Scikit-learn强化学习代码批注及相关练习
一、游戏介绍
木棒每保持平衡1个时间步,就得到1分。每一场游戏的最高得分为200分每一场游戏的结束条件为木棒倾斜角度大于41.8°或者已经达到200分。最终获胜条件为最近100场游戏的平均得分高于195。代码中env.step(),的返回值就分别代表了。观测Observation:当前step执行后,环境的观测。奖励Reward:执行上一步动作(action)后,智能体(agent)获得的奖励,不同的环境中奖励值变化范围也有不同,但是强化学习的目标就是总奖励值最大。完成Done表示是否需要将环境重置env.reset,大多数情况下,当Done为True时,就表明当前回合(episode)结束。信息Info:针对调试过程的诊断信息,在标准的智能体仿真评估当中不会使用到这个info。

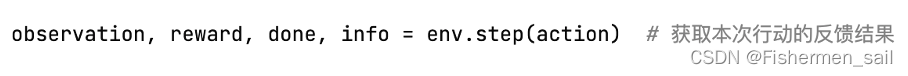
二、代码批注
import gym
import numpy as npenv = gym.make('CartPole-v0')max_number_of_steps = 200 # 每一场游戏的最高得分
#---------获胜的条件是最近100场平均得分高于195-------------
goal_average_steps = 195
num_consecutive_iterations = 100
#----------------------------------------------------------
num_episodes = 5000 # 共进行5000场游戏
last_time_steps = np.zeros(num_consecutive_iterations) # 只存储最近100场的得分(可以理解为是一个容量为100的栈)# q_table是一个256*2的二维数组
# 离散化后的状态共有4^4=256中可能的取值,每种状态会对应一个行动
# q_table[s][a]就是当状态为s时作出行动a的有利程度评价值
# 我们的AI模型要训练学习的就是这个映射关系表
q_table = np.random.uniform(low=-1, high=1, size=(4 ** 4, env.action_space.n))# 分箱处理函数,把[clip_min,clip_max]区间平均分为num段,位于i段区间的特征值x会被离散化为i
def bins(clip_min, clip_max, num):return np.linspace(clip_min, clip_max, num + 1)[1:-1]# 离散化处理,将由4个连续特征值组成的状态矢量转换为一个0~~255的整数离散值
def digitize_state(observation):# 将矢量打散回4个连续特征值cart_pos, cart_v, pole_angle, pole_v = observation# 分别对各个连续特征值进行离散化(分箱处理)digitized = [np.digitize(cart_pos, bins=bins(-2.4, 2.4, 4)),np.digitize(cart_v, bins=bins(-3.0, 3.0, 4)),np.digitize(pole_angle, bins=bins(-0.5, 0.5, 4)),np.digitize(pole_v, bins=bins(-2.0, 2.0, 4))]# 将4个离散值再组合为一个离散值,作为最终结果return sum([x * (4 ** i) for i, x in enumerate(digitized)])# 根据本次的行动及其反馈(下一个时间步的状态),返回下一次的最佳行动
def get_action(state, action, observation, reward):next_state = digitize_state(observation) # 获取下一个时间步的状态,并将其离散化next_action = np.argmax(q_table[next_state]) # 查表得到最佳行动#-------------------------------------训练学习,更新q_table----------------------------------alpha = 0.2 # 学习系数αgamma = 0.99 # 报酬衰减系数γq_table[state, action] = (1 - alpha) * q_table[state, action] + alpha * (reward + gamma * q_table[next_state, next_action])# -------------------------------------------------------------------------------------------return next_action, next_statedef get_action2(state, action, observation, reward, episode):next_state = digitize_state(observation)epsilon = 0.2*(0.95**episode) # ε-贪心策略中的εif epsilon <= np.random.uniform(0, 1):next_action = np.argmax(q_table[next_state])else:next_action = np.random.choice([0, 1])#-------------------------------------训练学习,更新q_table----------------------------------alpha = 0.2 # 学习系数αgamma = 0.99 # 报酬衰减系数γq_table[state, action] = (1 - alpha) * q_table[state, action] + alpha * (reward + gamma * q_table[next_state, next_action])# -------------------------------------------------------------------------------------------return next_action, next_state# 重复进行一场场的游戏
for episode in range(num_episodes):observation = env.reset() # 初始化本场游戏的环境state = digitize_state(observation) # 获取初始状态值action = np.argmax(q_table[state]) # 根据状态值作出行动决策episode_reward = 0# 一场游戏分为一个个时间步for t in range(max_number_of_steps):env.render() # 更新并渲染游戏画面observation, reward, done, info = env.step(action) # 获取本次行动的反馈结果print(reward)if done:reward = -200action, state = get_action2(state, action, observation, reward, episode) # 作出下一次行动的决策episode_reward += rewardif done:# print('%d Episode finished after %f time steps / mean %f' % (episode, t + 1, last_time_steps.mean()))last_time_steps = np.hstack((last_time_steps[1:], [episode_reward])) # 更新最近100场游戏的得分stackbreak# 如果最近100场平均得分高于195if (last_time_steps.mean() >= goal_average_steps):# print('Episode %d train agent successfuly!' % episode)breakprint('Failed!')
三、问题回答
代码中两个策略get_action和get_action2分别对应哪个算法?去除第73-74行游戏结束的reward值赋值,结果有什么变化?
get_action:Q-learning
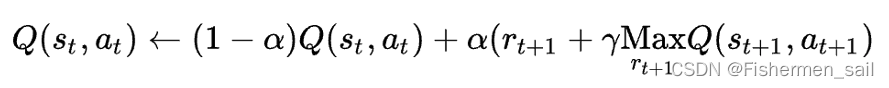
上面的α被称为学习系数,γ被称为报酬衰减系数,rt为时间步为t时得到的报酬。如果在时间步t时,状态为st,我们采取的行动为at,本次行动的有利程度记为Q(st,at)。

