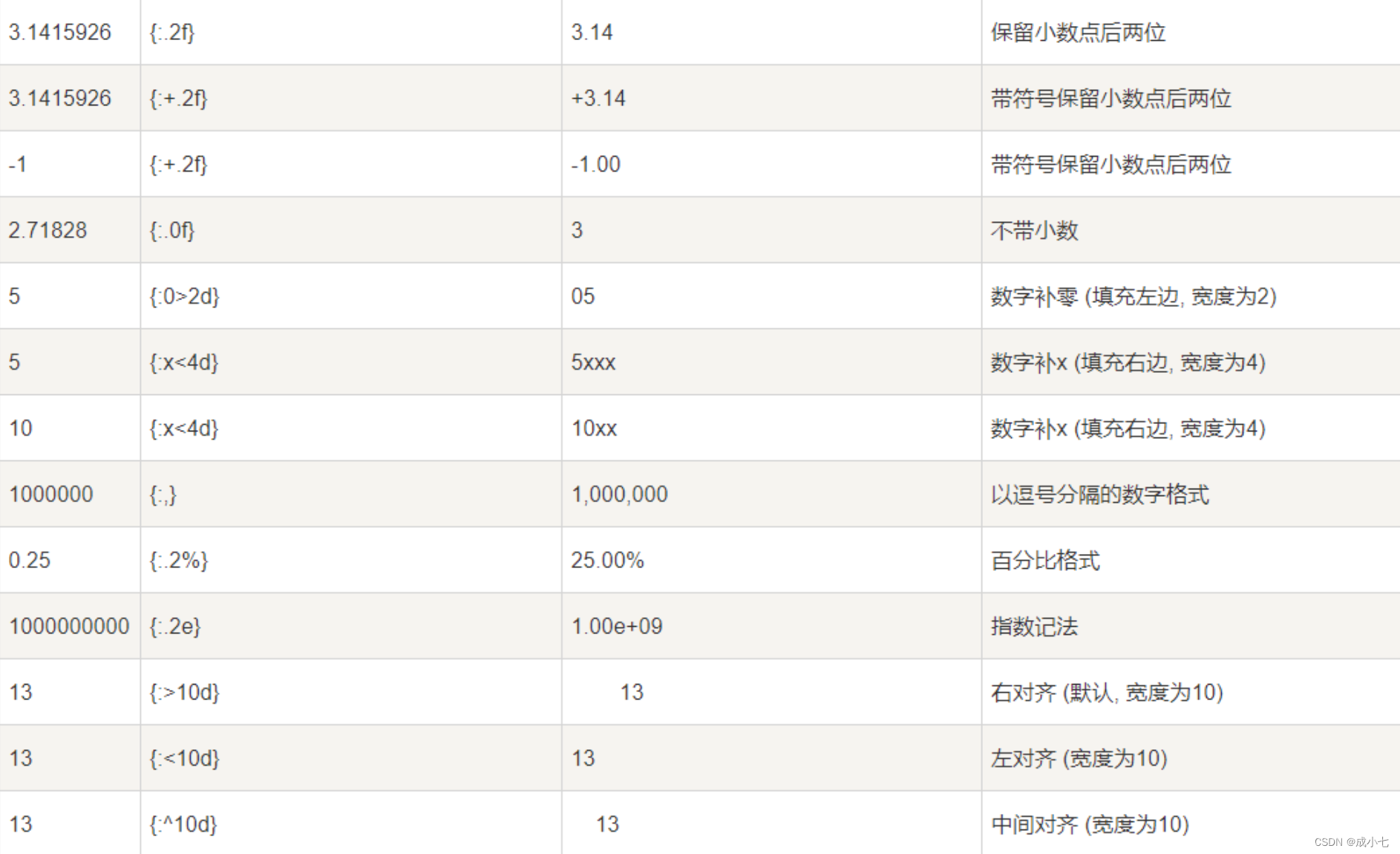
Python中的format()函数详细讲解
注:所以代码皆成功运行,可直接复制运行 一、基本使用 1、Python中的format()函数是一个格式字符串的函数,通过花括号{}识别替换字段,从而完成字符串的格式化。 #format后面放数字、字符串都可以 print("{}喜欢{}岁的{}&qu…...
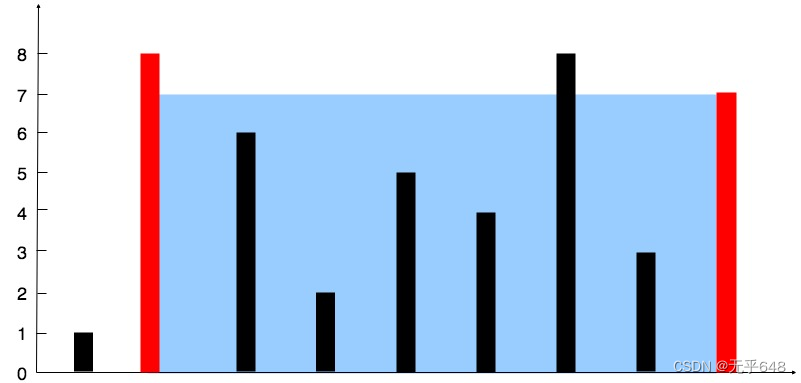
11. 盛最多水的容器(c++题解)
11. 盛最多水的容器(c题解) 给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大…...

历史最佳二季度表现后,爱奇艺想为用户提供更多价值
以爱奇艺为首,随着长视频平台相继转变运营思路,走向盈利目标,最早完成蜕变的爱奇艺,已开始迈向下一阶段。 近日,爱奇艺发布了截至6月30日的2023年第二季度财报。除了依然亮眼的内容表现、业绩成果外,爱奇艺…...
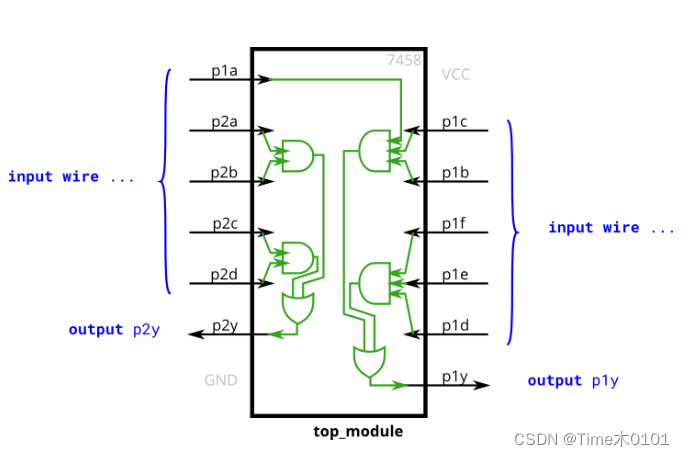
HDLBits-Verilog学习记录 | Verilog Language-Basics(2)
文章目录 9.Declaring wires | wire decl10. 7458 chip 9.Declaring wires | wire decl problem:Implement the following circuit. Create two intermediate wires (named anything you want) to connect the AND and OR gates together. Note that the wire that feeds the …...

Ubuntu22.0网络/网卡丢失
Ubuntu22.0开机突然连不上网了,右上角网络图标消失了,设置里网络也没有了“有线”,只剩下VPN了,试了好多种办法,最终终于解决了。 看到有些直接用的下面的两条命令,有解决的,不过我这不行。 s…...

Linux 常用
系统信息 查看CPU信息(型号) cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c查看物理CPU个数 cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo | grep "c…...
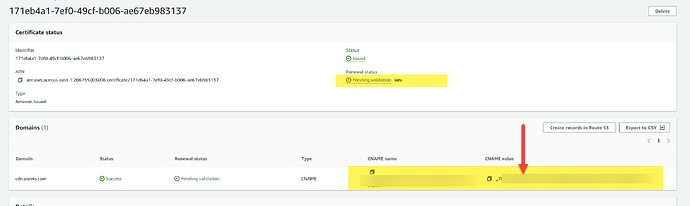
AWS 提示证书签名过期无法自动更新
如果域名没有通过验证的话,证书的过去是没有办法自动更新的。 验证的方式也非常简单,通过下面的配置,把 CNAME添加到你的域名上面,AWS 就可会自动完成验证了。 当添加完成后,AWS 验证需要的时间大致在 30 分钟到 1 个…...
 简介 基本提交相关命令)
Git版本管理(01) 简介 基本提交相关命令
1 git简介 Git是一种分布式版本控制工具,用于跟踪文件和代码的变化,协调多个开发者之间的协作,并提供版本控制和代码管理的功能。 官方学习可参考文档-> Git版本控制工具特点总结如下: 分布式版本控制:Git采用分…...