get_action2:Q-learning +ε-贪心策略
在get_action2中加入了贪心的策略。以ε的概率以均匀概率随机选一个方向进行移动;以1-ε的概率选择目前为止探索到的对于当前状态的最佳行动方向进行移动。

如果取去掉reward,得不到反馈。在main函数中的开头,这里的意思其实就是每次获得一个最好的action,然后计算,用更好的去填补他。这里evn.step每次返回的reward都是1,if done其实就代表了游戏被迫结束,如果不减值,那么相当于对模型没有反馈,模型会每次会找最好的值,但呢个最好的值是随机算出来的,最终的结果会卡在一个比较低的分数附近上上下下。


相关文章:
Scikit-learn强化学习代码批注及相关练习
一、游戏介绍 木棒每保持平衡1个时间步,就得到1分。每一场游戏的最高得分为200分每一场游戏的结束条件为木棒倾斜角度大于41.8或者已经达到200分。最终获胜条件为最近100场游戏的平均得分高于195。代码中env.step(),的返回值就分…...
执行jmeter端口不够用报错(Address not available)
执行jmeter端口不够用报错(Address not available) linux解决方案 // 增加本地端口范围 echo 1024 65000 > /proc/sys/net/ipv4/ip_local_port_range// 启用快速回收TIME_WAIT套接字 sudo sysctl -w net.ipv4.tcp_tw_recycle 1// 启用套接字的重用 sudo sysctl -w net.ipv4.…...
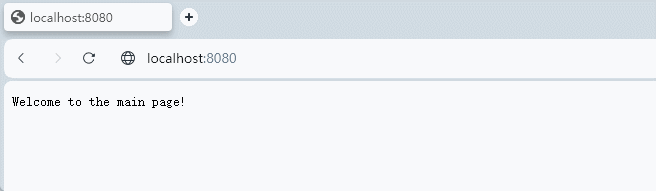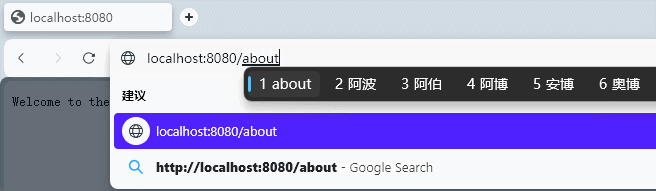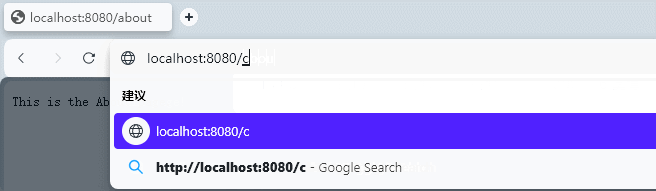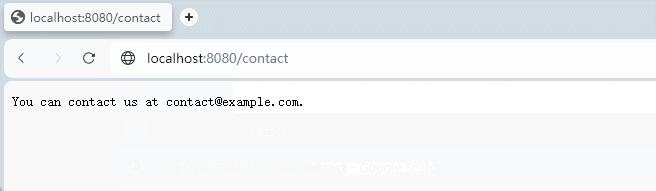
【Go Web 篇】从零开始:构建最简单的 Go 语言 Web 服务器
随着互联网的迅速发展,Web 服务器成为了连接世界的关键组件之一。而在现代编程语言中,Go 语言因其卓越的性能和并发能力而备受青睐。本篇博客将带你从零开始,一步步构建最简单的 Go 语言 Web 服务器,让你对 Go 语言的 Web 开发能力…...

Android系统-性能-优化概述
目录 引言: APP优化: 网络优化: 内存优化: 卡顿优化: 引言: 先大概对Android性能优化做一个简单分类和梳理。由于性能影响因素多,比如本文分类的APP,内存,网络&…...
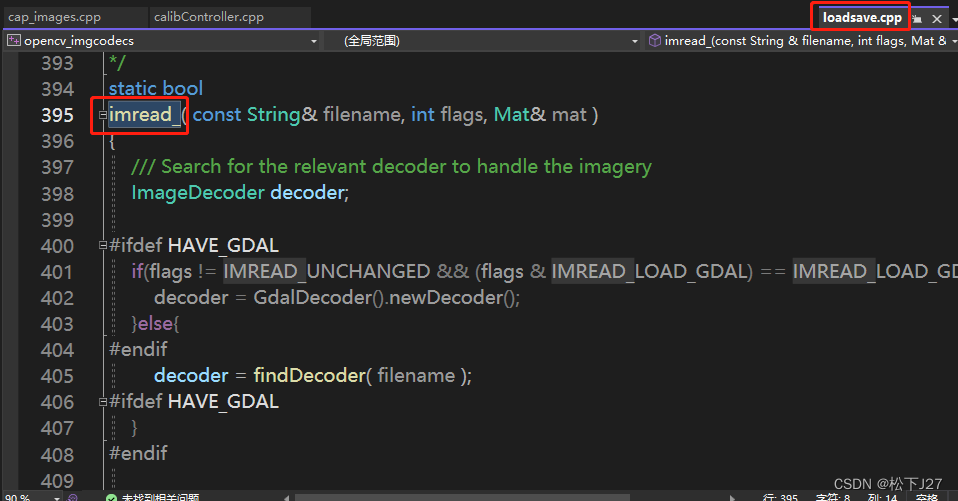
用Cmake build OpenCV后,在VS中查看OpenCV源码的方法(环境VS2022+openCV4.8.0) Part II
用Cmake build OpenCV后,在VS中查看OpenCV源码的方法 Part II 用Cmake build OpenCV后,在VS中查看OpenCV源码的方法(环境VS2022openCV4.8.0) Part I_松下J27的博客-CSDN博客 在上一篇文章中,我用cmake成功的生成了ope…...
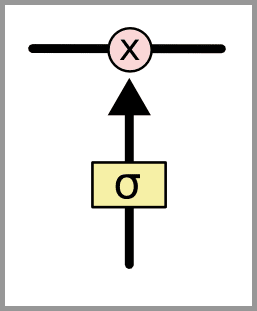
深度学习5:长短期记忆网络 – Long short-term memory | LSTM
目录 什么是 LSTM? LSTM的核心思路 什么是 LSTM? 长短期记忆网络——通常被称为 LSTM,是一种特殊的RNN,能够学习长期依赖性。由 Hochreiter 和 Schmidhuber(1997)提出的,并且在接下来的工作中…...