深入解析GROUPING SETS:多维聚合原理、性能优化与Spark实现
1. 从聚合到多维分析:为什么需要Grouping Sets?在日常的数据分析工作中,我们经常遇到这样的场景:老板不仅要看每个城市、每个车型的销量总和,还想同时看到每个城市的总销量(不考虑车型)…...

打开U盘文件夹变成.exe的问题:在MAC ios中的解决办法
Mac文件夹变成.exe文件,通常是由于病毒将原文件夹隐藏并生成同名exe文件所致。 此类情况多发生于Mac移动硬盘或U盘在Windows系统感染病毒后,病毒会隐藏原始文件夹,并生成伪装成文件夹的exe文件。由于Mac系统默认不显示文件扩展名,…...

森林The Forest - 服务器开服
对于想要自建游戏服务器的玩家,云鸢互联是一个不错的专业联机平台选择。它提供稳定、低延迟且724小时在线的服务器环境,助你轻松打造专属游戏世界。平台主打极致的新手友好——全图形化控制面板,无需编写代码,也无需掌握Linux命令…...

VSCode插件Claude Code for VSCode配置神马中转API详细教程_AI编程工具推荐_ClaudeCode中转API推荐
在 VS Code 中使用 Claude Code,意味着你可以把大模型的编码能力真正“嵌入”到日常开发流程中,而不是停留在浏览器里来回复制代码。Claude Code for VSCode 是 Anthropic 官方推出的 VS Code 扩展,它为 Claude Code 提供了原生的图形化交互界…...

【火箭】基于matlab模拟运载火箭俯仰控制系统中基于IMU的故障检测并结合执行器动力学【含Matlab源码 15550期】含报告
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

单神经元动态记忆机制及其神经形态计算应用
1. 动态记忆的神经实现范式革新在神经科学与类脑计算领域,动态记忆(或称工作记忆)一直被视为认知功能的基础模块。传统理论认为,这种能够短暂保持神经活动状态的功能必须依赖于神经元群体构成的递归网络——通过兴奋性神经元间的相…...

GAN与密码学的真实接口:从概念纠偏到工程落地
1. 项目概述:这不是密码学,也不是GAN训练指南,而是一场概念误读的深度解剖 “Understanding GAN Cryptography”——这个标题一出现,我就在笔记本上划了三道横线。不是因为难,而是因为它根本不存在。过去三年里&#x…...

如何用免费纹理打包器优化游戏性能:5个实战技巧提升加载速度
如何用免费纹理打包器优化游戏性能:5个实战技巧提升加载速度 【免费下载链接】free-tex-packer Free texture packer 项目地址: https://gitcode.com/gh_mirrors/fr/free-tex-packer Free Texture Packer 是一款完全开源的精灵表生成工具,专门为游…...

TDA4VEN-Q1入门级ADAS SoC:异构架构与全景泊车方案实战
1. 项目概述:为什么选择TDA4VEN-Q1这颗“入门级”SoC?在汽车电子,尤其是ADAS(高级驾驶辅助系统)领域,选型永远是项目成败的第一步。面对市场上琳琅满目的处理器,从动辄几十TOPS算力的域控制器芯…...

端侧AI与嵌入式系统融合:从模型轻量化到5G通信的产业化落地
1. 从展会看趋势:端侧AI与嵌入式系统的深度融合最近在德国纽伦堡举办的国际嵌入式展览会,可以说是全球嵌入式技术发展的风向标。作为从业者,我每年都会关注这个展会,因为它总能揭示未来几年工业和技术应用的核心走向。今年&#x…...