LabVIEW开发灭火器机器人
LabVIEW开发灭火器机器人 如今,自主机器人在行业中有着巨大的需求。这是因为它们根据不同情况的适应性。由于消防员很难进入高风险区域,自主机器人出现了。该机器人具有自行检测火灾的能力,并通过自己的决定穿越路径。 由于消防安全是主要问…...
1.2 Kali Linux的网络配置
前言 最新文章请见此处,持续更新,敬请订阅!https://blog.csdn.net/algorithmyyds/category_12418682.html 网络在如今的社会已是十分重要的媒介,如果没有网络,很多事情将难以办成。渗透测试也是一样——毕竟在攻击机…...

目标检测的训练过程
数据集准备(Dataset preparation): 收集或创建带有注释的数据集,其中包括图像或帧以及标注,指定了其中物体的位置和类别。标注通常包括边界框坐标(x、y、宽度、高度)和相应的类别标签。数据预处理: 将图像调整为模型能…...

软考高级系统架构设计师系列论文七十七:论软件产品线技术
软考高级系统架构设计师系列论文七十七:论软件产品线技术 一、摘要二、正文三、总结一、摘要 本人在测井行业的一个国有企业软件开发部工作,从2021年初开始,我陆续参加了多个测井软件开发项目,这些项目都是测井行业资料处理解释软件,具有很强的行业特征,其开发方向和应用…...

基于大语言模型知识问答应用落地实践 – 知识库构建(上)
01 背景介绍 随着大语言模型效果明显提升,其相关的应用不断涌现呈现出越来越火爆的趋势。其中一种比较被广泛关注的技术路线是大语言模型(LLM)知识召回(Knowledge Retrieval)的方式,在私域知识问答方面可以…...
一文1500字从0到1搭建 Jenkins 自动化测试平台
Jenkins 自动化测试平台的作用 自动化构建平台的执行流程(目标)是: 我们将代码提交到代码托管工具上,如github、gitlab、gitee等。 1、Jenkins要能够检测到我们的提交。 2、Jenkins检测到提交后,要自动拉取代码&#x…...

前端面试:【实际项目经验】团队协作、代码管理和Git命令梳理
在现代软件开发中,团队协作、代码管理和版本控制是至关重要的方面。本文将分享一些实际项目经验,重点关注团队协作、代码管理,以及Git版本控制的关键命令和最佳实践。 团队协作: 明确角色和责任: 在项目开始阶段&#…...

关于异数OS服务器CPU效能分析工具
该工具发布背景 近年来,国产服务器CPU产业的逐渐发展,但由于专业性较差,与国外存在40年以上技术差距,一些服务器CPU厂商利用信息差来制造一些非专业的数据夸大并虚假宣传混淆视听,成功达到劣币驱良币的目标࿰…...

十四、pikachu之XSS
文章目录 1、XSS概述2、实战2.1 反射型XSS(get)2.2 反射型XSS(POST型)2.3 存储型XSS2.4 DOM型XSS2.5 DOM型XSS-X2.6 XSS之盲打2.7 XSS之过滤2.8 XSS之htmlspecialchars2.9 XSS之href输出2.10 XSS之JS输出 1、XSS概述 Cross-Site S…...

五分钟了解最短路径寻路算法:Dijkstra 迪杰斯特拉
最短路径查找算法 寻路算法在生活中应用十分常见。本文实现的是关于图的最短路径查找算法。 该算法比较常见于游戏和室内地图导航。 实现 例子:几个节点之间,相连接的线段有固定长度,该长度决就是通过代价。查找到花费最少的路径。该图结构…...
【ARM】Day8 中断
1. 思维导图 2. 实验要求: 实现KEY1/LEY2/KE3三个按键,中断触发打印一句话,并且灯的状态取反 key1 ----> LED3灯状态取反 key2 ----> LED2灯状态取反 key3 ----> LED1灯状态取反 key3.h #ifndef __KEY3_H__ #define __KEY3_H__#in…...

大数据Flink(六十八):SQL Table 的基本概念及常用 API
文章目录 SQL & Table 的基本概念及常用 API 一、一个 Table API\SQL任务的代码结构...

算法练习- 其他算法练习6
文章目录 数字序列比大小最佳植树距离文艺汇演计算误码率二维伞的雨滴效应阿里巴巴找黄金宝箱4 数字序列比大小 A、B两人一人一个整数数组,长度相等,元素随即;两人随便拿出一个元素(弹出),比较大小&#x…...

ModaHub魔搭社区:WinPlan经营大脑管理中心
角色权限 展示设置的角色,及对应的成员及权限点。角色、成员、权限点可自由配置;管理员的角色不可删除、权限点默认全部不可更改。 WinPlan决策系统 算力 阿里云 腾讯云 AWS亚马逊 框架 业务数据基座 WinPlan垂直大模型 模型 分...
)
AI动态简报之技术前沿篇(2026.05.22)
📅 2026年5月22日 | 关注方向:AI技术突破 大模型创新 AI Agent 生成式AI 多模态AI 🔥 第1条:谷歌I/O 2026三箭齐发——Gemini 3.5 Flash速度碾压4倍、Spark全天候Agent、Omni全栈多模态 核心内容: 谷歌I/O 2026以…...

【论文阅读】ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training
快速了解部分 基础信息(英文): 1.题目: ManiFlow: A General Robot Manipulation Policy via Consistency Flow Training 2.时间: 2025.09 3.机构: University of Washington, UC San Diego, Nvidia, Allen Institute for AI 4.3个关键词: Fl…...

抖音下载神器:免费批量下载抖音视频、图集、音乐和直播回放完整指南
抖音下载神器:免费批量下载抖音视频、图集、音乐和直播回放完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser f…...

在昇腾NPU上写NumPy代码是种什么体验?asnumpy实战踩坑全记录
前言 最近项目需要在昇腾NPU上跑一些数值计算,不是训练模型,就是纯算东西——矩阵分解、特征值、随机采样之类的。一开始我想,NumPy代码直接跑不就行了? 不行。NumPy跑在CPU上,数据要从NPU搬回CPU才能算,…...

对比直接购买,使用Taotoken的Token Plan套餐如何节省API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买,使用Taotoken的Token Plan套餐如何节省API成本 1. 成本管理中的常见挑战 对于需要持续调用大模型API的开…...

超全 PS 快捷键汇总!新手一键收藏终身受用
对于经常使用Photoshop修图、做设计的小伙伴来说,最影响效率的从来不是创意不足,而是频繁点击菜单栏找功能。明明几秒就能完成的操作,却因为不熟悉工具,反复查找按钮、低效操作,大大拖慢修图节奏。熟练掌握PS快捷键&am…...

G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案
G-Helper终极指南:华硕笔记本轻量控制中心的3步快速配置方案 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbo…...
)
保姆级教程:用微信小程序测试号搞定getPhoneNumber功能(绕过企业认证限制)
微信小程序测试号实战:零成本解锁getPhoneNumber全流程指南 最近在帮朋友开发一个预约类小程序时,遇到了一个典型问题:需要获取用户手机号进行预约确认,但个人开发者账号无法直接调用getPhoneNumber接口。这让我想起了三年前第一次…...
:大模型落地的确定性保障机制)
人在回路(HITL):大模型落地的确定性保障机制
1. 什么是“人在回路中”:不是概念炒作,而是当前大模型落地的生存刚需上周茶歇时,我和同事聊起一个很实在的问题:我们团队刚上线的客服对话系统,明明用了最新版的开源大模型做底座,为什么用户投诉里反复出现…...

Docker 部署实战:前端应用容器化指南
Docker 部署实战:前端应用容器化指南 什么是 Docker? Docker 是一个开源平台,用于开发、部署和运行应用程序。它使用容器化技术,将应用程序及其依赖打包在一个独立的容器中。 Docker 的优势 一致性:开发环境与生产环境…...